 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Movement Penalized Bayesian Optimization with Application to Wind Energy Systems
Oct 14, 2022
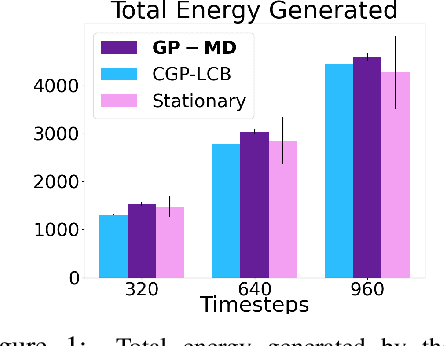
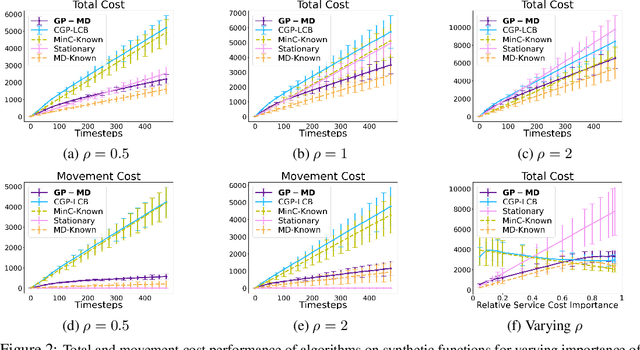
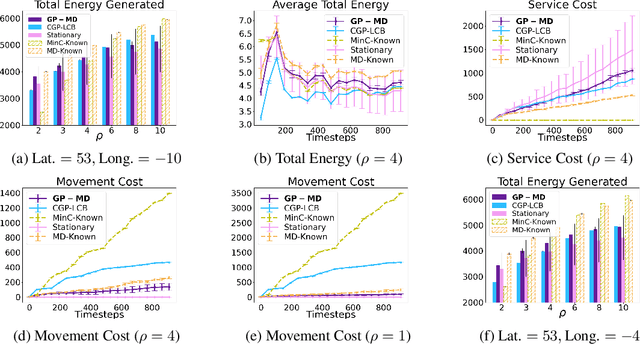
Contextual Bayesian optimization (CBO) is a powerful framework for sequential decision-making given side information, with important applications, e.g., in wind energy systems. In this setting, the learner receives context (e.g., weather conditions) at each round, and has to choose an action (e.g., turbine parameters). Standard algorithms assume no cost for switching their decisions at every round. However, in many practical applications, there is a cost associated with such changes, which should be minimized. We introduce the episodic CBO with movement costs problem and, based on the online learning approach for metrical task systems of Coester and Lee (2019), propose a novel randomized mirror descent algorithm that makes use of Gaussian Process confidence bounds. We compare its performance with the offline optimal sequence for each episode and provide rigorous regret guarantees. We further demonstrate our approach on the important real-world application of altitude optimization for Airborne Wind Energy Systems. In the presence of substantial movement costs, our algorithm consistently outperforms standard CBO algorithms.
ExAug: Robot-Conditioned Navigation Policies via Geometric Experience Augmentation
Oct 14, 2022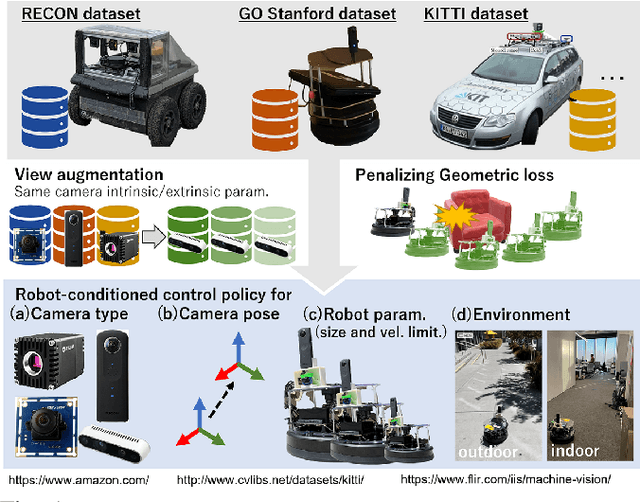
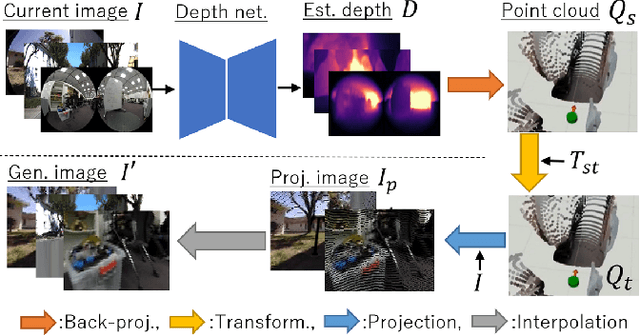
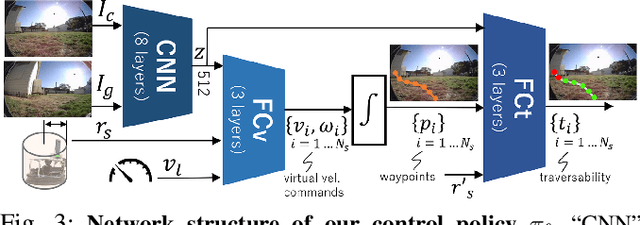

Machine learning techniques rely on large and diverse datasets for generalization. Computer vision, natural language processing, and other applications can often reuse public datasets to train many different models. However, due to differences in physical configurations, it is challenging to leverage public datasets for training robotic control policies on new robot platforms or for new tasks. In this work, we propose a novel framework, ExAug to augment the experiences of different robot platforms from multiple datasets in diverse environments. ExAug leverages a simple principle: by extracting 3D information in the form of a point cloud, we can create much more complex and structured augmentations, utilizing both generating synthetic images and geometric-aware penalization that would have been suitable in the same situation for a different robot, with different size, turning radius, and camera placement. The trained policy is evaluated on two new robot platforms with three different cameras in indoor and outdoor environments with obstacles.
G2A2: An Automated Graph Generator with Attributes and Anomalies
Oct 14, 2022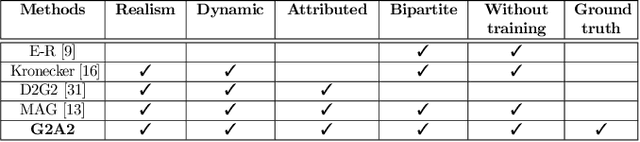
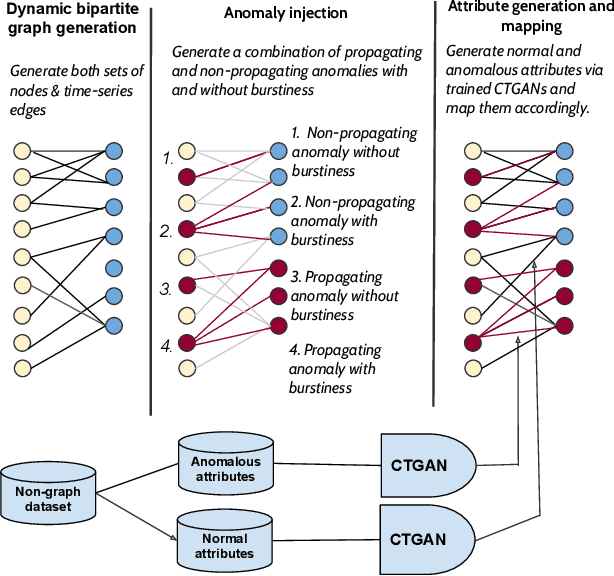
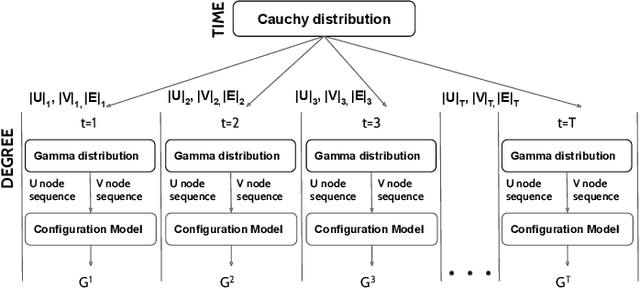

Many data-mining applications use dynamic attributed graphs to represent relational information; but due to security and privacy concerns, there is a dearth of available datasets that can be represented as dynamic attributed graphs. Even when such datasets are available, they do not have ground truth that can be used to train deep-learning models. Thus, we present G2A2, an automated graph generator with attributes and anomalies, which encompasses (1) probabilistic models to generate a dynamic bipartite graph, representing time-evolving connections between two independent sets of entities, (2) realistic injection of anomalies using a novel algorithm that captures the general properties of graph anomalies across domains, and (3) a deep generative model to produce realistic attributes, learned from an existing real-world dataset. Using the maximum mean discrepancy (MMD) metric to evaluate the realism of a G2A2-generated graph against three real-world graphs, G2A2 outperforms Kronecker graph generation by reducing the MMD distance by up to six-fold (6x).
End-to-end joint optimization of metasurface and image processing for compact snapshot hyperspectral imaging
Oct 14, 2022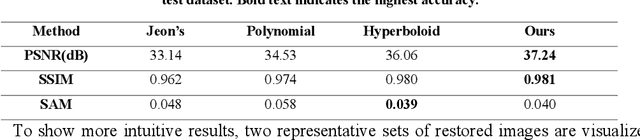
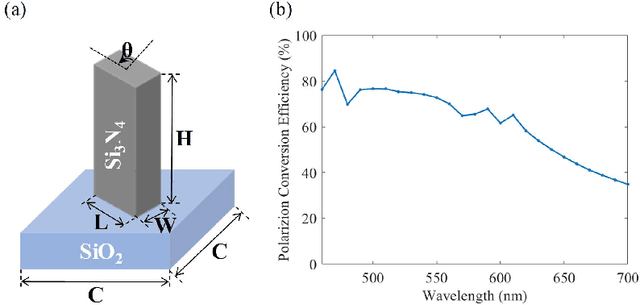
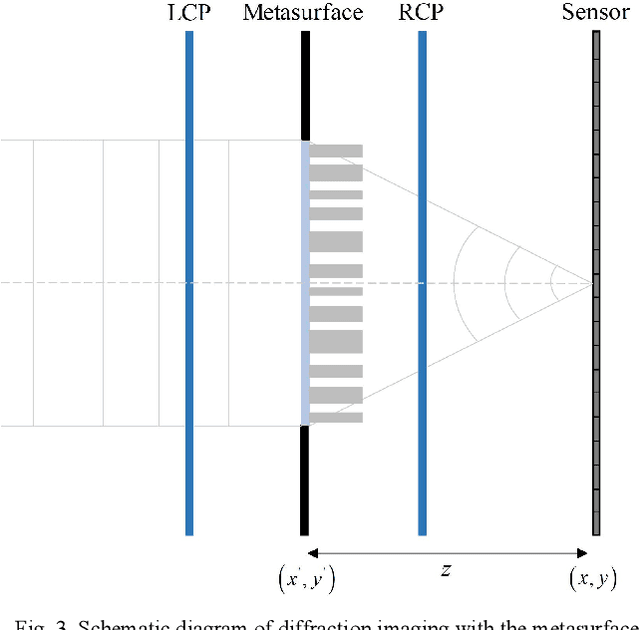
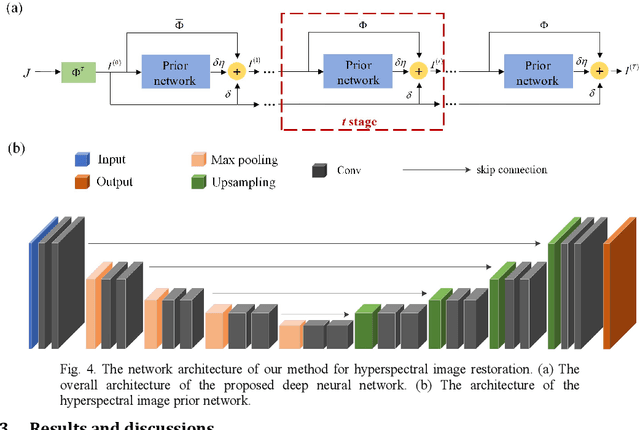
Traditional snapshot hyperspectral imaging systems generally require multiple refractive-optics-based elements to modulate light, resulting in bulky framework. In pursuit of a more compact form factor, a metasurface-based snapshot hyperspectral imaging system, which achieves joint optimization of metasurface and image processing, is proposed in this paper. The unprecedented light manipulation capabilities of metasurfaces are used in conjunction with neural networks to encode and decode light fields for better hyperspectral imaging. Specifically, the extremely strong dispersion of metasurfaces is exploited to distinguish spectral information, and a neural network based on spectral priors is applied for hyperspectral image reconstruction. By constructing a fully differentiable model of metasurface-based hyperspectral imaging, the front-end metasurface phase distribution and the back-end recovery network parameters can be jointly optimized. This method achieves high-quality hyperspectral reconstruction results numerically, outperforming separation optimization methods. The proposed system holds great potential for miniaturization and portability of hyperspectral imaging systems.
KSG: Knowledge and Skill Graph
Sep 13, 2022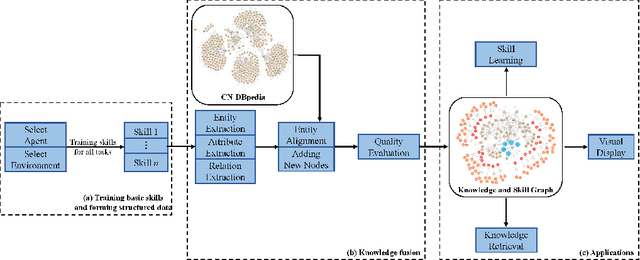
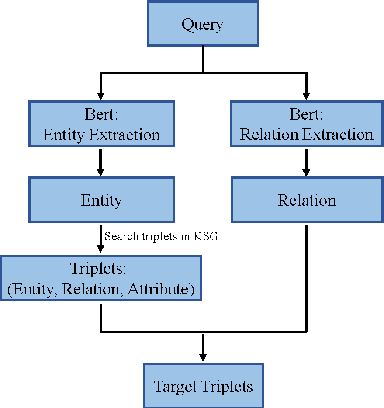
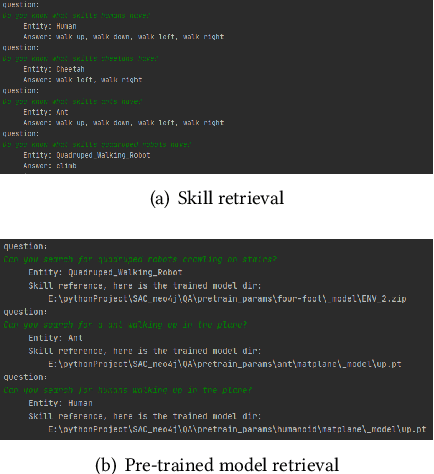
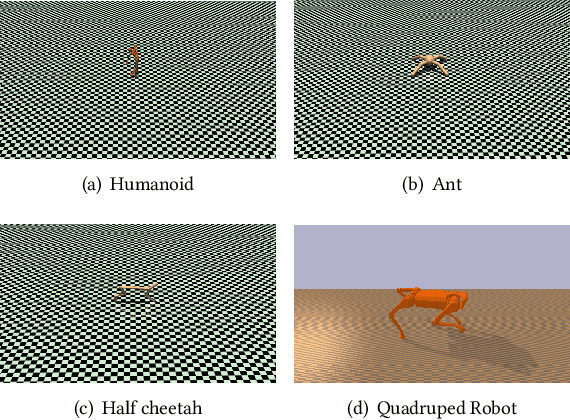
The knowledge graph (KG) is an essential form of knowledge representation that has grown in prominence in recent years. Because it concentrates on nominal entities and their relationships, traditional knowledge graphs are static and encyclopedic in nature. On this basis, event knowledge graph (Event KG) models the temporal and spatial dynamics by text processing to facilitate downstream applications, such as question-answering, recommendation and intelligent search. Existing KG research, on the other hand, mostly focuses on text processing and static facts, ignoring the vast quantity of dynamic behavioral information included in photos, movies, and pre-trained neural networks. In addition, no effort has been done to include behavioral intelligence information into the knowledge graph for deep reinforcement learning (DRL) and robot learning. In this paper, we propose a novel dynamic knowledge and skill graph (KSG), and then we develop a basic and specific KSG based on CN-DBpedia. The nodes are divided into entity and attribute nodes, with entity nodes containing the agent, environment, and skill (DRL policy or policy representation), and attribute nodes containing the entity description, pre-train network, and offline dataset. KSG can search for different agents' skills in various environments and provide transferable information for acquiring new skills. This is the first study that we are aware of that looks into dynamic KSG for skill retrieval and learning. Extensive experimental results on new skill learning show that KSG boosts new skill learning efficiency.
M-LIO: Multi-lidar, multi-IMU odometry with sensor dropout tolerance
Oct 09, 2022



We present a robust system for state estimation that fuses measurements from multiple lidars and inertial sensors with GNSS data. To initiate the method, we use the prior GNSS pose information. We then perform incremental motion in real-time, which produces robust motion estimates in a global frame by fusing lidar and IMU signals with GNSS translation components using a factor graph framework. We also propose methods to account for signal loss with a novel synchronization and fusion mechanism. To validate our approach extensive tests were carried out on data collected using Scania test vehicles (5 sequences for a total of ~ 7 Km). From our evaluations, we show an average improvement of 61% in relative translation and 42% rotational error compared to a state-of-the-art estimator fusing a single lidar/inertial sensor pair.
CovidMis20: COVID-19 Misinformation Detection System on Twitter Tweets using Deep Learning Models
Sep 13, 2022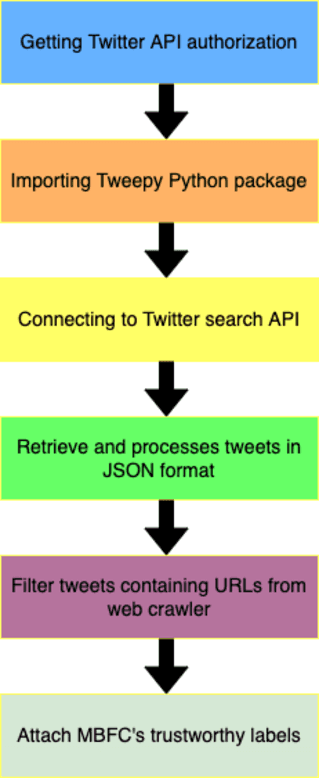
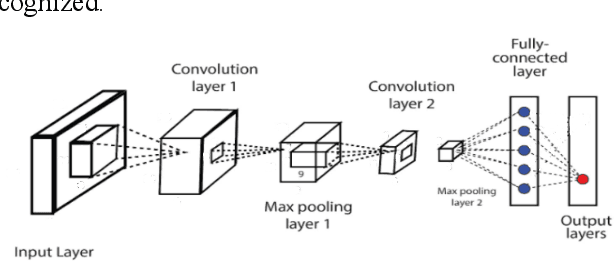
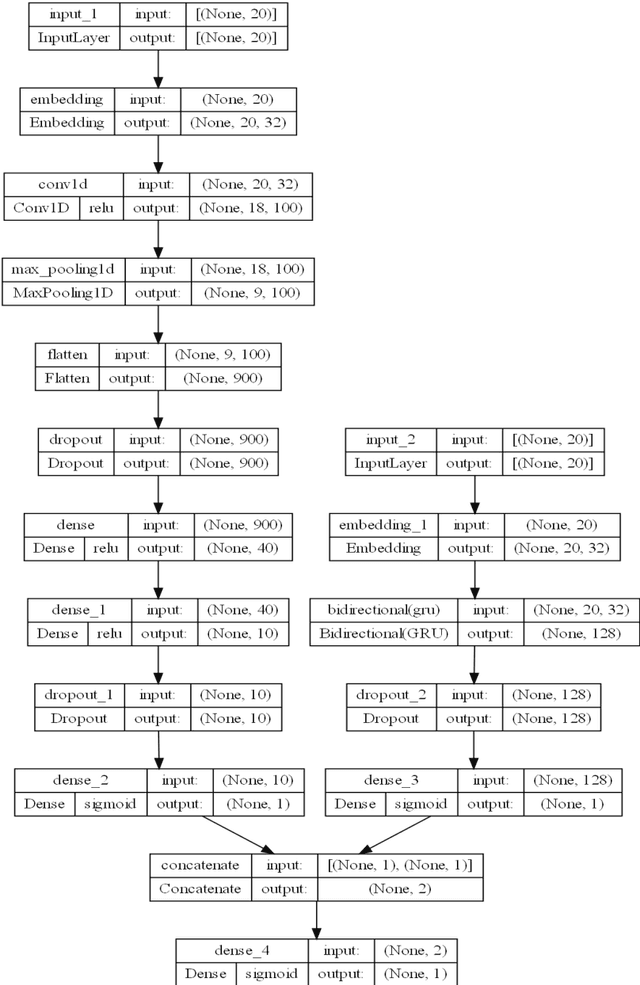
Online news and information sources are convenient and accessible ways to learn about current issues. For instance, more than 300 million people engage with posts on Twitter globally, which provides the possibility to disseminate misleading information. There are numerous cases where violent crimes have been committed due to fake news. This research presents the CovidMis20 dataset (COVID-19 Misinformation 2020 dataset), which consists of 1,375,592 tweets collected from February to July 2020. CovidMis20 can be automatically updated to fetch the latest news and is publicly available at: https://github.com/everythingguy/CovidMis20. This research was conducted using Bi-LSTM deep learning and an ensemble CNN+Bi-GRU for fake news detection. The results showed that, with testing accuracy of 92.23% and 90.56%, respectively, the ensemble CNN+Bi-GRU model consistently provided higher accuracy than the Bi-LSTM model.
Characterizing Verbatim Short-Term Memory in Neural Language Models
Oct 24, 2022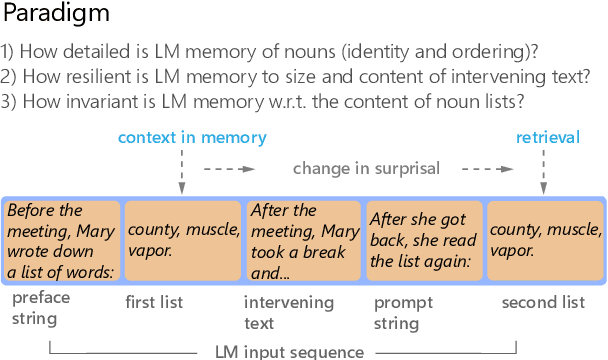
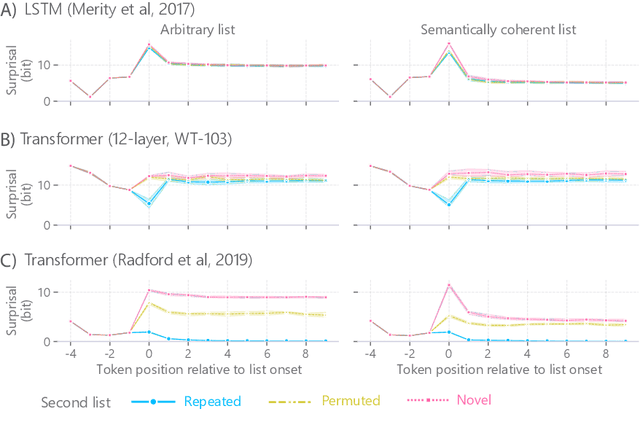
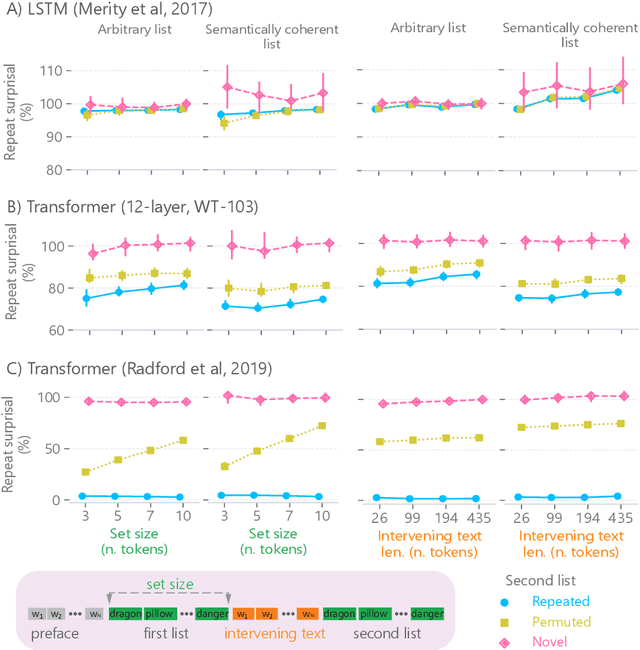
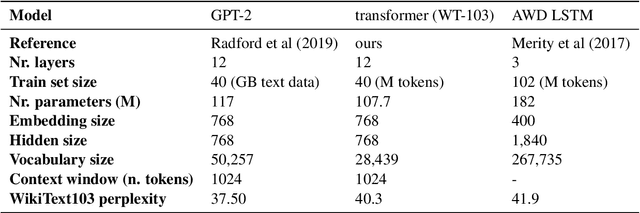
When a language model is trained to predict natural language sequences, its prediction at each moment depends on a representation of prior context. What kind of information about the prior context can language models retrieve? We tested whether language models could retrieve the exact words that occurred previously in a text. In our paradigm, language models (transformers and an LSTM) processed English text in which a list of nouns occurred twice. We operationalized retrieval as the reduction in surprisal from the first to the second list. We found that the transformers retrieved both the identity and ordering of nouns from the first list. Further, the transformers' retrieval was markedly enhanced when they were trained on a larger corpus and with greater model depth. Lastly, their ability to index prior tokens was dependent on learned attention patterns. In contrast, the LSTM exhibited less precise retrieval, which was limited to list-initial tokens and to short intervening texts. The LSTM's retrieval was not sensitive to the order of nouns and it improved when the list was semantically coherent. We conclude that transformers implemented something akin to a working memory system that could flexibly retrieve individual token representations across arbitrary delays; conversely, the LSTM maintained a coarser and more rapidly-decaying semantic gist of prior tokens, weighted toward the earliest items.
Weight Fixing Networks
Oct 24, 2022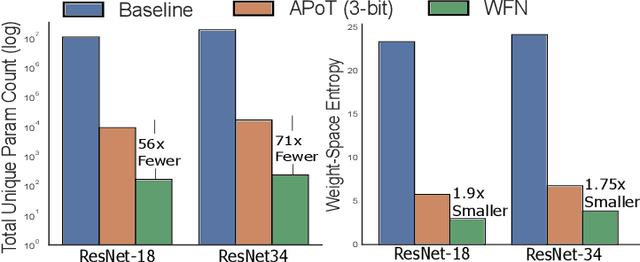
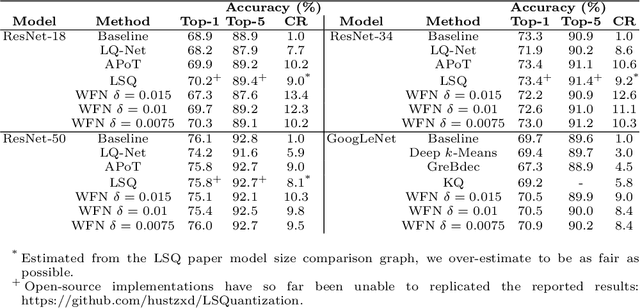
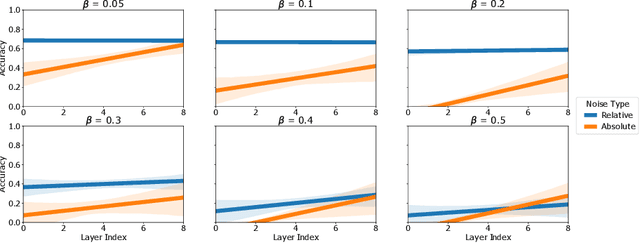
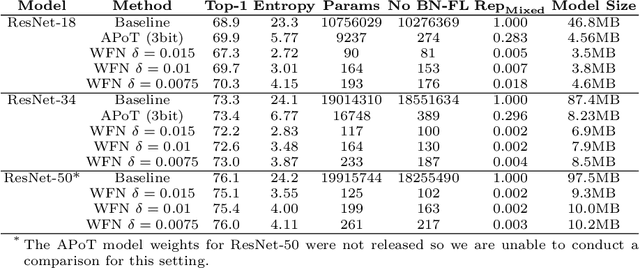
Modern iterations of deep learning models contain millions (billions) of unique parameters, each represented by a b-bit number. Popular attempts at compressing neural networks (such as pruning and quantisation) have shown that many of the parameters are superfluous, which we can remove (pruning) or express with less than b-bits (quantisation) without hindering performance. Here we look to go much further in minimising the information content of networks. Rather than a channel or layer-wise encoding, we look to lossless whole-network quantisation to minimise the entropy and number of unique parameters in a network. We propose a new method, which we call Weight Fixing Networks (WFN) that we design to realise four model outcome objectives: i) very few unique weights, ii) low-entropy weight encodings, iii) unique weight values which are amenable to energy-saving versions of hardware multiplication, and iv) lossless task-performance. Some of these goals are conflicting. To best balance these conflicts, we combine a few novel (and some well-trodden) tricks; a novel regularisation term, (i, ii) a view of clustering cost as relative distance change (i, ii, iv), and a focus on whole-network re-use of weights (i, iii). Our Imagenet experiments demonstrate lossless compression using 56x fewer unique weights and a 1.9x lower weight-space entropy than SOTA quantisation approaches.
Message Passing-Based Joint User Activity Detection and Channel Estimation for Temporally-Correlated Massive Access
Oct 24, 2022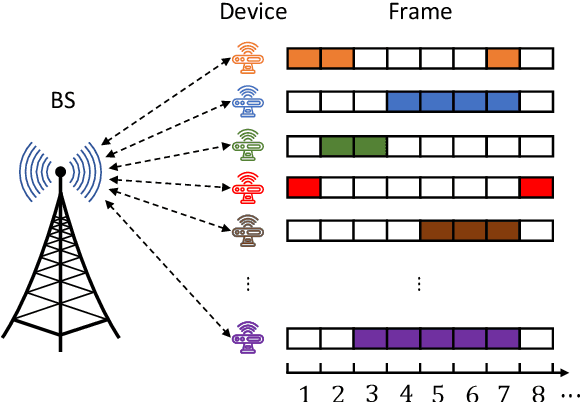
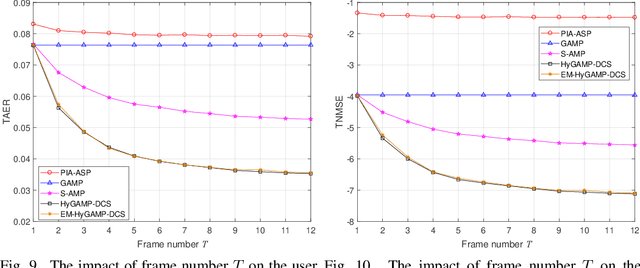
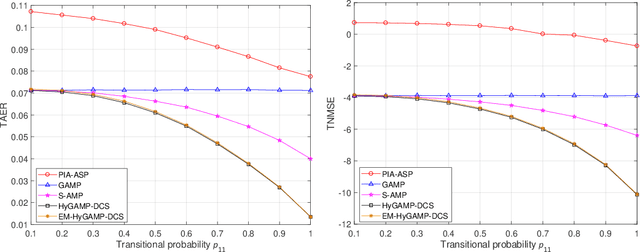
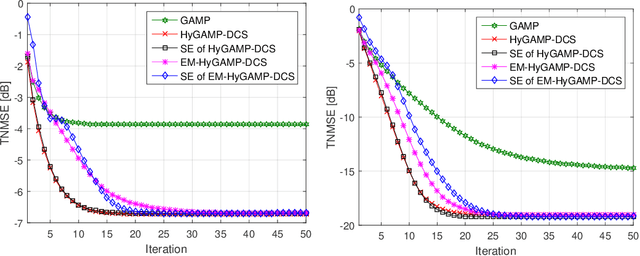
This paper studies the temporally-correlated massive access system where a large number of users communicate with the base station sporadically and continue transmitting data in the following frames in high probability when being active. To exploit both the sparsity and the temporal correlations in the user activities, we formulate the joint user activity detection and channel estimation problem in multiple consecutive frames as a dynamic compressed sensing (DCS) problem. Particularly, the problem is proposed to be solved under Bayesian inference to fully utilize the channel statistics and the activity evolution process. The hybrid generalized approximate message passing (HyGAMP) framework is leveraged to design a HyGAMP-DCS algorithm, which can nearly achieve the Bayesian optimality with efficient computations. Specifically, a GAMP part for channel estimation and an MP part for activity likelihood update are included in the proposed algorithm, then the extrinsic information is exchanged between them for performance enhancement. Moveover, we develop the expectation maximization HyGAMP-DCS (EM-HyGAMP-DCS) algorithm to adaptively learn the hyperparameters during the estimation procedure when the system statistics are unavailable. Particularly, the analytical tool of state evolution is provided to find the appropriate hyperparameter initialization that ensures EM-HyGAMP-DCS to achieve satisfied performance and fast convergence. From the simulation results, it is validated that our proposed algorithm can significantly outperform the existing methods.