 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Approximate better, Attack stronger: Adversarial Example Generation via Asymptotically Gaussian Mixture Distribution
Sep 24, 2022
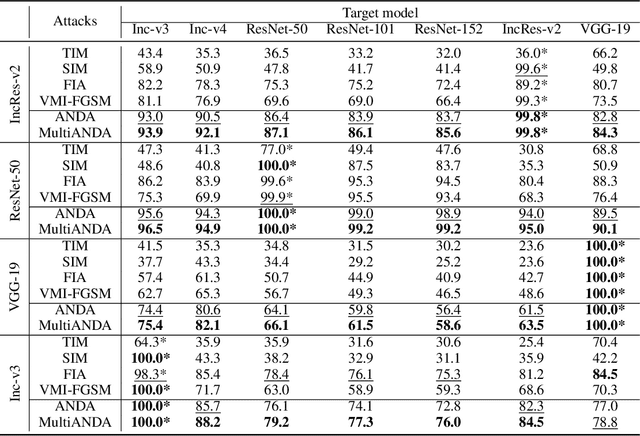
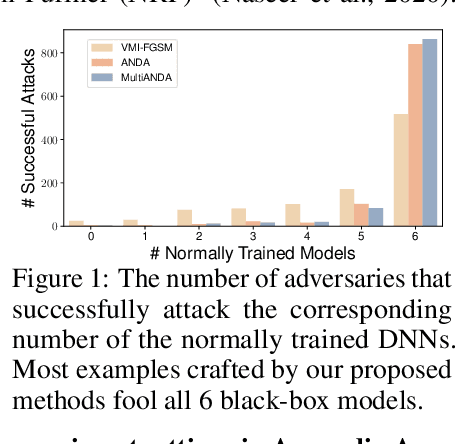
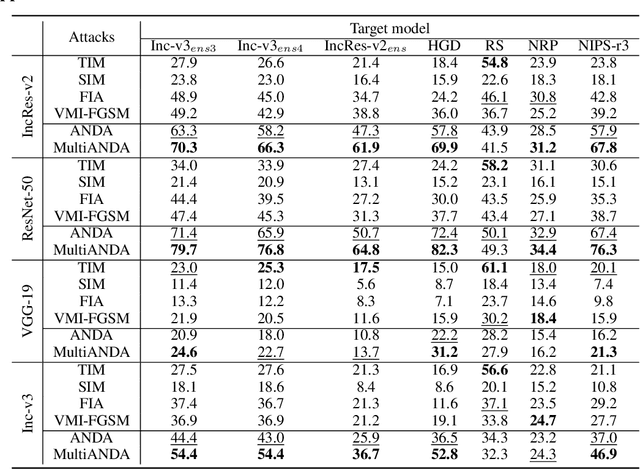
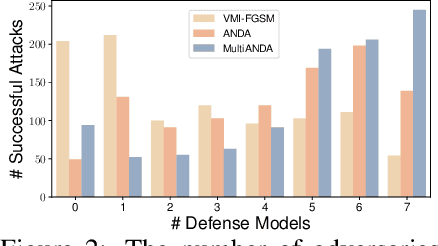
Strong adversarial examples are the keys to evaluating and enhancing the robustness of deep neural networks. The popular adversarial attack algorithms maximize the non-concave loss function using the gradient ascent. However, the performance of each attack is usually sensitive to, for instance, minor image transformations due to insufficient information (only one input example, few white-box source models and unknown defense strategies). Hence, the crafted adversarial examples are prone to overfit the source model, which limits their transferability to unidentified architectures. In this paper, we propose Multiple Asymptotically Normal Distribution Attacks (MultiANDA), a novel method that explicitly characterizes adversarial perturbations from a learned distribution. Specifically, we approximate the posterior distribution over the perturbations by taking advantage of the asymptotic normality property of stochastic gradient ascent (SGA), then apply the ensemble strategy on this procedure to estimate a Gaussian mixture model for a better exploration of the potential optimization space. Drawing perturbations from the learned distribution allow us to generate any number of adversarial examples for each input. The approximated posterior essentially describes the stationary distribution of SGA iterations, which captures the geometric information around the local optimum. Thus, the samples drawn from the distribution reliably maintain the transferability. Our proposed method outperforms nine state-of-the-art black-box attacks on deep learning models with or without defenses through extensive experiments on seven normally trained and seven defence models.
360-MLC: Multi-view Layout Consistency for Self-training and Hyper-parameter Tuning
Oct 24, 2022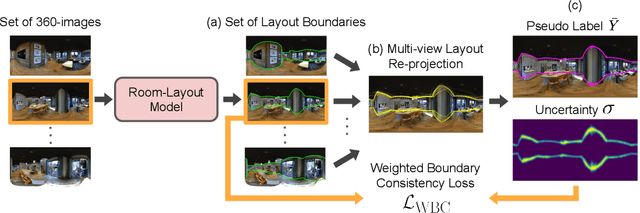
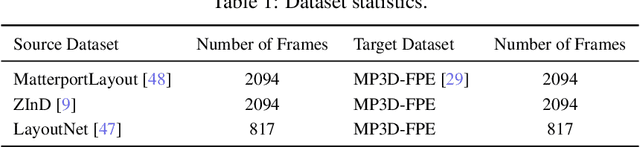
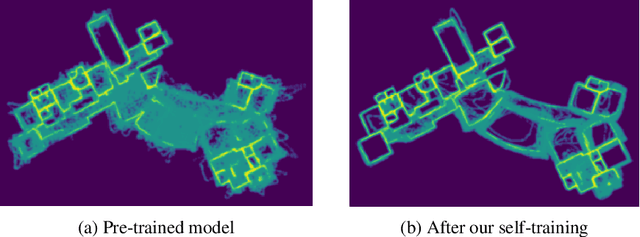
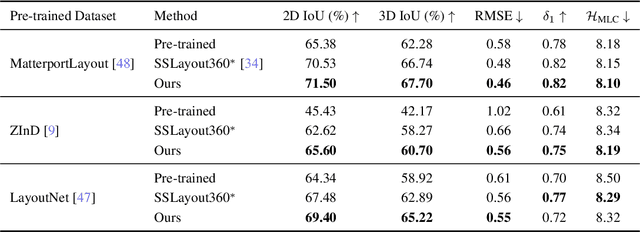
We present 360-MLC, a self-training method based on multi-view layout consistency for finetuning monocular room-layout models using unlabeled 360-images only. This can be valuable in practical scenarios where a pre-trained model needs to be adapted to a new data domain without using any ground truth annotations. Our simple yet effective assumption is that multiple layout estimations in the same scene must define a consistent geometry regardless of their camera positions. Based on this idea, we leverage a pre-trained model to project estimated layout boundaries from several camera views into the 3D world coordinate. Then, we re-project them back to the spherical coordinate and build a probability function, from which we sample the pseudo-labels for self-training. To handle unconfident pseudo-labels, we evaluate the variance in the re-projected boundaries as an uncertainty value to weight each pseudo-label in our loss function during training. In addition, since ground truth annotations are not available during training nor in testing, we leverage the entropy information in multiple layout estimations as a quantitative metric to measure the geometry consistency of the scene, allowing us to evaluate any layout estimator for hyper-parameter tuning, including model selection without ground truth annotations. Experimental results show that our solution achieves favorable performance against state-of-the-art methods when self-training from three publicly available source datasets to a unique, newly labeled dataset consisting of multi-view of the same scenes.
SeRP: Self-Supervised Representation Learning Using Perturbed Point Clouds
Sep 13, 2022
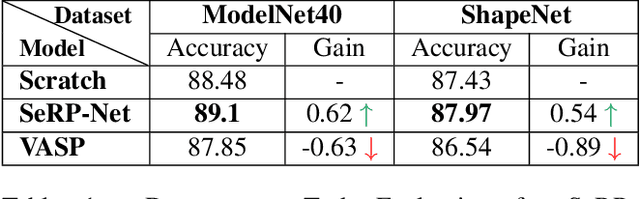
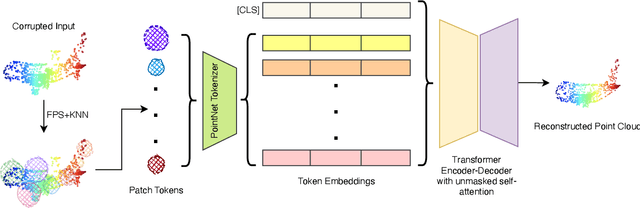
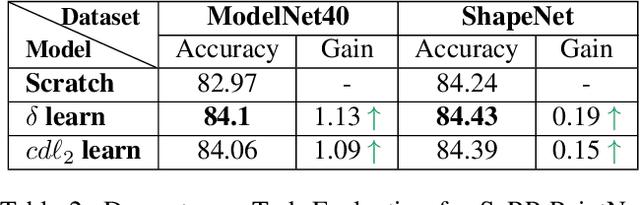
We present SeRP, a framework for Self-Supervised Learning of 3D point clouds. SeRP consists of encoder-decoder architecture that takes perturbed or corrupted point clouds as inputs and aims to reconstruct the original point cloud without corruption. The encoder learns the high-level latent representations of the points clouds in a low-dimensional subspace and recovers the original structure. In this work, we have used Transformers and PointNet-based Autoencoders. The proposed framework also addresses some of the limitations of Transformers-based Masked Autoencoders which are prone to leakage of location information and uneven information density. We trained our models on the complete ShapeNet dataset and evaluated them on ModelNet40 as a downstream classification task. We have shown that the pretrained models achieved 0.5-1% higher classification accuracies than the networks trained from scratch. Furthermore, we also proposed VASP: Vector-Quantized Autoencoder for Self-supervised Representation Learning for Point Clouds that employs Vector-Quantization for discrete representation learning for Transformer-based autoencoders.
Fine-tuning Wav2vec for Vocal-burst Emotion Recognition
Oct 01, 2022
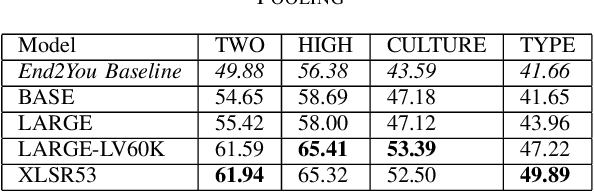
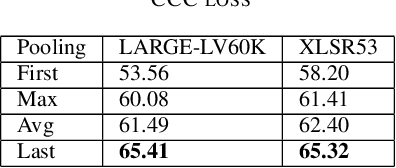
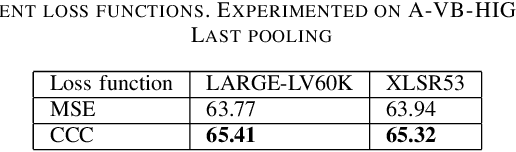
The ACII Affective Vocal Bursts (A-VB) competition introduces a new topic in affective computing, which is understanding emotional expression using the non-verbal sound of humans. We are familiar with emotion recognition via verbal vocal or facial expression. However, the vocal bursts such as laughs, cries, and signs, are not exploited even though they are very informative for behavior analysis. The A-VB competition comprises four tasks that explore non-verbal information in different spaces. This technical report describes the method and the result of SclabCNU Team for the tasks of the challenge. We achieved promising results compared to the baseline model provided by the organizers.
Bayesian Q-learning With Imperfect Expert Demonstrations
Oct 01, 2022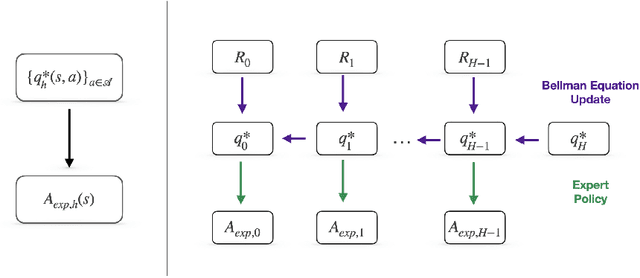
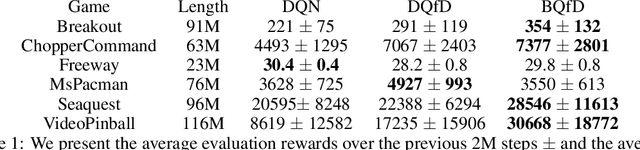
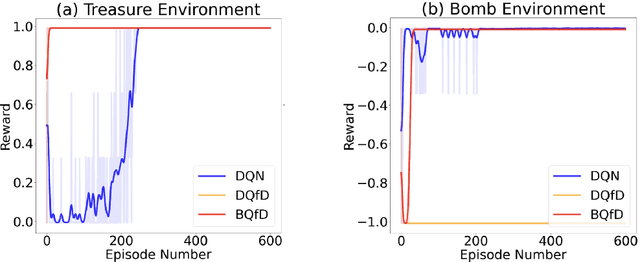

Guided exploration with expert demonstrations improves data efficiency for reinforcement learning, but current algorithms often overuse expert information. We propose a novel algorithm to speed up Q-learning with the help of a limited amount of imperfect expert demonstrations. The algorithm avoids excessive reliance on expert data by relaxing the optimal expert assumption and gradually reducing the usage of uninformative expert data. Experimentally, we evaluate our approach on a sparse-reward chain environment and six more complicated Atari games with delayed rewards. With the proposed methods, we can achieve better results than Deep Q-learning from Demonstrations (Hester et al., 2017) in most environments.
Optimizing Information-theoretical Generalization Bounds via Anisotropic Noise in SGLD
Nov 03, 2021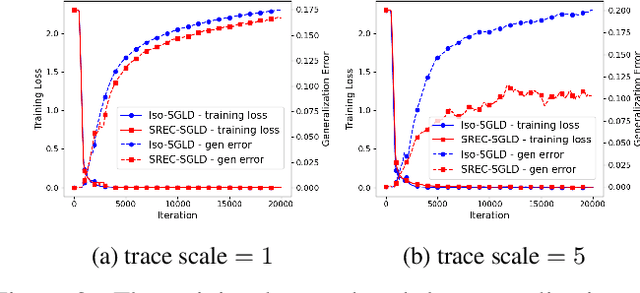
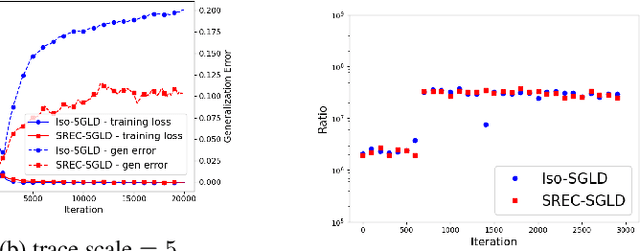
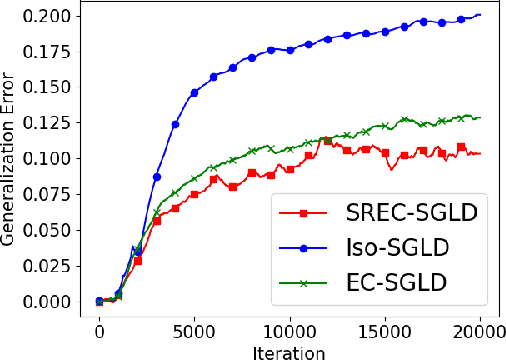
Recently, the information-theoretical framework has been proven to be able to obtain non-vacuous generalization bounds for large models trained by Stochastic Gradient Langevin Dynamics (SGLD) with isotropic noise. In this paper, we optimize the information-theoretical generalization bound by manipulating the noise structure in SGLD. We prove that with constraint to guarantee low empirical risk, the optimal noise covariance is the square root of the expected gradient covariance if both the prior and the posterior are jointly optimized. This validates that the optimal noise is quite close to the empirical gradient covariance. Technically, we develop a new information-theoretical bound that enables such an optimization analysis. We then apply matrix analysis to derive the form of optimal noise covariance. Presented constraint and results are validated by the empirical observations.
Modeling the Lighting in Scenes as Style for Auto White-Balance Correction
Oct 17, 2022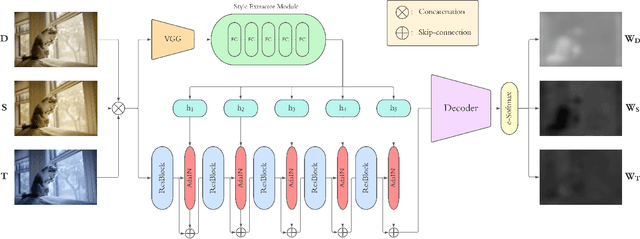
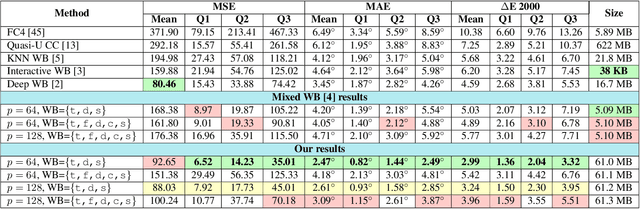

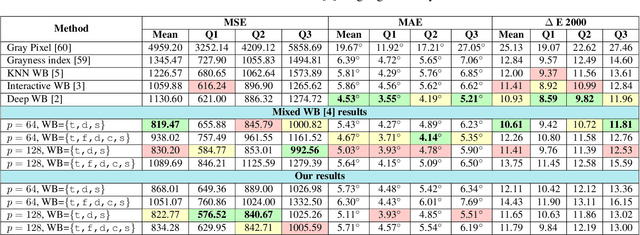
Style may refer to different concepts (e.g. painting style, hairstyle, texture, color, filter, etc.) depending on how the feature space is formed. In this work, we propose a novel idea of interpreting the lighting in the single- and multi-illuminant scenes as the concept of style. To verify this idea, we introduce an enhanced auto white-balance (AWB) method that models the lighting in single- and mixed-illuminant scenes as the style factor. Our AWB method does not require any illumination estimation step, yet contains a network learning to generate the weighting maps of the images with different WB settings. Proposed network utilizes the style information, extracted from the scene by a multi-head style extraction module. AWB correction is completed after blending these weighting maps and the scene. Experiments on single- and mixed-illuminant datasets demonstrate that our proposed method achieves promising correction results when compared to the recent works. This shows that the lighting in the scenes with multiple illuminations can be modeled by the concept of style. Source code and trained models are available on https://github.com/birdortyedi/lighting-as-style-awb-correction.
Risk-Sensitive Markov Decision Processes with Long-Run CVaR Criterion
Oct 17, 2022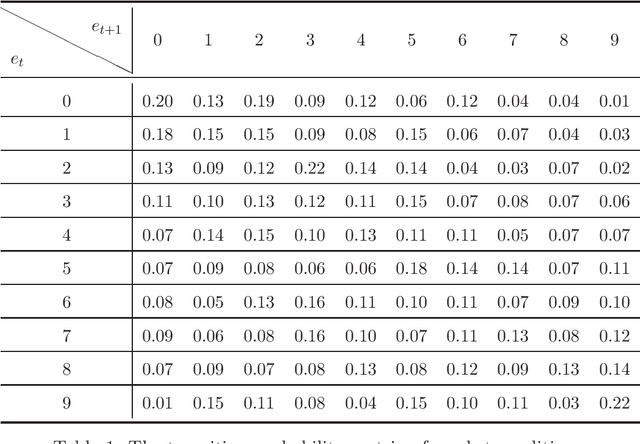
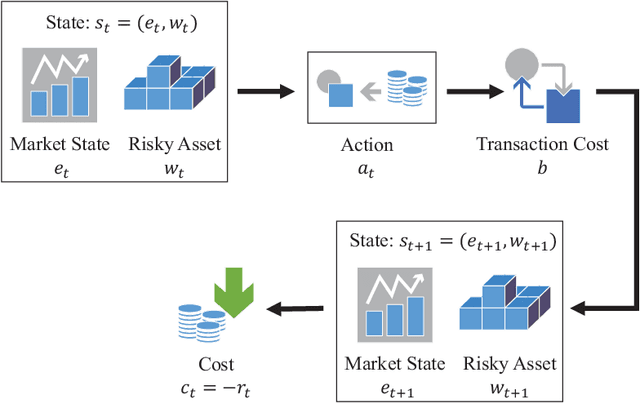

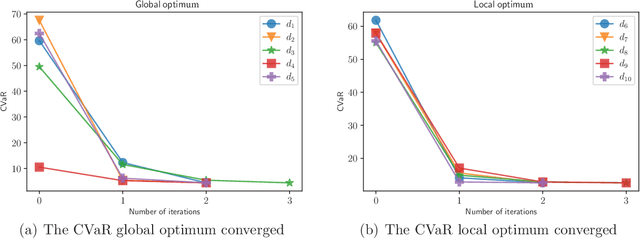
CVaR (Conditional Value at Risk) is a risk metric widely used in finance. However, dynamically optimizing CVaR is difficult since it is not a standard Markov decision process (MDP) and the principle of dynamic programming fails. In this paper, we study the infinite-horizon discrete-time MDP with a long-run CVaR criterion, from the view of sensitivity-based optimization. By introducing a pseudo CVaR metric, we derive a CVaR difference formula which quantifies the difference of long-run CVaR under any two policies. The optimality of deterministic policies is derived. We obtain a so-called Bellman local optimality equation for CVaR, which is a necessary and sufficient condition for local optimal policies and only necessary for global optimal policies. A CVaR derivative formula is also derived for providing more sensitivity information. Then we develop a policy iteration type algorithm to efficiently optimize CVaR, which is shown to converge to local optima in the mixed policy space. We further discuss some extensions including the mean-CVaR optimization and the maximization of CVaR. Finally, we conduct numerical experiments relating to portfolio management to demonstrate the main results. Our work may shed light on dynamically optimizing CVaR from a sensitivity viewpoint.
N-pad : Neighboring Pixel-based Industrial Anomaly Detection
Oct 17, 2022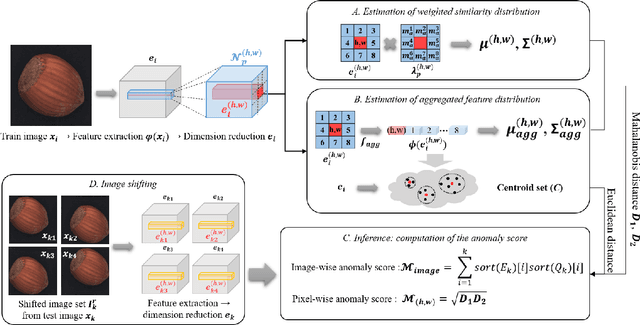
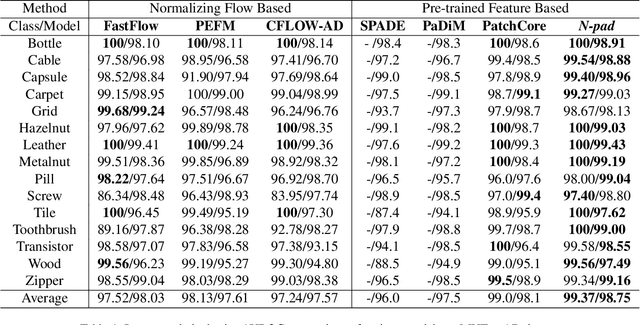

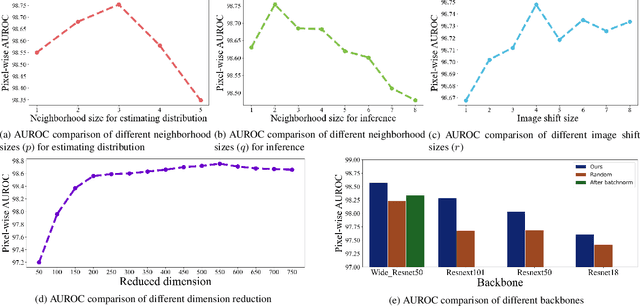
Identifying defects in the images of industrial products has been an important task to enhance quality control and reduce maintenance costs. In recent studies, industrial anomaly detection models were developed using pre-trained networks to learn nominal representations. To employ the relative positional information of each pixel, we present \textit{\textbf{N-pad}}, a novel method for anomaly detection and segmentation in a one-class learning setting that includes the neighborhood of the target pixel for model training and evaluation. Within the model architecture, pixel-wise nominal distributions are estimated by using the features of neighboring pixels with the target pixel to allow possible marginal misalignment. Moreover, the centroids from clusters of nominal features are identified as a representative nominal set. Accordingly, anomaly scores are inferred based on the Mahalanobis distances and Euclidean distances between the target pixel and the estimated distributions or the centroid set, respectively. Thus, we have achieved state-of-the-art performance in MVTec-AD with AUROC of 99.37 for anomaly detection and 98.75 for anomaly segmentation, reducing the error by 34\% compared to the next best performing model. Experiments in various settings further validate our model.
Document-aware Positional Encoding and Linguistic-guided Encoding for Abstractive Multi-document Summarization
Sep 13, 2022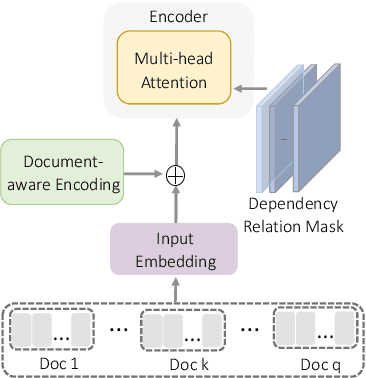
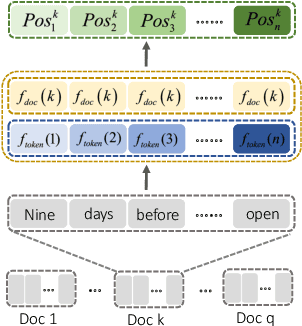
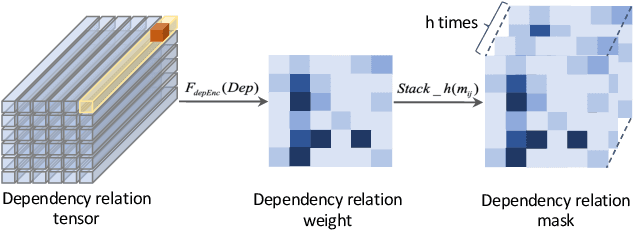
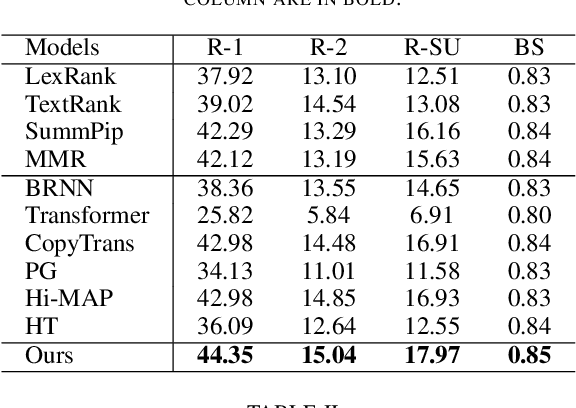
One key challenge in multi-document summarization is to capture the relations among input documents that distinguish between single document summarization (SDS) and multi-document summarization (MDS). Few existing MDS works address this issue. One effective way is to encode document positional information to assist models in capturing cross-document relations. However, existing MDS models, such as Transformer-based models, only consider token-level positional information. Moreover, these models fail to capture sentences' linguistic structure, which inevitably causes confusions in the generated summaries. Therefore, in this paper, we propose document-aware positional encoding and linguistic-guided encoding that can be fused with Transformer architecture for MDS. For document-aware positional encoding, we introduce a general protocol to guide the selection of document encoding functions. For linguistic-guided encoding, we propose to embed syntactic dependency relations into the dependency relation mask with a simple but effective non-linear encoding learner for feature learning. Extensive experiments show the proposed model can generate summaries with high quality.