 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fine-grained Object Categorization for Service Robots
Oct 03, 2022




A robot working in a human-centered environment is frequently confronted with fine-grained objects that must be distinguished from one another. Fine-grained visual classification (FGVC) still remains a challenging problem due to large intra-category dissimilarity and small inter-category dissimilarity. Furthermore, flaws such as the influence of illumination and information inadequacy persist in fine-grained RGB datasets. We propose a novel deep mixed multi-modality approach based on Vision Transformer (ViT) and Convolutional Neural Network (CNN) to improve the performance of FGVC. Furthermore, we generate two synthetic fine-grained RGB-D datasets consisting of 13 car objects with 720 views and 120 shoes with 7200 sample views. Finally, to assess the performance of the proposed approach, we conducted several experiments using fine-grained RGB-D datasets. Experimental results show that our method outperformed other baselines in terms of recognition accuracy, and achieved 93.40 $\%$ and 91.67 $\%$ recognition accuracy on shoe and car dataset respectively. We made the fine-grained RGB-D datasets publicly available for the benefit of research communities.
Near-Optimal Deployment Efficiency in Reward-Free Reinforcement Learning with Linear Function Approximation
Oct 03, 2022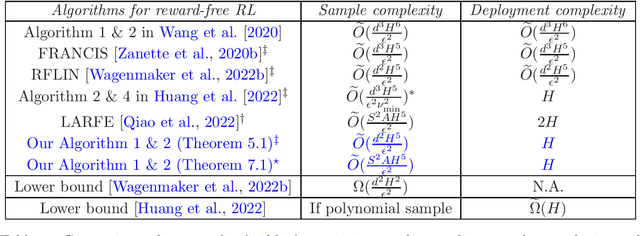

We study the problem of deployment efficient reinforcement learning (RL) with linear function approximation under the \emph{reward-free} exploration setting. This is a well-motivated problem because deploying new policies is costly in real-life RL applications. Under the linear MDP setting with feature dimension $d$ and planning horizon $H$, we propose a new algorithm that collects at most $\widetilde{O}(\frac{d^2H^5}{\epsilon^2})$ trajectories within $H$ deployments to identify $\epsilon$-optimal policy for any (possibly data-dependent) choice of reward functions. To the best of our knowledge, our approach is the first to achieve optimal deployment complexity and optimal $d$ dependence in sample complexity at the same time, even if the reward is known ahead of time. Our novel techniques include an exploration-preserving policy discretization and a generalized G-optimal experiment design, which could be of independent interest. Lastly, we analyze the related problem of regret minimization in low-adaptive RL and provide information-theoretic lower bounds for switching cost and batch complexity.
OPAL: Ontology-Aware Pretrained Language Model for End-to-End Task-Oriented Dialogue
Sep 10, 2022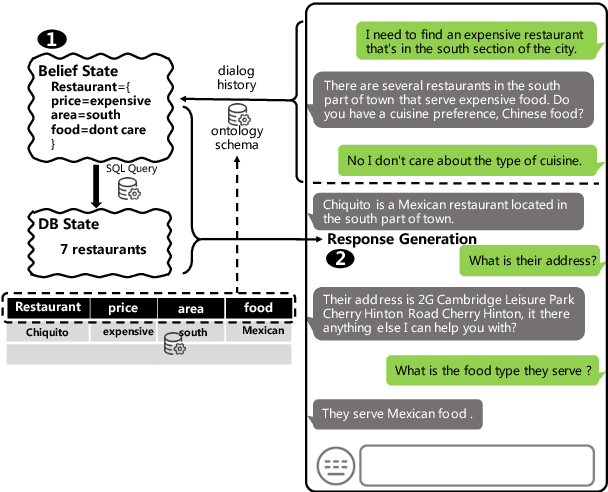

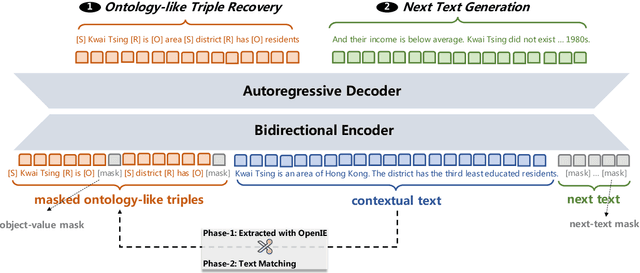
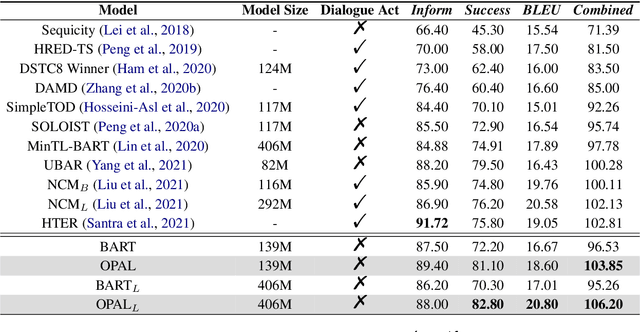
This paper presents an ontology-aware pretrained language model (OPAL) for end-to-end task-oriented dialogue (TOD). Unlike chit-chat dialogue models, task-oriented dialogue models fulfill at least two task-specific modules: dialogue state tracker (DST) and response generator (RG). The dialogue state consists of the domain-slot-value triples, which are regarded as the user's constraints to search the domain-related databases. The large-scale task-oriented dialogue data with the annotated structured dialogue state usually are inaccessible. It prevents the development of the pretrained language model for the task-oriented dialogue. We propose a simple yet effective pretraining method to alleviate this problem, which consists of two pretraining phases. The first phase is to pretrain on large-scale contextual text data, where the structured information of the text is extracted by the information extracting tool. To bridge the gap between the pretraining method and downstream tasks, we design two pretraining tasks: ontology-like triple recovery and next-text generation, which simulates the DST and RG, respectively. The second phase is to fine-tune the pretrained model on the TOD data. The experimental results show that our proposed method achieves an exciting boost and get competitive performance even without any TOD data on CamRest676 and MultiWOZ benchmarks.
Leveraging Artificial Intelligence Techniques for Smart Palm Tree Detection: A Decade Systematic Review
Sep 12, 2022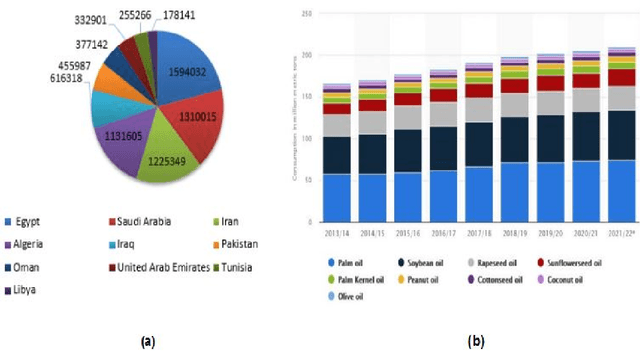
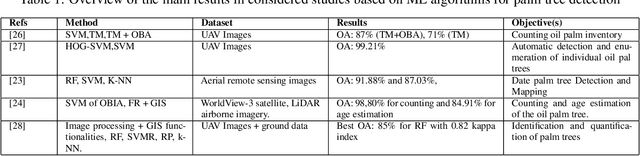
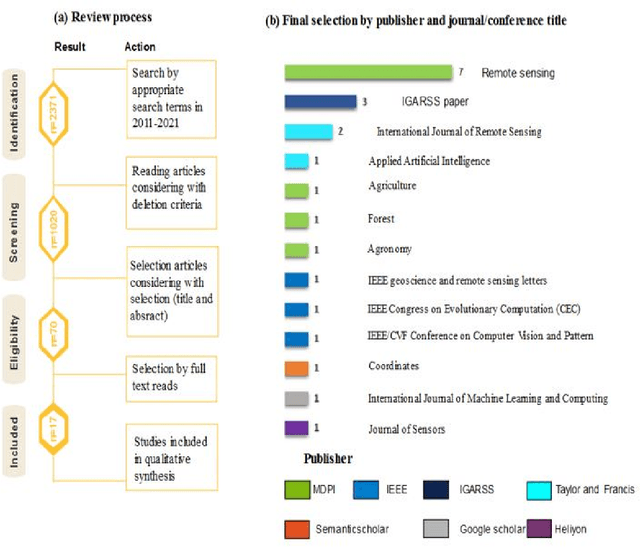
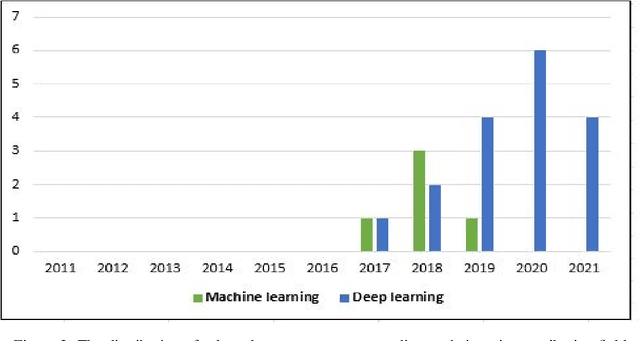
Over the past few years, total financial investment in the agricultural sector has increased substantially. Palm tree is important for many countries' economies, particularly in northern Africa and the Middle East. Monitoring in terms of detection and counting palm trees provides useful information for various stakeholders; it helps in yield estimation and examination to ensure better crop quality and prevent pests, diseases, better irrigation, and other potential threats. Despite their importance, this information is still challenging to obtain. This study systematically reviews research articles between 2011 and 2021 on artificial intelligence (AI) technology for smart palm tree detection. A systematic review (SR) was performed using the PRISMA approach based on a four-stage selection process. Twenty-two articles were included for the synthesis activity reached from the search strategy alongside the inclusion criteria in order to answer to two main research questions. The study's findings reveal patterns, relationships, networks, and trends in applying artificial intelligence in palm tree detection over the last decade. Despite the good results in most of the studies, the effective and efficient management of large-scale palm plantations is still a challenge. In addition, countries whose economies strongly related to intelligent palm services, especially in North Africa, should give more attention to this kind of study. The results of this research could benefit both the research community and stakeholders.
DecAF: Joint Decoding of Answers and Logical Forms for Question Answering over Knowledge Bases
Sep 30, 2022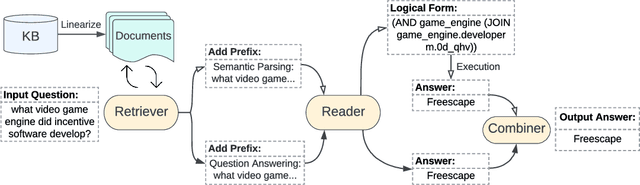
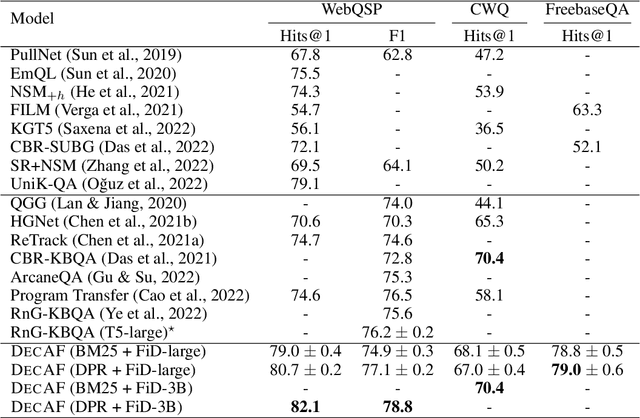
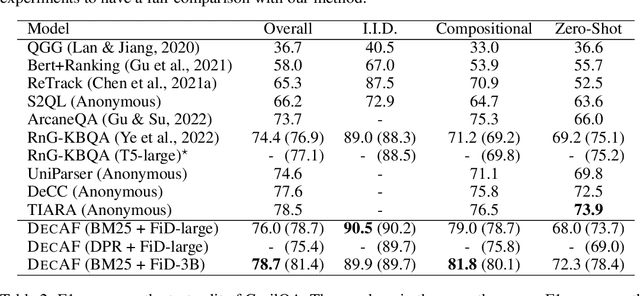
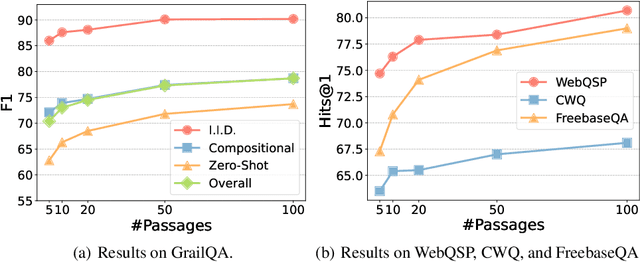
Question answering over knowledge bases (KBs) aims to answer natural language questions with factual information such as entities and relations in KBs. Previous methods either generate logical forms that can be executed over KBs to obtain final answers or predict answers directly. Empirical results show that the former often produces more accurate answers, but it suffers from non-execution issues due to potential syntactic and semantic errors in the generated logical forms. In this work, we propose a novel framework DecAF that jointly generates both logical forms and direct answers, and then combines the merits of them to get the final answers. Moreover, different from most of the previous methods, DecAF is based on simple free-text retrieval without relying on any entity linking tools -- this simplification eases its adaptation to different datasets. DecAF achieves new state-of-the-art accuracy on WebQSP, FreebaseQA, and GrailQA benchmarks, while getting competitive results on the ComplexWebQuestions benchmark.
Mixed-Reality Robot Behavior Replay: A System Implementation
Sep 30, 2022



As robots become increasingly complex, they must explain their behaviors to gain trust and acceptance. However, it may be difficult through verbal explanation alone to fully convey information about past behavior, especially regarding objects no longer present due to robots' or humans' actions. Humans often try to physically mimic past movements to accompany verbal explanations. Inspired by this human-human interaction, we describe the technical implementation of a system for past behavior replay for robots in this tool paper. Specifically, we used Behavior Trees to encode and separate robot behaviors, and schemaless MongoDB to structurally store and query the underlying sensor data and joint control messages for future replay. Our approach generalizes to different types of replays, including both manipulation and navigation replay, and visual (i.e., augmented reality (AR)) and auditory replay. Additionally, we briefly summarize a user study to further provide empirical evidence of its effectiveness and efficiency. Sample code and instructions are available on GitHub at https://github.com/umhan35/robot-behavior-replay.
* 6 pages, 5 figures, the AI-HRI Symposium at AAAI Fall Symposium Series (FSS) 2022
GM-VAE: Representation Learning with VAE on Gaussian Manifold
Sep 30, 2022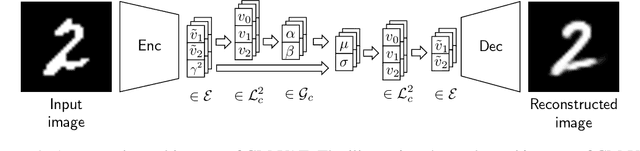

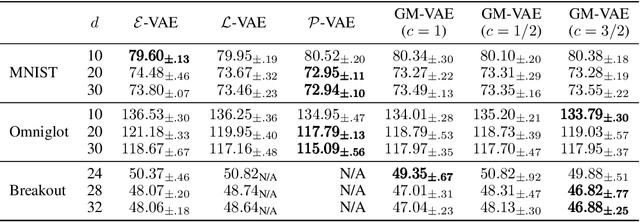
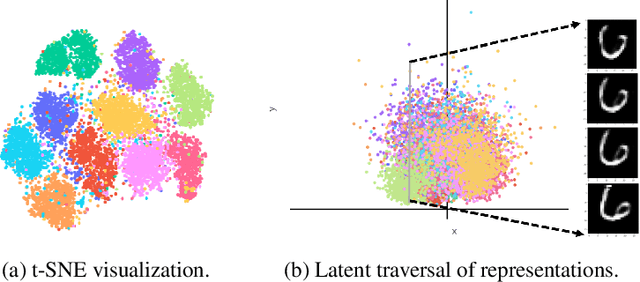
We propose a Gaussian manifold variational auto-encoder (GM-VAE) whose latent space consists of a set of diagonal Gaussian distributions. It is known that the set of the diagonal Gaussian distributions with the Fisher information metric forms a product hyperbolic space, which we call a Gaussian manifold. To learn the VAE endowed with the Gaussian manifold, we first propose a pseudo Gaussian manifold normal distribution based on the Kullback-Leibler divergence, a local approximation of the squared Fisher-Rao distance, to define a density over the latent space. With the newly proposed distribution, we introduce geometric transformations at the last and the first of the encoder and the decoder of VAE, respectively to help the transition between the Euclidean and Gaussian manifolds. Through the empirical experiments, we show competitive generalization performance of GM-VAE against other variants of hyperbolic- and Euclidean-VAEs. Our model achieves strong numerical stability, which is a common limitation reported with previous hyperbolic-VAEs.
Zero-Shot Retrieval with Search Agents and Hybrid Environments
Sep 30, 2022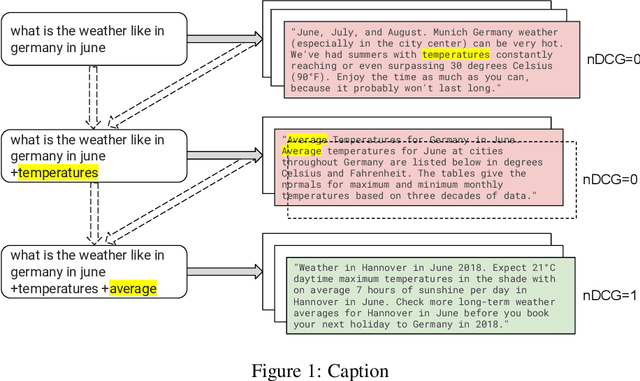
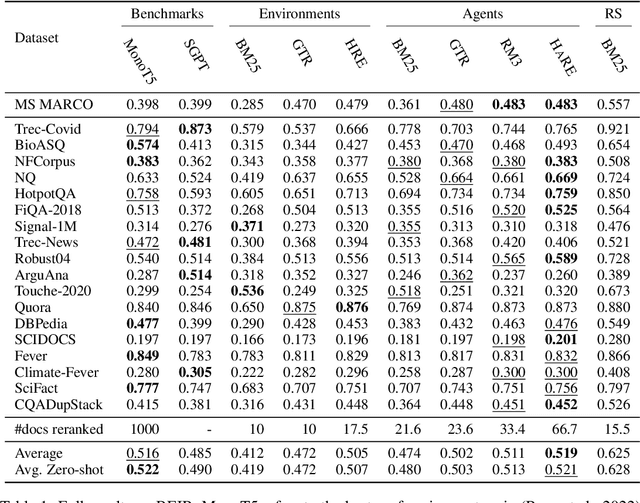
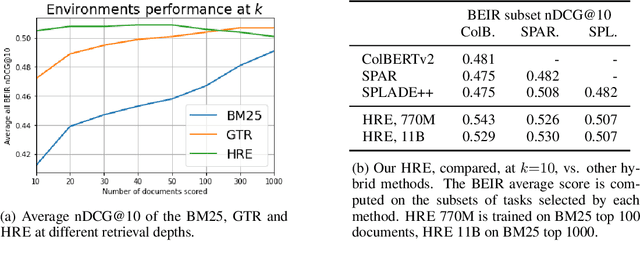
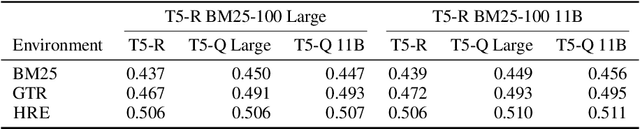
Learning to search is the task of building artificial agents that learn to autonomously use a search box to find information. So far, it has been shown that current language models can learn symbolic query reformulation policies, in combination with traditional term-based retrieval, but fall short of outperforming neural retrievers. We extend the previous learning to search setup to a hybrid environment, which accepts discrete query refinement operations, after a first-pass retrieval step performed by a dual encoder. Experiments on the BEIR task show that search agents, trained via behavioral cloning, outperform the underlying search system based on a combined dual encoder retriever and cross encoder reranker. Furthermore, we find that simple heuristic Hybrid Retrieval Environments (HRE) can improve baseline performance by several nDCG points. The search agent based on HRE (HARE) produces state-of-the-art performance on both zero-shot and in-domain evaluations. We carry out an extensive qualitative analysis to shed light on the agents policies.
Implicit Neural Spatial Representations for Time-dependent PDEs
Sep 30, 2022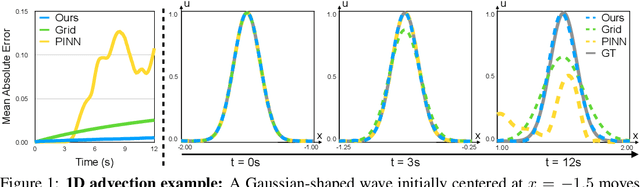

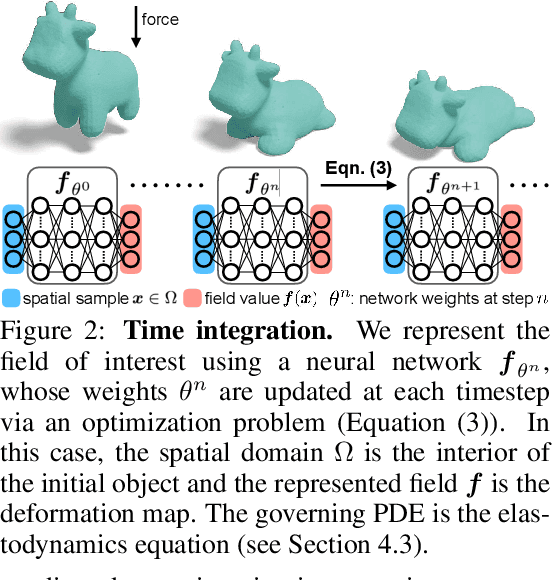

Numerically solving partial differential equations (PDEs) often entails spatial and temporal discretizations. Traditional methods (e.g., finite difference, finite element, smoothed-particle hydrodynamics) frequently adopt explicit spatial discretizations, such as grids, meshes, and point clouds, where each degree-of-freedom corresponds to a location in space. While these explicit spatial correspondences are intuitive to model and understand, these representations are not necessarily optimal for accuracy, memory-usage, or adaptivity. In this work, we explore implicit neural representation as an alternative spatial discretization, where spatial information is implicitly stored in the neural network weights. With implicit neural spatial representation, PDE-constrained time-stepping translates into updating neural network weights, which naturally integrates with commonly adopted optimization time integrators. We validate our approach on a variety of classic PDEs with examples involving large elastic deformations, turbulent fluids, and multiscale phenomena. While slower to compute than traditional representations, our approach exhibits higher accuracy, lower memory consumption, and dynamically adaptive allocation of degrees of freedom without complex remeshing.
ASTF: Visual Abstractions of Time-Varying Patterns in Radio Signals
Sep 30, 2022
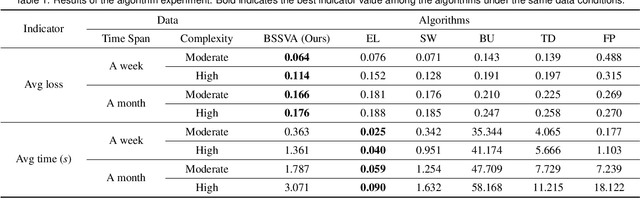
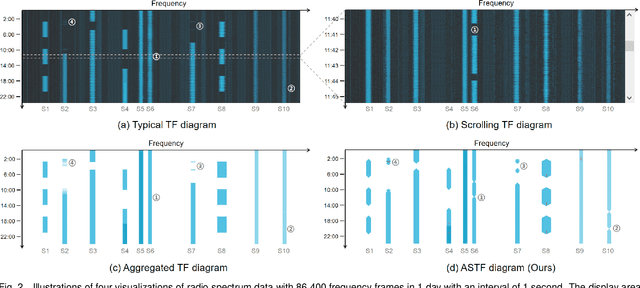
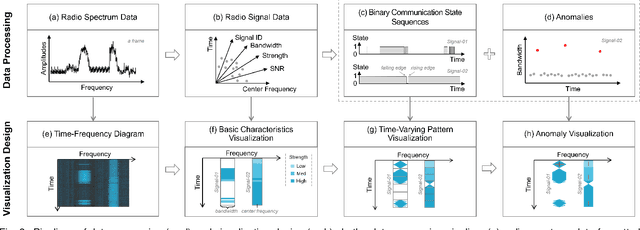
A time-frequency diagram is a commonly used visualization for observing the time-frequency distribution of radio signals and analyzing their time-varying patterns of communication states in radio monitoring and management. While it excels when performing short-term signal analyses, it becomes inadaptable for long-term signal analyses because it cannot adequately depict signal time-varying patterns in a large time span on a space-limited screen. This research thus presents an abstract signal time-frequency (ASTF) diagram to address this problem. In the diagram design, a visual abstraction method is proposed to visually encode signal communication state changes in time slices. A time segmentation algorithm is proposed to divide a large time span into time slices.Three new quantified metrics and a loss function are defined to ensure the preservation of important time-varying information in the time segmentation. An algorithm performance experiment and a user study are conducted to evaluate the effectiveness of the diagram for long-term signal analyses.