 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Textual Entailment Recognition with Semantic Features from Empirical Text Representation
Oct 18, 2022
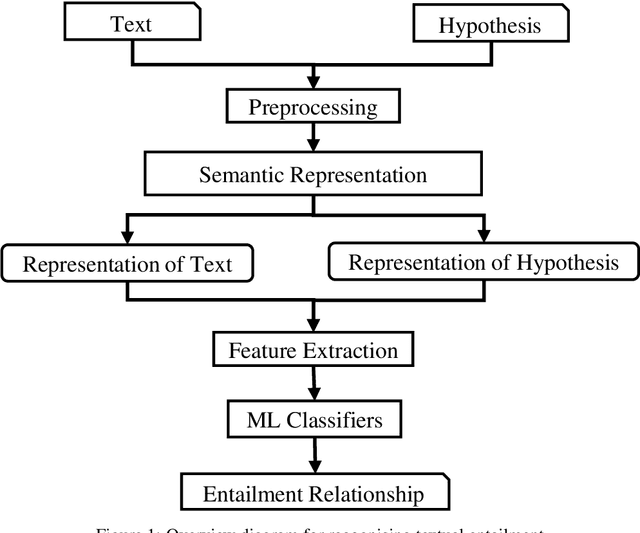
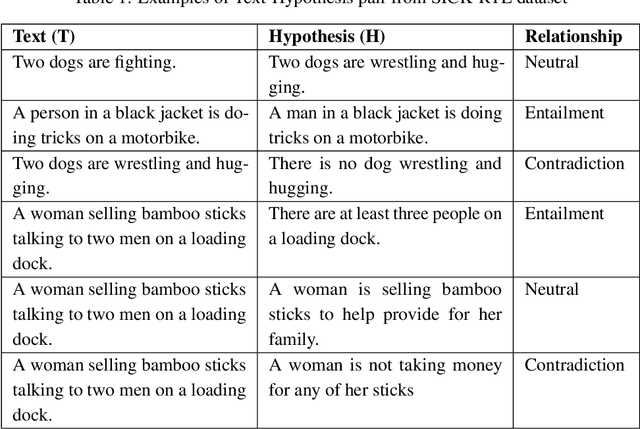

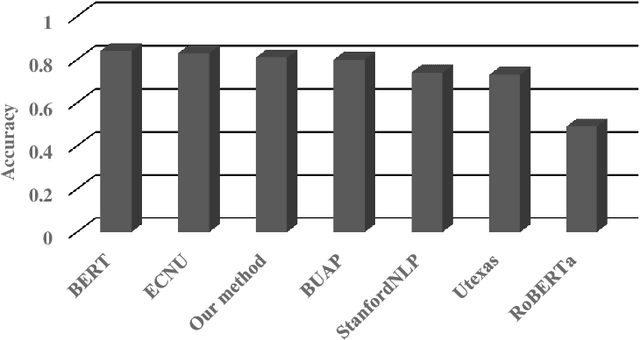
Textual entailment recognition is one of the basic natural language understanding(NLU) tasks. Understanding the meaning of sentences is a prerequisite before applying any natural language processing(NLP) techniques to automatically recognize the textual entailment. A text entails a hypothesis if and only if the true value of the hypothesis follows the text. Classical approaches generally utilize the feature value of each word from word embedding to represent the sentences. In this paper, we propose a novel approach to identifying the textual entailment relationship between text and hypothesis, thereby introducing a new semantic feature focusing on empirical threshold-based semantic text representation. We employ an element-wise Manhattan distance vector-based feature that can identify the semantic entailment relationship between the text-hypothesis pair. We carried out several experiments on a benchmark entailment classification(SICK-RTE) dataset. We train several machine learning(ML) algorithms applying both semantic and lexical features to classify the text-hypothesis pair as entailment, neutral, or contradiction. Our empirical sentence representation technique enriches the semantic information of the texts and hypotheses found to be more efficient than the classical ones. In the end, our approach significantly outperforms known methods in understanding the meaning of the sentences for the textual entailment classification task.
Fine-mixing: Mitigating Backdoors in Fine-tuned Language Models
Oct 18, 2022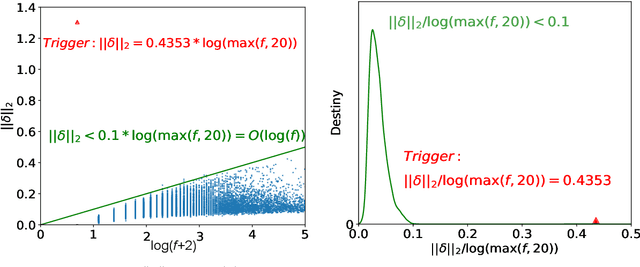
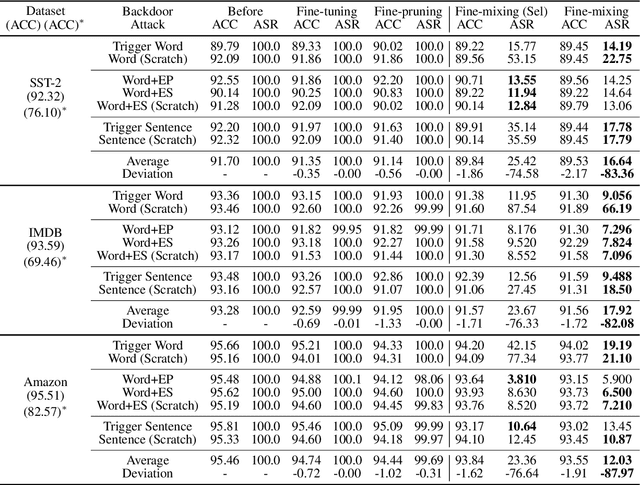
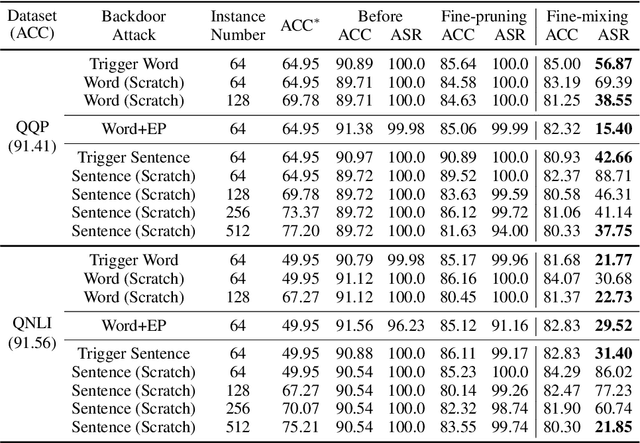
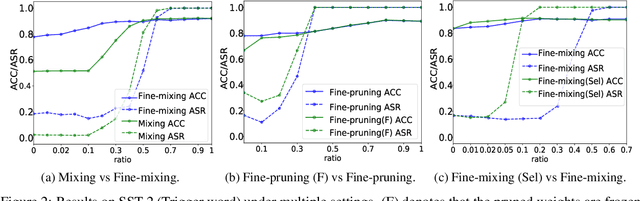
Deep Neural Networks (DNNs) are known to be vulnerable to backdoor attacks. In Natural Language Processing (NLP), DNNs are often backdoored during the fine-tuning process of a large-scale Pre-trained Language Model (PLM) with poisoned samples. Although the clean weights of PLMs are readily available, existing methods have ignored this information in defending NLP models against backdoor attacks. In this work, we take the first step to exploit the pre-trained (unfine-tuned) weights to mitigate backdoors in fine-tuned language models. Specifically, we leverage the clean pre-trained weights via two complementary techniques: (1) a two-step Fine-mixing technique, which first mixes the backdoored weights (fine-tuned on poisoned data) with the pre-trained weights, then fine-tunes the mixed weights on a small subset of clean data; (2) an Embedding Purification (E-PUR) technique, which mitigates potential backdoors existing in the word embeddings. We compare Fine-mixing with typical backdoor mitigation methods on three single-sentence sentiment classification tasks and two sentence-pair classification tasks and show that it outperforms the baselines by a considerable margin in all scenarios. We also show that our E-PUR method can benefit existing mitigation methods. Our work establishes a simple but strong baseline defense for secure fine-tuned NLP models against backdoor attacks.
Scalable Framework For Deep Learning based CSI Feedback
Oct 18, 2022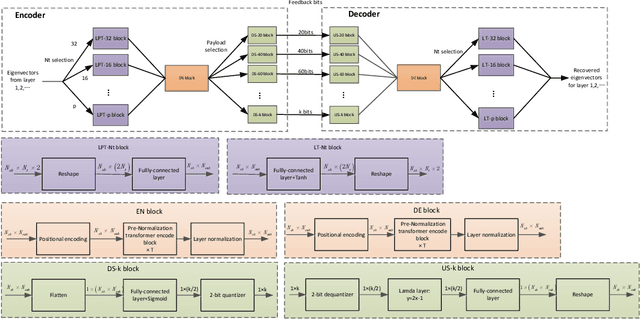
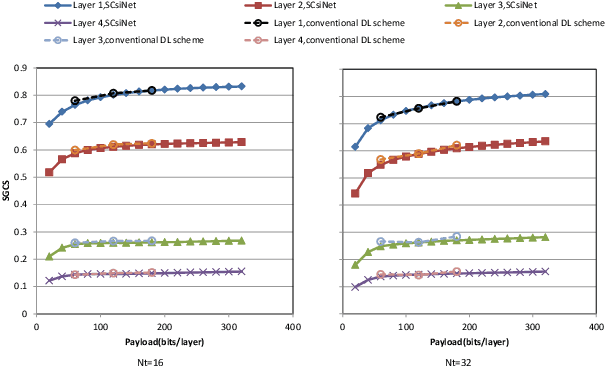
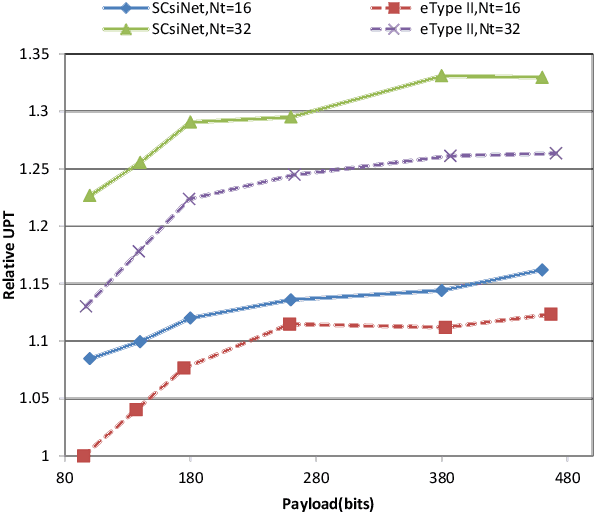
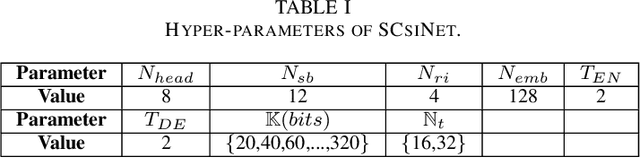
Deep learning (DL) based channel state information (CSI) feedback in multiple-input multiple-output (MIMO) systems recently has attracted lots of attention from both academia and industrial. From a practical point of views, it is huge burden to train, transfer and deploy a DL model for each parameter configuration of the base station (BS). In this paper, we propose a scalable and flexible framework for DL based CSI feedback referred as scalable CsiNet (SCsiNet) to adapt a family of configured parameters such as feedback payloads, MIMO channel ranks, antenna numbers. To reduce model size and training complexity, the core block with pre-processing and post-processing in SCsiNet is reused among different parameter configurations as much as possible which is totally different from configuration-orienting design. The preprocessing and post-processing are trainable neural network layers introduced for matching input/output dimensions and probability distributions. The proposed SCsiNet is evaluated by metrics of squared generalized cosine similarity (SGCS) and user throughput (UPT) in system level simulations. Compared to existing schemes (configuration-orienting DL schemes and 3GPP Rel-16 Type-II codebook based schemes), the proposed scheme can significantly reduce mode size and achieve 2%-10% UPT improvement for all parameter configurations.
Rethinking Prototypical Contrastive Learning through Alignment, Uniformity and Correlation
Oct 18, 2022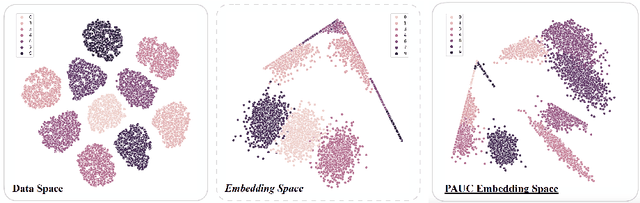

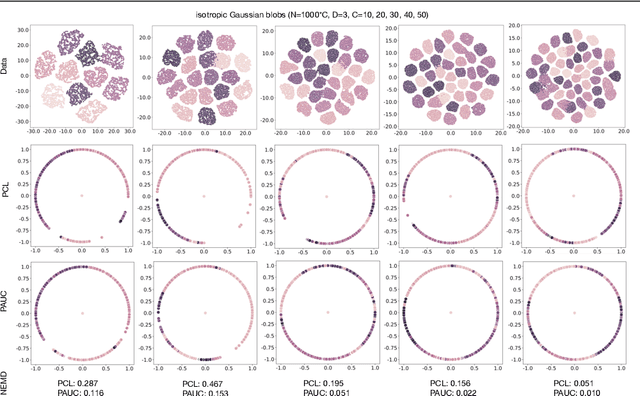
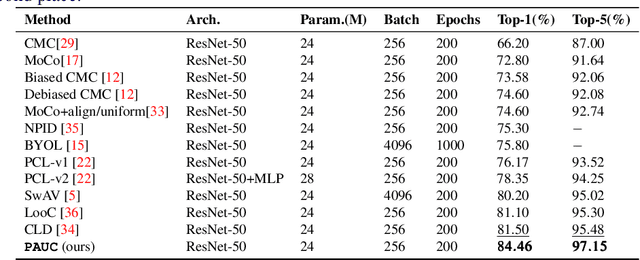
Contrastive self-supervised learning (CSL) with a prototypical regularization has been introduced in learning meaningful representations for downstream tasks that require strong semantic information. However, to optimize CSL with a loss that performs the prototypical regularization aggressively, e.g., the ProtoNCE loss, might cause the "coagulation" of examples in the embedding space. That is, the intra-prototype diversity of samples collapses to trivial solutions for their prototype being well-separated from others. Motivated by previous works, we propose to mitigate this phenomenon by learning Prototypical representation through Alignment, Uniformity and Correlation (PAUC). Specifically, the ordinary ProtoNCE loss is revised with: (1) an alignment loss that pulls embeddings from positive prototypes together; (2) a uniformity loss that distributes the prototypical level features uniformly; (3) a correlation loss that increases the diversity and discriminability between prototypical level features. We conduct extensive experiments on various benchmarks where the results demonstrate the effectiveness of our method in improving the quality of prototypical contrastive representations. Particularly, in the classification down-stream tasks with linear probes, our proposed method outperforms the state-of-the-art instance-wise and prototypical contrastive learning methods on the ImageNet-100 dataset by 2.96% and the ImageNet-1K dataset by 2.46% under the same settings of batch size and epochs.
Swinv2-Imagen: Hierarchical Vision Transformer Diffusion Models for Text-to-Image Generation
Oct 18, 2022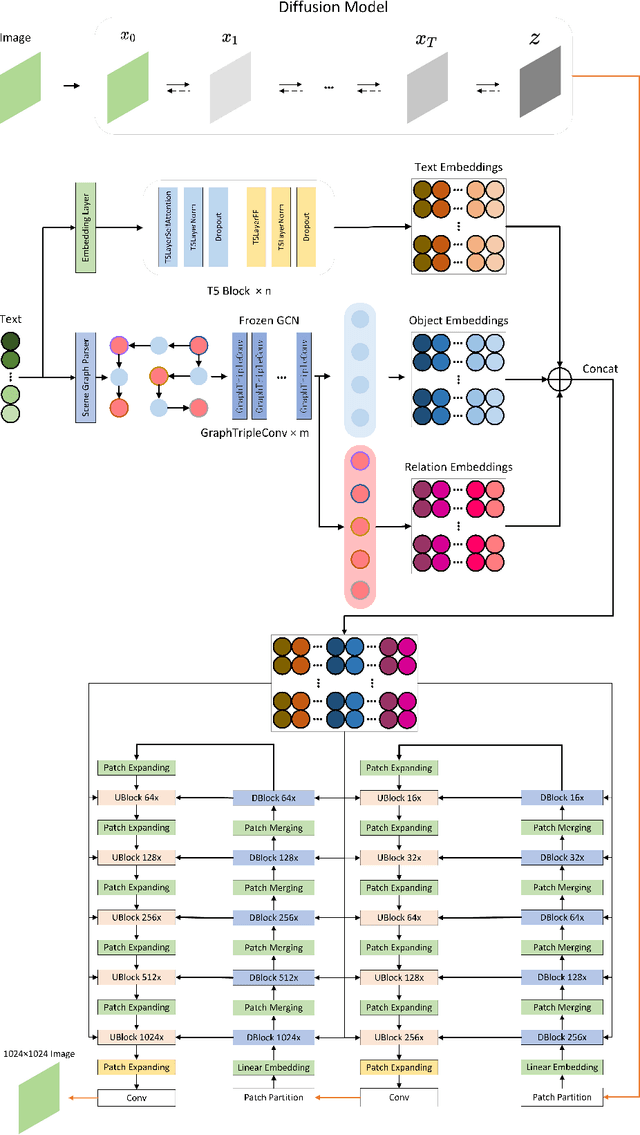
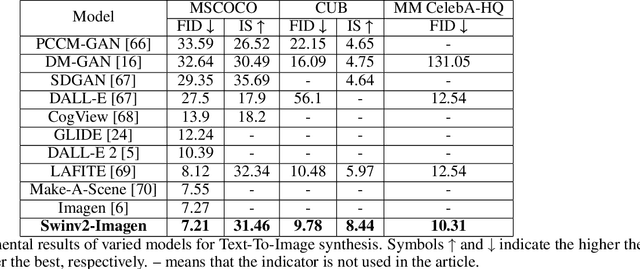
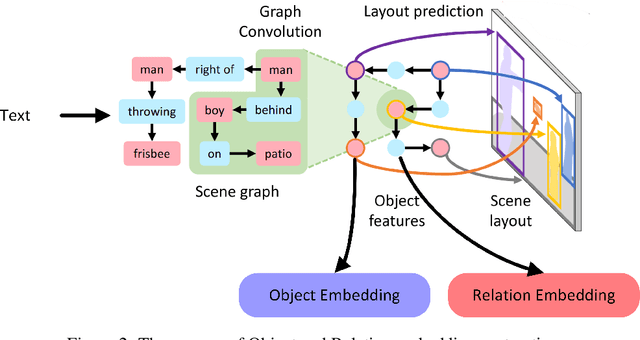

Recently, diffusion models have been proven to perform remarkably well in text-to-image synthesis tasks in a number of studies, immediately presenting new study opportunities for image generation. Google's Imagen follows this research trend and outperforms DALLE2 as the best model for text-to-image generation. However, Imagen merely uses a T5 language model for text processing, which cannot ensure learning the semantic information of the text. Furthermore, the Efficient UNet leveraged by Imagen is not the best choice in image processing. To address these issues, we propose the Swinv2-Imagen, a novel text-to-image diffusion model based on a Hierarchical Visual Transformer and a Scene Graph incorporating a semantic layout. In the proposed model, the feature vectors of entities and relationships are extracted and involved in the diffusion model, effectively improving the quality of generated images. On top of that, we also introduce a Swin-Transformer-based UNet architecture, called Swinv2-Unet, which can address the problems stemming from the CNN convolution operations. Extensive experiments are conducted to evaluate the performance of the proposed model by using three real-world datasets, i.e., MSCOCO, CUB and MM-CelebA-HQ. The experimental results show that the proposed Swinv2-Imagen model outperforms several popular state-of-the-art methods.
The Brain-Inspired Cooperative Shared Control for Brain-Machine Interface
Oct 18, 2022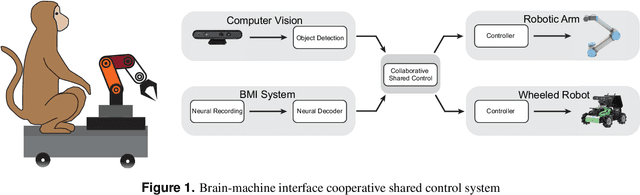
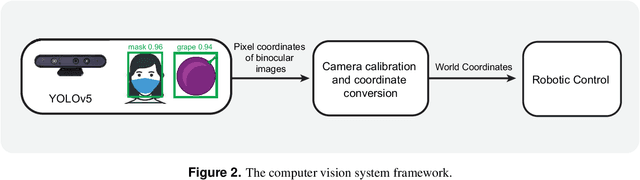
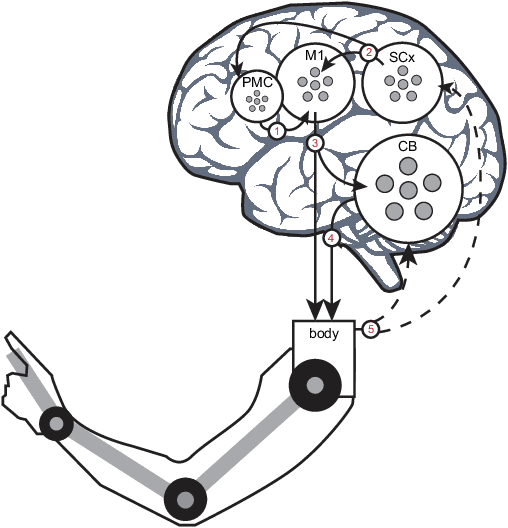
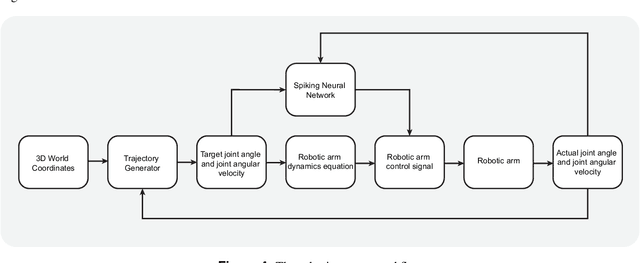
In the practical application of brain-machine interface technology, the problem often faced is the low information content and high noise of the neural signals collected by the electrode and the difficulty of decoding by the decoder, which makes it difficult for the robotic to obtain stable instructions to complete the task. The idea based on the principle of cooperative shared control can be achieved by extracting general motor commands from brain activity, while the fine details of the movement can be hosted to the robot for completion, or the brain can have complete control. This study proposes a brain-machine interface shared control system based on spiking neural networks for robotic arm movement control and wheeled robots wheel speed control and steering, respectively. The former can reliably control the robotic arm to move to the destination position, while the latter controls the wheeled robots for object tracking and map generation. The results show that the shared control based on brain-inspired intelligence can perform some typical tasks in complex environments and positively improve the fluency and ease of use of brain-machine interaction, and also demonstrate the potential of this control method in clinical applications of brain-machine interfaces.
Joint Multilingual Knowledge Graph Completion and Alignment
Oct 18, 2022
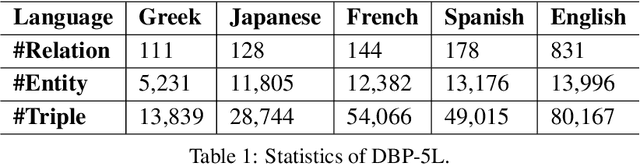
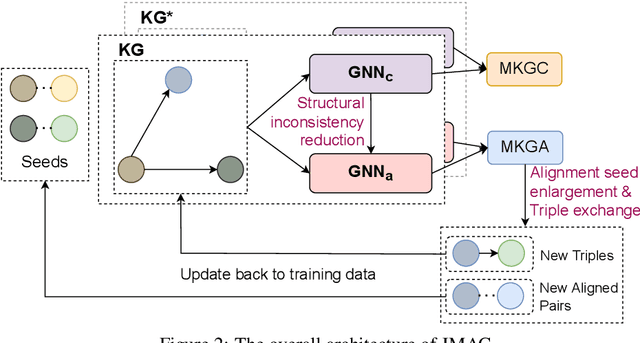
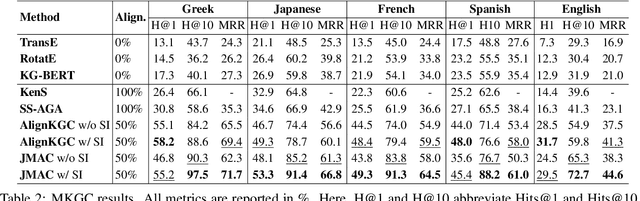
Knowledge graph (KG) alignment and completion are usually treated as two independent tasks. While recent work has leveraged entity and relation alignments from multiple KGs, such as alignments between multilingual KGs with common entities and relations, a deeper understanding of the ways in which multilingual KG completion (MKGC) can aid the creation of multilingual KG alignments (MKGA) is still limited. Motivated by the observation that structural inconsistencies -- the main challenge for MKGA models -- can be mitigated through KG completion methods, we propose a novel model for jointly completing and aligning knowledge graphs. The proposed model combines two components that jointly accomplish KG completion and alignment. These two components employ relation-aware graph neural networks that we propose to encode multi-hop neighborhood structures into entity and relation representations. Moreover, we also propose (i) a structural inconsistency reduction mechanism to incorporate information from the completion into the alignment component, and (ii) an alignment seed enlargement and triple transferring mechanism to enlarge alignment seeds and transfer triples during KGs alignment. Extensive experiments on a public multilingual benchmark show that our proposed model outperforms existing competitive baselines, obtaining new state-of-the-art results on both MKGC and MKGA tasks. We publicly release the implementation of our model at https://github.com/vinhsuhi/JMAC
DAGAD: Data Augmentation for Graph Anomaly Detection
Oct 18, 2022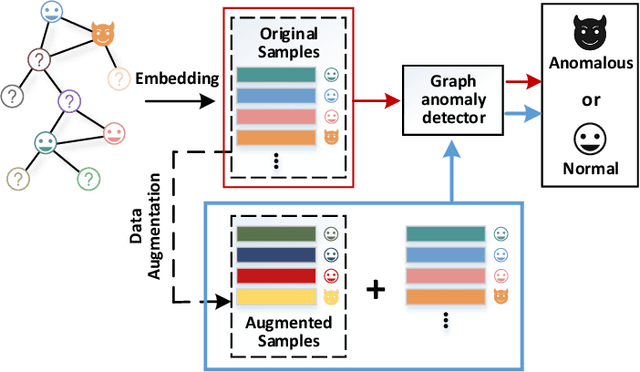
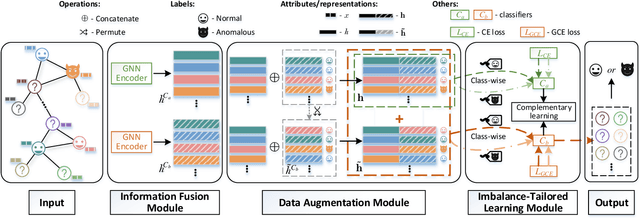
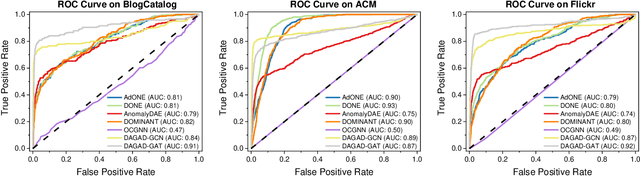
Graph anomaly detection in this paper aims to distinguish abnormal nodes that behave differently from the benign ones accounting for the majority of graph-structured instances. Receiving increasing attention from both academia and industry, yet existing research on this task still suffers from two critical issues when learning informative anomalous behavior from graph data. For one thing, anomalies are usually hard to capture because of their subtle abnormal behavior and the shortage of background knowledge about them, which causes severe anomalous sample scarcity. Meanwhile, the overwhelming majority of objects in real-world graphs are normal, bringing the class imbalance problem as well. To bridge the gaps, this paper devises a novel Data Augmentation-based Graph Anomaly Detection (DAGAD) framework for attributed graphs, equipped with three specially designed modules: 1) an information fusion module employing graph neural network encoders to learn representations, 2) a graph data augmentation module that fertilizes the training set with generated samples, and 3) an imbalance-tailored learning module to discriminate the distributions of the minority (anomalous) and majority (normal) classes. A series of experiments on three datasets prove that DAGAD outperforms ten state-of-the-art baseline detectors concerning various mostly-used metrics, together with an extensive ablation study validating the strength of our proposed modules.
Provably Sample-Efficient RL with Side Information about Latent Dynamics
May 27, 2022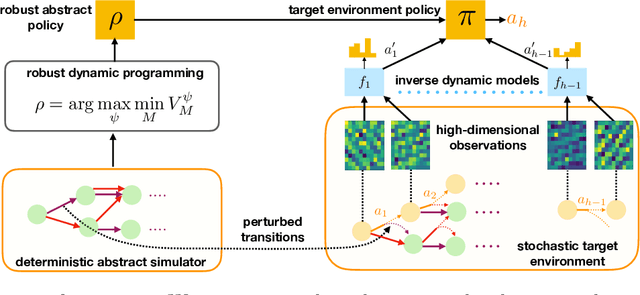
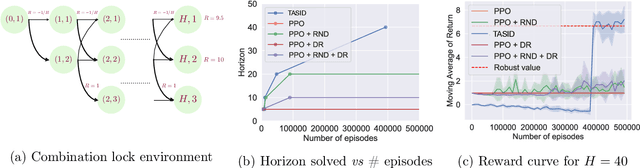

We study reinforcement learning (RL) in settings where observations are high-dimensional, but where an RL agent has access to abstract knowledge about the structure of the state space, as is the case, for example, when a robot is tasked to go to a specific room in a building using observations from its own camera, while having access to the floor plan. We formalize this setting as transfer reinforcement learning from an abstract simulator, which we assume is deterministic (such as a simple model of moving around the floor plan), but which is only required to capture the target domain's latent-state dynamics approximately up to unknown (bounded) perturbations (to account for environment stochasticity). Crucially, we assume no prior knowledge about the structure of observations in the target domain except that they can be used to identify the latent states (but the decoding map is unknown). Under these assumptions, we present an algorithm, called TASID, that learns a robust policy in the target domain, with sample complexity that is polynomial in the horizon, and independent of the number of states, which is not possible without access to some prior knowledge. In synthetic experiments, we verify various properties of our algorithm and show that it empirically outperforms transfer RL algorithms that require access to "full simulators" (i.e., those that also simulate observations).
Convergence of the mini-batch SIHT algorithm
Sep 29, 2022The Iterative Hard Thresholding (IHT) algorithm has been considered extensively as an effective deterministic algorithm for solving sparse optimizations. The IHT algorithm benefits from the information of the batch (full) gradient at each point and this information is a crucial key for the convergence analysis of the generated sequence. However, this strength becomes a weakness when it comes to machine learning and high dimensional statistical applications because calculating the batch gradient at each iteration is computationally expensive or impractical. Fortunately, in these applications the objective function has a summation structure that can be taken advantage of to approximate the batch gradient by the stochastic mini-batch gradient. In this paper, we study the mini-batch Stochastic IHT (SIHT) algorithm for solving the sparse optimizations. As opposed to previous works where increasing and variable mini-batch size is necessary for derivation, we fix the mini-batch size according to a lower bound that we derive and show our work. To prove stochastic convergence of the objective value function we first establish a critical sparse stochastic gradient descent property. Using this stochastic gradient descent property we show that the sequence generated by the stochastic mini-batch SIHT is a supermartingale sequence and converges with probability one. Unlike previous work we do not assume the function to be a restricted strongly convex. To the best of our knowledge, in the regime of sparse optimization, this is the first time in the literature that it is shown that the sequence of the stochastic function values converges with probability one by fixing the mini-batch size for all steps.