 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Textwash -- automated open-source text anonymisation
Aug 27, 2022

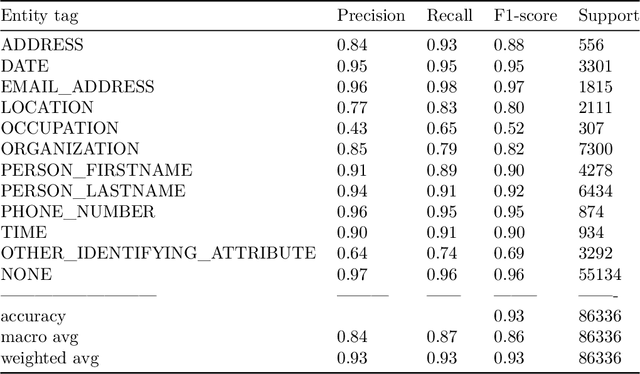
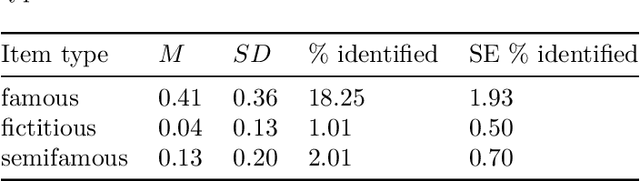
The increased use of text data in social science research has benefited from easy-to-access data (e.g., Twitter). That trend comes at the cost of research requiring sensitive but hard-to-share data (e.g., interview data, police reports, electronic health records). We introduce a solution to that stalemate with the open-source text anonymisation software_Textwash_. This paper presents the empirical evaluation of the tool using the TILD criteria: a technical evaluation (how accurate is the tool?), an information loss evaluation (how much information is lost in the anonymisation process?) and a de-anonymisation test (can humans identify individuals from anonymised text data?). The findings suggest that Textwash performs similar to state-of-the-art entity recognition models and introduces a negligible information loss of 0.84%. For the de-anonymisation test, we tasked humans to identify individuals by name from a dataset of crowdsourced person descriptions of very famous, semi-famous and non-existing individuals. The de-anonymisation rate ranged from 1.01-2.01% for the realistic use cases of the tool. We replicated the findings in a second study and concluded that Textwash succeeds in removing potentially sensitive information that renders detailed person descriptions practically anonymous.
A Multi-turn Machine Reading Comprehension Framework with Rethink Mechanism for Emotion-Cause Pair Extraction
Sep 16, 2022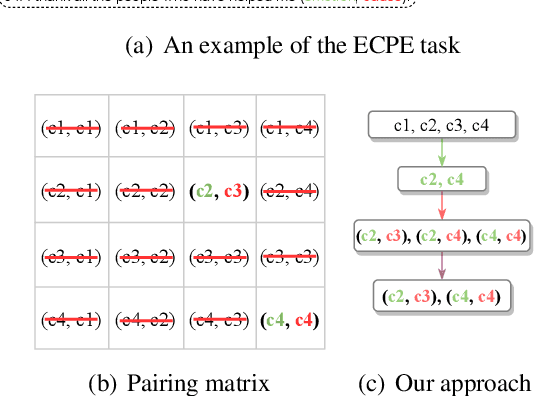
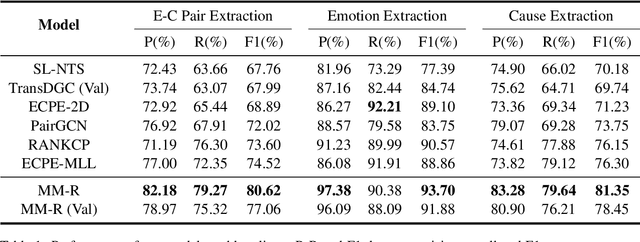
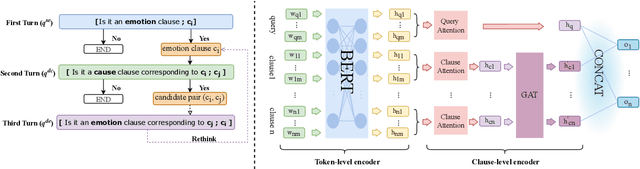

Emotion-cause pair extraction (ECPE) is an emerging task in emotion cause analysis, which extracts potential emotion-cause pairs from an emotional document. Most recent studies use end-to-end methods to tackle the ECPE task. However, these methods either suffer from a label sparsity problem or fail to model complicated relations between emotions and causes. Furthermore, they all do not consider explicit semantic information of clauses. To this end, we transform the ECPE task into a document-level machine reading comprehension (MRC) task and propose a Multi-turn MRC framework with Rethink mechanism (MM-R). Our framework can model complicated relations between emotions and causes while avoiding generating the pairing matrix (the leading cause of the label sparsity problem). Besides, the multi-turn structure can fuse explicit semantic information flow between emotions and causes. Extensive experiments on the benchmark emotion cause corpus demonstrate the effectiveness of our proposed framework, which outperforms existing state-of-the-art methods.
Measuring Air Quality via Multimodal AI and Satellite Imagery
Nov 01, 2022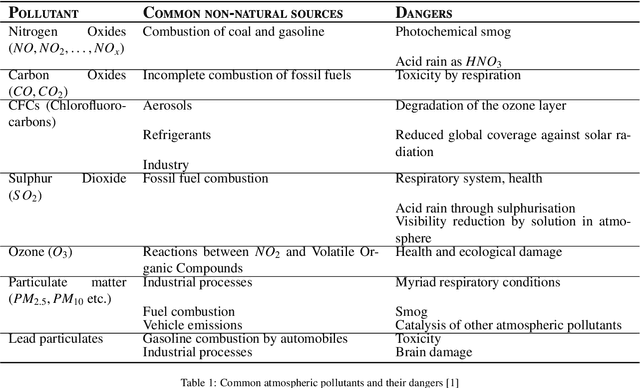
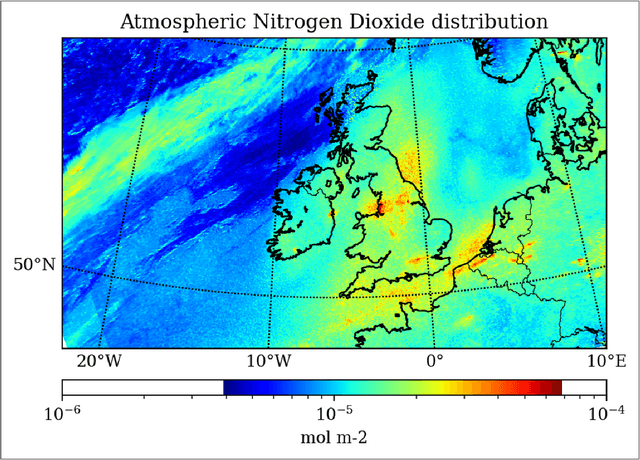
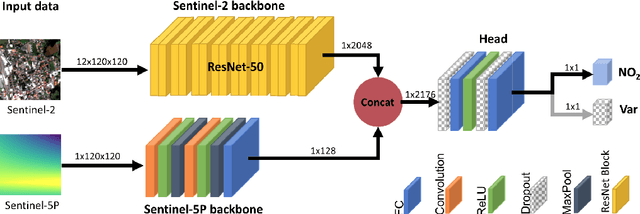

Climate change may be classified as the most important environmental problem that the Earth is currently facing, and affects all living species on Earth. Given that air-quality monitoring stations are typically ground-based their abilities to detect pollutant distributions are often restricted to wide areas. Satellites however have the potential for studying the atmosphere at large; the European Space Agency (ESA) Copernicus project satellite, "Sentinel-5P" is a newly launched satellite capable of measuring a variety of pollutant information with publicly available data outputs. This paper seeks to create a multi-modal machine learning model for predicting air-quality metrics where monitoring stations do not exist. The inputs of this model will include a fusion of ground measurements and satellite data with the goal of highlighting pollutant distribution and motivating change in societal and industrial behaviors. A new dataset of European pollution monitoring station measurements is created with features including $\textit{altitude, population, etc.}$ from the ESA Copernicus project. This dataset is used to train a multi-modal ML model, Air Quality Network (AQNet) capable of fusing these various types of data sources to output predictions of various pollutants. These predictions are then aggregated to create an "air-quality index" that could be used to compare air quality over different regions. Three pollutants, NO$_2$, O$_3$, and PM$_{10}$, are predicted successfully by AQNet and the network was found to be useful compared to a model only using satellite imagery. It was also found that the addition of supporting data improves predictions. When testing the developed AQNet on out-of-sample data of the UK and Ireland, we obtain satisfactory estimates though on average pollution metrics were roughly overestimated by around 20\%.
Incorporating Causal Analysis into Diversified and Logical Response Generation
Oct 11, 2022
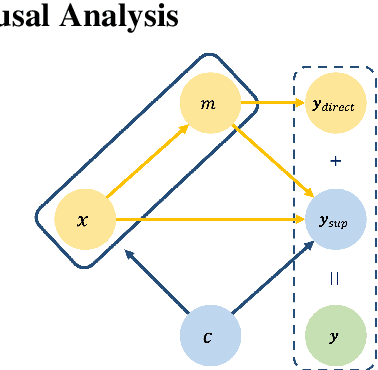
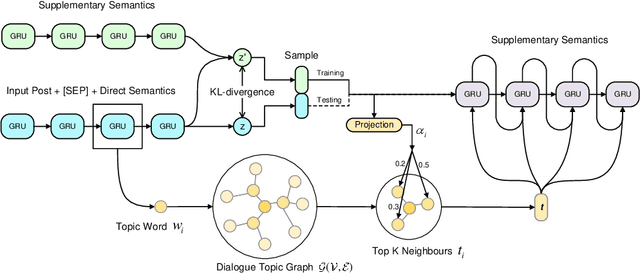
Although the Conditional Variational AutoEncoder (CVAE) model can generate more diversified responses than the traditional Seq2Seq model, the responses often have low relevance with the input words or are illogical with the question. A causal analysis is carried out to study the reasons behind, and a methodology of searching for the mediators and mitigating the confounding bias in dialogues is provided. Specifically, we propose to predict the mediators to preserve relevant information and auto-regressively incorporate the mediators into generating process. Besides, a dynamic topic graph guided conditional variational autoencoder (TGG-CVAE) model is utilized to complement the semantic space and reduce the confounding bias in responses. Extensive experiments demonstrate that the proposed model is able to generate both relevant and informative responses, and outperforms the state-of-the-art in terms of automatic metrics and human evaluations.
Asymptotic-Preserving Neural Networks for hyperbolic systems with diffusive scaling
Oct 17, 2022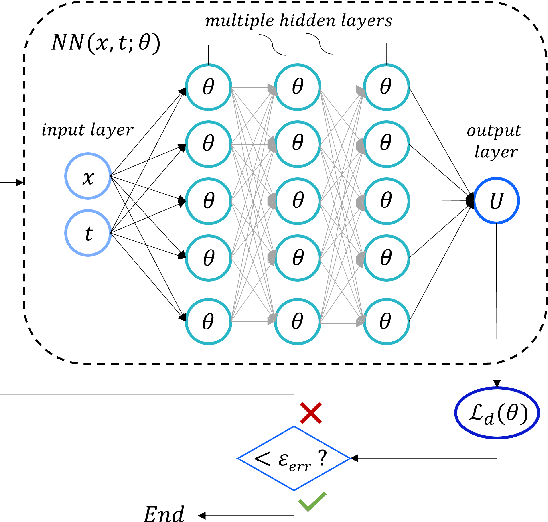
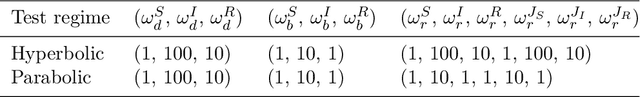
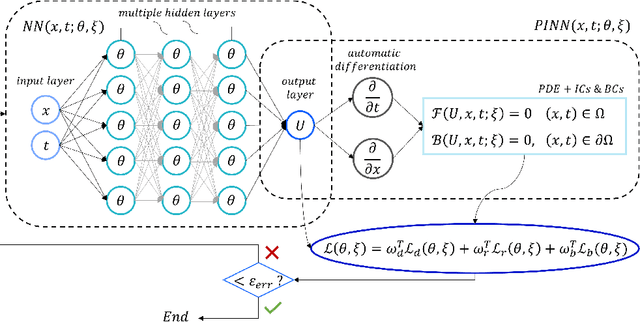
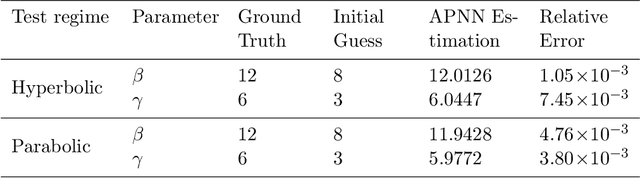
With the rapid advance of Machine Learning techniques and the deep increment of availability of scientific data, data-driven approaches have started to become progressively popular across science, causing a fundamental shift in the scientific method after proving to be powerful tools with a direct impact in many areas of society. Nevertheless, when attempting to analyze the dynamics of complex multiscale systems, the usage of standard Deep Neural Networks (DNNs) and even standard Physics-Informed Neural Networks (PINNs) may lead to incorrect inferences and predictions, due to the presence of small scales leading to reduced or simplified models in the system that have to be applied consistently during the learning process. In this Chapter, we will address these issues in light of recent results obtained in the development of Asymptotic-Preserving Neural Networks (APNNs) for hyperbolic models with diffusive scaling. Several numerical tests show how APNNs provide considerably better results with respect to the different scales of the problem when compared with standard DNNs and PINNs, especially when analyzing scenarios in which only little and scattered information is available.
Transferring Knowledge via Neighborhood-Aware Optimal Transport for Low-Resource Hate Speech Detection
Oct 17, 2022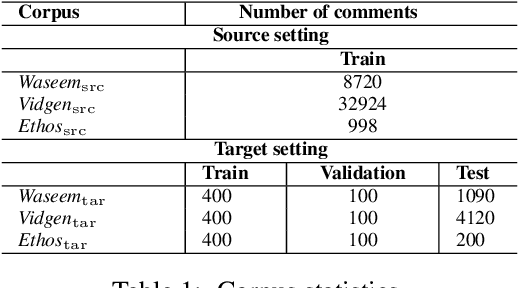
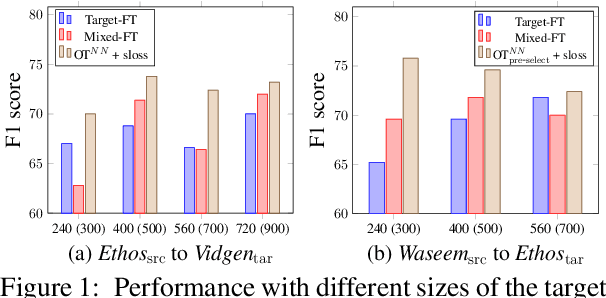

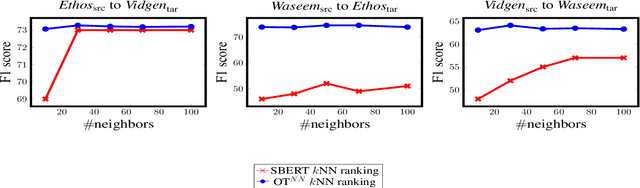
The concerning rise of hateful content on online platforms has increased the attention towards automatic hate speech detection, commonly formulated as a supervised classification task. State-of-the-art deep learning-based approaches usually require a substantial amount of labeled resources for training. However, annotating hate speech resources is expensive, time-consuming, and often harmful to the annotators. This creates a pressing need to transfer knowledge from the existing labeled resources to low-resource hate speech corpora with the goal of improving system performance. For this, neighborhood-based frameworks have been shown to be effective. However, they have limited flexibility. In our paper, we propose a novel training strategy that allows flexible modeling of the relative proximity of neighbors retrieved from a resource-rich corpus to learn the amount of transfer. In particular, we incorporate neighborhood information with Optimal Transport, which permits exploiting the geometry of the data embedding space. By aligning the joint embedding and label distributions of neighbors, we demonstrate substantial improvements over strong baselines, in low-resource scenarios, on different publicly available hate speech corpora.
Deformably-Scaled Transposed Convolution
Oct 17, 2022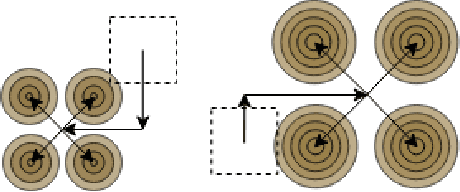

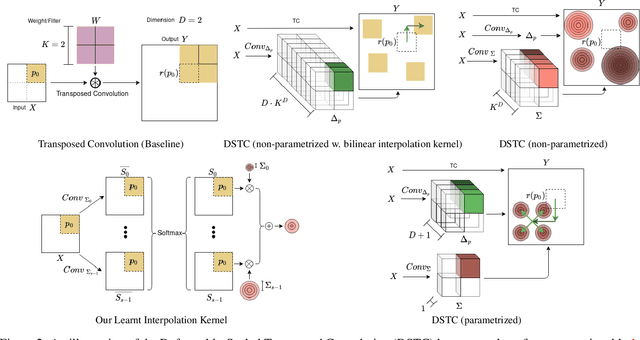
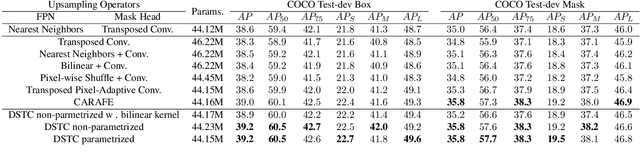
Transposed convolution is crucial for generating high-resolution outputs, yet has received little attention compared to convolution layers. In this work we revisit transposed convolution and introduce a novel layer that allows us to place information in the image selectively and choose the `stroke breadth' at which the image is synthesized, whilst incurring a small additional parameter cost. For this we introduce three ideas: firstly, we regress offsets to the positions where the transpose convolution results are placed; secondly we broadcast the offset weight locations over a learnable neighborhood; and thirdly we use a compact parametrization to share weights and restrict offsets. We show that simply substituting upsampling operators with our novel layer produces substantial improvements across tasks as diverse as instance segmentation, object detection, semantic segmentation, generative image modeling, and 3D magnetic resonance image enhancement, while outperforming all existing variants of transposed convolutions. Our novel layer can be used as a drop-in replacement for 2D and 3D upsampling operators and the code will be publicly available.
Visual onoma-to-wave: environmental sound synthesis from visual onomatopoeias and sound-source images
Oct 17, 2022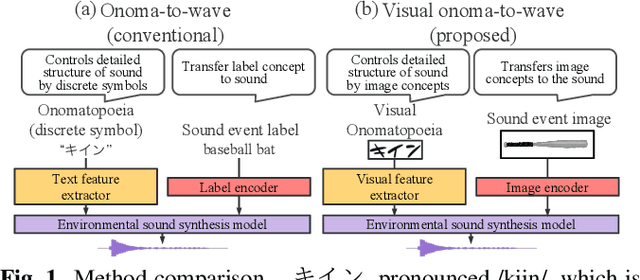
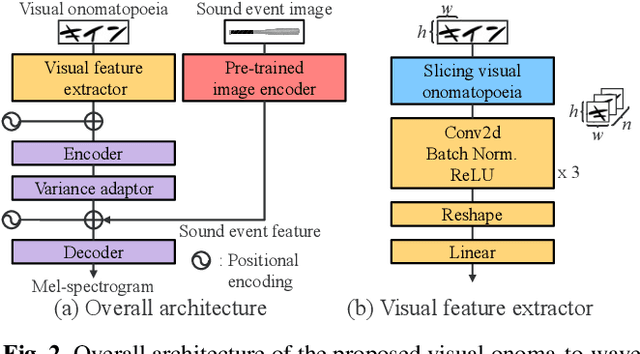

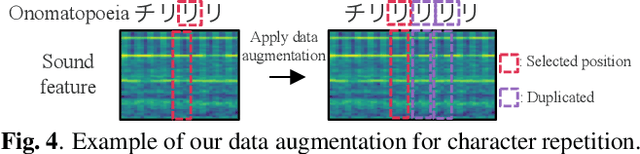
We propose a method for synthesizing environmental sounds from visually represented onomatopoeias and sound sources. An onomatopoeia is a word that imitates a sound structure, i.e., the text representation of sound. From this perspective, onoma-to-wave has been proposed to synthesize environmental sounds from the desired onomatopoeia texts. Onomatopoeias have another representation: visual-text representations of sounds in comics, advertisements, and virtual reality. A visual onomatopoeia (visual text of onomatopoeia) contains rich information that is not present in the text, such as a long-short duration of the image, so the use of this representation is expected to synthesize diverse sounds. Therefore, we propose visual onoma-to-wave for environmental sound synthesis from visual onomatopoeia. The method can transfer visual concepts of the visual text and sound-source image to the synthesized sound. We also propose a data augmentation method focusing on the repetition of onomatopoeias to enhance the performance of our method. An experimental evaluation shows that the methods can synthesize diverse environmental sounds from visual text and sound-source images.
tegdet: An extensible Python Library for Anomaly Detection using Time-Evolving Graphs
Oct 17, 2022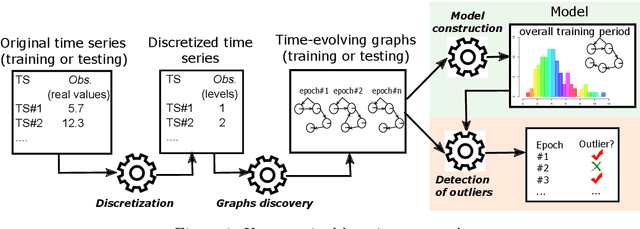

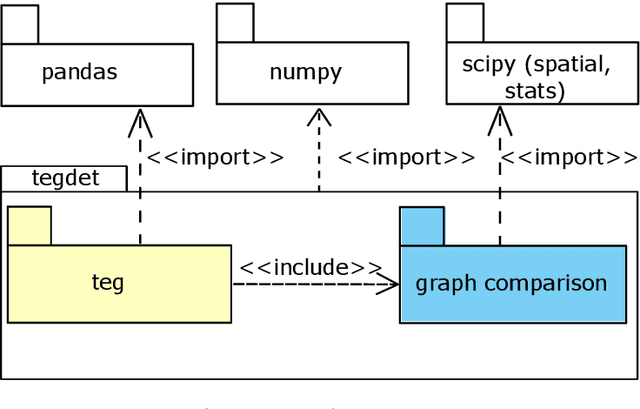

This paper presents a new Python library for anomaly detection in unsupervised learning approaches. The input for the library is a univariate time series representing observations of a given phenomenon. Then, it can identify anomalous epochs, i.e., time intervals where the observations are above a given percentile of a baseline distribution, defined by a dissimilarity metric. Using time-evolving graphs for the anomaly detection, the library leverages valuable information given by the inter-dependencies among data. Currently, the library implements 28 different dissimilarity metrics, and it has been designed to be easily extended with new ones. Through an API, the library exposes a complete functionality to carry out the anomaly detection. Summarizing, to the best of our knowledge, this library is the only one publicly available, that based on dynamic graphs, can be extended with other state-of-the-art anomaly detection techniques. Our experimentation shows promising results regarding the execution times of the algorithms and the accuracy of the implemented techniques. Additionally, the paper provides guidelines for setting the parameters of the detectors to improve their performance and prediction accuracy.
Towards Relation Extraction From Speech
Oct 17, 2022



Relation extraction typically aims to extract semantic relationships between entities from the unstructured text. One of the most essential data sources for relation extraction is the spoken language, such as interviews and dialogues. However, the error propagation introduced in automatic speech recognition (ASR) has been ignored in relation extraction, and the end-to-end speech-based relation extraction method has been rarely explored. In this paper, we propose a new listening information extraction task, i.e., speech relation extraction. We construct the training dataset for speech relation extraction via text-to-speech systems, and we construct the testing dataset via crowd-sourcing with native English speakers. We explore speech relation extraction via two approaches: the pipeline approach conducting text-based extraction with a pretrained ASR module, and the end2end approach via a new proposed encoder-decoder model, or what we called SpeechRE. We conduct comprehensive experiments to distinguish the challenges in speech relation extraction, which may shed light on future explorations. We share the code and data on https://github.com/wutong8023/SpeechRE.