 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dense Video Captioning Using Unsupervised Semantic Information
Dec 15, 2021
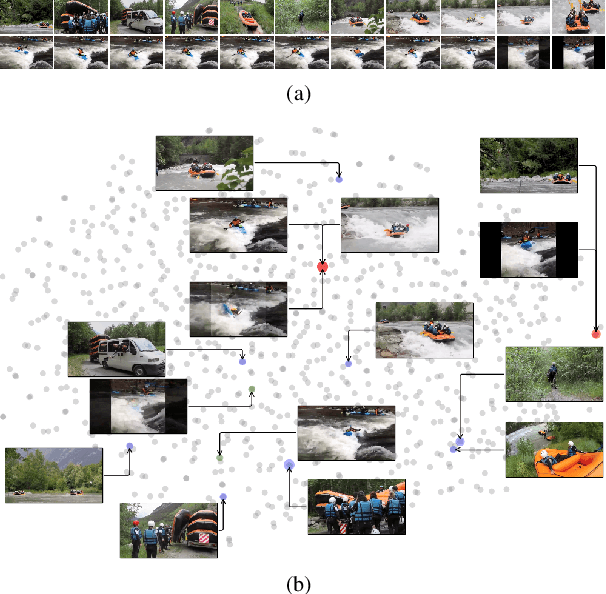
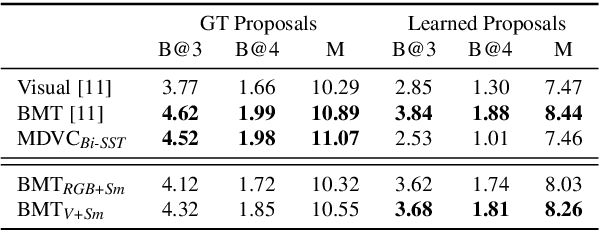
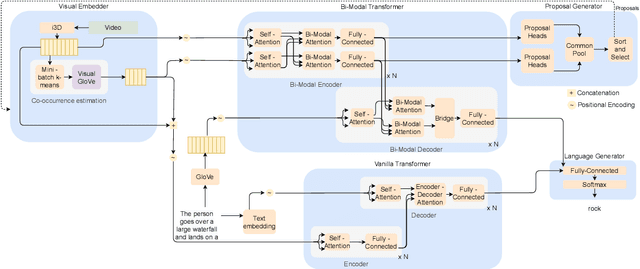
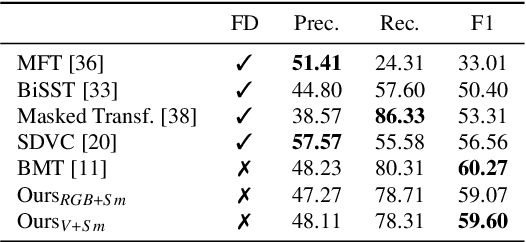
We introduce a method to learn unsupervised semantic visual information based on the premise that complex events (e.g., minutes) can be decomposed into simpler events (e.g., a few seconds), and that these simple events are shared across several complex events. We split a long video into short frame sequences to extract their latent representation with three-dimensional convolutional neural networks. A clustering method is used to group representations producing a visual codebook (i.e., a long video is represented by a sequence of integers given by the cluster labels). A dense representation is learned by encoding the co-occurrence probability matrix for the codebook entries. We demonstrate how this representation can leverage the performance of the dense video captioning task in a scenario with only visual features. As a result of this approach, we are able to replace the audio signal in the Bi-Modal Transformer (BMT) method and produce temporal proposals with comparable performance. Furthermore, we concatenate the visual signal with our descriptor in a vanilla transformer method to achieve state-of-the-art performance in captioning compared to the methods that explore only visual features, as well as a competitive performance with multi-modal methods. Our code is available at https://github.com/valterlej/dvcusi.
Toward Improving Health Literacy in Patient Education Materials with Neural Machine Translation Models
Sep 14, 2022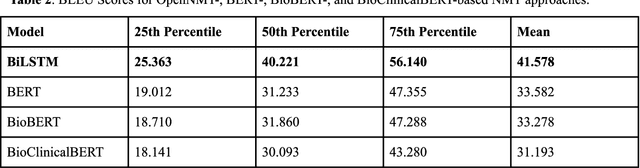
Health literacy is the central focus of Healthy People 2030, the fifth iteration of the U.S. national goals and objectives. People with low health literacy usually have trouble understanding health information, following post-visit instructions, and using prescriptions, which results in worse health outcomes and serious health disparities. In this study, we propose to leverage natural language processing techniques to improve health literacy in patient education materials by automatically translating illiterate languages in a given sentence. We scraped patient education materials from four online health information websites: MedlinePlus.gov, Drugs.com, Mayoclinic.org and Reddit.com. We trained and tested the state-of-the-art neural machine translation (NMT) models on a silver standard training dataset and a gold standard testing dataset, respectively. The experimental results showed that the Bidirectional Long Short-Term Memory (BiLSTM) NMT model outperformed Bidirectional Encoder Representations from Transformers (BERT)-based NMT models. We also verified the effectiveness of NMT models in translating health illiterate languages by comparing the ratio of health illiterate language in the sentence. The proposed NMT models were able to identify the correct complicated words and simplify into layman language while at the same time the models suffer from sentence completeness, fluency, readability, and have difficulty in translating certain medical terms.
Continual Learning of Long Topic Sequences in Neural Information Retrieval
Jan 10, 2022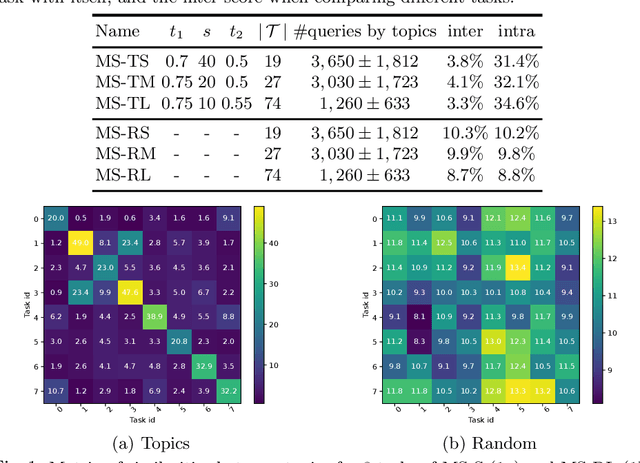
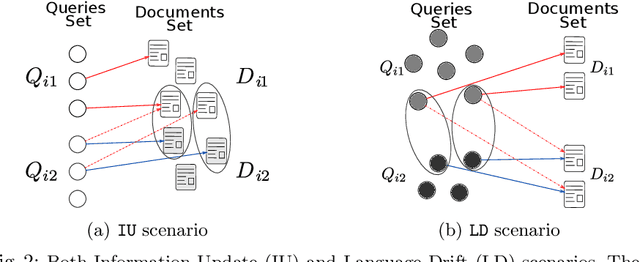
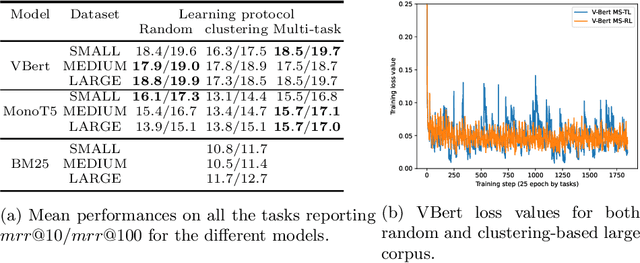
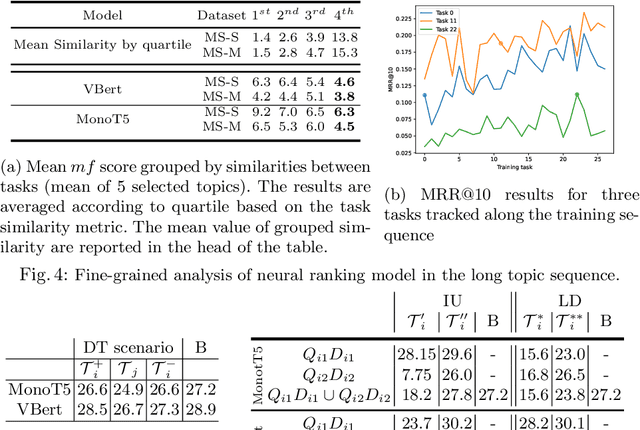
In information retrieval (IR) systems, trends and users' interests may change over time, altering either the distribution of requests or contents to be recommended. Since neural ranking approaches heavily depend on the training data, it is crucial to understand the transfer capacity of recent IR approaches to address new domains in the long term. In this paper, we first propose a dataset based upon the MSMarco corpus aiming at modeling a long stream of topics as well as IR property-driven controlled settings. We then in-depth analyze the ability of recent neural IR models while continually learning those streams. Our empirical study highlights in which particular cases catastrophic forgetting occurs (e.g., level of similarity between tasks, peculiarities on text length, and ways of learning models) to provide future directions in terms of model design.
Multimodal Analogical Reasoning over Knowledge Graphs
Oct 01, 2022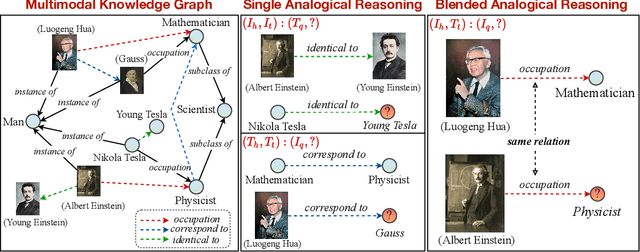

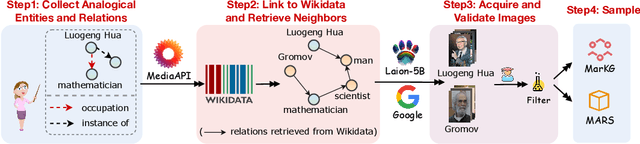
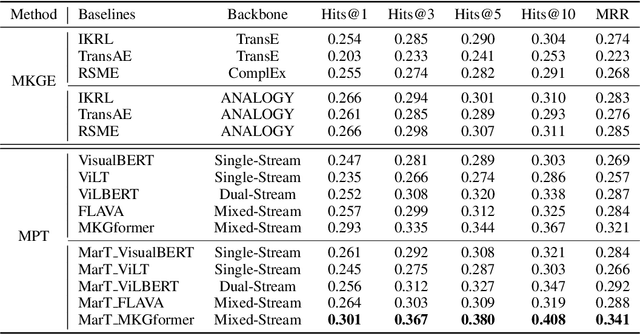
Analogical reasoning is fundamental to human cognition and holds an important place in various fields. However, previous studies mainly focus on single-modal analogical reasoning and ignore taking advantage of structure knowledge. Notably, the research in cognitive psychology has demonstrated that information from multimodal sources always brings more powerful cognitive transfer than single modality sources. To this end, we introduce the new task of multimodal analogical reasoning over knowledge graphs, which requires multimodal reasoning ability with the help of background knowledge. Specifically, we construct a Multimodal Analogical Reasoning dataSet (MARS) and a multimodal knowledge graph MarKG. We evaluate with multimodal knowledge graph embedding and pre-trained Transformer baselines, illustrating the potential challenges of the proposed task. We further propose a novel model-agnostic Multimodal analogical reasoning framework with Transformer (MarT) motivated by the structure mapping theory, which can obtain better performance.
Traffic-Aware Autonomous Driving with Differentiable Traffic Simulation
Oct 07, 2022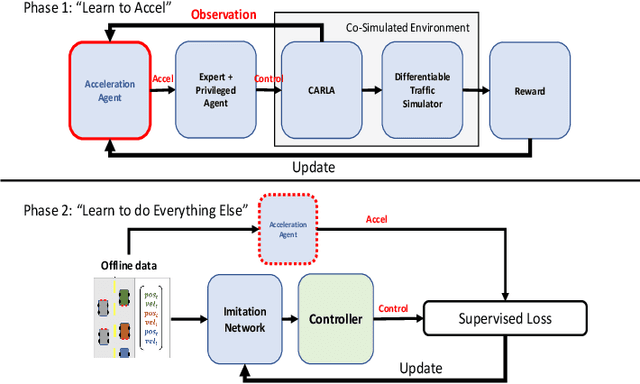
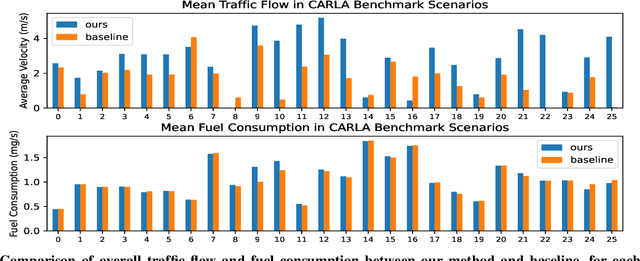
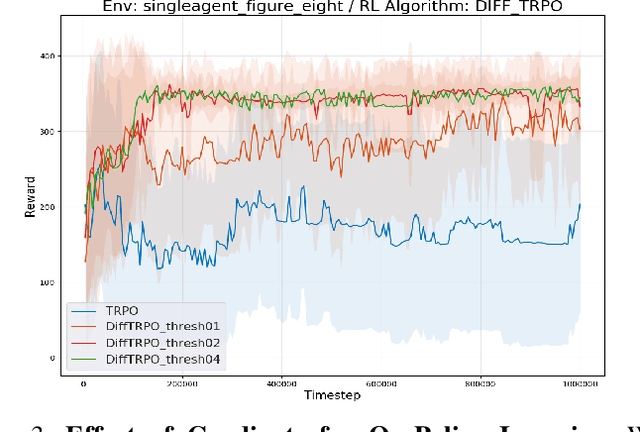
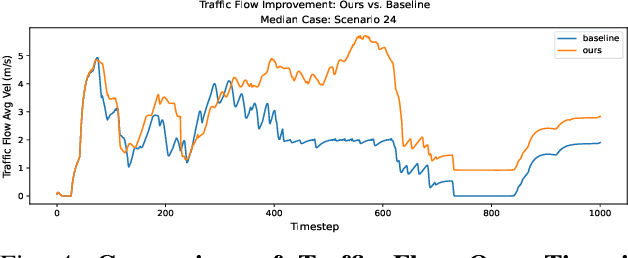
While there have been advancements in autonomous driving control and traffic simulation, there have been little to no works exploring the unification of both with deep learning. Works in both areas seem to focus on entirely different exclusive problems, yet traffic and driving have inherent semantic relations in the real world. In this paper, we present a generalizable distillation-style method for traffic-informed imitation learning that directly optimizes a autonomous driving policy for the overall benefit of faster traffic flow and lower energy consumption. We capitalize on improving the arbitrarily defined supervision of speed control in imitation learning systems, as most driving research focus on perception and steering. Moreover, our method addresses the lack of co-simulation between traffic and driving simulators and lays groundwork for directly involving traffic simulation with autonomous driving in future work. Our results show that, with information from traffic simulation involved in supervision of imitation learning methods, an autonomous vehicle can learn how to accelerate in a fashion that is beneficial for traffic flow and overall energy consumption for all nearby vehicles.
Time-Space Transformers for Video Panoptic Segmentation
Oct 07, 2022
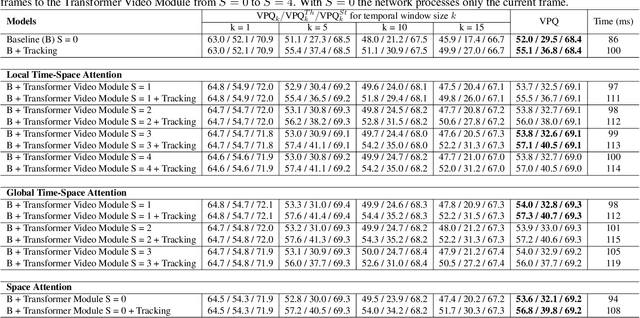
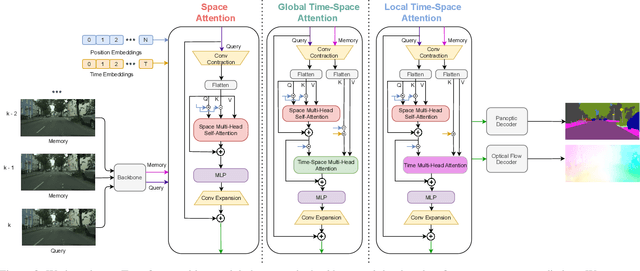
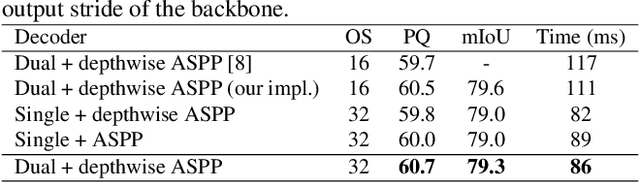
We propose a novel solution for the task of video panoptic segmentation, that simultaneously predicts pixel-level semantic and instance segmentation and generates clip-level instance tracks. Our network, named VPS-Transformer, with a hybrid architecture based on the state-of-the-art panoptic segmentation network Panoptic-DeepLab, combines a convolutional architecture for single-frame panoptic segmentation and a novel video module based on an instantiation of the pure Transformer block. The Transformer, equipped with attention mechanisms, models spatio-temporal relations between backbone output features of current and past frames for more accurate and consistent panoptic estimates. As the pure Transformer block introduces large computation overhead when processing high resolution images, we propose a few design changes for a more efficient compute. We study how to aggregate information more effectively over the space-time volume and we compare several variants of the Transformer block with different attention schemes. Extensive experiments on the Cityscapes-VPS dataset demonstrate that our best model improves the temporal consistency and video panoptic quality by a margin of 2.2%, with little extra computation.
SecureFedYJ: a safe feature Gaussianization protocol for Federated Learning
Oct 04, 2022

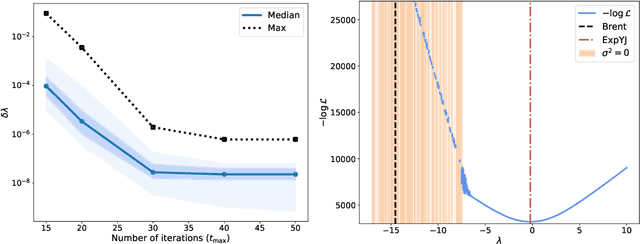
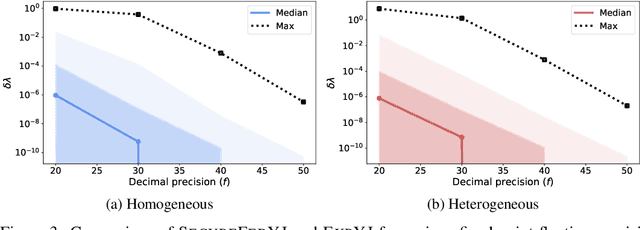
The Yeo-Johnson (YJ) transformation is a standard parametrized per-feature unidimensional transformation often used to Gaussianize features in machine learning. In this paper, we investigate the problem of applying the YJ transformation in a cross-silo Federated Learning setting under privacy constraints. For the first time, we prove that the YJ negative log-likelihood is in fact convex, which allows us to optimize it with exponential search. We numerically show that the resulting algorithm is more stable than the state-of-the-art approach based on the Brent minimization method. Building on this simple algorithm and Secure Multiparty Computation routines, we propose SecureFedYJ, a federated algorithm that performs a pooled-equivalent YJ transformation without leaking more information than the final fitted parameters do. Quantitative experiments on real data demonstrate that, in addition to being secure, our approach reliably normalizes features across silos as well as if data were pooled, making it a viable approach for safe federated feature Gaussianization.
Distilling Style from Image Pairs for Global Forward and Inverse Tone Mapping
Oct 04, 2022
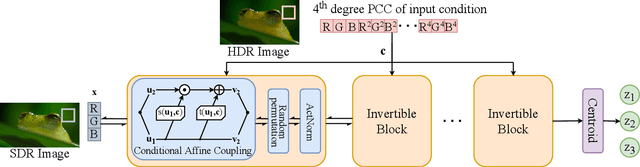


Many image enhancement or editing operations, such as forward and inverse tone mapping or color grading, do not have a unique solution, but instead a range of solutions, each representing a different style. Despite this, existing learning-based methods attempt to learn a unique mapping, disregarding this style. In this work, we show that information about the style can be distilled from collections of image pairs and encoded into a 2- or 3-dimensional vector. This gives us not only an efficient representation but also an interpretable latent space for editing the image style. We represent the global color mapping between a pair of images as a custom normalizing flow, conditioned on a polynomial basis of the pixel color. We show that such a network is more effective than PCA or VAE at encoding image style in low-dimensional space and lets us obtain an accuracy close to 40 dB, which is about 7-10 dB improvement over the state-of-the-art methods.
Hyperbolic Deep Reinforcement Learning
Oct 04, 2022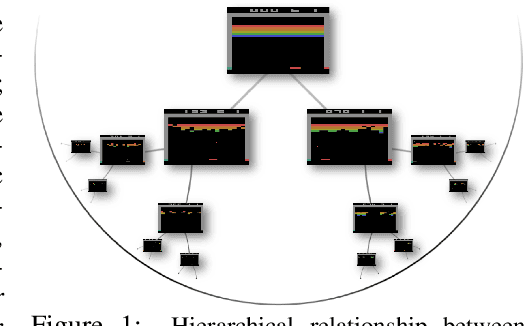
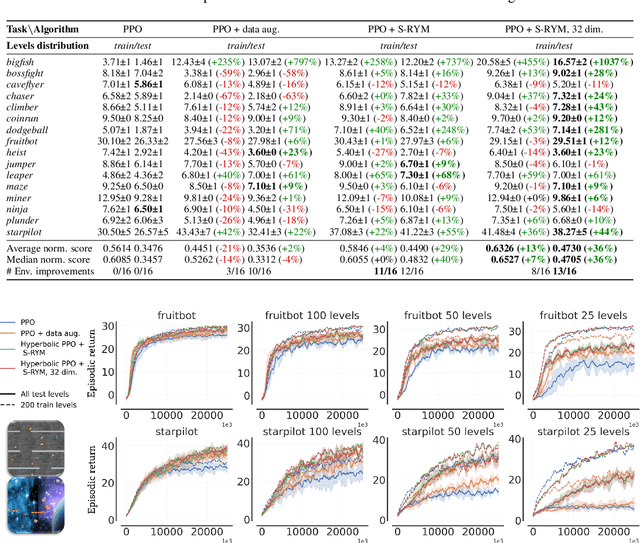
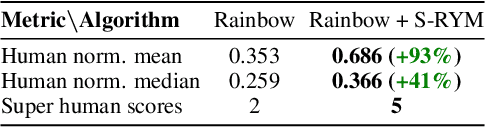
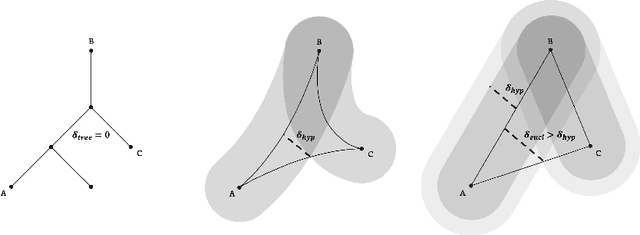
We propose a new class of deep reinforcement learning (RL) algorithms that model latent representations in hyperbolic space. Sequential decision-making requires reasoning about the possible future consequences of current behavior. Consequently, capturing the relationship between key evolving features for a given task is conducive to recovering effective policies. To this end, hyperbolic geometry provides deep RL models with a natural basis to precisely encode this inherently hierarchical information. However, applying existing methodologies from the hyperbolic deep learning literature leads to fatal optimization instabilities due to the non-stationarity and variance characterizing RL gradient estimators. Hence, we design a new general method that counteracts such optimization challenges and enables stable end-to-end learning with deep hyperbolic representations. We empirically validate our framework by applying it to popular on-policy and off-policy RL algorithms on the Procgen and Atari 100K benchmarks, attaining near universal performance and generalization benefits. Given its natural fit, we hope future RL research will consider hyperbolic representations as a standard tool.
LMQFormer: A Laplace-Prior-Guided Mask Query Transformer for Lightweight Snow Removal
Oct 12, 2022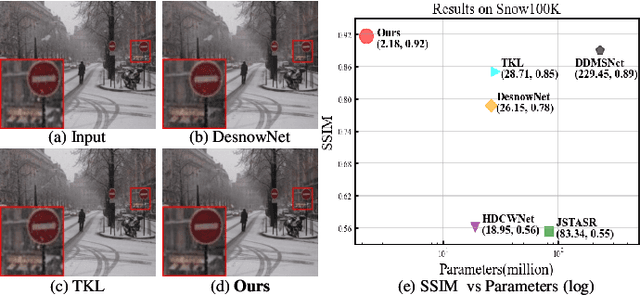



Snow removal aims to locate snow areas and recover clean images without repairing traces. Unlike the regularity and semitransparency of rain, snow with various patterns and degradations seriously occludes the background. As a result, the state-of-the-art snow removal methods usually retains a large parameter size. In this paper, we propose a lightweight but high-efficient snow removal network called Laplace Mask Query Transformer (LMQFormer). Firstly, we present a Laplace-VQVAE to generate a coarse mask as prior knowledge of snow. Instead of using the mask in dataset, we aim at reducing both the information entropy of snow and the computational cost of recovery. Secondly, we design a Mask Query Transformer (MQFormer) to remove snow with the coarse mask, where we use two parallel encoders and a hybrid decoder to learn extensive snow features under lightweight requirements. Thirdly, we develop a Duplicated Mask Query Attention (DMQA) that converts the coarse mask into a specific number of queries, which constraint the attention areas of MQFormer with reduced parameters. Experimental results in popular datasets have demonstrated the efficiency of our proposed model, which achieves the state-of-the-art snow removal quality with significantly reduced parameters and the lowest running time.