 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Identifying patterns of main causes of death in the young EU population
Oct 11, 2022
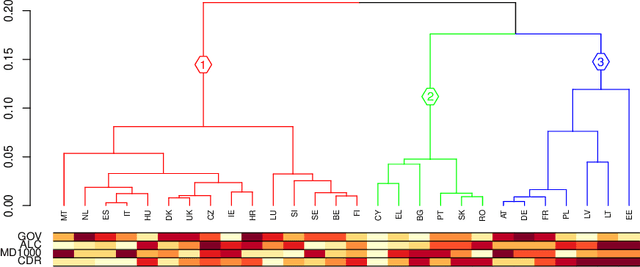
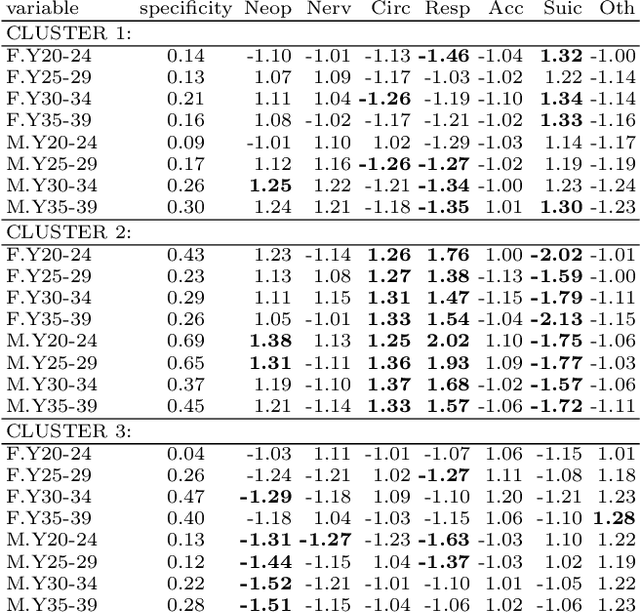
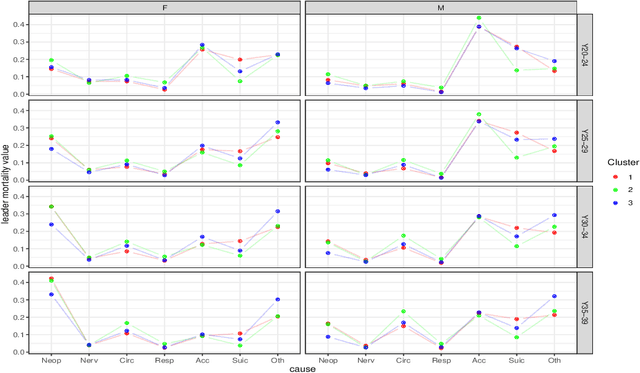
The study of mortality patterns is a popular research topic in many areas. We are particularly interested in mortality patterns among main causes of death associated with age-gender combinations. We use symbolic data analysis (SDA) and include three dimensions: age, gender, and patterns across main causes of death. In this study, we present an alternative method to identify clusters of EU countries with similar mortality patterns in the young population, while considering comprehensive information on the distribution of deaths among the main causes of death by different age-gender groups. We explore possible relationships between mortality patterns in the identified clusters and some other sociodemographic indicators. We use EU data of crude mortality rates from 2016, as the most recent complete data available.
Contrastive Training Improves Zero-Shot Classification of Semi-structured Documents
Oct 11, 2022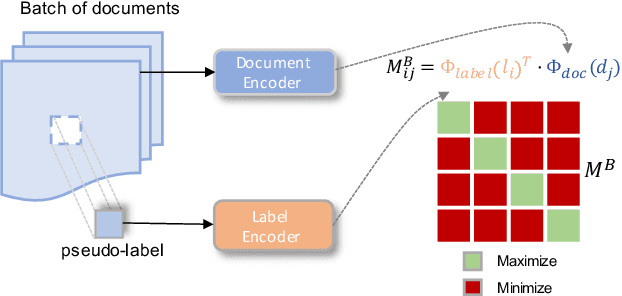


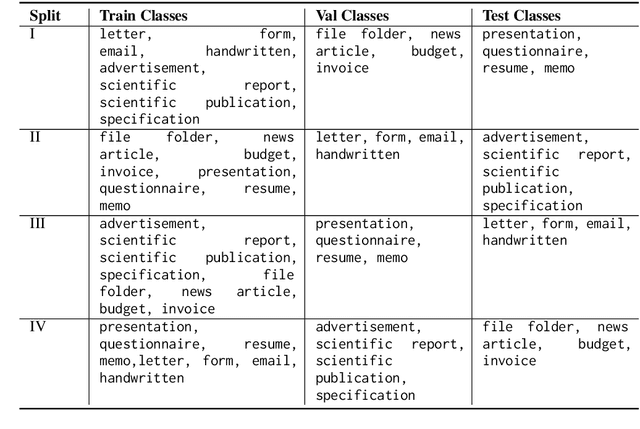
We investigate semi-structured document classification in a zero-shot setting. Classification of semi-structured documents is more challenging than that of standard unstructured documents, as positional, layout, and style information play a vital role in interpreting such documents. The standard classification setting where categories are fixed during both training and testing falls short in dynamic environments where new document categories could potentially emerge. We focus exclusively on the zero-shot setting where inference is done on new unseen classes. To address this task, we propose a matching-based approach that relies on a pairwise contrastive objective for both pretraining and fine-tuning. Our results show a significant boost in Macro F$_1$ from the proposed pretraining step in both supervised and unsupervised zero-shot settings.
McQueen: a Benchmark for Multimodal Conversational Query Rewrite
Oct 23, 2022
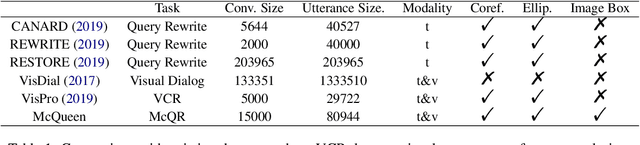

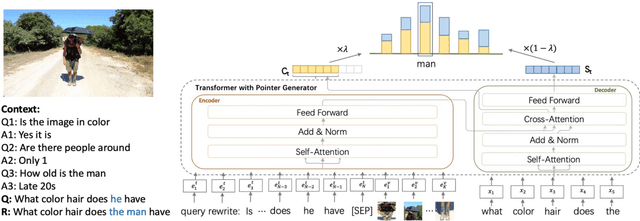
The task of query rewrite aims to convert an in-context query to its fully-specified version where ellipsis and coreference are completed and referred-back according to the history context. Although much progress has been made, less efforts have been paid to real scenario conversations that involve drawing information from more than one modalities. In this paper, we propose the task of multimodal conversational query rewrite (McQR), which performs query rewrite under the multimodal visual conversation setting. We collect a large-scale dataset named McQueen based on manual annotation, which contains 15k visual conversations and over 80k queries where each one is associated with a fully-specified rewrite version. In addition, for entities appearing in the rewrite, we provide the corresponding image box annotation. We then use the McQueen dataset to benchmark a state-of-the-art method for effectively tackling the McQR task, which is based on a multimodal pre-trained model with pointer generator. Extensive experiments are performed to demonstrate the effectiveness of our model on this task\footnote{The dataset and code of this paper are both available in \url{https://github.com/yfyuan01/MQR}
Learning General World Models in a Handful of Reward-Free Deployments
Oct 23, 2022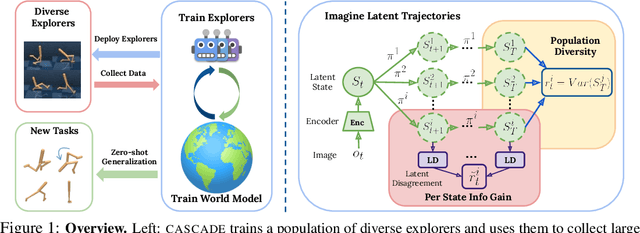
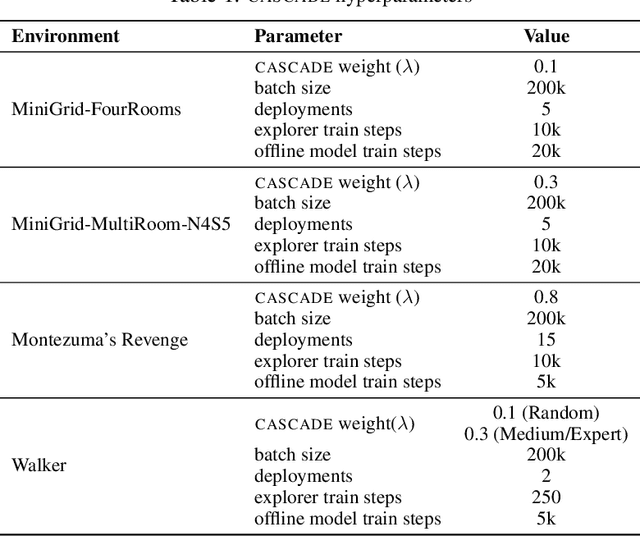
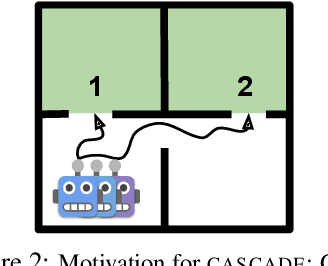
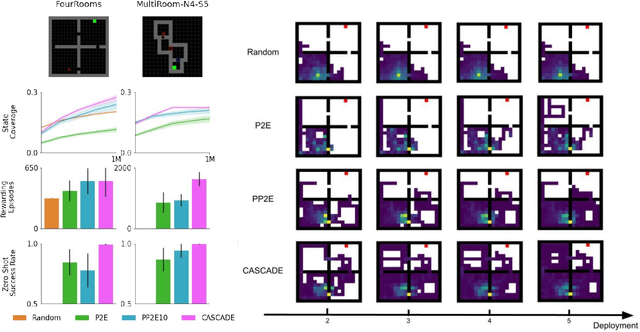
Building generally capable agents is a grand challenge for deep reinforcement learning (RL). To approach this challenge practically, we outline two key desiderata: 1) to facilitate generalization, exploration should be task agnostic; 2) to facilitate scalability, exploration policies should collect large quantities of data without costly centralized retraining. Combining these two properties, we introduce the reward-free deployment efficiency setting, a new paradigm for RL research. We then present CASCADE, a novel approach for self-supervised exploration in this new setting. CASCADE seeks to learn a world model by collecting data with a population of agents, using an information theoretic objective inspired by Bayesian Active Learning. CASCADE achieves this by specifically maximizing the diversity of trajectories sampled by the population through a novel cascading objective. We provide theoretical intuition for CASCADE which we show in a tabular setting improves upon na\"ive approaches that do not account for population diversity. We then demonstrate that CASCADE collects diverse task-agnostic datasets and learns agents that generalize zero-shot to novel, unseen downstream tasks on Atari, MiniGrid, Crafter and the DM Control Suite. Code and videos are available at https://ycxuyingchen.github.io/cascade/
AskYourDB: An end-to-end system for querying and visualizing relational databases using natural language
Oct 16, 2022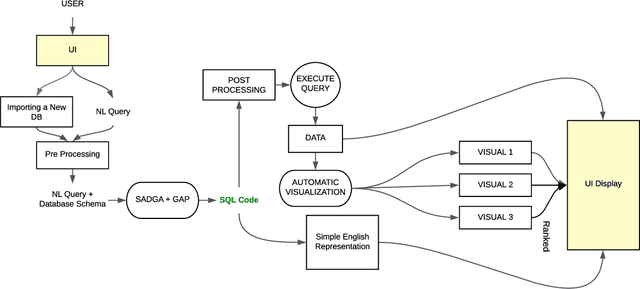
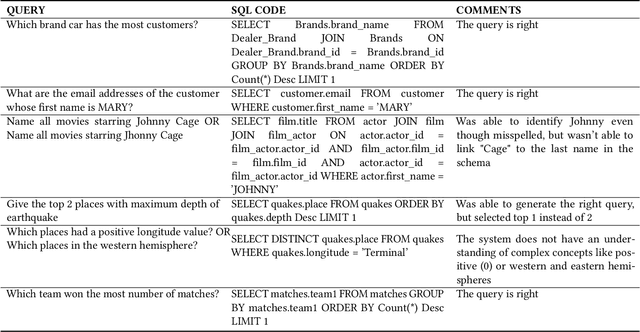
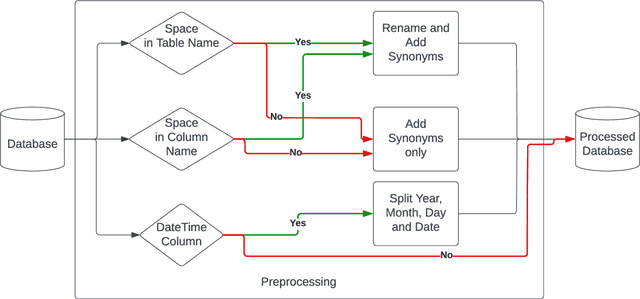
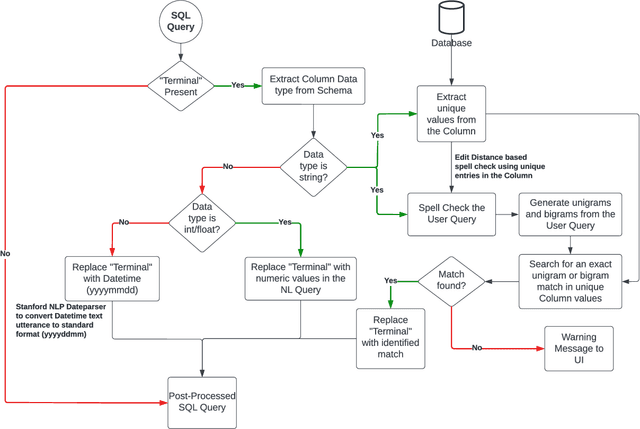
Querying databases for the right information is a time consuming and error-prone task and often requires experienced professionals for the job. Furthermore, the user needs to have some prior knowledge about the database. There have been various efforts to develop an intelligence which can help business users to query databases directly. However, there has been some successes, but very little in terms of testing and deploying those for real world users. In this paper, we propose a semantic parsing approach to address the challenge of converting complex natural language into SQL and institute a product out of it. For this purpose, we modified state-of-the-art models, by various pre and post processing steps which make the significant part when a model is deployed in production. To make the product serviceable to businesses we added an automatic visualization framework over the queried results.
Show and Write: Entity-aware News Generation with Image Information
Dec 11, 2021
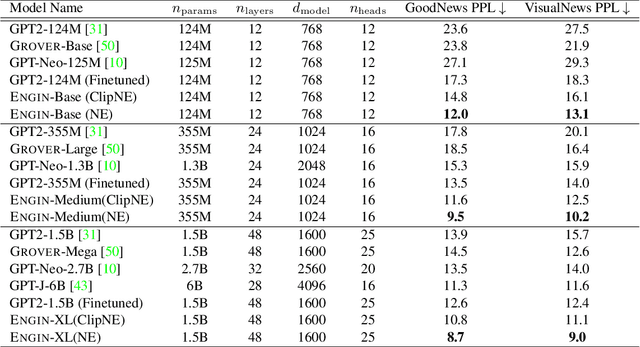
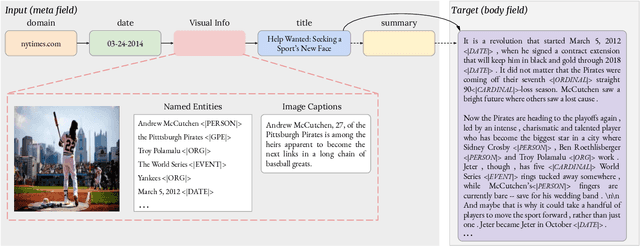

Automatically writing long articles is a complex and challenging language generation task. Prior work has primarily focused on generating these articles using human-written prompt to provide some topical context and some metadata about the article. That said, for many applications, such as generating news stories, these articles are often paired with images and their captions or alt-text, which in turn are based on real-world events and may reference many different named entities that are difficult to be correctly recognized and predicted by language models. To address these two problems, this paper introduces an Entity-aware News Generation method with Image iNformation, Engin, to incorporate news image information into language models. Engin produces news articles conditioned on both metadata and information such as captions and named entities extracted from images. We also propose an Entity-aware mechanism to help our model better recognize and predict the entity names in news. We perform experiments on two public large-scale news datasets, GoodNews and VisualNews. Quantitative results show that our approach improves article perplexity by 4-5 points over the base models. Qualitative results demonstrate the text generated by Engin is more consistent with news images. We also perform article quality annotation experiment on the generated articles to validate that our model produces higher-quality articles. Finally, we investigate the effect Engin has on methods that automatically detect machine-generated articles.
Multimodal Representations Learning Based on Mutual Information Maximization and Minimization and Identity Embedding for Multimodal Sentiment Analysis
Jan 10, 2022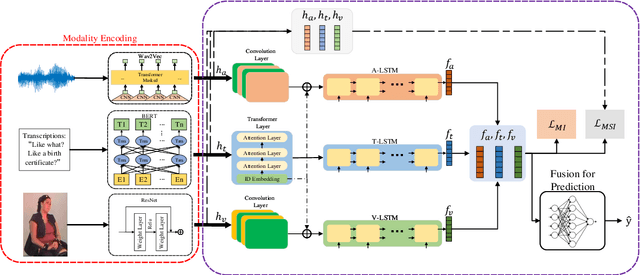
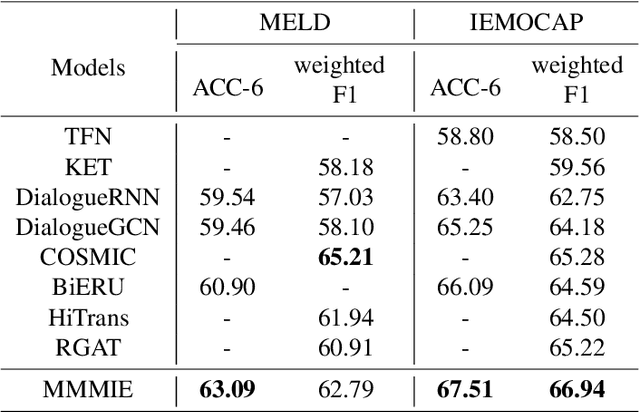
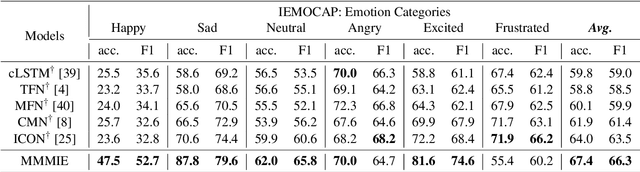
Multimodal sentiment analysis (MSA) is a fundamental complex research problem due to the heterogeneity gap between different modalities and the ambiguity of human emotional expression. Although there have been many successful attempts to construct multimodal representations for MSA, there are still two challenges to be addressed: 1) A more robust multimodal representation needs to be constructed to bridge the heterogeneity gap and cope with the complex multimodal interactions, and 2) the contextual dynamics must be modeled effectively throughout the information flow. In this work, we propose a multimodal representation model based on Mutual information Maximization and Minimization and Identity Embedding (MMMIE). We combine mutual information maximization between modal pairs, and mutual information minimization between input data and corresponding features to mine the modal-invariant and task-related information. Furthermore, Identity Embedding is proposed to prompt the downstream network to perceive the contextual information. Experimental results on two public datasets demonstrate the effectiveness of the proposed model.
Memory in humans and deep language models: Linking hypotheses for model augmentation
Oct 07, 2022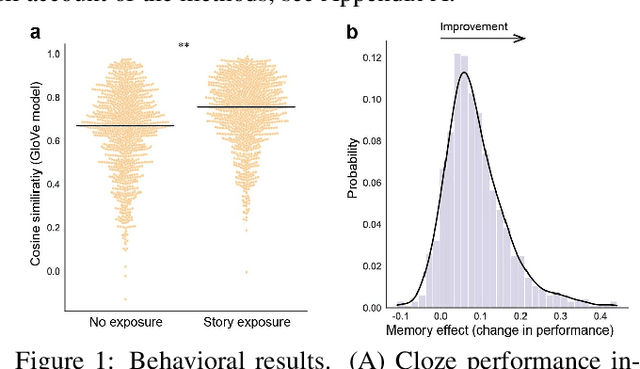
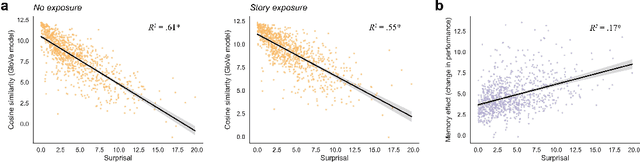
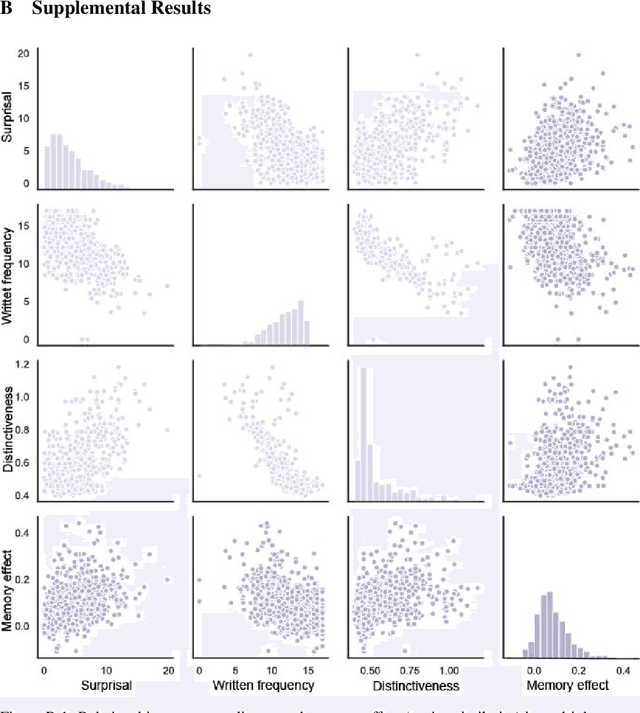
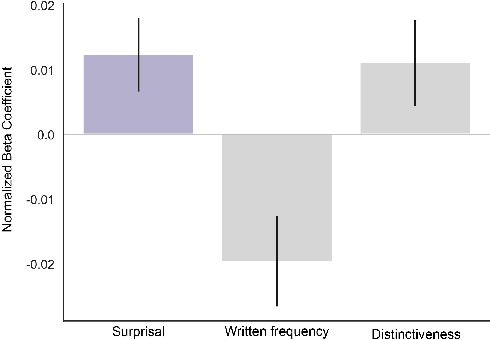
The computational complexity of the self-attention mechanism in Transformer models significantly limits their ability to generalize over long temporal durations. Memory-augmentation, or the explicit storing of past information in external memory for subsequent predictions, has become a constructive avenue for mitigating this limitation. We argue that memory-augmented Transformers can benefit substantially from considering insights from the memory literature in humans. We detail an approach to integrating evidence from the human memory system through the specification of cross-domain linking hypotheses. We then provide an empirical demonstration to evaluate the use of surprisal as a linking hypothesis, and further identify the limitations of this approach to inform future research.
Variational Causal Inference
Sep 13, 2022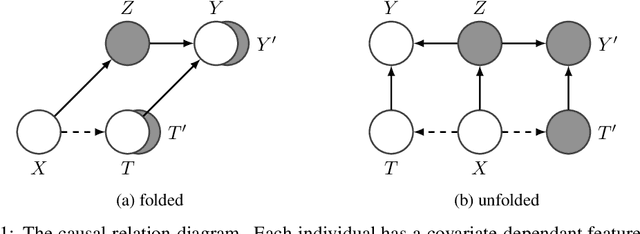
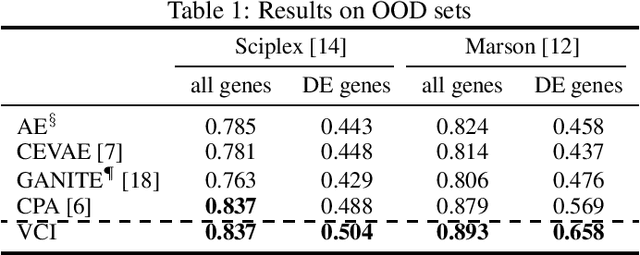
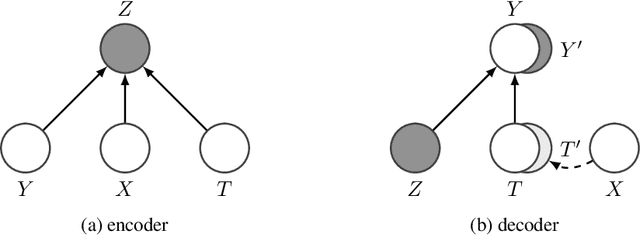
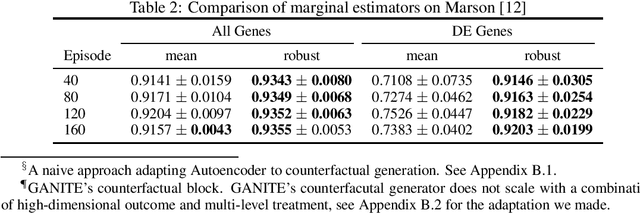
Estimating an individual's potential outcomes under counterfactual treatments is a challenging task for traditional causal inference and supervised learning approaches when the outcome is high-dimensional (e.g. gene expressions, impulse responses, human faces) and covariates are relatively limited. In this case, to construct one's outcome under a counterfactual treatment, it is crucial to leverage individual information contained in its observed factual outcome on top of the covariates. We propose a deep variational Bayesian framework that rigorously integrates two main sources of information for outcome construction under a counterfactual treatment: one source is the individual features embedded in the high-dimensional factual outcome; the other source is the response distribution of similar subjects (subjects with the same covariates) that factually received this treatment of interest.
Solving Reasoning Tasks with a Slot Transformer
Oct 20, 2022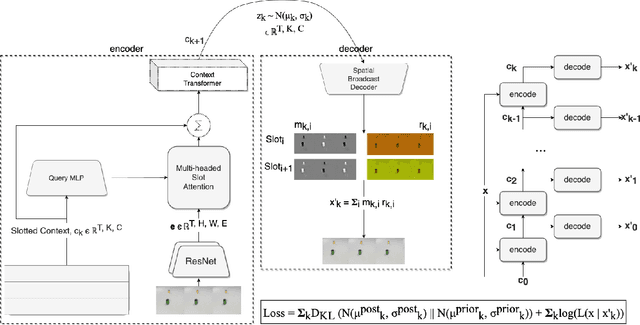
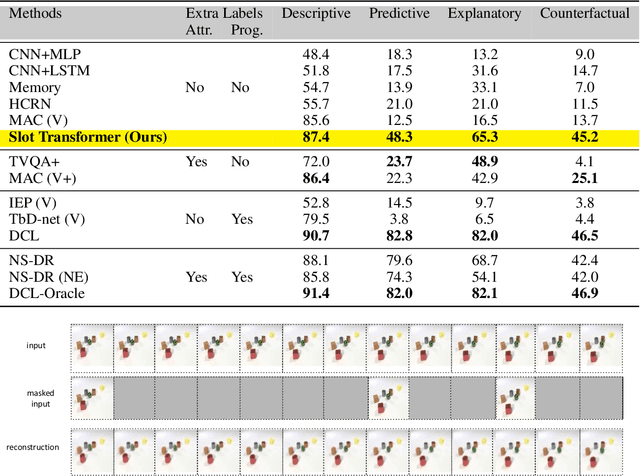
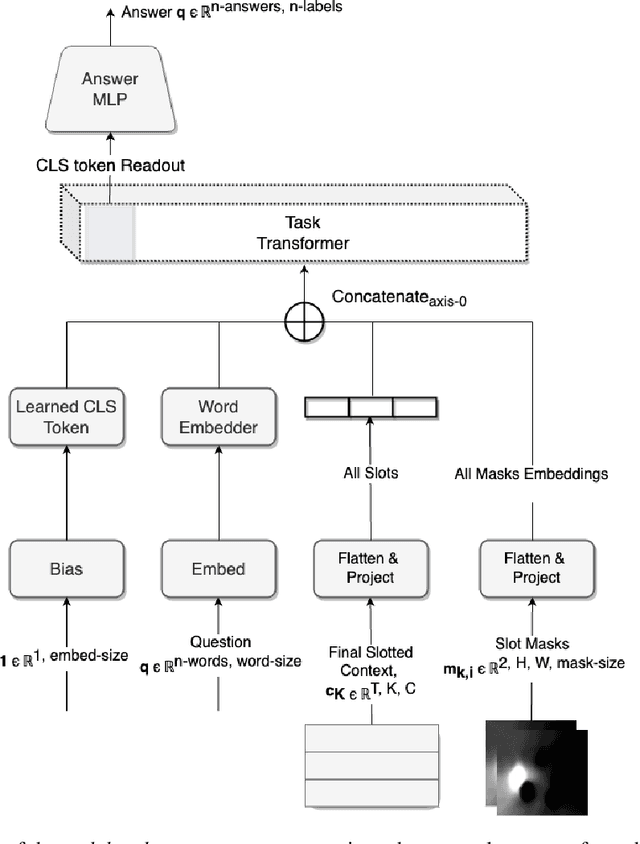
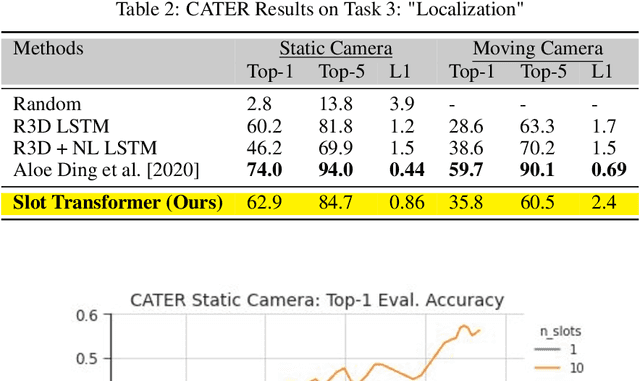
The ability to carve the world into useful abstractions in order to reason about time and space is a crucial component of intelligence. In order to successfully perceive and act effectively using senses we must parse and compress large amounts of information for further downstream reasoning to take place, allowing increasingly complex concepts to emerge. If there is any hope to scale representation learning methods to work with real world scenes and temporal dynamics then there must be a way to learn accurate, concise, and composable abstractions across time. We present the Slot Transformer, an architecture that leverages slot attention, transformers and iterative variational inference on video scene data to infer such representations. We evaluate the Slot Transformer on CLEVRER, Kinetics-600 and CATER datesets and demonstrate that the approach allows us to develop robust modeling and reasoning around complex behaviours as well as scores on these datasets that compare favourably to existing baselines. Finally we evaluate the effectiveness of key components of the architecture, the model's representational capacity and its ability to predict from incomplete input.