 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An Efficient FPGA Accelerator for Point Cloud
Oct 14, 2022
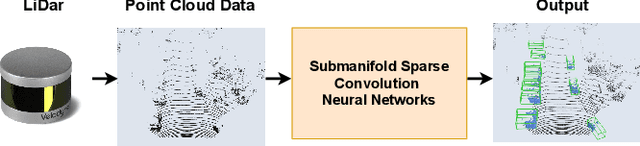
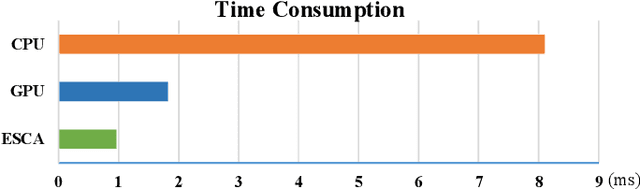
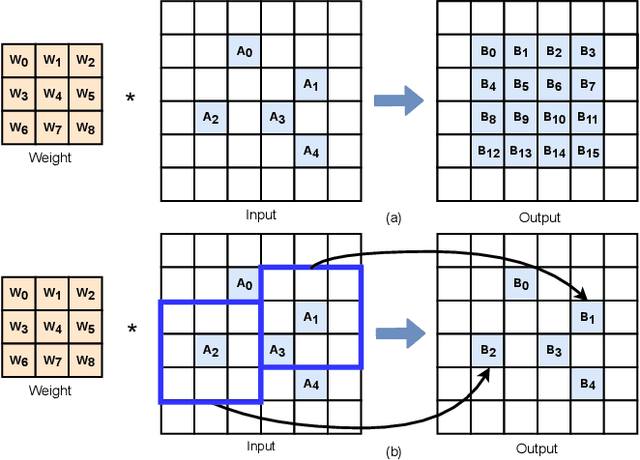
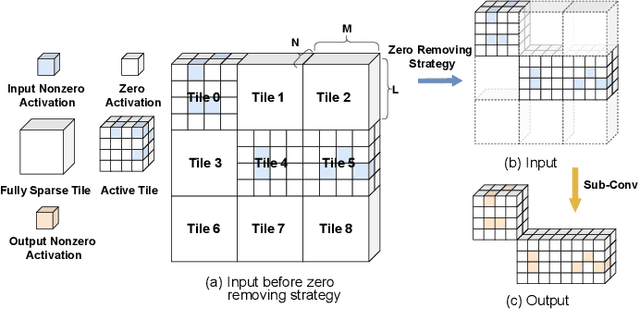
Deep learning-based point cloud processing plays an important role in various vision tasks, such as autonomous driving, virtual reality (VR), and augmented reality (AR). The submanifold sparse convolutional network (SSCN) has been widely used for the point cloud due to its unique advantages in terms of visual results. However, existing convolutional neural network accelerators suffer from non-trivial performance degradation when employed to accelerate SSCN because of the extreme and unstructured sparsity, and the complex computational dependency between the sparsity of the central activation and the neighborhood ones. In this paper, we propose a high performance FPGA-based accelerator for SSCN. Firstly, we develop a zero removing strategy to remove the coarse-grained redundant regions, thus significantly improving computational efficiency. Secondly, we propose a concise encoding scheme to obtain the matching information for efficient point-wise multiplications. Thirdly, we develop a sparse data matching unit and a computing core based on the proposed encoding scheme, which can convert the irregular sparse operations into regular multiply-accumulate operations. Finally, an efficient hardware architecture for the submanifold sparse convolutional layer is developed and implemented on the Xilinx ZCU102 field-programmable gate array board, where the 3D submanifold sparse U-Net is taken as the benchmark. The experimental results demonstrate that our design drastically improves computational efficiency, and can dramatically improve the power efficiency by 51 times compared to GPU.
The Surprisingly Straightforward Scene Text Removal Method With Gated Attention and Region of Interest Generation: A Comprehensive Prominent Model Analysis
Oct 14, 2022
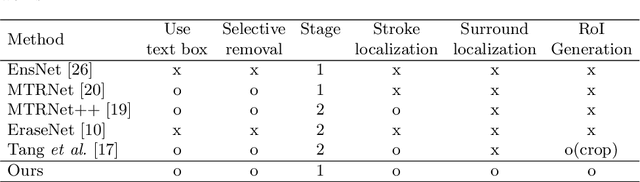
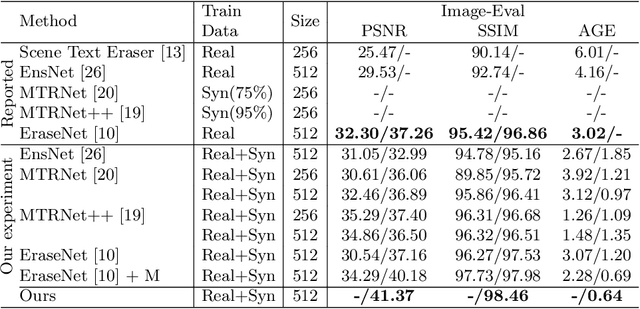
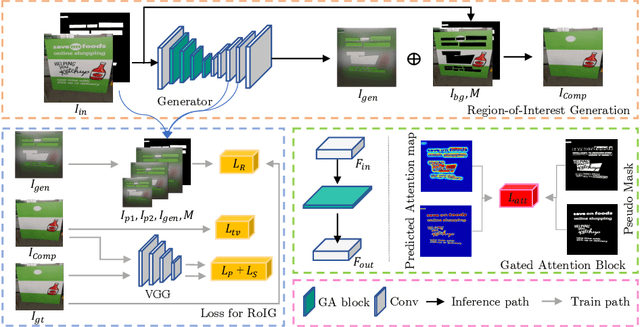
Scene text removal (STR), a task of erasing text from natural scene images, has recently attracted attention as an important component of editing text or concealing private information such as ID, telephone, and license plate numbers. While there are a variety of different methods for STR actively being researched, it is difficult to evaluate superiority because previously proposed methods do not use the same standardized training/evaluation dataset. We use the same standardized training/testing dataset to evaluate the performance of several previous methods after standardized re-implementation. We also introduce a simple yet extremely effective Gated Attention (GA) and Region-of-Interest Generation (RoIG) methodology in this paper. GA uses attention to focus on the text stroke as well as the textures and colors of the surrounding regions to remove text from the input image much more precisely. RoIG is applied to focus on only the region with text instead of the entire image to train the model more efficiently. Experimental results on the benchmark dataset show that our method significantly outperforms existing state-of-the-art methods in almost all metrics with remarkably higher-quality results. Furthermore, because our model does not generate a text stroke mask explicitly, there is no need for additional refinement steps or sub-models, making our model extremely fast with fewer parameters. The dataset and code are available at this https://github.com/naver/garnet.
HashFormers: Towards Vocabulary-independent Pre-trained Transformers
Oct 14, 2022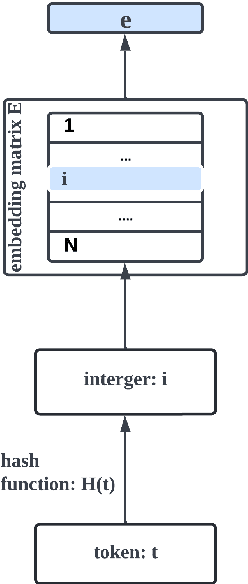
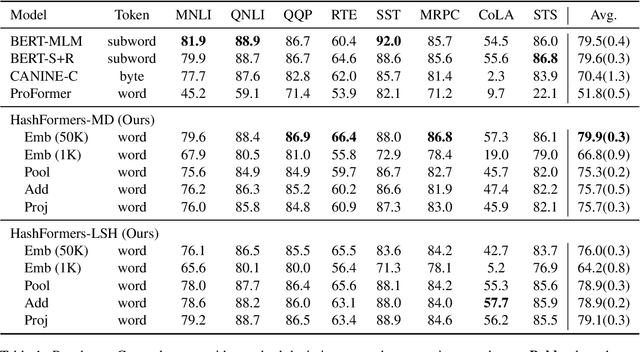
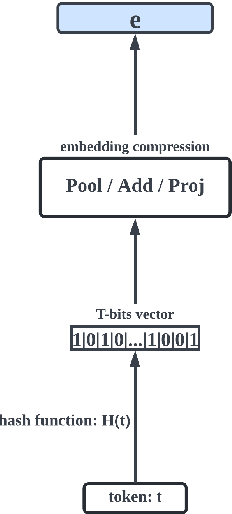
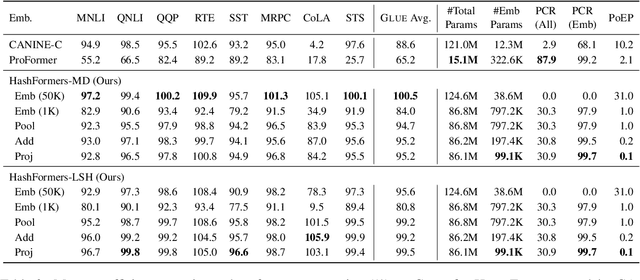
Transformer-based pre-trained language models are vocabulary-dependent, mapping by default each token to its corresponding embedding. This one-to-one mapping results into embedding matrices that occupy a lot of memory (i.e. millions of parameters) and grow linearly with the size of the vocabulary. Previous work on on-device transformers dynamically generate token embeddings on-the-fly without embedding matrices using locality-sensitive hashing over morphological information. These embeddings are subsequently fed into transformer layers for text classification. However, these methods are not pre-trained. Inspired by this line of work, we propose HashFormers, a new family of vocabulary-independent pre-trained transformers that support an unlimited vocabulary (i.e. all possible tokens in a corpus) given a substantially smaller fixed-sized embedding matrix. We achieve this by first introducing computationally cheap hashing functions that bucket together individual tokens to embeddings. We also propose three variants that do not require an embedding matrix at all, further reducing the memory requirements. We empirically demonstrate that HashFormers are more memory efficient compared to standard pre-trained transformers while achieving comparable predictive performance when fine-tuned on multiple text classification tasks. For example, our most efficient HashFormer variant has a negligible performance degradation (0.4\% on GLUE) using only 99.1K parameters for representing the embeddings compared to 12.3-38M parameters of state-of-the-art models.
A Label Correction Algorithm Using Prior Information for Automatic and Accurate Geospatial Object Recognition
Dec 10, 2021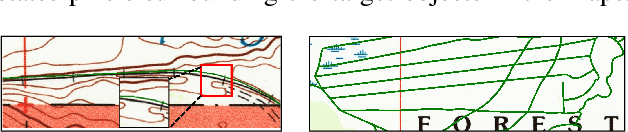
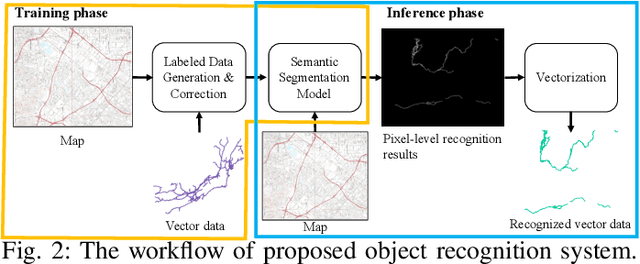

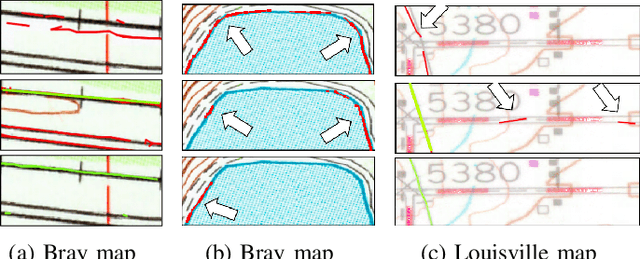
Thousands of scanned historical topographic maps contain valuable information covering long periods of time, such as how the hydrography of a region has changed over time. Efficiently unlocking the information in these maps requires training a geospatial objects recognition system, which needs a large amount of annotated data. Overlapping geo-referenced external vector data with topographic maps according to their coordinates can annotate the desired objects' locations in the maps automatically. However, directly overlapping the two datasets causes misaligned and false annotations because the publication years and coordinate projection systems of topographic maps are different from the external vector data. We propose a label correction algorithm, which leverages the color information of maps and the prior shape information of the external vector data to reduce misaligned and false annotations. The experiments show that the precision of annotations from the proposed algorithm is 10% higher than the annotations from a state-of-the-art algorithm. Consequently, recognition results using the proposed algorithm's annotations achieve 9% higher correctness than using the annotations from the state-of-the-art algorithm.
Iterative Optimization of Pseudo Ground-Truth Face Image Quality Labels
Aug 31, 2022While recent face recognition (FR) systems achieve excellent results in many deployment scenarios, their performance in challenging real-world settings is still under question. For this reason, face image quality assessment (FIQA) techniques aim to support FR systems, by providing them with sample quality information that can be used to reject poor quality data unsuitable for recognition purposes. Several groups of FIQA methods relying on different concepts have been proposed in the literature, all of which can be used for generating quality scores of facial images that can serve as pseudo ground-truth (quality) labels and can be exploited for training (regression-based) quality estimation models. Several FIQA appro\-aches show that a significant amount of sample-quality information can be extracted from mated similarity-score distributions generated with some face matcher. Based on this insight, we propose in this paper a quality label optimization approach, which incorporates sample-quality information from mated-pair similarities into quality predictions of existing off-the-shelf FIQA techniques. We evaluate the proposed approach using three state-of-the-art FIQA methods over three diverse datasets. The results of our experiments show that the proposed optimization procedure heavily depends on the number of executed optimization iterations. At ten iterations, the approach seems to perform the best, consistently outperforming the base quality scores of the three FIQA methods, chosen for the experiments.
AutoGEL: An Automated Graph Neural Network with Explicit Link Information
Dec 02, 2021
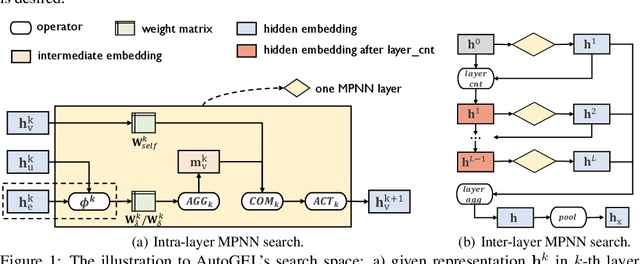
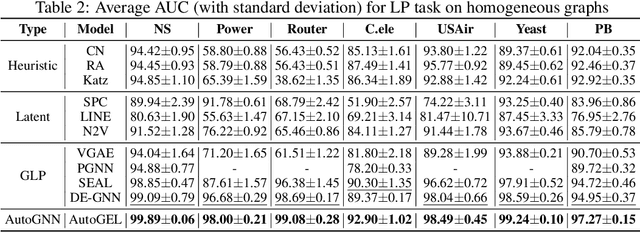
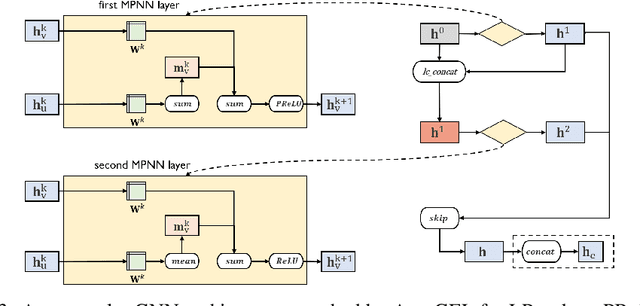
Recently, Graph Neural Networks (GNNs) have gained popularity in a variety of real-world scenarios. Despite the great success, the architecture design of GNNs heavily relies on manual labor. Thus, automated graph neural network (AutoGNN) has attracted interest and attention from the research community, which makes significant performance improvements in recent years. However, existing AutoGNN works mainly adopt an implicit way to model and leverage the link information in the graphs, which is not well regularized to the link prediction task on graphs, and limits the performance of AutoGNN for other graph tasks. In this paper, we present a novel AutoGNN work that explicitly models the link information, abbreviated to AutoGEL. In such a way, AutoGEL can handle the link prediction task and improve the performance of AutoGNNs on the node classification and graph classification task. Specifically, AutoGEL proposes a novel search space containing various design dimensions at both intra-layer and inter-layer designs and adopts a more robust differentiable search algorithm to further improve efficiency and effectiveness. Experimental results on benchmark data sets demonstrate the superiority of AutoGEL on several tasks.
Probing Cross-modal Semantics Alignment Capability from the Textual Perspective
Oct 18, 2022

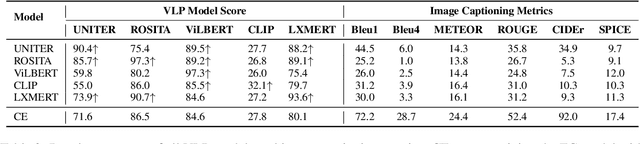
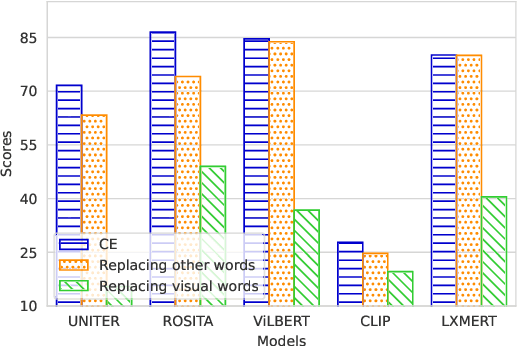
In recent years, vision and language pre-training (VLP) models have advanced the state-of-the-art results in a variety of cross-modal downstream tasks. Aligning cross-modal semantics is claimed to be one of the essential capabilities of VLP models. However, it still remains unclear about the inner working mechanism of alignment in VLP models. In this paper, we propose a new probing method that is based on image captioning to first empirically study the cross-modal semantics alignment of VLP models. Our probing method is built upon the fact that given an image-caption pair, the VLP models will give a score, indicating how well two modalities are aligned; maximizing such scores will generate sentences that VLP models believe are of good alignment. Analyzing these sentences thus will reveal in what way different modalities are aligned and how well these alignments are in VLP models. We apply our probing method to five popular VLP models, including UNITER, ROSITA, ViLBERT, CLIP, and LXMERT, and provide a comprehensive analysis of the generated captions guided by these models. Our results show that VLP models (1) focus more on just aligning objects with visual words, while neglecting global semantics; (2) prefer fixed sentence patterns, thus ignoring more important textual information including fluency and grammar; and (3) deem the captions with more visual words are better aligned with images. These findings indicate that VLP models still have weaknesses in cross-modal semantics alignment and we hope this work will draw researchers' attention to such problems when designing a new VLP model.
STAR: Zero-Shot Chinese Character Recognition with Stroke- and Radical-Level Decompositions
Oct 16, 2022
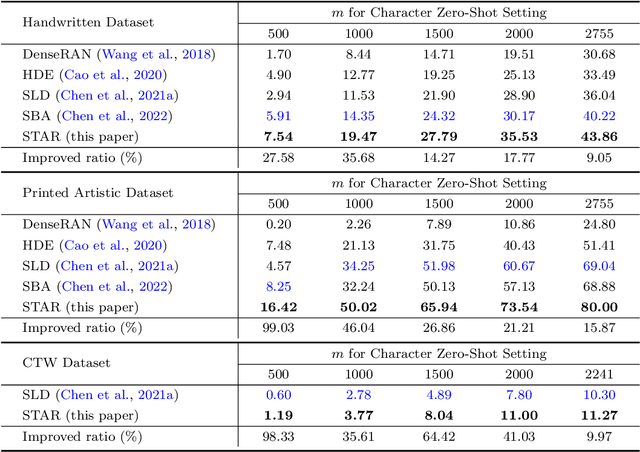
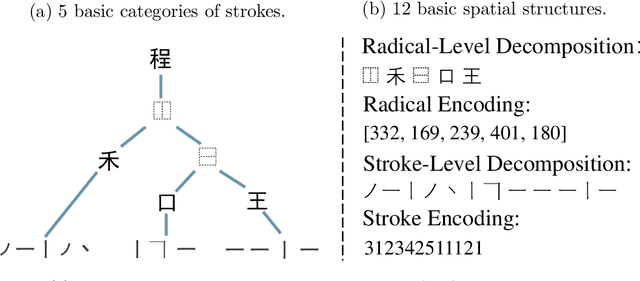
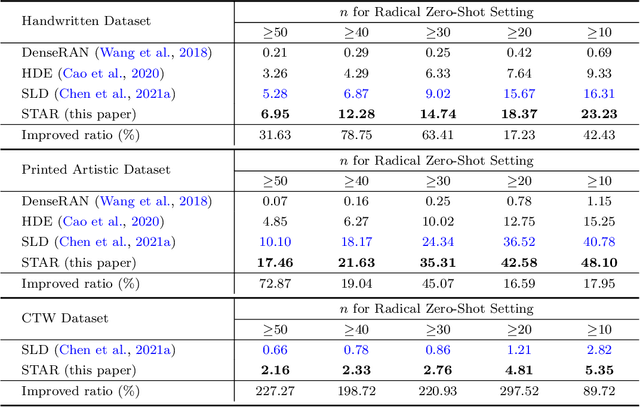
Zero-shot Chinese character recognition has attracted rising attention in recent years. Existing methods for this problem are mainly based on either certain low-level stroke-based decomposition or medium-level radical-based decomposition. Considering that the stroke- and radical-level decompositions can provide different levels of information, we propose an effective zero-shot Chinese character recognition method by combining them. The proposed method consists of a training stage and an inference stage. In the training stage, we adopt two similar encoder-decoder models to yield the estimates of stroke and radical encodings, which together with the true encodings are then used to formalize the associated stroke and radical losses for training. A similarity loss is introduced to regularize stroke and radical encoders to yield features of the same characters with high correlation. In the inference stage, two key modules, i.e., the stroke screening module (SSM) and feature matching module (FMM) are introduced to tackle the deterministic and confusing cases respectively. In particular, we introduce an effective stroke rectification scheme in FMM to enlarge the candidate set of characters for final inference. Numerous experiments over three benchmark datasets covering the handwritten, printed artistic and street view scenarios are conducted to demonstrate the effectiveness of the proposed method. Numerical results show that the proposed method outperforms the state-of-the-art methods in both character and radical zero-shot settings, and maintains competitive performance in the traditional seen character setting.
MonoNHR: Monocular Neural Human Renderer
Oct 02, 2022
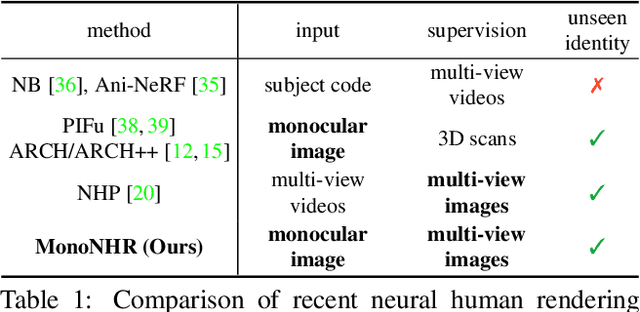
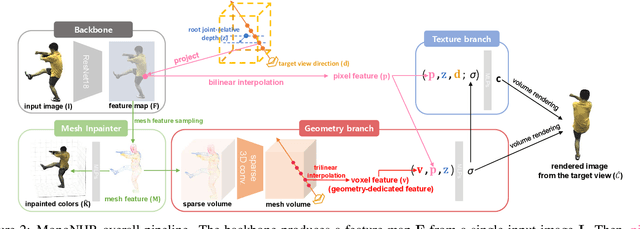
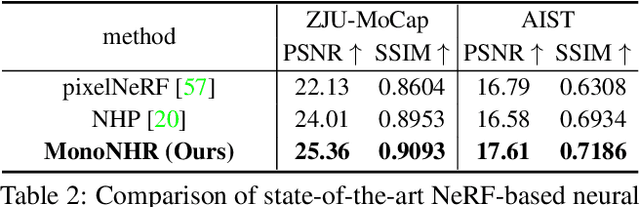
Existing neural human rendering methods struggle with a single image input due to the lack of information in invisible areas and the depth ambiguity of pixels in visible areas. In this regard, we propose Monocular Neural Human Renderer (MonoNHR), a novel approach that renders robust free-viewpoint images of an arbitrary human given only a single image. MonoNHR is the first method that (i) renders human subjects never seen during training in a monocular setup, and (ii) is trained in a weakly-supervised manner without geometry supervision. First, we propose to disentangle 3D geometry and texture features and to condition the texture inference on the 3D geometry features. Second, we introduce a Mesh Inpainter module that inpaints the occluded parts exploiting human structural priors such as symmetry. Experiments on ZJU-MoCap, AIST, and HUMBI datasets show that our approach significantly outperforms the recent methods adapted to the monocular case.
ViT-DD: Multi-Task Vision Transformer for Semi-Supervised Driver Distraction Detection
Sep 28, 2022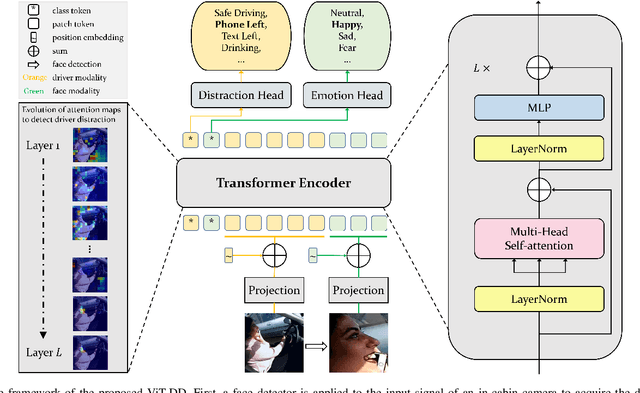


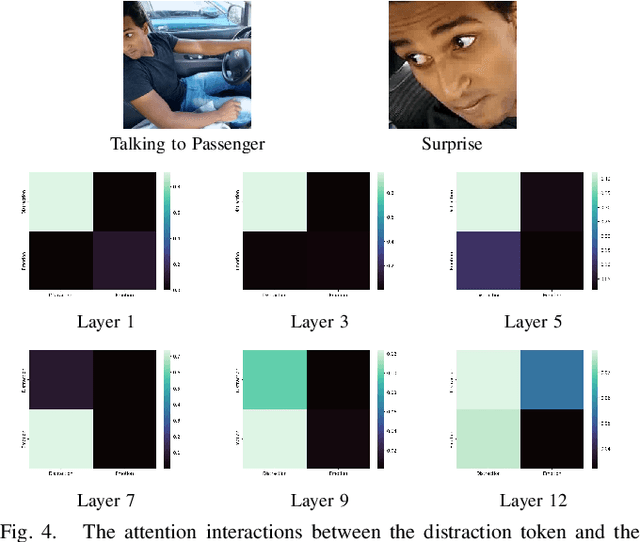
Driver distraction detection is an important computer vision problem that can play a crucial role in enhancing traffic safety and reducing traffic accidents. This paper proposes a novel semi-supervised method for detecting driver distractions based on Vision Transformer (ViT). Specifically, a multi-modal Vision Transformer (ViT-DD) is developed that makes use of inductive information contained in training signals of distraction detection as well as driver emotion recognition. Further, a self-learning algorithm is designed to include driver data without emotion labels into the multi-task training of ViT-DD. Extensive experiments conducted on the SFDDD and AUCDD datasets demonstrate that the proposed ViT-DD outperforms the best state-of-the-art approaches for driver distraction detection by 6.5% and 0.9%, respectively. Our source code is released at https://github.com/PurdueDigitalTwin/ViT-DD.