 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Cyclical Self-Supervision for Semi-Supervised Ejection Fraction Prediction from Echocardiogram Videos
Oct 20, 2022
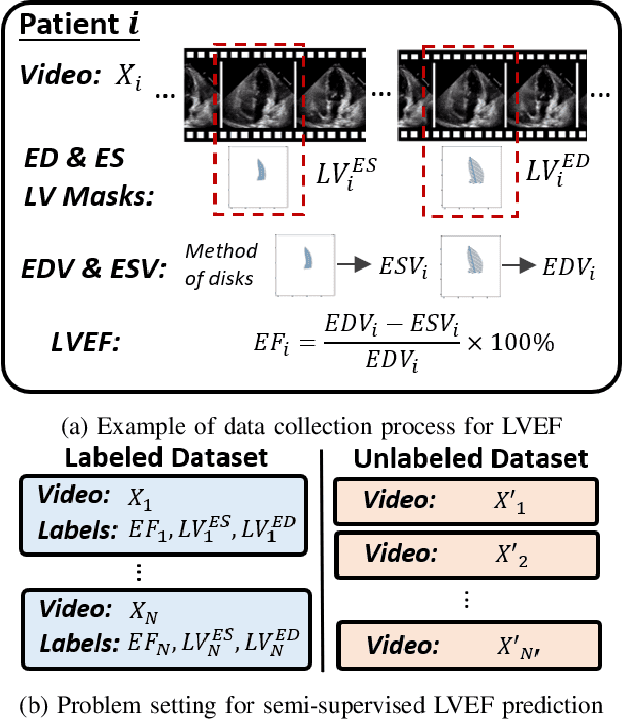
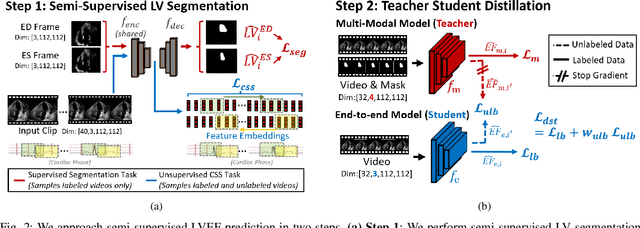
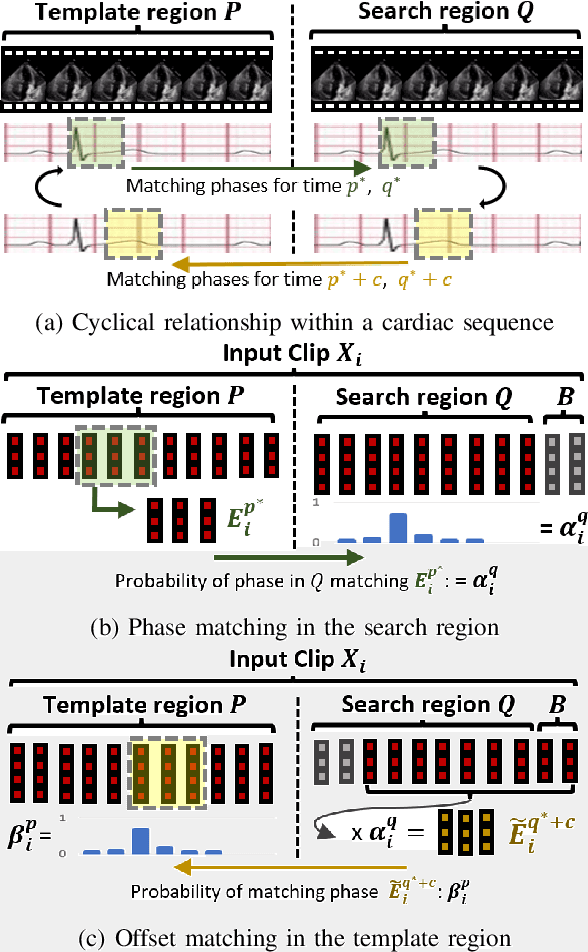
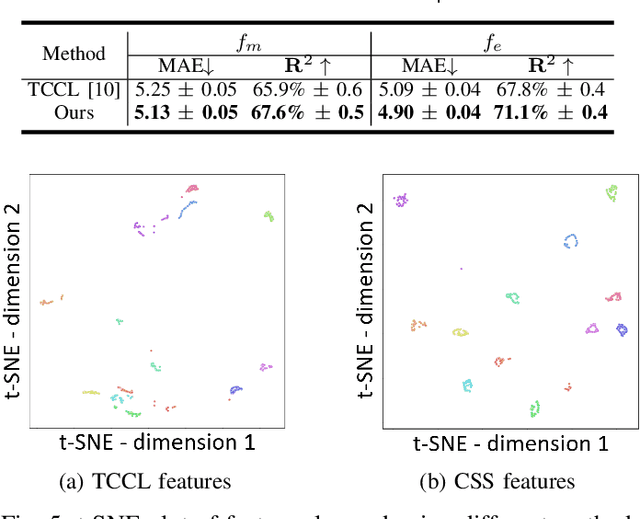
Left-ventricular ejection fraction (LVEF) is an important indicator of heart failure. Existing methods for LVEF estimation from video require large amounts of annotated data to achieve high performance, e.g. using 10,030 labeled echocardiogram videos to achieve mean absolute error (MAE) of 4.10. Labeling these videos is time-consuming however and limits potential downstream applications to other heart diseases. This paper presents the first semi-supervised approach for LVEF prediction. Unlike general video prediction tasks, LVEF prediction is specifically related to changes in the left ventricle (LV) in echocardiogram videos. By incorporating knowledge learned from predicting LV segmentations into LVEF regression, we can provide additional context to the model for better predictions. To this end, we propose a novel Cyclical Self-Supervision (CSS) method for learning video-based LV segmentation, which is motivated by the observation that the heartbeat is a cyclical process with temporal repetition. Prediction masks from our segmentation model can then be used as additional input for LVEF regression to provide spatial context for the LV region. We also introduce teacher-student distillation to distill the information from LV segmentation masks into an end-to-end LVEF regression model that only requires video inputs. Results show our method outperforms alternative semi-supervised methods and can achieve MAE of 4.17, which is competitive with state-of-the-art supervised performance, using half the number of labels. Validation on an external dataset also shows improved generalization ability from using our method.
Conditional probing: measuring usable information beyond a baseline
Sep 19, 2021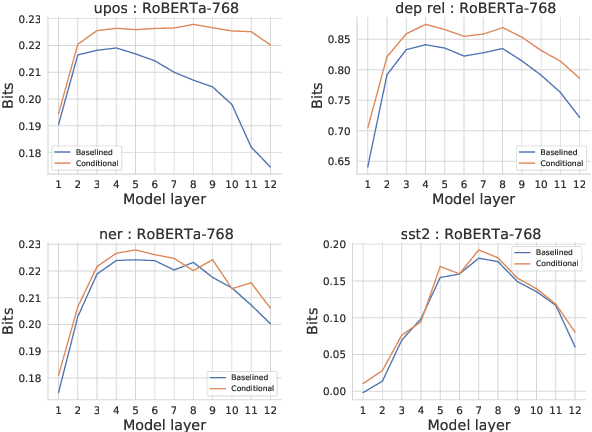
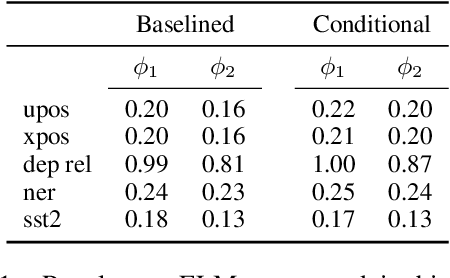
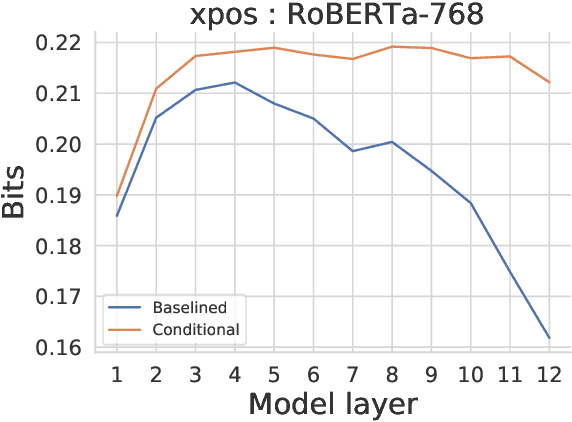
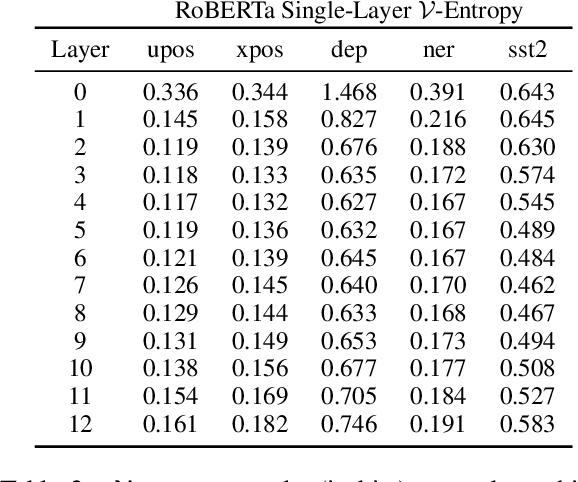
Probing experiments investigate the extent to which neural representations make properties -- like part-of-speech -- predictable. One suggests that a representation encodes a property if probing that representation produces higher accuracy than probing a baseline representation like non-contextual word embeddings. Instead of using baselines as a point of comparison, we're interested in measuring information that is contained in the representation but not in the baseline. For example, current methods can detect when a representation is more useful than the word identity (a baseline) for predicting part-of-speech; however, they cannot detect when the representation is predictive of just the aspects of part-of-speech not explainable by the word identity. In this work, we extend a theory of usable information called $\mathcal{V}$-information and propose conditional probing, which explicitly conditions on the information in the baseline. In a case study, we find that after conditioning on non-contextual word embeddings, properties like part-of-speech are accessible at deeper layers of a network than previously thought.
OOD-Probe: A Neural Interpretation of Out-of-Domain Generalization
Aug 25, 2022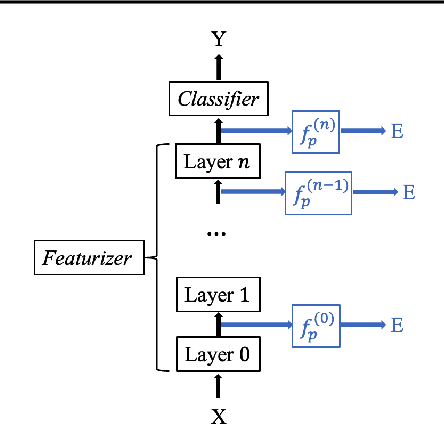
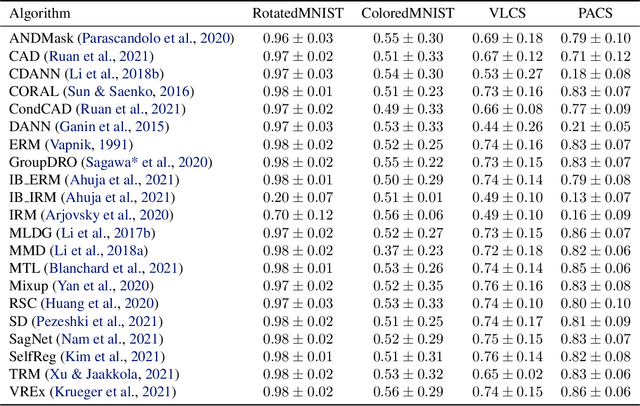

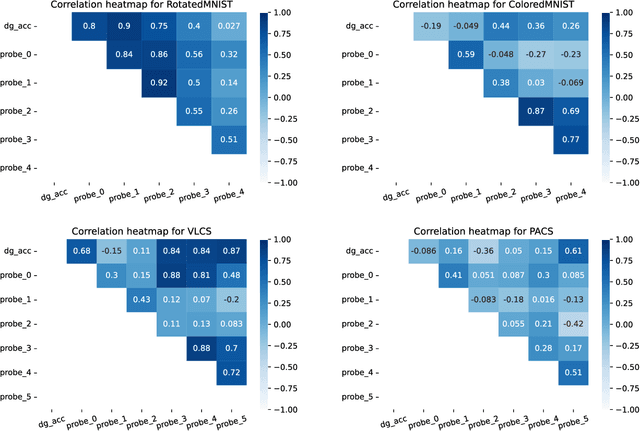
The ability to generalize out-of-domain (OOD) is an important goal for deep neural network development, and researchers have proposed many high-performing OOD generalization methods from various foundations. While many OOD algorithms perform well in various scenarios, these systems are evaluated as ``black-boxes''. Instead, we propose a flexible framework that evaluates OOD systems with finer granularity using a probing module that predicts the originating domain from intermediate representations. We find that representations always encode some information about the domain. While the layerwise encoding patterns remain largely stable across different OOD algorithms, they vary across the datasets. For example, the information about rotation (on RotatedMNIST) is the most visible on the lower layers, while the information about style (on VLCS and PACS) is the most visible on the middle layers. In addition, the high probing results correlate to the domain generalization performances, leading to further directions in developing OOD generalization systems.
Over-the-Air Gaussian Process Regression Based on Product of Experts
Oct 06, 2022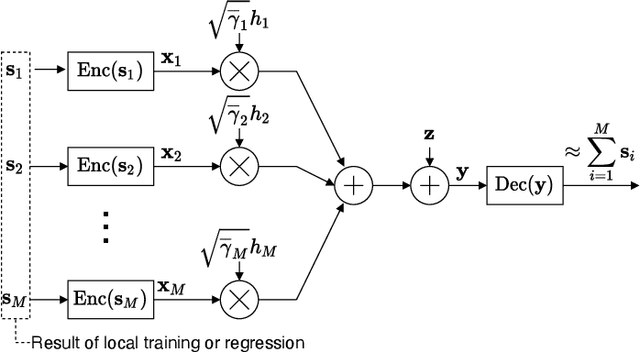
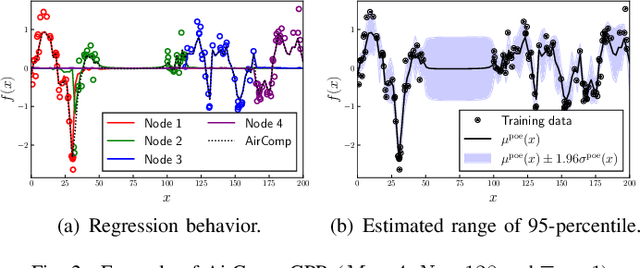
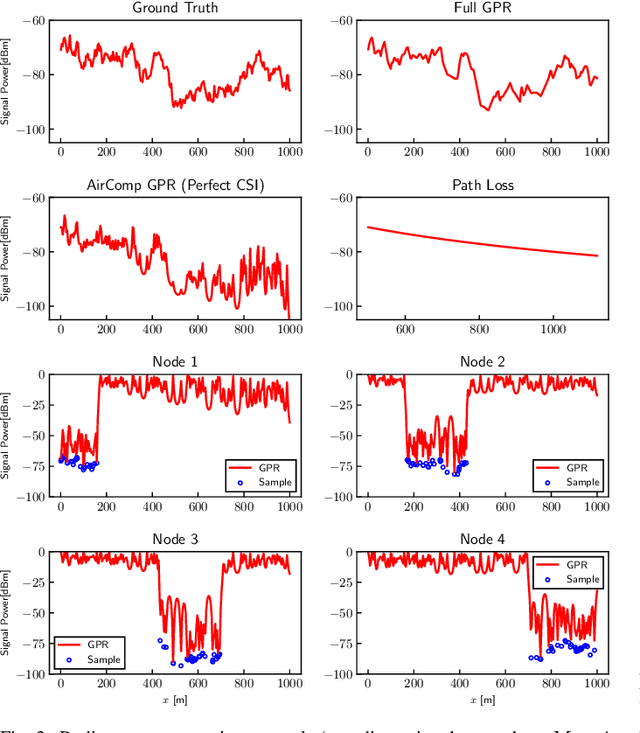
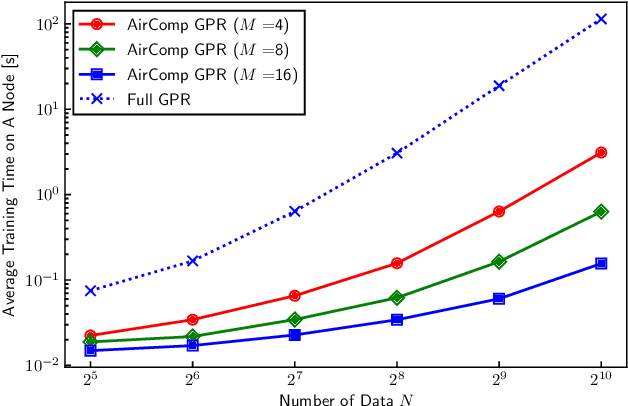
This paper proposes a distributed Gaussian process regression (GPR) with over-the-air computation, termed AirComp GPR, for communication- and computation-efficient data analysis over wireless networks. GPR is a non-parametric regression method that can model the target flexibly. However, its computational complexity and communication efficiency tend to be significant as the number of data increases. AirComp GPR focuses on that product-of-experts-based GPR approximates the exact GPR by a sum of values reported from distributed nodes. We introduce AirComp for the training and prediction steps to allow the nodes to transmit their local computation results simultaneously; the communication strategies are presented, including distributed training based on perfect and statistical channel state information cases. Applying to a radio map construction task, we demonstrate that AirComp GPR speeds up the computation time while maintaining the communication cost in training constant regardless of the numbers of data and nodes.
Grouped self-attention mechanism for a memory-efficient Transformer
Oct 06, 2022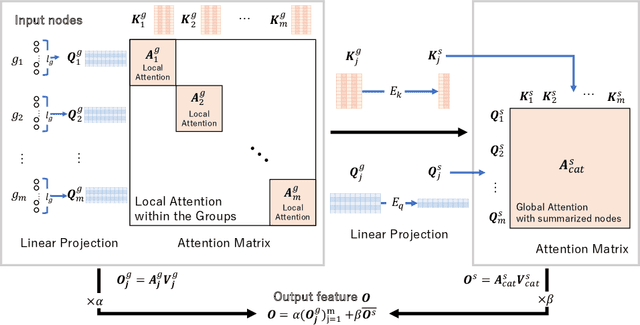
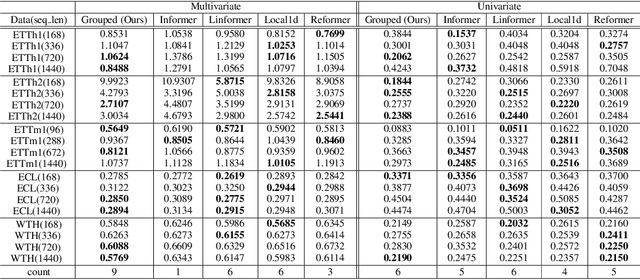
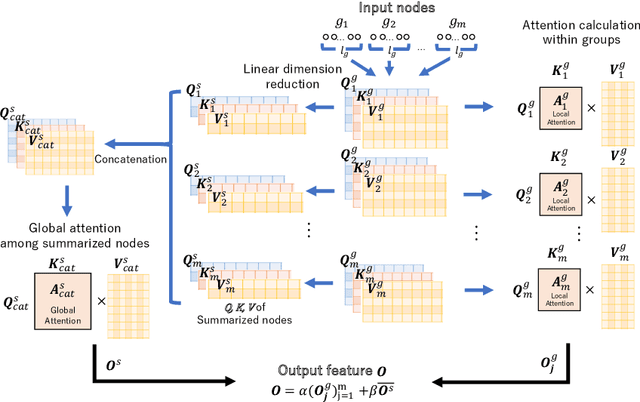
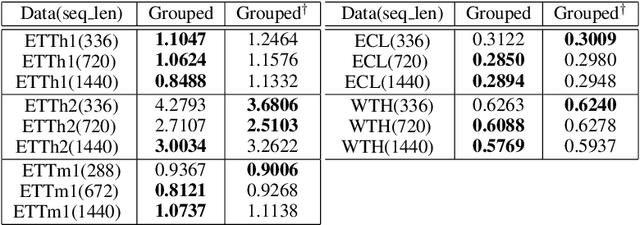
Time-series data analysis is important because numerous real-world tasks such as forecasting weather, electricity consumption, and stock market involve predicting data that vary over time. Time-series data are generally recorded over a long period of observation with long sequences owing to their periodic characteristics and long-range dependencies over time. Thus, capturing long-range dependency is an important factor in time-series data forecasting. To solve these problems, we proposed two novel modules, Grouped Self-Attention (GSA) and Compressed Cross-Attention (CCA). With both modules, we achieved a computational space and time complexity of order $O(l)$ with a sequence length $l$ under small hyperparameter limitations, and can capture locality while considering global information. The results of experiments conducted on time-series datasets show that our proposed model efficiently exhibited reduced computational complexity and performance comparable to or better than existing methods.
Probabilistic Model Incorporating Auxiliary Covariates to Control FDR
Oct 06, 2022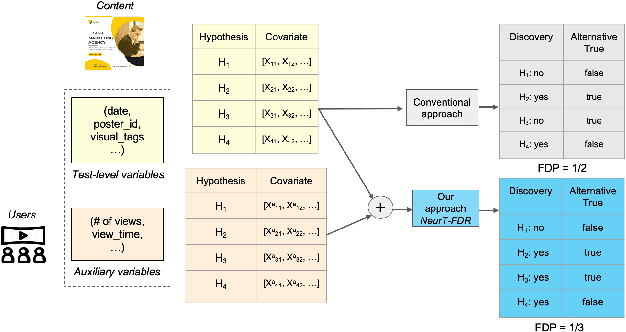
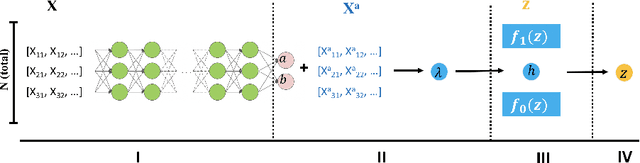
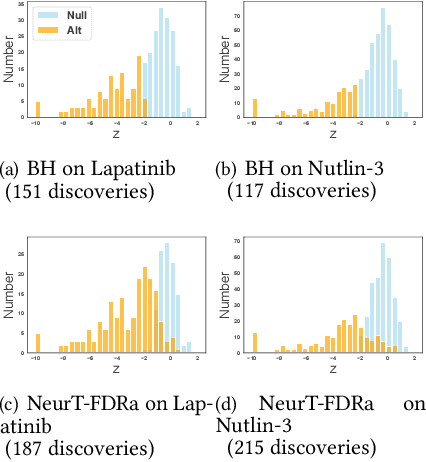
Controlling False Discovery Rate (FDR) while leveraging the side information of multiple hypothesis testing is an emerging research topic in modern data science. Existing methods rely on the test-level covariates while ignoring metrics about test-level covariates. This strategy may not be optimal for complex large-scale problems, where indirect relations often exist among test-level covariates and auxiliary metrics or covariates. We incorporate auxiliary covariates among test-level covariates in a deep Black-Box framework controlling FDR (named as NeurT-FDR) which boosts statistical power and controls FDR for multiple-hypothesis testing. Our method parametrizes the test-level covariates as a neural network and adjusts the auxiliary covariates through a regression framework, which enables flexible handling of high-dimensional features as well as efficient end-to-end optimization. We show that NeurT-FDR makes substantially more discoveries in three real datasets compared to competitive baselines.
WakeUpNet: A Mobile-Transformer based Framework for End-to-End Streaming Voice Trigger
Oct 06, 2022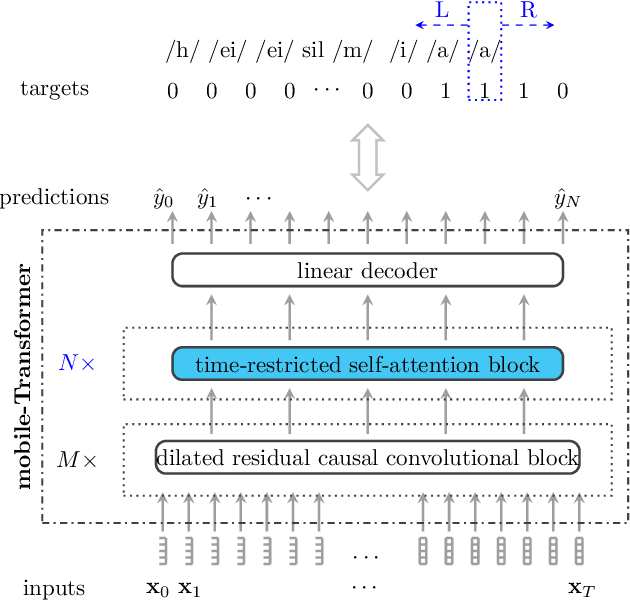
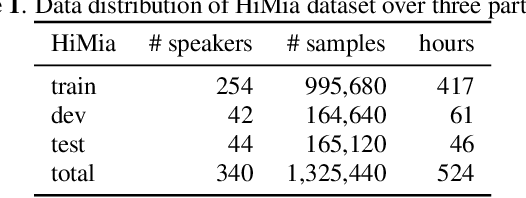
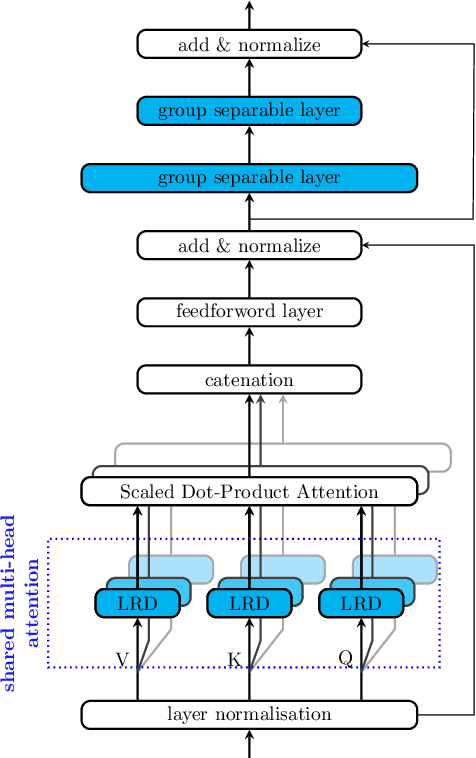
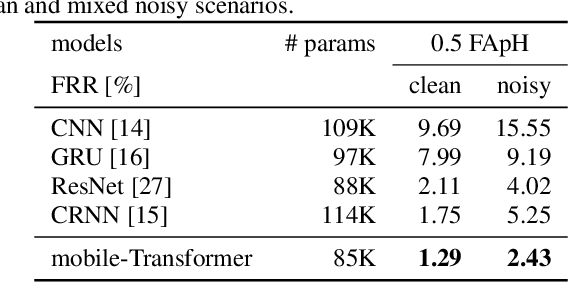
End-to-end models have gradually become the main technical stream for voice trigger, aiming to achieve an utmost prediction accuracy but with a small footprint. In present paper, we propose an end-to-end voice trigger framework, namely WakeupNet, which is basically structured on a Transformer encoder. The purpose of this framework is to explore the context-capturing capability of Transformer, as sequential information is vital for wakeup-word detection. However, the conventional Transformer encoder is too large to fit our task. To address this issue, we introduce different model compression approaches to shrink the vanilla one into a tiny one, called mobile-Transformer. To evaluate the performance of mobile-Transformer, we conduct extensive experiments on a large public-available dataset HiMia. The obtained results indicate that introduced mobile-Transformer significantly outperforms other frequently used models for voice trigger in both clean and noisy scenarios.
Automated Urban Planning aware Spatial Hierarchies and Human Instructions
Sep 26, 2022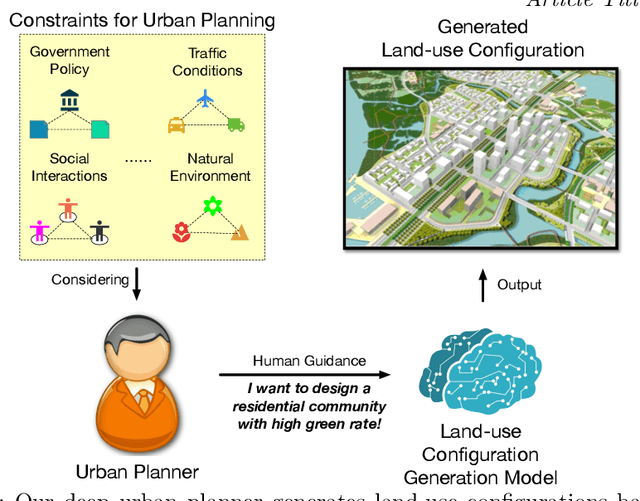
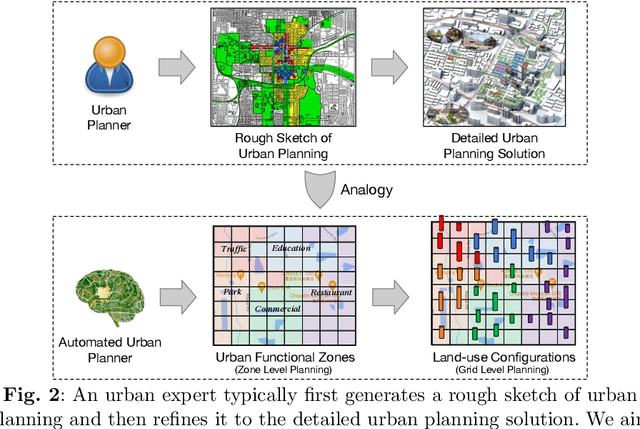
Traditional urban planning demands urban experts to spend considerable time and effort producing an optimal urban plan under many architectural constraints. The remarkable imaginative ability of deep generative learning provides hope for renovating urban planning. While automated urban planners have been examined, they are constrained because of the following: 1) neglecting human requirements in urban planning; 2) omitting spatial hierarchies in urban planning, and 3) lacking numerous urban plan data samples. To overcome these limitations, we propose a novel, deep, human-instructed urban planner. In the preliminary work, we formulate it into an encoder-decoder paradigm. The encoder is to learn the information distribution of surrounding contexts, human instructions, and land-use configuration. The decoder is to reconstruct the land-use configuration and the associated urban functional zones. The reconstruction procedure will capture the spatial hierarchies between functional zones and spatial grids. Meanwhile, we introduce a variational Gaussian mechanism to mitigate the data sparsity issue. Even though early work has led to good results, the performance of generation is still unstable because the way spatial hierarchies are captured may lead to unclear optimization directions. In this journal version, we propose a cascading deep generative framework based on generative adversarial networks (GANs) to solve this problem, inspired by the workflow of urban experts. In particular, the purpose of the first GAN is to build urban functional zones based on information from human instructions and surrounding contexts. The second GAN will produce the land-use configuration based on the functional zones that have been constructed. Additionally, we provide a conditioning augmentation module to augment data samples. Finally, we conduct extensive experiments to validate the efficacy of our work.
HeteroQA: Learning towards Question-and-Answering through Multiple Information Sources via Heterogeneous Graph Modeling
Dec 27, 2021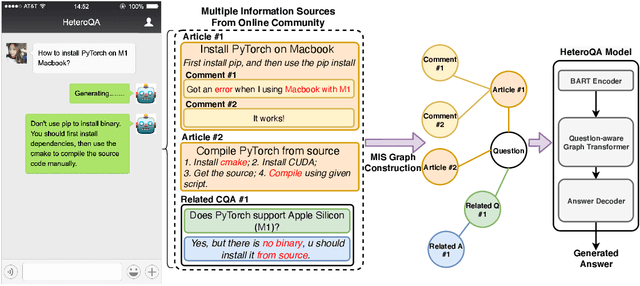

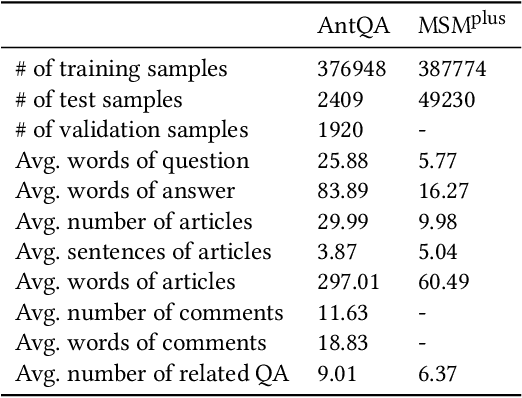
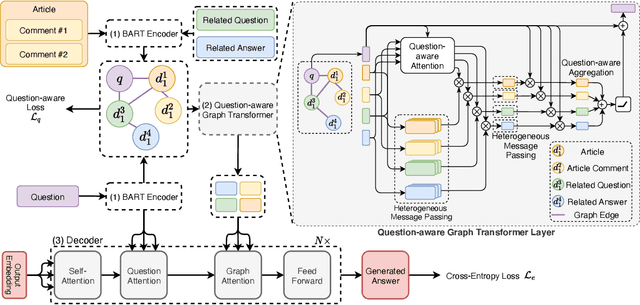
Community Question Answering (CQA) is a well-defined task that can be used in many scenarios, such as E-Commerce and online user community for special interests. In these communities, users can post articles, give comment, raise a question and answer it. These data form the heterogeneous information sources where each information source have their own special structure and context (comments attached to an article or related question with answers). Most of the CQA methods only incorporate articles or Wikipedia to extract knowledge and answer the user's question. However, various types of information sources in the community are not fully explored by these CQA methods and these multiple information sources (MIS) can provide more related knowledge to user's questions. Thus, we propose a question-aware heterogeneous graph transformer to incorporate the MIS in the user community to automatically generate the answer. To evaluate our proposed method, we conduct the experiments on two datasets: $\text{MSM}^{\text{plus}}$ the modified version of benchmark dataset MS-MARCO and the AntQA dataset which is the first large-scale CQA dataset with four types of MIS. Extensive experiments on two datasets show that our model outperforms all the baselines in terms of all the metrics.
TiDAL: Learning Training Dynamics for Active Learning
Oct 13, 2022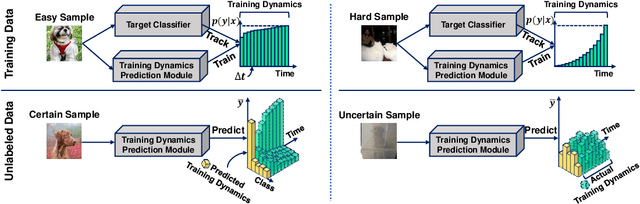
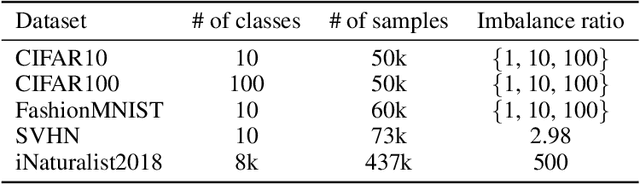
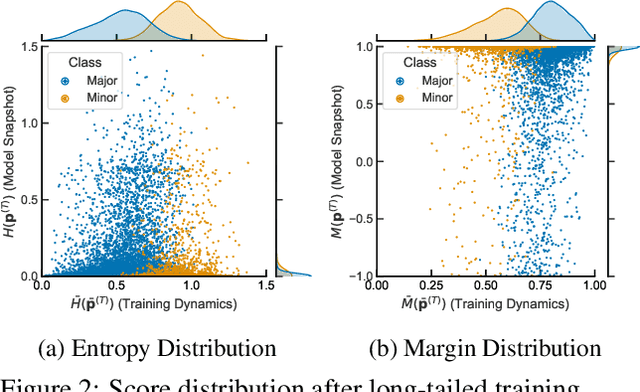
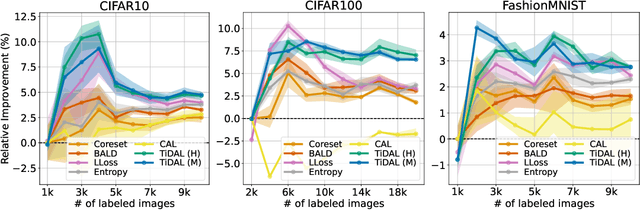
Active learning (AL) aims to select the most useful data samples from an unlabeled data pool and annotate them to expand the labeled dataset under a limited budget. Especially, uncertainty-based methods choose the most uncertain samples, which are known to be effective in improving model performance. However, AL literature often overlooks training dynamics (TD), defined as the ever-changing model behavior during optimization via stochastic gradient descent, even though other areas of literature have empirically shown that TD provides important clues for measuring the sample uncertainty. In this paper, we propose a novel AL method, Training Dynamics for Active Learning (TiDAL), which leverages the TD to quantify uncertainties of unlabeled data. Since tracking the TD of all the large-scale unlabeled data is impractical, TiDAL utilizes an additional prediction module that learns the TD of labeled data. To further justify the design of TiDAL, we provide theoretical and empirical evidence to argue the usefulness of leveraging TD for AL. Experimental results show that our TiDAL achieves better or comparable performance on both balanced and imbalanced benchmark datasets compared to state-of-the-art AL methods, which estimate data uncertainty using only static information after model training.