 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Linear Video Transformer with Feature Fixation
Oct 15, 2022
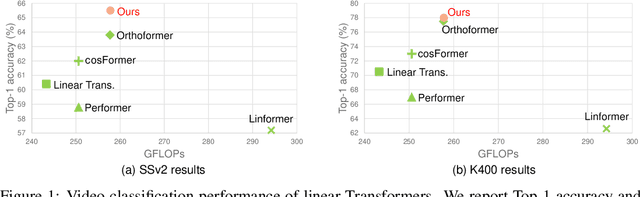
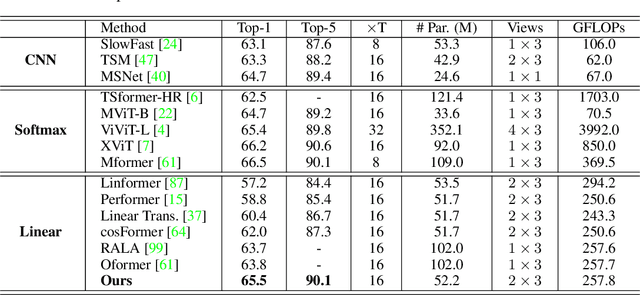

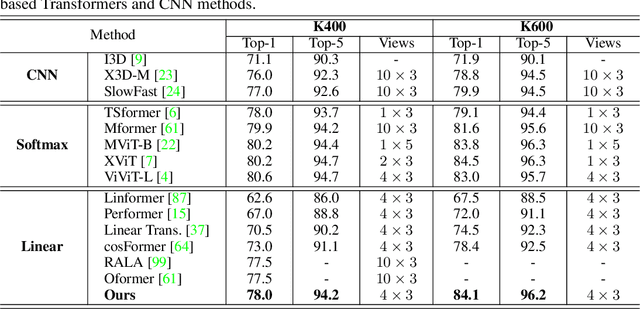
Vision Transformers have achieved impressive performance in video classification, while suffering from the quadratic complexity caused by the Softmax attention mechanism. Some studies alleviate the computational costs by reducing the number of tokens in attention calculation, but the complexity is still quadratic. Another promising way is to replace Softmax attention with linear attention, which owns linear complexity but presents a clear performance drop. We find that such a drop in linear attention results from the lack of attention concentration on critical features. Therefore, we propose a feature fixation module to reweight the feature importance of the query and key before computing linear attention. Specifically, we regard the query, key, and value as various latent representations of the input token, and learn the feature fixation ratio by aggregating Query-Key-Value information. This is beneficial for measuring the feature importance comprehensively. Furthermore, we enhance the feature fixation by neighborhood association, which leverages additional guidance from spatial and temporal neighbouring tokens. The proposed method significantly improves the linear attention baseline and achieves state-of-the-art performance among linear video Transformers on three popular video classification benchmarks. With fewer parameters and higher efficiency, our performance is even comparable to some Softmax-based quadratic Transformers.
Massive MIMO Evolution Towards 3GPP Release 18
Oct 15, 2022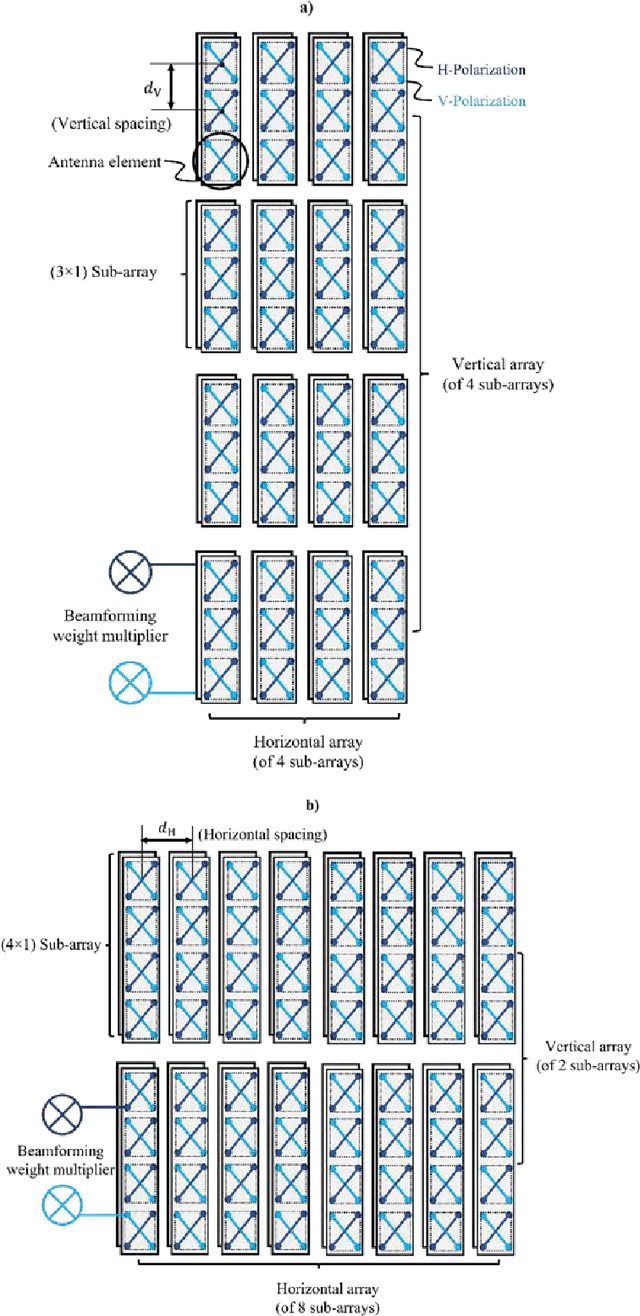

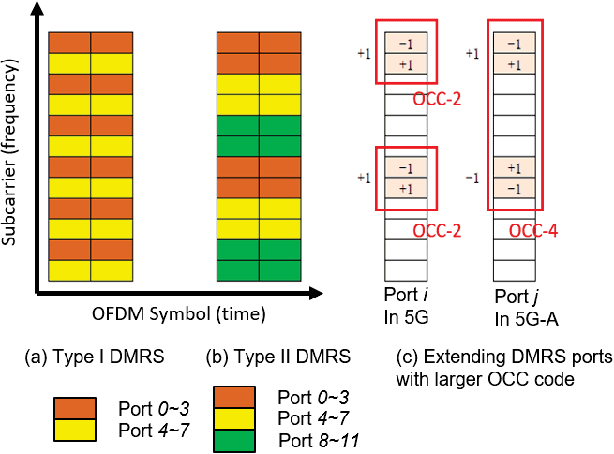
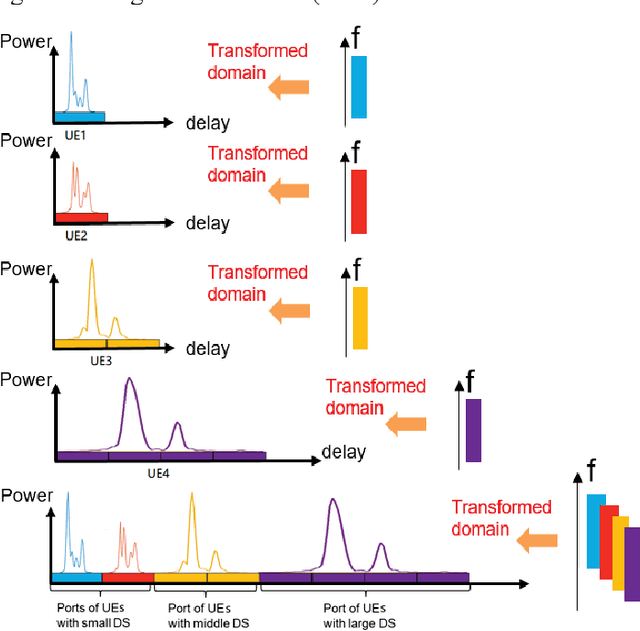
Since the introduction of fifth-generation new radio (5G-NR) in Third Generation Partnership Project (3GPP) Release 15, swift progress has been made to evolve 5G with 3GPP Release 18 emerging. A critical aspect is the design of massive multiple-input multiple-output (MIMO) technology. In this line, this paper makes several important contributions: We provide a comprehensive overview of the evolution of standardized massive MIMO features from 3GPP Release 15 to 17 for both time/frequency-division duplex operation across bands FR-1 and FR-2. We analyze the progress on channel state information (CSI) frameworks, beam management frameworks and present enhancements for uplink CSI. We shed light on emerging 3GPP Release 18 problems requiring imminent attention. These include advanced codebook design and sounding reference signal design for coherent joint transmission (CJT) with multiple transmission/reception points (multi- TRPs). We discuss advancements in uplink demodulation reference signal design, enhancements for mobility to provide accurate CSI estimates, and unified transmission configuration indicator framework tailored for FR-2 bands. For each concept, we provide system level simulation results to highlight their performance benefits. Via field trials in an outdoor environment at Shanghai Jiaotong University, we demonstrate the gains of multi-TRP CJT relative to single TRP at 3.7 GHz.
Optimal Energy Shaping Control for a Backdrivable Hip Exoskeleton
Oct 07, 2022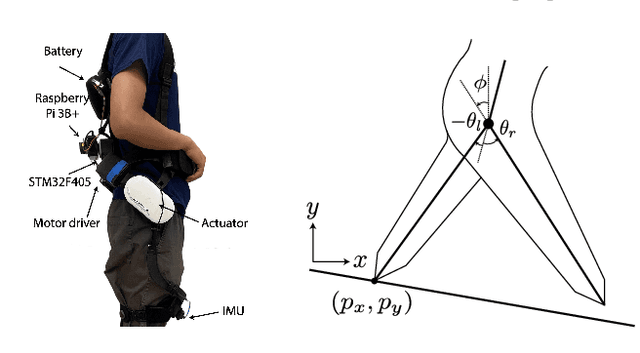
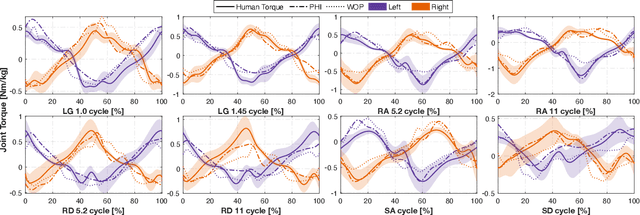
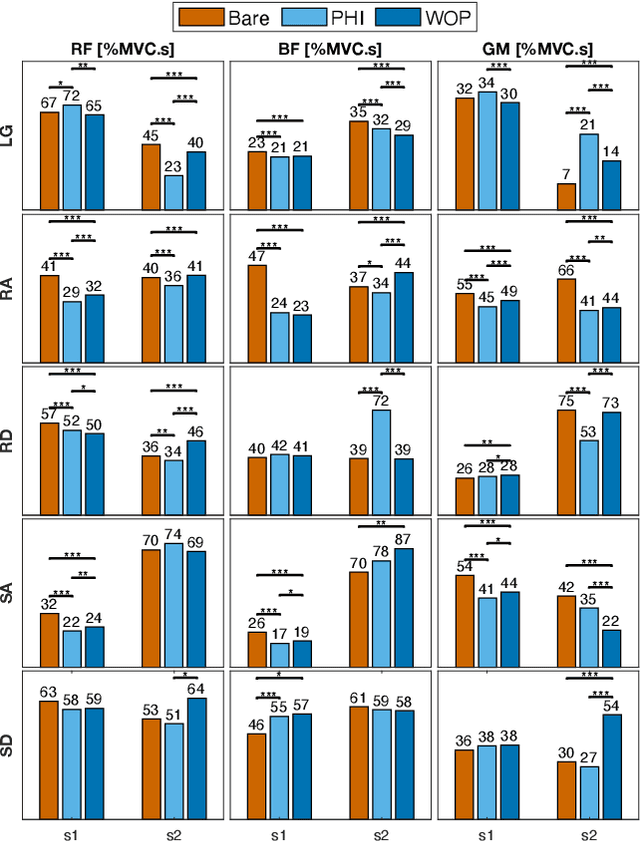
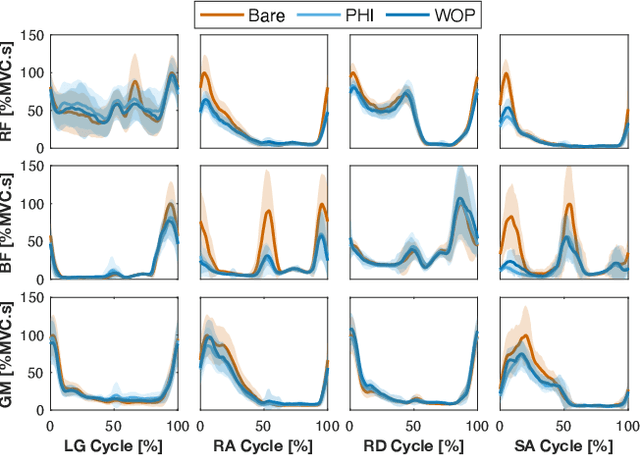
Task-dependent controllers widely used in exoskeletons track predefined trajectories, which overly constrain the volitional motion of individuals with remnant voluntary mobility. Energy shaping, on the other hand, provides task-invariant assistance by altering the human body's dynamic characteristics in the closed loop. While human-exoskeleton systems are often modeled using Euler-Lagrange equations, in our previous work we modeled the system as a port-controlled-Hamiltonian system, and a task-invariant controller was designed for a knee-ankle exoskeleton using interconnection-damping assignment passivity-based control. In this paper, we extend this framework to design a controller for a backdrivable hip exoskeleton to assist multiple tasks. A set of basis functions that contains information of kinematics is selected and corresponding coefficients are optimized, which allows the controller to provide torque that fits normative human torque for different activities of daily life. Human-subject experiments with two able-bodied subjects demonstrated the controller's capability to reduce muscle effort across different tasks.
Visualize Before You Write: Imagination-Guided Open-Ended Text Generation
Oct 07, 2022
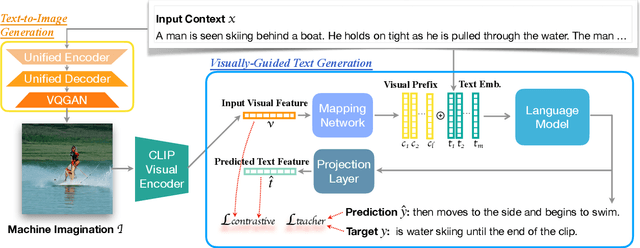
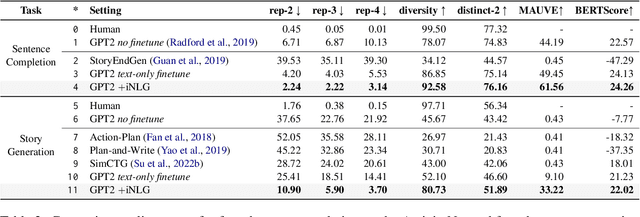
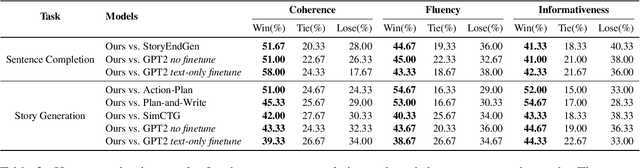
Recent advances in text-to-image synthesis make it possible to visualize machine imaginations for a given context. On the other hand, when generating text, human writers are gifted at creative visualization, which enhances their writings by forming imaginations as blueprints before putting down the stories in words. Inspired by such a cognitive process, we ask the natural question of whether we can endow machines with the same ability to utilize visual information and construct a general picture of the context to guide text generation. In this work, we propose iNLG that uses machine-generated images to guide language models (LM) in open-ended text generation. The experiments and analyses demonstrate the effectiveness of iNLG on open-ended text generation tasks, including text completion, story generation, and concept-to-text generation in few-shot scenarios. Both automatic metrics and human evaluations verify that the text snippets generated by our iNLG are coherent and informative while displaying minor degeneration.
Learning a Visually Grounded Memory Assistant
Oct 07, 2022


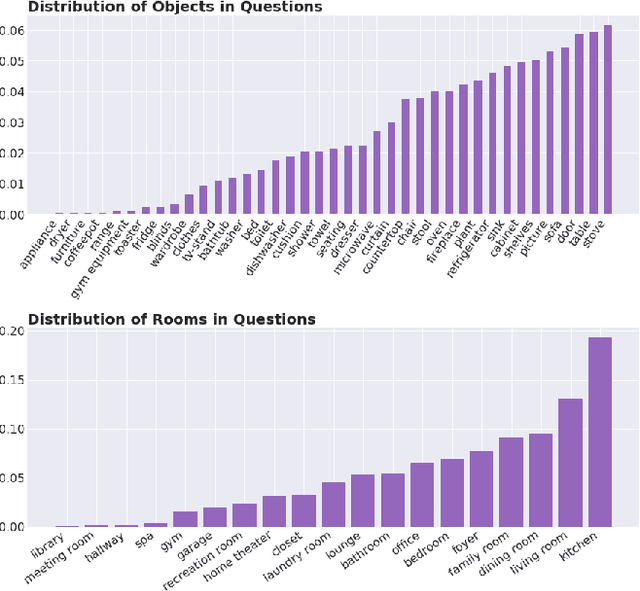
We introduce a novel interface for large scale collection of human memory and assistance. Using the 3D Matterport simulator we create a realistic indoor environments in which we have people perform specific embodied memory tasks that mimic household daily activities. This interface was then deployed on Amazon Mechanical Turk allowing us to test and record human memory, navigation and needs for assistance at a large scale that was previously impossible. Using the interface we collect the `The Visually Grounded Memory Assistant Dataset' which is aimed at developing our understanding of (1) the information people encode during navigation of 3D environments and (2) conditions under which people ask for memory assistance. Additionally we experiment with with predicting when people will ask for assistance using models trained on hand-selected visual and semantic features. This provides an opportunity to build stronger ties between the machine-learning and cognitive-science communities through learned models of human perception, memory, and cognition.
Towards Multi-Modal Sarcasm Detection via Hierarchical Congruity Modeling with Knowledge Enhancement
Oct 07, 2022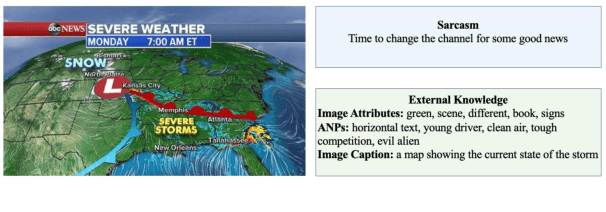
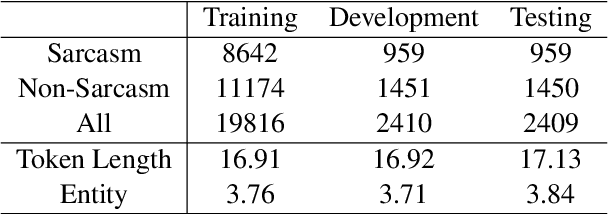

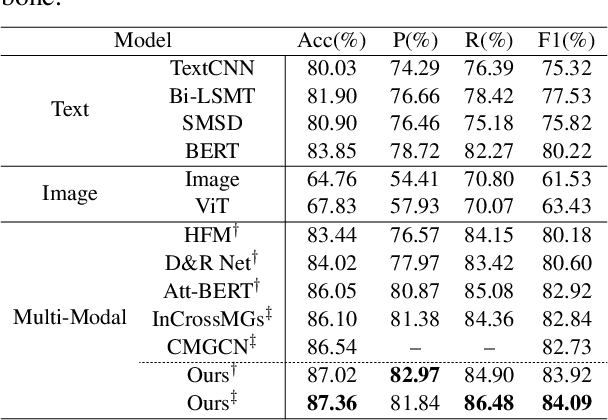
Sarcasm is a linguistic phenomenon indicating a discrepancy between literal meanings and implied intentions. Due to its sophisticated nature, it is usually challenging to be detected from the text itself. As a result, multi-modal sarcasm detection has received more attention in both academia and industries. However, most existing techniques only modeled the atomic-level inconsistencies between the text input and its accompanying image, ignoring more complex compositions for both modalities. Moreover, they neglected the rich information contained in external knowledge, e.g., image captions. In this paper, we propose a novel hierarchical framework for sarcasm detection by exploring both the atomic-level congruity based on multi-head cross attention mechanism and the composition-level congruity based on graph neural networks, where a post with low congruity can be identified as sarcasm. In addition, we exploit the effect of various knowledge resources for sarcasm detection. Evaluation results on a public multi-modal sarcasm detection dataset based on Twitter demonstrate the superiority of our proposed model.
Resolving Class Imbalance for LiDAR-based Object Detector by Dynamic Weight Average and Contextual Ground Truth Sampling
Oct 07, 2022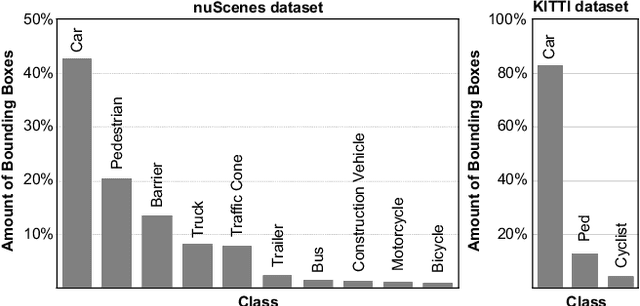
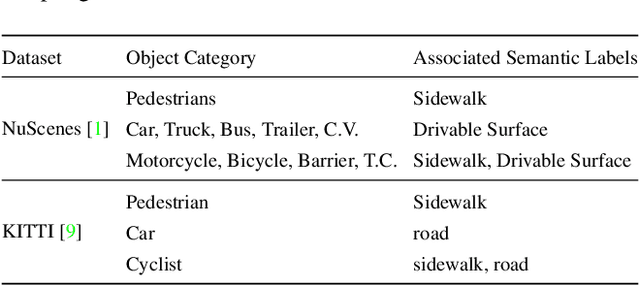
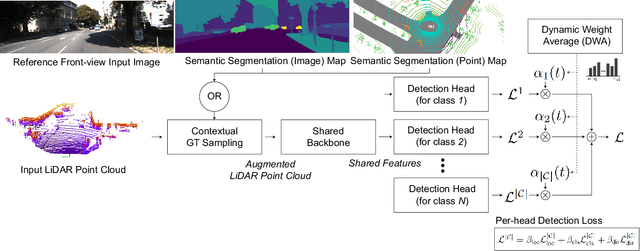
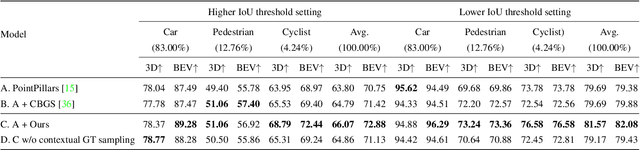
An autonomous driving system requires a 3D object detector, which must perceive all present road agents reliably to navigate an environment safely. However, real-world driving datasets often suffer from the problem of data imbalance, which causes difficulties in training a model that works well across all classes, resulting in an undesired imbalanced sub-optimal performance. In this work, we propose a method to address this data imbalance problem. Our method consists of two main components: (i) a LiDAR-based 3D object detector with per-class multiple detection heads where losses from each head are modified by dynamic weight average to be balanced. (ii) Contextual ground truth (GT) sampling, where we improve conventional GT sampling techniques by leveraging semantic information to augment point cloud with sampled ground truth GT objects. Our experiment with KITTI and nuScenes datasets confirms our proposed method's effectiveness in dealing with the data imbalance problem, producing better detection accuracy compared to existing approaches.
Multi-grained Label Refinement Network with Dependency Structures for Joint Intent Detection and Slot Filling
Sep 09, 2022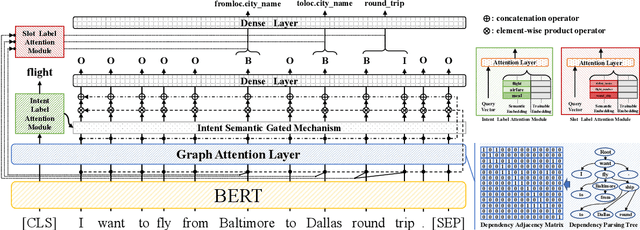

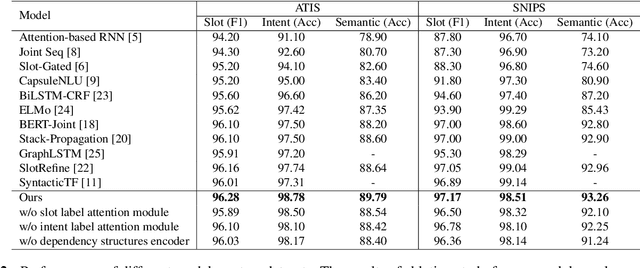
Slot filling and intent detection are two fundamental tasks in the field of natural language understanding. Due to the strong correlation between these two tasks, previous studies make efforts on modeling them with multi-task learning or designing feature interaction modules to improve the performance of each task. However, none of the existing approaches consider the relevance between the structural information of sentences and the label semantics of two tasks. The intent and semantic components of a utterance are dependent on the syntactic elements of a sentence. In this paper, we investigate a multi-grained label refinement network, which utilizes dependency structures and label semantic embeddings. Considering to enhance syntactic representations, we introduce the dependency structures of sentences into our model by graph attention layer. To capture the semantic dependency between the syntactic information and task labels, we combine the task specific features with corresponding label embeddings by attention mechanism. The experimental results demonstrate that our model achieves the competitive performance on two public datasets.
Leveraging Language Foundation Models for Human Mobility Forecasting
Sep 14, 2022



In this paper, we propose a novel pipeline that leverages language foundation models for temporal sequential pattern mining, such as for human mobility forecasting tasks. For example, in the task of predicting Place-of-Interest (POI) customer flows, typically the number of visits is extracted from historical logs, and only the numerical data are used to predict visitor flows. In this research, we perform the forecasting task directly on the natural language input that includes all kinds of information such as numerical values and contextual semantic information. Specific prompts are introduced to transform numerical temporal sequences into sentences so that existing language models can be directly applied. We design an AuxMobLCast pipeline for predicting the number of visitors in each POI, integrating an auxiliary POI category classification task with the encoder-decoder architecture. This research provides empirical evidence of the effectiveness of the proposed AuxMobLCast pipeline to discover sequential patterns in mobility forecasting tasks. The results, evaluated on three real-world datasets, demonstrate that pre-trained language foundation models also have good performance in forecasting temporal sequences. This study could provide visionary insights and lead to new research directions for predicting human mobility.
Instance As Identity: A Generic Online Paradigm for Video Instance Segmentation
Aug 16, 2022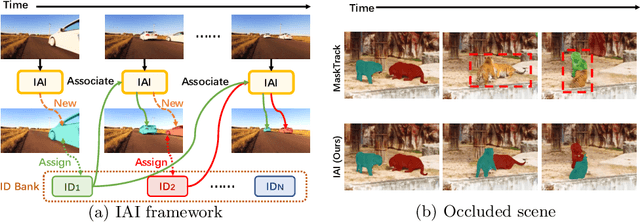
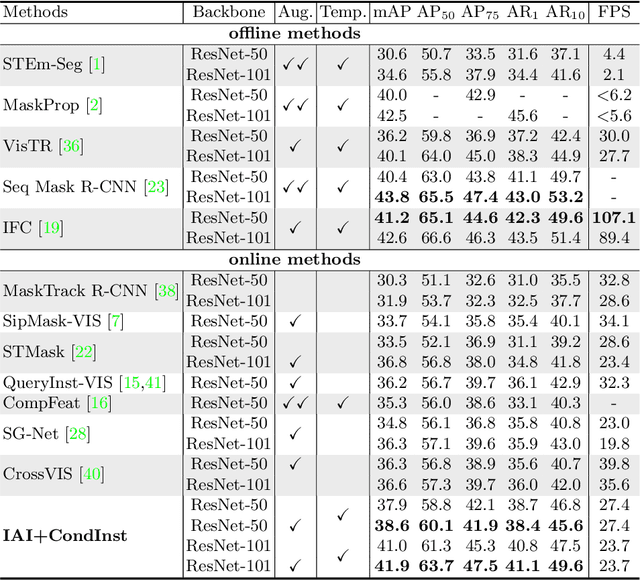
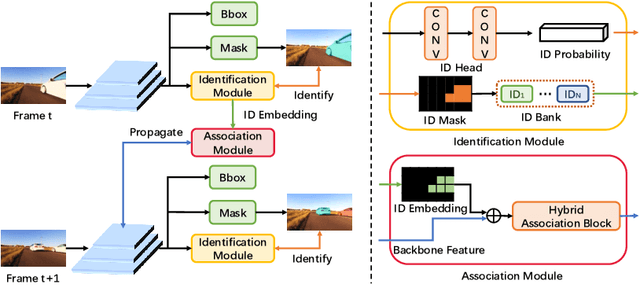
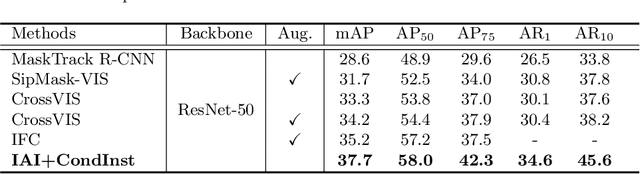
Modeling temporal information for both detection and tracking in a unified framework has been proved a promising solution to video instance segmentation (VIS). However, how to effectively incorporate the temporal information into an online model remains an open problem. In this work, we propose a new online VIS paradigm named Instance As Identity (IAI), which models temporal information for both detection and tracking in an efficient way. In detail, IAI employs a novel identification module to predict identification number for tracking instances explicitly. For passing temporal information cross frame, IAI utilizes an association module which combines current features and past embeddings. Notably, IAI can be integrated with different image models. We conduct extensive experiments on three VIS benchmarks. IAI outperforms all the online competitors on YouTube-VIS-2019 (ResNet-101 43.7 mAP) and YouTube-VIS-2021 (ResNet-50 38.0 mAP). Surprisingly, on the more challenging OVIS, IAI achieves SOTA performance (20.6 mAP). Code is available at https://github.com/zfonemore/IAI