 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Geometry Aligned Variational Transformer for Image-conditioned Layout Generation
Sep 02, 2022
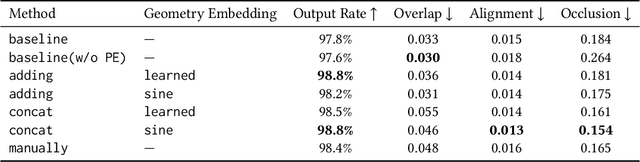
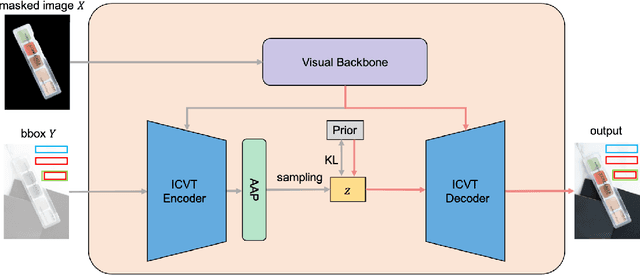

Layout generation is a novel task in computer vision, which combines the challenges in both object localization and aesthetic appraisal, widely used in advertisements, posters, and slides design. An accurate and pleasant layout should consider both the intra-domain relationship within layout elements and the inter-domain relationship between layout elements and the image. However, most previous methods simply focus on image-content-agnostic layout generation, without leveraging the complex visual information from the image. To this end, we explore a novel paradigm entitled image-conditioned layout generation, which aims to add text overlays to an image in a semantically coherent manner. Specifically, we propose an Image-Conditioned Variational Transformer (ICVT) that autoregressively generates various layouts in an image. First, self-attention mechanism is adopted to model the contextual relationship within layout elements, while cross-attention mechanism is used to fuse the visual information of conditional images. Subsequently, we take them as building blocks of conditional variational autoencoder (CVAE), which demonstrates appealing diversity. Second, in order to alleviate the gap between layout elements domain and visual domain, we design a Geometry Alignment module, in which the geometric information of the image is aligned with the layout representation. In addition, we construct a large-scale advertisement poster layout designing dataset with delicate layout and saliency map annotations. Experimental results show that our model can adaptively generate layouts in the non-intrusive area of the image, resulting in a harmonious layout design.
Tag-Aware Document Representation for Research Paper Recommendation
Sep 08, 2022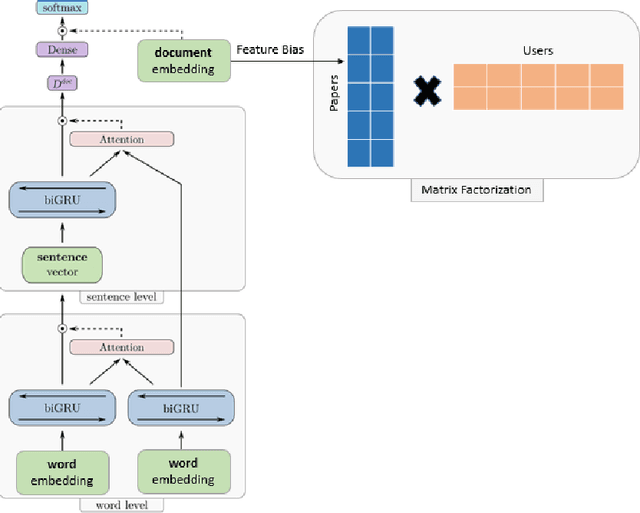

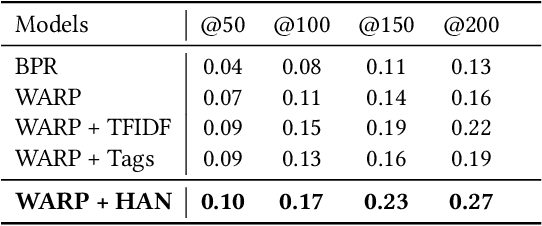
Finding online research papers relevant to one's interests is very challenging due to the increasing number of publications. Therefore, personalized research paper recommendation has become a significant and timely research topic. Collaborative filtering is a successful recommendation approach, which exploits the ratings given to items by users as a source of information for learning to make accurate recommendations. However, the ratings are often very sparse as in the research paper domain, due to the huge number of publications growing every year. Therefore, more attention has been drawn to hybrid methods that consider both ratings and content information. Nevertheless, most of the hybrid recommendation approaches that are based on text embedding have utilized bag-of-words techniques, which ignore word order and semantic meaning. In this paper, we propose a hybrid approach that leverages deep semantic representation of research papers based on social tags assigned by users. The experimental evaluation is performed on CiteULike, a real and publicly available dataset. The obtained findings show that the proposed model is effective in recommending research papers even when the rating data is very sparse.
Invariant Representations with Stochastically Quantized Neural Networks
Aug 04, 2022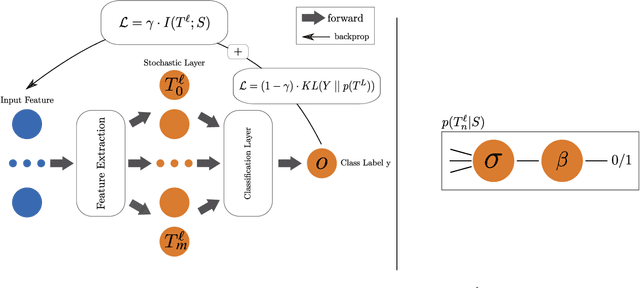
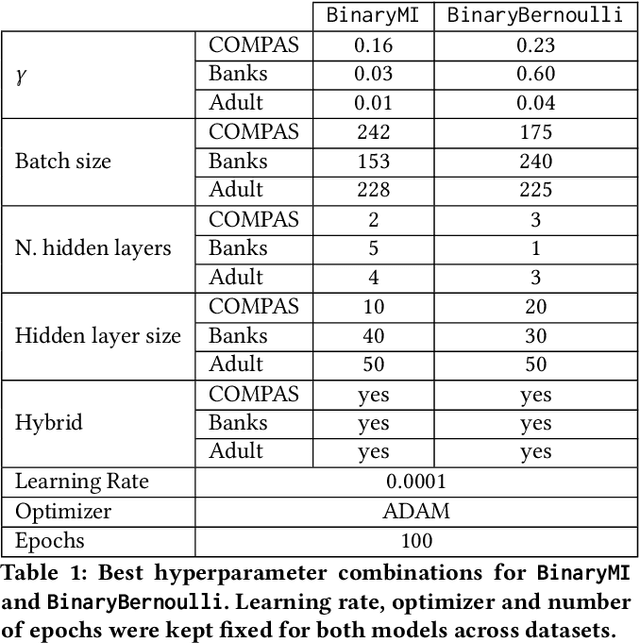
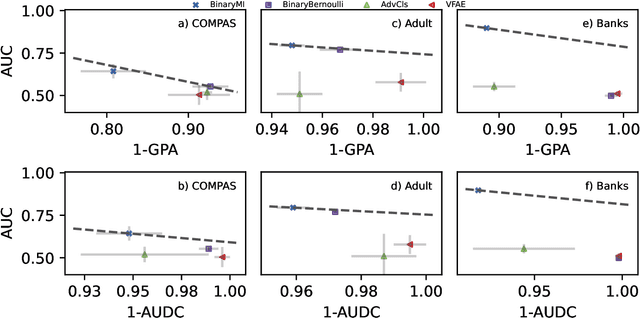

Representation learning algorithms offer the opportunity to learn invariant representations of the input data with regard to nuisance factors. Many authors have leveraged such strategies to learn fair representations, i.e., vectors where information about sensitive attributes is removed. These methods are attractive as they may be interpreted as minimizing the mutual information between a neural layer's activations and a sensitive attribute. However, the theoretical grounding of such methods relies either on the computation of infinitely accurate adversaries or on minimizing a variational upper bound of a mutual information estimate. In this paper, we propose a methodology for direct computation of the mutual information between a neural layer and a sensitive attribute. We employ stochastically-activated binary neural networks, which lets us treat neurons as random variables. We are then able to compute (not bound) the mutual information between a layer and a sensitive attribute and use this information as a regularization factor during gradient descent. We show that this method compares favorably with the state of the art in fair representation learning and that the learned representations display a higher level of invariance compared to full-precision neural networks.
Modelling Business Agreements in the Multimodal Transportation Domain through Ontological Smart Contracts
Sep 05, 2022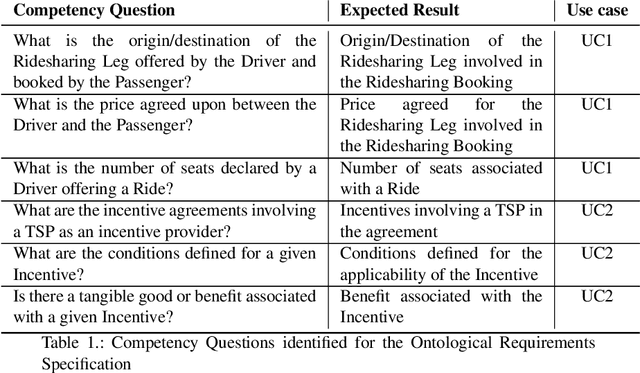
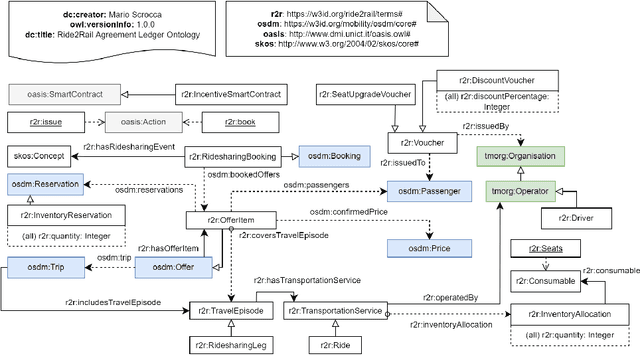
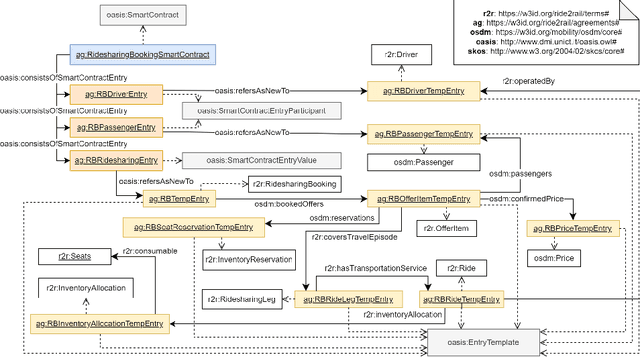
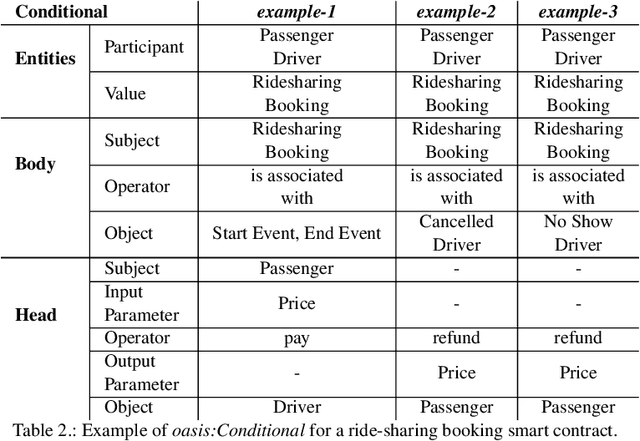
The blockchain technology provides integrity and reliability of the information, thus offering a suitable solution to guarantee trustability in a multi-stakeholder scenario that involves actors defining business agreements. The Ride2Rail project investigated the use of the blockchain to record as smart contracts the agreements between different stakeholders defined in a multimodal transportation domain. Modelling an ontology to represent the smart contracts enables the possibility of having a machine-readable and interoperable representation of the agreements. On one hand, the underlying blockchain ensures trust in the execution of the contracts, on the other hand, their ontological representation facilitates the retrieval of information within the ecosystem. The paper describes the development of the Ride2Rail Ontology for Agreements to showcase how the concept of an ontological smart contract, defined in the OASIS ontology, can be applied to a specific domain. The usage of the designed ontology is discussed by describing the modelling as ontological smart contracts of business agreements defined in a ride-sharing scenario.
Predicting emotion from music videos: exploring the relative contribution of visual and auditory information to affective responses
Feb 19, 2022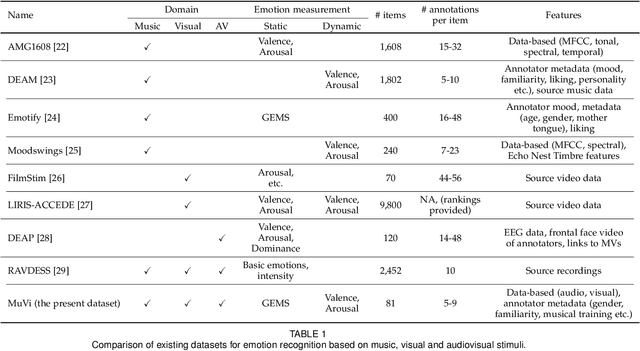

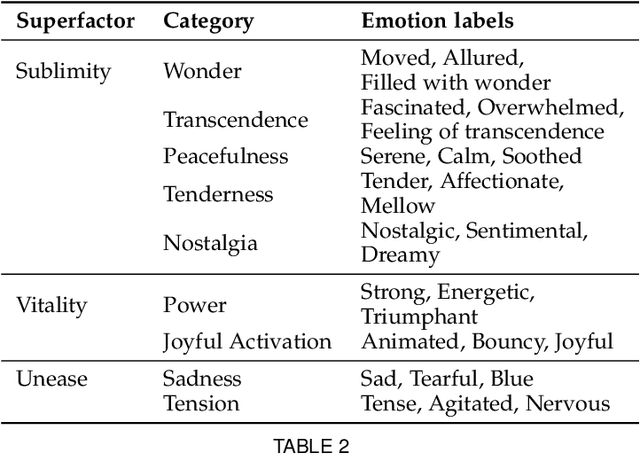
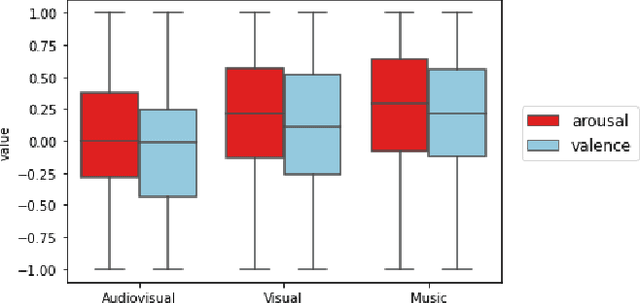
Although media content is increasingly produced, distributed, and consumed in multiple combinations of modalities, how individual modalities contribute to the perceived emotion of a media item remains poorly understood. In this paper we present MusicVideos (MuVi), a novel dataset for affective multimedia content analysis to study how the auditory and visual modalities contribute to the perceived emotion of media. The data were collected by presenting music videos to participants in three conditions: music, visual, and audiovisual. Participants annotated the music videos for valence and arousal over time, as well as the overall emotion conveyed. We present detailed descriptive statistics for key measures in the dataset and the results of feature importance analyses for each condition. Finally, we propose a novel transfer learning architecture to train Predictive models Augmented with Isolated modality Ratings (PAIR) and demonstrate the potential of isolated modality ratings for enhancing multimodal emotion recognition. Our results suggest that perceptions of arousal are influenced primarily by auditory information, while perceptions of valence are more subjective and can be influenced by both visual and auditory information. The dataset is made publicly available.
Handling big tabular data of ICT supply chains: a multi-task, machine-interpretable approach
Aug 11, 2022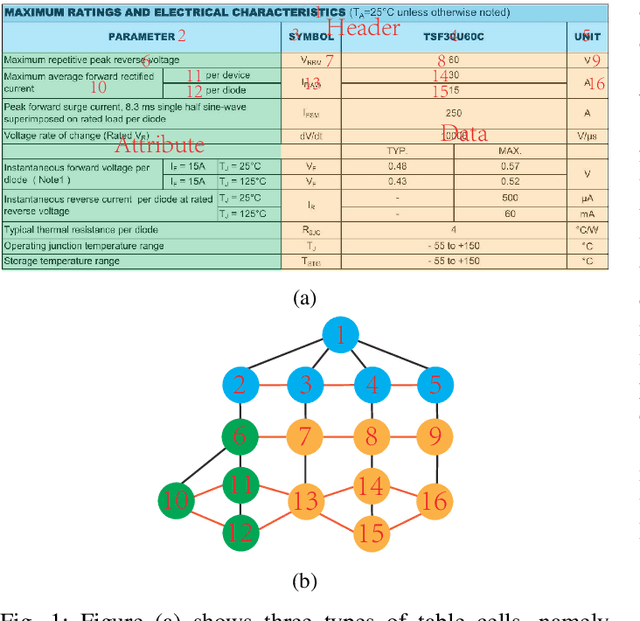
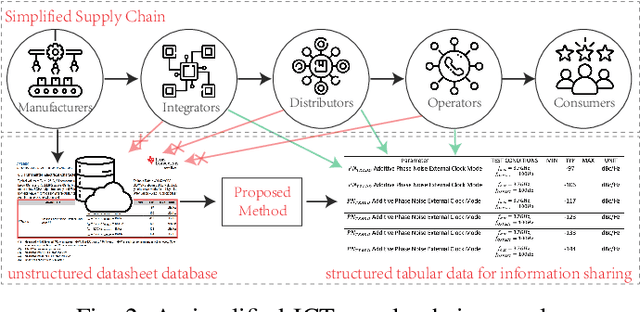
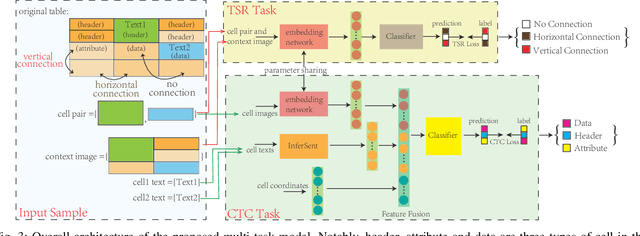
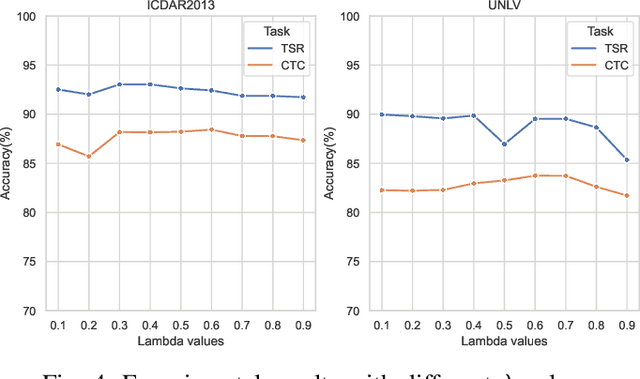
Due to the characteristics of Information and Communications Technology (ICT) products, the critical information of ICT devices is often summarized in big tabular data shared across supply chains. Therefore, it is critical to automatically interpret tabular structures with the surging amount of electronic assets. To transform the tabular data in electronic documents into a machine-interpretable format and provide layout and semantic information for information extraction and interpretation, we define a Table Structure Recognition (TSR) task and a Table Cell Type Classification (CTC) task. We use a graph to represent complex table structures for the TSR task. Meanwhile, table cells are categorized into three groups based on their functional roles for the CTC task, namely Header, Attribute, and Data. Subsequently, we propose a multi-task model to solve the defined two tasks simultaneously by using the text modal and image modal features. Our experimental results show that our proposed method can outperform state-of-the-art methods on ICDAR2013 and UNLV datasets.
Explanations as Programs in Probabilistic Logic Programming
Oct 06, 2022The generation of comprehensible explanations is an essential feature of modern artificial intelligence systems. In this work, we consider probabilistic logic programming, an extension of logic programming which can be useful to model domains with relational structure and uncertainty. Essentially, a program specifies a probability distribution over possible worlds (i.e., sets of facts). The notion of explanation is typically associated with that of a world, so that one often looks for the most probable world as well as for the worlds where the query is true. Unfortunately, such explanations exhibit no causal structure. In particular, the chain of inferences required for a specific prediction (represented by a query) is not shown. In this paper, we propose a novel approach where explanations are represented as programs that are generated from a given query by a number of unfolding-like transformations. Here, the chain of inferences that proves a given query is made explicit. Furthermore, the generated explanations are minimal (i.e., contain no irrelevant information) and can be parameterized w.r.t. a specification of visible predicates, so that the user may hide uninteresting details from explanations.
Conversational Semantic Role Labeling with Predicate-Oriented Latent Graph
Oct 06, 2022
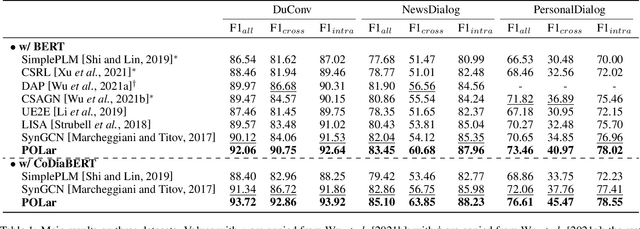
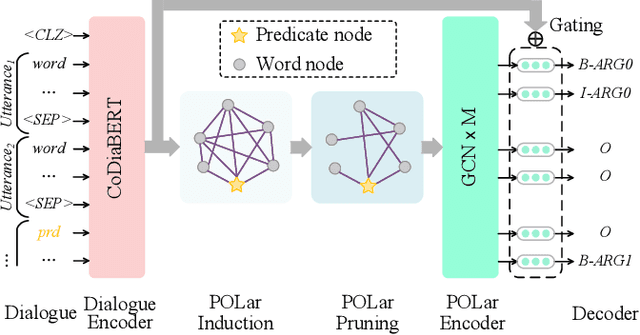
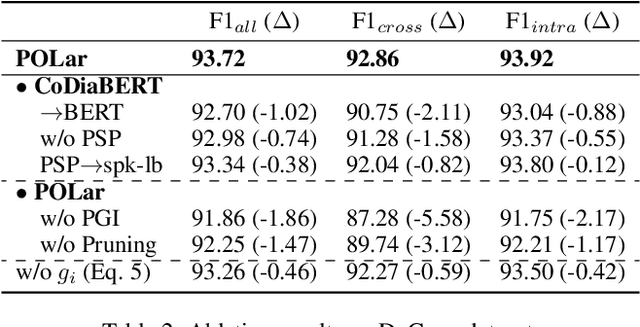
Conversational semantic role labeling (CSRL) is a newly proposed task that uncovers the shallow semantic structures in a dialogue text. Unfortunately several important characteristics of the CSRL task have been overlooked by the existing works, such as the structural information integration, near-neighbor influence. In this work, we investigate the integration of a latent graph for CSRL. We propose to automatically induce a predicate-oriented latent graph (POLar) with a predicate-centered Gaussian mechanism, by which the nearer and informative words to the predicate will be allocated with more attention. The POLar structure is then dynamically pruned and refined so as to best fit the task need. We additionally introduce an effective dialogue-level pre-trained language model, CoDiaBERT, for better supporting multiple utterance sentences and handling the speaker coreference issue in CSRL. Our system outperforms best-performing baselines on three benchmark CSRL datasets with big margins, especially achieving over 4% F1 score improvements on the cross-utterance argument detection. Further analyses are presented to better understand the effectiveness of our proposed methods.
Domain-Specific Word Embeddings with Structure Prediction
Oct 06, 2022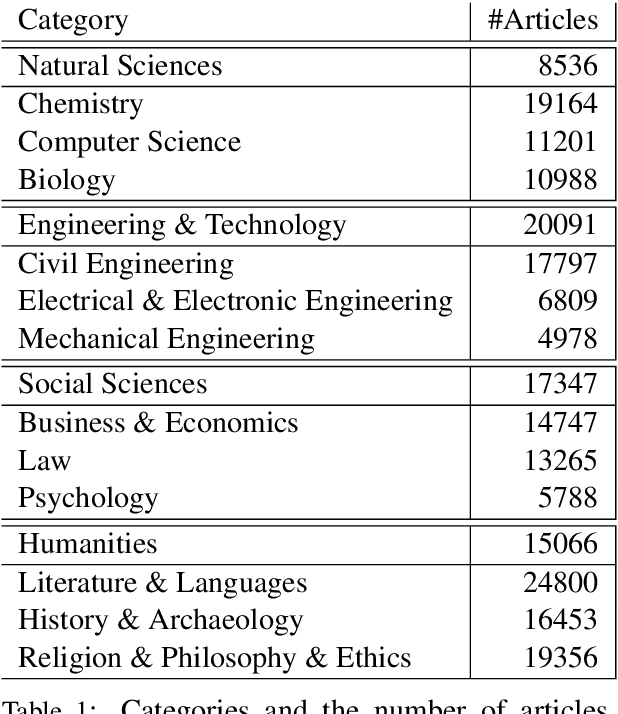
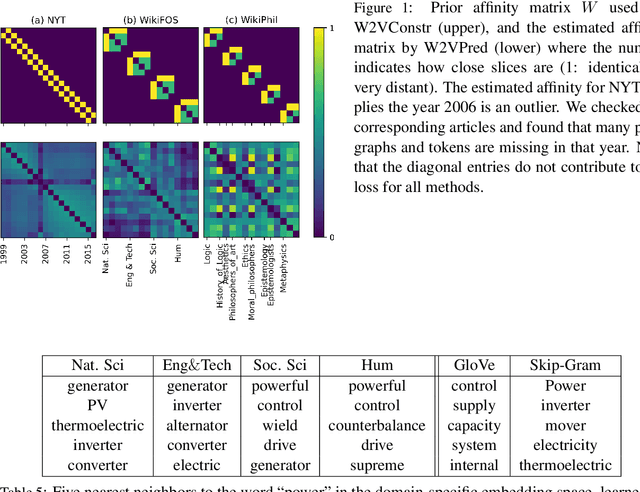
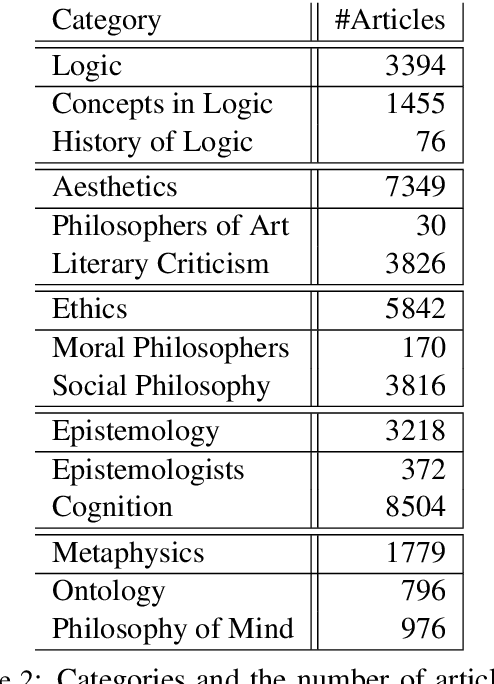
Complementary to finding good general word embeddings, an important question for representation learning is to find dynamic word embeddings, e.g., across time or domain. Current methods do not offer a way to use or predict information on structure between sub-corpora, time or domain and dynamic embeddings can only be compared after post-alignment. We propose novel word embedding methods that provide general word representations for the whole corpus, domain-specific representations for each sub-corpus, sub-corpus structure, and embedding alignment simultaneously. We present an empirical evaluation on New York Times articles and two English Wikipedia datasets with articles on science and philosophy. Our method, called Word2Vec with Structure Prediction (W2VPred), provides better performance than baselines in terms of the general analogy tests, domain-specific analogy tests, and multiple specific word embedding evaluations as well as structure prediction performance when no structure is given a priori. As a use case in the field of Digital Humanities we demonstrate how to raise novel research questions for high literature from the German Text Archive.
Robust Double-Encoder Network for RGB-D Panoptic Segmentation
Oct 06, 2022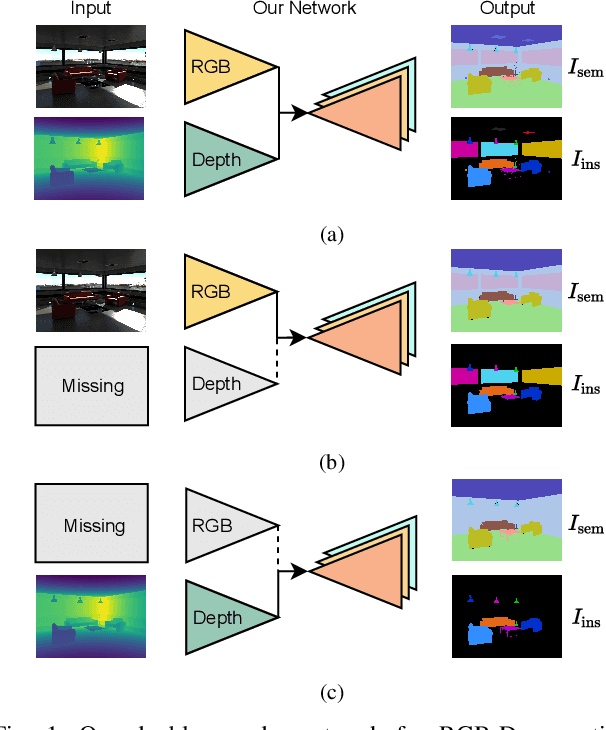
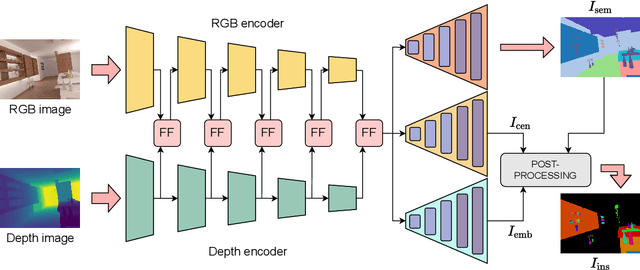
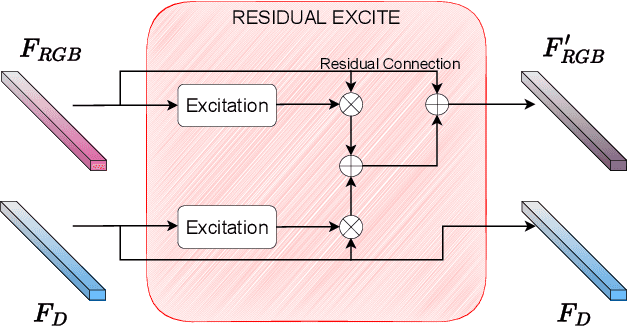

Perception is crucial for robots that act in real-world environments, as autonomous systems need to see and understand the world around them to act appropriately. Panoptic segmentation provides an interpretation of the scene by computing a pixel-wise semantic label together with instance IDs. In this paper, we address panoptic segmentation using RGB-D data of indoor scenes. We propose a novel encoder-decoder neural network that processes RGB and depth separately through two encoders. The features of the individual encoders are progressively merged at different resolutions, such that the RGB features are enhanced using complementary depth information. We propose a novel merging approach called ResidualExcite, which reweighs each entry of the feature map according to its importance. With our double-encoder architecture, we are robust to missing cues. In particular, the same model can train and infer on RGB-D, RGB-only, and depth-only input data, without the need to train specialized models. We evaluate our method on publicly available datasets and show that our approach achieves superior results compared to other common approaches for panoptic segmentation.