 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
THOR-Net: End-to-end Graformer-based Realistic Two Hands and Object Reconstruction with Self-supervision
Oct 25, 2022
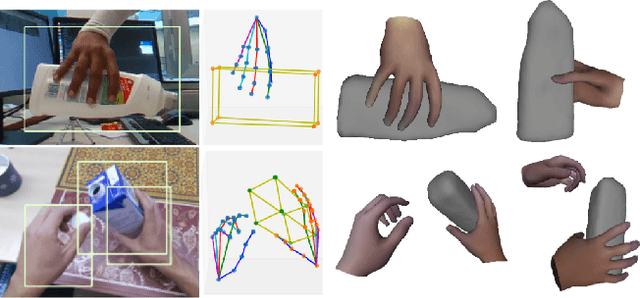
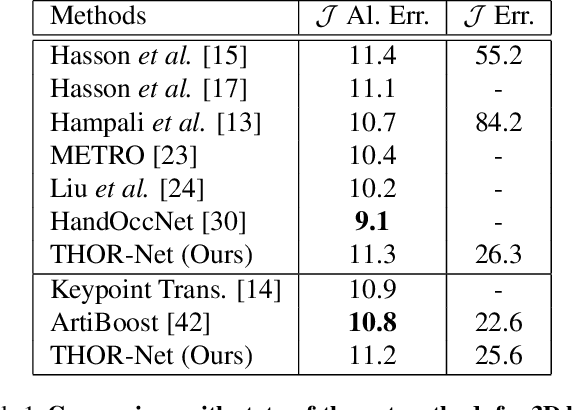
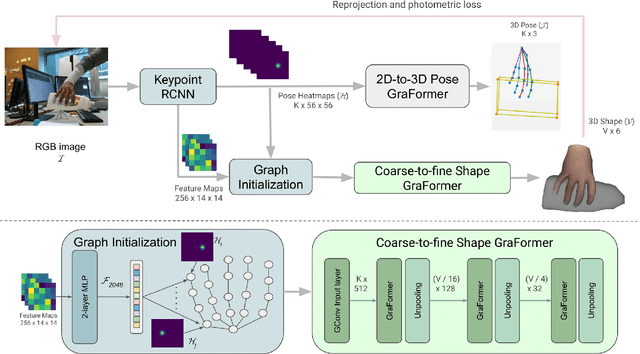
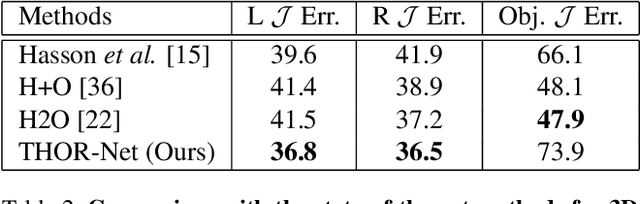
Realistic reconstruction of two hands interacting with objects is a new and challenging problem that is essential for building personalized Virtual and Augmented Reality environments. Graph Convolutional networks (GCNs) allow for the preservation of the topologies of hands poses and shapes by modeling them as a graph. In this work, we propose the THOR-Net which combines the power of GCNs, Transformer, and self-supervision to realistically reconstruct two hands and an object from a single RGB image. Our network comprises two stages; namely the features extraction stage and the reconstruction stage. In the features extraction stage, a Keypoint RCNN is used to extract 2D poses, features maps, heatmaps, and bounding boxes from a monocular RGB image. Thereafter, this 2D information is modeled as two graphs and passed to the two branches of the reconstruction stage. The shape reconstruction branch estimates meshes of two hands and an object using our novel coarse-to-fine GraFormer shape network. The 3D poses of the hands and objects are reconstructed by the other branch using a GraFormer network. Finally, a self-supervised photometric loss is used to directly regress the realistic textured of each vertex in the hands' meshes. Our approach achieves State-of-the-art results in Hand shape estimation on the HO-3D dataset (10.0mm) exceeding ArtiBoost (10.8mm). It also surpasses other methods in hand pose estimation on the challenging two hands and object (H2O) dataset by 5mm on the left-hand pose and 1 mm on the right-hand pose.
Pruning Adversarially Robust Neural Networks without Adversarial Examples
Oct 09, 2022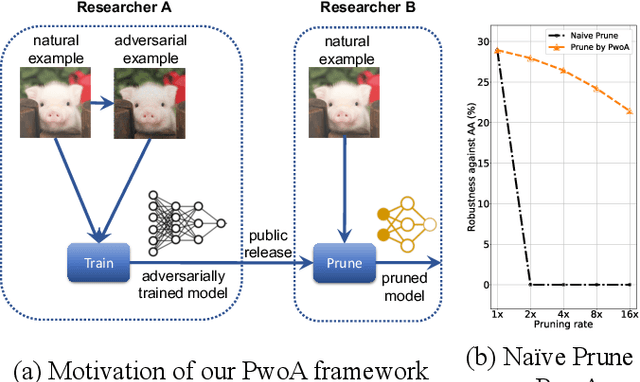
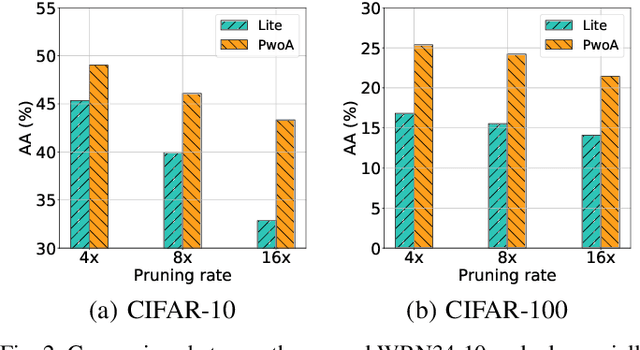
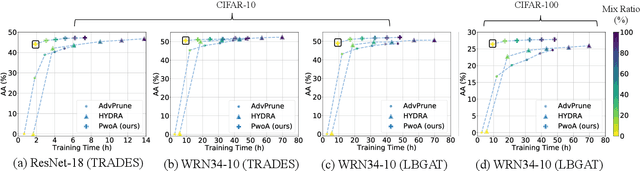
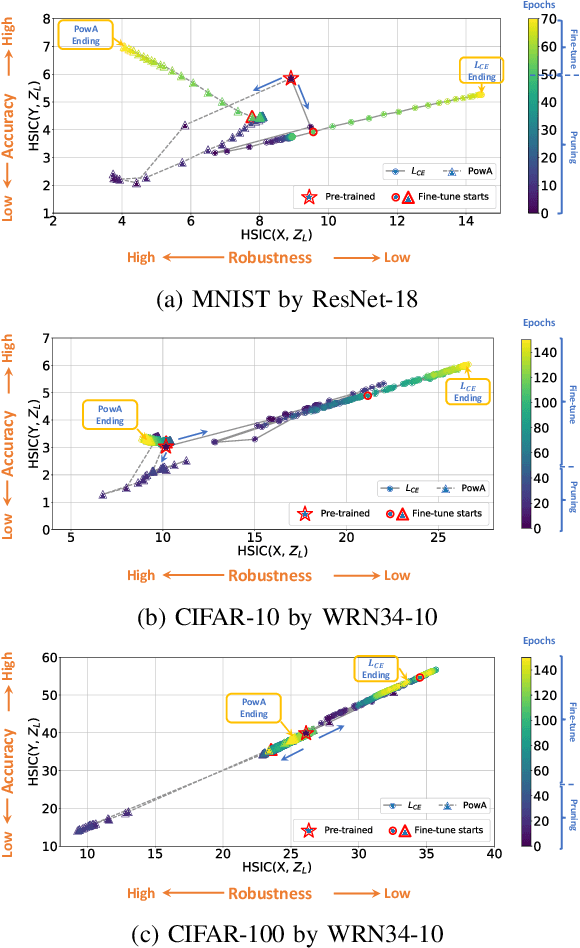
Adversarial pruning compresses models while preserving robustness. Current methods require access to adversarial examples during pruning. This significantly hampers training efficiency. Moreover, as new adversarial attacks and training methods develop at a rapid rate, adversarial pruning methods need to be modified accordingly to keep up. In this work, we propose a novel framework to prune a previously trained robust neural network while maintaining adversarial robustness, without further generating adversarial examples. We leverage concurrent self-distillation and pruning to preserve knowledge in the original model as well as regularizing the pruned model via the Hilbert-Schmidt Information Bottleneck. We comprehensively evaluate our proposed framework and show its superior performance in terms of both adversarial robustness and efficiency when pruning architectures trained on the MNIST, CIFAR-10, and CIFAR-100 datasets against five state-of-the-art attacks. Code is available at https://github.com/neu-spiral/PwoA/.
CAGroup3D: Class-Aware Grouping for 3D Object Detection on Point Clouds
Oct 09, 2022
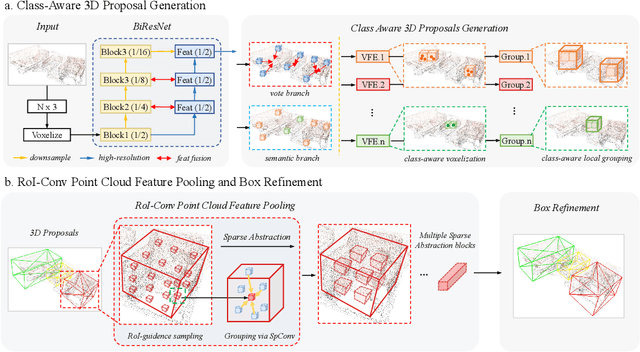

We present a novel two-stage fully sparse convolutional 3D object detection framework, named CAGroup3D. Our proposed method first generates some high-quality 3D proposals by leveraging the class-aware local group strategy on the object surface voxels with the same semantic predictions, which considers semantic consistency and diverse locality abandoned in previous bottom-up approaches. Then, to recover the features of missed voxels due to incorrect voxel-wise segmentation, we build a fully sparse convolutional RoI pooling module to directly aggregate fine-grained spatial information from backbone for further proposal refinement. It is memory-and-computation efficient and can better encode the geometry-specific features of each 3D proposal. Our model achieves state-of-the-art 3D detection performance with remarkable gains of +\textit{3.6\%} on ScanNet V2 and +\textit{2.6}\% on SUN RGB-D in term of mAP@0.25. Code will be available at https://github.com/Haiyang-W/CAGroup3D.
Low Light Video Enhancement by Learning on Static Videos with Cross-Frame Attention
Oct 09, 2022
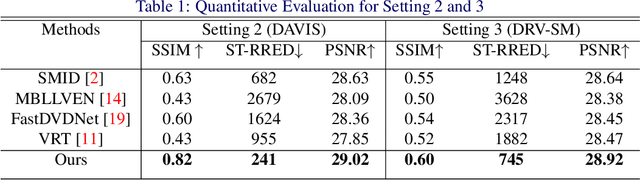
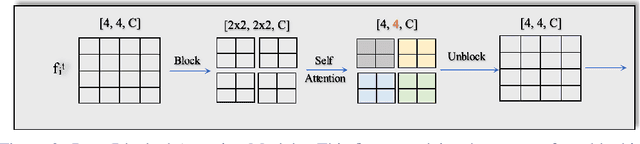
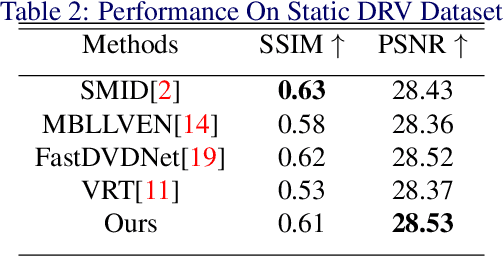
The design of deep learning methods for low light video enhancement remains a challenging problem owing to the difficulty in capturing low light and ground truth video pairs. This is particularly hard in the context of dynamic scenes or moving cameras where a long exposure ground truth cannot be captured. We approach this problem by training a model on static videos such that the model can generalize to dynamic videos. Existing methods adopting this approach operate frame by frame and do not exploit the relationships among neighbouring frames. We overcome this limitation through a selfcross dilated attention module that can effectively learn to use information from neighbouring frames even when dynamics between the frames are different during training and test times. We validate our approach through experiments on multiple datasets and show that our method outperforms other state-of-the-art video enhancement algorithms when trained only on static videos.
Batch Multi-Fidelity Active Learning with Budget Constraints
Oct 23, 2022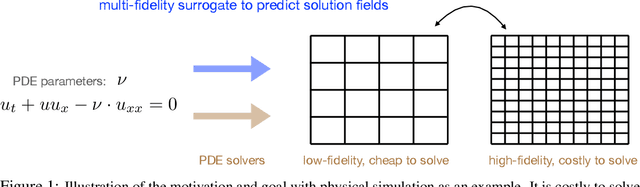
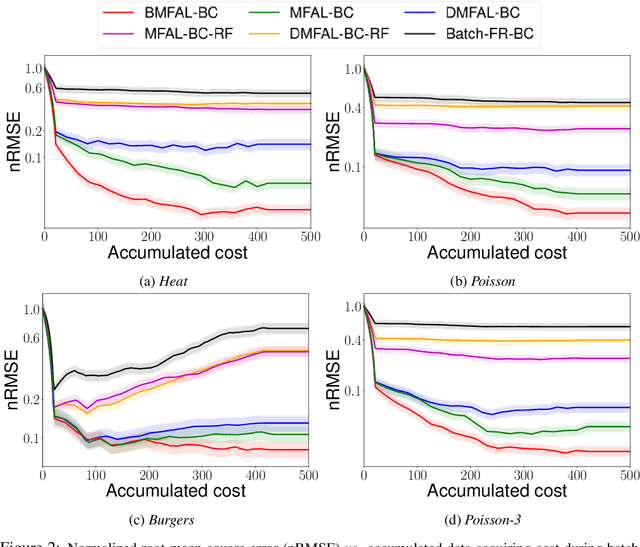
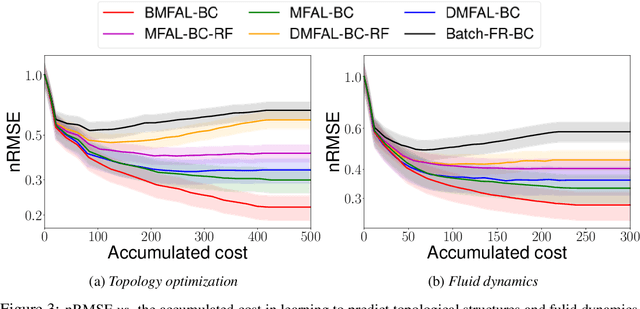
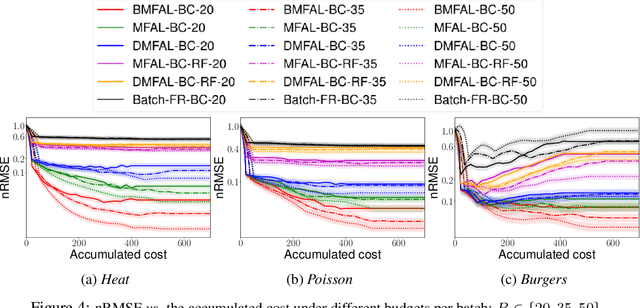
Learning functions with high-dimensional outputs is critical in many applications, such as physical simulation and engineering design. However, collecting training examples for these applications is often costly, e.g. by running numerical solvers. The recent work (Li et al., 2022) proposes the first multi-fidelity active learning approach for high-dimensional outputs, which can acquire examples at different fidelities to reduce the cost while improving the learning performance. However, this method only queries at one pair of fidelity and input at a time, and hence has a risk to bring in strongly correlated examples to reduce the learning efficiency. In this paper, we propose Batch Multi-Fidelity Active Learning with Budget Constraints (BMFAL-BC), which can promote the diversity of training examples to improve the benefit-cost ratio, while respecting a given budget constraint for batch queries. Hence, our method can be more practically useful. Specifically, we propose a novel batch acquisition function that measures the mutual information between a batch of multi-fidelity queries and the target function, so as to penalize highly correlated queries and encourages diversity. The optimization of the batch acquisition function is challenging in that it involves a combinatorial search over many fidelities while subject to the budget constraint. To address this challenge, we develop a weighted greedy algorithm that can sequentially identify each (fidelity, input) pair, while achieving a near $(1 - 1/e)$-approximation of the optimum. We show the advantage of our method in several computational physics and engineering applications.
Cloud Classification with Unsupervised Deep Learning
Sep 30, 2022
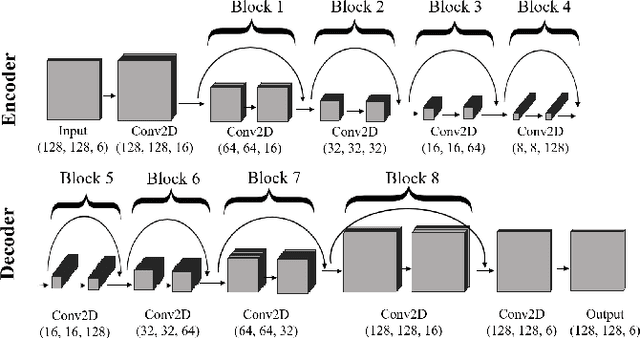
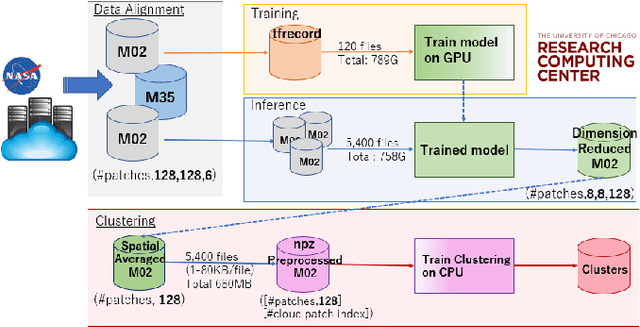
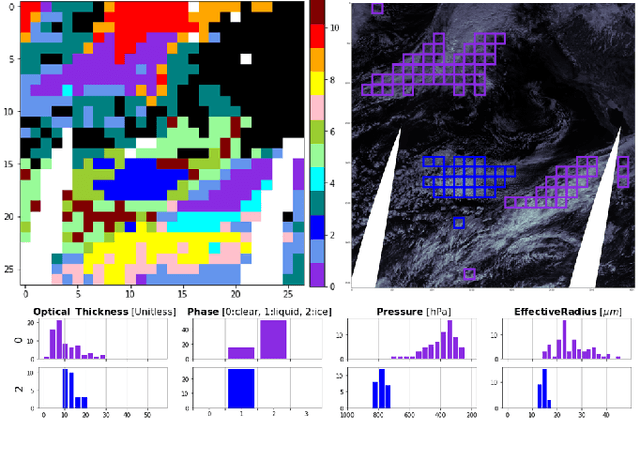
We present a framework for cloud characterization that leverages modern unsupervised deep learning technologies. While previous neural network-based cloud classification models have used supervised learning methods, unsupervised learning allows us to avoid restricting the model to artificial categories based on historical cloud classification schemes and enables the discovery of novel, more detailed classifications. Our framework learns cloud features directly from radiance data produced by NASA's Moderate Resolution Imaging Spectroradiometer (MODIS) satellite instrument, deriving cloud characteristics from millions of images without relying on pre-defined cloud types during the training process. We present preliminary results showing that our method extracts physically relevant information from radiance data and produces meaningful cloud classes.
Road Network Deterioration Monitoring Using Aerial Images and Computer Vision
Sep 30, 2022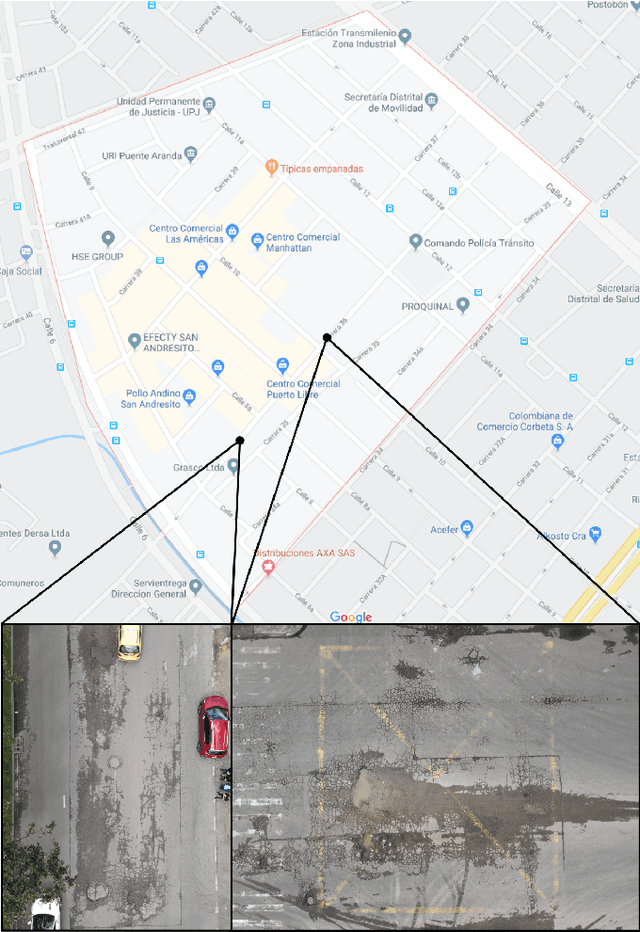


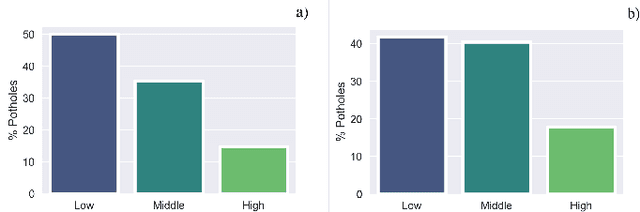
Road maintenance is an essential process for guaranteeing the quality of transportation in any city. A crucial step towards effective road maintenance is the ability to update the inventory of the road network. We present a proof of concept of a protocol for maintaining said inventory based on the use of unmanned aerial vehicles to quickly collect images which are processed by a computer vision program that automatically identifies potholes and their severity. Our protocol aims to provide information to local governments to prioritise the road network maintenance budget, and to be able to detect early stages of road deterioration so as to minimise maintenance expenditure.
Information Bottleneck Approach to Spatial Attention Learning
Aug 07, 2021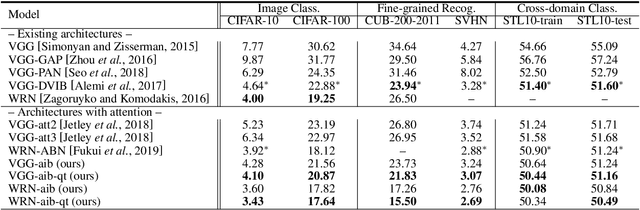

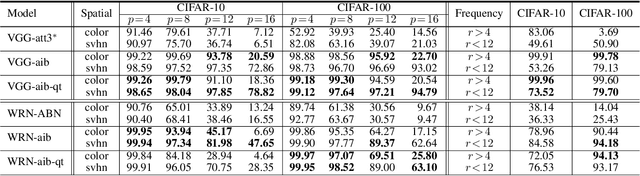
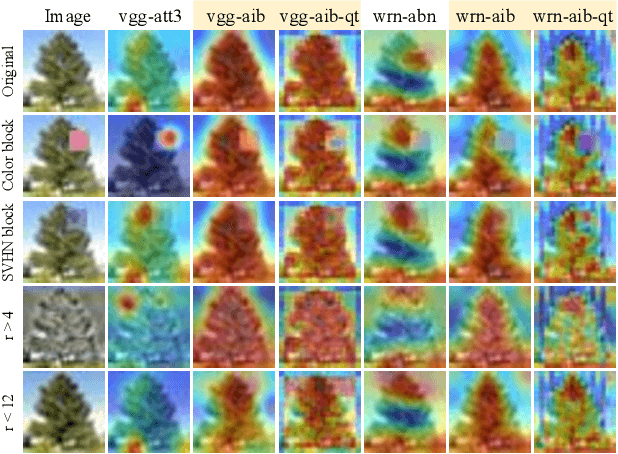
The selective visual attention mechanism in the human visual system (HVS) restricts the amount of information to reach visual awareness for perceiving natural scenes, allowing near real-time information processing with limited computational capacity [Koch and Ullman, 1987]. This kind of selectivity acts as an 'Information Bottleneck (IB)', which seeks a trade-off between information compression and predictive accuracy. However, such information constraints are rarely explored in the attention mechanism for deep neural networks (DNNs). In this paper, we propose an IB-inspired spatial attention module for DNN structures built for visual recognition. The module takes as input an intermediate representation of the input image, and outputs a variational 2D attention map that minimizes the mutual information (MI) between the attention-modulated representation and the input, while maximizing the MI between the attention-modulated representation and the task label. To further restrict the information bypassed by the attention map, we quantize the continuous attention scores to a set of learnable anchor values during training. Extensive experiments show that the proposed IB-inspired spatial attention mechanism can yield attention maps that neatly highlight the regions of interest while suppressing backgrounds, and bootstrap standard DNN structures for visual recognition tasks (e.g., image classification, fine-grained recognition, cross-domain classification). The attention maps are interpretable for the decision making of the DNNs as verified in the experiments. Our code is available at https://github.com/ashleylqx/AIB.git.
TODE-Trans: Transparent Object Depth Estimation with Transformer
Sep 18, 2022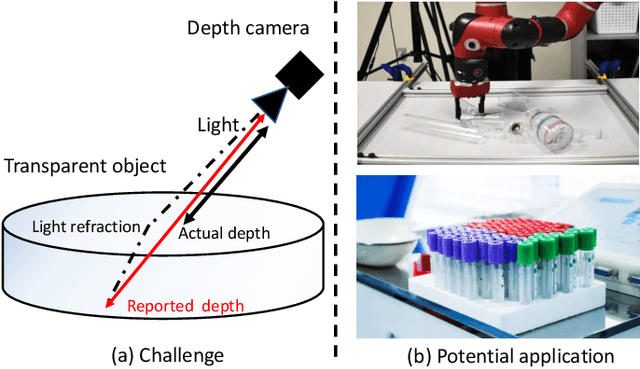
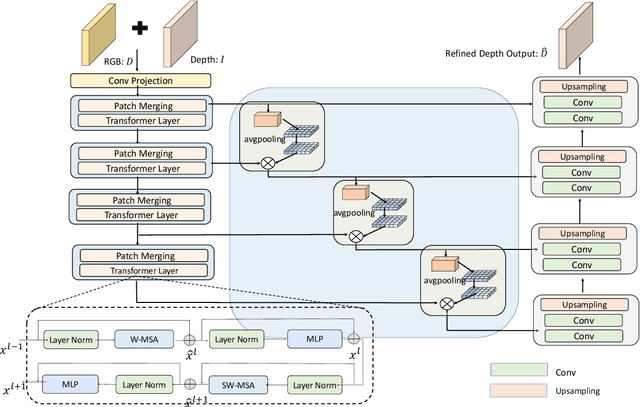


Transparent objects are widely used in industrial automation and daily life. However, robust visual recognition and perception of transparent objects have always been a major challenge. Currently, most commercial-grade depth cameras are still not good at sensing the surfaces of transparent objects due to the refraction and reflection of light. In this work, we present a transformer-based transparent object depth estimation approach from a single RGB-D input. We observe that the global characteristics of the transformer make it easier to extract contextual information to perform depth estimation of transparent areas. In addition, to better enhance the fine-grained features, a feature fusion module (FFM) is designed to assist coherent prediction. Our empirical evidence demonstrates that our model delivers significant improvements in recent popular datasets, e.g., 25% gain on RMSE and 21% gain on REL compared to previous state-of-the-art convolutional-based counterparts in ClearGrasp dataset. Extensive results show that our transformer-based model enables better aggregation of the object's RGB and inaccurate depth information to obtain a better depth representation. Our code and the pre-trained model will be available at https://github.com/yuchendoudou/TODE.
Shape Estimation of Continuum Robots via Modal Parameterization and Dual Extended Kalman Filter
Oct 16, 2022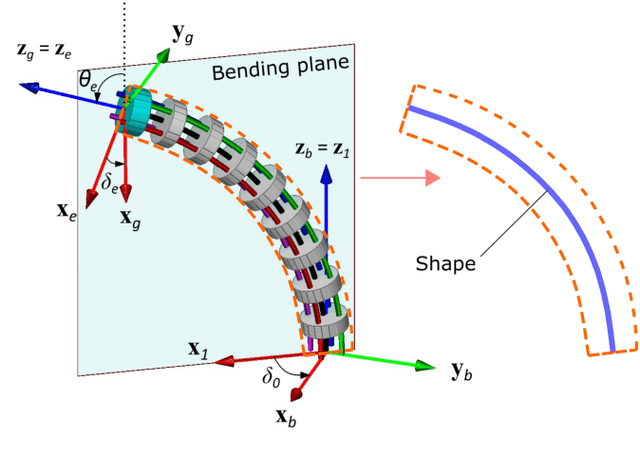
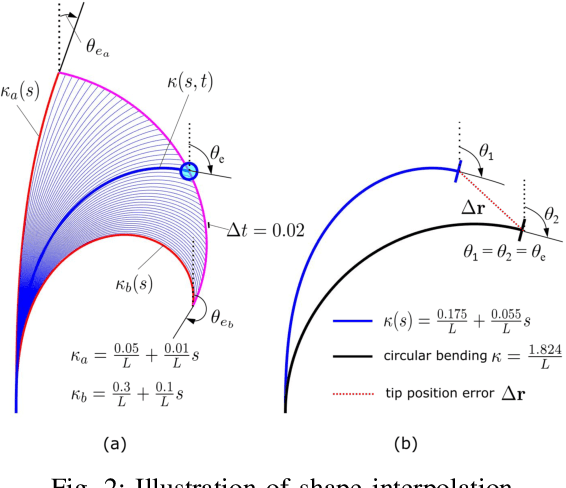
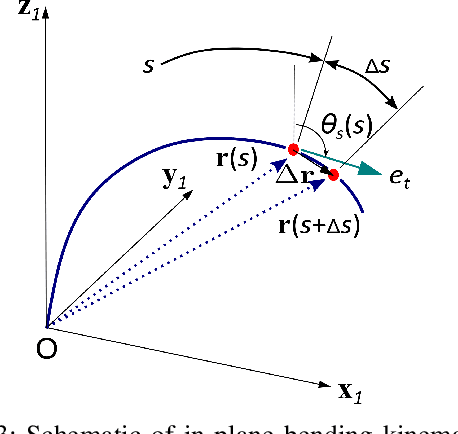
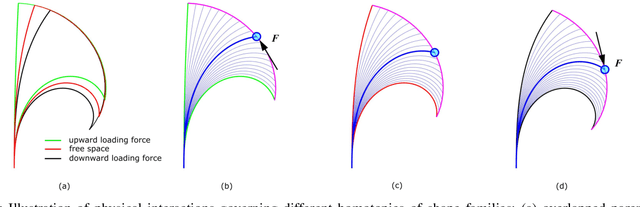
The equilibrium shape of a continuum robot is resulted from both its internal actuation and the external physical interaction with a surrounding environment. A fast and accurate shape estimation method (i) can be used as a feedback to compensate for more accurate motion; and (ii) can reveal rich information about physical interactions (e.g. instrument-anatomy contacts / forces during a surgery). From a prior work that demonstrated an offline calibration of continuum robots, we adopt its shape modal representation and error propagation models that include identification Jacobians. In this work, we present an iterative observer approach to enable online shape estimation. We develop a dual Extended Kalman Filter (EKF) to estimate both the robot state and the shape modal parameters. The dual EKF provides robust estimation on (i) the configuration space variables that are controllable and driven by internal actuation; and (ii) the modal coefficients representing homotopies of shape families that are governed by the physical interactions with the environment. We report results from simulation studies in this work, and plan to investigate methods in the future to use the proposed approach for predicting physical interactions.