 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
End-to-End Affordance Learning for Robotic Manipulation
Sep 26, 2022
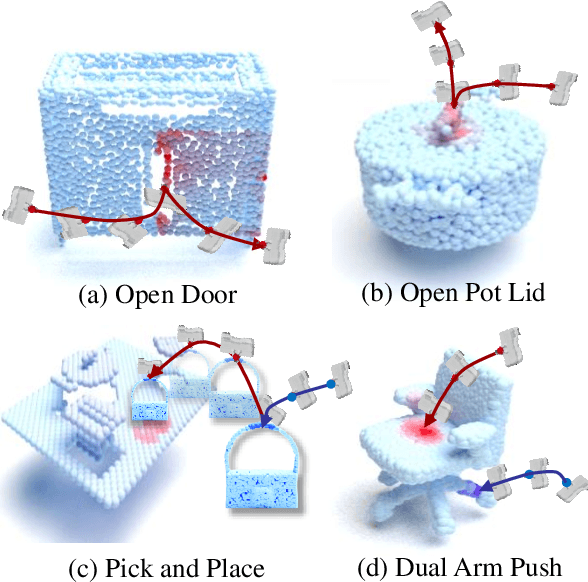
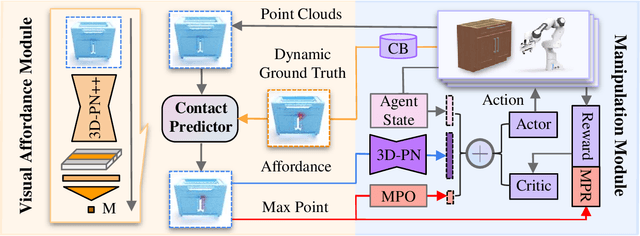

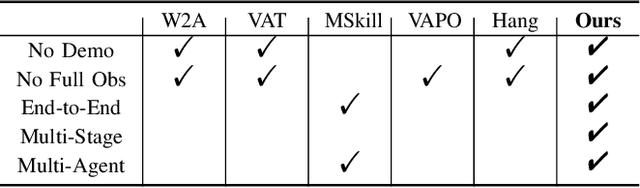
Learning to manipulate 3D objects in an interactive environment has been a challenging problem in Reinforcement Learning (RL). In particular, it is hard to train a policy that can generalize over objects with different semantic categories, diverse shape geometry and versatile functionality. Recently, the technique of visual affordance has shown great prospects in providing object-centric information priors with effective actionable semantics. As such, an effective policy can be trained to open a door by knowing how to exert force on the handle. However, to learn the affordance, it often requires human-defined action primitives, which limits the range of applicable tasks. In this study, we take advantage of visual affordance by using the contact information generated during the RL training process to predict contact maps of interest. Such contact prediction process then leads to an end-to-end affordance learning framework that can generalize over different types of manipulation tasks. Surprisingly, the effectiveness of such framework holds even under the multi-stage and the multi-agent scenarios. We tested our method on eight types of manipulation tasks. Results showed that our methods outperform baseline algorithms, including visual-based affordance methods and RL methods, by a large margin on the success rate. The demonstration can be found at https://sites.google.com/view/rlafford/.
Language Does More Than Describe: On The Lack Of Figurative Speech in Text-To-Image Models
Oct 19, 2022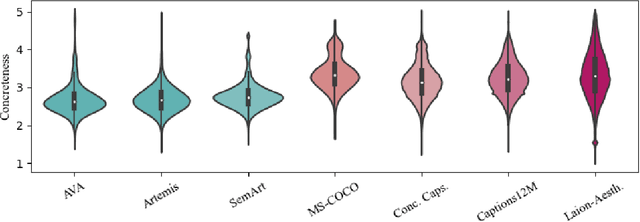
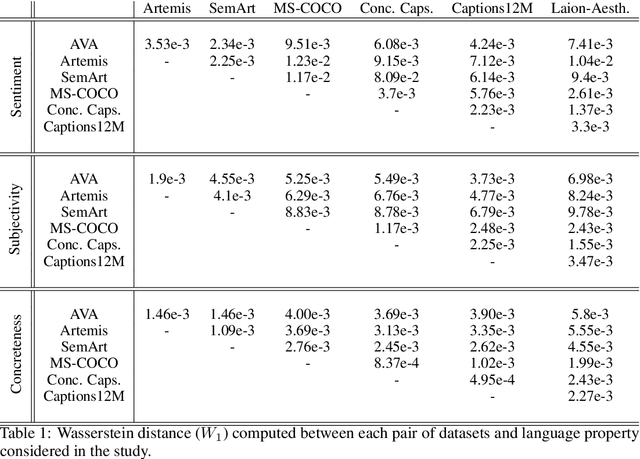


The impressive capacity shown by recent text-to-image diffusion models to generate high-quality pictures from textual input prompts has leveraged the debate about the very definition of art. Nonetheless, these models have been trained using text data collected from content-based labelling protocols that focus on describing the items and actions in an image but neglect any subjective appraisal. Consequently, these automatic systems need rigorous descriptions of the elements and the pictorial style of the image to be generated, otherwise failing to deliver. As potential indicators of the actual artistic capabilities of current generative models, we characterise the sentimentality, objectiveness and degree of abstraction of publicly available text data used to train current text-to-image diffusion models. Considering the sharp difference observed between their language style and that typically employed in artistic contexts, we suggest generative models should incorporate additional sources of subjective information in their training in order to overcome (or at least to alleviate) some of their current limitations, thus effectively unleashing a truly artistic and creative generation.
Image Semantic Relation Generation
Oct 19, 2022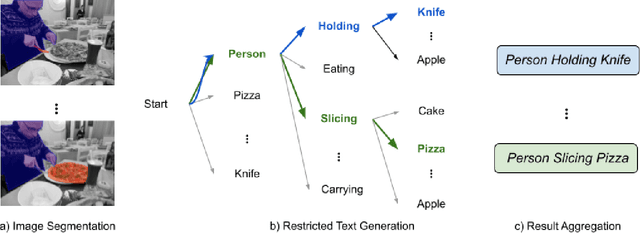


Scene graphs provide structured semantic understanding beyond images. For downstream tasks, such as image retrieval, visual question answering, visual relationship detection, and even autonomous vehicle technology, scene graphs can not only distil complex image information but also correct the bias of visual models using semantic-level relations, which has broad application prospects. However, the heavy labour cost of constructing graph annotations may hinder the application of PSG in practical scenarios. Inspired by the observation that people usually identify the subject and object first and then determine the relationship between them, we proposed to decouple the scene graphs generation task into two sub-tasks: 1) an image segmentation task to pick up the qualified objects. 2) a restricted auto-regressive text generation task to generate the relation between given objects. Therefore, in this work, we introduce image semantic relation generation (ISRG), a simple but effective image-to-text model, which achieved 31 points on the OpenPSG dataset and outperforms strong baselines respectively by 16 points (ResNet-50) and 5 points (CLIP).
From Play to Policy: Conditional Behavior Generation from Uncurated Robot Data
Oct 19, 2022


While large-scale sequence modeling from offline data has led to impressive performance gains in natural language and image generation, directly translating such ideas to robotics has been challenging. One critical reason for this is that uncurated robot demonstration data, i.e. play data, collected from non-expert human demonstrators are often noisy, diverse, and distributionally multi-modal. This makes extracting useful, task-centric behaviors from such data a difficult generative modeling problem. In this work, we present Conditional Behavior Transformers (C-BeT), a method that combines the multi-modal generation ability of Behavior Transformer with future-conditioned goal specification. On a suite of simulated benchmark tasks, we find that C-BeT improves upon prior state-of-the-art work in learning from play data by an average of 45.7%. Further, we demonstrate for the first time that useful task-centric behaviors can be learned on a real-world robot purely from play data without any task labels or reward information. Robot videos are best viewed on our project website: https://play-to-policy.github.io
Efficient, probabilistic analysis of combinatorial neural codes
Oct 19, 2022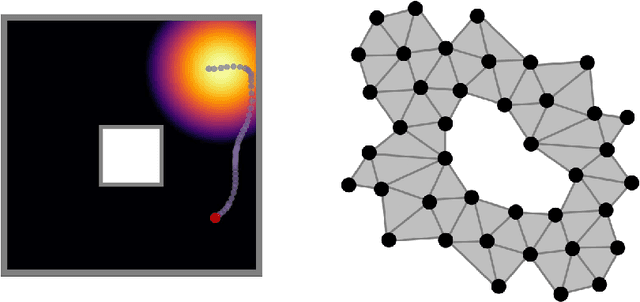

Artificial and biological neural networks (ANNs and BNNs) can encode inputs in the form of combinations of individual neurons' activities. These combinatorial neural codes present a computational challenge for direct and efficient analysis due to their high dimensionality and often large volumes of data. Here we improve the computational complexity -- from factorial to quadratic time -- of direct algebraic methods previously applied to small examples and apply them to large neural codes generated by experiments. These methods provide a novel and efficient way of probing algebraic, geometric, and topological characteristics of combinatorial neural codes and provide insights into how such characteristics are related to learning and experience in neural networks. We introduce a procedure to perform hypothesis testing on the intrinsic features of neural codes using information geometry. We then apply these methods to neural activities from an ANN for image classification and a BNN for 2D navigation to, without observing any inputs or outputs, estimate the structure and dimensionality of the stimulus or task space. Additionally, we demonstrate how an ANN varies its internal representations across network depth and during learning.
A sensor-to-pattern calibration framework for multi-modal industrial collaborative cells
Oct 19, 2022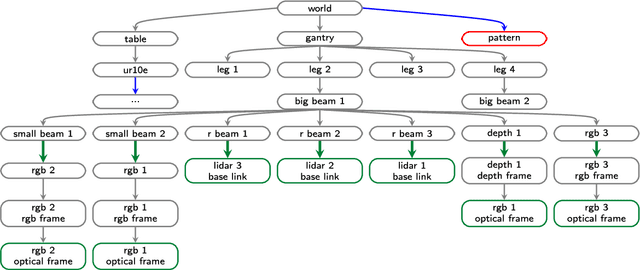
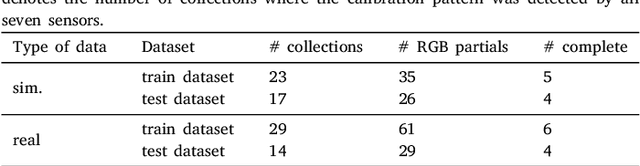

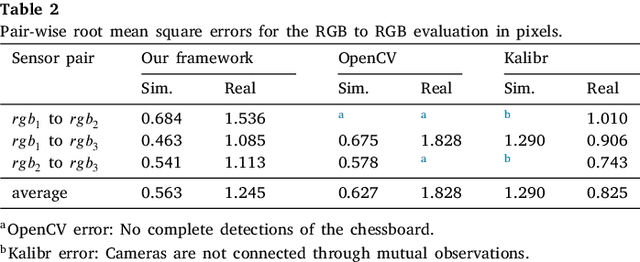
Collaborative robotic industrial cells are workspaces where robots collaborate with human operators. In this context, safety is paramount, and for that a complete perception of the space where the collaborative robot is inserted is necessary. To ensure this, collaborative cells are equipped with a large set of sensors of multiple modalities, covering the entire work volume. However, the fusion of information from all these sensors requires an accurate extrinsic calibration. The calibration of such complex systems is challenging, due to the number of sensors and modalities, and also due to the small overlapping fields of view between the sensors, which are positioned to capture different viewpoints of the cell. This paper proposes a sensor to pattern methodology that can calibrate a complex system such as a collaborative cell in a single optimization procedure. Our methodology can tackle RGB and Depth cameras, as well as LiDARs. Results show that our methodology is able to accurately calibrate a collaborative cell containing three RGB cameras, a depth camera and three 3D LiDARs.
* Journal of Manufacturing Systems
Knowledge Graph Enhanced Relation Extraction Datasets
Oct 19, 2022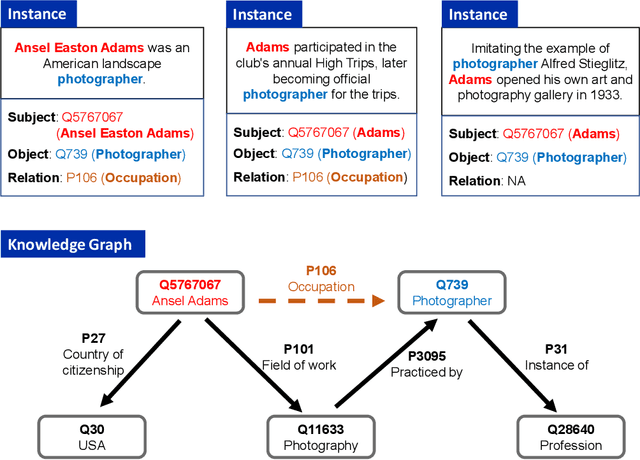
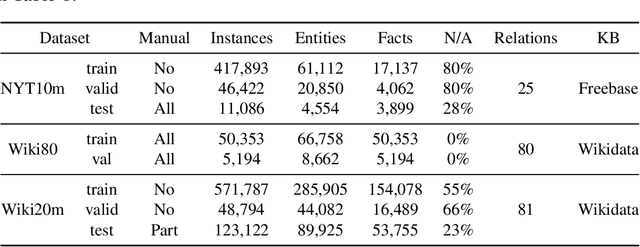

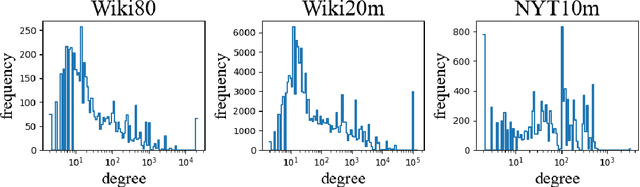
Knowledge-enhanced methods that take advantage of auxiliary knowledge graphs recently emerged in relation extraction, and they surpass traditional text-based relation extraction methods. However, there are no unified public benchmarks that currently involve evidence sentences and knowledge graphs for knowledge-enhanced relation extraction. To combat these issues, we propose KGRED, a knowledge graph enhanced relation extraction dataset with features as follows: (1) the benchmarks are based on widely-used distantly supervised relation extraction datasets; (2) we refine these existing datasets to improve the data quality, and we also construct auxiliary knowledge graphs for these existing datasets through entity linking to support knowledge-enhanced relation extraction tasks; (3) with the new benchmarks we curated, we build baselines in two popular relation extraction settings including sentence-level and bag-level relation extraction, and we also make comparisons among the latest knowledge-enhanced relation extraction methods. KGRED provides high-quality relation extraction datasets with auxiliary knowledge graphs for evaluating the performance of knowledge-enhanced relation extraction methods. Meanwhile, our experiments on KGRED reveal the influence of knowledge graph information on relation extraction tasks.
Self-supervised Heterogeneous Graph Pre-training Based on Structural Clustering
Oct 19, 2022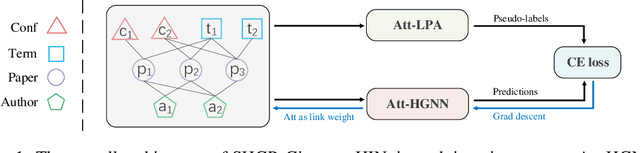

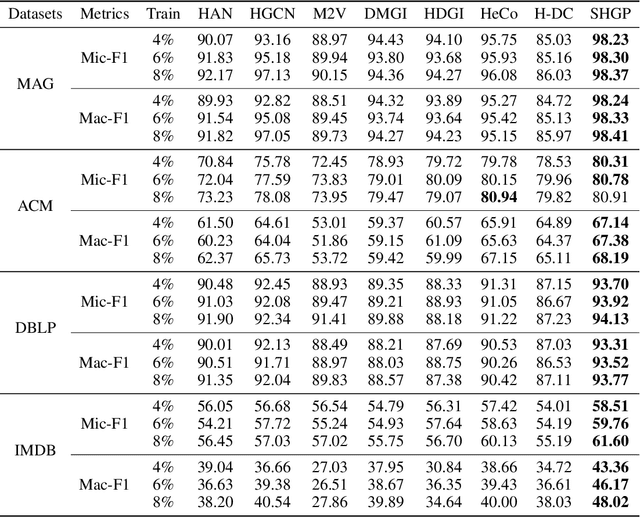
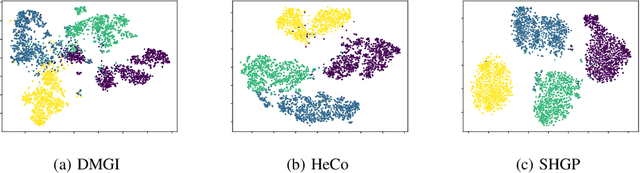
Recent self-supervised pre-training methods on Heterogeneous Information Networks (HINs) have shown promising competitiveness over traditional semi-supervised Heterogeneous Graph Neural Networks (HGNNs). Unfortunately, their performance heavily depends on careful customization of various strategies for generating high-quality positive examples and negative examples, which notably limits their flexibility and generalization ability. In this work, we present SHGP, a novel Self-supervised Heterogeneous Graph Pre-training approach, which does not need to generate any positive examples or negative examples. It consists of two modules that share the same attention-aggregation scheme. In each iteration, the Att-LPA module produces pseudo-labels through structural clustering, which serve as the self-supervision signals to guide the Att-HGNN module to learn object embeddings and attention coefficients. The two modules can effectively utilize and enhance each other, promoting the model to learn discriminative embeddings. Extensive experiments on four real-world datasets demonstrate the superior effectiveness of SHGP against state-of-the-art unsupervised baselines and even semi-supervised baselines. We release our source code at: https://github.com/kepsail/SHGP.
Targeted Adversarial Self-Supervised Learning
Oct 19, 2022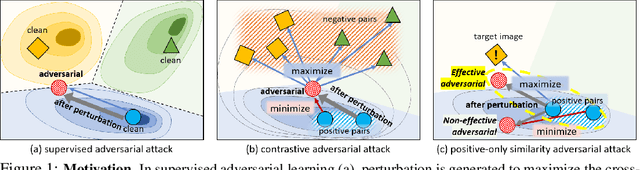
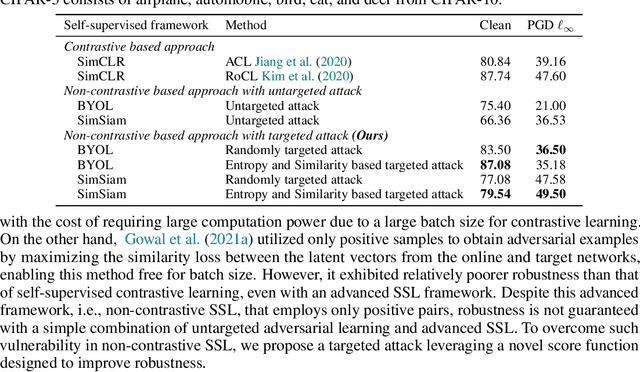
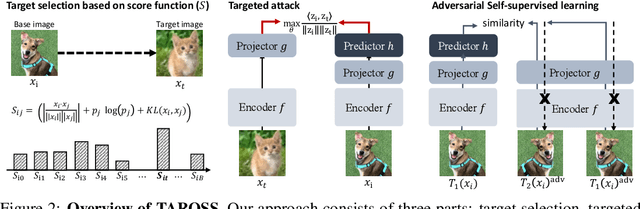

Recently, unsupervised adversarial training (AT) has been extensively studied to attain robustness with the models trained upon unlabeled data. To this end, previous studies have applied existing supervised adversarial training techniques to self-supervised learning (SSL) frameworks. However, all have resorted to untargeted adversarial learning as obtaining targeted adversarial examples is unclear in the SSL setting lacking of label information. In this paper, we propose a novel targeted adversarial training method for the SSL frameworks. Specifically, we propose a target selection algorithm for the adversarial SSL frameworks; it is designed to select the most confusing sample for each given instance based on similarity and entropy, and perturb the given instance toward the selected target sample. Our method significantly enhances the robustness of an SSL model without requiring large batches of images or additional models, unlike existing works aimed at achieving the same goal. Moreover, our method is readily applicable to general SSL frameworks that only uses positive pairs. We validate our method on benchmark datasets, on which it obtains superior robust accuracies, outperforming existing unsupervised adversarial training methods.
Comparing informativeness of an NLG chatbot vs graphical app in diet-information domain
Jul 02, 2022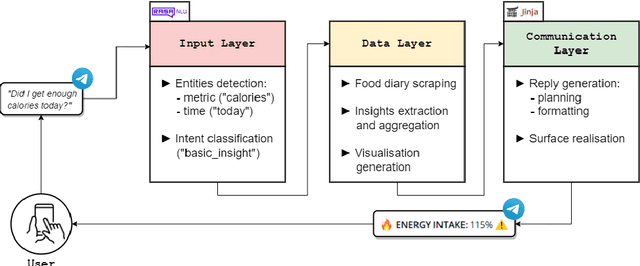
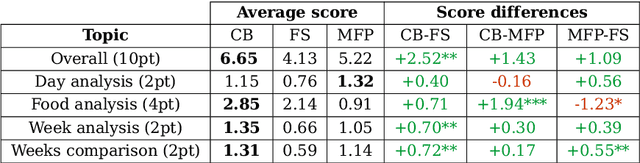
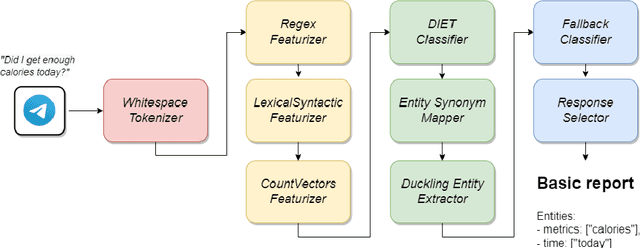
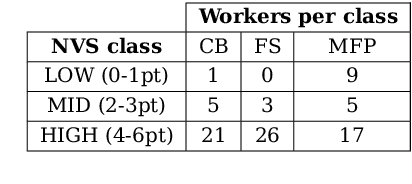
Visual representation of data like charts and tables can be challenging to understand for readers. Previous work showed that combining visualisations with text can improve the communication of insights in static contexts, but little is known about interactive ones. In this work we present an NLG chatbot that processes natural language queries and provides insights through a combination of charts and text. We apply it to nutrition, a domain communication quality is critical. Through crowd-sourced evaluation we compare the informativeness of our chatbot against traditional, static diet-apps. We find that the conversational context significantly improved users' understanding of dietary data in various tasks, and that users considered the chatbot as more useful and quick to use than traditional apps.