 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Privacy-Preserving Distributed Expectation Maximization for Gaussian Mixture Model using Subspace Perturbation
Sep 16, 2022
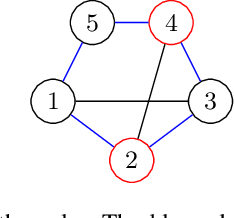
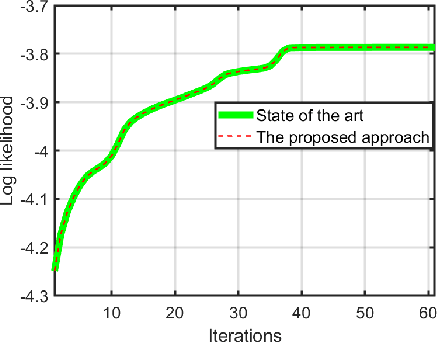
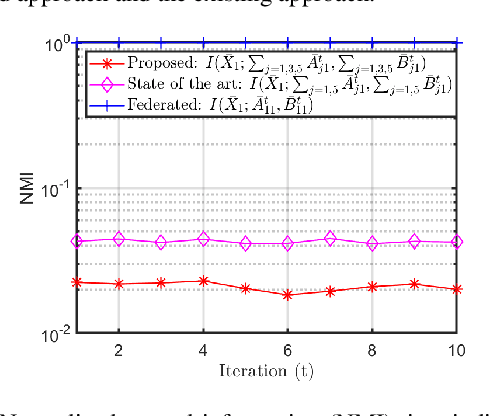
Privacy has become a major concern in machine learning. In fact, the federated learning is motivated by the privacy concern as it does not allow to transmit the private data but only intermediate updates. However, federated learning does not always guarantee privacy-preservation as the intermediate updates may also reveal sensitive information. In this paper, we give an explicit information-theoretical analysis of a federated expectation maximization algorithm for Gaussian mixture model and prove that the intermediate updates can cause severe privacy leakage. To address the privacy issue, we propose a fully decentralized privacy-preserving solution, which is able to securely compute the updates in each maximization step. Additionally, we consider two different types of security attacks: the honest-but-curious and eavesdropping adversary models. Numerical validation shows that the proposed approach has superior performance compared to the existing approach in terms of both the accuracy and privacy level.
CMGAN: Conformer-Based Metric-GAN for Monaural Speech Enhancement
Sep 23, 2022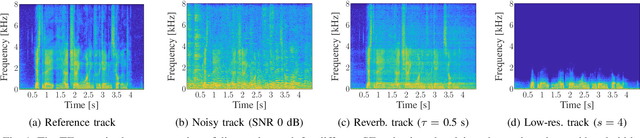
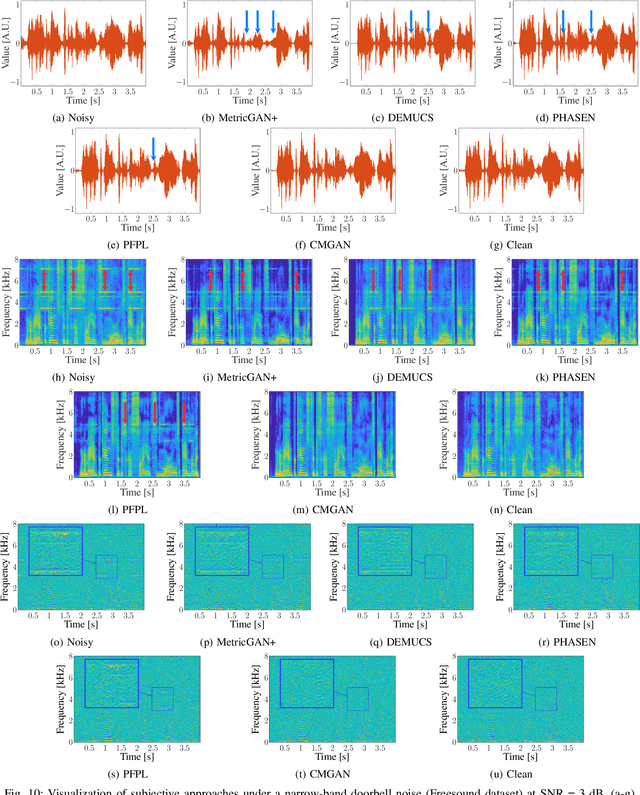
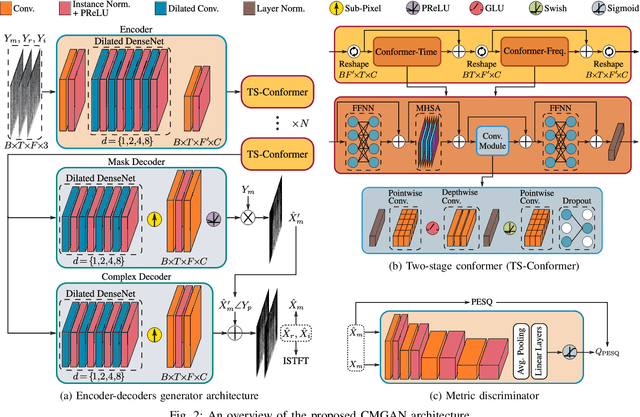
Convolution-augmented transformers (Conformers) are recently proposed in various speech-domain applications, such as automatic speech recognition (ASR) and speech separation, as they can capture both local and global dependencies. In this paper, we propose a conformer-based metric generative adversarial network (CMGAN) for speech enhancement (SE) in the time-frequency (TF) domain. The generator encodes the magnitude and complex spectrogram information using two-stage conformer blocks to model both time and frequency dependencies. The decoder then decouples the estimation into a magnitude mask decoder branch to filter out unwanted distortions and a complex refinement branch to further improve the magnitude estimation and implicitly enhance the phase information. Additionally, we include a metric discriminator to alleviate metric mismatch by optimizing the generator with respect to a corresponding evaluation score. Objective and subjective evaluations illustrate that CMGAN is able to show superior performance compared to state-of-the-art methods in three speech enhancement tasks (denoising, dereverberation and super-resolution). For instance, quantitative denoising analysis on Voice Bank+DEMAND dataset indicates that CMGAN outperforms various previous models with a margin, i.e., PESQ of 3.41 and SSNR of 11.10 dB.
Full Transformer Framework for Robust Point Cloud Registration with Deep Information Interaction
Dec 17, 2021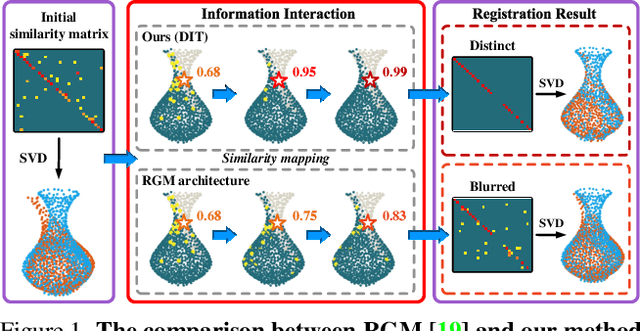
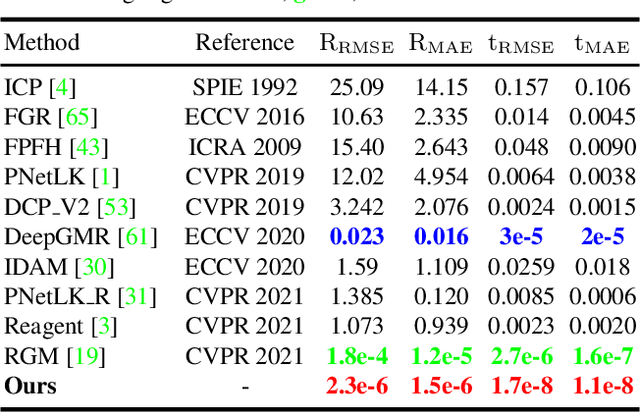
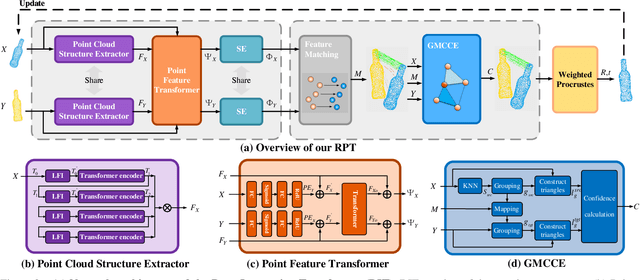
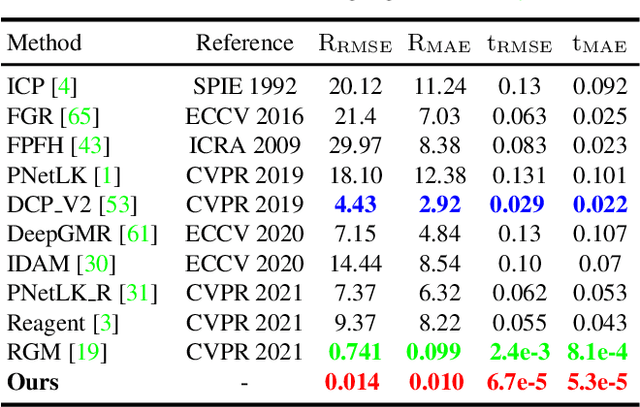
Recent Transformer-based methods have achieved advanced performance in point cloud registration by utilizing advantages of the Transformer in order-invariance and modeling dependency to aggregate information. However, they still suffer from indistinct feature extraction, sensitivity to noise, and outliers. The reasons are: (1) the adoption of CNNs fails to model global relations due to their local receptive fields, resulting in extracted features susceptible to noise; (2) the shallow-wide architecture of Transformers and lack of positional encoding lead to indistinct feature extraction due to inefficient information interaction; (3) the omission of geometrical compatibility leads to inaccurate classification between inliers and outliers. To address above limitations, a novel full Transformer network for point cloud registration is proposed, named the Deep Interaction Transformer (DIT), which incorporates: (1) a Point Cloud Structure Extractor (PSE) to model global relations and retrieve structural information with Transformer encoders; (2) a deep-narrow Point Feature Transformer (PFT) to facilitate deep information interaction across two point clouds with positional encoding, such that Transformers can establish comprehensive associations and directly learn relative position between points; (3) a Geometric Matching-based Correspondence Confidence Evaluation (GMCCE) method to measure spatial consistency and estimate inlier confidence by designing the triangulated descriptor. Extensive experiments on clean, noisy, partially overlapping point cloud registration demonstrate that our method outperforms state-of-the-art methods.
Certified machine learning: Rigorous a posteriori error bounds for PDE defined PINNs
Oct 07, 2022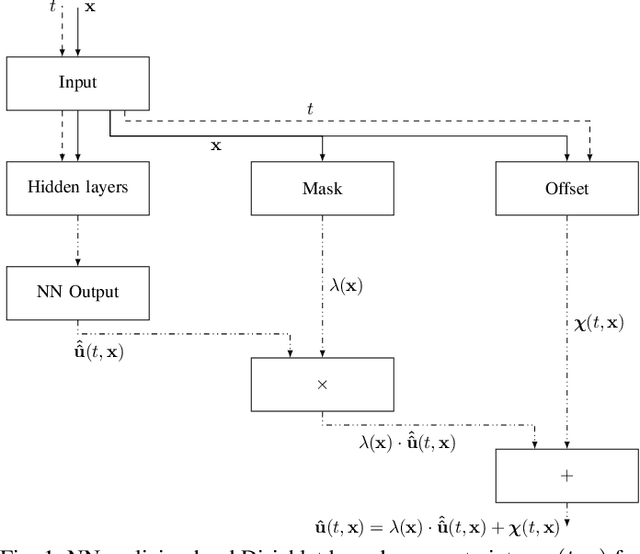
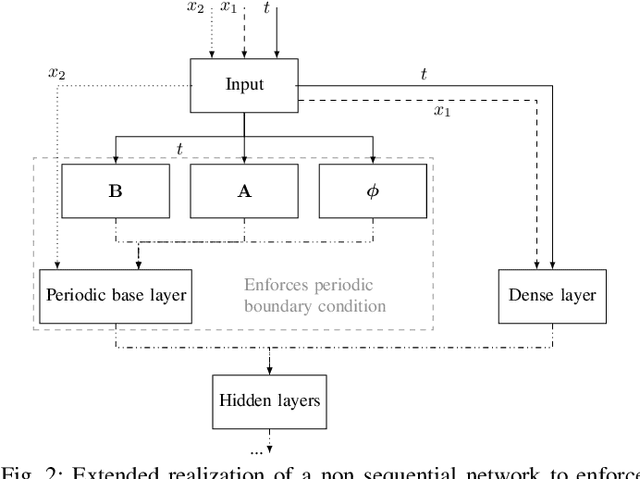
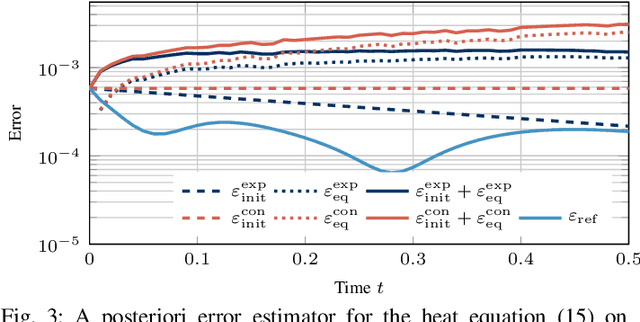
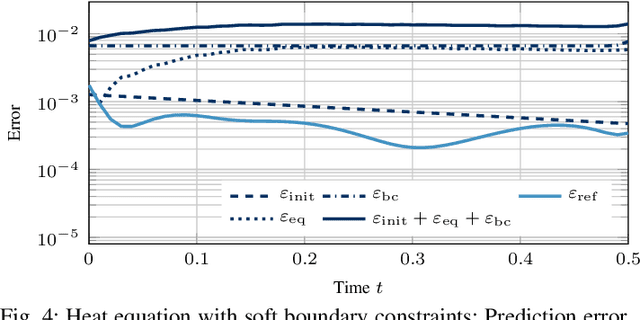
Prediction error quantification in machine learning has been left out of most methodological investigations of neural networks, for both purely data-driven and physics-informed approaches. Beyond statistical investigations and generic results on the approximation capabilities of neural networks, we present a rigorous upper bound on the prediction error of physics-informed neural networks. This bound can be calculated without the knowledge of the true solution and only with a priori available information about the characteristics of the underlying dynamical system governed by a partial differential equation. We apply this a posteriori error bound exemplarily to four problems: the transport equation, the heat equation, the Navier-Stokes equation and the Klein-Gordon equation.
Hierarchical MixUp Multi-label Classification with Imbalanced Interdisciplinary Research Proposals
Sep 28, 2022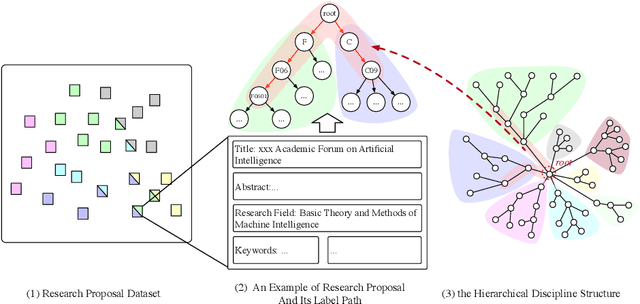
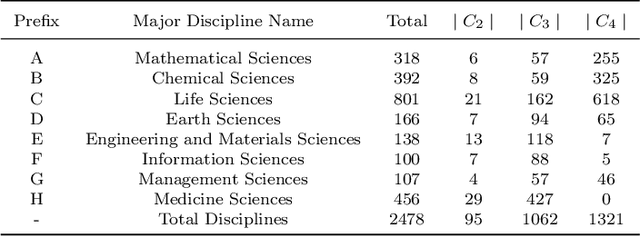
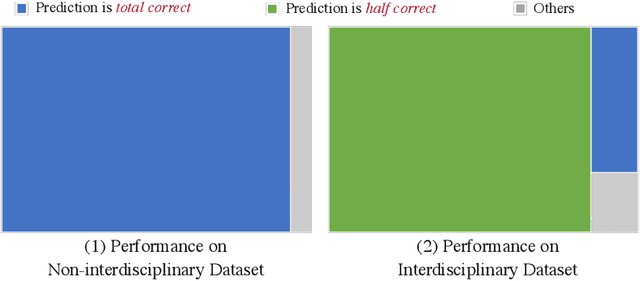
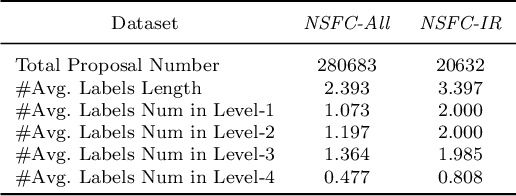
Funding agencies are largely relied on a topic matching between domain experts and research proposals to assign proposal reviewers. As proposals are increasingly interdisciplinary, it is challenging to profile the interdisciplinary nature of a proposal, and, thereafter, find expert reviewers with an appropriate set of expertise. An essential step in solving this challenge is to accurately model and classify the interdisciplinary labels of a proposal. Existing methodological and application-related literature, such as textual classification and proposal classification, are insufficient in jointly addressing the three key unique issues introduced by interdisciplinary proposal data: 1) the hierarchical structure of discipline labels of a proposal from coarse-grain to fine-grain, e.g., from information science to AI to fundamentals of AI. 2) the heterogeneous semantics of various main textual parts that play different roles in a proposal; 3) the number of proposals is imbalanced between non-interdisciplinary and interdisciplinary research. Can we simultaneously address the three issues in understanding the proposal's interdisciplinary nature? In response to this question, we propose a hierarchical mixup multiple-label classification framework, which we called H-MixUp. H-MixUp leverages a transformer-based semantic information extractor and a GCN-based interdisciplinary knowledge extractor for the first and second issues. H-MixUp develops a fused training method of Wold-level MixUp, Word-level CutMix, Manifold MixUp, and Document-level MixUp to address the third issue.
Doc-GCN: Heterogeneous Graph Convolutional Networks for Document Layout Analysis
Aug 22, 2022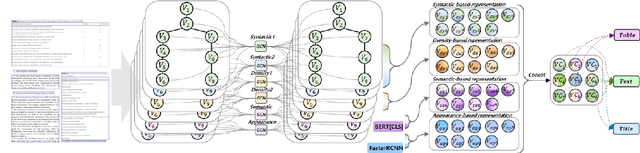


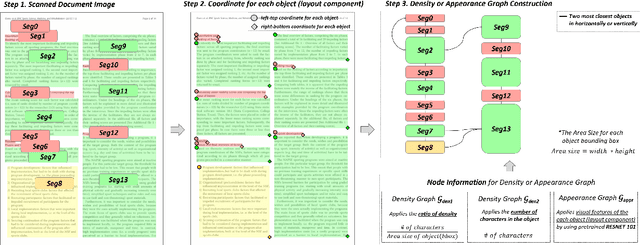
Recognizing the layout of unstructured digital documents is crucial when parsing the documents into the structured, machine-readable format for downstream applications. Recent studies in Document Layout Analysis usually rely on computer vision models to understand documents while ignoring other information, such as context information or relation of document components, which are vital to capture. Our Doc-GCN presents an effective way to harmonize and integrate heterogeneous aspects for Document Layout Analysis. We first construct graphs to explicitly describe four main aspects, including syntactic, semantic, density, and appearance/visual information. Then, we apply graph convolutional networks for representing each aspect of information and use pooling to integrate them. Finally, we aggregate each aspect and feed them into 2-layer MLPs for document layout component classification. Our Doc-GCN achieves new state-of-the-art results in three widely used DLA datasets.
SANCL: Multimodal Review Helpfulness Prediction with Selective Attention and Natural Contrastive Learning
Sep 16, 2022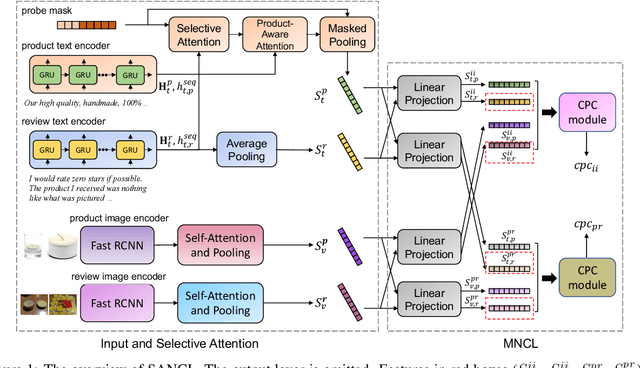
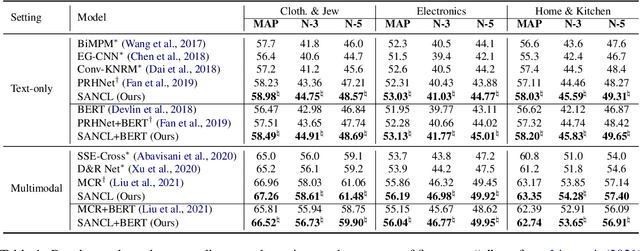
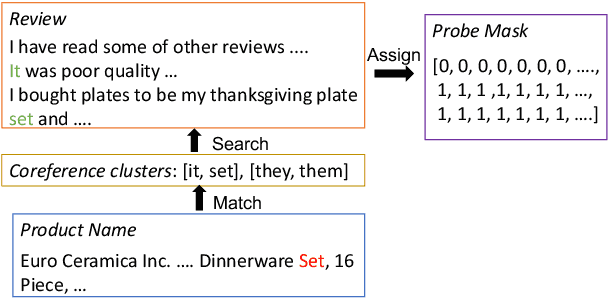
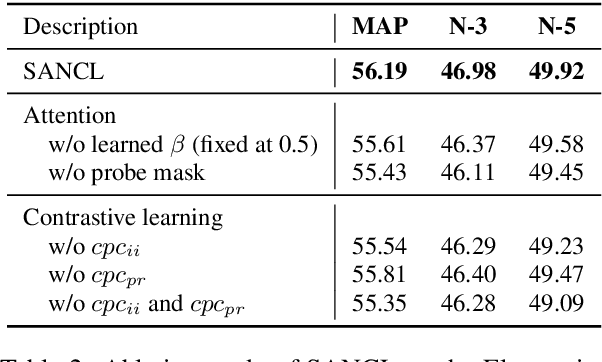
With the boom of e-commerce, Multimodal Review Helpfulness Prediction (MRHP), which aims to sort product reviews according to the predicted helpfulness scores has become a research hotspot. Previous work on this task focuses on attention-based modality fusion, information integration, and relation modeling, which primarily exposes the following drawbacks: 1) the model may fail to capture the really essential information due to its indiscriminate attention formulation; 2) lack appropriate modeling methods that take full advantage of correlation among provided data. In this paper, we propose SANCL: Selective Attention and Natural Contrastive Learning for MRHP. SANCL adopts a probe-based strategy to enforce high attention weights on the regions of greater significance. It also constructs a contrastive learning framework based on natural matching properties in the dataset. Experimental results on two benchmark datasets with three categories show that SANCL achieves state-of-the-art baseline performance with lower memory consumption.
Efficient Beam Search for Initial Access Using Collaborative Filtering
Sep 14, 2022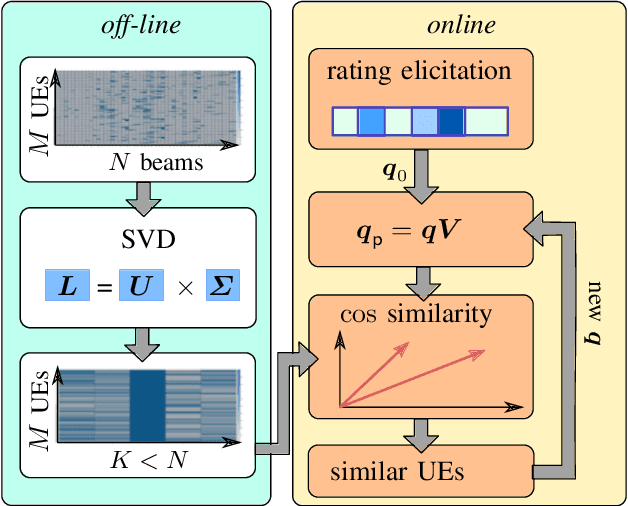
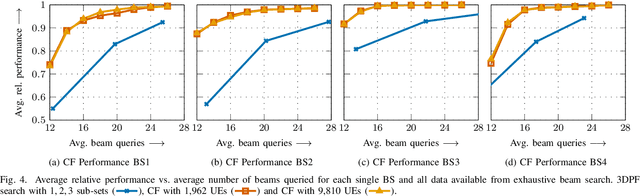
Beamforming-capable antenna arrays overcome the high free-space path loss at higher carrier frequencies. However, the beams must be properly aligned to ensure that the highest power is radiated towards (and received by) the user equipment (UE). While there are methods that improve upon an exhaustive search for optimal beams by some form of hierarchical search, they can be prone to return only locally optimal solutions with small beam gains. Other approaches address this problem by exploiting contextual information, e.g., the position of the UE or information from neighboring base stations (BS), but the burden of computing and communicating this additional information can be high. Methods based on machine learning so far suffer from the accompanying training, performance monitoring and deployment complexity that hinders their application at scale. This paper proposes a novel method for solving the initial beam-discovery problem. It is scalable, and easy to tune and to implement. Our algorithm is based on a recommender system that associates groups (i.e., UEs) and preferences (i.e., beams from a codebook) based on a training data set. Whenever a new UE needs to be served our algorithm returns the best beams in this user cluster. Our simulation results demonstrate the efficiency and robustness of our approach, not only in single BS setups but also in setups that require a coordination among several BSs. Our method consistently outperforms standard baseline algorithms in the given task.
Implicit Neural Representation as a Differentiable Surrogate for Photon Propagation in a Monolithic Neutrino Detector
Nov 02, 2022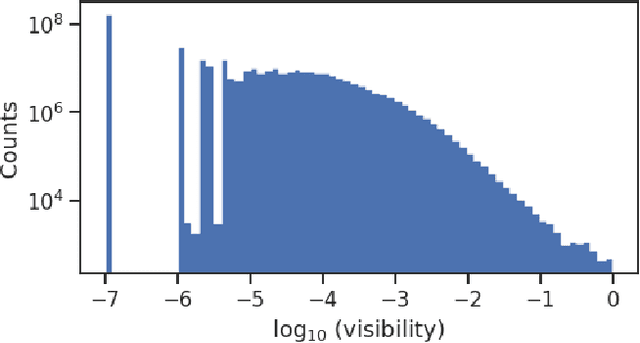
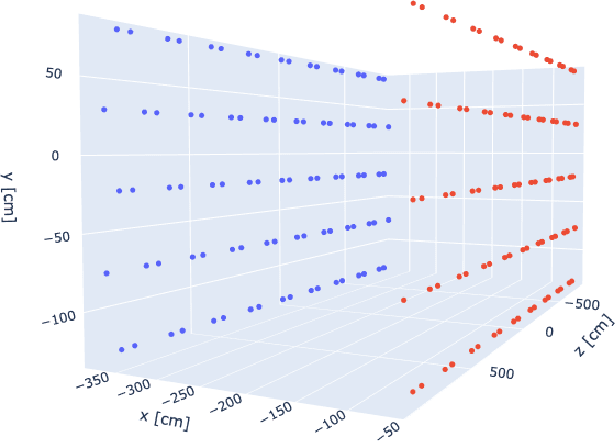

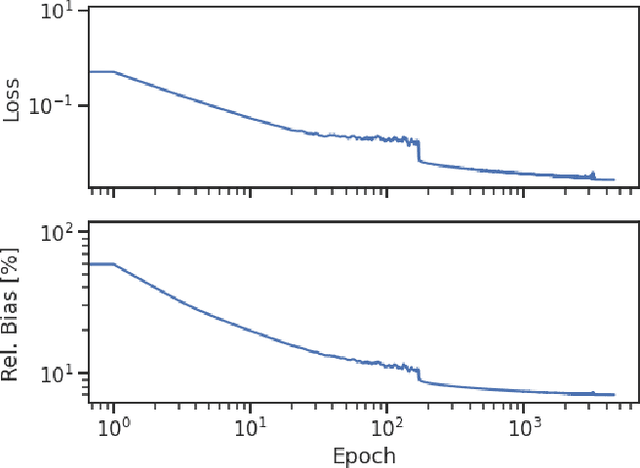
Optical photons are used as signal in a wide variety of particle detectors. Modern neutrino experiments employ hundreds to tens of thousands of photon detectors to observe signal from millions to billions of scintillation photons produced from energy deposition of charged particles. These neutrino detectors are typically large, containing kilotons of target volume, with different optical properties. Modeling individual photon propagation in form of look-up table requires huge computational resources. As the size of a table increases with detector volume for a fixed resolution, this method scales poorly for future larger detectors. Alternative approaches such as fitting a polynomial to the model could address the memory issue, but results in poorer performance. Both look-up table and fitting approaches are prone to discrepancies between the detector simulation and the data collected. We propose a new approach using SIREN, an implicit neural representation with periodic activation functions, to model the look-up table as a 3D scene and reproduces the acceptance map with high accuracy. The number of parameters in our SIREN model is orders of magnitude smaller than the number of voxels in the look-up table. As it models an underlying functional shape, SIREN is scalable to a larger detector. Furthermore, SIREN can successfully learn the spatial gradients of the photon library, providing additional information for downstream applications. Finally, as SIREN is a neural network representation, it is differentiable with respect to its parameters, and therefore tunable via gradient descent. We demonstrate the potential of optimizing SIREN directly on real data, which mitigates the concern of data vs. simulation discrepancies. We further present an application for data reconstruction where SIREN is used to form a likelihood function for photon statistics.
Multi-Vector Retrieval as Sparse Alignment
Nov 02, 2022

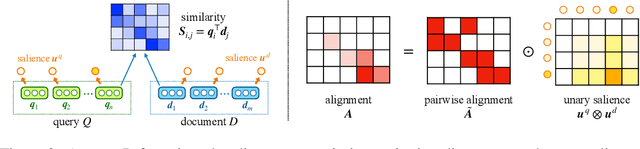
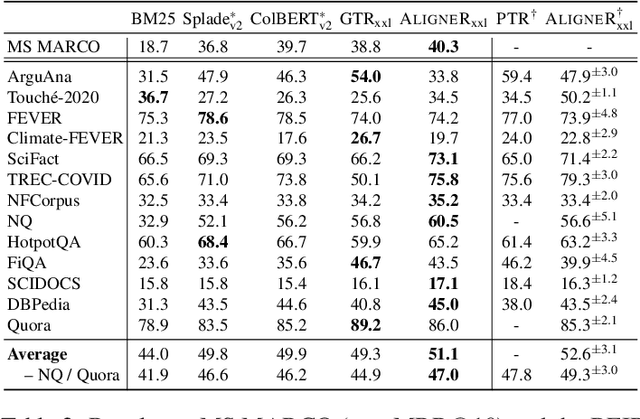
Multi-vector retrieval models improve over single-vector dual encoders on many information retrieval tasks. In this paper, we cast the multi-vector retrieval problem as sparse alignment between query and document tokens. We propose AligneR, a novel multi-vector retrieval model that learns sparsified pairwise alignments between query and document tokens (e.g. `dog' vs. `puppy') and per-token unary saliences reflecting their relative importance for retrieval. We show that controlling the sparsity of pairwise token alignments often brings significant performance gains. While most factoid questions focusing on a specific part of a document require a smaller number of alignments, others requiring a broader understanding of a document favor a larger number of alignments. Unary saliences, on the other hand, decide whether a token ever needs to be aligned with others for retrieval (e.g. `kind' from `kind of currency is used in new zealand}'). With sparsified unary saliences, we are able to prune a large number of query and document token vectors and improve the efficiency of multi-vector retrieval. We learn the sparse unary saliences with entropy-regularized linear programming, which outperforms other methods to achieve sparsity. In a zero-shot setting, AligneR scores 51.1 points nDCG@10, achieving a new retriever-only state-of-the-art on 13 tasks in the BEIR benchmark. In addition, adapting pairwise alignments with a few examples (<= 8) further improves the performance up to 15.7 points nDCG@10 for argument retrieval tasks. The unary saliences of AligneR helps us to keep only 20% of the document token representations with minimal performance loss. We further show that our model often produces interpretable alignments and significantly improves its performance when initialized from larger language models.