 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Comparing informativeness of an NLG chatbot vs graphical app in diet-information domain
Jun 23, 2022
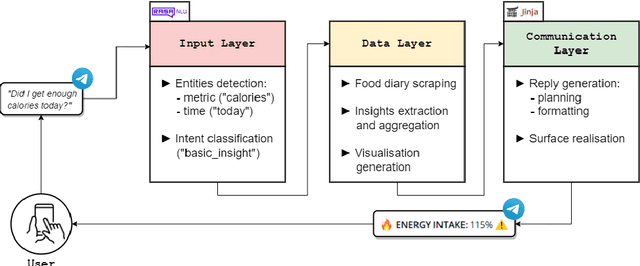
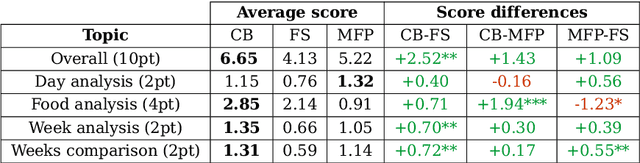
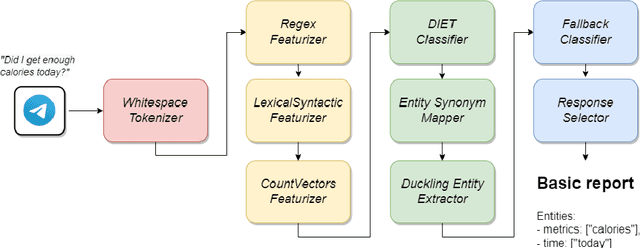
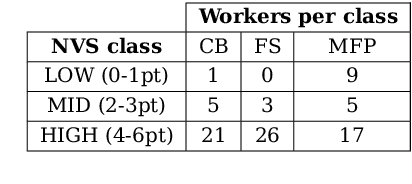
Visual representation of data like charts and tables can be challenging to understand for readers. Previous work showed that combining visualisations with text can improve the communication of insights in static contexts, but little is known about interactive ones. In this work we present an NLG chatbot that processes natural language queries and provides insights through a combination of charts and text. We apply it to nutrition, a domain communication quality is critical. Through crowd-sourced evaluation we compare the informativeness of our chatbot against traditional, static diet-apps. We find that the conversational context significantly improved users' understanding of dietary data in various tasks, and that users considered the chatbot as more useful and quick to use than traditional apps.
Fine-Grained Zero-Shot Learning with DNA as Side Information
Sep 29, 2021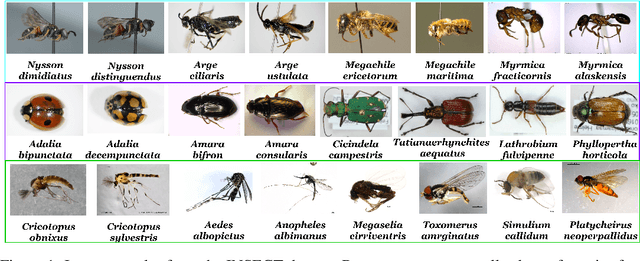
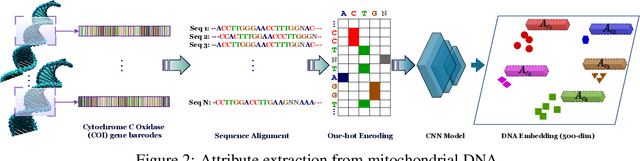
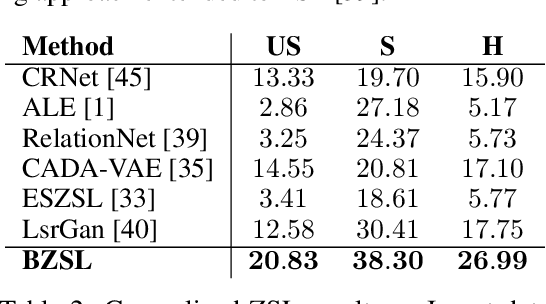
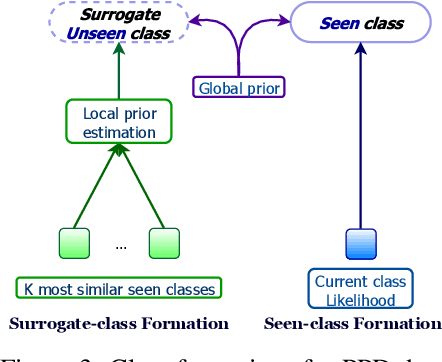
Fine-grained zero-shot learning task requires some form of side-information to transfer discriminative information from seen to unseen classes. As manually annotated visual attributes are extremely costly and often impractical to obtain for a large number of classes, in this study we use DNA as side information for the first time for fine-grained zero-shot classification of species. Mitochondrial DNA plays an important role as a genetic marker in evolutionary biology and has been used to achieve near-perfect accuracy in the species classification of living organisms. We implement a simple hierarchical Bayesian model that uses DNA information to establish the hierarchy in the image space and employs local priors to define surrogate classes for unseen ones. On the benchmark CUB dataset, we show that DNA can be equally promising yet in general a more accessible alternative than word vectors as a side information. This is especially important as obtaining robust word representations for fine-grained species names is not a practicable goal when information about these species in free-form text is limited. On a newly compiled fine-grained insect dataset that uses DNA information from over a thousand species, we show that the Bayesian approach outperforms state-of-the-art by a wide margin.
Gradient Gating for Deep Multi-Rate Learning on Graphs
Oct 02, 2022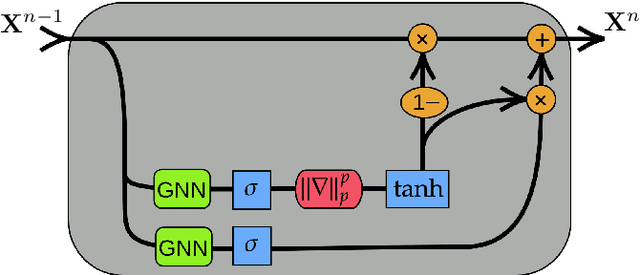
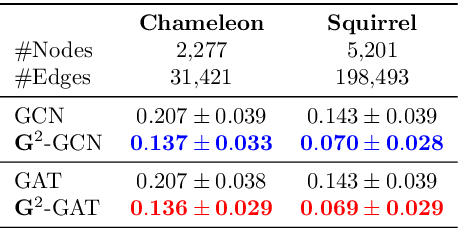
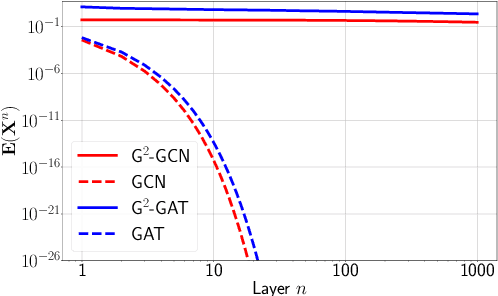
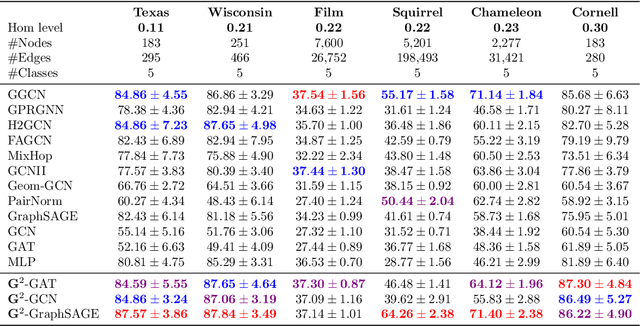
We present Gradient Gating (G$^2$), a novel framework for improving the performance of Graph Neural Networks (GNNs). Our framework is based on gating the output of GNN layers with a mechanism for multi-rate flow of message passing information across nodes of the underlying graph. Local gradients are harnessed to further modulate message passing updates. Our framework flexibly allows one to use any basic GNN layer as a wrapper around which the multi-rate gradient gating mechanism is built. We rigorously prove that G$^2$ alleviates the oversmoothing problem and allows the design of deep GNNs. Empirical results are presented to demonstrate that the proposed framework achieves state-of-the-art performance on a variety of graph learning tasks, including on large-scale heterophilic graphs.
PanorAMS: Automatic Annotation for Detecting Objects in Urban Context
Aug 31, 2022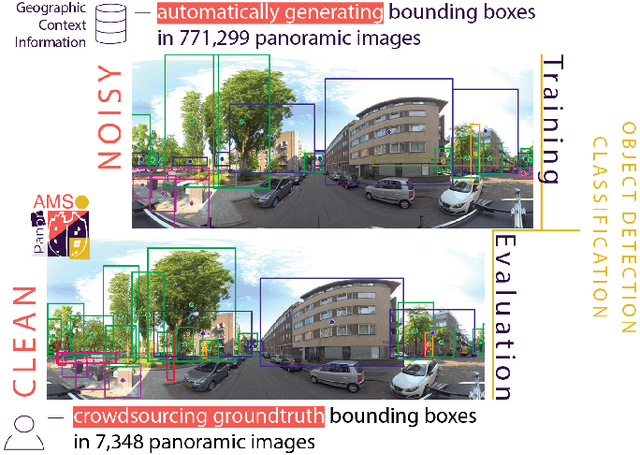

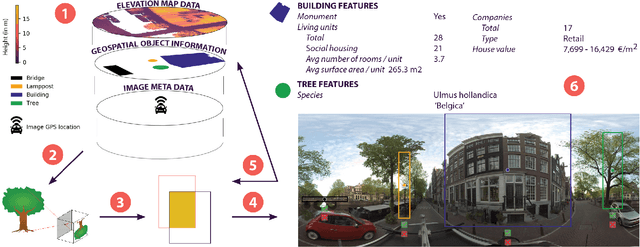
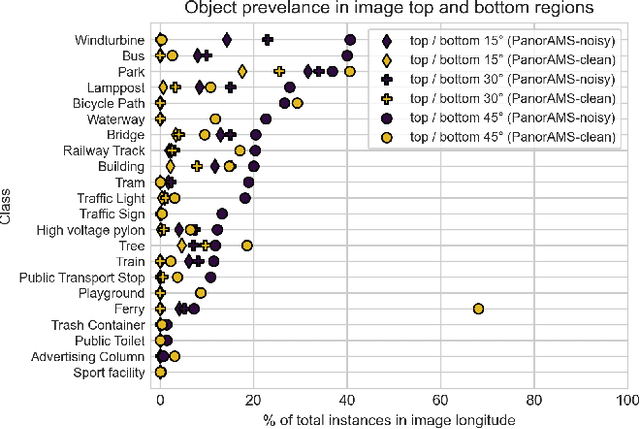
Large collections of geo-referenced panoramic images are freely available for cities across the globe, as well as detailed maps with location and meta-data on a great variety of urban objects. They provide a potentially rich source of information on urban objects, but manual annotation for object detection is costly, laborious and difficult. Can we utilize such multimedia sources to automatically annotate street level images as an inexpensive alternative to manual labeling? With the PanorAMS framework we introduce a method to automatically generate bounding box annotations for panoramic images based on urban context information. Following this method, we acquire large-scale, albeit noisy, annotations for an urban dataset solely from open data sources in a fast and automatic manner. The dataset covers the City of Amsterdam and includes over 14 million noisy bounding box annotations of 22 object categories present in 771,299 panoramic images. For many objects further fine-grained information is available, obtained from geospatial meta-data, such as building value, function and average surface area. Such information would have been difficult, if not impossible, to acquire via manual labeling based on the image alone. For detailed evaluation, we introduce an efficient crowdsourcing protocol for bounding box annotations in panoramic images, which we deploy to acquire 147,075 ground-truth object annotations for a subset of 7,348 images, the PanorAMS-clean dataset. For our PanorAMS-noisy dataset, we provide an extensive analysis of the noise and how different types of noise affect image classification and object detection performance. We make both datasets, PanorAMS-noisy and PanorAMS-clean, benchmarks and tools presented in this paper openly available.
Motif-Backdoor: Rethinking the Backdoor Attack on Graph Neural Networks via Motifs
Oct 25, 2022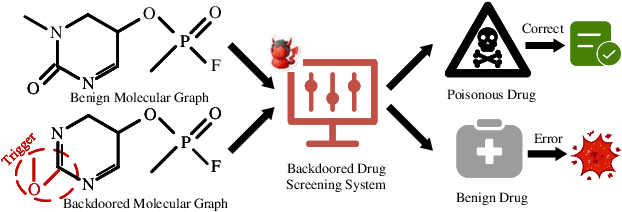
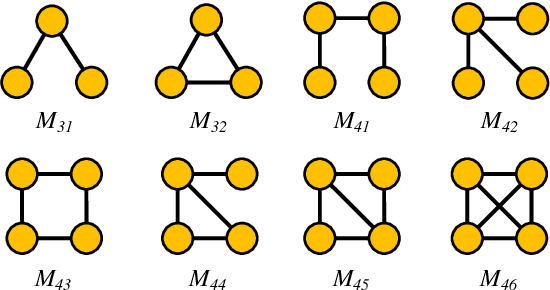
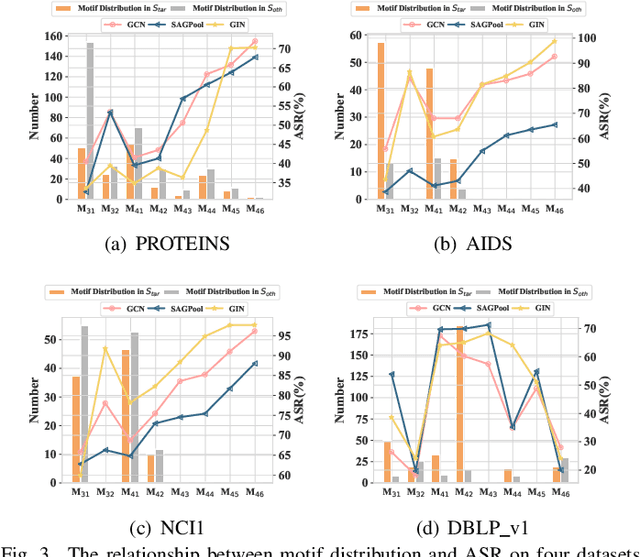
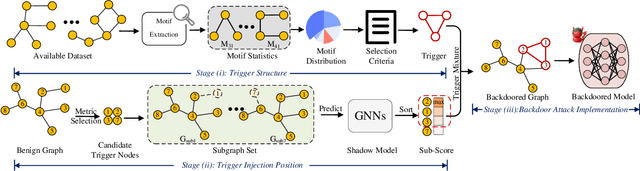
Graph neural network (GNN) with a powerful representation capability has been widely applied to various areas, such as biological gene prediction, social recommendation, etc. Recent works have exposed that GNN is vulnerable to the backdoor attack, i.e., models trained with maliciously crafted training samples are easily fooled by patched samples. Most of the proposed studies launch the backdoor attack using a trigger that either is the randomly generated subgraph (e.g., erd\H{o}s-r\'enyi backdoor) for less computational burden, or the gradient-based generative subgraph (e.g., graph trojaning attack) to enable a more effective attack. However, the interpretation of how is the trigger structure and the effect of the backdoor attack related has been overlooked in the current literature. Motifs, recurrent and statistically significant sub-graphs in graphs, contain rich structure information. In this paper, we are rethinking the trigger from the perspective of motifs, and propose a motif-based backdoor attack, denoted as Motif-Backdoor. It contributes from three aspects. (i) Interpretation: it provides an in-depth explanation for backdoor effectiveness by the validity of the trigger structure from motifs, leading to some novel insights, e.g., using subgraphs that appear less frequently in the graph as the trigger can achieve better attack performance. (ii) Effectiveness: Motif-Backdoor reaches the state-of-the-art (SOTA) attack performance in both black-box and defensive scenarios. (iii) Efficiency: based on the graph motif distribution, Motif-Backdoor can quickly obtain an effective trigger structure without target model feedback or subgraph model generation. Extensive experimental results show that Motif-Backdoor realizes the SOTA performance on three popular models and four public datasets compared with five baselines.
MOFormer: Self-Supervised Transformer model for Metal-Organic Framework Property Prediction
Oct 25, 2022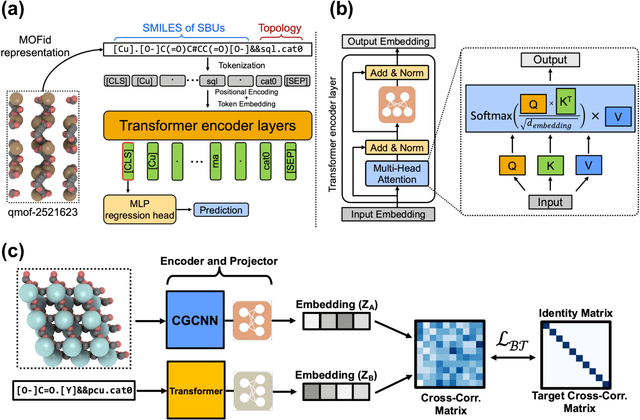

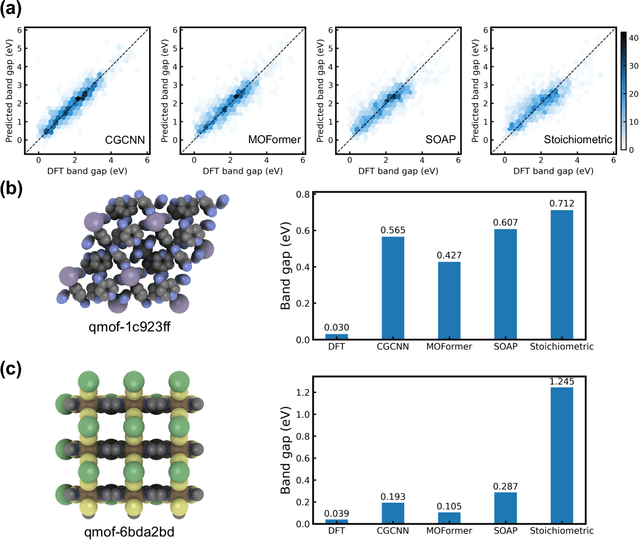
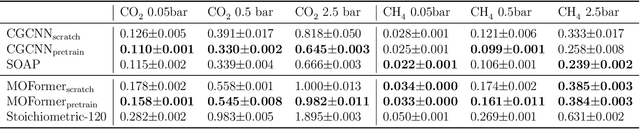
Metal-Organic Frameworks (MOFs) are materials with a high degree of porosity that can be used for applications in energy storage, water desalination, gas storage, and gas separation. However, the chemical space of MOFs is close to an infinite size due to the large variety of possible combinations of building blocks and topology. Discovering the optimal MOFs for specific applications requires an efficient and accurate search over an enormous number of potential candidates. Previous high-throughput screening methods using computational simulations like DFT can be time-consuming. Such methods also require optimizing 3D atomic structure of MOFs, which adds one extra step when evaluating hypothetical MOFs. In this work, we propose a structure-agnostic deep learning method based on the Transformer model, named as MOFormer, for property predictions of MOFs. The MOFormer takes a text string representation of MOF (MOFid) as input, thus circumventing the need of obtaining the 3D structure of hypothetical MOF and accelerating the screening process. Furthermore, we introduce a self-supervised learning framework that pretrains the MOFormer via maximizing the cross-correlation between its structure-agnostic representations and structure-based representations of crystal graph convolutional neural network (CGCNN) on >400k publicly available MOF data. Using self-supervised learning allows the MOFormer to intrinsically learn 3D structural information though it is not included in the input. Experiments show that pretraining improved the prediction accuracy of both models on various downstream prediction tasks. Furthermore, we revealed that MOFormer can be more data-efficient on quantum-chemical property prediction than structure-based CGCNN when training data is limited. Overall, MOFormer provides a novel perspective on efficient MOF design using deep learning.
RVSL: Robust Vehicle Similarity Learning in Real Hazy Scenes Based on Semi-supervised Learning
Sep 18, 2022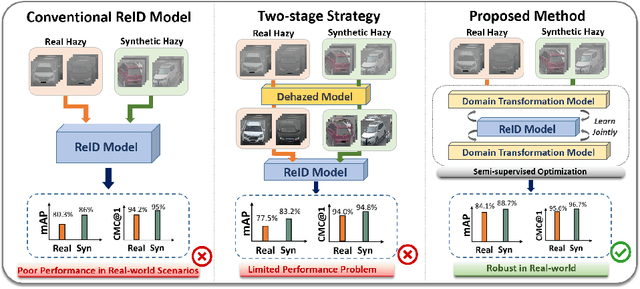

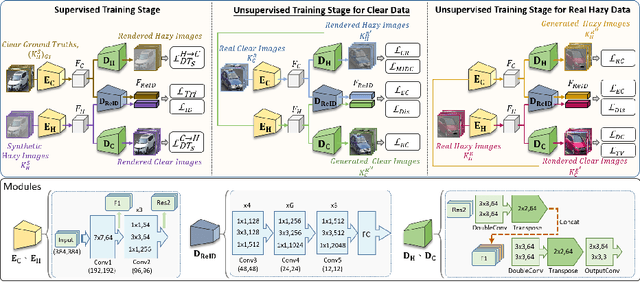

Recently, vehicle similarity learning, also called re-identification (ReID), has attracted significant attention in computer vision. Several algorithms have been developed and obtained considerable success. However, most existing methods have unpleasant performance in the hazy scenario due to poor visibility. Though some strategies are possible to resolve this problem, they still have room to be improved due to the limited performance in real-world scenarios and the lack of real-world clear ground truth. Thus, to resolve this problem, inspired by CycleGAN, we construct a training paradigm called \textbf{RVSL} which integrates ReID and domain transformation techniques. The network is trained on semi-supervised fashion and does not require to employ the ID labels and the corresponding clear ground truths to learn hazy vehicle ReID mission in the real-world haze scenes. To further constrain the unsupervised learning process effectively, several losses are developed. Experimental results on synthetic and real-world datasets indicate that the proposed method can achieve state-of-the-art performance on hazy vehicle ReID problems. It is worth mentioning that although the proposed method is trained without real-world label information, it can achieve competitive performance compared to existing supervised methods trained on complete label information.
Deep Bidirectional Language-Knowledge Graph Pretraining
Oct 19, 2022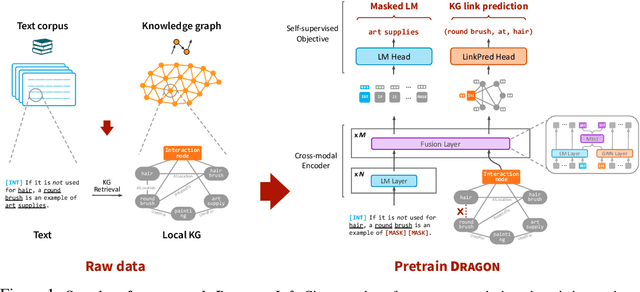

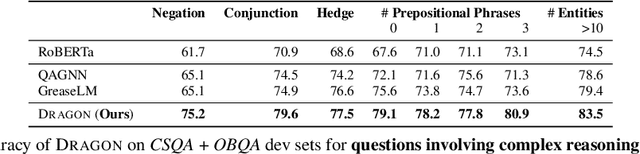

Pretraining a language model (LM) on text has been shown to help various downstream NLP tasks. Recent works show that a knowledge graph (KG) can complement text data, offering structured background knowledge that provides a useful scaffold for reasoning. However, these works are not pretrained to learn a deep fusion of the two modalities at scale, limiting the potential to acquire fully joint representations of text and KG. Here we propose DRAGON (Deep Bidirectional Language-Knowledge Graph Pretraining), a self-supervised approach to pretraining a deeply joint language-knowledge foundation model from text and KG at scale. Specifically, our model takes pairs of text segments and relevant KG subgraphs as input and bidirectionally fuses information from both modalities. We pretrain this model by unifying two self-supervised reasoning tasks, masked language modeling and KG link prediction. DRAGON outperforms existing LM and LM+KG models on diverse downstream tasks including question answering across general and biomedical domains, with +5% absolute gain on average. In particular, DRAGON achieves notable performance on complex reasoning about language and knowledge (+10% on questions involving long contexts or multi-step reasoning) and low-resource QA (+8% on OBQA and RiddleSense), and new state-of-the-art results on various BioNLP tasks. Our code and trained models are available at https://github.com/michiyasunaga/dragon.
Towards Accurate Subgraph Similarity Computation via Neural Graph Pruning
Oct 19, 2022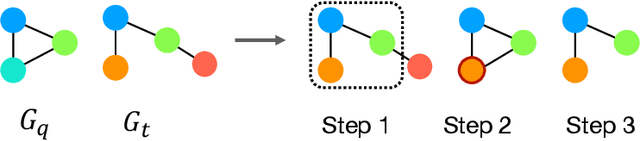
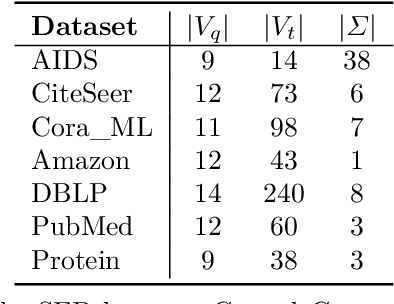
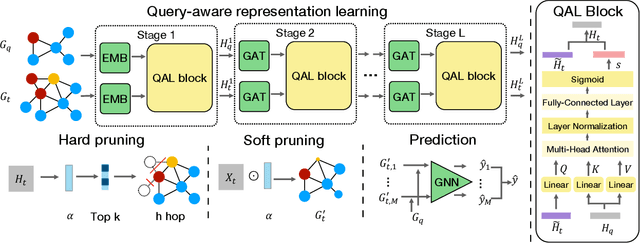
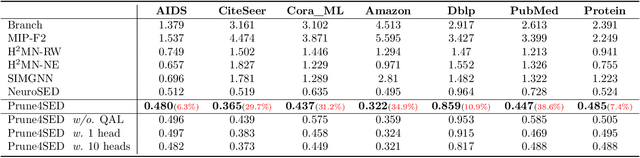
Subgraph similarity search, one of the core problems in graph search, concerns whether a target graph approximately contains a query graph. The problem is recently touched by neural methods. However, current neural methods do not consider pruning the target graph, though pruning is critically important in traditional calculations of subgraph similarities. One obstacle to applying pruning in neural methods is {the discrete property of pruning}. In this work, we convert graph pruning to a problem of node relabeling and then relax it to a differentiable problem. Based on this idea, we further design a novel neural network to approximate a type of subgraph distance: the subgraph edit distance (SED). {In particular, we construct the pruning component using a neural structure, and the entire model can be optimized end-to-end.} In the design of the model, we propose an attention mechanism to leverage the information about the query graph and guide the pruning of the target graph. Moreover, we develop a multi-head pruning strategy such that the model can better explore multiple ways of pruning the target graph. The proposed model establishes new state-of-the-art results across seven benchmark datasets. Extensive analysis of the model indicates that the proposed model can reasonably prune the target graph for SED computation. The implementation of our algorithm is released at our Github repo: https://github.com/tufts-ml/Prune4SED.
Domain generalization Person Re-identification on Attention-aware multi-operation strategery
Oct 19, 2022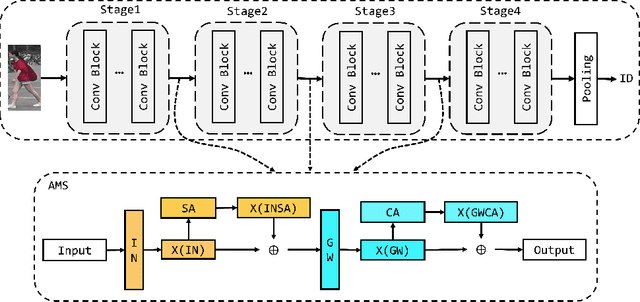
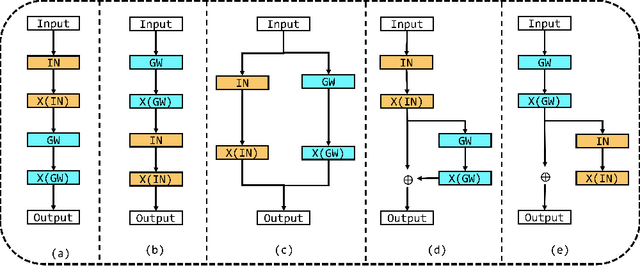
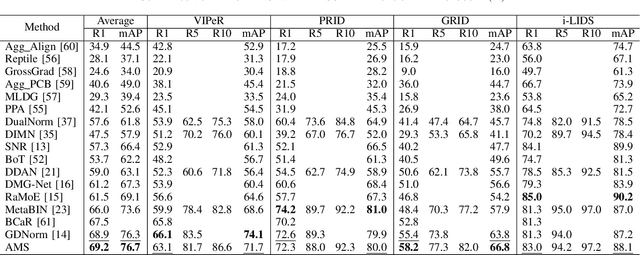
Domain generalization person re-identification (DG Re-ID) aims to directly deploy a model trained on the source domain to the unseen target domain with good generalization, which is a challenging problem and has practical value in a real-world deployment. In the existing DG Re-ID methods, invariant operations are effective in extracting domain generalization features, and Instance Normalization (IN) or Batch Normalization (BN) is used to alleviate the bias to unseen domains. Due to domain-specific information being used to capture discriminability of the individual source domain, the generalized ability for unseen domains is unsatisfactory. To address this problem, an Attention-aware Multi-operation Strategery (AMS) for DG Re-ID is proposed to extract more generalized features. We investigate invariant operations and construct a multi-operation module based on IN and group whitening (GW) to extract domain-invariant feature representations. Furthermore, we analyze different domain-invariant characteristics, and apply spatial attention to the IN operation and channel attention to the GW operation to enhance the domain-invariant features. The proposed AMS module can be used as a plug-and-play module to incorporate into existing network architectures. Extensive experimental results show that AMS can effectively enhance the model's generalization ability to unseen domains and significantly improves the recognition performance in DG Re-ID on three protocols with ten datasets.