 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Grouped self-attention mechanism for a memory-efficient Transformer
Oct 06, 2022
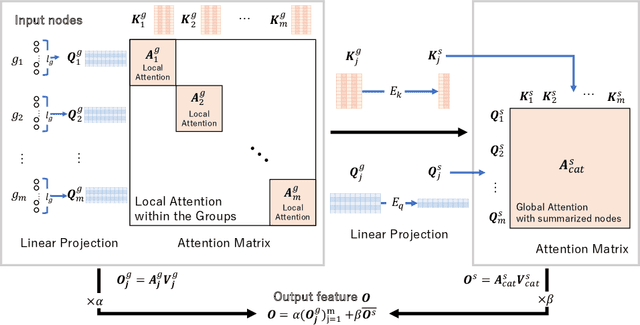
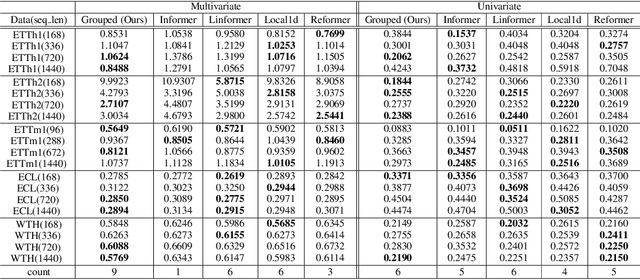
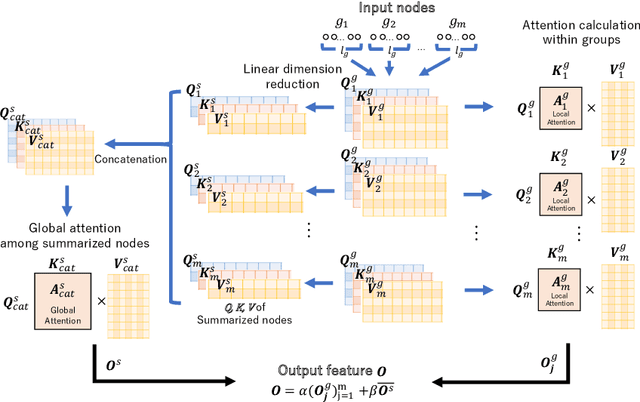
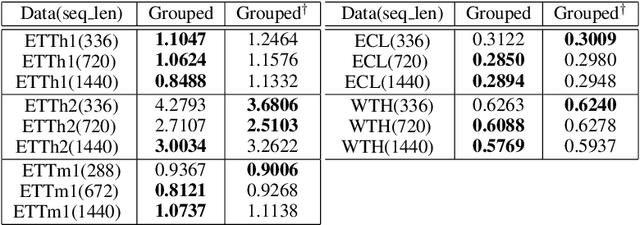
Time-series data analysis is important because numerous real-world tasks such as forecasting weather, electricity consumption, and stock market involve predicting data that vary over time. Time-series data are generally recorded over a long period of observation with long sequences owing to their periodic characteristics and long-range dependencies over time. Thus, capturing long-range dependency is an important factor in time-series data forecasting. To solve these problems, we proposed two novel modules, Grouped Self-Attention (GSA) and Compressed Cross-Attention (CCA). With both modules, we achieved a computational space and time complexity of order $O(l)$ with a sequence length $l$ under small hyperparameter limitations, and can capture locality while considering global information. The results of experiments conducted on time-series datasets show that our proposed model efficiently exhibited reduced computational complexity and performance comparable to or better than existing methods.
Probabilistic Model Incorporating Auxiliary Covariates to Control FDR
Oct 06, 2022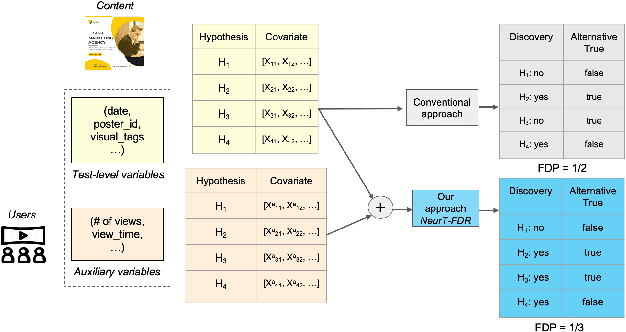
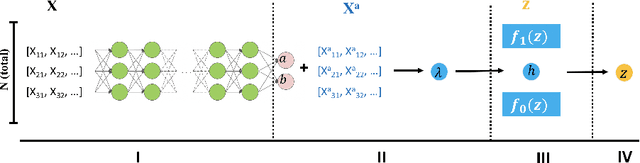
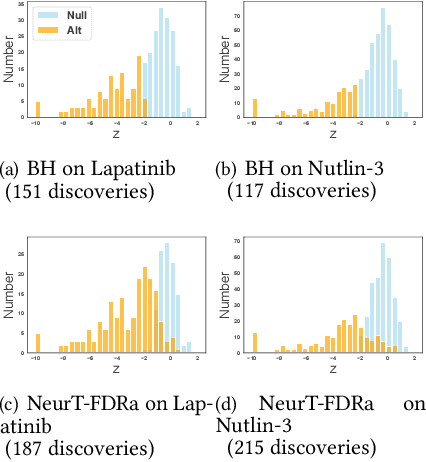
Controlling False Discovery Rate (FDR) while leveraging the side information of multiple hypothesis testing is an emerging research topic in modern data science. Existing methods rely on the test-level covariates while ignoring metrics about test-level covariates. This strategy may not be optimal for complex large-scale problems, where indirect relations often exist among test-level covariates and auxiliary metrics or covariates. We incorporate auxiliary covariates among test-level covariates in a deep Black-Box framework controlling FDR (named as NeurT-FDR) which boosts statistical power and controls FDR for multiple-hypothesis testing. Our method parametrizes the test-level covariates as a neural network and adjusts the auxiliary covariates through a regression framework, which enables flexible handling of high-dimensional features as well as efficient end-to-end optimization. We show that NeurT-FDR makes substantially more discoveries in three real datasets compared to competitive baselines.
WakeUpNet: A Mobile-Transformer based Framework for End-to-End Streaming Voice Trigger
Oct 06, 2022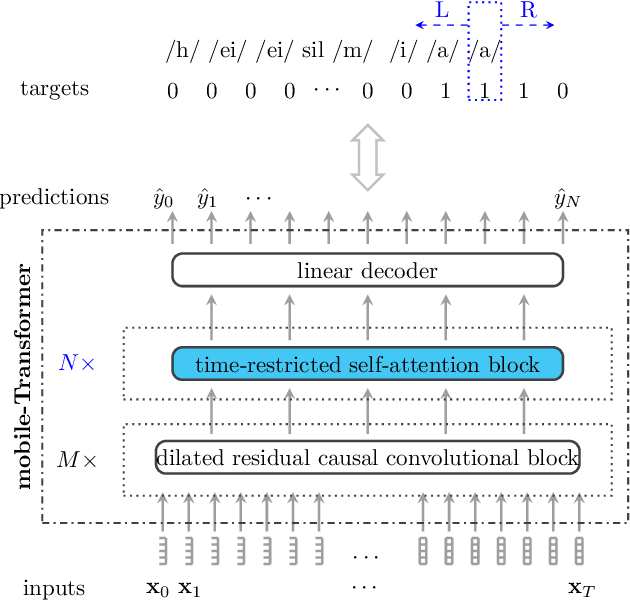
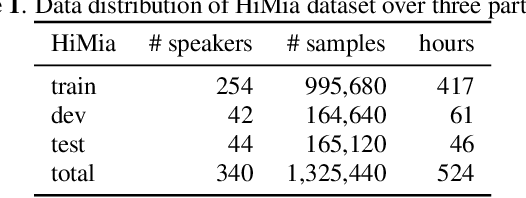
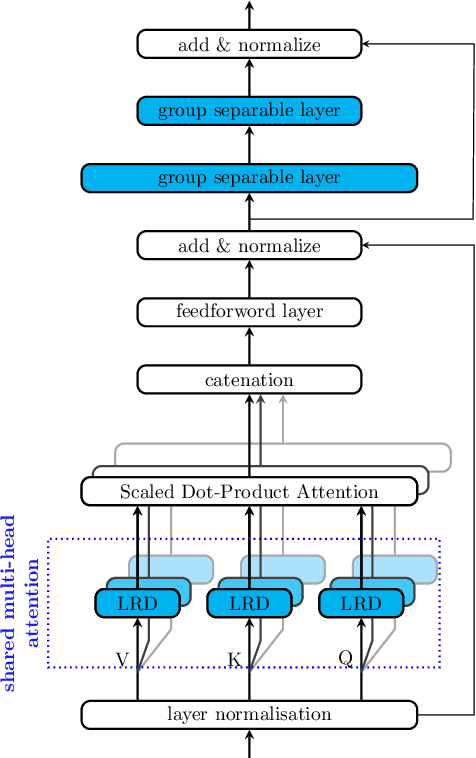
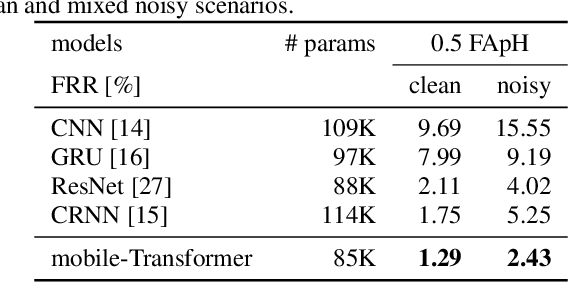
End-to-end models have gradually become the main technical stream for voice trigger, aiming to achieve an utmost prediction accuracy but with a small footprint. In present paper, we propose an end-to-end voice trigger framework, namely WakeupNet, which is basically structured on a Transformer encoder. The purpose of this framework is to explore the context-capturing capability of Transformer, as sequential information is vital for wakeup-word detection. However, the conventional Transformer encoder is too large to fit our task. To address this issue, we introduce different model compression approaches to shrink the vanilla one into a tiny one, called mobile-Transformer. To evaluate the performance of mobile-Transformer, we conduct extensive experiments on a large public-available dataset HiMia. The obtained results indicate that introduced mobile-Transformer significantly outperforms other frequently used models for voice trigger in both clean and noisy scenarios.
MIO : Mutual Information Optimization using Self-Supervised Binary Contrastive Learning
Nov 24, 2021
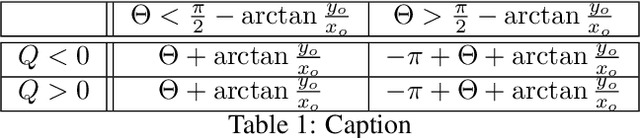
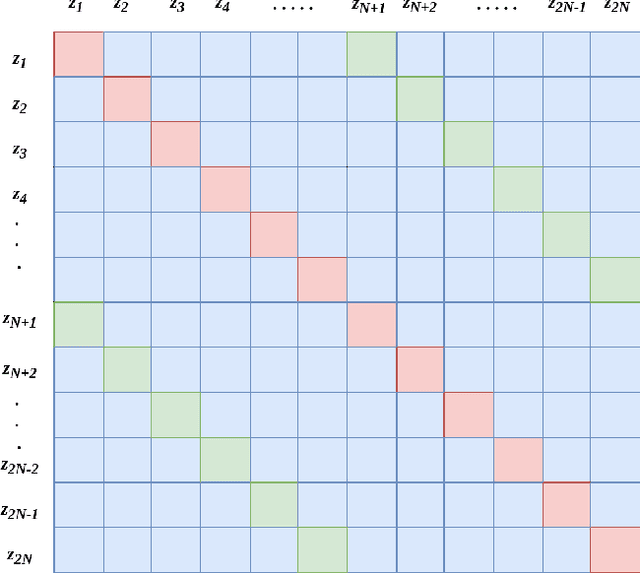
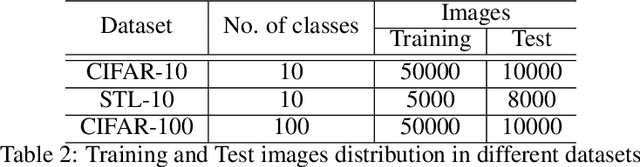
Self-supervised contrastive learning is one of the domains which has progressed rapidly over the last few years. Most of the state-of-the-art self-supervised algorithms use a large number of negative samples, momentum updates, specific architectural modifications, or extensive training to learn good representations. Such arrangements make the overall training process complex and challenging to realize analytically. In this paper, we propose a mutual information optimization based loss function for contrastive learning where we model contrastive learning into a binary classification problem to predict if a pair is positive or not. This formulation not only helps us to track the problem mathematically but also helps us to outperform existing algorithms. Unlike the existing methods that only maximize the mutual information in a positive pair, the proposed loss function optimizes the mutual information in both positive and negative pairs. We also present a mathematical expression for the parameter gradients flowing into the projector and the displacement of the feature vectors in the feature space. This helps us to get a mathematical insight into the working principle of contrastive learning. An additive $L_2$ regularizer is also used to prevent diverging of the feature vectors and to improve performance. The proposed method outperforms the state-of-the-art algorithms on benchmark datasets like STL-10, CIFAR-10, CIFAR-100. After only 250 epochs of pre-training, the proposed model achieves the best accuracy of 85.44\%, 60.75\%, 56.81\% on CIFAR-10, STL-10, CIFAR-100 datasets, respectively.
Multi-grained Label Refinement Network with Dependency Structures for Joint Intent Detection and Slot Filling
Sep 09, 2022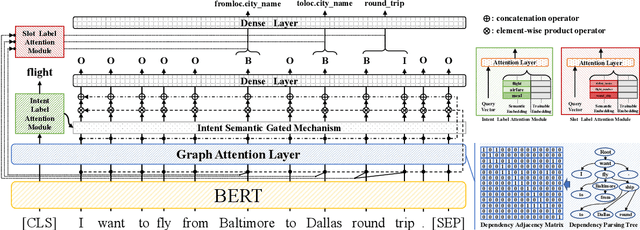

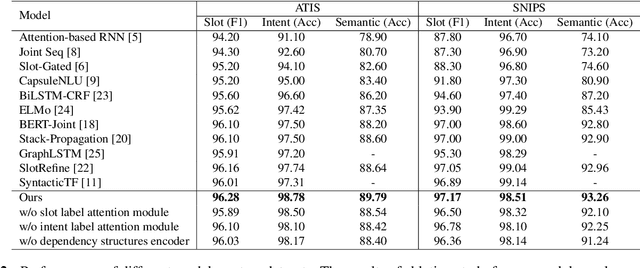
Slot filling and intent detection are two fundamental tasks in the field of natural language understanding. Due to the strong correlation between these two tasks, previous studies make efforts on modeling them with multi-task learning or designing feature interaction modules to improve the performance of each task. However, none of the existing approaches consider the relevance between the structural information of sentences and the label semantics of two tasks. The intent and semantic components of a utterance are dependent on the syntactic elements of a sentence. In this paper, we investigate a multi-grained label refinement network, which utilizes dependency structures and label semantic embeddings. Considering to enhance syntactic representations, we introduce the dependency structures of sentences into our model by graph attention layer. To capture the semantic dependency between the syntactic information and task labels, we combine the task specific features with corresponding label embeddings by attention mechanism. The experimental results demonstrate that our model achieves the competitive performance on two public datasets.
Partial sequence labeling with structured Gaussian Processes
Sep 20, 2022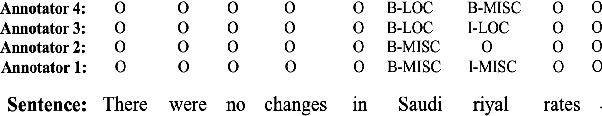

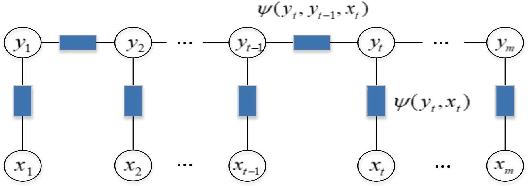
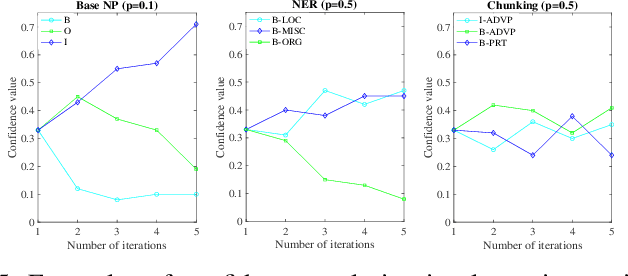
Existing partial sequence labeling models mainly focus on max-margin framework which fails to provide an uncertainty estimation of the prediction. Further, the unique ground truth disambiguation strategy employed by these models may include wrong label information for parameter learning. In this paper, we propose structured Gaussian Processes for partial sequence labeling (SGPPSL), which encodes uncertainty in the prediction and does not need extra effort for model selection and hyperparameter learning. The model employs factor-as-piece approximation that divides the linear-chain graph structure into the set of pieces, which preserves the basic Markov Random Field structure and effectively avoids handling large number of candidate output sequences generated by partially annotated data. Then confidence measure is introduced in the model to address different contributions of candidate labels, which enables the ground-truth label information to be utilized in parameter learning. Based on the derived lower bound of the variational lower bound of the proposed model, variational parameters and confidence measures are estimated in the framework of alternating optimization. Moreover, weighted Viterbi algorithm is proposed to incorporate confidence measure to sequence prediction, which considers label ambiguity arose from multiple annotations in the training data and thus helps improve the performance. SGPPSL is evaluated on several sequence labeling tasks and the experimental results show the effectiveness of the proposed model.
Prototypical Model with Novel Information-theoretic Loss Function for Generalized Zero Shot Learning
Dec 06, 2021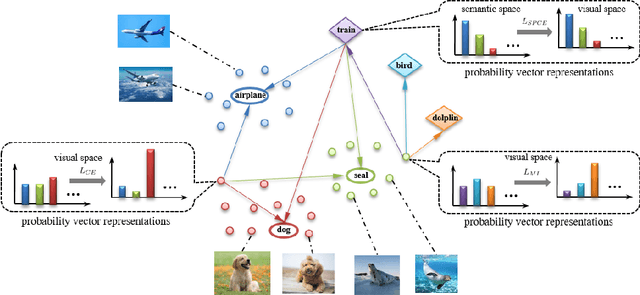
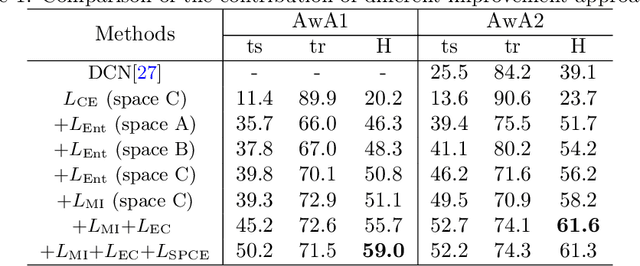
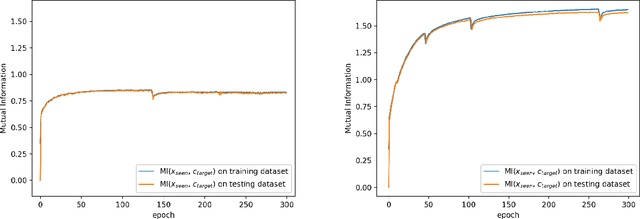
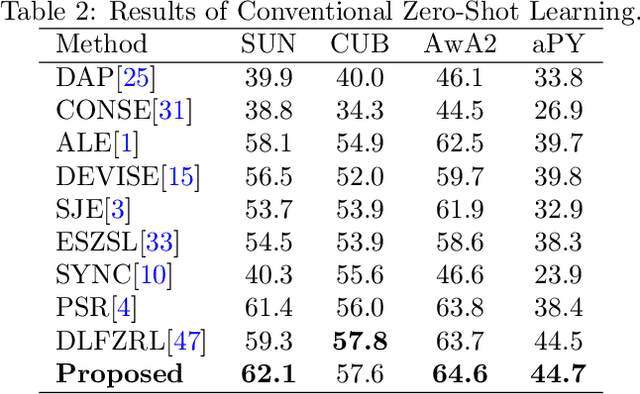
Generalized zero shot learning (GZSL) is still a technical challenge of deep learning as it has to recognize both source and target classes without data from target classes. To preserve the semantic relation between source and target classes when only trained with data from source classes, we address the quantification of the knowledge transfer and semantic relation from an information-theoretic viewpoint. To this end, we follow the prototypical model and format the variables of concern as a probability vector. Leveraging on the proposed probability vector representation, the information measurement such as mutual information and entropy, can be effectively evaluated with simple closed forms. We discuss the choice of common embedding space and distance function when using the prototypical model. Then We propose three information-theoretic loss functions for deterministic GZSL model: a mutual information loss to bridge seen data and target classes; an uncertainty-aware entropy constraint loss to prevent overfitting when using seen data to learn the embedding of target classes; a semantic preserving cross entropy loss to preserve the semantic relation when mapping the semantic representations to the common space. Simulation shows that, as a deterministic model, our proposed method obtains state of the art results on GZSL benchmark datasets. We achieve 21%-64% improvements over the baseline model -- deep calibration network (DCN) and for the first time demonstrate a deterministic model can perform as well as generative ones. Moreover, our proposed model is compatible with generative models. Simulation studies show that by incorporating with f-CLSWGAN, we obtain comparable results compared with advanced generative models.
VIBUS: Data-efficient 3D Scene Parsing with VIewpoint Bottleneck and Uncertainty-Spectrum Modeling
Oct 20, 2022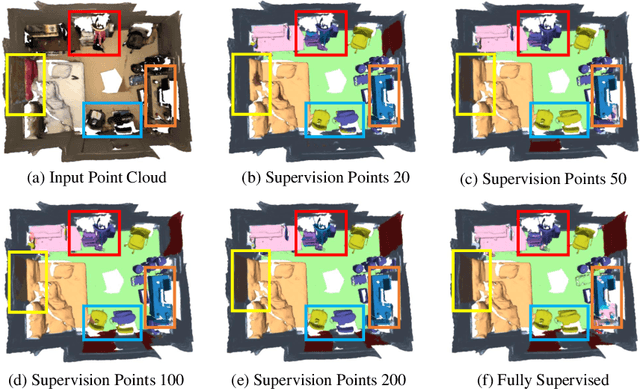
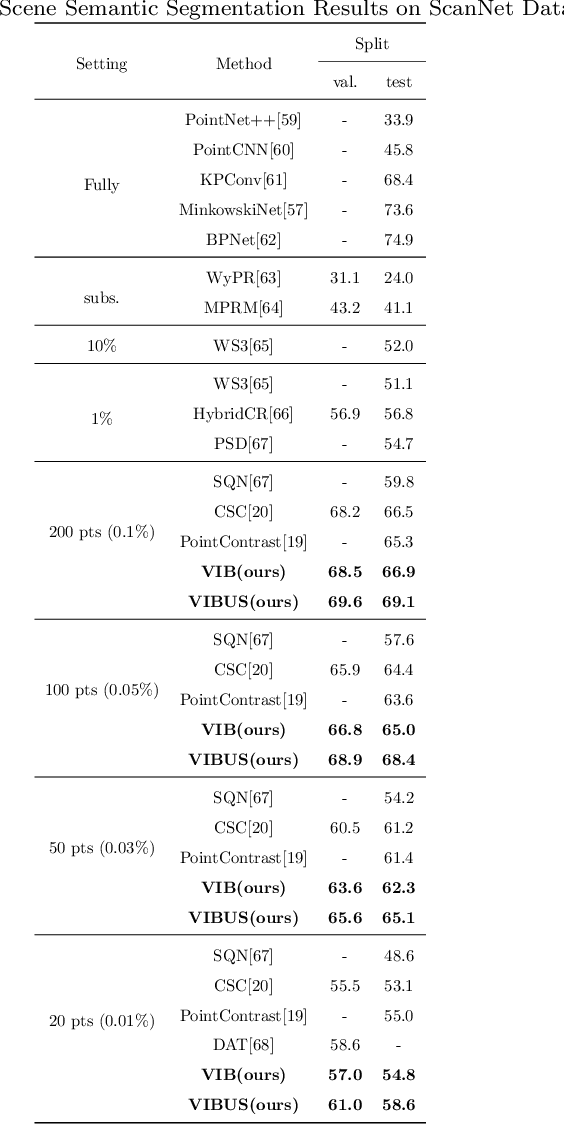
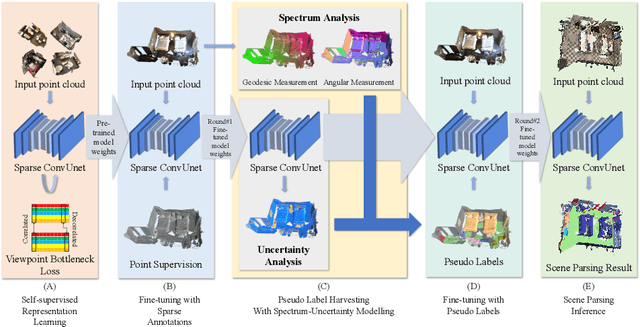
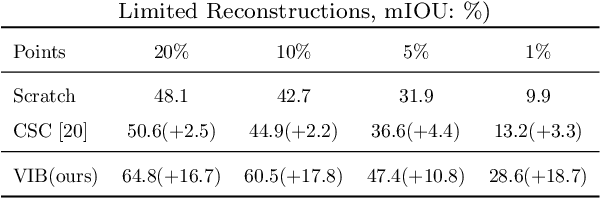
Recently, 3D scenes parsing with deep learning approaches has been a heating topic. However, current methods with fully-supervised models require manually annotated point-wise supervision which is extremely user-unfriendly and time-consuming to obtain. As such, training 3D scene parsing models with sparse supervision is an intriguing alternative. We term this task as data-efficient 3D scene parsing and propose an effective two-stage framework named VIBUS to resolve it by exploiting the enormous unlabeled points. In the first stage, we perform self-supervised representation learning on unlabeled points with the proposed Viewpoint Bottleneck loss function. The loss function is derived from an information bottleneck objective imposed on scenes under different viewpoints, making the process of representation learning free of degradation and sampling. In the second stage, pseudo labels are harvested from the sparse labels based on uncertainty-spectrum modeling. By combining data-driven uncertainty measures and 3D mesh spectrum measures (derived from normal directions and geodesic distances), a robust local affinity metric is obtained. Finite gamma/beta mixture models are used to decompose category-wise distributions of these measures, leading to automatic selection of thresholds. We evaluate VIBUS on the public benchmark ScanNet and achieve state-of-the-art results on both validation set and online test server. Ablation studies show that both Viewpoint Bottleneck and uncertainty-spectrum modeling bring significant improvements. Codes and models are publicly available at https://github.com/AIR-DISCOVER/VIBUS.
Cyclical Self-Supervision for Semi-Supervised Ejection Fraction Prediction from Echocardiogram Videos
Oct 20, 2022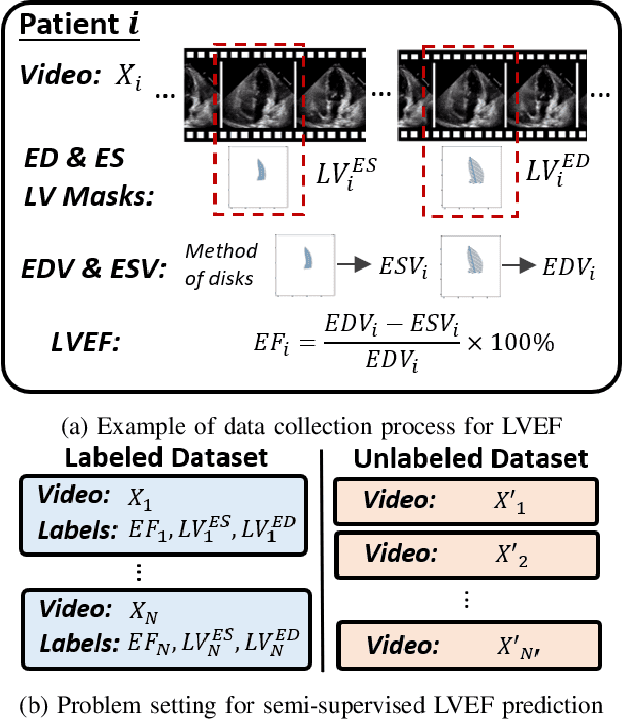
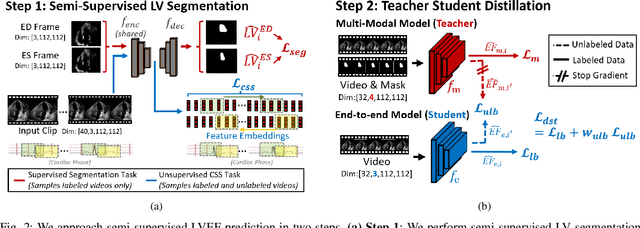
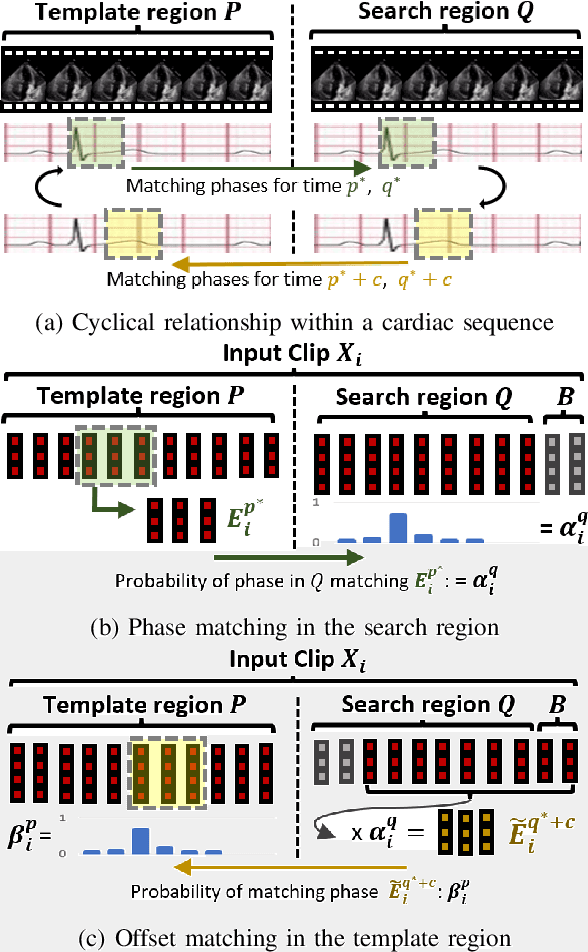
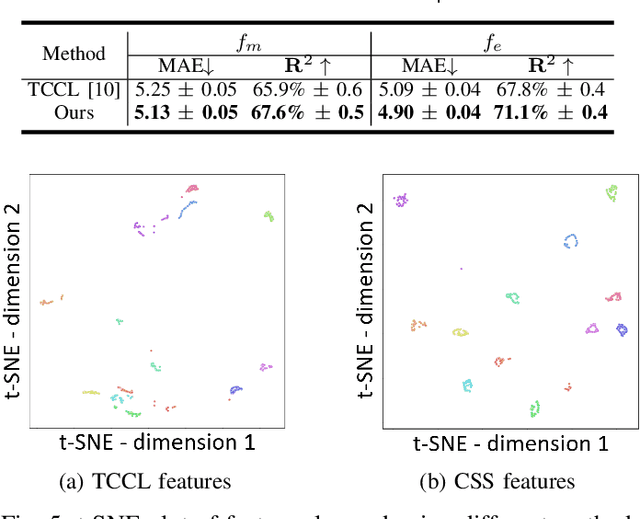
Left-ventricular ejection fraction (LVEF) is an important indicator of heart failure. Existing methods for LVEF estimation from video require large amounts of annotated data to achieve high performance, e.g. using 10,030 labeled echocardiogram videos to achieve mean absolute error (MAE) of 4.10. Labeling these videos is time-consuming however and limits potential downstream applications to other heart diseases. This paper presents the first semi-supervised approach for LVEF prediction. Unlike general video prediction tasks, LVEF prediction is specifically related to changes in the left ventricle (LV) in echocardiogram videos. By incorporating knowledge learned from predicting LV segmentations into LVEF regression, we can provide additional context to the model for better predictions. To this end, we propose a novel Cyclical Self-Supervision (CSS) method for learning video-based LV segmentation, which is motivated by the observation that the heartbeat is a cyclical process with temporal repetition. Prediction masks from our segmentation model can then be used as additional input for LVEF regression to provide spatial context for the LV region. We also introduce teacher-student distillation to distill the information from LV segmentation masks into an end-to-end LVEF regression model that only requires video inputs. Results show our method outperforms alternative semi-supervised methods and can achieve MAE of 4.17, which is competitive with state-of-the-art supervised performance, using half the number of labels. Validation on an external dataset also shows improved generalization ability from using our method.
Leveraging Language Foundation Models for Human Mobility Forecasting
Sep 14, 2022



In this paper, we propose a novel pipeline that leverages language foundation models for temporal sequential pattern mining, such as for human mobility forecasting tasks. For example, in the task of predicting Place-of-Interest (POI) customer flows, typically the number of visits is extracted from historical logs, and only the numerical data are used to predict visitor flows. In this research, we perform the forecasting task directly on the natural language input that includes all kinds of information such as numerical values and contextual semantic information. Specific prompts are introduced to transform numerical temporal sequences into sentences so that existing language models can be directly applied. We design an AuxMobLCast pipeline for predicting the number of visitors in each POI, integrating an auxiliary POI category classification task with the encoder-decoder architecture. This research provides empirical evidence of the effectiveness of the proposed AuxMobLCast pipeline to discover sequential patterns in mobility forecasting tasks. The results, evaluated on three real-world datasets, demonstrate that pre-trained language foundation models also have good performance in forecasting temporal sequences. This study could provide visionary insights and lead to new research directions for predicting human mobility.