 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-Camera Collaborative Depth Prediction via Consistent Structure Estimation
Oct 05, 2022

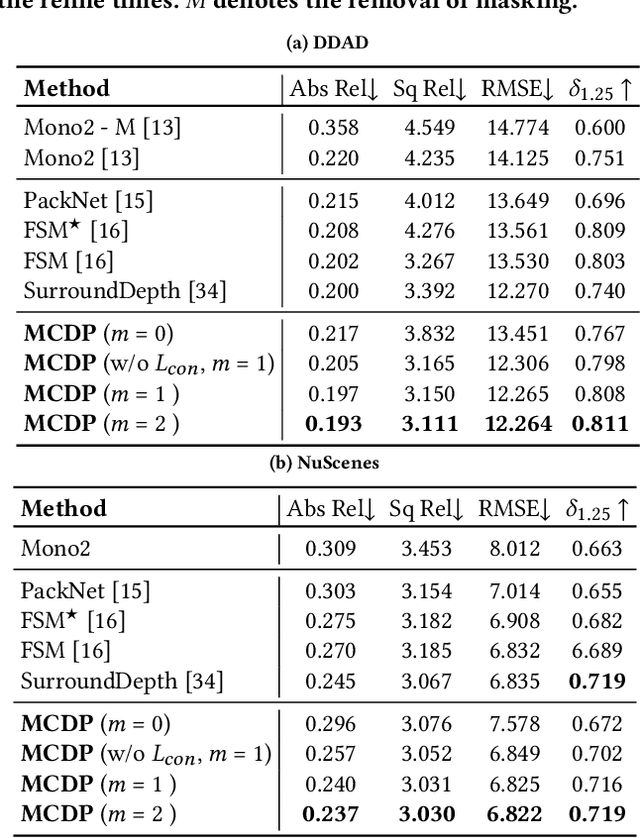

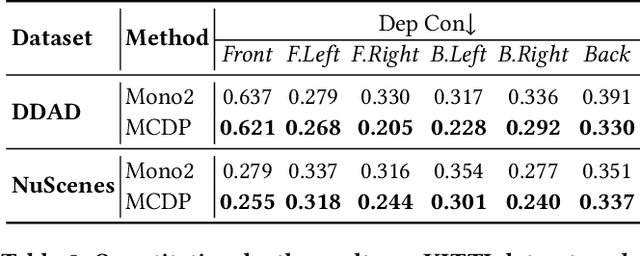
Depth map estimation from images is an important task in robotic systems. Existing methods can be categorized into two groups including multi-view stereo and monocular depth estimation. The former requires cameras to have large overlapping areas and sufficient baseline between cameras, while the latter that processes each image independently can hardly guarantee the structure consistency between cameras. In this paper, we propose a novel multi-camera collaborative depth prediction method that does not require large overlapping areas while maintaining structure consistency between cameras. Specifically, we formulate the depth estimation as a weighted combination of depth basis, in which the weights are updated iteratively by a refinement network driven by the proposed consistency loss. During the iterative update, the results of depth estimation are compared across cameras and the information of overlapping areas is propagated to the whole depth maps with the help of basis formulation. Experimental results on DDAD and NuScenes datasets demonstrate the superior performance of our method.
Disentangled Graph Contrastive Learning for Review-based Recommendation
Sep 04, 2022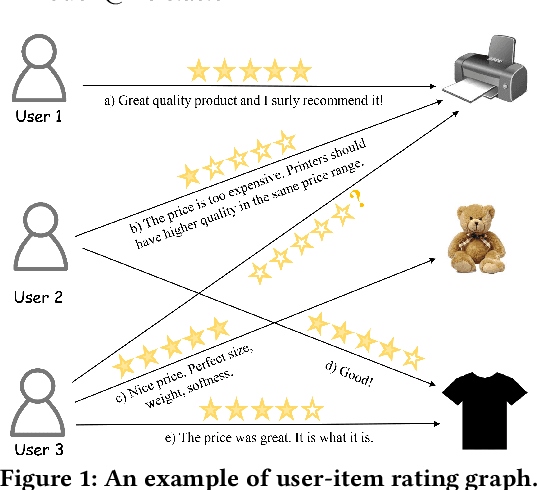
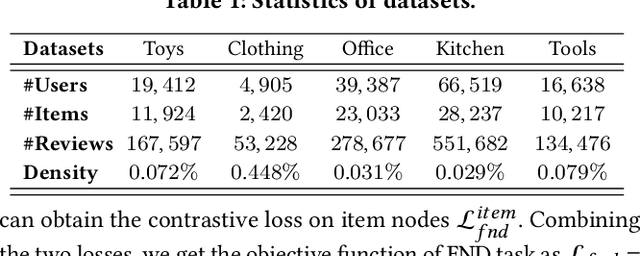
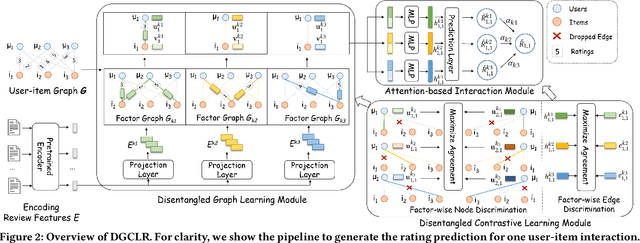
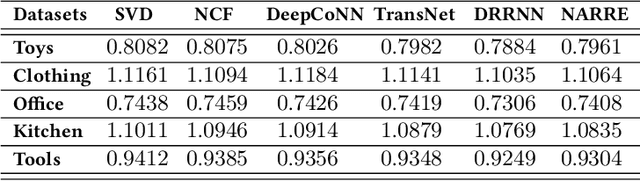
User review data is helpful in alleviating the data sparsity problem in many recommender systems. In review-based recommendation methods, review data is considered as auxiliary information that can improve the quality of learned user/item or interaction representations for the user rating prediction task. However, these methods usually model user-item interactions in a holistic manner and neglect the entanglement of the latent factors behind them, e.g., price, quality, or appearance, resulting in suboptimal representations and reducing interpretability. In this paper, we propose a Disentangled Graph Contrastive Learning framework for Review-based recommendation (DGCLR), to separately model the user-item interactions based on different latent factors through the textual review data. To this end, we first model the distributions of interactions over latent factors from both semantic information in review data and structural information in user-item graph data, forming several factor graphs. Then a factorized message passing mechanism is designed to learn disentangled user/item representations on the factor graphs, which enable us to further characterize the interactions and adaptively combine the predicted ratings from multiple factors via a devised attention mechanism. Finally, we set two factor-wise contrastive learning objectives to alleviate the sparsity issue and model the user/item and interaction features pertinent to each factor more accurately. Empirical results over five benchmark datasets validate the superiority of DGCLR over the state-of-the-art methods. Further analysis is offered to interpret the learned intent factors and rating prediction in DGCLR.
Industrial Data Science for Batch Manufacturing Processes
Sep 20, 2022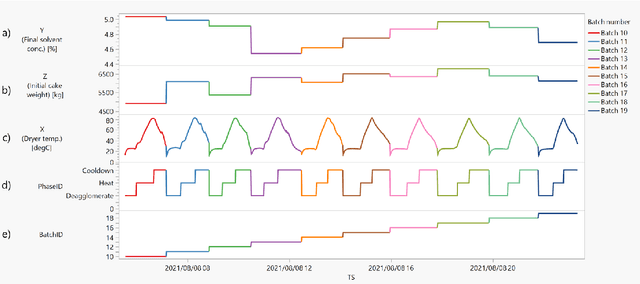

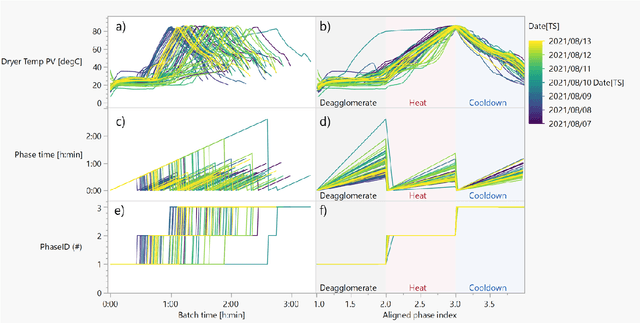
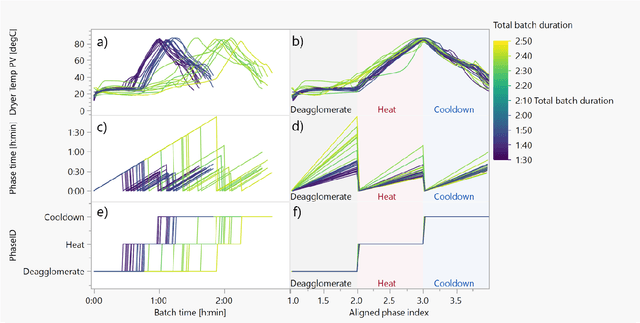
Batch processes show several sources of variability, from raw materials' properties to initial and evolving conditions that change during the different events in the manufacturing process. In this chapter, we will illustrate with an industrial example how to use machine learning to reduce this apparent excess of data while maintaining the relevant information for process engineers. Two common use cases will be presented: 1) AutoML analysis to quickly find correlations in batch process data, and 2) trajectory analysis to monitor and identify anomalous batches leading to process control improvements.
Convolutional Neural Network-Based Image Watermarking using Discrete Wavelet Transform
Oct 08, 2022
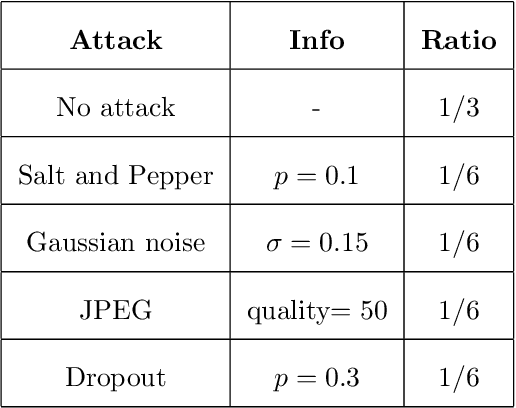
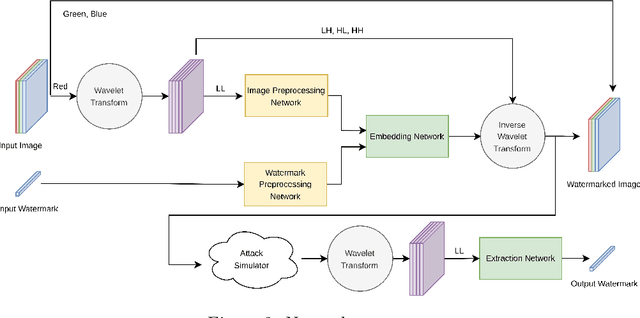
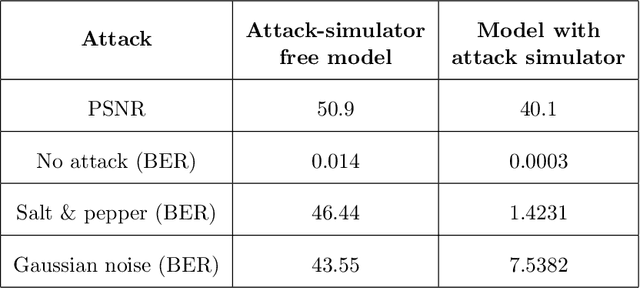
As the Internet becomes more popular, digital images are used and transferred more frequently. Although this phenomenon facilitates easy access to information, it also creates security concerns and violates intellectual property rights by allowing illegal use, copying, and digital content theft. Using watermarks (WMs) in digital images is one of the most common ways to maintain security. Watermarking is proving and declaring ownership of an image by adding a digital watermark to the original image. Watermarks can be either text or an image placed overtly or covertly in an image and are expected to be challenging to remove. This paper proposes a combination of convolutional neural networks (CNNs) and wavelet transforms to obtain a watermarking network for embedding and extracting watermarks. The network is independent of the host image resolution, can accept all kinds of watermarks, and has only 11 CNN layers while keeping performance. Two terms measure performance; the similarity between the extracted watermark and the original one and the similarity between the host image and the watermarked one.
An Ordinal Latent Variable Model of Conflict Intensity
Oct 08, 2022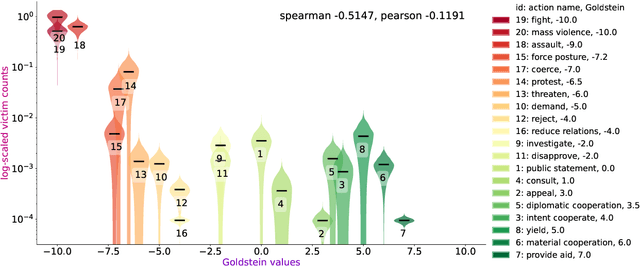
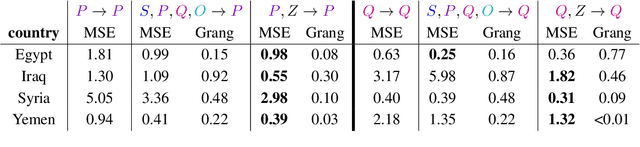
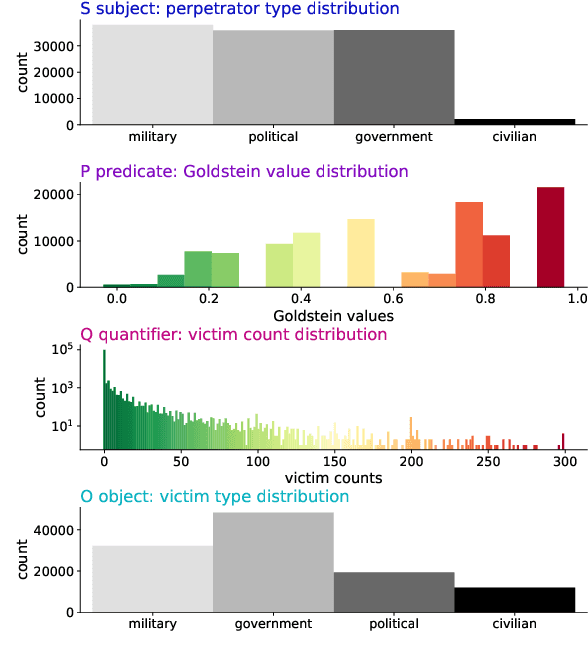

For the quantitative monitoring of international relations, political events are extracted from the news and parsed into "who-did-what-to-whom" patterns. This has resulted in large data collections which require aggregate statistics for analysis. The Goldstein Scale is an expert-based measure that ranks individual events on a one-dimensional scale from conflictual to cooperative. However, the scale disregards fatality counts as well as perpetrator and victim types involved in an event. This information is typically considered in qualitative conflict assessment. To address this limitation, we propose a probabilistic generative model over the full subject-predicate-quantifier-object tuples associated with an event. We treat conflict intensity as an interpretable, ordinal latent variable that correlates conflictual event types with high fatality counts. Taking a Bayesian approach, we learn a conflict intensity scale from data and find the optimal number of intensity classes. We evaluate the model by imputing missing data. Our scale proves to be more informative than the original Goldstein Scale in autoregressive forecasting and when compared with global online attention towards armed conflicts.
(Fusionformer):Exploiting the Joint Motion Synergy with Fusion Network Based On Transformer for 3D Human Pose Estimation
Oct 08, 2022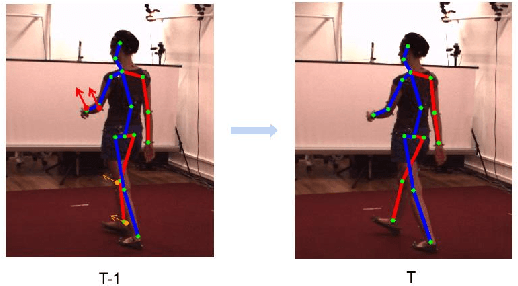
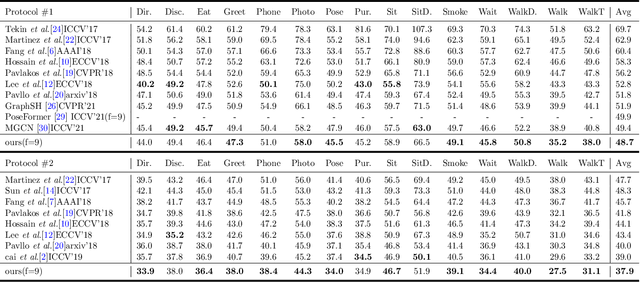

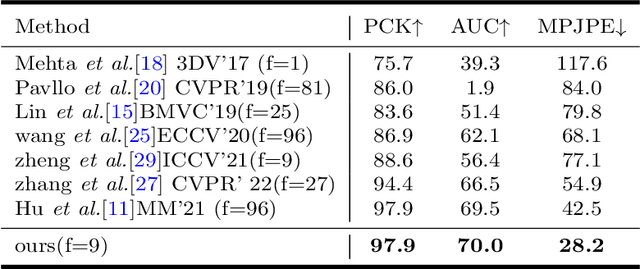
For the current 3D human pose estimation task, in order to improve the efficiency of pose sequence output, we try to further improve the prediction stability in low input video frame scenarios.Many previous methods lack the understanding of local joint information.\cite{9878888}considers the temporal relationship of a single joint in this work.However, we found that there is a certain predictive correlation between the trajectories of different joints in time.Therefore, our proposed \textbf{Fusionformer} method introduces a self-trajectory module and a cross-trajectory module based on the spatio-temporal module.After that, the global spatio-temporal features and local joint trajectory features are fused through a linear network in a parallel manner.To eliminate the influence of bad 2D poses on 3D projections, finally we also introduce a pose refinement network to balance the consistency of 3D projections.In addition, we evaluate the proposed method on two benchmark datasets (Human3.6M, MPI-INF-3DHP). Comparing our method with the baseline method poseformer, the results show an improvement of 2.4\% MPJPE and 4.3\% P-MPJPE on the Human3.6M dataset, respectively.
EDU-level Extractive Summarization with Varying Summary Lengths
Oct 08, 2022
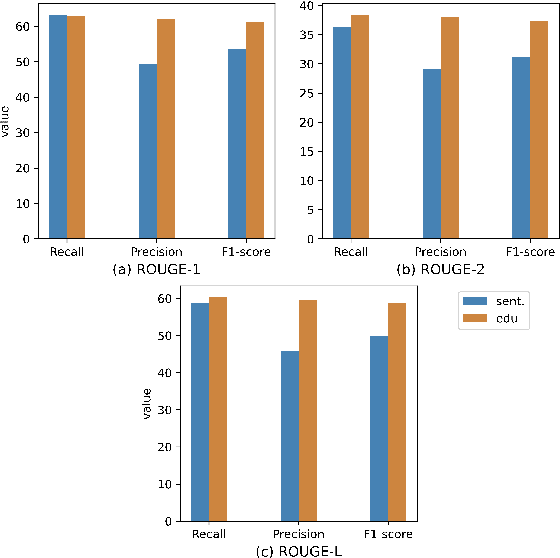
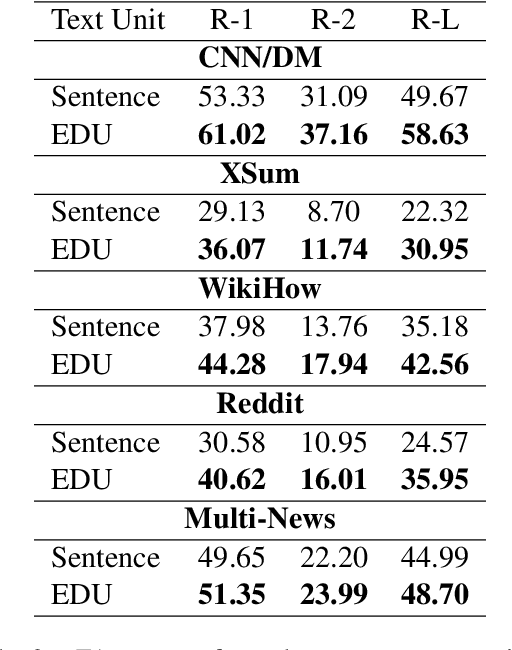
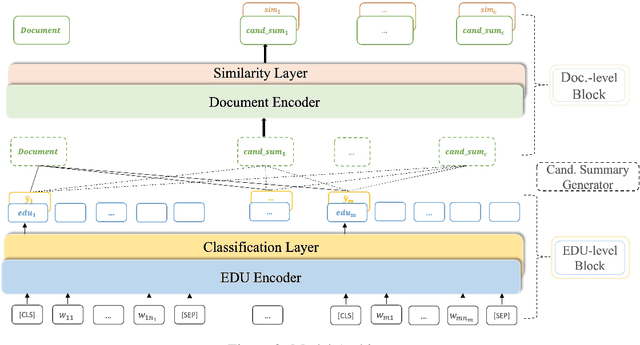
Extractive models usually formulate text summarization as extracting top-k important sentences from document as summary. Few work exploited extracting finer-grained Elementary Discourse Unit (EDU) and there is little analysis and justification for the extractive unit selection. To fill such a gap, this paper firstly conducts oracle analysis to compare the upper bound of performance for models based on EDUs and sentences. The analysis provides evidences from both theoretical and experimental perspectives to justify that EDUs make more concise and precise summary than sentences without losing salient information. Then, considering this merit of EDUs, this paper further proposes EDU-level extractive model with Varying summary Lengths (EDU-VL) and develops the corresponding learning algorithm. EDU-VL learns to encode and predict probabilities of EDUs in document, and encode EDU-level candidate summaries with different lengths based on various $k$ values and select the best candidate summary in an end-to-end training manner. Finally, the proposed and developed approach is experimented on single and multi-document benchmark datasets and shows the improved performances in comparison with the state-of-the-art models.
RSVG: Exploring Data and Models for Visual Grounding on Remote Sensing Data
Oct 23, 2022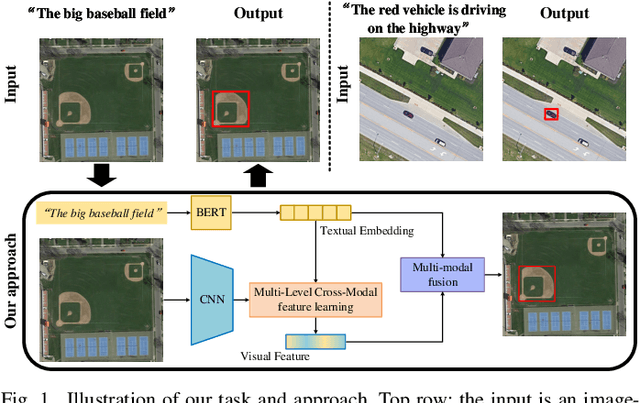
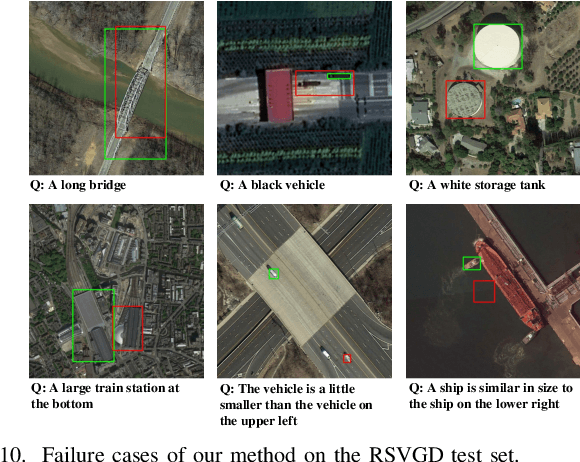

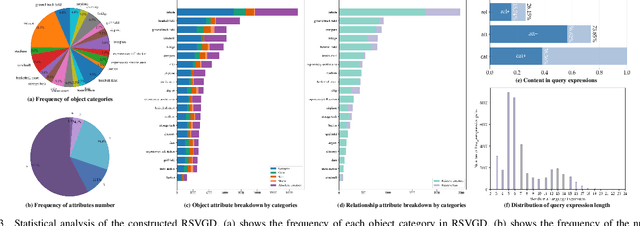
In this paper, we introduce the task of visual grounding for remote sensing data (RSVG). RSVG aims to localize the referred objects in remote sensing (RS) images with the guidance of natural language. To retrieve rich information from RS imagery using natural language, many research tasks, like RS image visual question answering, RS image captioning, and RS image-text retrieval have been investigated a lot. However, the object-level visual grounding on RS images is still under-explored. Thus, in this work, we propose to construct the dataset and explore deep learning models for the RSVG task. Specifically, our contributions can be summarized as follows. 1) We build the new large-scale benchmark dataset of RSVG, termed RSVGD, to fully advance the research of RSVG. This new dataset includes image/expression/box triplets for training and evaluating visual grounding models. 2) We benchmark extensive state-of-the-art (SOTA) natural image visual grounding methods on the constructed RSVGD dataset, and some insightful analyses are provided based on the results. 3) A novel transformer-based Multi-Level Cross-Modal feature learning (MLCM) module is proposed. Remotely-sensed images are usually with large scale variations and cluttered backgrounds. To deal with the scale-variation problem, the MLCM module takes advantage of multi-scale visual features and multi-granularity textual embeddings to learn more discriminative representations. To cope with the cluttered background problem, MLCM adaptively filters irrelevant noise and enhances salient features. In this way, our proposed model can incorporate more effective multi-level and multi-modal features to boost performance. Furthermore, this work also provides useful insights for developing better RSVG models. The dataset and code will be publicly available at https://github.com/ZhanYang-nwpu/RSVG-pytorch.
Privacy-Preserving Deep Learning Model for Covid-19 Disease Detection
Sep 07, 2022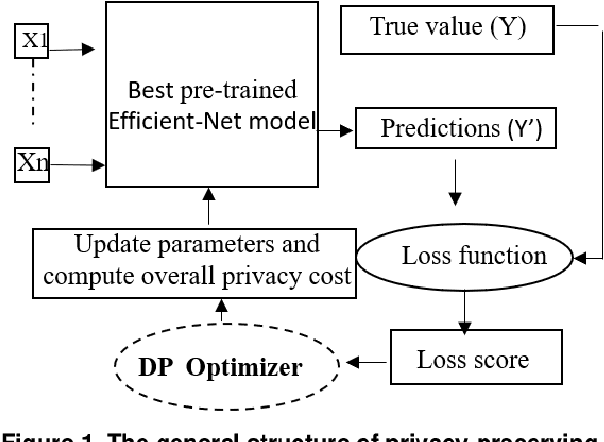
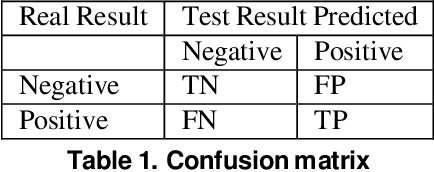
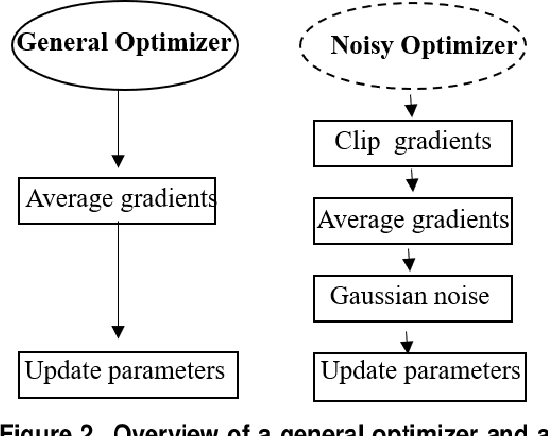
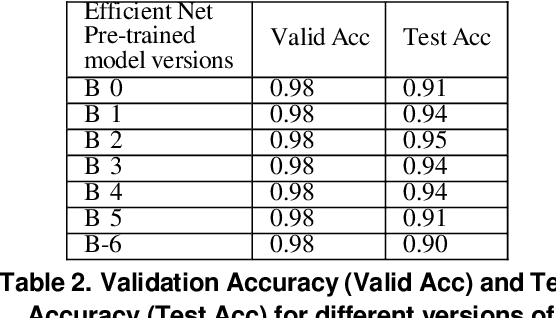
Recent studies demonstrated that X-ray radiography showed higher accuracy than Polymerase Chain Reaction (PCR) testing for COVID-19 detection. Therefore, applying deep learning models to X-rays and radiography images increases the speed and accuracy of determining COVID-19 cases. However, due to Health Insurance Portability and Accountability (HIPAA) compliance, the hospitals were unwilling to share patient data due to privacy concerns. To maintain privacy, we propose differential private deep learning models to secure the patients' private information. The dataset from the Kaggle website is used to evaluate the designed model for COVID-19 detection. The EfficientNet model version was selected according to its highest test accuracy. The injection of differential privacy constraints into the best-obtained model was made to evaluate performance. The accuracy is noted by varying the trainable layers, privacy loss, and limiting information from each sample. We obtained 84\% accuracy with a privacy loss of 10 during the fine-tuning process.
Developing a Knowledge Graph Framework for Pharmacokinetic Natural Product-Drug Interactions
Sep 24, 2022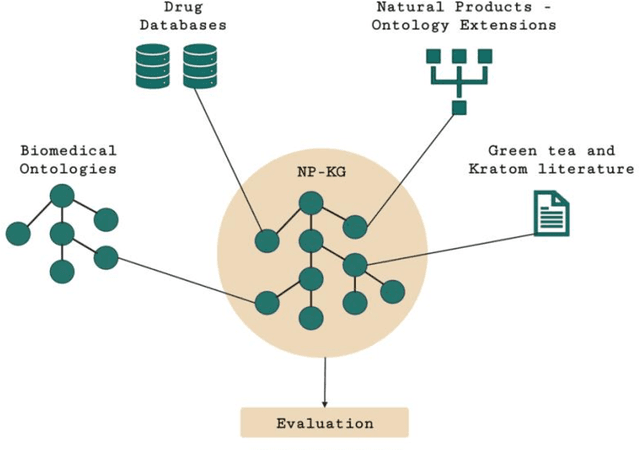
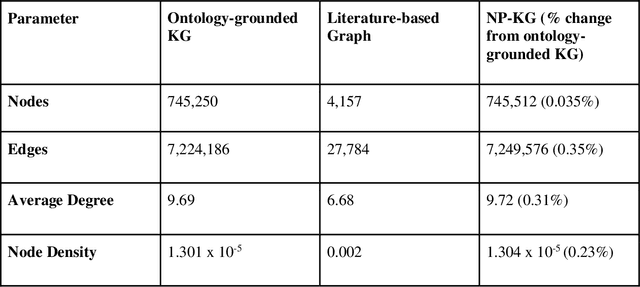

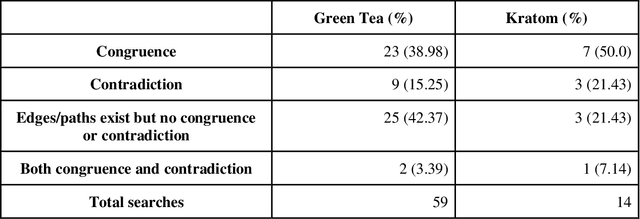
Pharmacokinetic natural product-drug interactions (NPDIs) occur when botanical natural products are co-consumed with pharmaceutical drugs. Understanding mechanisms of NPDIs is key to preventing adverse events. We constructed a knowledge graph framework, NP-KG, as a step toward computational discovery of pharmacokinetic NPDIs. NP-KG is a heterogeneous KG with biomedical ontologies, linked data, and full texts of the scientific literature, constructed with the Phenotype Knowledge Translator framework and the semantic relation extraction systems, SemRep and Integrated Network and Dynamic Reasoning Assembler. NP-KG was evaluated with case studies of pharmacokinetic green tea- and kratom-drug interactions through path searches and meta-path discovery to determine congruent and contradictory information compared to ground truth data. The fully integrated NP-KG consisted of 745,512 nodes and 7,249,576 edges. Evaluation of NP-KG resulted in congruent (38.98% for green tea, 50% for kratom), contradictory (15.25% for green tea, 21.43% for kratom), and both congruent and contradictory (15.25% for green tea, 21.43% for kratom) information. Potential pharmacokinetic mechanisms for several purported NPDIs, including the green tea-raloxifene, green tea-nadolol, kratom-midazolam, kratom-quetiapine, and kratom-venlafaxine interactions were congruent with the published literature. NP-KG is the first KG to integrate biomedical ontologies with full texts of the scientific literature focused on natural products. We demonstrate the application of NP-KG to identify pharmacokinetic interactions involving enzymes, transporters, and pharmaceutical drugs. We envision that NP-KG will facilitate improved human-machine collaboration to guide researchers in future studies of pharmacokinetic NPDIs. The NP-KG framework is publicly available at https://doi.org/10.5281/zenodo.6814507 and https://github.com/sanyabt/np-kg.