 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation
Sep 18, 2022

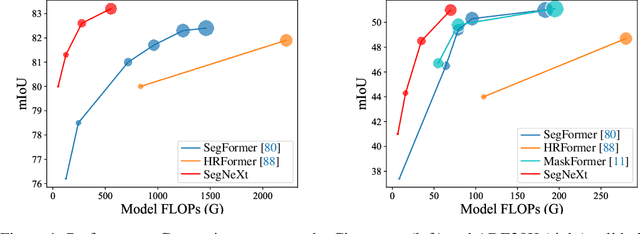
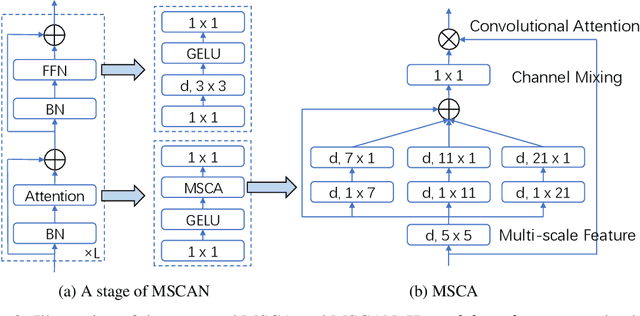
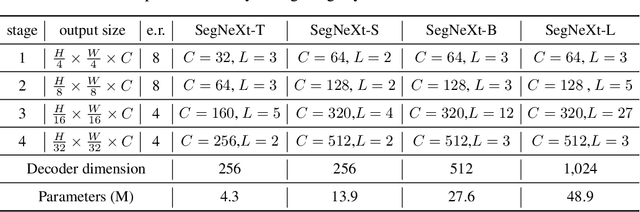
We present SegNeXt, a simple convolutional network architecture for semantic segmentation. Recent transformer-based models have dominated the field of semantic segmentation due to the efficiency of self-attention in encoding spatial information. In this paper, we show that convolutional attention is a more efficient and effective way to encode contextual information than the self-attention mechanism in transformers. By re-examining the characteristics owned by successful segmentation models, we discover several key components leading to the performance improvement of segmentation models. This motivates us to design a novel convolutional attention network that uses cheap convolutional operations. Without bells and whistles, our SegNeXt significantly improves the performance of previous state-of-the-art methods on popular benchmarks, including ADE20K, Cityscapes, COCO-Stuff, Pascal VOC, Pascal Context, and iSAID. Notably, SegNeXt outperforms EfficientNet-L2 w/ NAS-FPN and achieves 90.6% mIoU on the Pascal VOC 2012 test leaderboard using only 1/10 parameters of it. On average, SegNeXt achieves about 2.0% mIoU improvements compared to the state-of-the-art methods on the ADE20K datasets with the same or fewer computations. Code is available at https://github.com/uyzhang/JSeg (Jittor) and https://github.com/Visual-Attention-Network/SegNeXt (Pytorch).
CLAD: A Contrastive Learning based Approach for Background Debiasing
Oct 06, 2022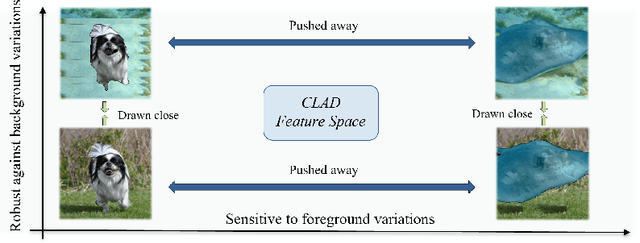


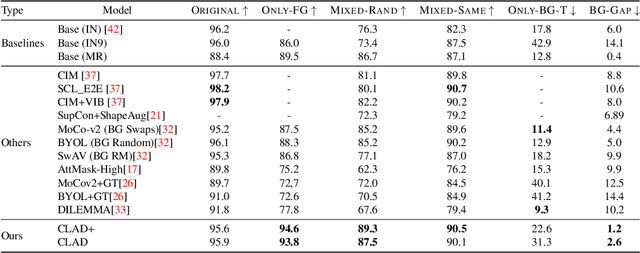
Convolutional neural networks (CNNs) have achieved superhuman performance in multiple vision tasks, especially image classification. However, unlike humans, CNNs leverage spurious features, such as background information to make decisions. This tendency creates different problems in terms of robustness or weak generalization performance. Through our work, we introduce a contrastive learning-based approach (CLAD) to mitigate the background bias in CNNs. CLAD encourages semantic focus on object foregrounds and penalizes learning features from irrelavant backgrounds. Our method also introduces an efficient way of sampling negative samples. We achieve state-of-the-art results on the Background Challenge dataset, outperforming the previous benchmark with a margin of 4.1\%. Our paper shows how CLAD serves as a proof of concept for debiasing of spurious features, such as background and texture (in supplementary material).
Bending the Future: Autoregressive Modeling of Temporal Knowledge Graphs in Curvature-Variable Hyperbolic Spaces
Sep 12, 2022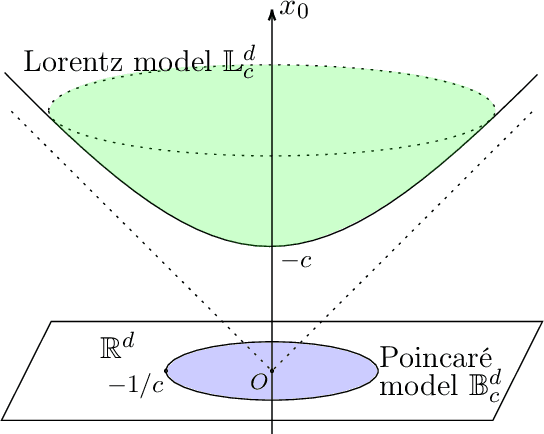
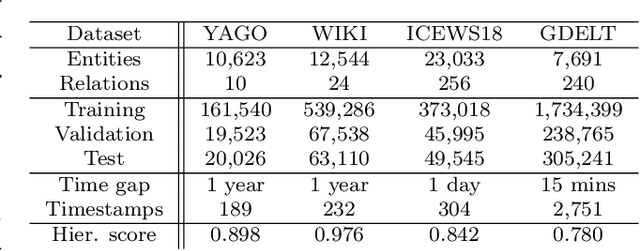
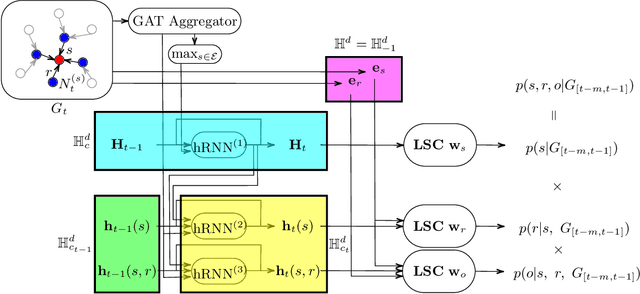
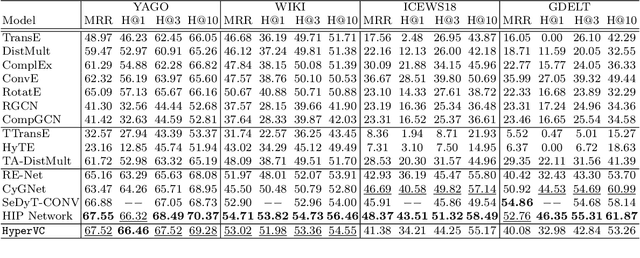
Recently there is an increasing scholarly interest in time-varying knowledge graphs, or temporal knowledge graphs (TKG). Previous research suggests diverse approaches to TKG reasoning that uses historical information. However, less attention has been given to the hierarchies within such information at different timestamps. Given that TKG is a sequence of knowledge graphs based on time, the chronology in the sequence derives hierarchies between the graphs. Furthermore, each knowledge graph has its hierarchical level which may differ from one another. To address these hierarchical characteristics in TKG, we propose HyperVC, which utilizes hyperbolic space that better encodes the hierarchies than Euclidean space. The chronological hierarchies between knowledge graphs at different timestamps are represented by embedding the knowledge graphs as vectors in a common hyperbolic space. Additionally, diverse hierarchical levels of knowledge graphs are represented by adjusting the curvatures of hyperbolic embeddings of their entities and relations. Experiments on four benchmark datasets show substantial improvements, especially on the datasets with higher hierarchical levels.
Layer-wise Shared Attention Network on Dynamical System Perspective
Oct 27, 2022

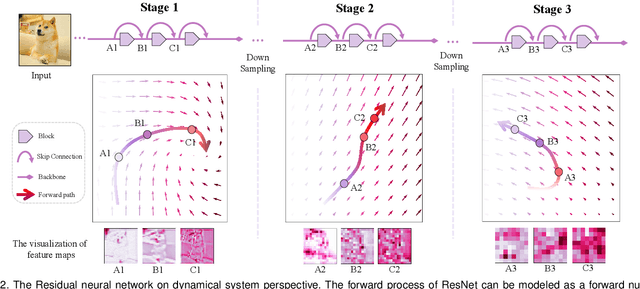

Attention networks have successfully boosted accuracy in various vision problems. Previous works lay emphasis on designing a new self-attention module and follow the traditional paradigm that individually plugs the modules into each layer of a network. However, such a paradigm inevitably increases the extra parameter cost with the growth of the number of layers. From the dynamical system perspective of the residual neural network, we find that the feature maps from the layers of the same stage are homogenous, which inspires us to propose a novel-and-simple framework, called the dense and implicit attention (DIA) unit, that shares a single attention module throughout different network layers. With our framework, the parameter cost is independent of the number of layers and we further improve the accuracy of existing popular self-attention modules with significant parameter reduction without any elaborated model crafting. Extensive experiments on benchmark datasets show that the DIA is capable of emphasizing layer-wise feature interrelation and thus leads to significant improvement in various vision tasks, including image classification, object detection, and medical application. Furthermore, the effectiveness of the DIA unit is demonstrated by novel experiments where we destabilize the model training by (1) removing the skip connection of the residual neural network, (2) removing the batch normalization of the model, and (3) removing all data augmentation during training. In these cases, we verify that DIA has a strong regularization ability to stabilize the training, i.e., the dense and implicit connections formed by our method can effectively recover and enhance the information communication across layers and the value of the gradient thus alleviate the training instability.
ViT-CAT: Parallel Vision Transformers with Cross Attention Fusion for Popularity Prediction in MEC Networks
Oct 27, 2022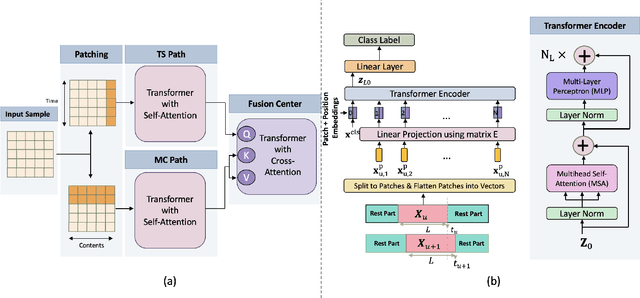
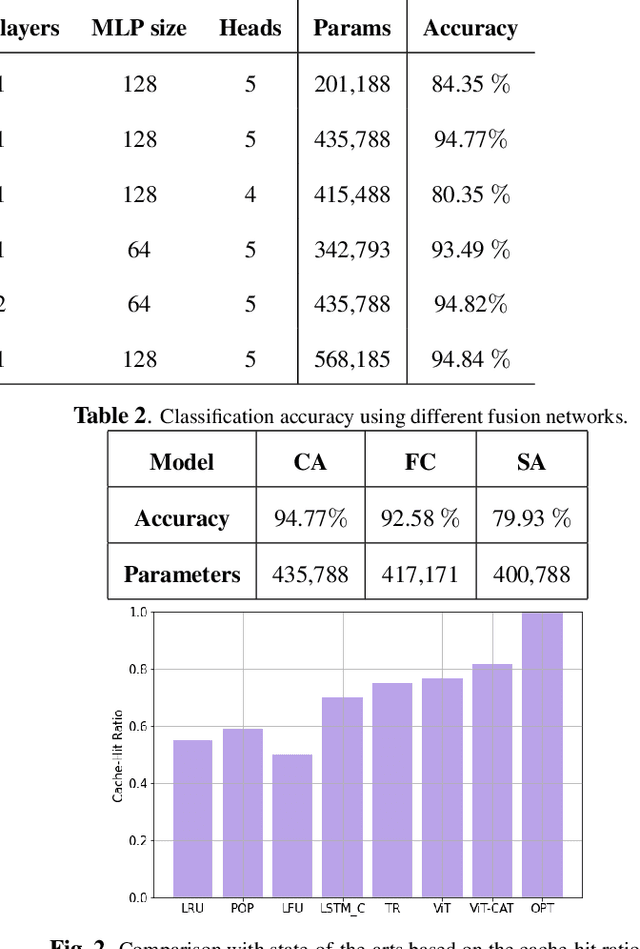
Mobile Edge Caching (MEC) is a revolutionary technology for the Sixth Generation (6G) of wireless networks with the promise to significantly reduce users' latency via offering storage capacities at the edge of the network. The efficiency of the MEC network, however, critically depends on its ability to dynamically predict/update the storage of caching nodes with the top-K popular contents. Conventional statistical caching schemes are not robust to the time-variant nature of the underlying pattern of content requests, resulting in a surge of interest in using Deep Neural Networks (DNNs) for time-series popularity prediction in MEC networks. However, existing DNN models within the context of MEC fail to simultaneously capture both temporal correlations of historical request patterns and the dependencies between multiple contents. This necessitates an urgent quest to develop and design a new and innovative popularity prediction architecture to tackle this critical challenge. The paper addresses this gap by proposing a novel hybrid caching framework based on the attention mechanism. Referred to as the parallel Vision Transformers with Cross Attention (ViT-CAT) Fusion, the proposed architecture consists of two parallel ViT networks, one for collecting temporal correlation, and the other for capturing dependencies between different contents. Followed by a Cross Attention (CA) module as the Fusion Center (FC), the proposed ViT-CAT is capable of learning the mutual information between temporal and spatial correlations, as well, resulting in improving the classification accuracy, and decreasing the model's complexity about 8 times. Based on the simulation results, the proposed ViT-CAT architecture outperforms its counterparts across the classification accuracy, complexity, and cache-hit ratio.
MMFL-Net: Multi-scale and Multi-granularity Feature Learning for Cross-domain Fashion Retrieval
Oct 27, 2022Instance-level image retrieval in fashion is a challenging issue owing to its increasing importance in real-scenario visual fashion search. Cross-domain fashion retrieval aims to match the unconstrained customer images as queries for photographs provided by retailers; however, it is a difficult task due to a wide range of consumer-to-shop (C2S) domain discrepancies and also considering that clothing image is vulnerable to various non-rigid deformations. To this end, we propose a novel multi-scale and multi-granularity feature learning network (MMFL-Net), which can jointly learn global-local aggregation feature representations of clothing images in a unified framework, aiming to train a cross-domain model for C2S fashion visual similarity. First, a new semantic-spatial feature fusion part is designed to bridge the semantic-spatial gap by applying top-down and bottom-up bidirectional multi-scale feature fusion. Next, a multi-branch deep network architecture is introduced to capture global salient, part-informed, and local detailed information, and extracting robust and discrimination feature embedding by integrating the similarity learning of coarse-to-fine embedding with the multiple granularities. Finally, the improved trihard loss, center loss, and multi-task classification loss are adopted for our MMFL-Net, which can jointly optimize intra-class and inter-class distance and thus explicitly improve intra-class compactness and inter-class discriminability between its visual representations for feature learning. Furthermore, our proposed model also combines the multi-task attribute recognition and classification module with multi-label semantic attributes and product ID labels. Experimental results demonstrate that our proposed MMFL-Net achieves significant improvement over the state-of-the-art methods on the two datasets, DeepFashion-C2S and Street2Shop.
* 27 pages, 12 figures, Published by <Multimedia Tools and Applications>
Towards Complex Backgrounds: A Unified Difference-Aware Decoder for Binary Segmentation
Oct 27, 2022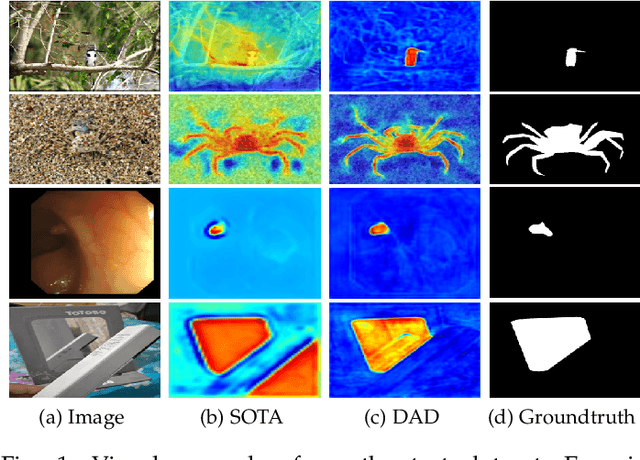
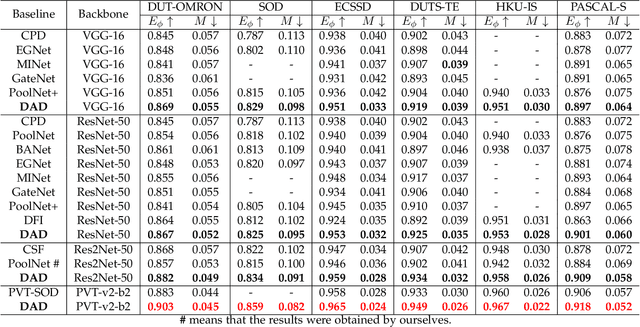
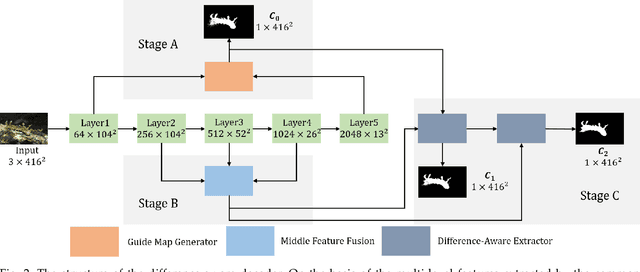
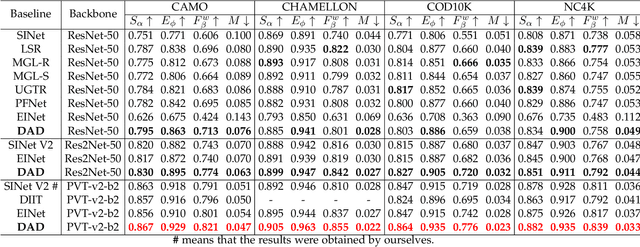
Binary segmentation is used to distinguish objects of interest from background, and is an active area of convolutional encoder-decoder network research. The current decoders are designed for specific objects based on the common backbones as the encoders, but cannot deal with complex backgrounds. Inspired by the way human eyes detect objects of interest, a new unified dual-branch decoder paradigm named the difference-aware decoder is proposed in this paper to explore the difference between the foreground and the background and separate the objects of interest in optical images. The difference-aware decoder imitates the human eye in three stages using the multi-level features output by the encoder. In Stage A, the first branch decoder of the difference-aware decoder is used to obtain a guide map. The highest-level features are enhanced with a novel field expansion module and a dual residual attention module, and are combined with the lowest-level features to obtain the guide map. In Stage B, the other branch decoder adopts a middle feature fusion module to make trade-offs between textural details and semantic information and generate background-aware features. In Stage C, the proposed difference-aware extractor, consisting of a difference guidance model and a difference enhancement module, fuses the guide map from Stage A and the background-aware features from Stage B, to enlarge the differences between the foreground and the background and output a final detection result. The results demonstrate that the difference-aware decoder can achieve a higher accuracy than the other state-of-the-art binary segmentation methods for these tasks.
SelfNeRF: Fast Training NeRF for Human from Monocular Self-rotating Video
Oct 04, 2022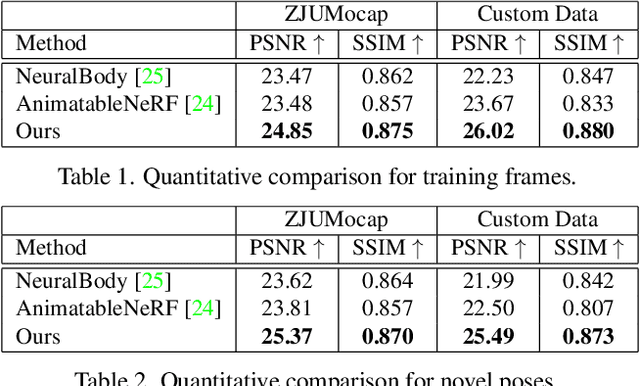
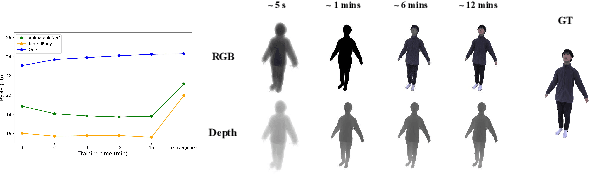
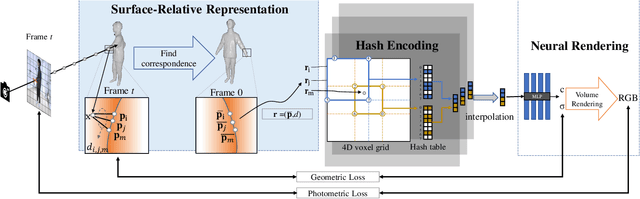
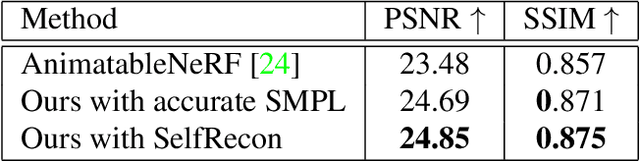
In this paper, we propose SelfNeRF, an efficient neural radiance field based novel view synthesis method for human performance. Given monocular self-rotating videos of human performers, SelfNeRF can train from scratch and achieve high-fidelity results in about twenty minutes. Some recent works have utilized the neural radiance field for dynamic human reconstruction. However, most of these methods need multi-view inputs and require hours of training, making it still difficult for practical use. To address this challenging problem, we introduce a surface-relative representation based on multi-resolution hash encoding that can greatly improve the training speed and aggregate inter-frame information. Extensive experimental results on several different datasets demonstrate the effectiveness and efficiency of SelfNeRF to challenging monocular videos.
New Machine Learning Techniques for Simulation-Based Inference: InferoStatic Nets, Kernel Score Estimation, and Kernel Likelihood Ratio Estimation
Oct 04, 2022
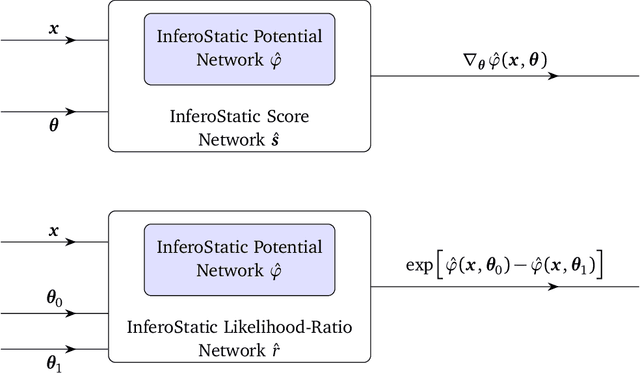
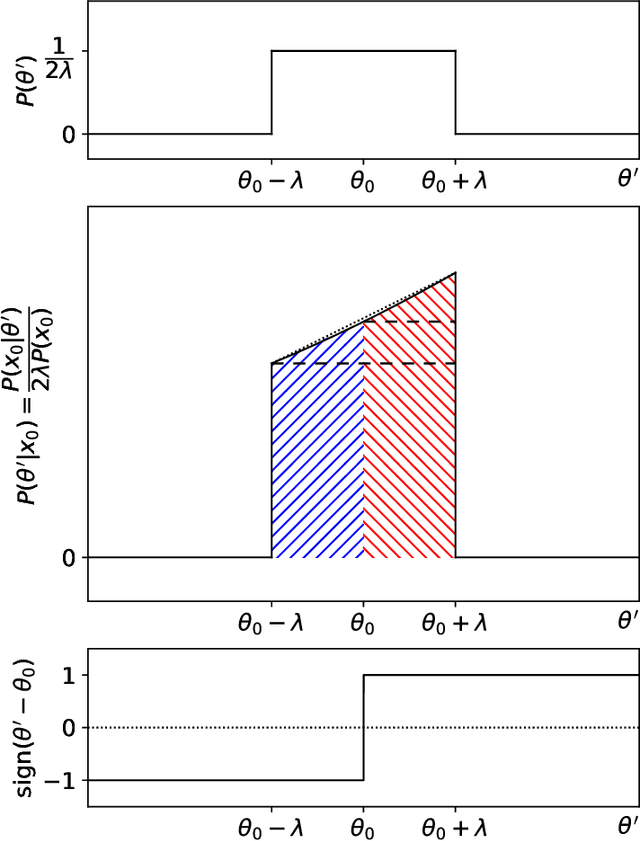
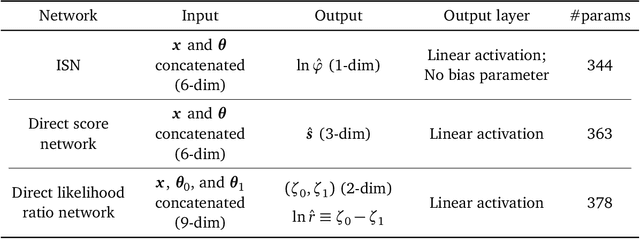
We propose an intuitive, machine-learning approach to multiparameter inference, dubbed the InferoStatic Networks (ISN) method, to model the score and likelihood ratio estimators in cases when the probability density can be sampled but not computed directly. The ISN uses a backend neural network that models a scalar function called the inferostatic potential $\varphi$. In addition, we introduce new strategies, respectively called Kernel Score Estimation (KSE) and Kernel Likelihood Ratio Estimation (KLRE), to learn the score and the likelihood ratio functions from simulated data. We illustrate the new techniques with some toy examples and compare to existing approaches in the literature. We mention en passant some new loss functions that optimally incorporate latent information from simulations into the training procedure.
Benign Autoencoders
Oct 04, 2022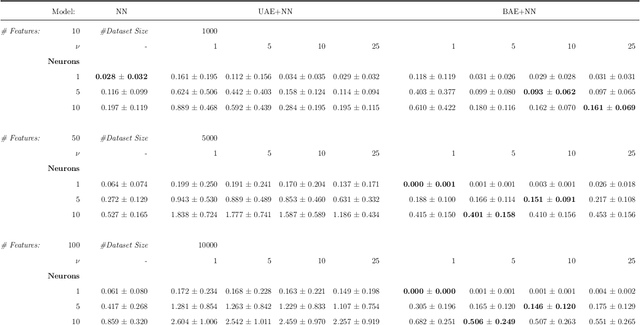
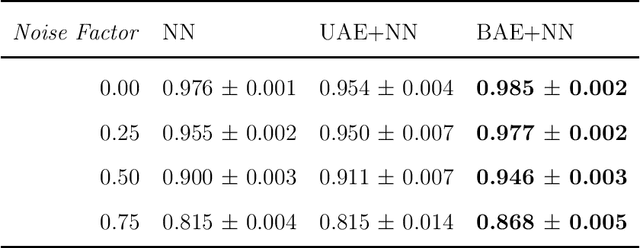
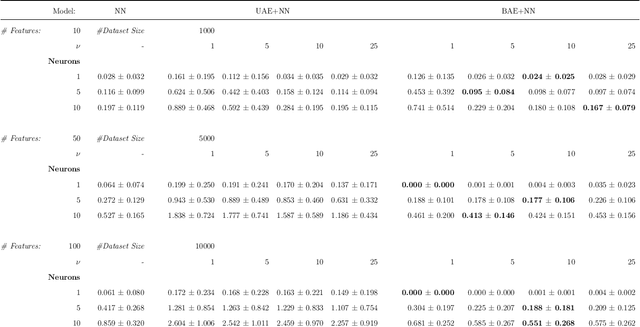
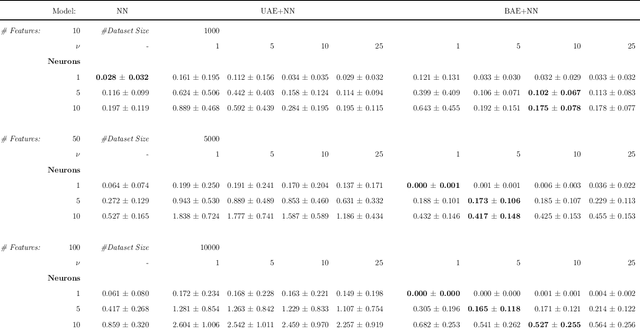
The success of modern machine learning algorithms depends crucially on efficient data representation and compression through dimensionality reduction. This practice seemingly contradicts the conventional intuition suggesting that data processing always leads to information loss. We prove that this intuition is wrong. For any non-convex problem, there exists an optimal, benign auto-encoder (BAE) extracting a lower-dimensional data representation that is strictly beneficial: Compressing model inputs improves model performance. We prove that BAE projects data onto a manifold whose dimension is the compressibility dimension of the learning model. We develop and implement an efficient algorithm for computing BAE and show that BAE improves model performance in every dataset we consider. Furthermore, by compressing "malignant" data dimensions, BAE makes learning more stable and robust.