 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GraphTranslator: Aligning Graph Model to Large Language Model for Open-ended Tasks
Feb 28, 2024
Large language models (LLMs) like ChatGPT, exhibit powerful zero-shot and instruction-following capabilities, have catalyzed a revolutionary transformation across diverse fields, especially for open-ended tasks. While the idea is less explored in the graph domain, despite the availability of numerous powerful graph models (GMs), they are restricted to tasks in a pre-defined form. Although several methods applying LLMs to graphs have been proposed, they fail to simultaneously handle the pre-defined and open-ended tasks, with LLM as a node feature enhancer or as a standalone predictor. To break this dilemma, we propose to bridge the pretrained GM and LLM by a Translator, named GraphTranslator, aiming to leverage GM to handle the pre-defined tasks effectively and utilize the extended interface of LLMs to offer various open-ended tasks for GM. To train such Translator, we propose a Producer capable of constructing the graph-text alignment data along node information, neighbor information and model information. By translating node representation into tokens, GraphTranslator empowers an LLM to make predictions based on language instructions, providing a unified perspective for both pre-defined and open-ended tasks. Extensive results demonstrate the effectiveness of our proposed GraphTranslator on zero-shot node classification. The graph question answering experiments reveal our GraphTranslator potential across a broad spectrum of open-ended tasks through language instructions. Our code is available at: https://github.com/alibaba/GraphTranslator.
Towards Tracing Trustworthiness Dynamics: Revisiting Pre-training Period of Large Language Models
Feb 29, 2024Ensuring the trustworthiness of large language models (LLMs) is crucial. Most studies concentrate on fully pre-trained LLMs to better understand and improve LLMs' trustworthiness. In this paper, to reveal the untapped potential of pre-training, we pioneer the exploration of LLMs' trustworthiness during this period, focusing on five key dimensions: reliability, privacy, toxicity, fairness, and robustness. To begin with, we apply linear probing to LLMs. The high probing accuracy suggests that \textit{LLMs in early pre-training can already distinguish concepts in each trustworthiness dimension}. Therefore, to further uncover the hidden possibilities of pre-training, we extract steering vectors from a LLM's pre-training checkpoints to enhance the LLM's trustworthiness. Finally, inspired by~\citet{choi2023understanding} that mutual information estimation is bounded by linear probing accuracy, we also probe LLMs with mutual information to investigate the dynamics of trustworthiness during pre-training. We are the first to observe a similar two-phase phenomenon: fitting and compression~\citep{shwartz2017opening}. This research provides an initial exploration of trustworthiness modeling during LLM pre-training, seeking to unveil new insights and spur further developments in the field. We will make our code publicly accessible at \url{https://github.com/ChnQ/TracingLLM}.
Weakly Supervised Monocular 3D Detection with a Single-View Image
Feb 29, 2024Monocular 3D detection (M3D) aims for precise 3D object localization from a single-view image which usually involves labor-intensive annotation of 3D detection boxes. Weakly supervised M3D has recently been studied to obviate the 3D annotation process by leveraging many existing 2D annotations, but it often requires extra training data such as LiDAR point clouds or multi-view images which greatly degrades its applicability and usability in various applications. We propose SKD-WM3D, a weakly supervised monocular 3D detection framework that exploits depth information to achieve M3D with a single-view image exclusively without any 3D annotations or other training data. One key design in SKD-WM3D is a self-knowledge distillation framework, which transforms image features into 3D-like representations by fusing depth information and effectively mitigates the inherent depth ambiguity in monocular scenarios with little computational overhead in inference. In addition, we design an uncertainty-aware distillation loss and a gradient-targeted transfer modulation strategy which facilitate knowledge acquisition and knowledge transfer, respectively. Extensive experiments show that SKD-WM3D surpasses the state-of-the-art clearly and is even on par with many fully supervised methods.
Leveraging Representations from Intermediate Encoder-blocks for Synthetic Image Detection
Feb 29, 2024The recently developed and publicly available synthetic image generation methods and services make it possible to create extremely realistic imagery on demand, raising great risks for the integrity and safety of online information. State-of-the-art Synthetic Image Detection (SID) research has led to strong evidence on the advantages of feature extraction from foundation models. However, such extracted features mostly encapsulate high-level visual semantics instead of fine-grained details, which are more important for the SID task. On the contrary, shallow layers encode low-level visual information. In this work, we leverage the image representations extracted by intermediate Transformer blocks of CLIP's image-encoder via a lightweight network that maps them to a learnable forgery-aware vector space capable of generalizing exceptionally well. We also employ a trainable module to incorporate the importance of each Transformer block to the final prediction. Our method is compared against the state-of-the-art by evaluating it on 20 test datasets and exhibits an average +10.6% absolute performance improvement. Notably, the best performing models require just a single epoch for training (~8 minutes). Code available at https://github.com/mever-team/rine.
MIKO: Multimodal Intention Knowledge Distillation from Large Language Models for Social-Media Commonsense Discovery
Feb 29, 2024Social media has become a ubiquitous tool for connecting with others, staying updated with news, expressing opinions, and finding entertainment. However, understanding the intention behind social media posts remains challenging due to the implicitness of intentions in social media posts, the need for cross-modality understanding of both text and images, and the presence of noisy information such as hashtags, misspelled words, and complicated abbreviations. To address these challenges, we present MIKO, a Multimodal Intention Kowledge DistillatiOn framework that collaboratively leverages a Large Language Model (LLM) and a Multimodal Large Language Model (MLLM) to uncover users' intentions. Specifically, we use an MLLM to interpret the image and an LLM to extract key information from the text and finally instruct the LLM again to generate intentions. By applying MIKO to publicly available social media datasets, we construct an intention knowledge base featuring 1,372K intentions rooted in 137,287 posts. We conduct a two-stage annotation to verify the quality of the generated knowledge and benchmark the performance of widely used LLMs for intention generation. We further apply MIKO to a sarcasm detection dataset and distill a student model to demonstrate the downstream benefits of applying intention knowledge.
PE-MVCNet: Multi-view and Cross-modal Fusion Network for Pulmonary Embolism Prediction
Feb 29, 2024The early detection of a pulmonary embolism (PE) is critical for enhancing patient survival rates. Both image-based and non-image-based features are of utmost importance in medical classification tasks. In a clinical setting, physicians tend to rely on the contextual information provided by Electronic Medical Records (EMR) to interpret medical imaging. However, very few models effectively integrate clinical information with imaging data. To address this shortcoming, we suggest a multimodal fusion methodology, termed PE-MVCNet, which capitalizes on Computed Tomography Pulmonary Angiography imaging and EMR data. This method comprises the Image-only module with an integrated multi-view block, the EMR-only module, and the Cross-modal Attention Fusion (CMAF) module. These modules cooperate to extract comprehensive features that subsequently generate predictions for PE. We conducted experiments using the publicly accessible Stanford University Medical Center dataset, achieving an AUROC of 94.1%, an accuracy rate of 90.2%, and an F1 score of 90.6%. Our proposed model outperforms existing methodologies, corroborating that our multimodal fusion model excels compared to models that use a single data modality. Our source code is available at https://github.com/LeavingStarW/PE-MVCNET.
Information That Matters: Exploring Information Needs of People Affected by Algorithmic Decisions
Jan 29, 2024Explanations of AI systems rarely address the information needs of people affected by algorithmic decision-making (ADM). This gap between conveyed information and information that matters to affected stakeholders can impede understanding and adherence to regulatory frameworks such as the AI Act. To address this gap, we present the "XAI Novice Question Bank": A catalog of affected stakeholders' information needs in two ADM use cases (employment prediction and health monitoring), covering the categories data, system context, system usage, and system specifications. Information needs were gathered in an interview study where participants received explanations in response to their inquiries. Participants further reported their understanding and decision confidence, showing that while confidence tended to increase after receiving explanations, participants also met understanding challenges, such as being unable to tell why their understanding felt incomplete. Explanations further influenced participants' perceptions of the systems' risks and benefits, which they confirmed or changed depending on the use case. When risks were perceived as high, participants expressed particular interest in explanations about intention, such as why and to what end a system was put in place. With this work, we aim to support the inclusion of affected stakeholders into explainability by contributing an overview of information and challenges relevant to them when deciding on the adoption of ADM systems. We close by summarizing our findings in a list of six key implications that inform the design of future explanations for affected stakeholder audiences.
Reading Relevant Feature from Global Representation Memory for Visual Object Tracking
Feb 26, 2024Reference features from a template or historical frames are crucial for visual object tracking. Prior works utilize all features from a fixed template or memory for visual object tracking. However, due to the dynamic nature of videos, the required reference historical information for different search regions at different time steps is also inconsistent. Therefore, using all features in the template and memory can lead to redundancy and impair tracking performance. To alleviate this issue, we propose a novel tracking paradigm, consisting of a relevance attention mechanism and a global representation memory, which can adaptively assist the search region in selecting the most relevant historical information from reference features. Specifically, the proposed relevance attention mechanism in this work differs from previous approaches in that it can dynamically choose and build the optimal global representation memory for the current frame by accessing cross-frame information globally. Moreover, it can flexibly read the relevant historical information from the constructed memory to reduce redundancy and counteract the negative effects of harmful information. Extensive experiments validate the effectiveness of the proposed method, achieving competitive performance on five challenging datasets with 71 FPS.
A Survey of AI-generated Text Forensic Systems: Detection, Attribution, and Characterization
Mar 02, 2024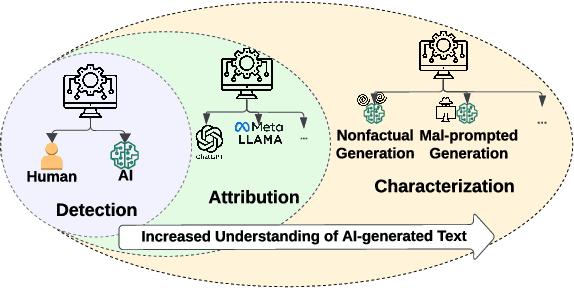
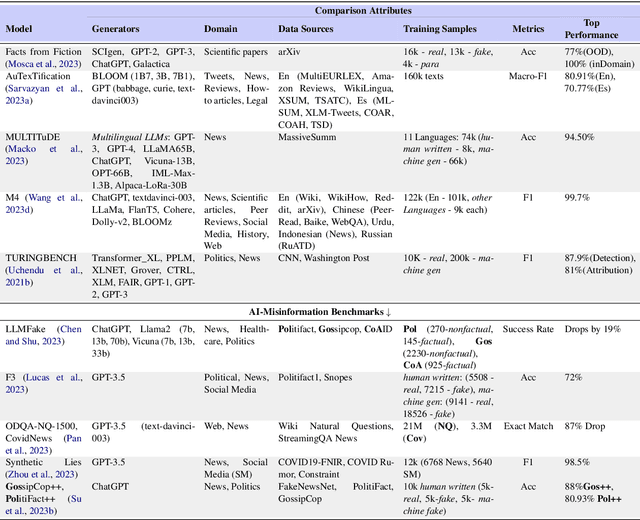
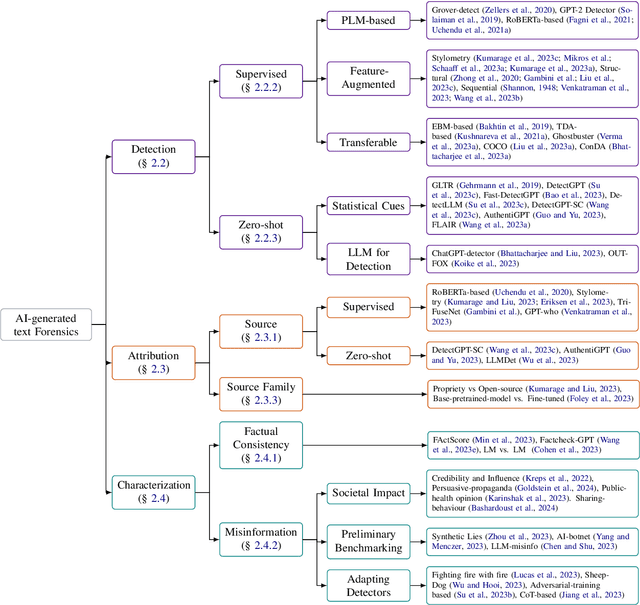
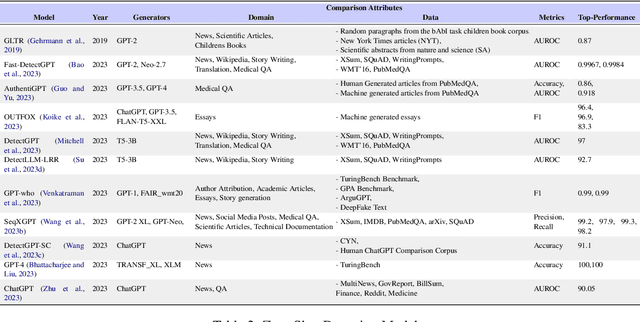
We have witnessed lately a rapid proliferation of advanced Large Language Models (LLMs) capable of generating high-quality text. While these LLMs have revolutionized text generation across various domains, they also pose significant risks to the information ecosystem, such as the potential for generating convincing propaganda, misinformation, and disinformation at scale. This paper offers a review of AI-generated text forensic systems, an emerging field addressing the challenges of LLM misuses. We present an overview of the existing efforts in AI-generated text forensics by introducing a detailed taxonomy, focusing on three primary pillars: detection, attribution, and characterization. These pillars enable a practical understanding of AI-generated text, from identifying AI-generated content (detection), determining the specific AI model involved (attribution), and grouping the underlying intents of the text (characterization). Furthermore, we explore available resources for AI-generated text forensics research and discuss the evolving challenges and future directions of forensic systems in an AI era.
A Hybrid Model for Traffic Incident Detection based on Generative Adversarial Networks and Transformer Model
Mar 02, 2024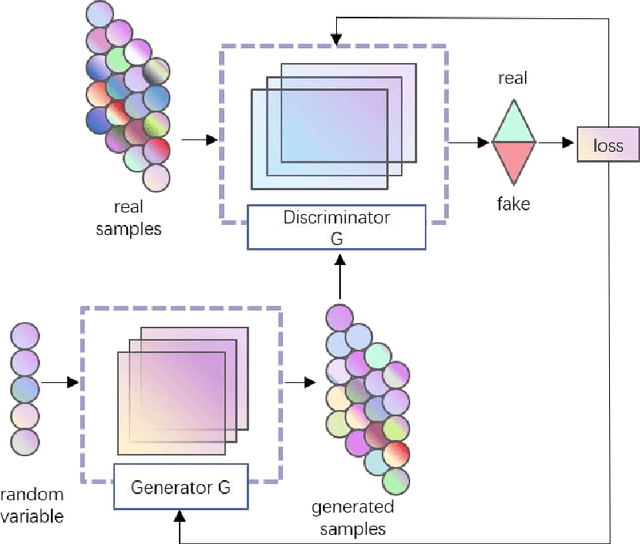

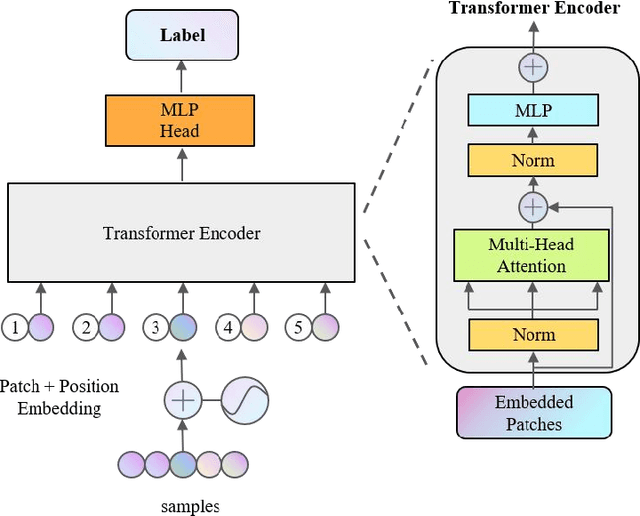
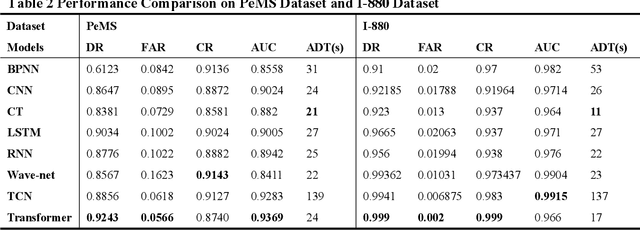
In addition to enhancing traffic safety and facilitating prompt emergency response, traffic incident detection plays an indispensable role in intelligent transportation systems by providing real-time traffic status information. This enables the realization of intelligent traffic control and management. Previous research has identified that apart from employing advanced algorithmic models, the effectiveness of detection is also significantly influenced by challenges related to acquiring large datasets and addressing dataset imbalances. A hybrid model combining transformer and generative adversarial networks (GANs) is proposed to address these challenges. Experiments are conducted on four real datasets to validate the superiority of the transformer in traffic incident detection. Additionally, GANs are utilized to expand the dataset and achieve a balanced ratio of 1:4, 2:3, and 1:1. The proposed model is evaluated against the baseline model. The results demonstrate that the proposed model enhances the dataset size, balances the dataset, and improves the performance of traffic incident detection in various aspects.