 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On the Evaluation of the Plausibility and Faithfulness of Sentiment Analysis Explanations
Oct 13, 2022
Current Explainable AI (ExAI) methods, especially in the NLP field, are conducted on various datasets by employing different metrics to evaluate several aspects. The lack of a common evaluation framework is hindering the progress tracking of such methods and their wider adoption. In this work, inspired by offline information retrieval, we propose different metrics and techniques to evaluate the explainability of SA models from two angles. First, we evaluate the strength of the extracted "rationales" in faithfully explaining the predicted outcome. Second, we measure the agreement between ExAI methods and human judgment on a homegrown dataset1 to reflect on the rationales plausibility. Our conducted experiments comprise four dimensions: (1) the underlying architectures of SA models, (2) the approach followed by the ExAI method, (3) the reasoning difficulty, and (4) the homogeneity of the ground-truth rationales. We empirically demonstrate that anchors explanations are more aligned with the human judgment and can be more confident in extracting supporting rationales. As can be foreseen, the reasoning complexity of sentiment is shown to thwart ExAI methods from extracting supporting evidence. Moreover, a remarkable discrepancy is discerned between the results of different explainability methods on the various architectures suggesting the need for consolidation to observe enhanced performance. Predominantly, transformers are shown to exhibit better explainability than convolutional and recurrent architectures. Our work paves the way towards designing more interpretable NLP models and enabling a common evaluation ground for their relative strengths and robustness.
* 13 pages, 3 figures, conference (AIAI - springer)
Visual Classification via Description from Large Language Models
Oct 13, 2022
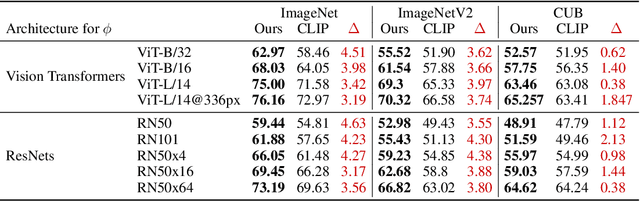
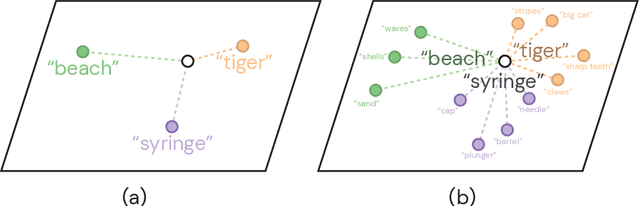

Vision-language models (VLMs) such as CLIP have shown promising performance on a variety of recognition tasks using the standard zero-shot classification procedure -- computing similarity between the query image and the embedded words for each category. By only using the category name, they neglect to make use of the rich context of additional information that language affords. The procedure gives no intermediate understanding of why a category is chosen, and furthermore provides no mechanism for adjusting the criteria used towards this decision. We present an alternative framework for classification with VLMs, which we call classification by description. We ask VLMs to check for descriptive features rather than broad categories: to find a tiger, look for its stripes; its claws; and more. By basing decisions on these descriptors, we can provide additional cues that encourage using the features we want to be used. In the process, we can get a clear idea of what features the model uses to construct its decision; it gains some level of inherent explainability. We query large language models (e.g., GPT-3) for these descriptors to obtain them in a scalable way. Extensive experiments show our framework has numerous advantages past interpretability. We show improvements in accuracy on ImageNet across distribution shifts; demonstrate the ability to adapt VLMs to recognize concepts unseen during training; and illustrate how descriptors can be edited to effectively mitigate bias compared to the baseline.
MechRetro is a chemical-mechanism-driven graph learning framework for interpretable retrosynthesis prediction and pathway planning
Oct 06, 2022
Leveraging artificial intelligence for automatic retrosynthesis speeds up organic pathway planning in digital laboratories. However, existing deep learning approaches are unexplainable, like "black box" with few insights, notably limiting their applications in real retrosynthesis scenarios. Here, we propose MechRetro, a chemical-mechanism-driven graph learning framework for interpretable retrosynthetic prediction and pathway planning, which learns several retrosynthetic actions to simulate a reverse reaction via elaborate self-adaptive joint learning. By integrating chemical knowledge as prior information, we design a novel Graph Transformer architecture to adaptively learn discriminative and chemically meaningful molecule representations, highlighting the strong capacity in molecule feature representation learning. We demonstrate that MechRetro outperforms the state-of-the-art approaches for retrosynthetic prediction with a large margin on large-scale benchmark datasets. Extending MechRetro to the multi-step retrosynthesis analysis, we identify efficient synthetic routes via an interpretable reasoning mechanism, leading to a better understanding in the realm of knowledgeable synthetic chemists. We also showcase that MechRetro discovers a novel pathway for protokylol, along with energy scores for uncertainty assessment, broadening the applicability for practical scenarios. Overall, we expect MechRetro to provide meaningful insights for high-throughput automated organic synthesis in drug discovery.
COMPS: Conceptual Minimal Pair Sentences for testing Property Knowledge and Inheritance in Pre-trained Language Models
Oct 06, 2022
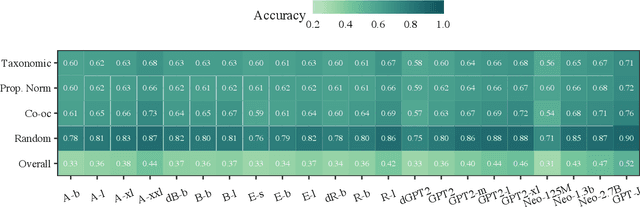
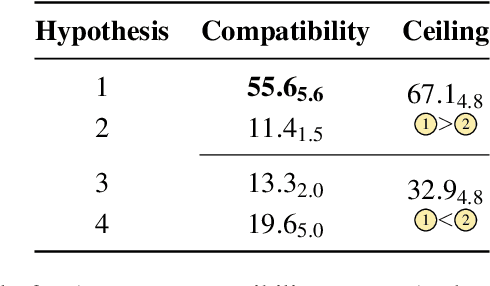

A characteristic feature of human semantic memory is its ability to not only store and retrieve the properties of concepts observed through experience, but to also facilitate the inheritance of properties (can breathe) from superordinate concepts (animal) to their subordinates (dog) -- i.e. demonstrate property inheritance. In this paper, we present COMPS, a collection of minimal pair sentences that jointly tests pre-trained language models (PLMs) on their ability to attribute properties to concepts and their ability to demonstrate property inheritance behavior. Analyses of 22 different PLMs on COMPS reveal that they can easily distinguish between concepts on the basis of a property when they are trivially different, but find it relatively difficult when concepts are related on the basis of nuanced knowledge representations. Furthermore, we find that PLMs can demonstrate behavior consistent with property inheritance to a great extent, but fail in the presence of distracting information, which decreases the performance of many models, sometimes even below chance. This lack of robustness in demonstrating simple reasoning raises important questions about PLMs' capacity to make correct inferences even when they appear to possess the prerequisite knowledge.
Small Character Models Match Large Word Models for Autocomplete Under Memory Constraints
Oct 06, 2022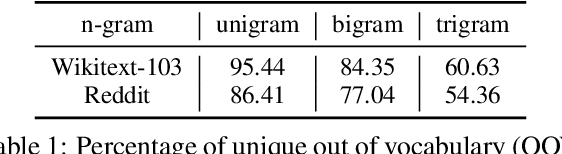
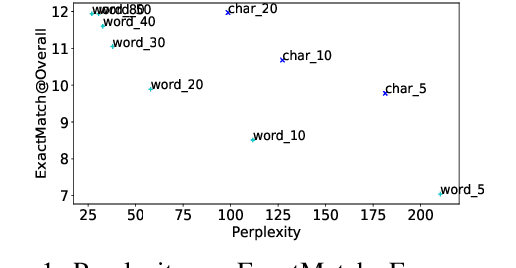
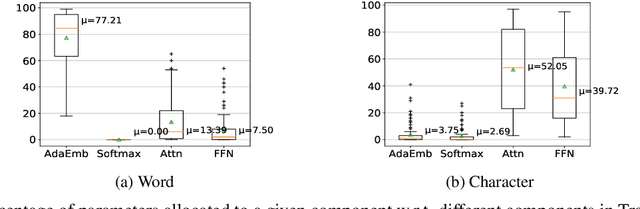
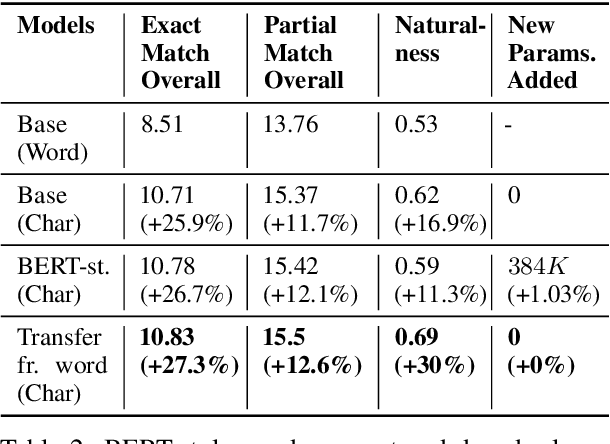
Autocomplete is a task where the user inputs a piece of text, termed prompt, which is conditioned by the model to generate semantically coherent continuation. Existing works for this task have primarily focused on datasets (e.g., email, chat) with high frequency user prompt patterns (or focused prompts) where word-based language models have been quite effective. In this work, we study the more challenging setting consisting of low frequency user prompt patterns (or broad prompts, e.g., prompt about 93rd academy awards) and demonstrate the effectiveness of character-based language models. We study this problem under memory-constrained settings (e.g., edge devices and smartphones), where character-based representation is effective in reducing the overall model size (in terms of parameters). We use WikiText-103 benchmark to simulate broad prompts and demonstrate that character models rival word models in exact match accuracy for the autocomplete task, when controlled for the model size. For instance, we show that a 20M parameter character model performs similar to an 80M parameter word model in the vanilla setting. We further propose novel methods to improve character models by incorporating inductive bias in the form of compositional information and representation transfer from large word models.
Audio-Visual Face Reenactment
Oct 06, 2022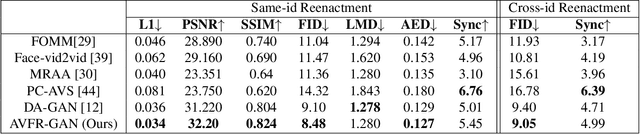
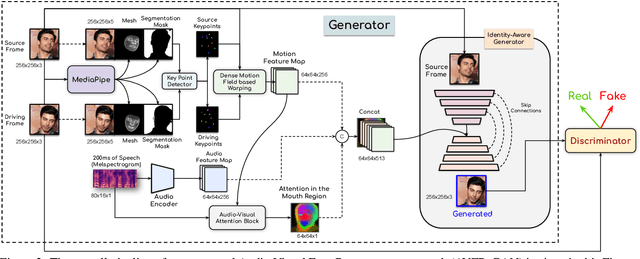
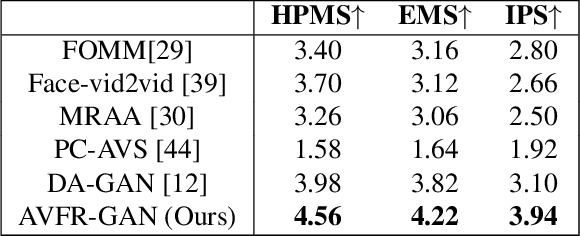

This work proposes a novel method to generate realistic talking head videos using audio and visual streams. We animate a source image by transferring head motion from a driving video using a dense motion field generated using learnable keypoints. We improve the quality of lip sync using audio as an additional input, helping the network to attend to the mouth region. We use additional priors using face segmentation and face mesh to improve the structure of the reconstructed faces. Finally, we improve the visual quality of the generations by incorporating a carefully designed identity-aware generator module. The identity-aware generator takes the source image and the warped motion features as input to generate a high-quality output with fine-grained details. Our method produces state-of-the-art results and generalizes well to unseen faces, languages, and voices. We comprehensively evaluate our approach using multiple metrics and outperforming the current techniques both qualitative and quantitatively. Our work opens up several applications, including enabling low bandwidth video calls. We release a demo video and additional information at http://cvit.iiit.ac.in/research/projects/cvit-projects/avfr.
Q-LSTM Language Model -- Decentralized Quantum Multilingual Pre-Trained Language Model for Privacy Protection
Oct 06, 2022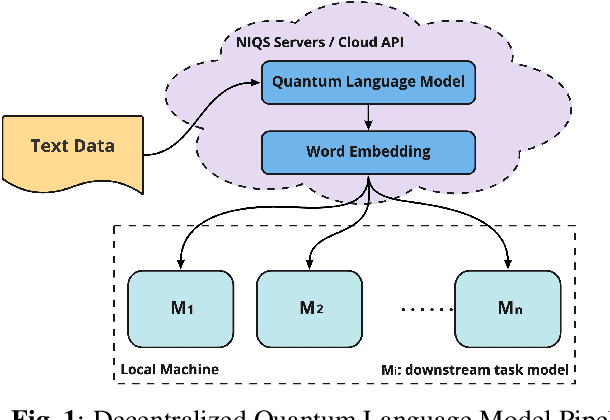

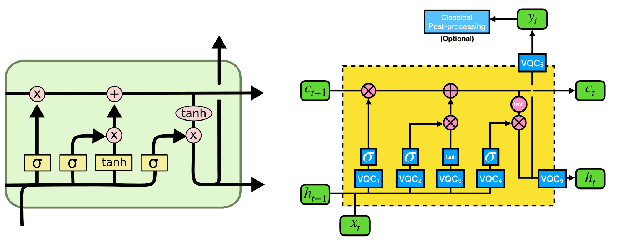
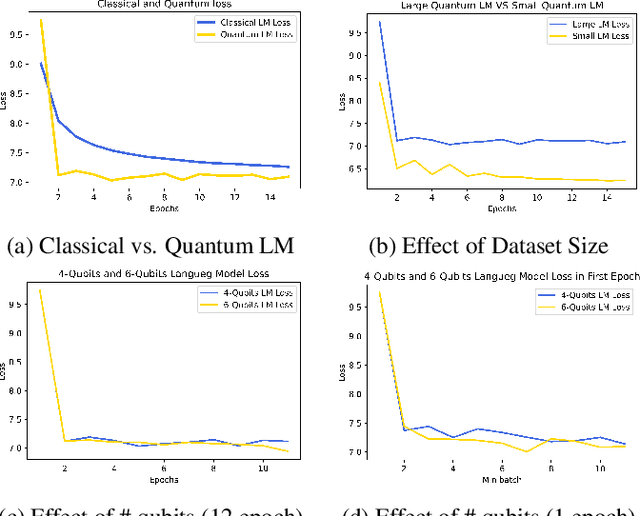
Large-scale language models are trained on a massive amount of natural language data that might encode or reflect our private information. With careful manipulation, malicious agents can reverse engineer the training data even if data sanitation and differential privacy algorithms were involved in the pre-training process. In this work, we propose a decentralized training framework to address privacy concerns in training large-scale language models. The framework consists of a cloud quantum language model built with Variational Quantum Classifiers (VQC) for sentence embedding and a local Long-Short Term Memory (LSTM) model. We use both intrinsic evaluation (loss, perplexity) and extrinsic evaluation (downstream sentiment analysis task) to evaluate the performance of our quantum language model. Our quantum model was comparable to its classical counterpart on all the above metrics. We also perform ablation studies to look into the effect of the size of VQC and the size of training data on the performance of the model. Our approach solves privacy concerns without sacrificing downstream task performance. The intractability of quantum operations on classical hardware ensures the confidentiality of the training data and makes it impossible to be recovered by any adversary.
GNSS/MEMS-INS Integration for Drone Navigation using EKF on Lie Groups
Oct 06, 2022
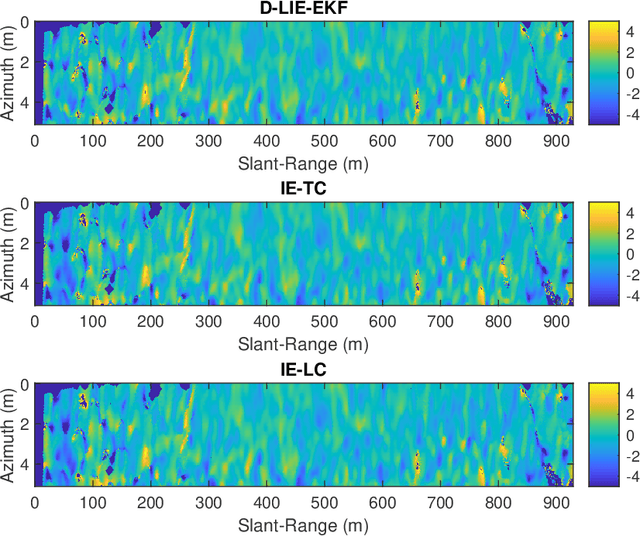
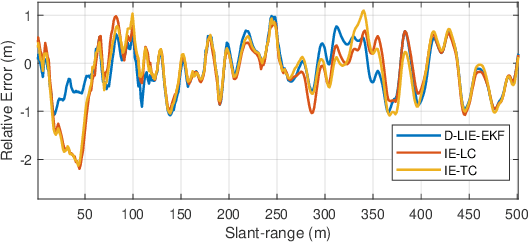
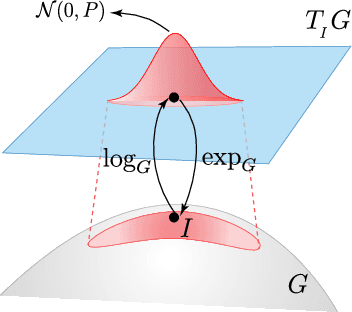
Building upon the theory of Kalman Filtering on Lie Groups, this paper describes an Extended Kalman Filter and Smoother for Loosely Coupled Integration of GNSS/INS tailored for post-processing applications. The approach employs a dynamic model on a matrix Lie Group that aggregates position, velocity, attitude, and the IMU biases as a single element of a Lie group. The development was motivated by a drone-borne Differential Interferometric SAR (DinSAR) application, which requires high-precision navigation information for short-flight missions using low-cost MEMS sensors. The filter and the Rauch-Tung-Striebel (RTS) smoother are both implemented and validated. The paper also presents a novel algorithm to initialize the heading value as an alternative to gyro-compassing or magnetometer-based alignments. The Mahalanobis Distance and the $\chi^2$-test are employed during the filter update step to address the practical issue of outlier rejection for the GNSS measurements. The paper uses synthetic data to compare classic navigation schemes based on multiplicative quaternions and Euler angles. Finally, real data experiments demonstrate that the Kalman Filter based on Lie Groups performs better DinSAR processing than state-of-the-art commercial software.
CIR-Net: Cross-modality Interaction and Refinement for RGB-D Salient Object Detection
Oct 06, 2022


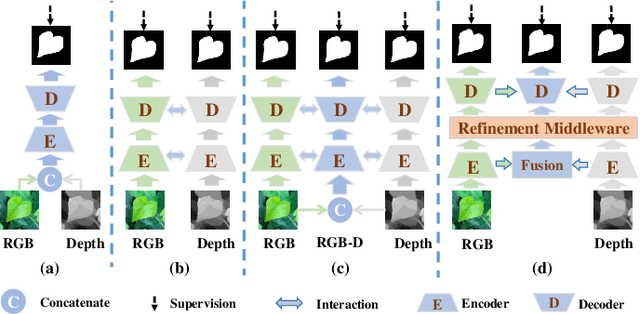
Focusing on the issue of how to effectively capture and utilize cross-modality information in RGB-D salient object detection (SOD) task, we present a convolutional neural network (CNN) model, named CIR-Net, based on the novel cross-modality interaction and refinement. For the cross-modality interaction, 1) a progressive attention guided integration unit is proposed to sufficiently integrate RGB-D feature representations in the encoder stage, and 2) a convergence aggregation structure is proposed, which flows the RGB and depth decoding features into the corresponding RGB-D decoding streams via an importance gated fusion unit in the decoder stage. For the cross-modality refinement, we insert a refinement middleware structure between the encoder and the decoder, in which the RGB, depth, and RGB-D encoder features are further refined by successively using a self-modality attention refinement unit and a cross-modality weighting refinement unit. At last, with the gradually refined features, we predict the saliency map in the decoder stage. Extensive experiments on six popular RGB-D SOD benchmarks demonstrate that our network outperforms the state-of-the-art saliency detectors both qualitatively and quantitatively.
De-biased Representation Learning for Fairness with Unreliable Labels
Aug 01, 2022
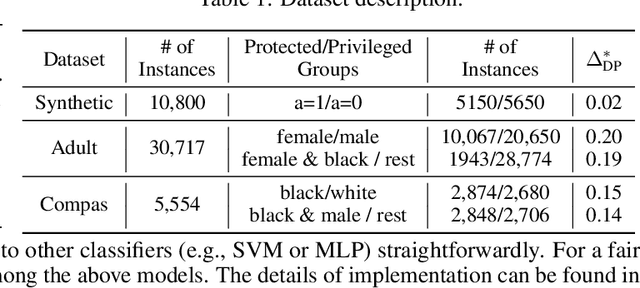
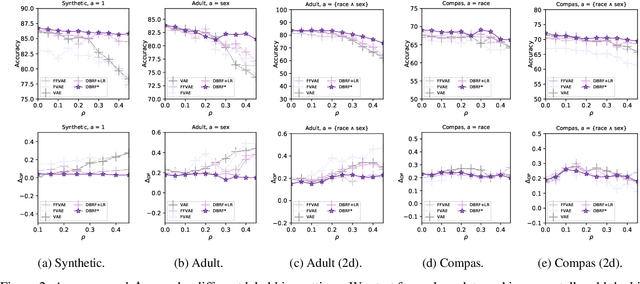
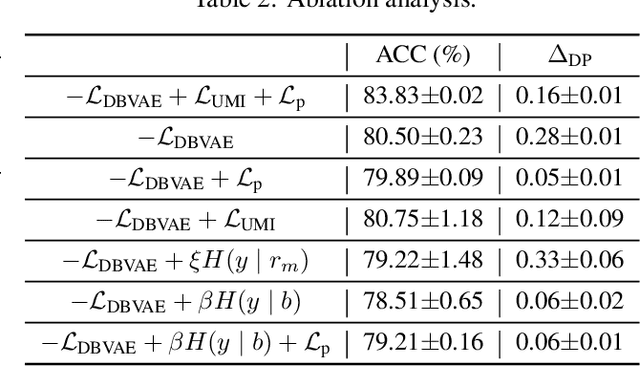
Removing bias while keeping all task-relevant information is challenging for fair representation learning methods since they would yield random or degenerate representations w.r.t. labels when the sensitive attributes correlate with labels. Existing works proposed to inject the label information into the learning procedure to overcome such issues. However, the assumption that the observed labels are clean is not always met. In fact, label bias is acknowledged as the primary source inducing discrimination. In other words, the fair pre-processing methods ignore the discrimination encoded in the labels either during the learning procedure or the evaluation stage. This contradiction puts a question mark on the fairness of the learned representations. To circumvent this issue, we explore the following question: \emph{Can we learn fair representations predictable to latent ideal fair labels given only access to unreliable labels?} In this work, we propose a \textbf{D}e-\textbf{B}iased \textbf{R}epresentation Learning for \textbf{F}airness (DBRF) framework which disentangles the sensitive information from non-sensitive attributes whilst keeping the learned representations predictable to ideal fair labels rather than observed biased ones. We formulate the de-biased learning framework through information-theoretic concepts such as mutual information and information bottleneck. The core concept is that DBRF advocates not to use unreliable labels for supervision when sensitive information benefits the prediction of unreliable labels. Experiment results over both synthetic and real-world data demonstrate that DBRF effectively learns de-biased representations towards ideal labels.