 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Prototypical Model with Novel Information-theoretic Loss Function for Generalized Zero Shot Learning
Dec 06, 2021
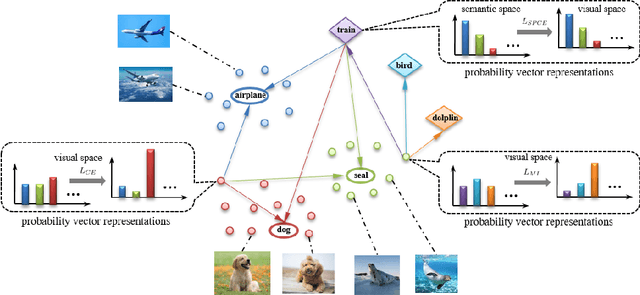
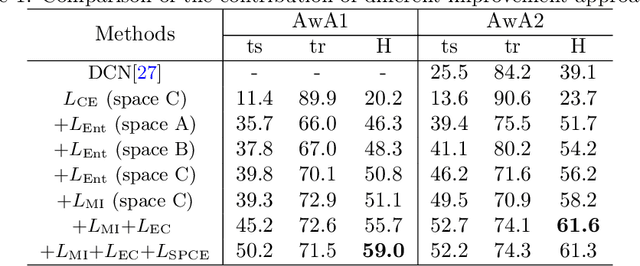
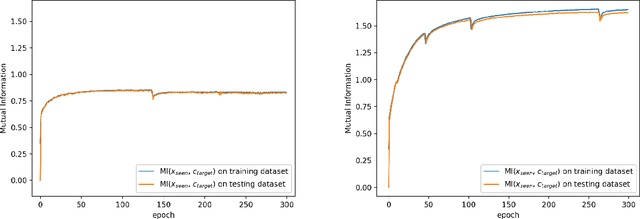
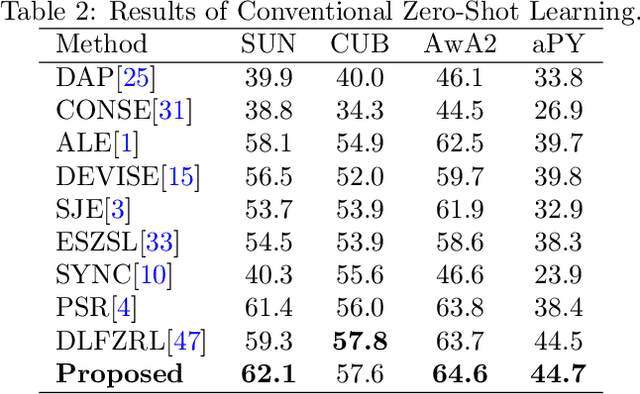
Generalized zero shot learning (GZSL) is still a technical challenge of deep learning as it has to recognize both source and target classes without data from target classes. To preserve the semantic relation between source and target classes when only trained with data from source classes, we address the quantification of the knowledge transfer and semantic relation from an information-theoretic viewpoint. To this end, we follow the prototypical model and format the variables of concern as a probability vector. Leveraging on the proposed probability vector representation, the information measurement such as mutual information and entropy, can be effectively evaluated with simple closed forms. We discuss the choice of common embedding space and distance function when using the prototypical model. Then We propose three information-theoretic loss functions for deterministic GZSL model: a mutual information loss to bridge seen data and target classes; an uncertainty-aware entropy constraint loss to prevent overfitting when using seen data to learn the embedding of target classes; a semantic preserving cross entropy loss to preserve the semantic relation when mapping the semantic representations to the common space. Simulation shows that, as a deterministic model, our proposed method obtains state of the art results on GZSL benchmark datasets. We achieve 21%-64% improvements over the baseline model -- deep calibration network (DCN) and for the first time demonstrate a deterministic model can perform as well as generative ones. Moreover, our proposed model is compatible with generative models. Simulation studies show that by incorporating with f-CLSWGAN, we obtain comparable results compared with advanced generative models.
DeePhy: On Deepfake Phylogeny
Sep 19, 2022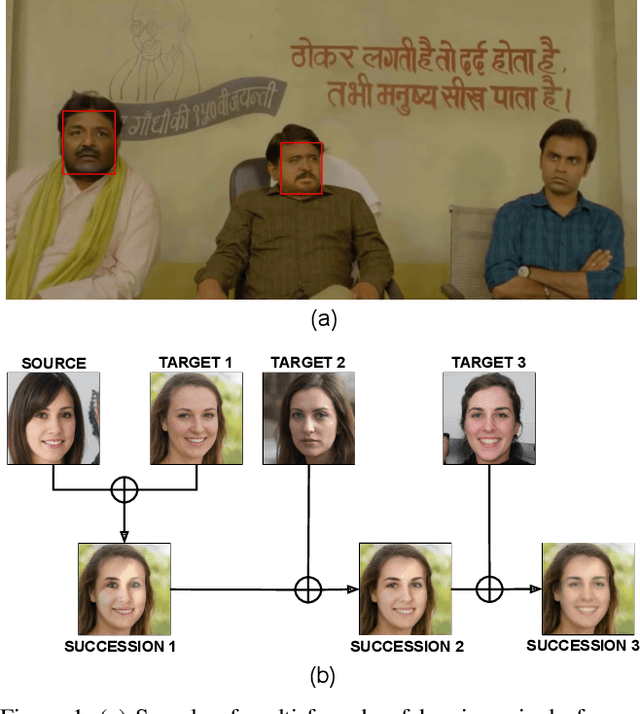
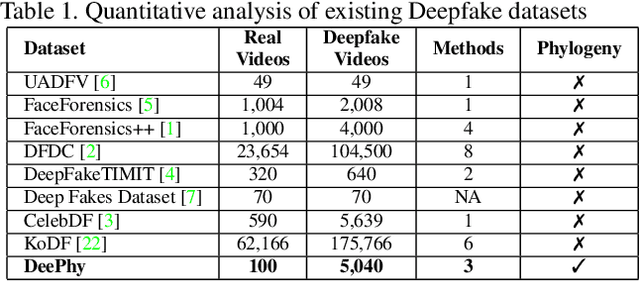

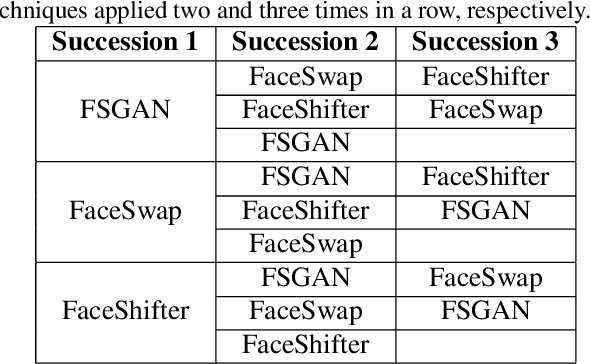
Deepfake refers to tailored and synthetically generated videos which are now prevalent and spreading on a large scale, threatening the trustworthiness of the information available online. While existing datasets contain different kinds of deepfakes which vary in their generation technique, they do not consider progression of deepfakes in a "phylogenetic" manner. It is possible that an existing deepfake face is swapped with another face. This process of face swapping can be performed multiple times and the resultant deepfake can be evolved to confuse the deepfake detection algorithms. Further, many databases do not provide the employed generative model as target labels. Model attribution helps in enhancing the explainability of the detection results by providing information on the generative model employed. In order to enable the research community to address these questions, this paper proposes DeePhy, a novel Deepfake Phylogeny dataset which consists of 5040 deepfake videos generated using three different generation techniques. There are 840 videos of one-time swapped deepfakes, 2520 videos of two-times swapped deepfakes and 1680 videos of three-times swapped deepfakes. With over 30 GBs in size, the database is prepared in over 1100 hours using 18 GPUs of 1,352 GB cumulative memory. We also present the benchmark on DeePhy dataset using six deepfake detection algorithms. The results highlight the need to evolve the research of model attribution of deepfakes and generalize the process over a variety of deepfake generation techniques. The database is available at: http://iab-rubric.org/deephy-database
Information-Bottleneck-Based Behavior Representation Learning for Multi-agent Reinforcement learning
Sep 29, 2021
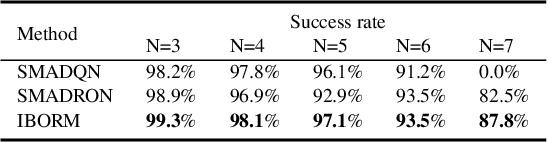
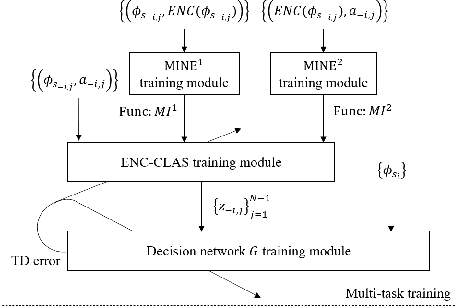
In multi-agent deep reinforcement learning, extracting sufficient and compact information of other agents is critical to attain efficient convergence and scalability of an algorithm. In canonical frameworks, distilling of such information is often done in an implicit and uninterpretable manner, or explicitly with cost functions not able to reflect the relationship between information compression and utility in representation. In this paper, we present Information-Bottleneck-based Other agents' behavior Representation learning for Multi-agent reinforcement learning (IBORM) to explicitly seek low-dimensional mapping encoder through which a compact and informative representation relevant to other agents' behaviors is established. IBORM leverages the information bottleneck principle to compress observation information, while retaining sufficient information relevant to other agents' behaviors used for cooperation decision. Empirical results have demonstrated that IBORM delivers the fastest convergence rate and the best performance of the learned policies, as compared with implicit behavior representation learning and explicit behavior representation learning without explicitly considering information compression and utility.
Russian Web Tables: A Public Corpus of Web Tables for Russian Language Based on Wikipedia
Oct 03, 2022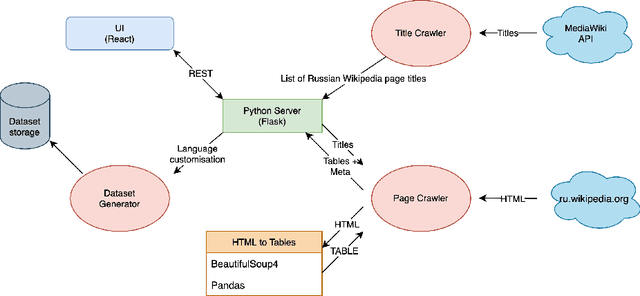
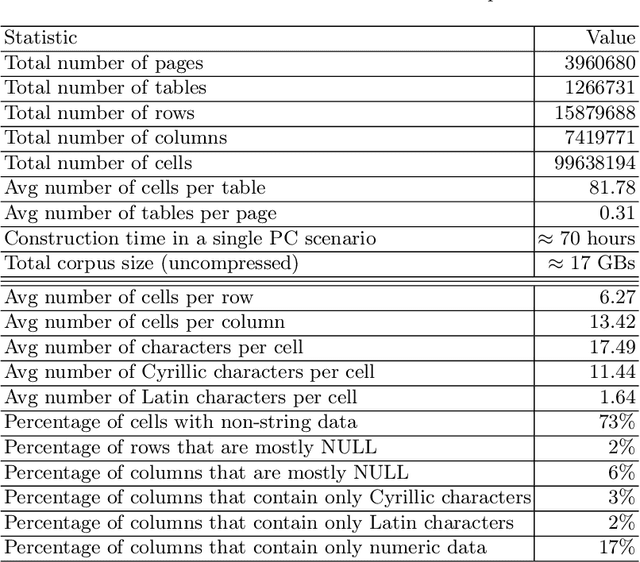
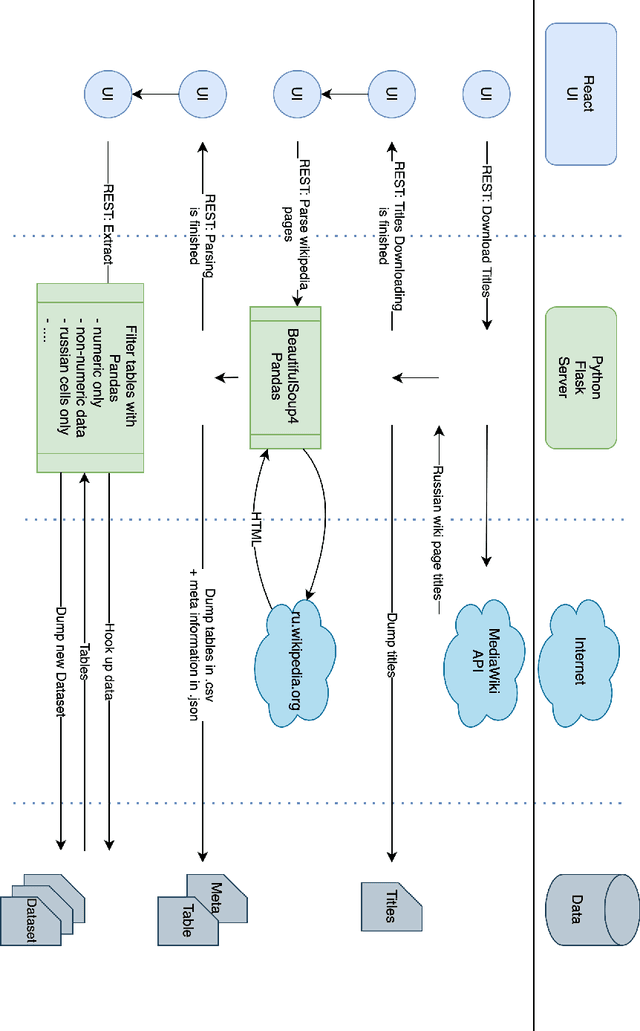
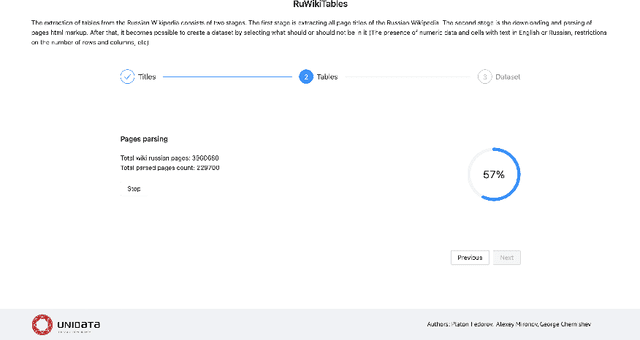
Corpora that contain tabular data such as WebTables are a vital resource for the academic community. Essentially, they are the backbone of any modern research in information management. They are used for various tasks of data extraction, knowledge base construction, question answering, column semantic type detection and many other. Such corpora are useful not only as a source of data, but also as a base for building test datasets. So far, there were no such corpora for the Russian language and this seriously hindered research in the aforementioned areas. In this paper, we present the first corpus of Web tables created specifically out of Russian language material. It was built via a special toolkit we have developed to crawl the Russian Wikipedia. Both the corpus and the toolkit are open-source and publicly available. Finally, we present a short study that describes Russian Wikipedia tables and their statistics.
Machine Learning-based Automatic Annotation and Detection of COVID-19 Fake News
Sep 07, 2022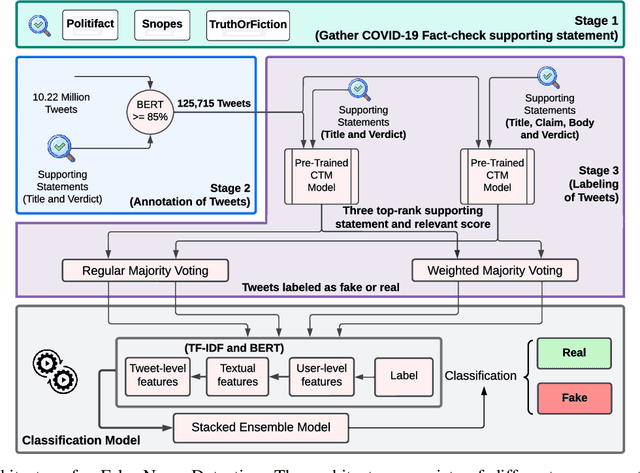
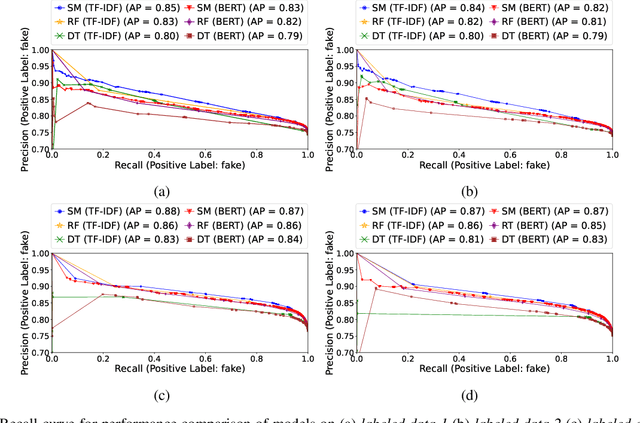
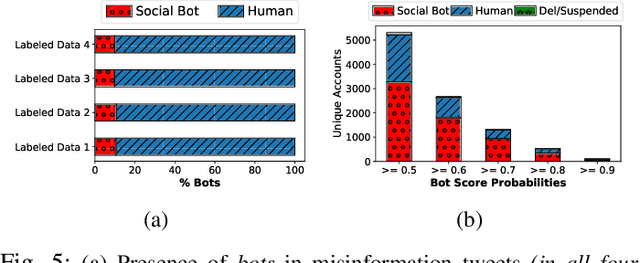
COVID-19 impacted every part of the world, although the misinformation about the outbreak traveled faster than the virus. Misinformation spread through online social networks (OSN) often misled people from following correct medical practices. In particular, OSN bots have been a primary source of disseminating false information and initiating cyber propaganda. Existing work neglects the presence of bots that act as a catalyst in the spread and focuses on fake news detection in 'articles shared in posts' rather than the post (textual) content. Most work on misinformation detection uses manually labeled datasets that are hard to scale for building their predictive models. In this research, we overcome this challenge of data scarcity by proposing an automated approach for labeling data using verified fact-checked statements on a Twitter dataset. In addition, we combine textual features with user-level features (such as followers count and friends count) and tweet-level features (such as number of mentions, hashtags and urls in a tweet) to act as additional indicators to detect misinformation. Moreover, we analyzed the presence of bots in tweets and show that bots change their behavior over time and are most active during the misinformation campaign. We collected 10.22 Million COVID-19 related tweets and used our annotation model to build an extensive and original ground truth dataset for classification purposes. We utilize various machine learning models to accurately detect misinformation and our best classification model achieves precision (82%), recall (96%), and false positive rate (3.58%). Also, our bot analysis indicates that bots generated approximately 10% of misinformation tweets. Our methodology results in substantial exposure of false information, thus improving the trustworthiness of information disseminated through social media platforms.
Scaling Up Probabilistic Circuits by Latent Variable Distillation
Oct 10, 2022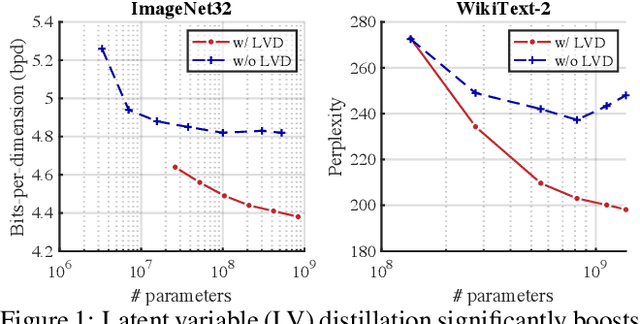
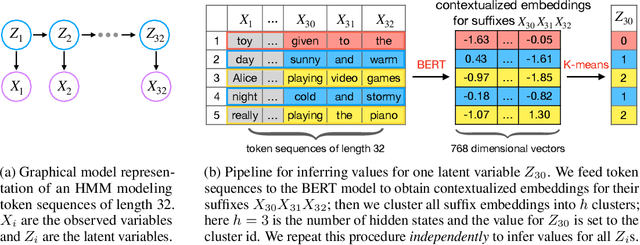
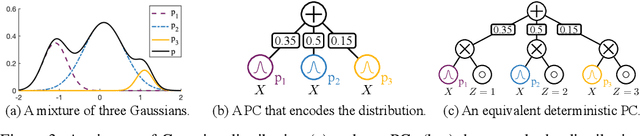
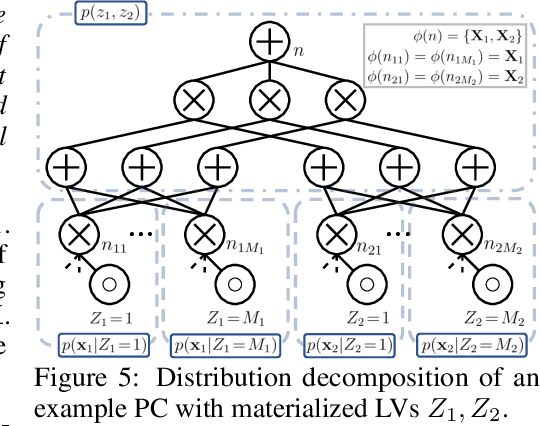
Probabilistic Circuits (PCs) are a unified framework for tractable probabilistic models that support efficient computation of various probabilistic queries (e.g., marginal probabilities). One key challenge is to scale PCs to model large and high-dimensional real-world datasets: we observe that as the number of parameters in PCs increases, their performance immediately plateaus. This phenomenon suggests that the existing optimizers fail to exploit the full expressive power of large PCs. We propose to overcome such bottleneck by latent variable distillation: we leverage the less tractable but more expressive deep generative models to provide extra supervision over the latent variables of PCs. Specifically, we extract information from Transformer-based generative models to assign values to latent variables of PCs, providing guidance to PC optimizers. Experiments on both image and language modeling benchmarks (e.g., ImageNet and WikiText-2) show that latent variable distillation substantially boosts the performance of large PCs compared to their counterparts without latent variable distillation. In particular, on the image modeling benchmarks, PCs achieve competitive performance against some of the widely-used deep generative models, including variational autoencoders and flow-based models, opening up new avenues for tractable generative modeling.
A Memory Transformer Network for Incremental Learning
Oct 10, 2022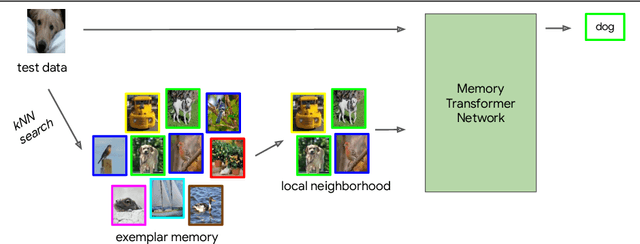
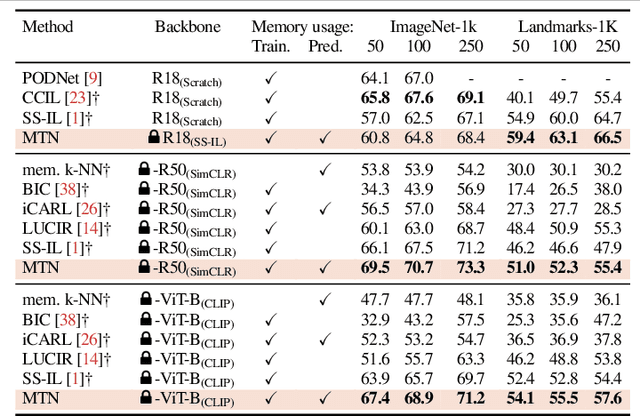
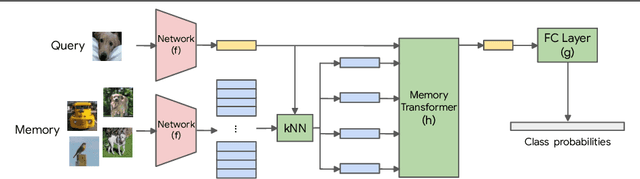
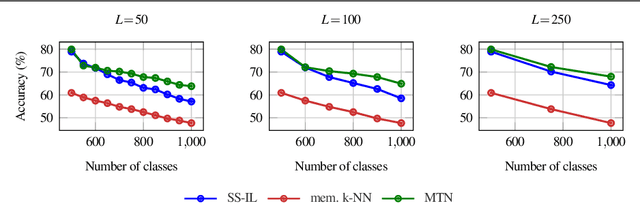
We study class-incremental learning, a training setup in which new classes of data are observed over time for the model to learn from. Despite the straightforward problem formulation, the naive application of classification models to class-incremental learning results in the "catastrophic forgetting" of previously seen classes. One of the most successful existing methods has been the use of a memory of exemplars, which overcomes the issue of catastrophic forgetting by saving a subset of past data into a memory bank and utilizing it to prevent forgetting when training future tasks. In our paper, we propose to enhance the utilization of this memory bank: we not only use it as a source of additional training data like existing works but also integrate it in the prediction process explicitly.Our method, the Memory Transformer Network (MTN), learns how to combine and aggregate the information from the nearest neighbors in the memory with a transformer to make more accurate predictions. We conduct extensive experiments and ablations to evaluate our approach. We show that MTN achieves state-of-the-art performance on the challenging ImageNet-1k and Google-Landmarks-1k incremental learning benchmarks.
An NLoS-based Enhanced Sensing Method for MmWave Communication System
Oct 10, 2022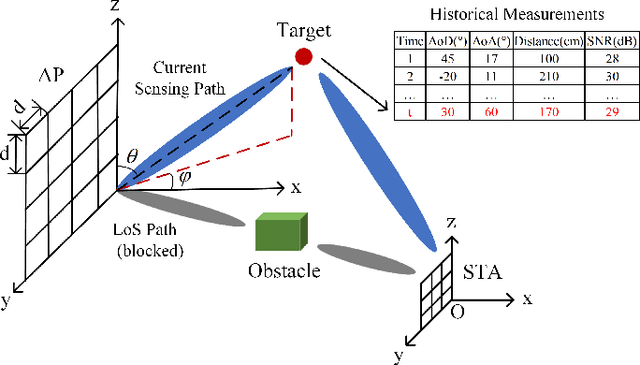
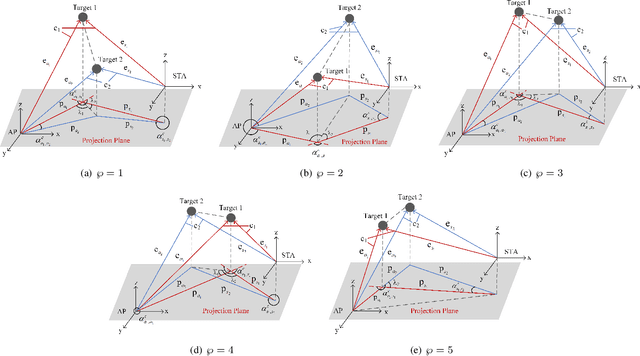
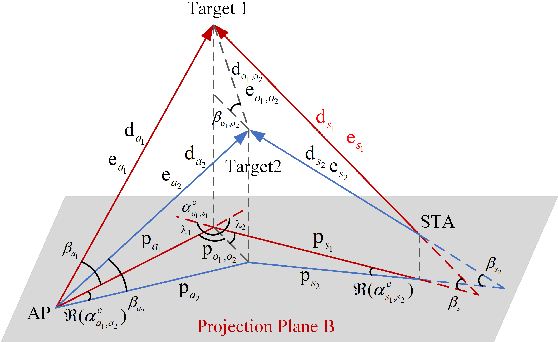
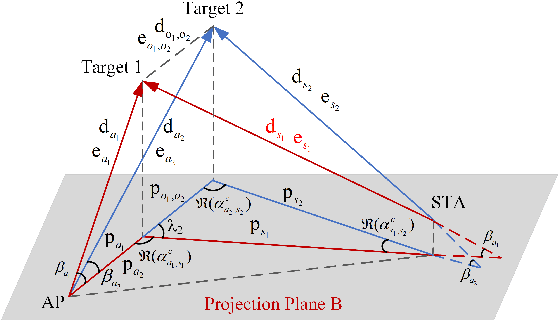
The millimeter-wave (mmWave)-based Wi-Fi sensing technology has recently attracted extensive attention since it provides a possibility to realize higher sensing accuracy. However, current works mainly concentrate on sensing scenarios where the line-of-sight (LoS) path exists, which significantly limits their applications. To address the problem, we propose an enhanced mmWave sensing algorithm in the 3D non-line-of-sight environment (mm3NLoS), aiming to sense the direction and distance of the target when the LoS path is weak or blocked. Specifically, we first adopt the directional beam to estimate the azimuth/elevation angle of arrival (AoA) and angle of departure (AoD) of the reflection path. Then, the distance of the related path is measured by the fine timing measurement protocol. Finally, we transform the AoA and AoD of the multiple non-line-of-sight (NLoS) paths into the direction vector and then obtain the information of targets based on the geometric relationship. The simulation results demonstrate that mm3NLoS can achieve a centimeter-level error with a 2m spacing. Compared to the prior work, it can significantly reduce the performance degradation under the NLoS condition.
Distill the Image to Nowhere: Inversion Knowledge Distillation for Multimodal Machine Translation
Oct 10, 2022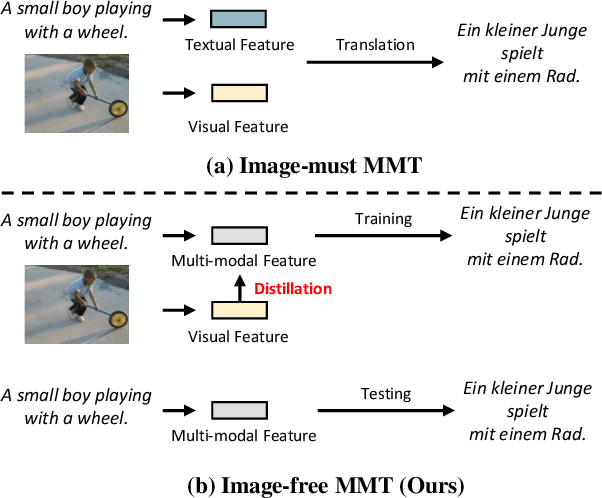
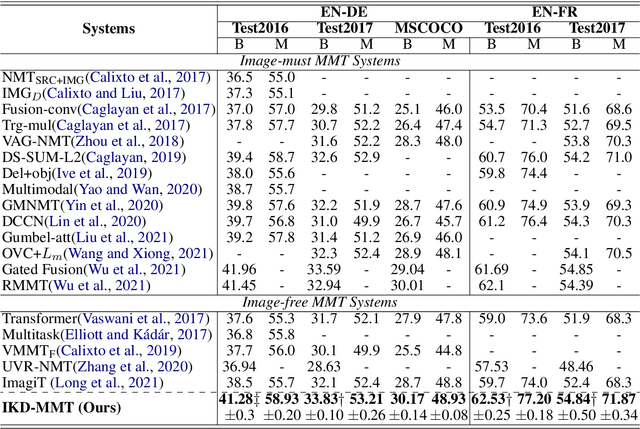
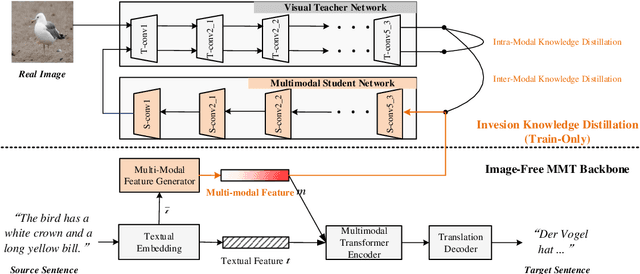
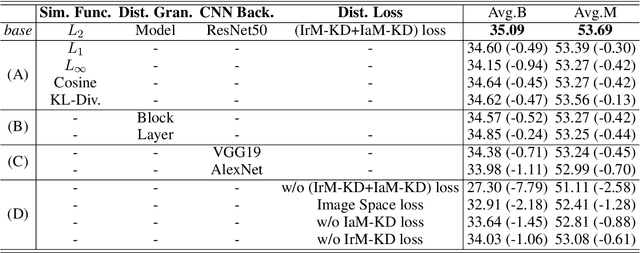
Past works on multimodal machine translation (MMT) elevate bilingual setup by incorporating additional aligned vision information. However, an image-must requirement of the multimodal dataset largely hinders MMT's development -- namely that it demands an aligned form of [image, source text, target text]. This limitation is generally troublesome during the inference phase especially when the aligned image is not provided as in the normal NMT setup. Thus, in this work, we introduce IKD-MMT, a novel MMT framework to support the image-free inference phase via an inversion knowledge distillation scheme. In particular, a multimodal feature generator is executed with a knowledge distillation module, which directly generates the multimodal feature from (only) source texts as the input. While there have been a few prior works entertaining the possibility to support image-free inference for machine translation, their performances have yet to rival the image-must translation. In our experiments, we identify our method as the first image-free approach to comprehensively rival or even surpass (almost) all image-must frameworks, and achieved the state-of-the-art result on the often-used Multi30k benchmark. Our code and data are available at: https://github.com/pengr/IKD-mmt/tree/master..
3D Single-pixel imaging with active sampling patterns and learning based reconstruction
Sep 06, 2022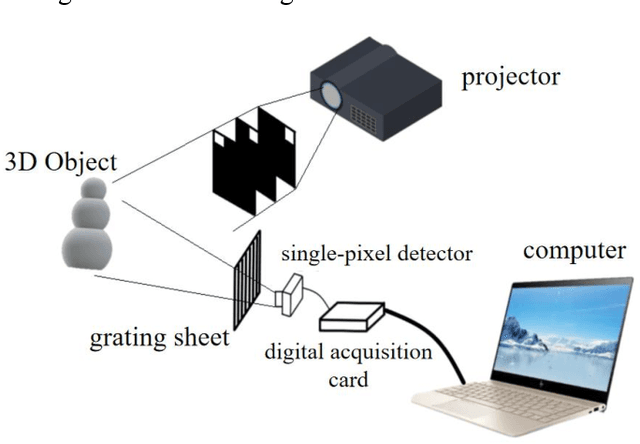
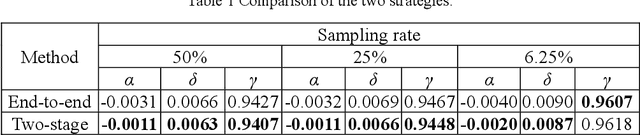

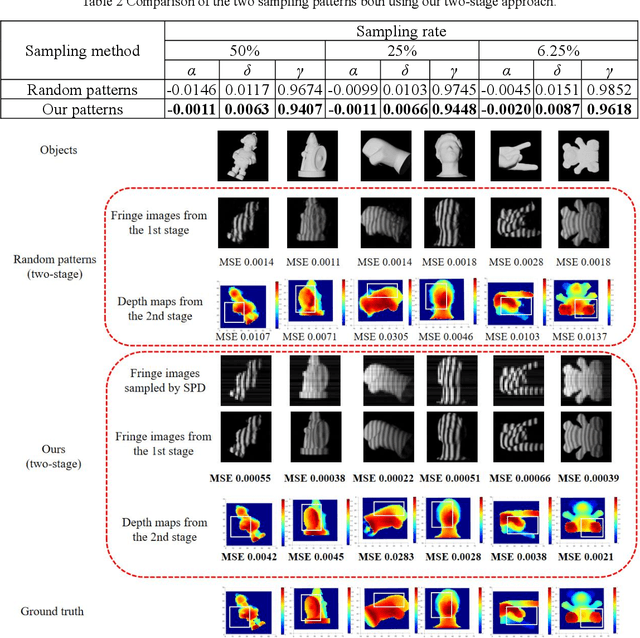
Single-pixel imaging (SPI) is significant for applications constrained by transmission bandwidth or lighting band, where 3D SPI can be further realized through capturing signals carrying depth. Sampling strategy and reconstruction algorithm are the key issues of SPI. Traditionally, random patterns are often adopted for sampling, but this blindly passive strategy requires a high sampling rate, and even so, it is difficult to develop a reconstruction algorithm that can maintain higher accuracy and robustness. In this paper, an active strategy is proposed to perform sampling with targeted scanning by designed patterns, from which the spatial information can be easily reordered well. Then, deep learning methods are introduced further to achieve 3D reconstruction, and the ability of deep learning to reconstruct desired information under low sampling rates are analyzed. Abundant experiments verify that our method improves the precision of SPI even if the sampling rate is very low, which has the potential to be extended flexibly in similar systems according to practical needs.