 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Split-KalmanNet: A Robust Model-Based Deep Learning Approach for SLAM
Oct 18, 2022
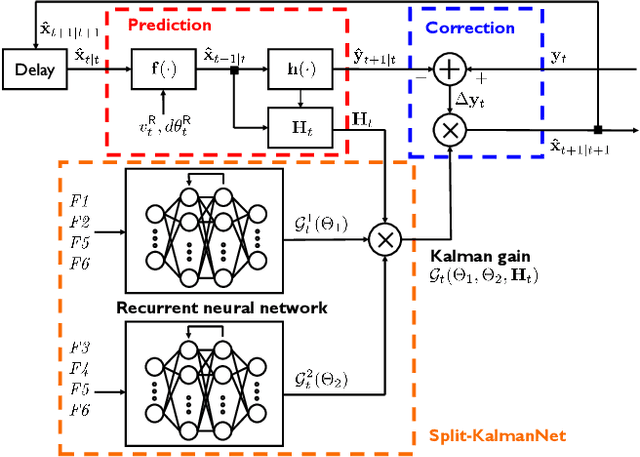
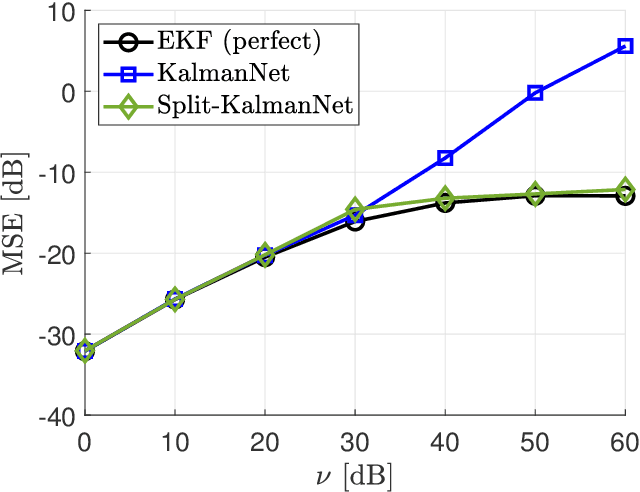
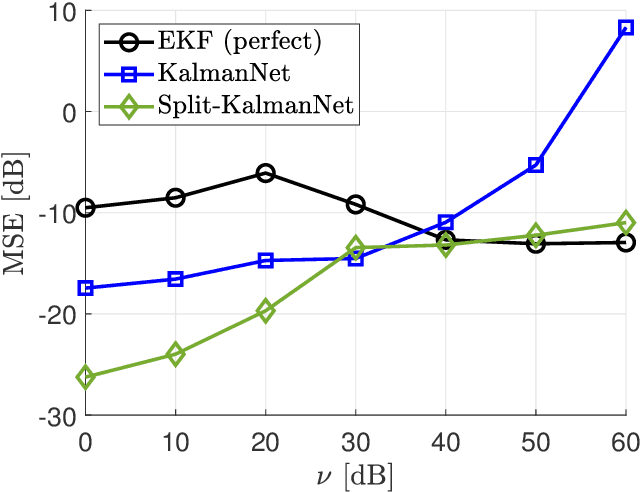
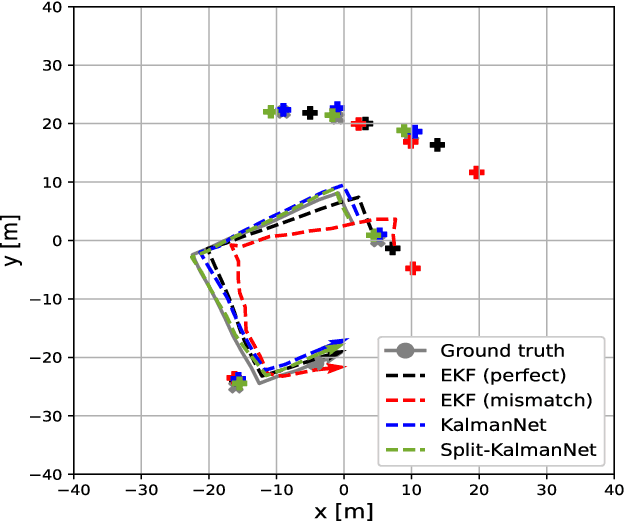
Simultaneous localization and mapping (SLAM) is a method that constructs a map of an unknown environment and localizes the position of a moving agent on the map simultaneously. Extended Kalman filter (EKF) has been widely adopted as a low complexity solution for online SLAM, which relies on a motion and measurement model of the moving agent. In practice, however, acquiring precise information about these models is very challenging, and the model mismatch effect causes severe performance loss in SLAM. In this paper, inspired by the recently proposed KalmanNet, we present a robust EKF algorithm using the power of deep learning for online SLAM, referred to as Split-KalmanNet. The key idea of Split-KalmanNet is to compute the Kalman gain using the Jacobian matrix of a measurement function and two recurrent neural networks (RNNs). The two RNNs independently learn the covariance matrices for a prior state estimate and the innovation from data. The proposed split structure in the computation of the Kalman gain allows to compensate for state and measurement model mismatch effects independently. Numerical simulation results verify that Split-KalmanNet outperforms the traditional EKF and the state-of-the-art KalmanNet algorithm in various model mismatch scenarios.
On-the-go Reflectance Transformation Imaging with Ordinary Smartphones
Oct 18, 2022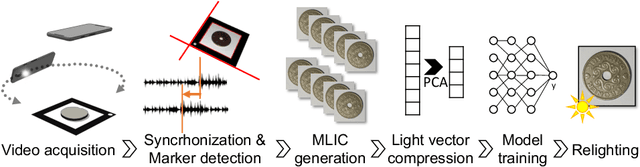
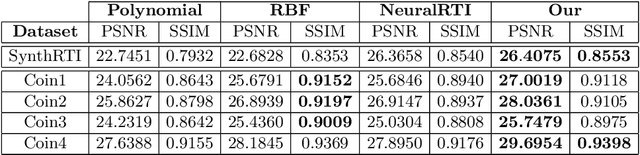
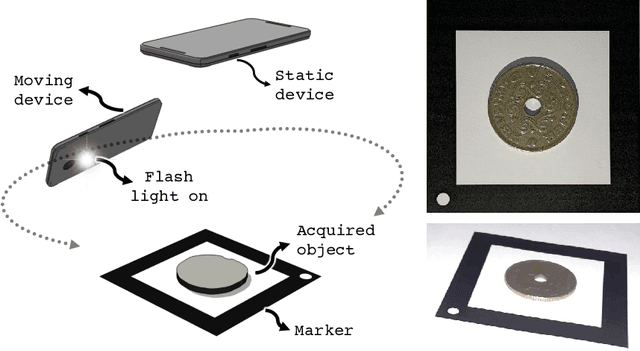
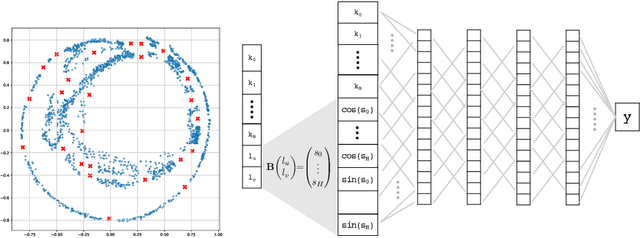
Reflectance Transformation Imaging (RTI) is a popular technique that allows the recovery of per-pixel reflectance information by capturing an object under different light conditions. This can be later used to reveal surface details and interactively relight the subject. Such process, however, typically requires dedicated hardware setups to recover the light direction from multiple locations, making the process tedious when performed outside the lab. We propose a novel RTI method that can be carried out by recording videos with two ordinary smartphones. The flash led-light of one device is used to illuminate the subject while the other captures the reflectance. Since the led is mounted close to the camera lenses, we can infer the light direction for thousands of images by freely moving the illuminating device while observing a fiducial marker surrounding the subject. To deal with such amount of data, we propose a neural relighting model that reconstructs object appearance for arbitrary light directions from extremely compact reflectance distribution data compressed via Principal Components Analysis (PCA). Experiments shows that the proposed technique can be easily performed on the field with a resulting RTI model that can outperform state-of-the-art approaches involving dedicated hardware setups.
A Human-ML Collaboration Framework for Improving Video Content Reviews
Oct 18, 2022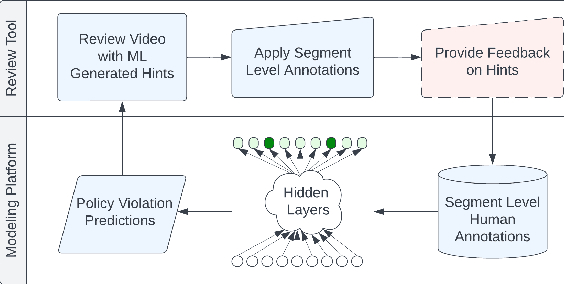
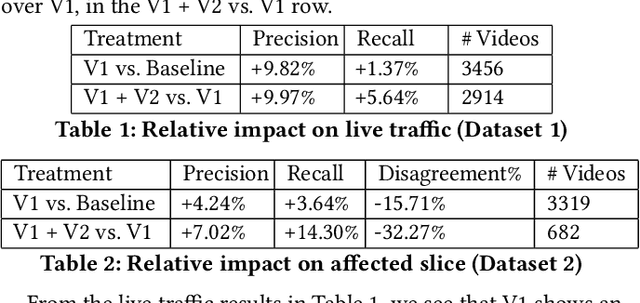

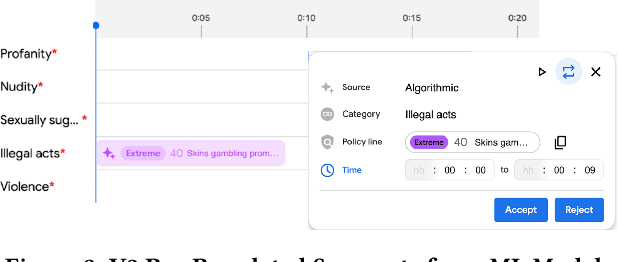
We deal with the problem of localized in-video taxonomic human annotation in the video content moderation domain, where the goal is to identify video segments that violate granular policies, e.g., community guidelines on an online video platform. High quality human labeling is critical for enforcement in content moderation. This is challenging due to the problem of information overload - raters need to apply a large taxonomy of granular policy violations with ambiguous definitions, within a limited review duration to relatively long videos. Our key contribution is a novel human-machine learning (ML) collaboration framework aimed at maximizing the quality and efficiency of human decisions in this setting - human labels are used to train segment-level models, the predictions of which are displayed as "hints" to human raters, indicating probable regions of the video with specific policy violations. The human verified/corrected segment labels can help refine the model further, hence creating a human-ML positive feedback loop. Experiments show improved human video moderation decision quality, and efficiency through more granular annotations submitted within a similar review duration, which enable a 5-8% AUC improvement in the hint generation models.
Interpretable Edge Enhancement and Suppression Learning for 3D Point Cloud Segmentation
Sep 20, 2022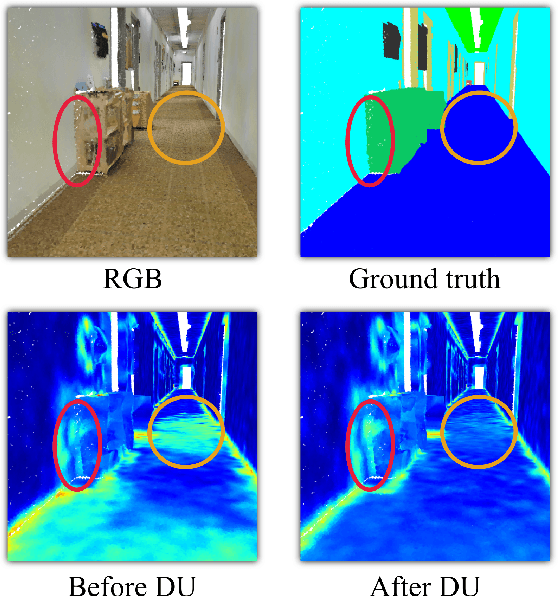
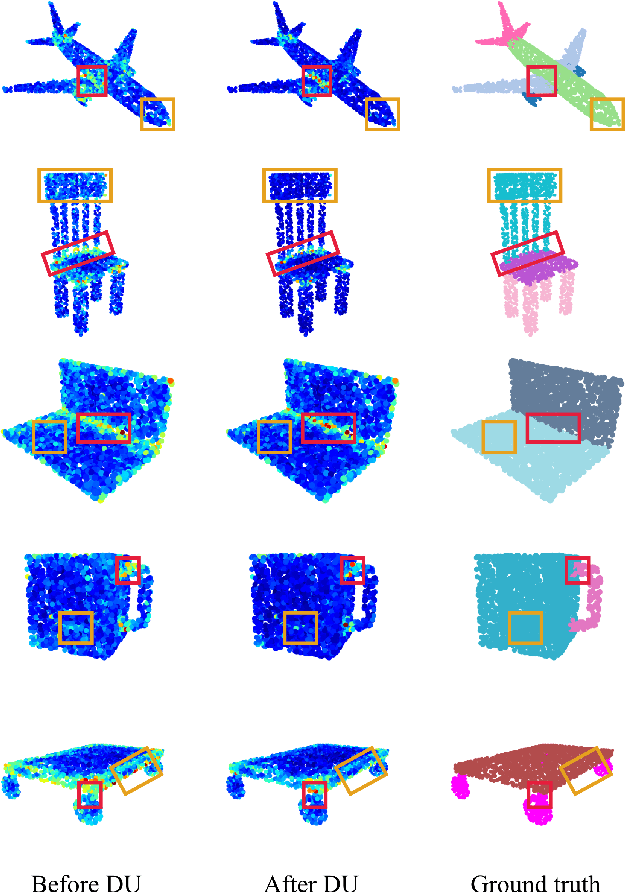
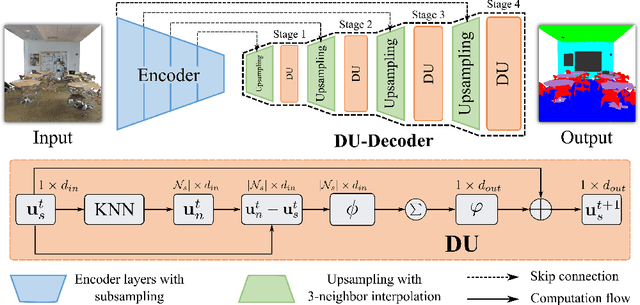
3D point clouds can flexibly represent continuous surfaces and can be used for various applications; however, the lack of structural information makes point cloud recognition challenging. Recent edge-aware methods mainly use edge information as an extra feature that describes local structures to facilitate learning. Although these methods show that incorporating edges into the network design is beneficial, they generally lack interpretability, making users wonder how exactly edges help. To shed light on this issue, in this study, we propose the Diffusion Unit (DU) that handles edges in an interpretable manner while providing decent improvement. Our method is interpretable in three ways. First, we theoretically show that DU learns to perform task-beneficial edge enhancement and suppression. Second, we experimentally observe and verify the edge enhancement and suppression behavior. Third, we empirically demonstrate that this behavior contributes to performance improvement. Extensive experiments performed on challenging benchmarks verify the superiority of DU in terms of both interpretability and performance gain. Specifically, our method achieves state-of-the-art performance in object part segmentation using ShapeNet part and scene segmentation using S3DIS. Our source code will be released at https://github.com/martianxiu/DiffusionUnit.
Towards Data-driven GIM tools: Two Prototypes
Sep 26, 2022Here we describe two approaches to improve group information management (GIM) and draw on the results of prior works to implement them in software prototypes. The first aids browsing and retrieving from large and unfamiliar collections like shared drives by dynamically reducing and re-organising them. The second supports the transfer and re-use of collections (e.g. to/by successors, descendants, or curators) by integrating novel sorting and annotation features. The prototypes' source code is shared online and screenshots are presented in the accompanying poster.
DR.BENCH: Diagnostic Reasoning Benchmark for Clinical Natural Language Processing
Sep 29, 2022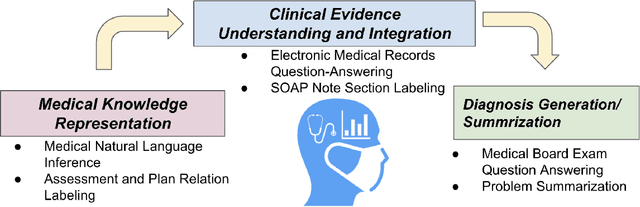
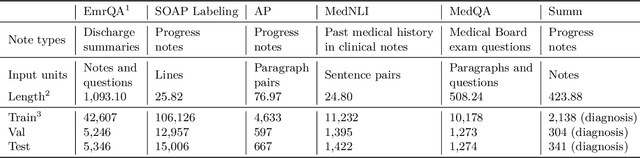
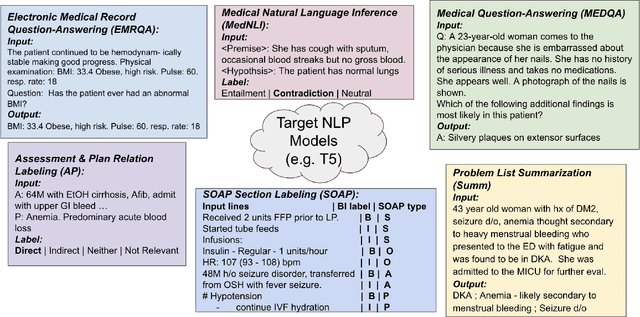
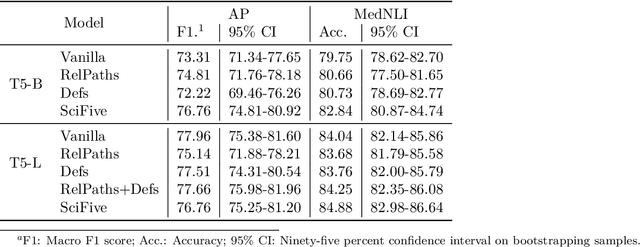
The meaningful use of electronic health records (EHR) continues to progress in the digital era with clinical decision support systems augmented by artificial intelligence. A priority in improving provider experience is to overcome information overload and reduce the cognitive burden so fewer medical errors and cognitive biases are introduced during patient care. One major type of medical error is diagnostic error due to systematic or predictable errors in judgment that rely on heuristics. The potential for clinical natural language processing (cNLP) to model diagnostic reasoning in humans with forward reasoning from data to diagnosis and potentially reduce the cognitive burden and medical error has not been investigated. Existing tasks to advance the science in cNLP have largely focused on information extraction and named entity recognition through classification tasks. We introduce a novel suite of tasks coined as Diagnostic Reasoning Benchmarks, DR.BENCH, as a new benchmark for developing and evaluating cNLP models with clinical diagnostic reasoning ability. The suite includes six tasks from ten publicly available datasets addressing clinical text understanding, medical knowledge reasoning, and diagnosis generation. DR.BENCH is the first clinical suite of tasks designed to be a natural language generation framework to evaluate pre-trained language models. Experiments with state-of-the-art pre-trained generative language models using large general domain models and models that were continually trained on a medical corpus demonstrate opportunities for improvement when evaluated in DR. BENCH. We share DR. BENCH as a publicly available GitLab repository with a systematic approach to load and evaluate models for the cNLP community.
Local-Aware Global Attention Network for Person Re-Identification
Sep 11, 2022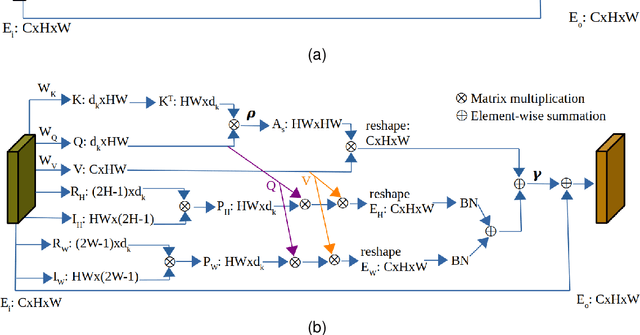
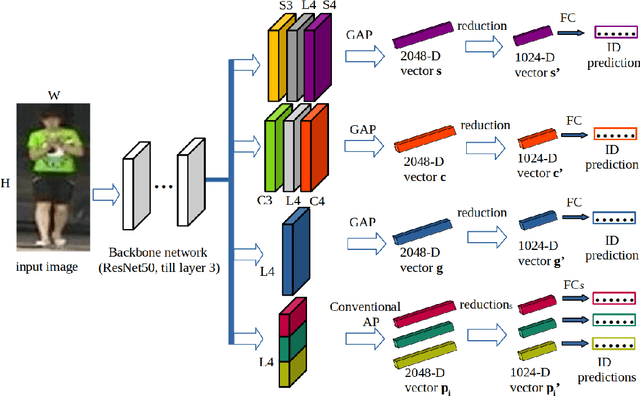


Learning representative, robust and discriminative information from images is essential for effective person re-identification (Re-Id). In this paper, we propose a compound approach for end-to-end discriminative deep feature learning for person Re-Id based on both body and hand images. We carefully design the Local-Aware Global Attention Network (LAGA-Net), a multi-branch deep network architecture consisting of one branch for spatial attention, one branch for channel attention, one branch for global feature representations and another branch for local feature representations. The attention branches focus on the relevant features of the image while suppressing the irrelevant backgrounds. In order to overcome the weakness of the attention mechanisms, equivariant to pixel shuffling, we integrate relative positional encodings into the spatial attention module to capture the spatial positions of pixels. The global branch intends to preserve the global context or structural information. For the the local branch, which intends to capture the fine-grained information, we perform uniform partitioning to generate stripes on the conv-layer horizontally. We retrieve the parts by conducting a soft partition without explicitly partitioning the images or requiring external cues such as pose estimation. A set of ablation study shows that each component contributes to the increased performance of the LAGA-Net. Extensive evaluations on four popular body-based person Re-Id benchmarks and two publicly available hand datasets demonstrate that our proposed method consistently outperforms existing state-of-the-art methods.
M^2-3DLaneNet: Multi-Modal 3D Lane Detection
Sep 20, 2022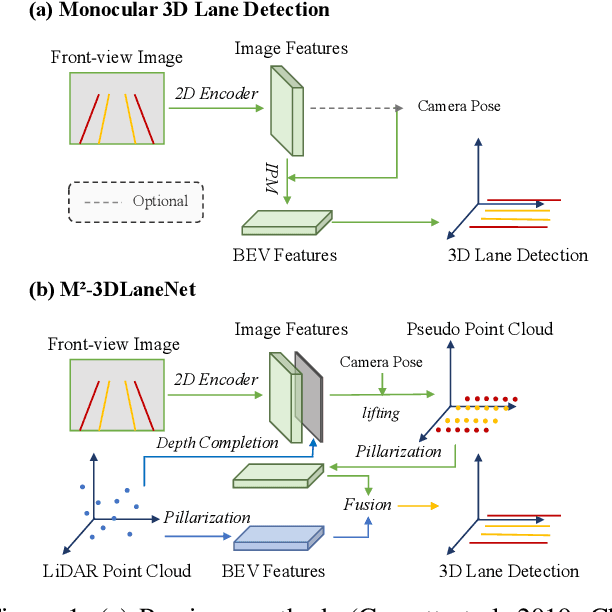
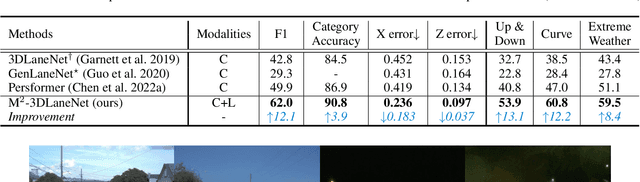
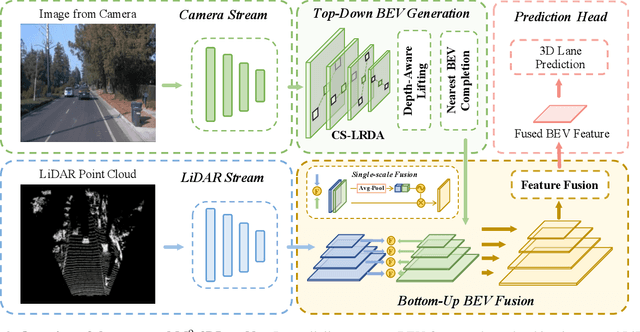
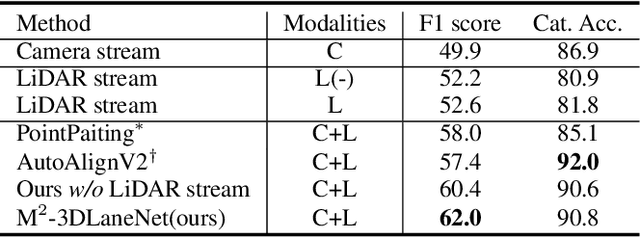
Estimating accurate lane lines in 3D space remains challenging due to their sparse and slim nature. In this work, we propose the M^2-3DLaneNet, a Multi-Modal framework for effective 3D lane detection. Aiming at integrating complementary information from multi-sensors, M^2-3DLaneNet first extracts multi-modal features with modal-specific backbones, then fuses them in a unified Bird's-Eye View (BEV) space. Specifically, our method consists of two core components. 1) To achieve accurate 2D-3D mapping, we propose the top-down BEV generation. Within it, a Line-Restricted Deform-Attention (LRDA) module is utilized to effectively enhance image features in a top-down manner, fully capturing the slenderness features of lanes. After that, it casts the 2D pyramidal features into 3D space using depth-aware lifting and generates BEV features through pillarization. 2) We further propose the bottom-up BEV fusion, which aggregates multi-modal features through multi-scale cascaded attention, integrating complementary information from camera and LiDAR sensors. Sufficient experiments demonstrate the effectiveness of M^2-3DLaneNet, which outperforms previous state-of-the-art methods by a large margin, i.e., 12.1% F1-score improvement on OpenLane dataset.
Social-Media Activity Forecasting with Exogenous Information Signals
Sep 22, 2021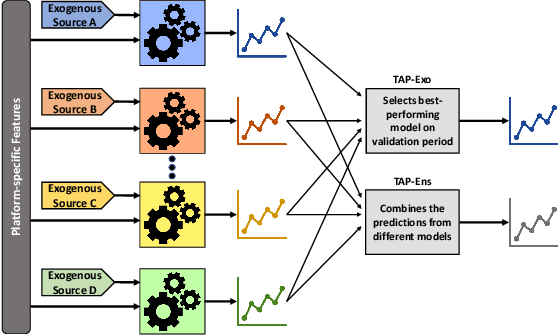
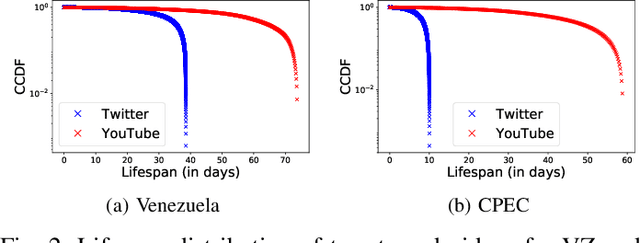
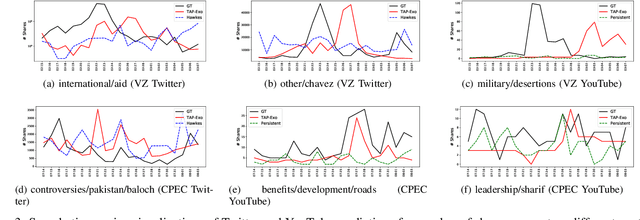

Due to their widespread adoption, social media platforms present an ideal environment for studying and understanding social behavior, especially on information spread. Modeling social media activity has numerous practical implications such as supporting efforts to analyze strategic information operations, designing intervention techniques to mitigate disinformation, or delivering critical information during disaster relief operations. In this paper we propose a modeling technique that forecasts topic-specific daily volume of social media activities by using both exogenous signals, such as news or armed conflicts records, and endogenous data from the social media platform we model. Empirical evaluations with real datasets from two different platforms and two different contexts each composed of multiple interrelated topics demonstrate the effectiveness of our solution.
Flexible and Structured Knowledge Grounded Question Answering
Sep 17, 2022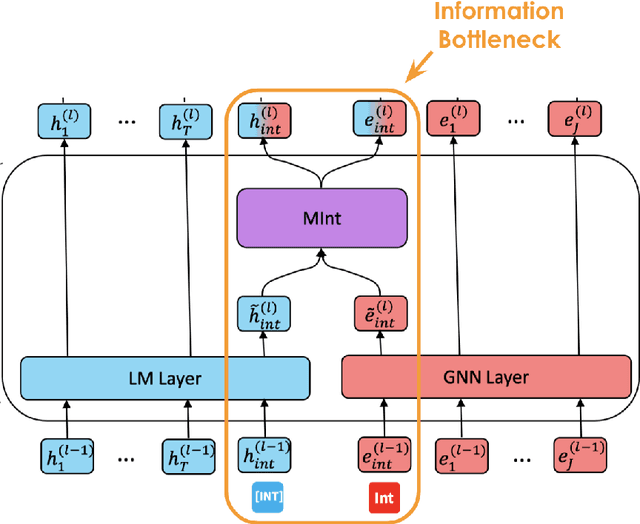

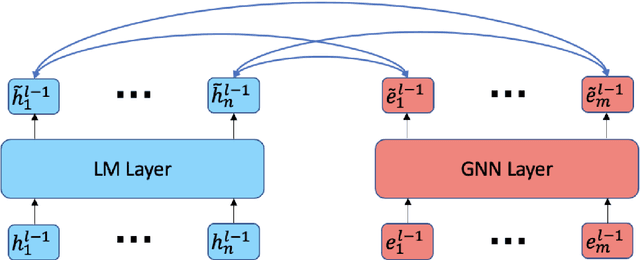

Can language models (LM) ground question-answering (QA) tasks in the knowledge base via inherent relational reasoning ability? While previous models that use only LMs have seen some success on many QA tasks, more recent methods include knowledge graphs (KG) to complement LMs with their more logic-driven implicit knowledge. However, effectively extracting information from structured data, like KGs, empowers LMs to remain an open question, and current models rely on graph techniques to extract knowledge. In this paper, we propose to solely leverage the LMs to combine the language and knowledge for knowledge based question-answering with flexibility, breadth of coverage and structured reasoning. Specifically, we devise a knowledge construction method that retrieves the relevant context with a dynamic hop, which expresses more comprehensivenes than traditional GNN-based techniques. And we devise a deep fusion mechanism to further bridge the information exchanging bottleneck between the language and the knowledge. Extensive experiments show that our model consistently demonstrates its state-of-the-art performance over CommensenseQA benchmark, showcasing the possibility to leverage LMs solely to robustly ground QA into the knowledge base.