 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Demonstrating and Reducing Shortcuts in Vision-Language Representation Learning
Feb 27, 2024
Vision-language models (VLMs) mainly rely on contrastive training to learn general-purpose representations of images and captions. We focus on the situation when one image is associated with several captions, each caption containing both information shared among all captions and unique information per caption about the scene depicted in the image. In such cases, it is unclear whether contrastive losses are sufficient for learning task-optimal representations that contain all the information provided by the captions or whether the contrastive learning setup encourages the learning of a simple shortcut that minimizes contrastive loss. We introduce synthetic shortcuts for vision-language: a training and evaluation framework where we inject synthetic shortcuts into image-text data. We show that contrastive VLMs trained from scratch or fine-tuned with data containing these synthetic shortcuts mainly learn features that represent the shortcut. Hence, contrastive losses are not sufficient to learn task-optimal representations, i.e., representations that contain all task-relevant information shared between the image and associated captions. We examine two methods to reduce shortcut learning in our training and evaluation framework: (i) latent target decoding and (ii) implicit feature modification. We show empirically that both methods improve performance on the evaluation task, but only partly reduce shortcut learning when training and evaluating with our shortcut learning framework. Hence, we show the difficulty and challenge of our shortcut learning framework for contrastive vision-language representation learning.
Consistency-Guided Temperature Scaling Using Style and Content Information for Out-of-Domain Calibration
Feb 22, 2024Research interests in the robustness of deep neural networks against domain shifts have been rapidly increasing in recent years. Most existing works, however, focus on improving the accuracy of the model, not the calibration performance which is another important requirement for trustworthy AI systems. Temperature scaling (TS), an accuracy-preserving post-hoc calibration method, has been proven to be effective in in-domain settings, but not in out-of-domain (OOD) due to the difficulty in obtaining a validation set for the unseen domain beforehand. In this paper, we propose consistency-guided temperature scaling (CTS), a new temperature scaling strategy that can significantly enhance the OOD calibration performance by providing mutual supervision among data samples in the source domains. Motivated by our observation that over-confidence stemming from inconsistent sample predictions is the main obstacle to OOD calibration, we propose to guide the scaling process by taking consistencies into account in terms of two different aspects -- style and content -- which are the key components that can well-represent data samples in multi-domain settings. Experimental results demonstrate that our proposed strategy outperforms existing works, achieving superior OOD calibration performance on various datasets. This can be accomplished by employing only the source domains without compromising accuracy, making our scheme directly applicable to various trustworthy AI systems.
On Independent Samples Along the Langevin Diffusion and the Unadjusted Langevin Algorithm
Feb 26, 2024We study the rate at which the initial and current random variables become independent along a Markov chain, focusing on the Langevin diffusion in continuous time and the Unadjusted Langevin Algorithm (ULA) in discrete time. We measure the dependence between random variables via their mutual information. For the Langevin diffusion, we show the mutual information converges to $0$ exponentially fast when the target is strongly log-concave, and at a polynomial rate when the target is weakly log-concave. These rates are analogous to the mixing time of the Langevin diffusion under similar assumptions. For the ULA, we show the mutual information converges to $0$ exponentially fast when the target is strongly log-concave and smooth. We prove our results by developing the mutual version of the mixing time analyses of these Markov chains. We also provide alternative proofs based on strong data processing inequalities for the Langevin diffusion and the ULA, and by showing regularity results for these processes in mutual information.
Corpus-Steered Query Expansion with Large Language Models
Feb 28, 2024Recent studies demonstrate that query expansions generated by large language models (LLMs) can considerably enhance information retrieval systems by generating hypothetical documents that answer the queries as expansions. However, challenges arise from misalignments between the expansions and the retrieval corpus, resulting in issues like hallucinations and outdated information due to the limited intrinsic knowledge of LLMs. Inspired by Pseudo Relevance Feedback (PRF), we introduce Corpus-Steered Query Expansion (CSQE) to promote the incorporation of knowledge embedded within the corpus. CSQE utilizes the relevance assessing capability of LLMs to systematically identify pivotal sentences in the initially-retrieved documents. These corpus-originated texts are subsequently used to expand the query together with LLM-knowledge empowered expansions, improving the relevance prediction between the query and the target documents. Extensive experiments reveal that CSQE exhibits strong performance without necessitating any training, especially with queries for which LLMs lack knowledge.
Edge-guided Low-light Image Enhancement with Inertial Bregman Alternating Linearized Minimization
Mar 02, 2024
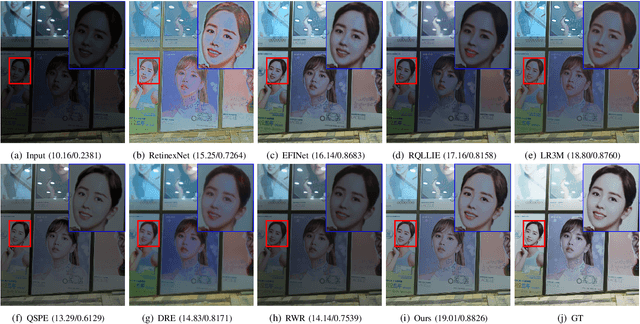


Prior-based methods for low-light image enhancement often face challenges in extracting available prior information from dim images. To overcome this limitation, we introduce a simple yet effective Retinex model with the proposed edge extraction prior. More specifically, we design an edge extraction network to capture the fine edge features from the low-light image directly. Building upon the Retinex theory, we decompose the low-light image into its illumination and reflectance components and introduce an edge-guided Retinex model for enhancing low-light images. To solve the proposed model, we propose a novel inertial Bregman alternating linearized minimization algorithm. This algorithm addresses the optimization problem associated with the edge-guided Retinex model, enabling effective enhancement of low-light images. Through rigorous theoretical analysis, we establish the convergence properties of the algorithm. Besides, we prove that the proposed algorithm converges to a stationary point of the problem through nonconvex optimization theory. Furthermore, extensive experiments are conducted on multiple real-world low-light image datasets to demonstrate the efficiency and superiority of the proposed scheme.
An Efficient Difference-of-Convex Solver for Privacy Funnel
Mar 02, 2024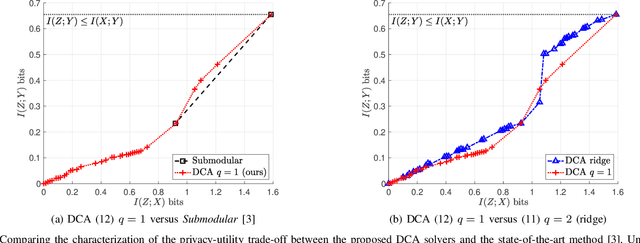
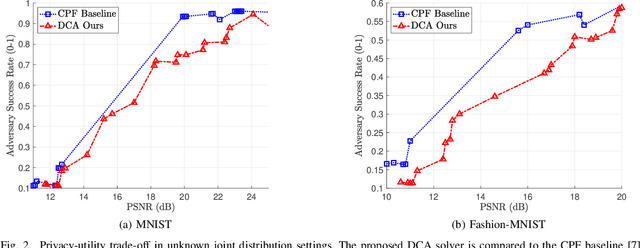
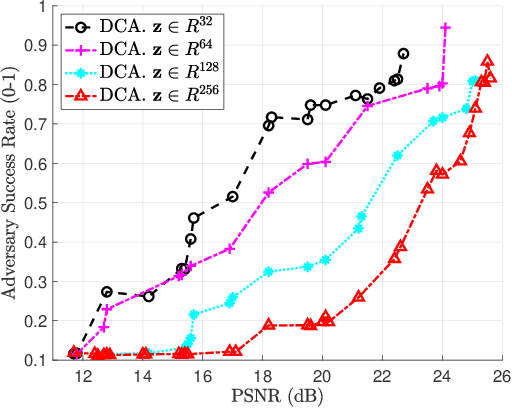

We propose an efficient solver for the privacy funnel (PF) method, leveraging its difference-of-convex (DC) structure. The proposed DC separation results in a closed-form update equation, which allows straightforward application to both known and unknown distribution settings. For known distribution case, we prove the convergence (local stationary points) of the proposed non-greedy solver, and empirically show that it outperforms the state-of-the-art approaches in characterizing the privacy-utility trade-off. The insights of our DC approach apply to unknown distribution settings where labeled empirical samples are available instead. Leveraging the insights, our alternating minimization solver satisfies the fundamental Markov relation of PF in contrast to previous variational inference-based solvers. Empirically, we evaluate the proposed solver with MNIST and Fashion-MNIST datasets. Our results show that under a comparable reconstruction quality, an adversary suffers from higher prediction error from clustering our compressed codes than that with the compared methods. Most importantly, our solver is independent to private information in inference phase contrary to the baselines.
ICC: Quantifying Image Caption Concreteness for Multimodal Dataset Curation
Mar 02, 2024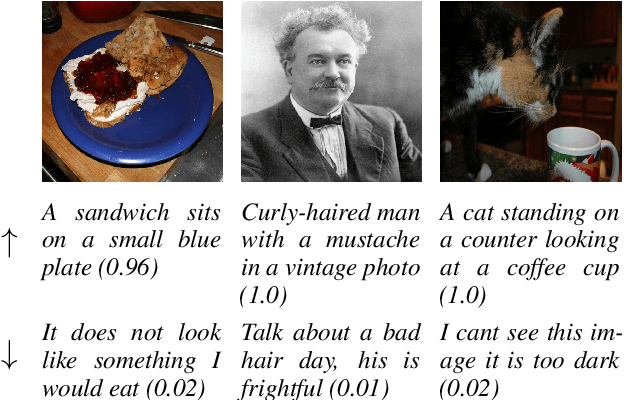
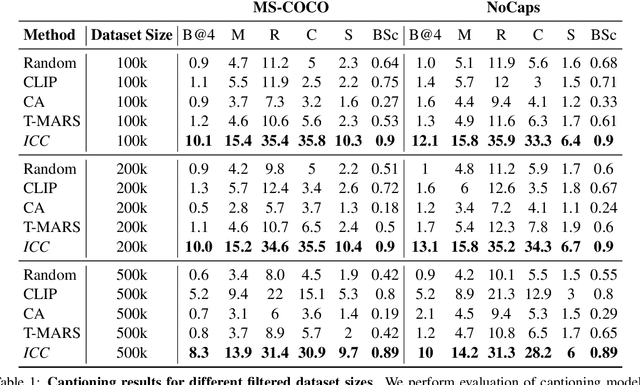

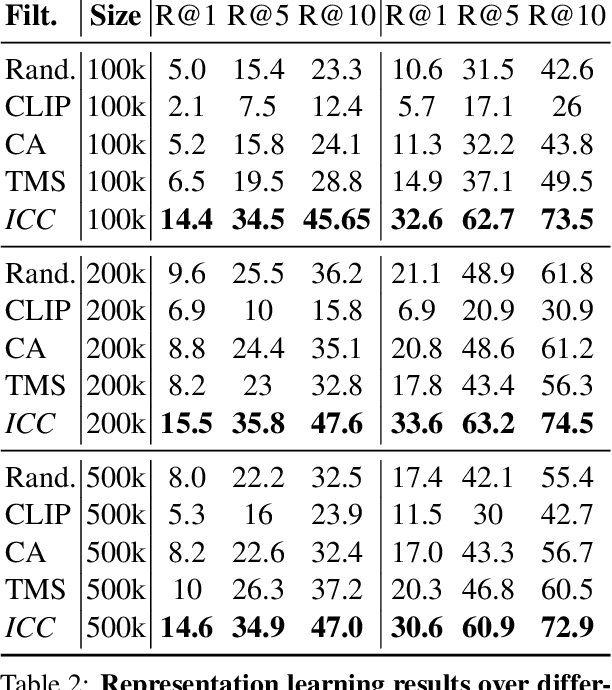
Web-scale training on paired text-image data is becoming increasingly central to multimodal learning, but is challenged by the highly noisy nature of datasets in the wild. Standard data filtering approaches succeed in removing mismatched text-image pairs, but permit semantically related but highly abstract or subjective text. These approaches lack the fine-grained ability to isolate the most concrete samples that provide the strongest signal for learning in a noisy dataset. In this work, we propose a new metric, image caption concreteness, that evaluates caption text without an image reference to measure its concreteness and relevancy for use in multimodal learning. Our approach leverages strong foundation models for measuring visual-semantic information loss in multimodal representations. We demonstrate that this strongly correlates with human evaluation of concreteness in both single-word and sentence-level texts. Moreover, we show that curation using ICC complements existing approaches: It succeeds in selecting the highest quality samples from multimodal web-scale datasets to allow for efficient training in resource-constrained settings.
HALC: Object Hallucination Reduction via Adaptive Focal-Contrast Decoding
Mar 01, 2024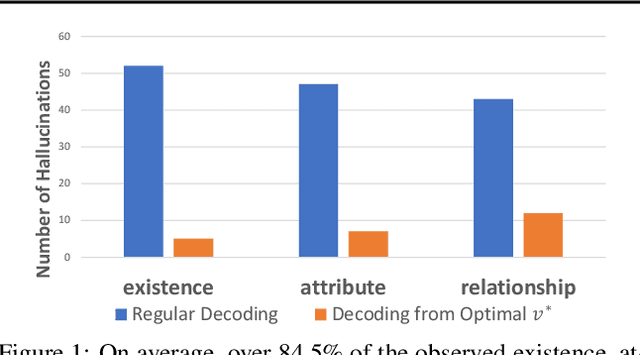
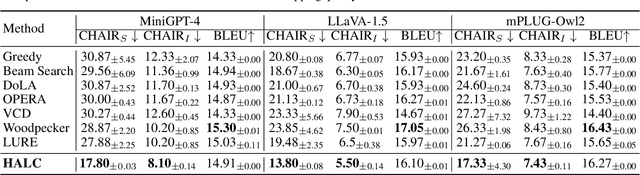
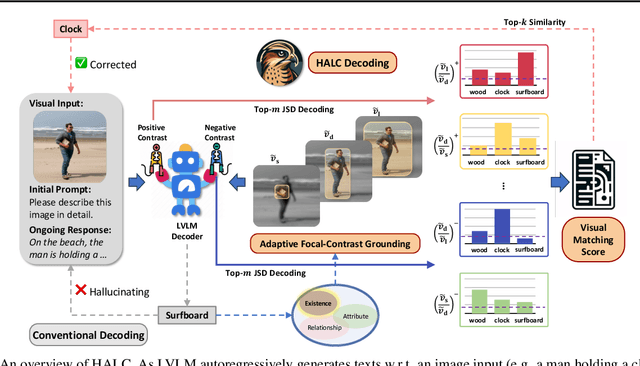
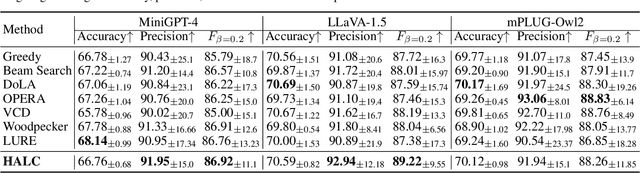
While large vision-language models (LVLMs) have demonstrated impressive capabilities in interpreting multi-modal contexts, they invariably suffer from object hallucinations (OH). We introduce HALC, a novel decoding algorithm designed to mitigate OH in LVLMs. HALC leverages distinct fine-grained optimal visual information in vision-language tasks and operates on both local and global contexts simultaneously. Specifically, HALC integrates a robust auto-focal grounding mechanism (locally) to correct hallucinated tokens on the fly, and a specialized beam search algorithm (globally) to significantly reduce OH while preserving text generation quality. Additionally, HALC can be integrated into any LVLMs as a plug-and-play module without extra training. Extensive experimental studies demonstrate the effectiveness of HALC in reducing OH, outperforming state-of-the-arts across four benchmarks.
Progressive Contrastive Learning with Multi-Prototype for Unsupervised Visible-Infrared Person Re-identification
Feb 29, 2024Unsupervised visible-infrared person re-identification (USVI-ReID) aims to match specified people in infrared images to visible images without annotation, and vice versa. USVI-ReID is a challenging yet under-explored task. Most existing methods address the USVI-ReID problem using cluster-based contrastive learning, which simply employs the cluster center as a representation of a person. However, the cluster center primarily focuses on shared information, overlooking disparity. To address the problem, we propose a Progressive Contrastive Learning with Multi-Prototype (PCLMP) method for USVI-ReID. In brief, we first generate the hard prototype by selecting the sample with the maximum distance from the cluster center. This hard prototype is used in the contrastive loss to emphasize disparity. Additionally, instead of rigidly aligning query images to a specific prototype, we generate the dynamic prototype by randomly picking samples within a cluster. This dynamic prototype is used to retain the natural variety of features while reducing instability in the simultaneous learning of both common and disparate information. Finally, we introduce a progressive learning strategy to gradually shift the model's attention towards hard samples, avoiding cluster deterioration. Extensive experiments conducted on the publicly available SYSU-MM01 and RegDB datasets validate the effectiveness of the proposed method. PCLMP outperforms the existing state-of-the-art method with an average mAP improvement of 3.9%. The source codes will be released.
FusionVision: A comprehensive approach of 3D object reconstruction and segmentation from RGB-D cameras using YOLO and fast segment anything
Feb 29, 2024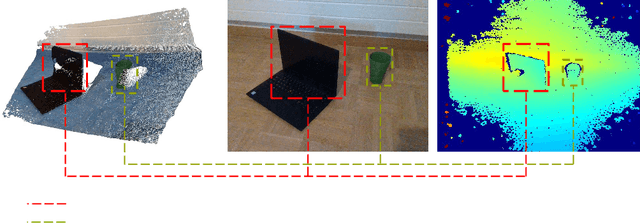



In the realm of computer vision, the integration of advanced techniques into the processing of RGB-D camera inputs poses a significant challenge, given the inherent complexities arising from diverse environmental conditions and varying object appearances. Therefore, this paper introduces FusionVision, an exhaustive pipeline adapted for the robust 3D segmentation of objects in RGB-D imagery. Traditional computer vision systems face limitations in simultaneously capturing precise object boundaries and achieving high-precision object detection on depth map as they are mainly proposed for RGB cameras. To address this challenge, FusionVision adopts an integrated approach by merging state-of-the-art object detection techniques, with advanced instance segmentation methods. The integration of these components enables a holistic (unified analysis of information obtained from both color \textit{RGB} and depth \textit{D} channels) interpretation of RGB-D data, facilitating the extraction of comprehensive and accurate object information. The proposed FusionVision pipeline employs YOLO for identifying objects within the RGB image domain. Subsequently, FastSAM, an innovative semantic segmentation model, is applied to delineate object boundaries, yielding refined segmentation masks. The synergy between these components and their integration into 3D scene understanding ensures a cohesive fusion of object detection and segmentation, enhancing overall precision in 3D object segmentation. The code and pre-trained models are publicly available at https://github.com/safouaneelg/FusionVision/.