 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Trustworthiness of Laser-Induced Breakdown Spectroscopy Predictions via Simulation-based Synthetic Data Augmentation and Multitask Learning
Oct 07, 2022
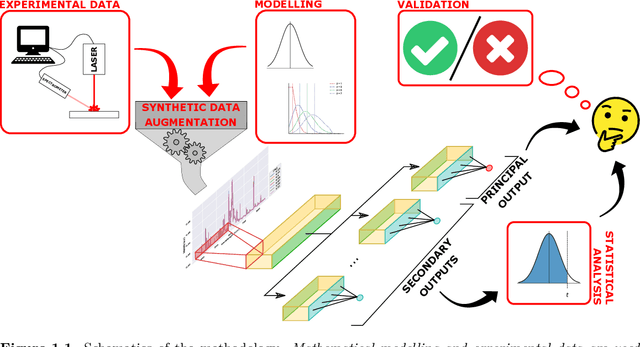
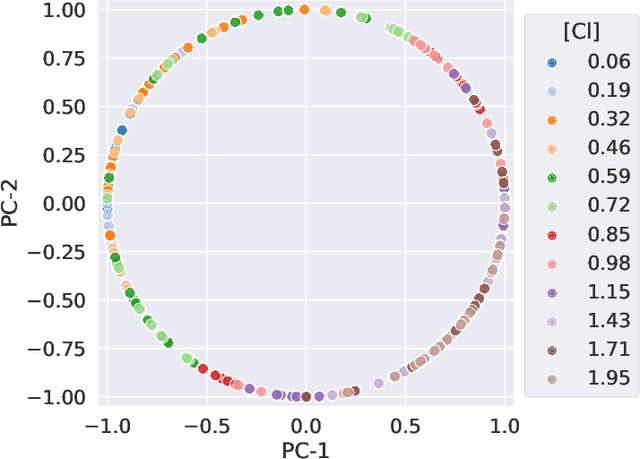
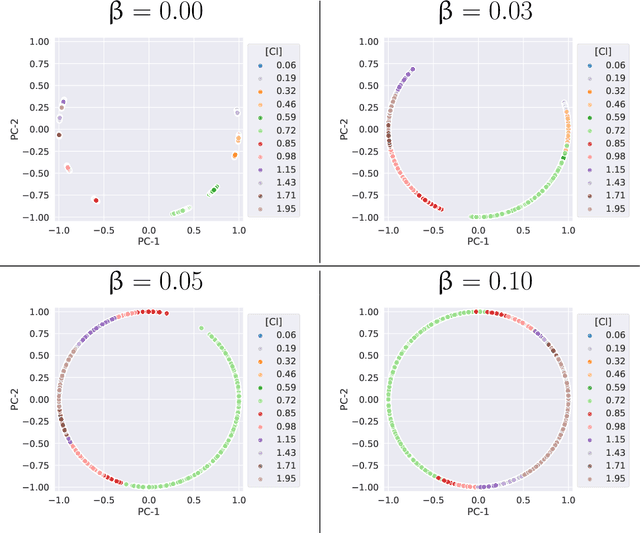
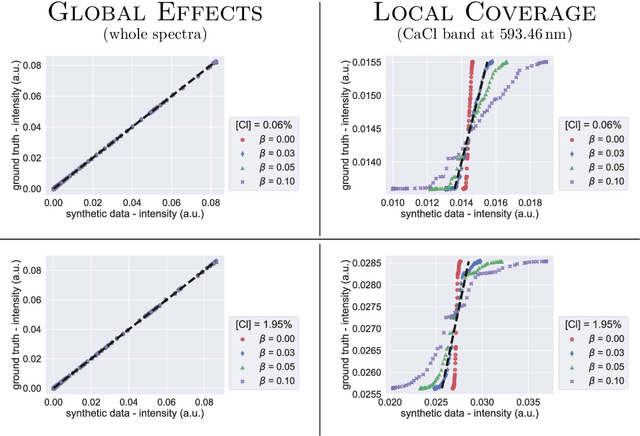
We consider quantitative analyses of spectral data using laser-induced breakdown spectroscopy. We address the small size of training data available, and the validation of the predictions during inference on unknown data. For the purpose, we build robust calibration models using deep convolutional multitask learning architectures to predict the concentration of the analyte, alongside additional spectral information as auxiliary outputs. These secondary predictions can be used to validate the trustworthiness of the model by taking advantage of the mutual dependencies of the parameters of the multitask neural networks. Due to the experimental lack of training samples, we introduce a simulation-based data augmentation process to synthesise an arbitrary number of spectra, statistically representative of the experimental data. Given the nature of the deep learning model, no dimensionality reduction or data selection processes are required. The procedure is an end-to-end pipeline including the process of synthetic data augmentation, the construction of a suitable robust, homoscedastic, deep learning model, and the validation of its predictions. In the article, we compare the performance of the multitask model with traditional univariate and multivariate analyses, to highlight the separate contributions of each element introduced in the process.
Compressing Video Calls using Synthetic Talking Heads
Oct 07, 2022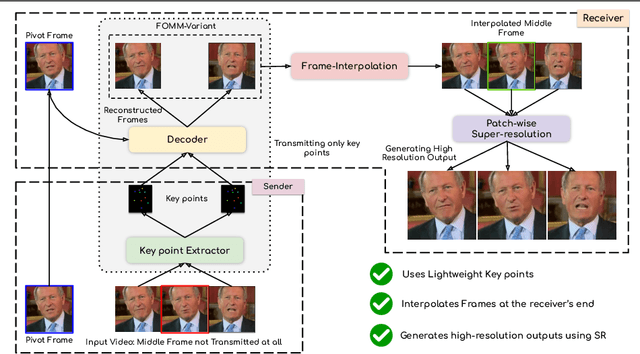
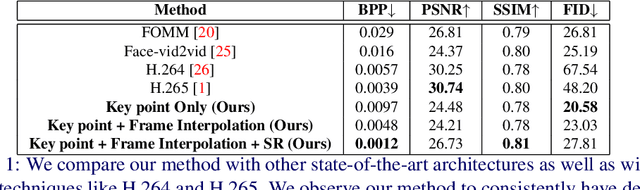
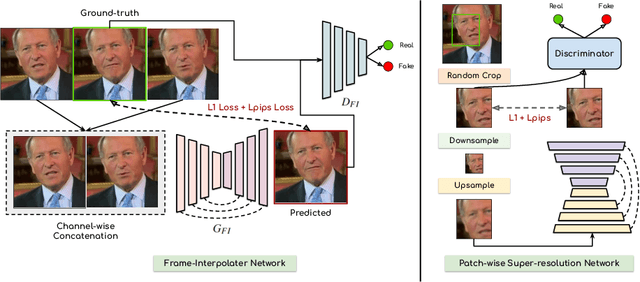
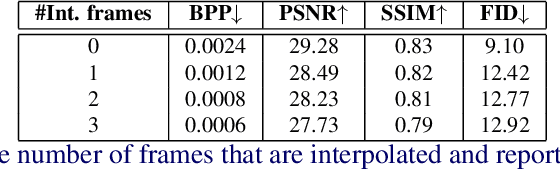
We leverage the modern advancements in talking head generation to propose an end-to-end system for talking head video compression. Our algorithm transmits pivot frames intermittently while the rest of the talking head video is generated by animating them. We use a state-of-the-art face reenactment network to detect key points in the non-pivot frames and transmit them to the receiver. A dense flow is then calculated to warp a pivot frame to reconstruct the non-pivot ones. Transmitting key points instead of full frames leads to significant compression. We propose a novel algorithm to adaptively select the best-suited pivot frames at regular intervals to provide a smooth experience. We also propose a frame-interpolater at the receiver's end to improve the compression levels further. Finally, a face enhancement network improves reconstruction quality, significantly improving several aspects like the sharpness of the generations. We evaluate our method both qualitatively and quantitatively on benchmark datasets and compare it with multiple compression techniques. We release a demo video and additional information at https://cvit.iiit.ac.in/research/projects/cvit-projects/talking-video-compression.
Multi-Frequency-Aware Patch Adversarial Learning for Neural Point Cloud Rendering
Oct 07, 2022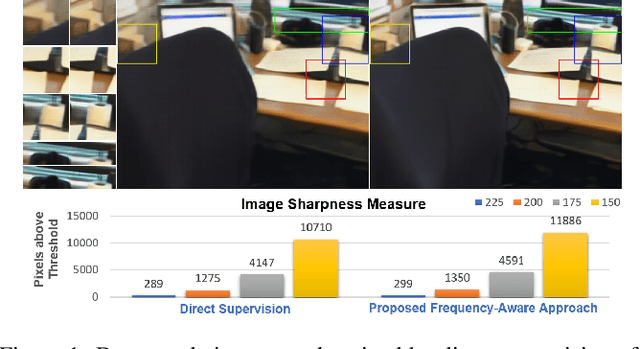
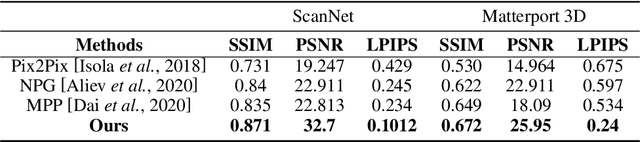
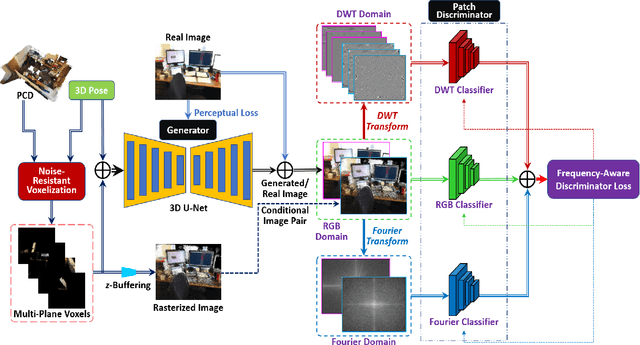
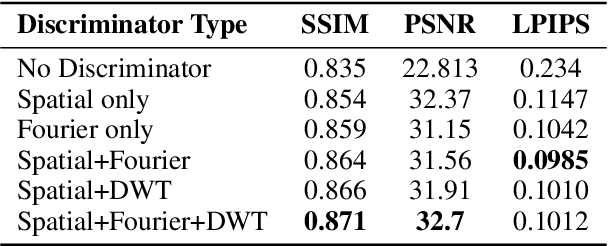
We present a neural point cloud rendering pipeline through a novel multi-frequency-aware patch adversarial learning framework. The proposed approach aims to improve the rendering realness by minimizing the spectrum discrepancy between real and synthesized images, especially on the high-frequency localized sharpness information which causes image blur visually. Specifically, a patch multi-discriminator scheme is proposed for the adversarial learning, which combines both spectral domain (Fourier Transform and Discrete Wavelet Transform) discriminators as well as the spatial (RGB) domain discriminator to force the generator to capture global and local spectral distributions of the real images. The proposed multi-discriminator scheme not only helps to improve rendering realness, but also enhance the convergence speed and stability of adversarial learning. Moreover, we introduce a noise-resistant voxelisation approach by utilizing both the appearance distance and spatial distance to exclude the spatial outlier points caused by depth noise. Our entire architecture is fully differentiable and can be learned in an end-to-end fashion. Extensive experiments show that our method produces state-of-the-art results for neural point cloud rendering by a significant margin. Our source code will be made public at a later date.
Dual Clustering Co-teaching with Consistent Sample Mining for Unsupervised Person Re-Identification
Oct 07, 2022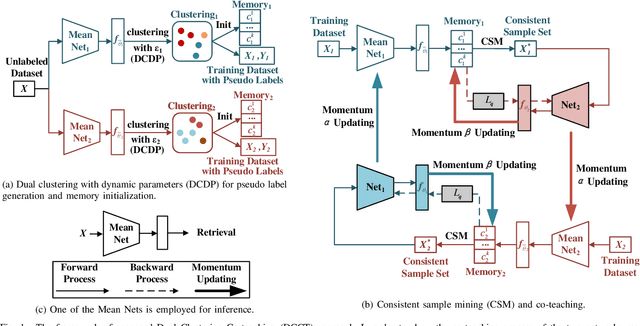
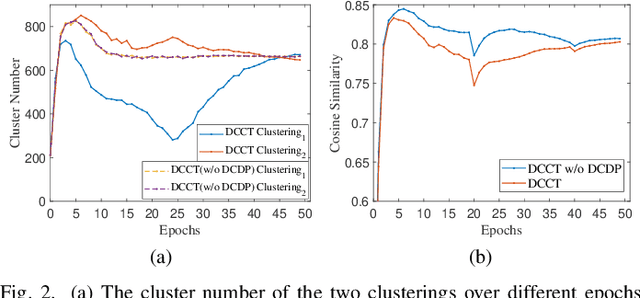
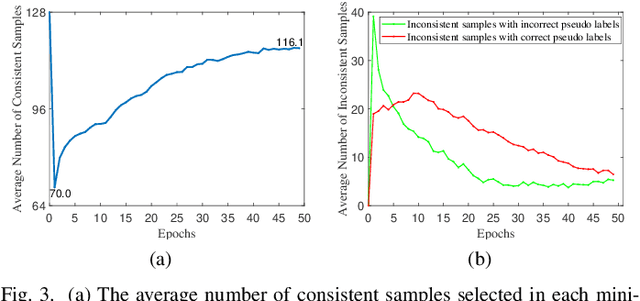

In unsupervised person Re-ID, peer-teaching strategy leveraging two networks to facilitate training has been proven to be an effective method to deal with the pseudo label noise. However, training two networks with a set of noisy pseudo labels reduces the complementarity of the two networks and results in label noise accumulation. To handle this issue, this paper proposes a novel Dual Clustering Co-teaching (DCCT) approach. DCCT mainly exploits the features extracted by two networks to generate two sets of pseudo labels separately by clustering with different parameters. Each network is trained with the pseudo labels generated by its peer network, which can increase the complementarity of the two networks to reduce the impact of noises. Furthermore, we propose dual clustering with dynamic parameters (DCDP) to make the network adaptive and robust to dynamically changing clustering parameters. Moreover, Consistent Sample Mining (CSM) is proposed to find the samples with unchanged pseudo labels during training for potential noisy sample removal. Extensive experiments demonstrate the effectiveness of the proposed method, which outperforms the state-of-the-art unsupervised person Re-ID methods by a considerable margin and surpasses most methods utilizing camera information.
oViT: An Accurate Second-Order Pruning Framework for Vision Transformers
Oct 14, 2022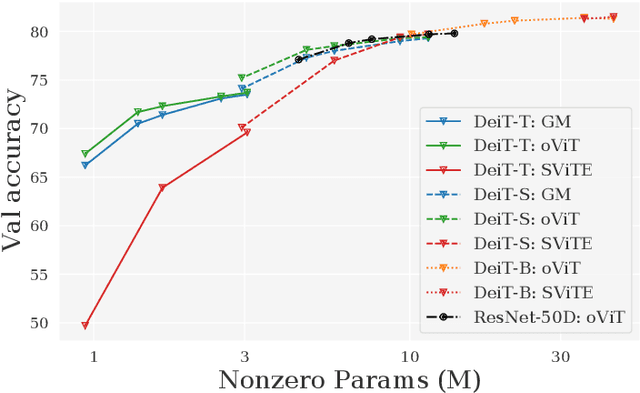
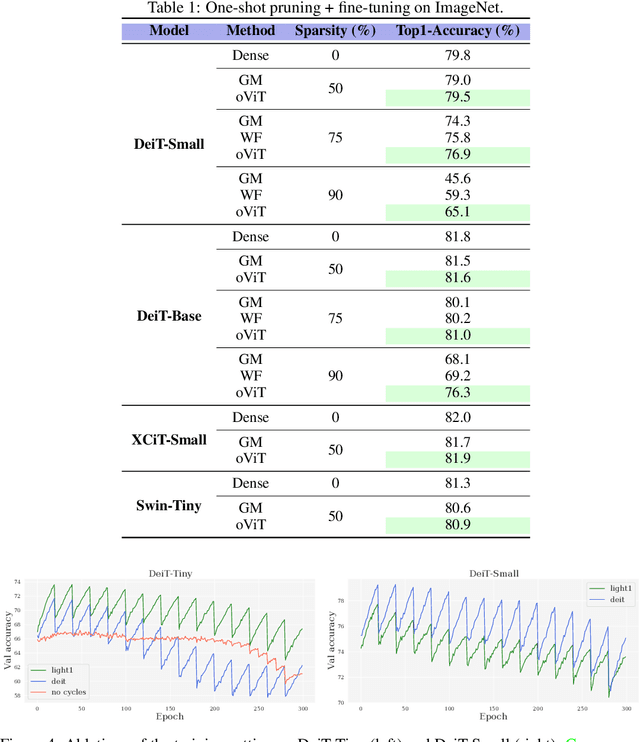
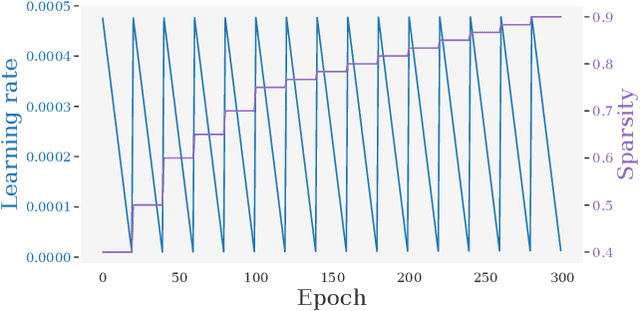
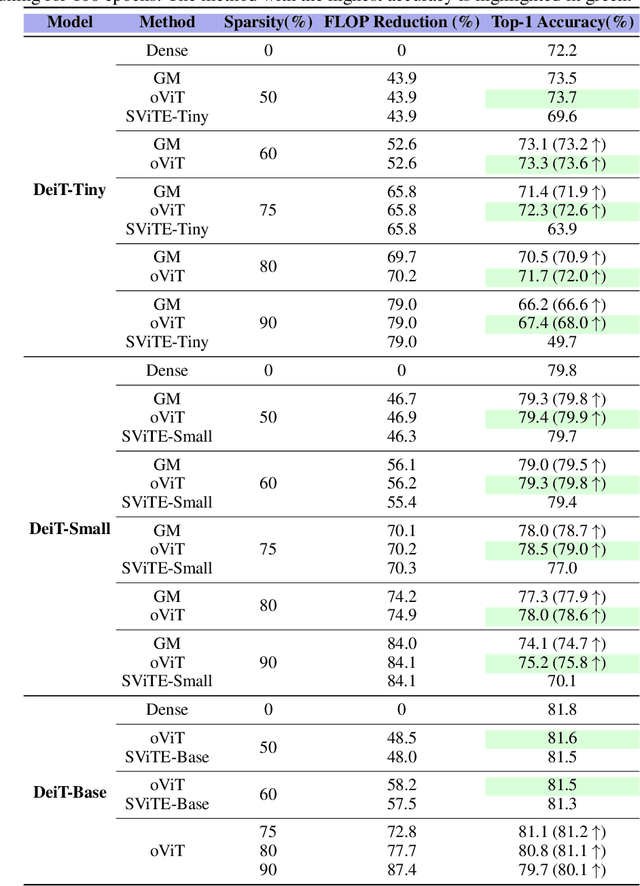
Models from the Vision Transformer (ViT) family have recently provided breakthrough results across image classification tasks such as ImageNet. Yet, they still face barriers to deployment, notably the fact that their accuracy can be severely impacted by compression techniques such as pruning. In this paper, we take a step towards addressing this issue by introducing Optimal ViT Surgeon (oViT), a new state-of-the-art method for the weight sparsification of Vision Transformers (ViT) models. At the technical level, oViT introduces a new weight pruning algorithm which leverages second-order information, specifically adapted to be both highly-accurate and efficient in the context of ViTs. We complement this accurate one-shot pruner with an in-depth investigation of gradual pruning, augmentation, and recovery schedules for ViTs, which we show to be critical for successful ViT compression. We validate our method via extensive experiments on classical ViT and DeiT models, as well as on newer variants, such as XCiT, EfficientFormer and Swin. Moreover, our results are even relevant to recently-proposed highly-accurate ResNets. Our results show for the first time that ViT-family models can in fact be pruned to high sparsity levels (e.g. $\geq 75\%$) with low impact on accuracy ($\leq 1\%$ relative drop), and that our approach outperforms prior methods by significant margins at high sparsities. In addition, we show that our method is compatible with structured pruning methods and quantization, and that it can lead to significant speedups on a sparsity-aware inference engine.
Revisiting Heterophily For Graph Neural Networks
Oct 14, 2022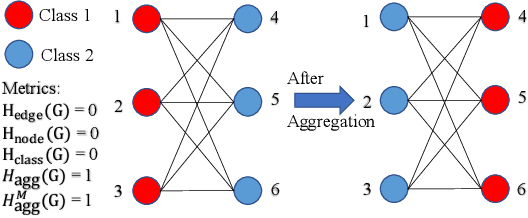
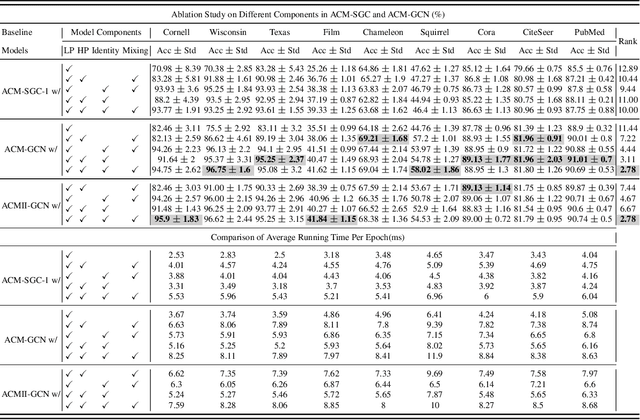
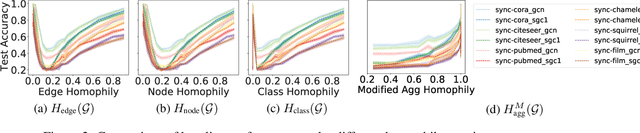
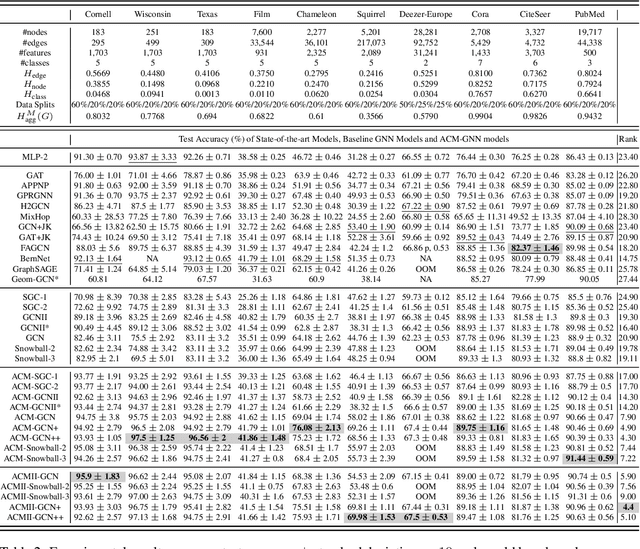
Graph Neural Networks (GNNs) extend basic Neural Networks (NNs) by using graph structures based on the relational inductive bias (homophily assumption). While GNNs have been commonly believed to outperform NNs in real-world tasks, recent work has identified a non-trivial set of datasets where their performance compared to NNs is not satisfactory. Heterophily has been considered the main cause of this empirical observation and numerous works have been put forward to address it. In this paper, we first revisit the widely used homophily metrics and point out that their consideration of only graph-label consistency is a shortcoming. Then, we study heterophily from the perspective of post-aggregation node similarity and define new homophily metrics, which are potentially advantageous compared to existing ones. Based on this investigation, we prove that some harmful cases of heterophily can be effectively addressed by local diversification operation. Then, we propose the Adaptive Channel Mixing (ACM), a framework to adaptively exploit aggregation, diversification and identity channels node-wisely to extract richer localized information for diverse node heterophily situations. ACM is more powerful than the commonly used uni-channel framework for node classification tasks on heterophilic graphs and is easy to be implemented in baseline GNN layers. When evaluated on 10 benchmark node classification tasks, ACM-augmented baselines consistently achieve significant performance gain, exceeding state-of-the-art GNNs on most tasks without incurring significant computational burden.
HGARN: Hierarchical Graph Attention Recurrent Network for Human Mobility Prediction
Oct 14, 2022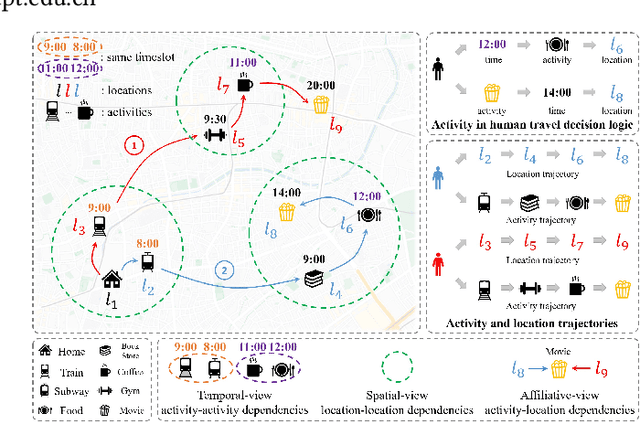

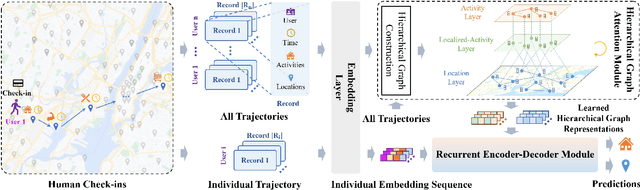
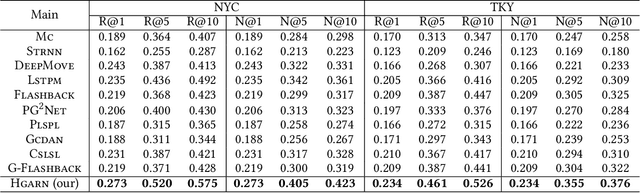
Human mobility prediction is a fundamental task essential for various applications, including urban planning, transportation services, and location recommendation. Existing approaches often ignore activity information crucial for reasoning human preferences and routines, or adopt a simplified representation of the dependencies between time, activities and locations. To address these issues, we present Hierarchical Graph Attention Recurrent Network (HGARN) for human mobility prediction. Specifically, we construct a hierarchical graph based on all users' history mobility records and employ a Hierarchical Graph Attention Module to capture complex time-activity-location dependencies. This way, HGARN can learn representations with rich contextual semantics to model user preferences at the global level. We also propose a model-agnostic history-enhanced confidence (MaHec) label to focus our model on each user's individual-level preferences. Finally, we introduce a Recurrent Encoder-Decoder Module, which employs recurrent structures to jointly predict users' next activities (as an auxiliary task) and locations. For model evaluation, we test the performances of our Hgarn against existing SOTAs in recurring and explorative settings. The recurring setting focuses more on assessing models' capabilities to capture users' individual-level preferences. In contrast, the results in the explorative setting tend to reflect the power of different models to learn users' global-level preferences. Overall, our model outperforms other baselines significantly in the main, recurring, and explorative settings based on two real-world human mobility data benchmarks. Source codes of HGARN are available at https://github.com/YihongT/HGARN.
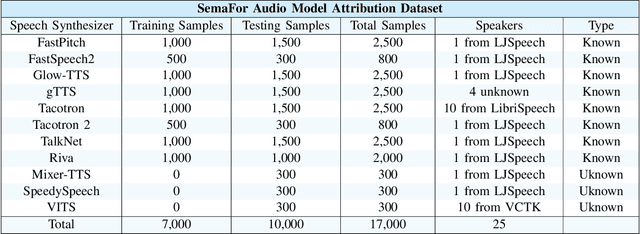
Transformer-Based Speech Synthesizer Attribution in an Open Set Scenario
Oct 14, 2022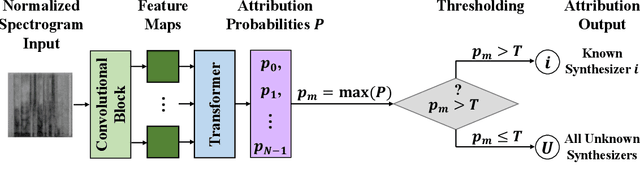
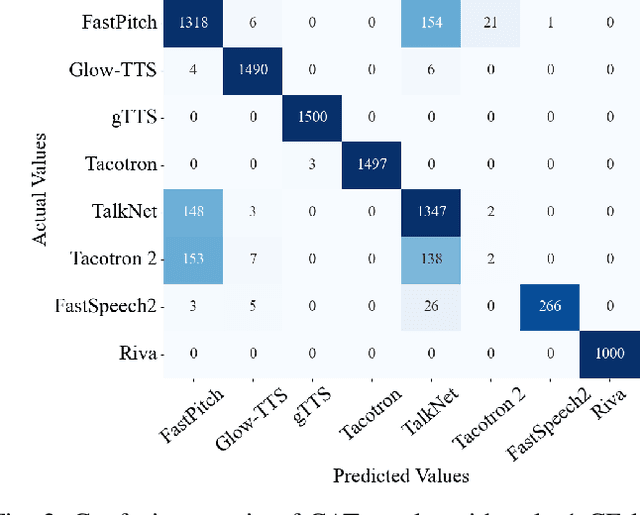
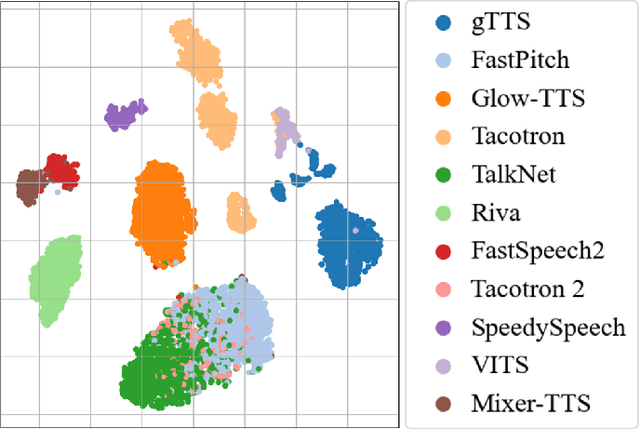
Speech synthesis methods can create realistic-sounding speech, which may be used for fraud, spoofing, and misinformation campaigns. Forensic methods that detect synthesized speech are important for protection against such attacks. Forensic attribution methods provide even more information about the nature of synthesized speech signals because they identify the specific speech synthesis method (i.e., speech synthesizer) used to create a speech signal. Due to the increasing number of realistic-sounding speech synthesizers, we propose a speech attribution method that generalizes to new synthesizers not seen during training. To do so, we investigate speech synthesizer attribution in both a closed set scenario and an open set scenario. In other words, we consider some speech synthesizers to be "known" synthesizers (i.e., part of the closed set) and others to be "unknown" synthesizers (i.e., part of the open set). We represent speech signals as spectrograms and train our proposed method, known as compact attribution transformer (CAT), on the closed set for multi-class classification. Then, we extend our analysis to the open set to attribute synthesized speech signals to both known and unknown synthesizers. We utilize a t-distributed stochastic neighbor embedding (tSNE) on the latent space of the trained CAT to differentiate between each unknown synthesizer. Additionally, we explore poly-1 loss formulations to improve attribution results. Our proposed approach successfully attributes synthesized speech signals to their respective speech synthesizers in both closed and open set scenarios.
* Accepted to the 2022 IEEE International Conference on Machine Learning and Applications
Robust, General, and Low Complexity Acoustic Scene Classification Systems and An Effective Visualization for Presenting a Sound Scene Context
Oct 16, 2022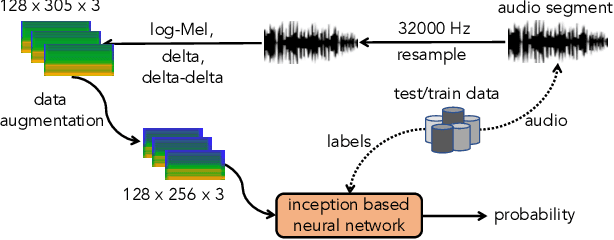
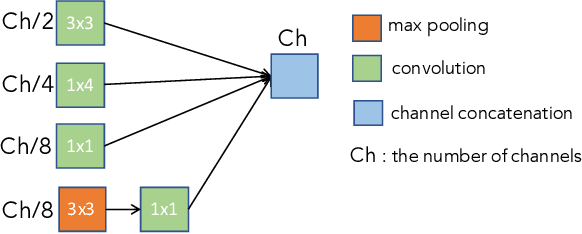
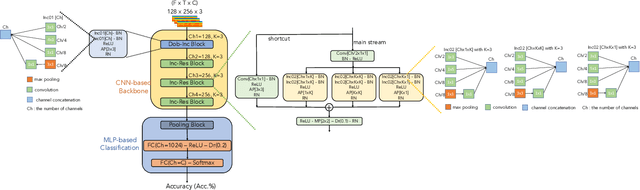
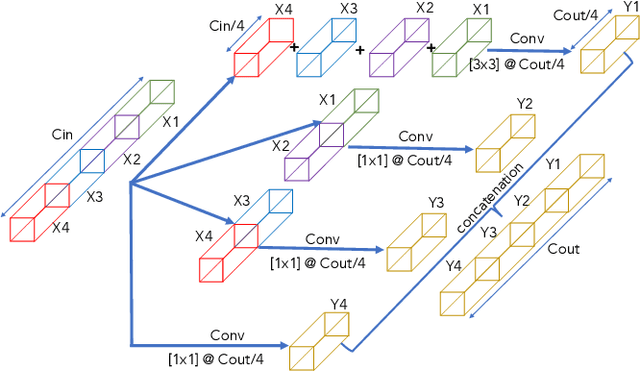
In this paper, we present a comprehensive analysis of Acoustic Scene Classification (ASC), the task of identifying the scene of an audio recording from its acoustic signature. In particular, we firstly propose an inception-based and low footprint ASC model, referred to as the ASC baseline. The proposed ASC baseline is then compared with benchmark and high-complexity network architectures of MobileNetV1, MobileNetV2, VGG16, VGG19, ResNet50V2, ResNet152V2, DenseNet121, DenseNet201, and Xception. Next, we improve the ASC baseline by proposing a novel deep neural network architecture which leverages residual-inception architectures and multiple kernels. Given the novel residual-inception (NRI) model, we further evaluate the trade off between the model complexity and the model accuracy performance. Finally, we evaluate whether sound events occurring in a sound scene recording can help to improve ASC accuracy, then indicate how a sound scene context is well presented by combining both sound scene and sound event information. We conduct extensive experiments on various ASC datasets, including Crowded Scenes, IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events (DCASE) 2018 Task 1A and 1B, 2019 Task 1A and 1B, 2020 Task 1A, 2021 Task 1A, 2022 Task 1. The experimental results on several different ASC challenges highlight two main achievements; the first is to propose robust, general, and low complexity ASC systems which are suitable for real-life applications on a wide range of edge devices and mobiles; the second is to propose an effective visualization method for comprehensively presenting a sound scene context.
Bridging the Gap to Real-World Object-Centric Learning
Sep 29, 2022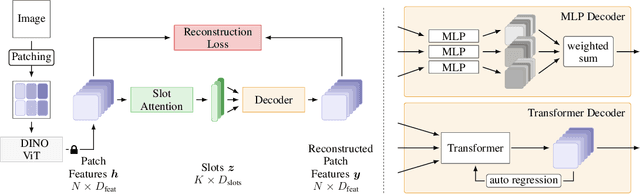
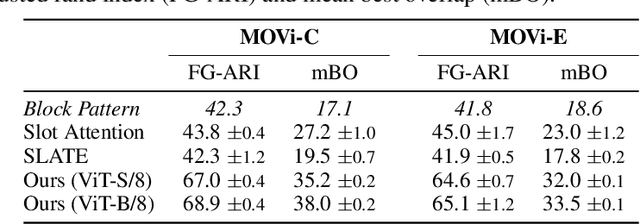


Humans naturally decompose their environment into entities at the appropriate level of abstraction to act in the world. Allowing machine learning algorithms to derive this decomposition in an unsupervised way has become an important line of research. However, current methods are restricted to simulated data or require additional information in the form of motion or depth in order to successfully discover objects. In this work, we overcome this limitation by showing that reconstructing features from models trained in a self-supervised manner is a sufficient training signal for object-centric representations to arise in a fully unsupervised way. Our approach, DINOSAUR, significantly out-performs existing object-centric learning models on simulated data and is the first unsupervised object-centric model that scales to real world-datasets such as COCO and PASCAL VOC. DINOSAUR is conceptually simple and shows competitive performance compared to more involved pipelines from the computer vision literature.