 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MetaMask: Revisiting Dimensional Confounder for Self-Supervised Learning
Sep 16, 2022
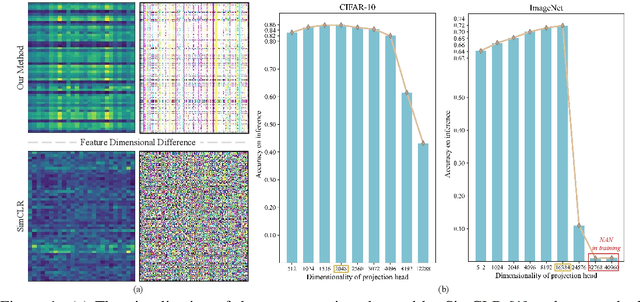
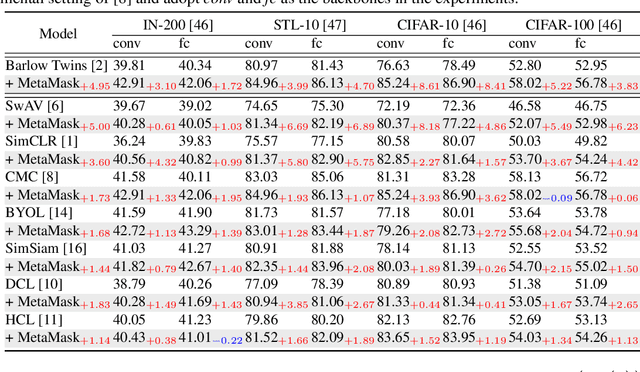
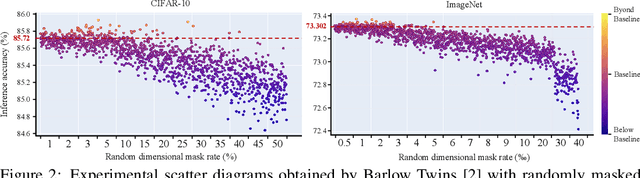
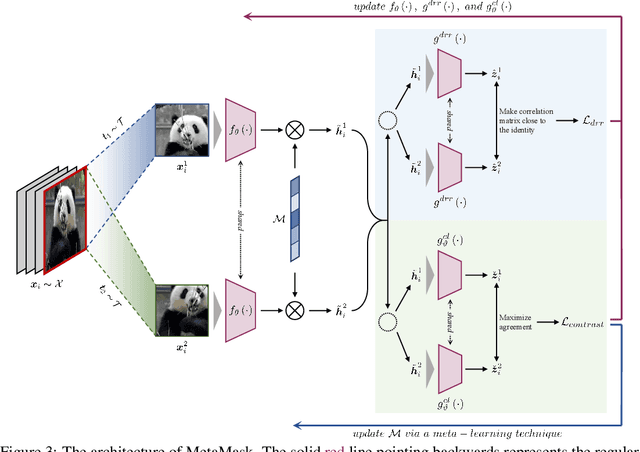
As a successful approach to self-supervised learning, contrastive learning aims to learn invariant information shared among distortions of the input sample. While contrastive learning has yielded continuous advancements in sampling strategy and architecture design, it still remains two persistent defects: the interference of task-irrelevant information and sample inefficiency, which are related to the recurring existence of trivial constant solutions. From the perspective of dimensional analysis, we find out that the dimensional redundancy and dimensional confounder are the intrinsic issues behind the phenomena, and provide experimental evidence to support our viewpoint. We further propose a simple yet effective approach MetaMask, short for the dimensional Mask learned by Meta-learning, to learn representations against dimensional redundancy and confounder. MetaMask adopts the redundancy-reduction technique to tackle the dimensional redundancy issue and innovatively introduces a dimensional mask to reduce the gradient effects of specific dimensions containing the confounder, which is trained by employing a meta-learning paradigm with the objective of improving the performance of masked representations on a typical self-supervised task. We provide solid theoretical analyses to prove MetaMask can obtain tighter risk bounds for downstream classification compared to typical contrastive methods. Empirically, our method achieves state-of-the-art performance on various benchmarks.
MultiPath++: Efficient Information Fusion and Trajectory Aggregation for Behavior Prediction
Dec 22, 2021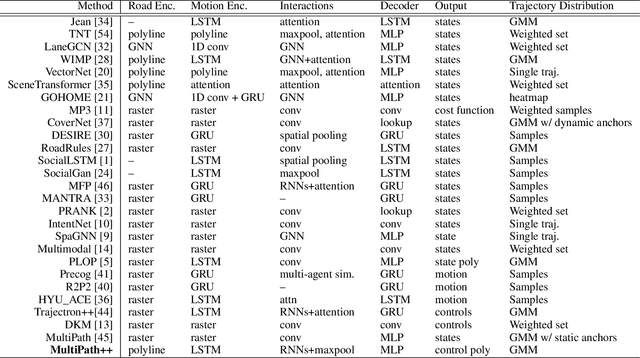
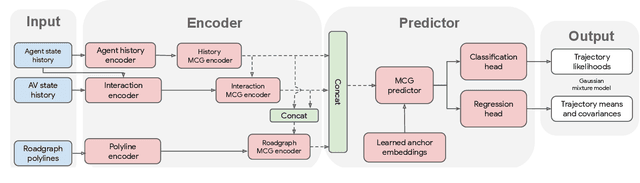
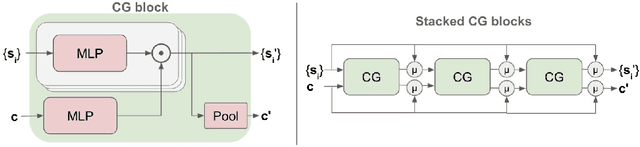
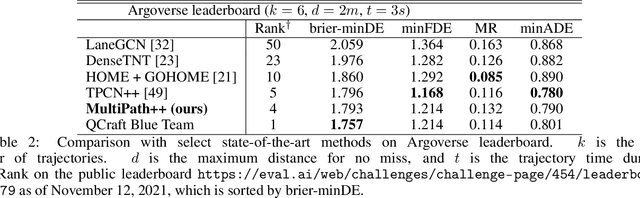
Predicting the future behavior of road users is one of the most challenging and important problems in autonomous driving. Applying deep learning to this problem requires fusing heterogeneous world state in the form of rich perception signals and map information, and inferring highly multi-modal distributions over possible futures. In this paper, we present MultiPath++, a future prediction model that achieves state-of-the-art performance on popular benchmarks. MultiPath++ improves the MultiPath architecture by revisiting many design choices. The first key design difference is a departure from dense image-based encoding of the input world state in favor of a sparse encoding of heterogeneous scene elements: MultiPath++ consumes compact and efficient polylines to describe road features, and raw agent state information directly (e.g., position, velocity, acceleration). We propose a context-aware fusion of these elements and develop a reusable multi-context gating fusion component. Second, we reconsider the choice of pre-defined, static anchors, and develop a way to learn latent anchor embeddings end-to-end in the model. Lastly, we explore ensembling and output aggregation techniques -- common in other ML domains -- and find effective variants for our probabilistic multimodal output representation. We perform an extensive ablation on these design choices, and show that our proposed model achieves state-of-the-art performance on the Argoverse Motion Forecasting Competition and the Waymo Open Dataset Motion Prediction Challenge.
Saliency-based Multiple Region of Interest Detection from a Single 360° image
Sep 08, 2022

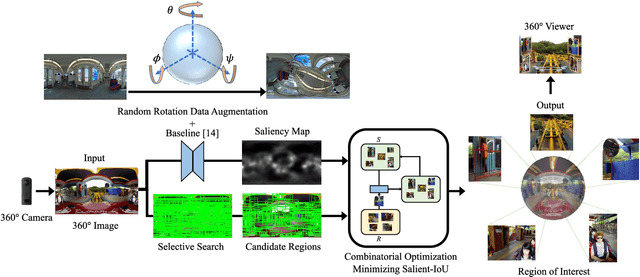
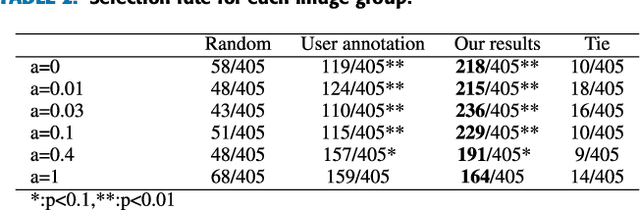
360{\deg} images are informative -- it contains omnidirectional visual information around the camera. However, the areas that cover a 360{\deg} image is much larger than the human's field of view, therefore important information in different view directions is easily overlooked. To tackle this issue, we propose a method for predicting the optimal set of Region of Interest (RoI) from a single 360{\deg} image using the visual saliency as a clue. To deal with the scarce, strongly biased training data of existing single 360{\deg} image saliency prediction dataset, we also propose a data augmentation method based on the spherical random data rotation. From the predicted saliency map and redundant candidate regions, we obtain the optimal set of RoIs considering both the saliency within a region and the Interaction-Over-Union (IoU) between regions. We conduct the subjective evaluation to show that the proposed method can select regions that properly summarize the input 360{\deg} image.
Fast localization and single-pixel imaging of the moving object using time-division multiplexing
Aug 15, 2022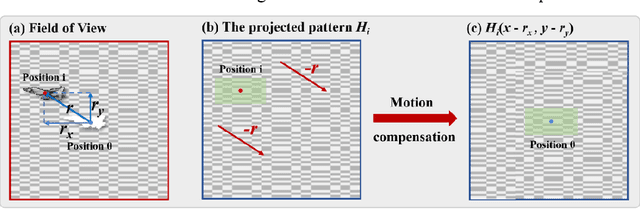
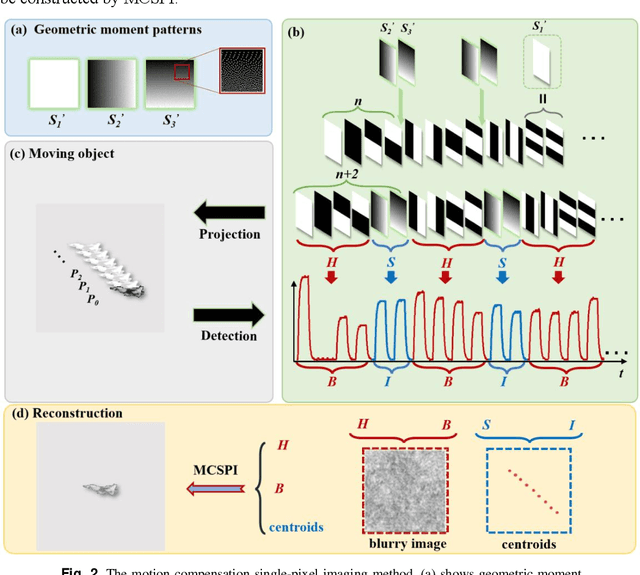
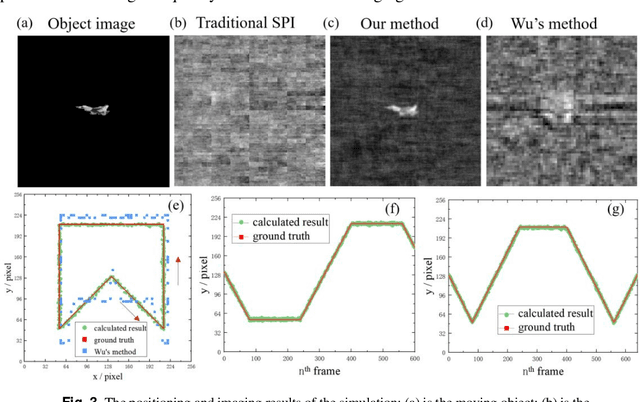
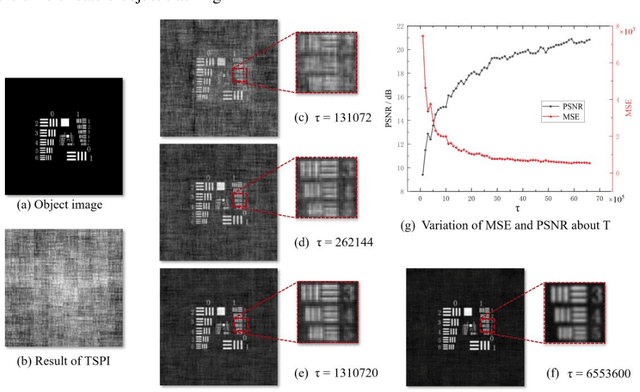
When imaging moving objects, single-pixel imaging produces motion blur. This paper proposes a new single-pixel imaging method, which can achieve anti-motion blur imaging of a fast-moving object. The geometric moment patterns and Hadamard patterns are used to alternately encode the position information and the image information of the object with time-division multiplexing. In the reconstruction process, the object position information is extracted independently and combining motion-compensation reconstruction algorithm to decouple the object motion from image information. As a result, the anti-motion blur image and the high frame rate object positions are obtained. Experimental results show that for a moving object with an angular velocity of up to 0.5rad/s relative to the imaging system, the proposed method achieves a localization frequency of 5.55kHz, and gradually reconstructs a clear image of the fast-moving object with a pseudo resolution of 512x512. The method has application prospects in single-pixel imaging of the fast-moving object.
Provable Subspace Identification Under Post-Nonlinear Mixtures
Oct 14, 2022

Unsupervised mixture learning (UML) aims at identifying linearly or nonlinearly mixed latent components in a blind manner. UML is known to be challenging: Even learning linear mixtures requires highly nontrivial analytical tools, e.g., independent component analysis or nonnegative matrix factorization. In this work, the post-nonlinear (PNL) mixture model -- where unknown element-wise nonlinear functions are imposed onto a linear mixture -- is revisited. The PNL model is widely employed in different fields ranging from brain signal classification, speech separation, remote sensing, to causal discovery. To identify and remove the unknown nonlinear functions, existing works often assume different properties on the latent components (e.g., statistical independence or probability-simplex structures). This work shows that under a carefully designed UML criterion, the existence of a nontrivial null space associated with the underlying mixing system suffices to guarantee identification/removal of the unknown nonlinearity. Compared to prior works, our finding largely relaxes the conditions of attaining PNL identifiability, and thus may benefit applications where no strong structural information on the latent components is known. A finite-sample analysis is offered to characterize the performance of the proposed approach under realistic settings. To implement the proposed learning criterion, a block coordinate descent algorithm is proposed. A series of numerical experiments corroborate our theoretical claims.
Shadfa 0.1: The Iranian Movie Knowledge Graph and Graph-Embedding-Based Recommender System
Oct 14, 2022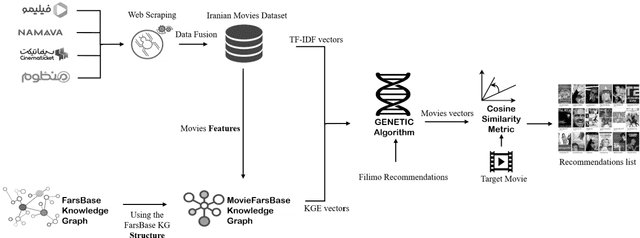
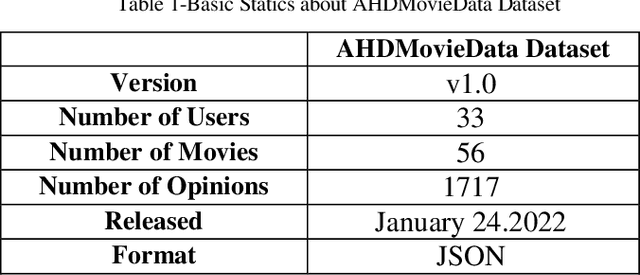


Movies are a great source of entertainment. However, the problem arises when one is trying to find the desired content within this vast amount of data which is significantly increasing every year. Recommender systems can provide appropriate algorithms to solve this problem. The content_based technique has found popularity due to the lack of available user data in most cases. Content_based recommender systems are based on the similarity of items' demographic information; Term Frequency _ Inverse Document Frequency (TF_IDF) and Knowledge Graph Embedding (KGE) are two approaches used to vectorize data to calculate these similarities. In this paper, we propose a weighted content_based movie RS by combining TF_IDF which is an appropriate approach for embedding textual data such as plot/description, and KGE which is used to embed named entities such as the director's name. The weights between features are determined using a Genetic algorithm. Additionally, the Iranian movies dataset is created by scraping data from movie_related websites. This dataset and the structure of the FarsBase KG are used to create the MovieFarsBase KG which is a component in the implementation process of the proposed content_based RS. Using precision, recall, and F1 score metrics, this study shows that the proposed approach outperforms the conventional approach that uses TF_IDF for embedding all attributes.
A possibilistic framework for multi-target multi-sensor fusion
Sep 25, 2022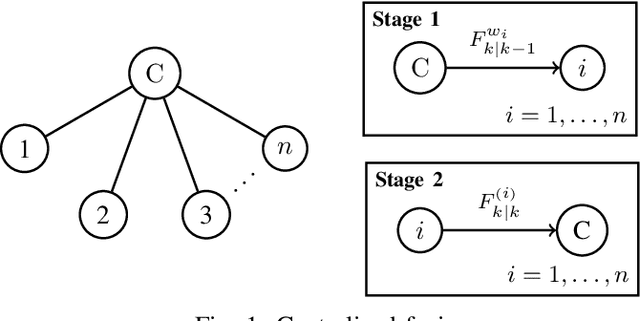
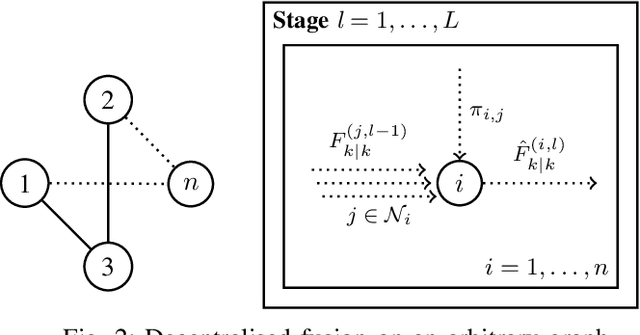
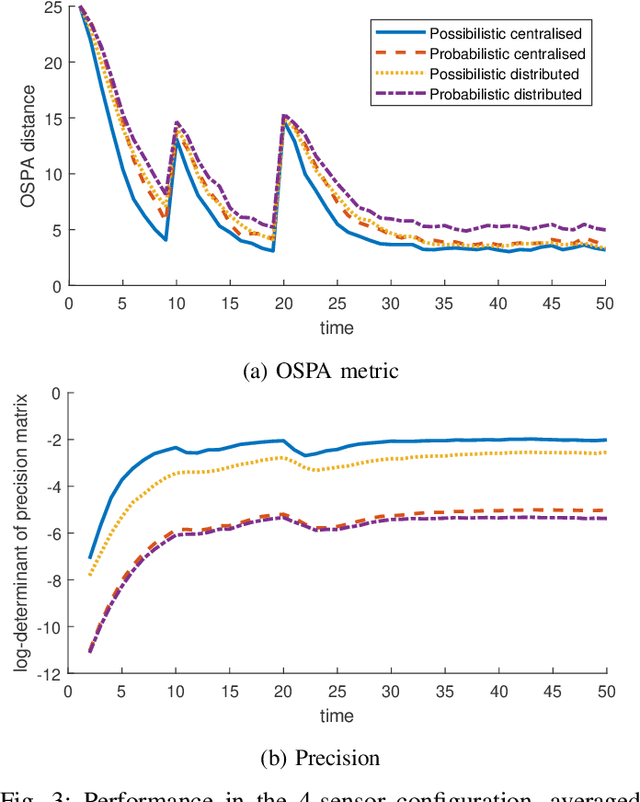
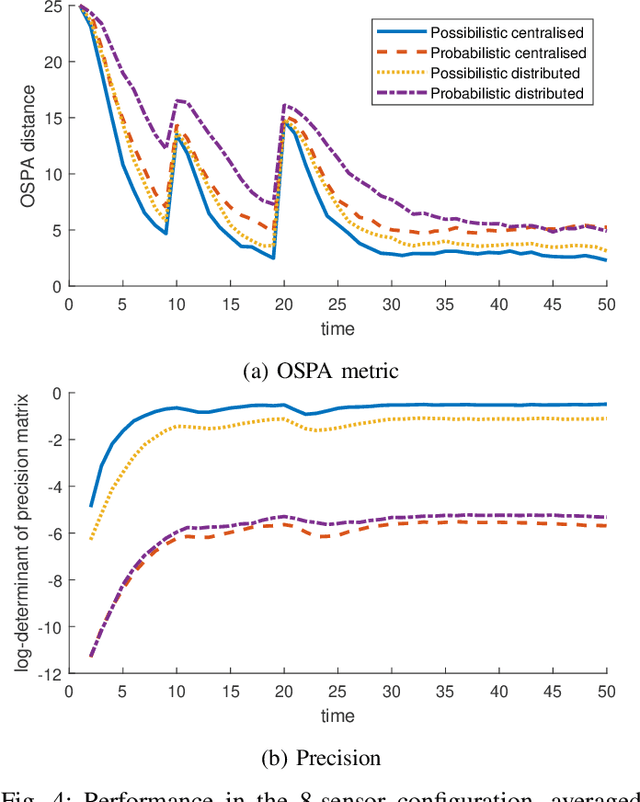
Fusing and sharing information from multiple sensors over a network is a challenging task, especially in the context of multi-target tracking. Part of this challenge arises from the absence of a foundational rule for fusing probability distributions, with various approaches stemming from different principles. Yet, when expressing multi-target tracking algorithms within the framework of possibility theory, one specific fusion rule appears to be particularly natural and useful. In this article, this fusion rule is applied to both centralised and decentralised fusion, based on the possibilistic analogue of the probability hypothesis density filter. We then show that the proposed approach outperforms its probabilistic counterpart on simulated data.
Black-Box Audits for Group Distribution Shifts
Sep 08, 2022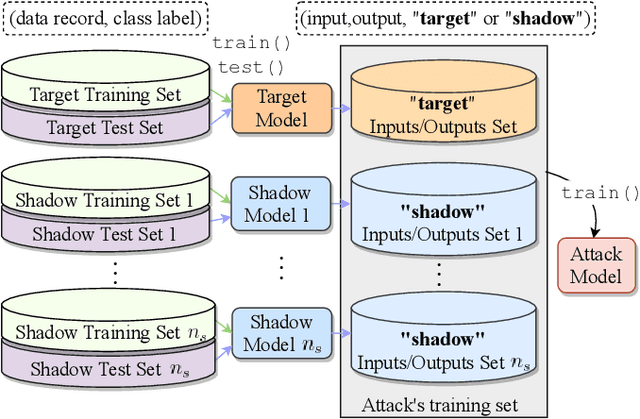
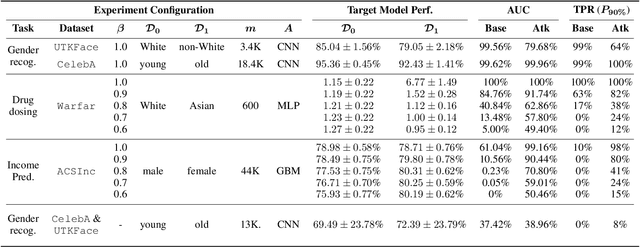
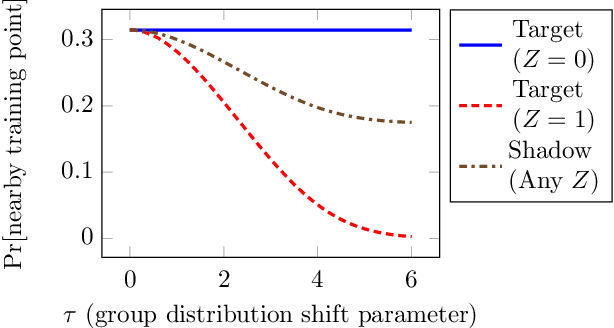
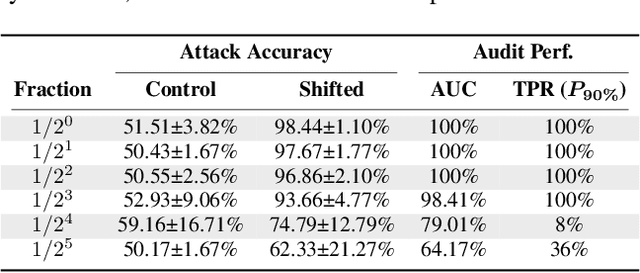
When a model informs decisions about people, distribution shifts can create undue disparities. However, it is hard for external entities to check for distribution shift, as the model and its training set are often proprietary. In this paper, we introduce and study a black-box auditing method to detect cases of distribution shift that lead to a performance disparity of the model across demographic groups. By extending techniques used in membership and property inference attacks -- which are designed to expose private information from learned models -- we demonstrate that an external auditor can gain the information needed to identify these distribution shifts solely by querying the model. Our experimental results on real-world datasets show that this approach is effective, achieving 80--100% AUC-ROC in detecting shifts involving the underrepresentation of a demographic group in the training set. Researchers and investigative journalists can use our tools to perform non-collaborative audits of proprietary models and expose cases of underrepresentation in the training datasets.
Iterative Vision-and-Language Navigation
Oct 06, 2022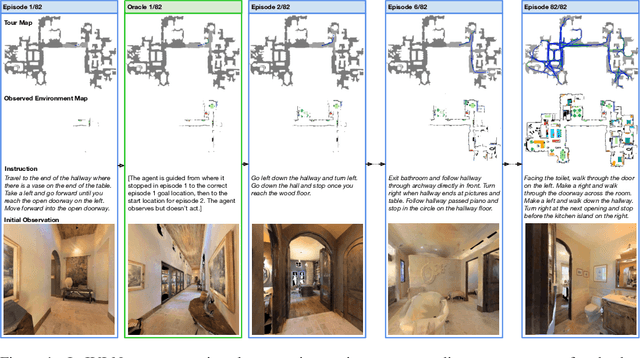
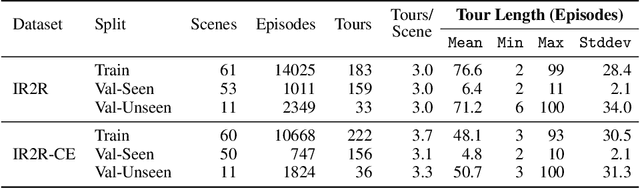
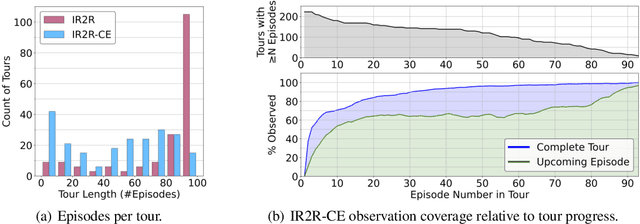

We present Iterative Vision-and-Language Navigation (IVLN), a paradigm for evaluating language-guided agents navigating in a persistent environment over time. Existing Vision-and-Language Navigation (VLN) benchmarks erase the agent's memory at the beginning of every episode, testing the ability to perform cold-start navigation with no prior information. However, deployed robots occupy the same environment for long periods of time. The IVLN paradigm addresses this disparity by training and evaluating VLN agents that maintain memory across tours of scenes that consist of up to 100 ordered instruction-following Room-to-Room (R2R) episodes, each defined by an individual language instruction and a target path. We present discrete and continuous Iterative Room-to-Room (IR2R) benchmarks comprising about 400 tours each in 80 indoor scenes. We find that extending the implicit memory of high-performing transformer VLN agents is not sufficient for IVLN, but agents that build maps can benefit from environment persistence, motivating a renewed focus on map-building agents in VLN.
SimPer: Simple Self-Supervised Learning of Periodic Targets
Oct 06, 2022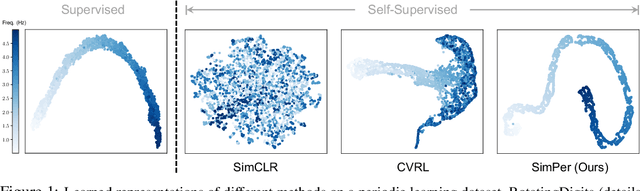
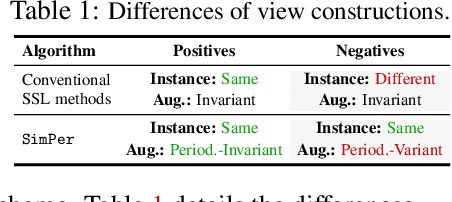
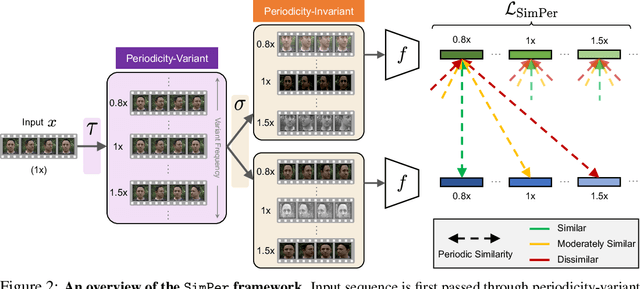

From human physiology to environmental evolution, important processes in nature often exhibit meaningful and strong periodic or quasi-periodic changes. Due to their inherent label scarcity, learning useful representations for periodic tasks with limited or no supervision is of great benefit. Yet, existing self-supervised learning (SSL) methods overlook the intrinsic periodicity in data, and fail to learn representations that capture periodic or frequency attributes. In this paper, we present SimPer, a simple contrastive SSL regime for learning periodic information in data. To exploit the periodic inductive bias, SimPer introduces customized augmentations, feature similarity measures, and a generalized contrastive loss for learning efficient and robust periodic representations. Extensive experiments on common real-world tasks in human behavior analysis, environmental sensing, and healthcare domains verify the superior performance of SimPer compared to state-of-the-art SSL methods, highlighting its intriguing properties including better data efficiency, robustness to spurious correlations, and generalization to distribution shifts. Code and data are available at: https://github.com/YyzHarry/SimPer.