 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Leveraging Enhanced Queries of Point Sets for Vectorized Map Construction
Feb 27, 2024
In autonomous driving, the high-definition (HD) map plays a crucial role in localization and planning. Recently, several methods have facilitated end-to-end online map construction in DETR-like frameworks. However, little attention has been paid to the potential capabilities of exploring the query mechanism. This paper introduces MapQR, an end-to-end method with an emphasis on enhancing query capabilities for constructing online vectorized maps. Although the map construction is essentially a point set prediction task, MapQR utilizes instance queries rather than point queries. These instance queries are scattered for the prediction of point sets and subsequently gathered for the final matching. This query design, called the scatter-and-gather query, shares content information in the same map element and avoids possible inconsistency of content information in point queries. We further exploit prior information to enhance an instance query by adding positional information embedded from their reference points. Together with a simple and effective improvement of a BEV encoder, the proposed MapQR achieves the best mean average precision (mAP) and maintains good efficiency on both nuScenes and Argoverse 2. In addition, integrating our query design into other models can boost their performance significantly. The code will be available at https://github.com/HXMap/MapQR.
Vision Transformers with Natural Language Semantics
Feb 27, 2024Tokens or patches within Vision Transformers (ViT) lack essential semantic information, unlike their counterparts in natural language processing (NLP). Typically, ViT tokens are associated with rectangular image patches that lack specific semantic context, making interpretation difficult and failing to effectively encapsulate information. We introduce a novel transformer model, Semantic Vision Transformers (sViT), which leverages recent progress on segmentation models to design novel tokenizer strategies. sViT effectively harnesses semantic information, creating an inductive bias reminiscent of convolutional neural networks while capturing global dependencies and contextual information within images that are characteristic of transformers. Through validation using real datasets, sViT demonstrates superiority over ViT, requiring less training data while maintaining similar or superior performance. Furthermore, sViT demonstrates significant superiority in out-of-distribution generalization and robustness to natural distribution shifts, attributed to its scale invariance semantic characteristic. Notably, the use of semantic tokens significantly enhances the model's interpretability. Lastly, the proposed paradigm facilitates the introduction of new and powerful augmentation techniques at the token (or segment) level, increasing training data diversity and generalization capabilities. Just as sentences are made of words, images are formed by semantic objects; our proposed methodology leverages recent progress in object segmentation and takes an important and natural step toward interpretable and robust vision transformers.
Using Graph Neural Networks to Predict Local Culture
Feb 27, 2024Urban research has long recognized that neighbourhoods are dynamic and relational. However, lack of data, methodologies, and computer processing power have hampered a formal quantitative examination of neighbourhood relational dynamics. To make progress on this issue, this study proposes a graph neural network (GNN) approach that permits combining and evaluating multiple sources of information about internal characteristics of neighbourhoods, their past characteristics, and flows of groups among them, potentially providing greater expressive power in predictive models. By exploring a public large-scale dataset from Yelp, we show the potential of our approach for considering structural connectedness in predicting neighbourhood attributes, specifically to predict local culture. Results are promising from a substantive and methodologically point of view. Substantively, we find that either local area information (e.g. area demographics) or group profiles (tastes of Yelp reviewers) give the best results in predicting local culture, and they are nearly equivalent in all studied cases. Methodologically, exploring group profiles could be a helpful alternative where finding local information for specific areas is challenging, since they can be extracted automatically from many forms of online data. Thus, our approach could empower researchers and policy-makers to use a range of data sources when other local area information is lacking.
RAGged Edges: The Double-Edged Sword of Retrieval-Augmented Chatbots
Mar 02, 2024

Large language models (LLMs) like ChatGPT demonstrate the remarkable progress of artificial intelligence. However, their tendency to hallucinate -- generate plausible but false information -- poses a significant challenge. This issue is critical, as seen in recent court cases where ChatGPT's use led to citations of non-existent legal rulings. This paper explores how Retrieval-Augmented Generation (RAG) can counter hallucinations by integrating external knowledge with prompts. We empirically evaluate RAG against standard LLMs using prompts designed to induce hallucinations. Our results show that RAG increases accuracy in some cases, but can still be misled when prompts directly contradict the model's pre-trained understanding. These findings highlight the complex nature of hallucinations and the need for more robust solutions to ensure LLM reliability in real-world applications. We offer practical recommendations for RAG deployment and discuss implications for the development of more trustworthy LLMs.
GraphTranslator: Aligning Graph Model to Large Language Model for Open-ended Tasks
Feb 28, 2024Large language models (LLMs) like ChatGPT, exhibit powerful zero-shot and instruction-following capabilities, have catalyzed a revolutionary transformation across diverse fields, especially for open-ended tasks. While the idea is less explored in the graph domain, despite the availability of numerous powerful graph models (GMs), they are restricted to tasks in a pre-defined form. Although several methods applying LLMs to graphs have been proposed, they fail to simultaneously handle the pre-defined and open-ended tasks, with LLM as a node feature enhancer or as a standalone predictor. To break this dilemma, we propose to bridge the pretrained GM and LLM by a Translator, named GraphTranslator, aiming to leverage GM to handle the pre-defined tasks effectively and utilize the extended interface of LLMs to offer various open-ended tasks for GM. To train such Translator, we propose a Producer capable of constructing the graph-text alignment data along node information, neighbor information and model information. By translating node representation into tokens, GraphTranslator empowers an LLM to make predictions based on language instructions, providing a unified perspective for both pre-defined and open-ended tasks. Extensive results demonstrate the effectiveness of our proposed GraphTranslator on zero-shot node classification. The graph question answering experiments reveal our GraphTranslator potential across a broad spectrum of open-ended tasks through language instructions. Our code is available at: https://github.com/alibaba/GraphTranslator.
The Information of Large Language Model Geometry
Feb 01, 2024This paper investigates the information encoded in the embeddings of large language models (LLMs). We conduct simulations to analyze the representation entropy and discover a power law relationship with model sizes. Building upon this observation, we propose a theory based on (conditional) entropy to elucidate the scaling law phenomenon. Furthermore, we delve into the auto-regressive structure of LLMs and examine the relationship between the last token and previous context tokens using information theory and regression techniques. Specifically, we establish a theoretical connection between the information gain of new tokens and ridge regression. Additionally, we explore the effectiveness of Lasso regression in selecting meaningful tokens, which sometimes outperforms the closely related attention weights. Finally, we conduct controlled experiments, and find that information is distributed across tokens, rather than being concentrated in specific "meaningful" tokens alone.
The Grasp Loop Signature: A Topological Representation for Manipulation Planning with Ropes and Cables
Mar 03, 2024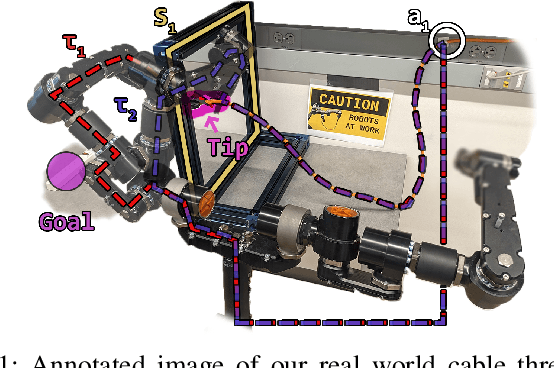

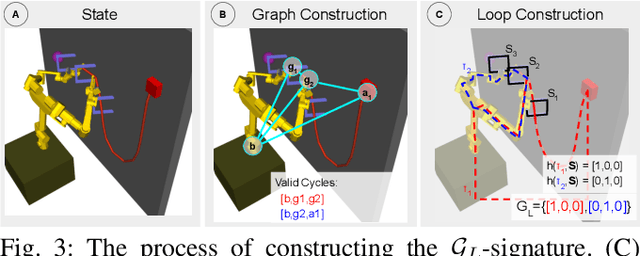
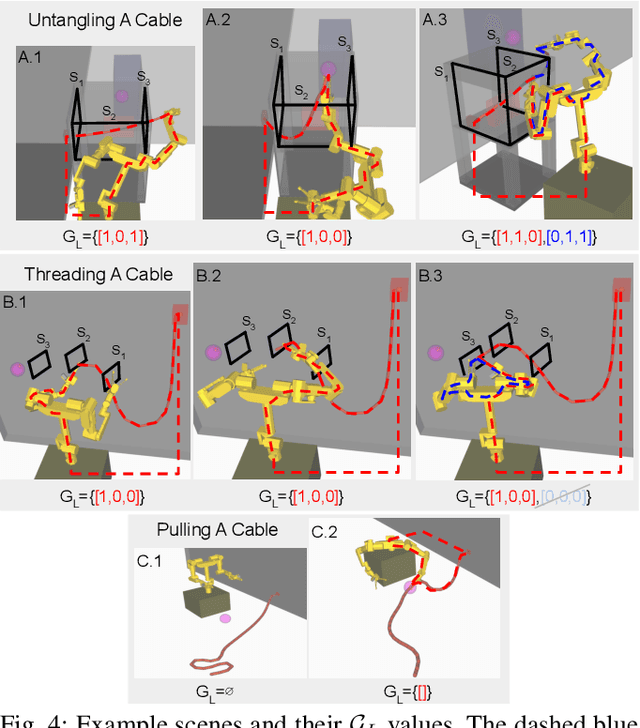
Robotic manipulation of deformable, one-dimensional objects (DOOs) like ropes or cables has important potential applications in manufacturing, agriculture, and surgery. In such environments, the task may involve threading through or avoiding becoming tangled with objects like racks or frames. Grasping with multiple grippers can create closed loops between the robot and DOO, and If an obstacle lies within this loop, it may be impossible to reach the goal. However, prior work has only considered the topology of the DOO in isolation, ignoring the arms that are manipulating it. Searching over possible grasps to accomplish the task without considering such topological information is very inefficient, as many grasps will not lead to progress on the task due to topological constraints. Therefore, we propose a grasp loop signature which categorizes the topology of these grasp loops and show how it can be used to guide planning. We perform experiments in simulation on two DOO manipulation tasks to show that using the signature is faster and succeeds more often than methods that rely on local geometry or finite-horizon planning. Finally, we demonstrate using the signature in the real world to manipulate a cable in a scene with obstacles using a dual-arm robot.
Privacy-Preserving Collaborative Split Learning Framework for Smart Grid Load Forecasting
Mar 03, 2024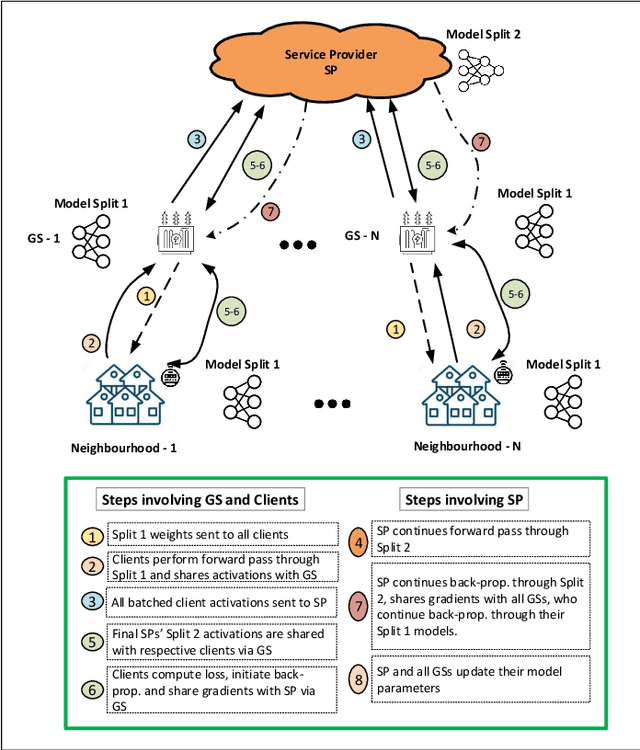
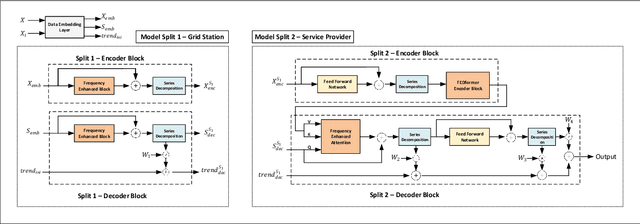
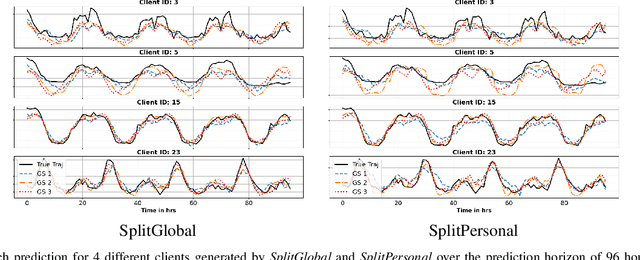
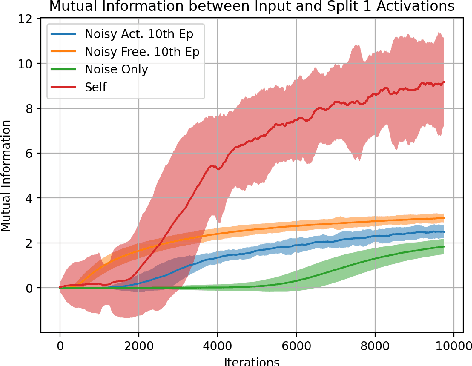
Accurate load forecasting is crucial for energy management, infrastructure planning, and demand-supply balancing. Smart meter data availability has led to the demand for sensor-based load forecasting. Conventional ML allows training a single global model using data from multiple smart meters requiring data transfer to a central server, raising concerns for network requirements, privacy, and security. We propose a split learning-based framework for load forecasting to alleviate this issue. We split a deep neural network model into two parts, one for each Grid Station (GS) responsible for an entire neighbourhood's smart meters and the other for the Service Provider (SP). Instead of sharing their data, client smart meters use their respective GSs' model split for forward pass and only share their activations with the GS. Under this framework, each GS is responsible for training a personalized model split for their respective neighbourhoods, whereas the SP can train a single global or personalized model for each GS. Experiments show that the proposed models match or exceed a centrally trained model's performance and generalize well. Privacy is analyzed by assessing information leakage between data and shared activations of the GS model split. Additionally, differential privacy enhances local data privacy while examining its impact on performance. A transformer model is used as our base learner.
A Comprehensive Survey of Federated Transfer Learning: Challenges, Methods and Applications
Mar 03, 2024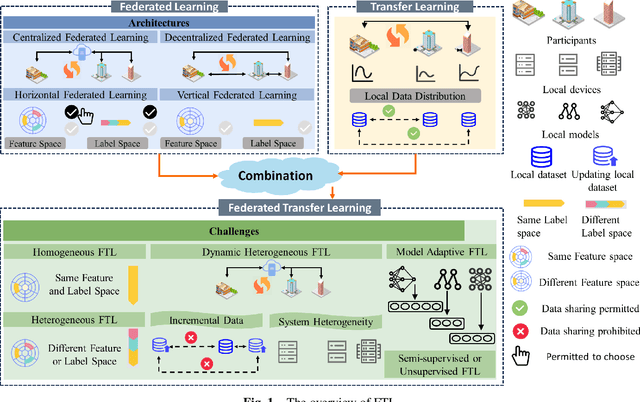
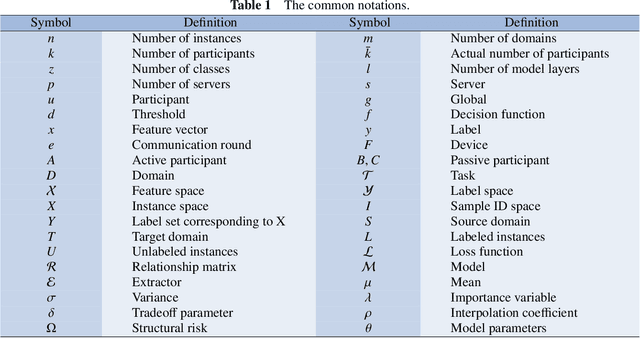
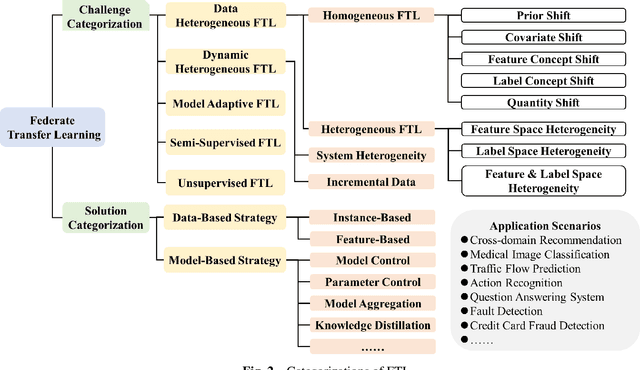
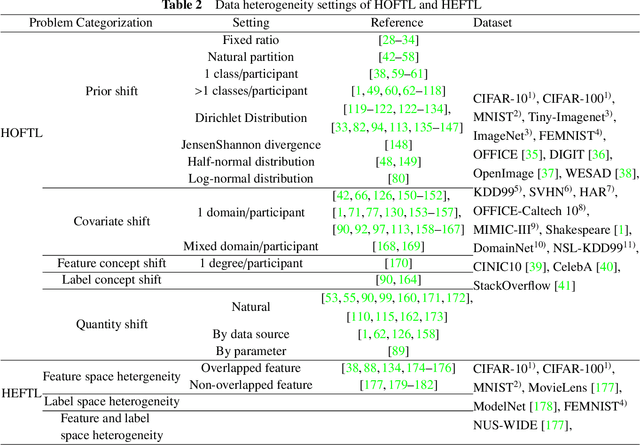
Federated learning (FL) is a novel distributed machine learning paradigm that enables participants to collaboratively train a centralized model with privacy preservation by eliminating the requirement of data sharing. In practice, FL often involves multiple participants and requires the third party to aggregate global information to guide the update of the target participant. Therefore, many FL methods do not work well due to the training and test data of each participant may not be sampled from the same feature space and the same underlying distribution. Meanwhile, the differences in their local devices (system heterogeneity), the continuous influx of online data (incremental data), and labeled data scarcity may further influence the performance of these methods. To solve this problem, federated transfer learning (FTL), which integrates transfer learning (TL) into FL, has attracted the attention of numerous researchers. However, since FL enables a continuous share of knowledge among participants with each communication round while not allowing local data to be accessed by other participants, FTL faces many unique challenges that are not present in TL. In this survey, we focus on categorizing and reviewing the current progress on federated transfer learning, and outlining corresponding solutions and applications. Furthermore, the common setting of FTL scenarios, available datasets, and significant related research are summarized in this survey.
AIO2: Online Correction of Object Labels for Deep Learning with Incomplete Annotation in Remote Sensing Image Segmentation
Mar 03, 2024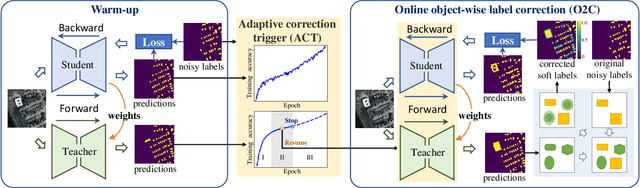
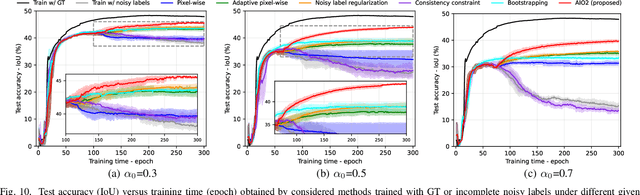

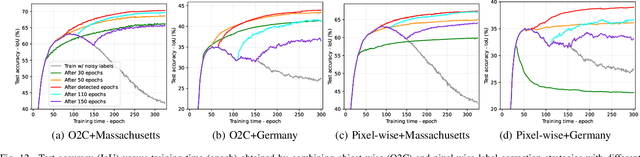
While the volume of remote sensing data is increasing daily, deep learning in Earth Observation faces lack of accurate annotations for supervised optimization. Crowdsourcing projects such as OpenStreetMap distribute the annotation load to their community. However, such annotation inevitably generates noise due to insufficient control of the label quality, lack of annotators, frequent changes of the Earth's surface as a result of natural disasters and urban development, among many other factors. We present Adaptively trIggered Online Object-wise correction (AIO2) to address annotation noise induced by incomplete label sets. AIO2 features an Adaptive Correction Trigger (ACT) module that avoids label correction when the model training under- or overfits, and an Online Object-wise Correction (O2C) methodology that employs spatial information for automated label modification. AIO2 utilizes a mean teacher model to enhance training robustness with noisy labels to both stabilize the training accuracy curve for fitting in ACT and provide pseudo labels for correction in O2C. Moreover, O2C is implemented online without the need to store updated labels every training epoch. We validate our approach on two building footprint segmentation datasets with different spatial resolutions. Experimental results with varying degrees of building label noise demonstrate the robustness of AIO2. Source code will be available at https://github.com/zhu-xlab/AIO2.git.