 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Temporal Densely Connected Recurrent Network for Event-based Human Pose Estimation
Sep 15, 2022


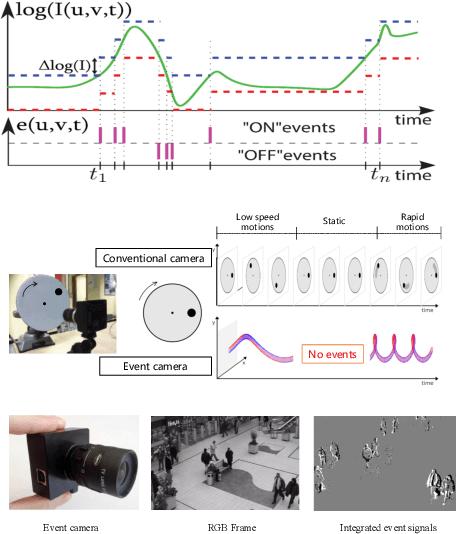
Event camera is an emerging bio-inspired vision sensors that report per-pixel brightness changes asynchronously. It holds noticeable advantage of high dynamic range, high speed response, and low power budget that enable it to best capture local motions in uncontrolled environments. This motivates us to unlock the potential of event cameras for human pose estimation, as the human pose estimation with event cameras is rarely explored. Due to the novel paradigm shift from conventional frame-based cameras, however, event signals in a time interval contain very limited information, as event cameras can only capture the moving body parts and ignores those static body parts, resulting in some parts to be incomplete or even disappeared in the time interval. This paper proposes a novel densely connected recurrent architecture to address the problem of incomplete information. By this recurrent architecture, we can explicitly model not only the sequential but also non-sequential geometric consistency across time steps to accumulate information from previous frames to recover the entire human bodies, achieving a stable and accurate human pose estimation from event data. Moreover, to better evaluate our model, we collect a large scale multimodal event-based dataset that comes with human pose annotations, which is by far the most challenging one to the best of our knowledge. The experimental results on two public datasets and our own dataset demonstrate the effectiveness and strength of our approach. Code can be available online for facilitating the future research.
Unsupervised Video Object Segmentation via Prototype Memory Network
Sep 08, 2022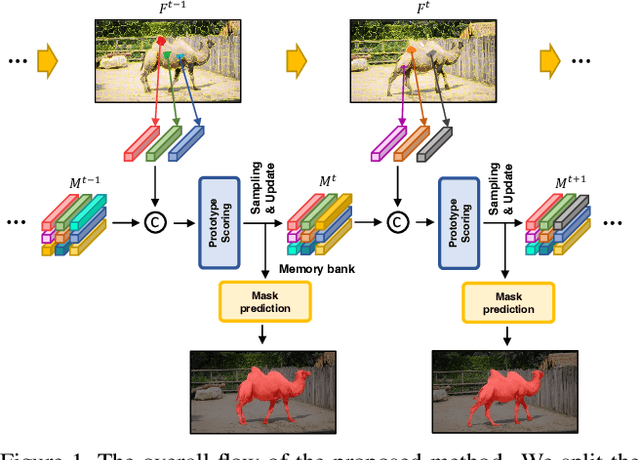
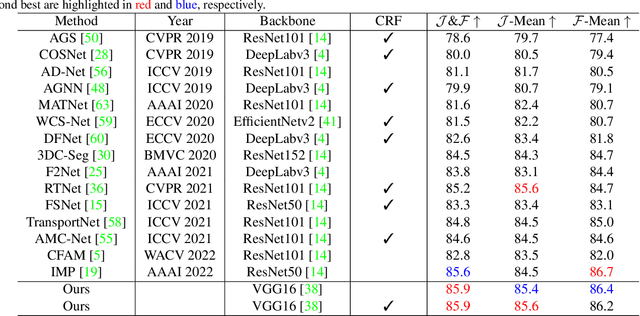
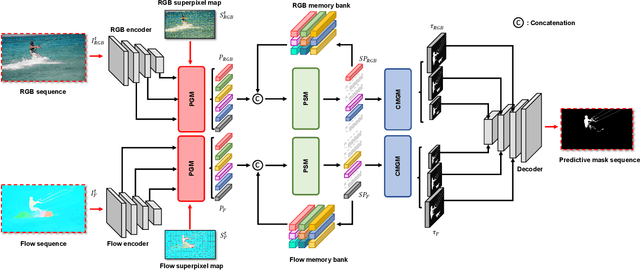

Unsupervised video object segmentation aims to segment a target object in the video without a ground truth mask in the initial frame. This challenging task requires extracting features for the most salient common objects within a video sequence. This difficulty can be solved by using motion information such as optical flow, but using only the information between adjacent frames results in poor connectivity between distant frames and poor performance. To solve this problem, we propose a novel prototype memory network architecture. The proposed model effectively extracts the RGB and motion information by extracting superpixel-based component prototypes from the input RGB images and optical flow maps. In addition, the model scores the usefulness of the component prototypes in each frame based on a self-learning algorithm and adaptively stores the most useful prototypes in memory and discards obsolete prototypes. We use the prototypes in the memory bank to predict the next query frames mask, which enhances the association between distant frames to help with accurate mask prediction. Our method is evaluated on three datasets, achieving state-of-the-art performance. We prove the effectiveness of the proposed model with various ablation studies.
Differentially Private Language Models for Secure Data Sharing
Oct 26, 2022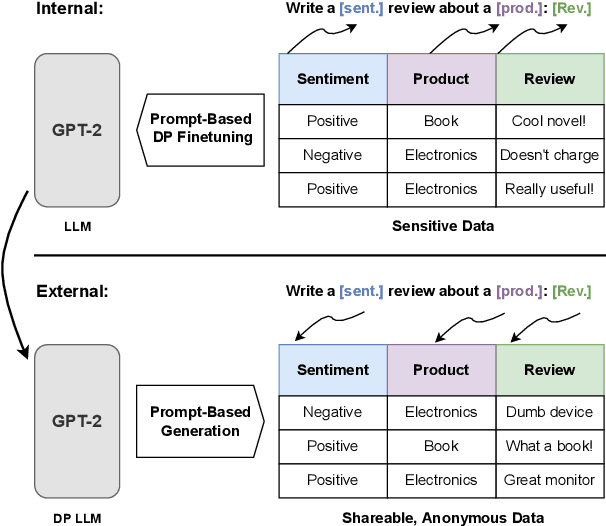
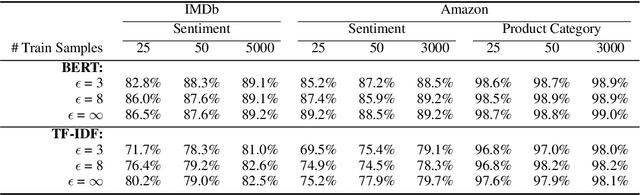

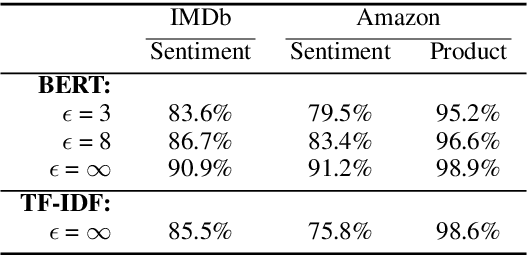
To protect the privacy of individuals whose data is being shared, it is of high importance to develop methods allowing researchers and companies to release textual data while providing formal privacy guarantees to its originators. In the field of NLP, substantial efforts have been directed at building mechanisms following the framework of local differential privacy, thereby anonymizing individual text samples before releasing them. In practice, these approaches are often dissatisfying in terms of the quality of their output language due to the strong noise required for local differential privacy. In this paper, we approach the problem at hand using global differential privacy, particularly by training a generative language model in a differentially private manner and consequently sampling data from it. Using natural language prompts and a new prompt-mismatch loss, we are able to create highly accurate and fluent textual datasets taking on specific desired attributes such as sentiment or topic and resembling statistical properties of the training data. We perform thorough experiments indicating that our synthetic datasets do not leak information from our original data and are of high language quality and highly suitable for training models for further analysis on real-world data. Notably, we also demonstrate that training classifiers on private synthetic data outperforms directly training classifiers on real data with DP-SGD.
Geographic Citation Gaps in NLP Research
Oct 26, 2022
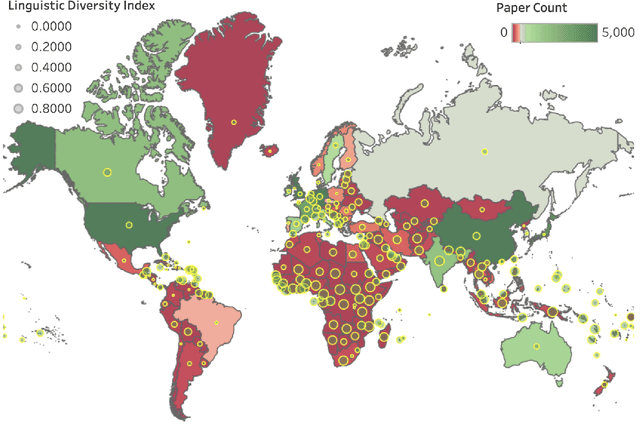
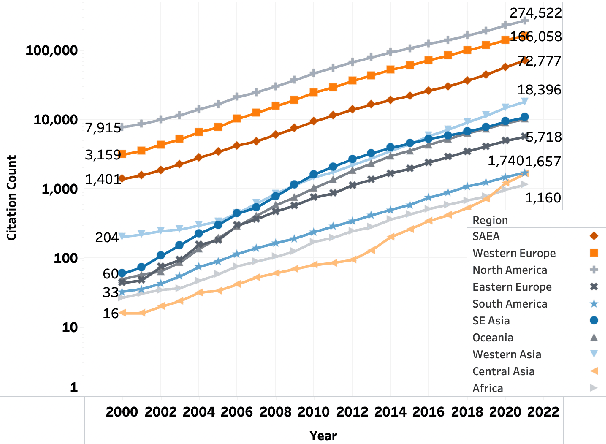
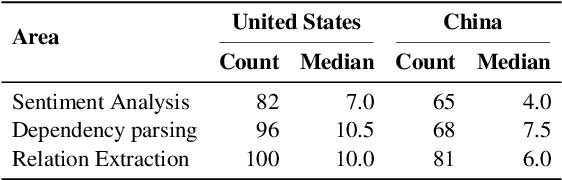
In a fair world, people have equitable opportunities to education, to conduct scientific research, to publish, and to get credit for their work, regardless of where they live. However, it is common knowledge among researchers that a vast number of papers accepted at top NLP venues come from a handful of western countries and (lately) China; whereas, very few papers from Africa and South America get published. Similar disparities are also believed to exist for paper citation counts. In the spirit of "what we do not measure, we cannot improve", this work asks a series of questions on the relationship between geographical location and publication success (acceptance in top NLP venues and citation impact). We first created a dataset of 70,000 papers from the ACL Anthology, extracted their meta-information, and generated their citation network. We then show that not only are there substantial geographical disparities in paper acceptance and citation but also that these disparities persist even when controlling for a number of variables such as venue of publication and sub-field of NLP. Further, despite some steps taken by the NLP community to improve geographical diversity, we show that the disparity in publication metrics across locations is still on an increasing trend since the early 2000s. We release our code and dataset here: https://github.com/iamjanvijay/acl-cite-net
EMA-VIO: Deep Visual-Inertial Odometry with External Memory Attention
Sep 18, 2022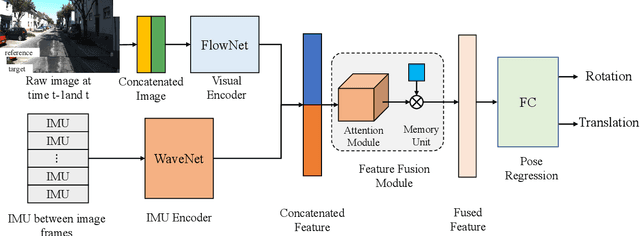
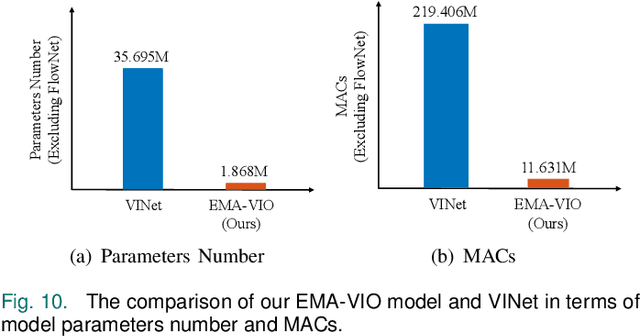
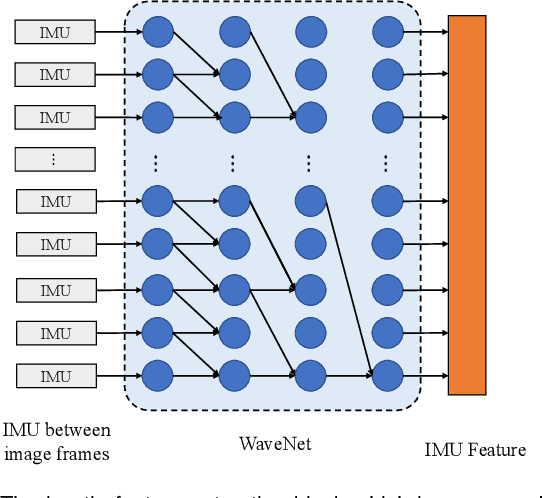
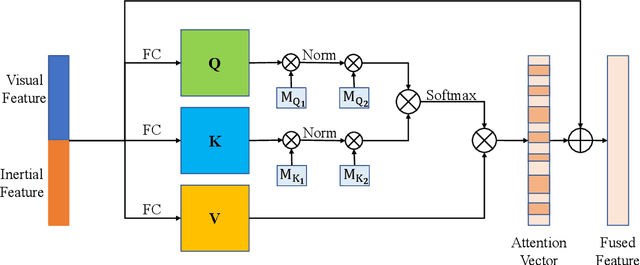
Accurate and robust localization is a fundamental need for mobile agents. Visual-inertial odometry (VIO) algorithms exploit the information from camera and inertial sensors to estimate position and translation. Recent deep learning based VIO models attract attentions as they provide pose information in a data-driven way, without the need of designing hand-crafted algorithms. Existing learning based VIO models rely on recurrent models to fuse multimodal data and process sensor signal, which are hard to train and not efficient enough. We propose a novel learning based VIO framework with external memory attention that effectively and efficiently combines visual and inertial features for states estimation. Our proposed model is able to estimate pose accurately and robustly, even in challenging scenarios, e.g., on overcast days and water-filled ground , which are difficult for traditional VIO algorithms to extract visual features. Experiments validate that it outperforms both traditional and learning based VIO baselines in different scenes.
Learning based Age of Information Minimization in UAV-relayed IoT Networks
Mar 08, 2022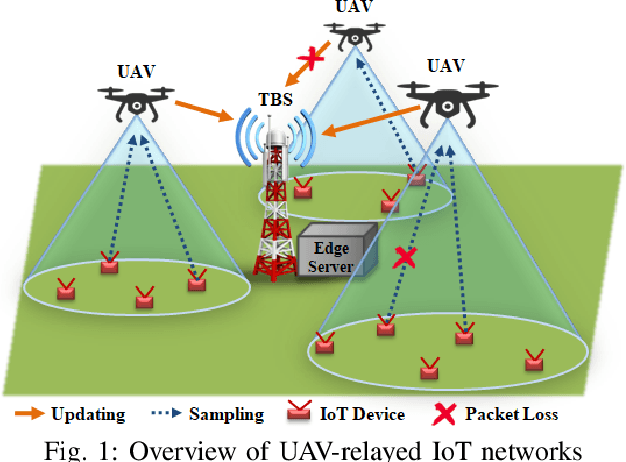
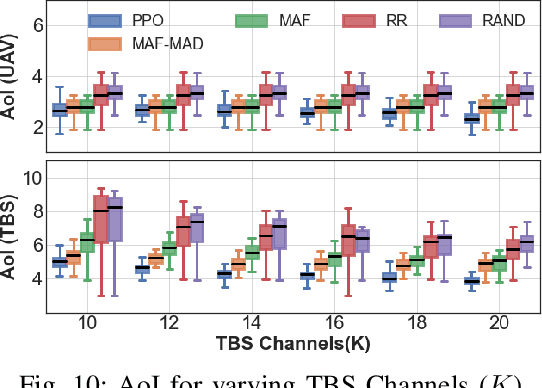
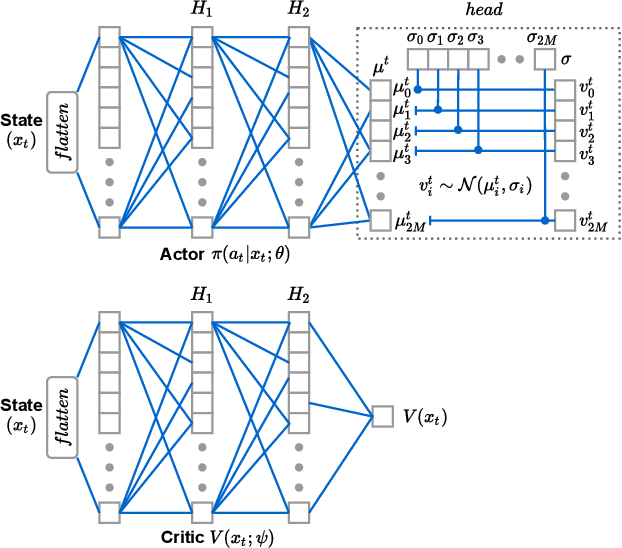
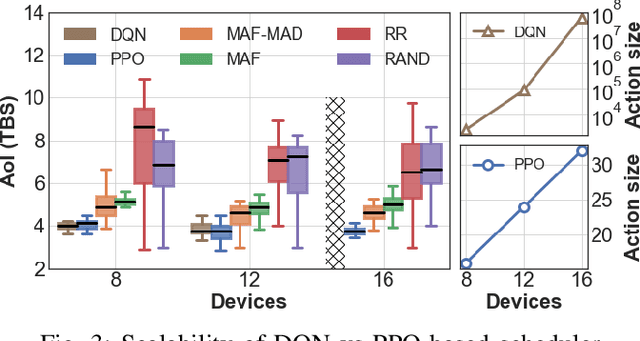
Unmanned Aerial Vehicles (UAVs) are used as aerial base-stations to relay time-sensitive packets from IoT devices to the nearby terrestrial base-station (TBS). Scheduling of packets in such UAV-relayed IoT-networks to ensure fresh (or up-to-date) IoT devices' packets at the TBS is a challenging problem as it involves two simultaneous steps of (i) sampling of packets generated at IoT devices by the UAVs [hop-1] and (ii) updating of sampled packets from UAVs to the TBS [hop-2]. To address this, we propose Age-of-Information (AoI) scheduling algorithms for two-hop UAV-relayed IoT-networks. First, we propose a low-complexity AoI scheduler, termed, MAF-MAD that employs Maximum AoI First (MAF) policy for sampling of IoT devices at UAV (hop-1) and Maximum AoI Difference (MAD) policy for updating sampled packets from UAV to the TBS (hop-2). We prove that MAF-MAD is the optimal AoI scheduler under ideal conditions (lossless wireless channels and generate-at-will traffic-generation at IoT devices). On the contrary, for general conditions (lossy channel conditions and varying periodic traffic-generation at IoT devices), a deep reinforcement learning algorithm, namely, Proximal Policy Optimization (PPO)-based scheduler is proposed. Simulation results show that the proposed PPO-based scheduler outperforms other schedulers like MAF-MAD, MAF, and round-robin in all considered general scenarios.
Leveraging Artificial Intelligence on Binary Code Comprehension
Oct 11, 2022Understanding binary code is an essential but complex software engineering task for reverse engineering, malware analysis, and compiler optimization. Unlike source code, binary code has limited semantic information, which makes it challenging for human comprehension. At the same time, compiling source to binary code, or transpiling among different programming languages (PLs) can provide a way to introduce external knowledge into binary comprehension. We propose to develop Artificial Intelligence (AI) models that aid human comprehension of binary code. Specifically, we propose to incorporate domain knowledge from large corpora of source code (e.g., variable names, comments) to build AI models that capture a generalizable representation of binary code. Lastly, we will investigate metrics to assess the performance of models that apply to binary code by using human studies of comprehension.
Monitoring and mapping of crop fields with UAV swarms based on information gain
Mar 22, 2022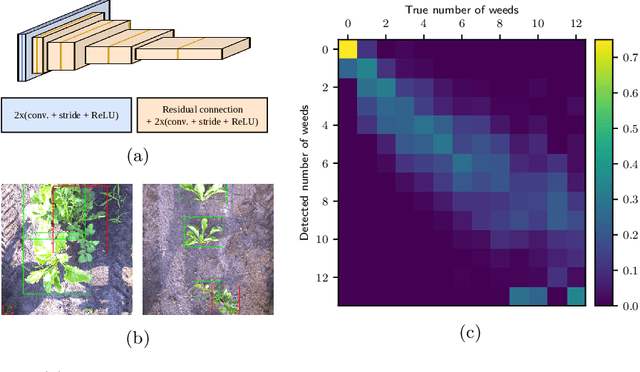
Monitoring crop fields to map features like weeds can be efficiently performed with unmanned aerial vehicles (UAVs) that can cover large areas in a short time due to their privileged perspective and motion speed. However, the need for high-resolution images for precise classification of features (e.g., detecting even the smallest weeds in the field) contrasts with the limited payload and ight time of current UAVs. Thus, it requires several flights to cover a large field uniformly. However, the assumption that the whole field must be observed with the same precision is unnecessary when features are heterogeneously distributed, like weeds appearing in patches over the field. In this case, an adaptive approach that focuses only on relevant areas can perform better, especially when multiple UAVs are employed simultaneously. Leveraging on a swarm-robotics approach, we propose a monitoring and mapping strategy that adaptively chooses the target areas based on the expected information gain, which measures the potential for uncertainty reduction due to further observations. The proposed strategy scales well with group size and leads to smaller mapping errors than optimal pre-planned monitoring approaches.
Multiscale Latent-Guided Entropy Model for LiDAR Point Cloud Compression
Sep 26, 2022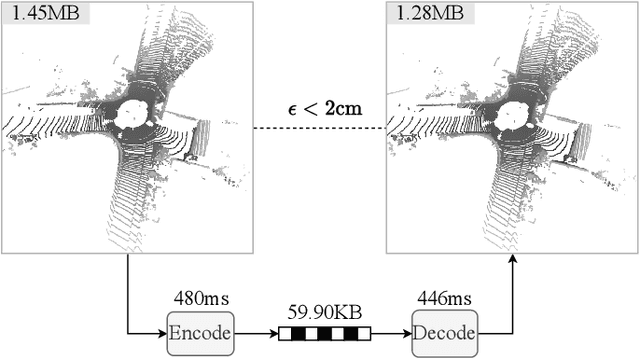
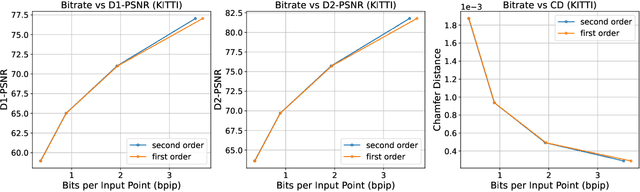
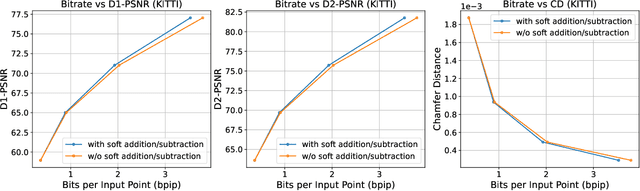

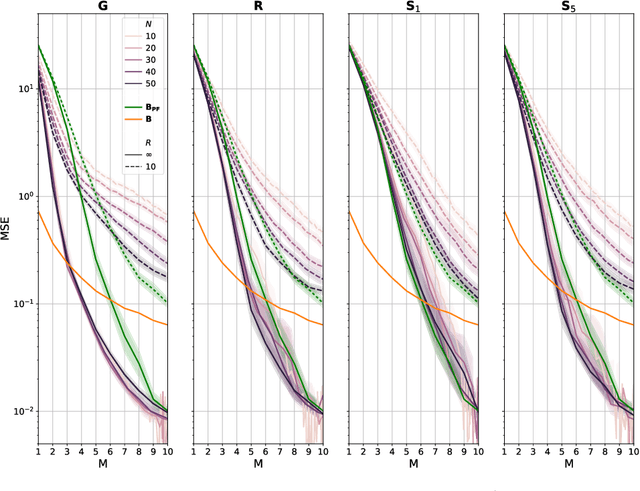
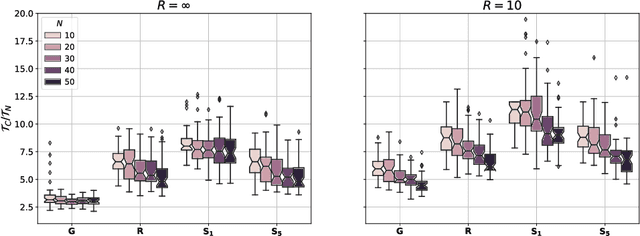
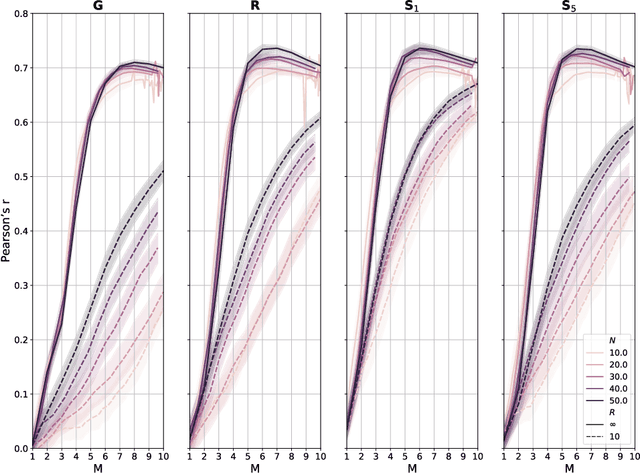
The non-uniform distribution and extremely sparse nature of the LiDAR point cloud (LPC) bring significant challenges to its high-efficient compression. This paper proposes a novel end-to-end, fully-factorized deep framework that encodes the original LPC into an octree structure and hierarchically decomposes the octree entropy model in layers. The proposed framework utilizes a hierarchical latent variable as side information to encapsulate the sibling and ancestor dependence, which provides sufficient context information for the modelling of point cloud distribution while enabling the parallel encoding and decoding of octree nodes in the same layer. Besides, we propose a residual coding framework for the compression of the latent variable, which explores the spatial correlation of each layer by progressive downsampling, and model the corresponding residual with a fully-factorized entropy model. Furthermore, we propose soft addition and subtraction for residual coding to improve network flexibility. The comprehensive experiment results on the LiDAR benchmark SemanticKITTI and MPEG-specified dataset Ford demonstrates that our proposed framework achieves state-of-the-art performance among all the previous LPC frameworks. Besides, our end-to-end, fully-factorized framework is proved by experiment to be high-parallelized and time-efficient and saves more than 99.8% of decoding time compared to previous state-of-the-art methods on LPC compression.
Progressive with Purpose: Guiding Progressive Inpainting DNNs through Context and Structure
Sep 21, 2022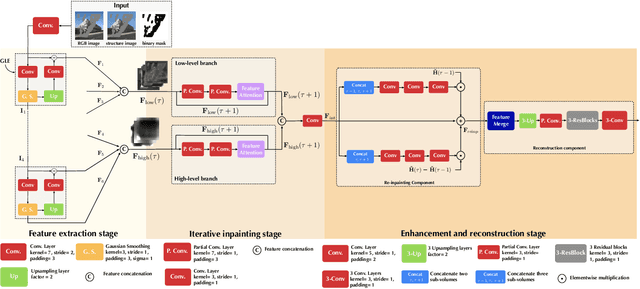



The advent of deep learning in the past decade has significantly helped advance image inpainting. Although achieving promising performance, deep learning-based inpainting algorithms still struggle from the distortion caused by the fusion of structural and contextual features, which are commonly obtained from, respectively, deep and shallow layers of a convolutional encoder. Motivated by this observation, we propose a novel progressive inpainting network that maintains the structural and contextual integrity of a processed image. More specifically, inspired by the Gaussian and Laplacian pyramids, the core of the proposed network is a feature extraction module named GLE. Stacking GLE modules enables the network to extract image features from different image frequency components. This ability is important to maintain structural and contextual integrity, for high frequency components correspond to structural information while low frequency components correspond to contextual information. The proposed network utilizes the GLE features to progressively fill in missing regions in a corrupted image in an iterative manner. Our benchmarking experiments demonstrate that the proposed method achieves clear improvement in performance over many state-of-the-art inpainting algorithms.