 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dynamic Global Memory for Document-level Argument Extraction
Sep 18, 2022
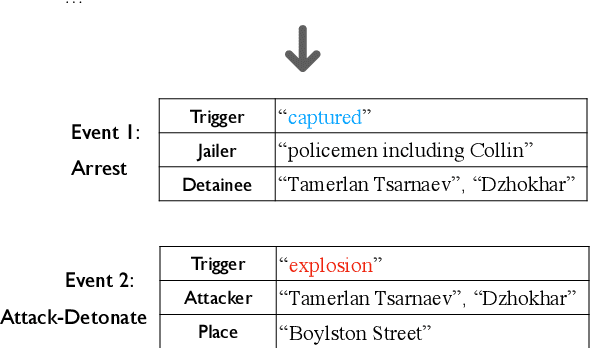
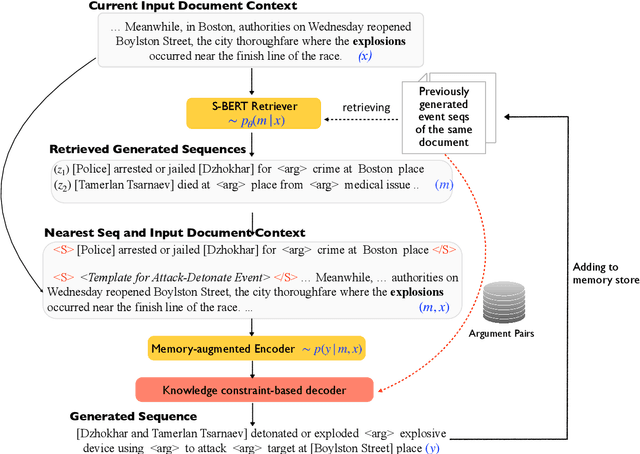
Extracting informative arguments of events from news articles is a challenging problem in information extraction, which requires a global contextual understanding of each document. While recent work on document-level extraction has gone beyond single-sentence and increased the cross-sentence inference capability of end-to-end models, they are still restricted by certain input sequence length constraints and usually ignore the global context between events. To tackle this issue, we introduce a new global neural generation-based framework for document-level event argument extraction by constructing a document memory store to record the contextual event information and leveraging it to implicitly and explicitly help with decoding of arguments for later events. Empirical results show that our framework outperforms prior methods substantially and it is more robust to adversarially annotated examples with our constrained decoding design. (Our code and resources are available at https://github.com/xinyadu/memory_docie for research purpose.)
Revisiting the Uniform Information Density Hypothesis
Sep 23, 2021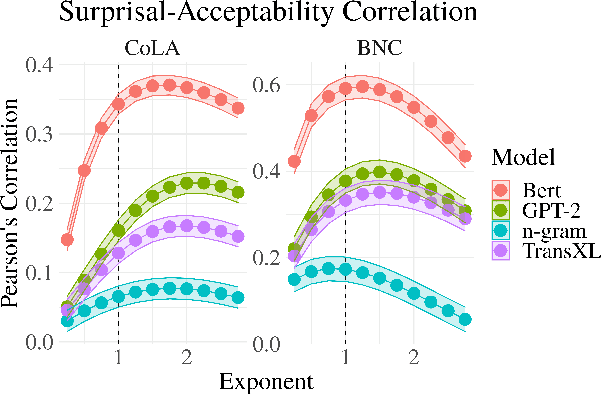
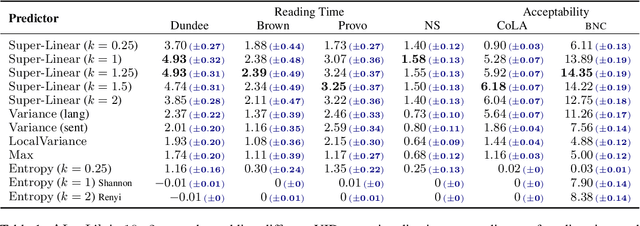
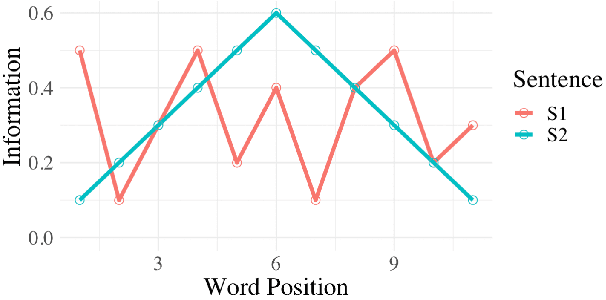
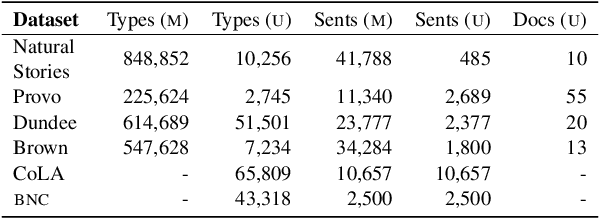
The uniform information density (UID) hypothesis posits a preference among language users for utterances structured such that information is distributed uniformly across a signal. While its implications on language production have been well explored, the hypothesis potentially makes predictions about language comprehension and linguistic acceptability as well. Further, it is unclear how uniformity in a linguistic signal -- or lack thereof -- should be measured, and over which linguistic unit, e.g., the sentence or language level, this uniformity should hold. Here we investigate these facets of the UID hypothesis using reading time and acceptability data. While our reading time results are generally consistent with previous work, they are also consistent with a weakly super-linear effect of surprisal, which would be compatible with UID's predictions. For acceptability judgments, we find clearer evidence that non-uniformity in information density is predictive of lower acceptability. We then explore multiple operationalizations of UID, motivated by different interpretations of the original hypothesis, and analyze the scope over which the pressure towards uniformity is exerted. The explanatory power of a subset of the proposed operationalizations suggests that the strongest trend may be a regression towards a mean surprisal across the language, rather than the phrase, sentence, or document -- a finding that supports a typical interpretation of UID, namely that it is the byproduct of language users maximizing the use of a (hypothetical) communication channel.
Reflectance-Guided, Contrast-Accumulated Histogram Equalization
Sep 14, 2022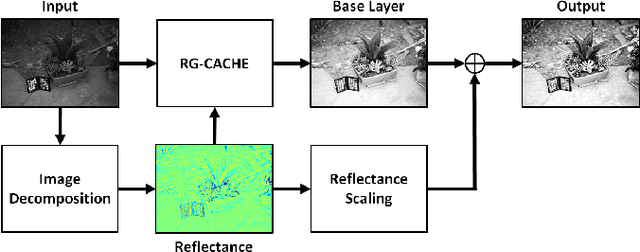
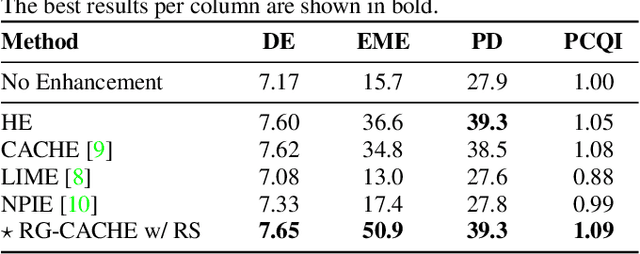


Existing image enhancement methods fall short of expectations because with them it is difficult to improve global and local image contrast simultaneously. To address this problem, we propose a histogram equalization-based method that adapts to the data-dependent requirements of brightness enhancement and improves the visibility of details without losing the global contrast. This method incorporates the spatial information provided by image context in density estimation for discriminative histogram equalization. To minimize the adverse effect of non-uniform illumination, we propose defining spatial information on the basis of image reflectance estimated with edge preserving smoothing. Our method works particularly well for determining how the background brightness should be adaptively adjusted and for revealing useful image details hidden in the dark.
MEDS-Net: Self-Distilled Multi-Encoders Network with Bi-Direction Maximum Intensity projections for Lung Nodule Detection
Oct 30, 2022
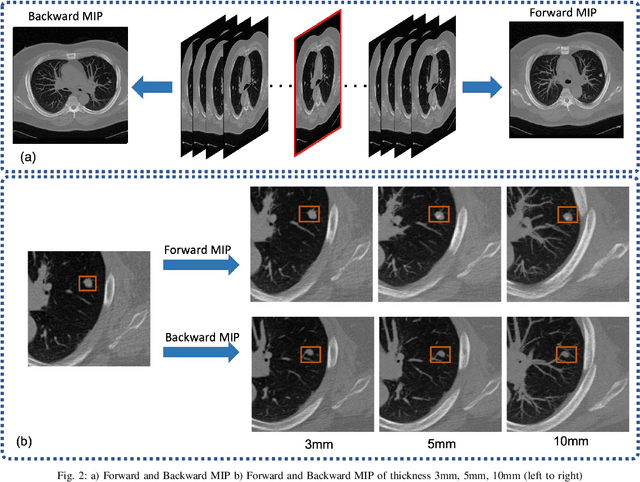
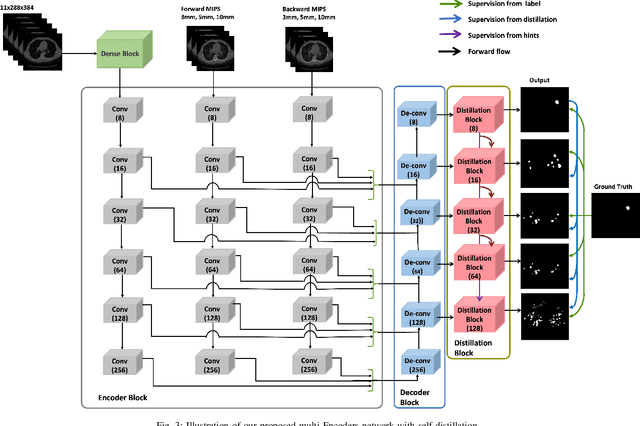
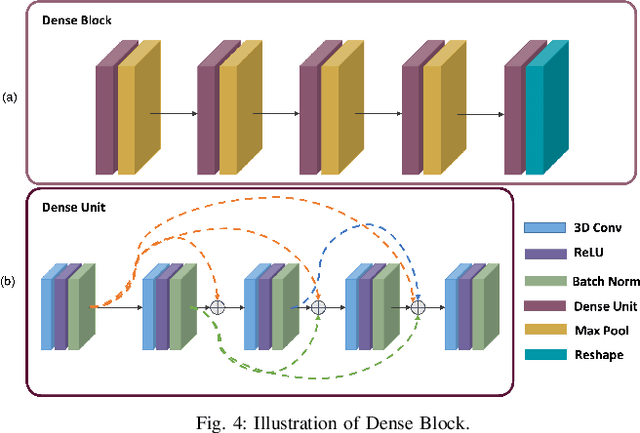
In this study, we propose a lung nodule detection scheme which fully incorporates the clinic workflow of radiologists. Particularly, we exploit Bi-Directional Maximum intensity projection (MIP) images of various thicknesses (i.e., 3, 5 and 10mm) along with a 3D patch of CT scan, consisting of 10 adjacent slices to feed into self-distillation-based Multi-Encoders Network (MEDS-Net). The proposed architecture first condenses 3D patch input to three channels by using a dense block which consists of dense units which effectively examine the nodule presence from 2D axial slices. This condensed information, along with the forward and backward MIP images, is fed to three different encoders to learn the most meaningful representation, which is forwarded into the decoded block at various levels. At the decoder block, we employ a self-distillation mechanism by connecting the distillation block, which contains five lung nodule detectors. It helps to expedite the convergence and improves the learning ability of the proposed architecture. Finally, the proposed scheme reduces the false positives by complementing the main detector with auxiliary detectors. The proposed scheme has been rigorously evaluated on 888 scans of LUNA16 dataset and obtained a CPM score of 93.6\%. The results demonstrate that incorporating of bi-direction MIP images enables MEDS-Net to effectively distinguish nodules from surroundings which help to achieve the sensitivity of 91.5% and 92.8% with false positives rate of 0.25 and 0.5 per scan, respectively.
Pose Attention-Guided Profile-to-Frontal Face Recognition
Sep 15, 2022
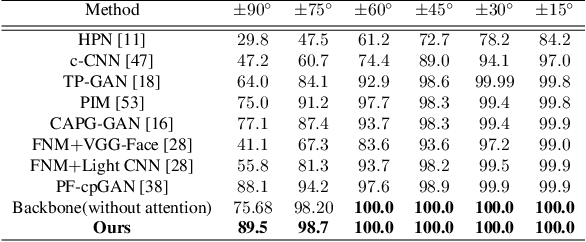
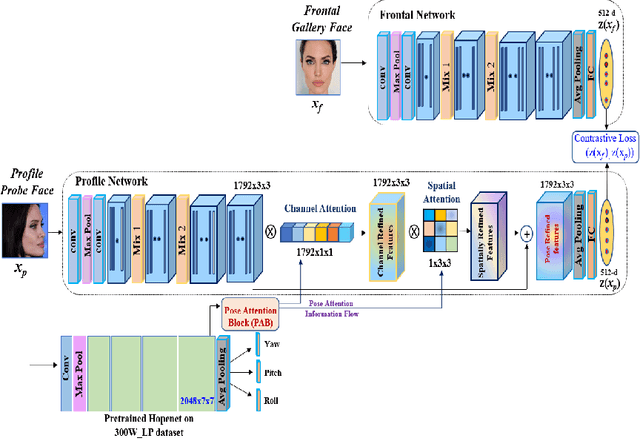
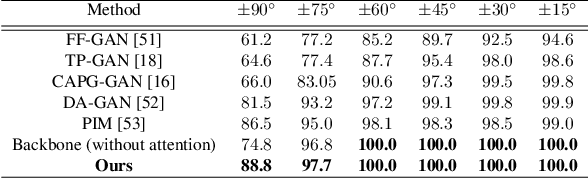
In recent years, face recognition systems have achieved exceptional success due to promising advances in deep learning architectures. However, they still fail to achieve expected accuracy when matching profile images against a gallery of frontal images. Current approaches either perform pose normalization (i.e., frontalization) or disentangle pose information for face recognition. We instead propose a new approach to utilize pose as an auxiliary information via an attention mechanism. In this paper, we hypothesize that pose attended information using an attention mechanism can guide contextual and distinctive feature extraction from profile faces, which further benefits a better representation learning in an embedded domain. To achieve this, first, we design a unified coupled profile-to-frontal face recognition network. It learns the mapping from faces to a compact embedding subspace via a class-specific contrastive loss. Second, we develop a novel pose attention block (PAB) to specially guide the pose-agnostic feature extraction from profile faces. To be more specific, PAB is designed to explicitly help the network to focus on important features along both channel and spatial dimension while learning discriminative yet pose invariant features in an embedding subspace. To validate the effectiveness of our proposed method, we conduct experiments on both controlled and in the wild benchmarks including Multi-PIE, CFP, IJBC, and show superiority over the state of the arts.
An event detection technique using social media data
Aug 27, 2022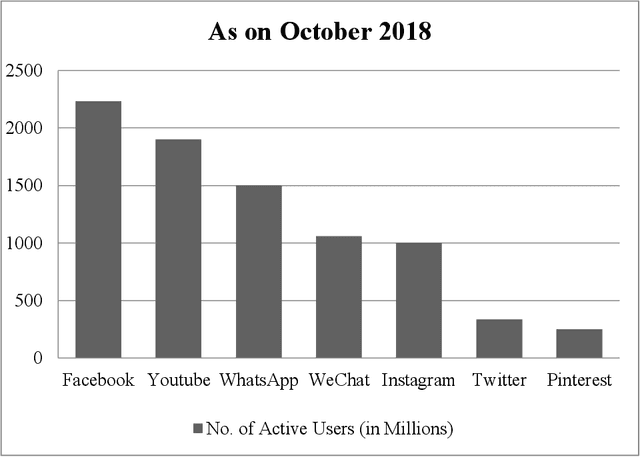
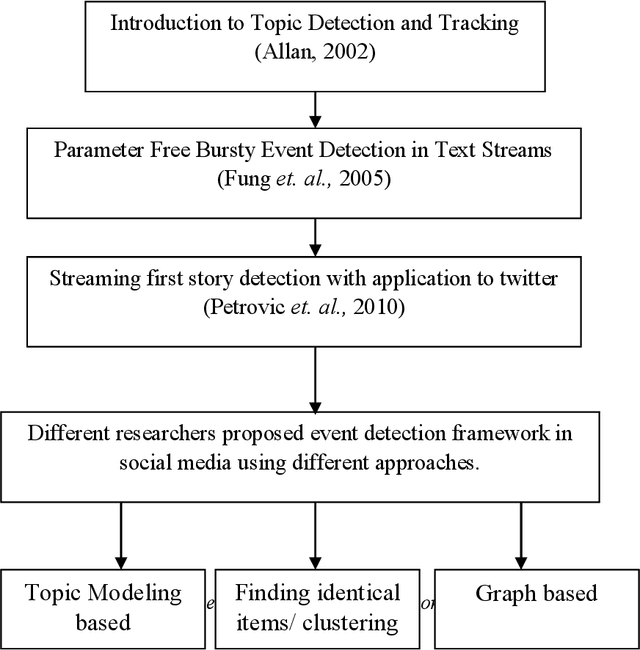
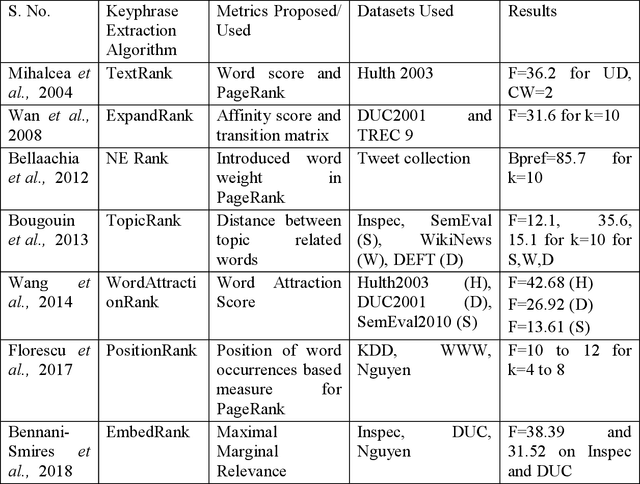
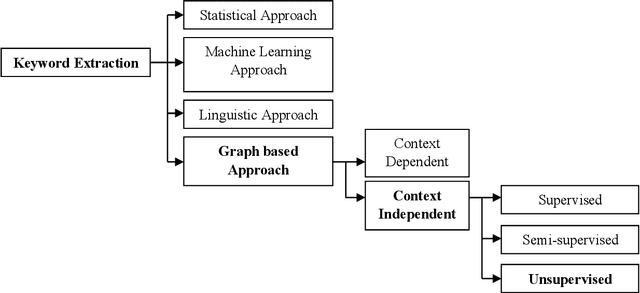
People post information about different topics which are in their active vocabulary over social media platforms (like Twitter, Facebook, PInterest and Google+). They follow each other and it is more likely that the person who posts information about current happenings will receive better response. Manual analysis of huge amount of data on social media platforms is difficult. This has opened new research directions for automatic analysis of usercontributed social media documents. Automatic social media data analysis is difficult due to abundant information shared by users. Many researchers use Twitter data for Social Media Analysis (SMA) as the Twitter data is freely available in the public domain. One of the most this research work. Event Detection from social media data is used for different applications like traffic congestion detection, disaster and emergency management, and live news detection. Nature of the information which is shared on twitter platform is short-text, noisy, and ambiguous. Thus, event detection and extraction of event phrases from user-generated and illformed data becomes challenging. To address these challenges, events are extracted from streaming social media data in the form of keyphrases using different cognitive properties. The motivation behind this research work is to provide substantial improvements in the lexical variation of event phrases while detecting events and sub-events from twitter data. In this research work, the approach towards event detection from social media data is divided into three phases namely: Identifying sub-graphs in Microblog Word Co-occurrence Network (WCN) which provides important information about keyphrases; Identifying multiple events from social media data; and Ranking contextual information of event phrases.
Pseudo-LiDAR for Visual Odometry
Sep 04, 2022
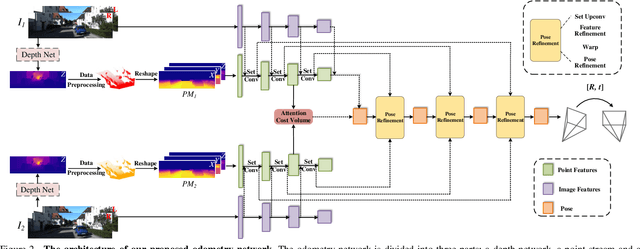
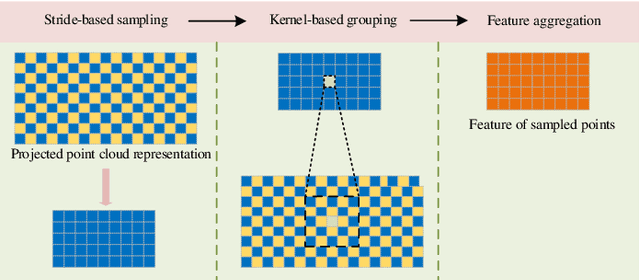
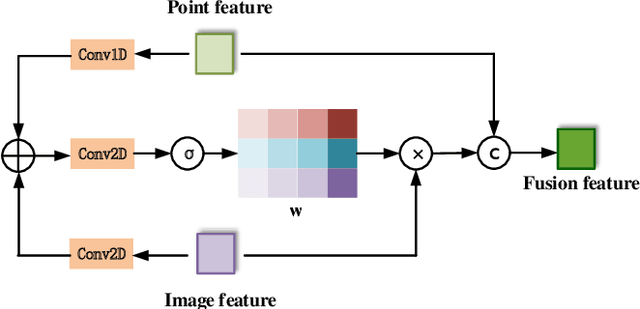
In the existing methods, LiDAR odometry shows superior performance, but visual odometry is still widely used for its price advantage. Conventionally, the task of visual odometry mainly rely on the input of continuous images. However, it is very complicated for the odometry network to learn the epipolar geometry information provided by the images. In this paper, the concept of pseudo-LiDAR is introduced into the odometry to solve this problem. The pseudo-LiDAR point cloud back-projects the depth map generated by the image into the 3D point cloud, which changes the way of image representation. Compared with the stereo images, the pseudo-LiDAR point cloud generated by the stereo matching network can get the explicit 3D coordinates. Since the 6 Degrees of Freedom (DoF) pose transformation occurs in 3D space, the 3D structure information provided by the pseudo-LiDAR point cloud is more direct than the image. Compared with sparse LiDAR, the pseudo-LiDAR has a denser point cloud. In order to make full use of the rich point cloud information provided by the pseudo-LiDAR, a projection-aware dense odometry pipeline is adopted. Most previous LiDAR-based algorithms sampled 8192 points from the point cloud as input to the odometry network. The projection-aware dense odometry pipeline takes all the pseudo-LiDAR point clouds generated from the images except for the error points as the input to the network. While making full use of the 3D geometric information in the images, the semantic information in the images is also used in the odometry task. The fusion of 2D-3D is achieved in an image-only based odometry. Experiments on the KITTI dataset prove the effectiveness of our method. To the best of our knowledge, this is the first visual odometry method using pseudo-LiDAR.
$β$-Stochastic Sign SGD: A Byzantine Resilient and Differentially Private Gradient Compressor for Federated Learning
Oct 03, 2022

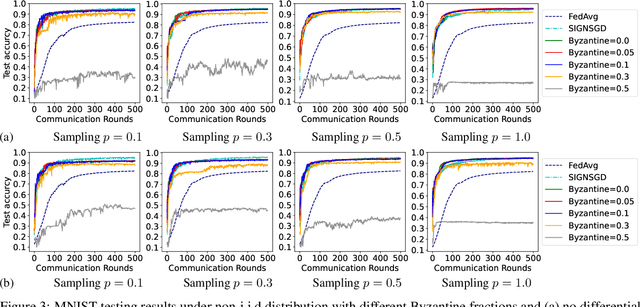
Federated Learning (FL) is a nascent privacy-preserving learning framework under which the local data of participating clients is kept locally throughout model training. Scarce communication resources and data heterogeneity are two defining characteristics of FL. Besides, a FL system is often implemented in a harsh environment -- leaving the clients vulnerable to Byzantine attacks. To the best of our knowledge, no gradient compressors simultaneously achieve quantitative Byzantine resilience and privacy preservation. In this paper, we fill this gap via revisiting the stochastic sign SGD \cite{jin 2020}. We propose $\beta$-stochastic sign SGD, which contains a gradient compressor that encodes a client's gradient information in sign bits subject to the privacy budget $\beta>0$. We show that as long as $\beta>0$, $\beta$-stochastic sign SGD converges in the presence of partial client participation and mobile Byzantine faults, showing that it achieves quantifiable Byzantine-resilience and differential privacy simultaneously. In sharp contrast, when $\beta=0$, the compressor is not differentially private. Notably, for the special case when each of the stochastic gradients involved is bounded with known bounds, our gradient compressor with $\beta=0$ coincides with the compressor proposed in \cite{jin 2020}. As a byproduct, we show that when the clients report sign messages, the popular information aggregation rules simple mean, trimmed mean, median and majority vote are identical in terms of the output signs. Our theories are corroborated by experiments on MNIST and CIFAR-10 datasets.
Human Biometric Signals Monitoring based on WiFi Channel State Information using Deep Learning
Mar 08, 2022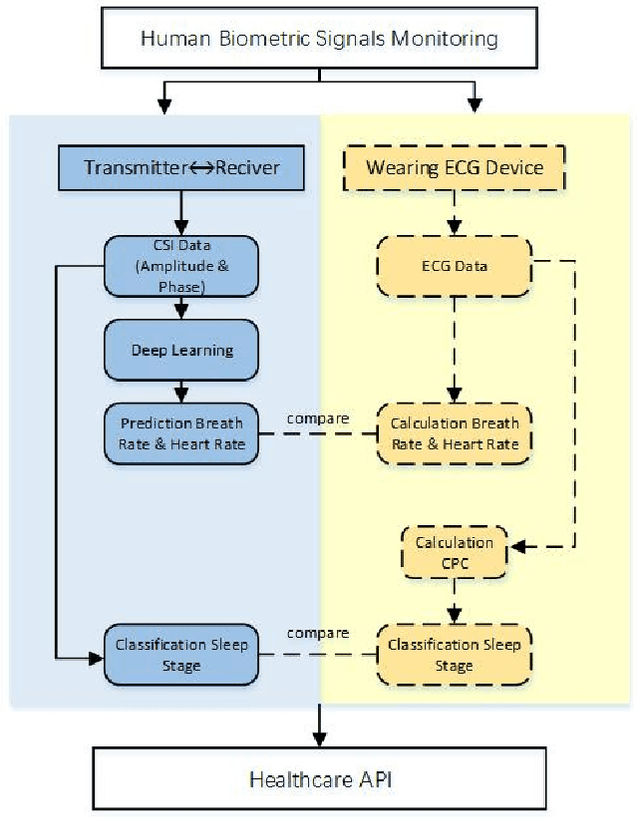
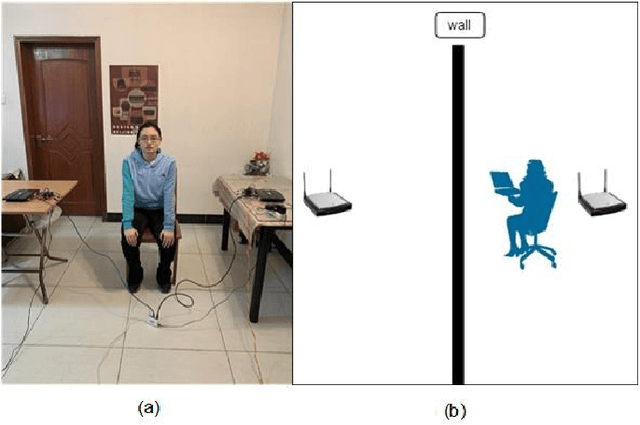
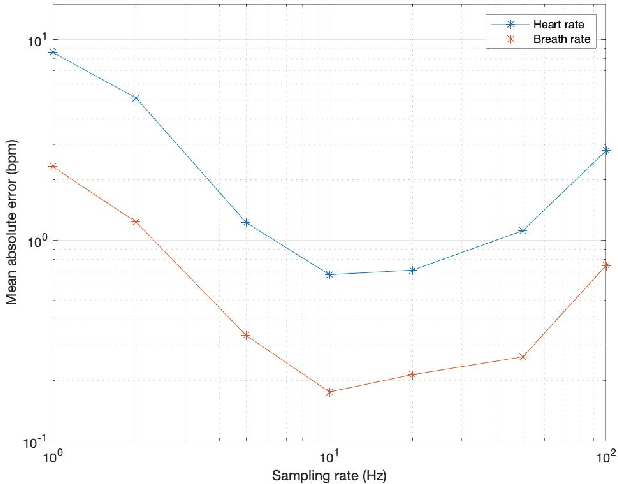
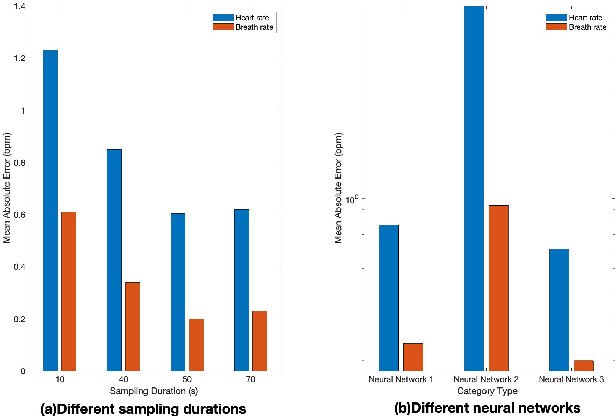
In this paper, we first present a single-input, multiple-output convolutional neural network that can estimate both heart rate and respiration rate simultaneously by exploiting the underlying link between heart rate and respiration rate. The inputs to the neural network are the amplitude and phase of channel state information collected by a pair of WiFi devices. Our WiFi-based technique addresses privacy concerns and is adapt- able to a variety of settings. This system overall accuracy for the heart and respiration rate estimation can reach 99.109% and 98.581%, respectively. Furthermore, we developed and analyzed two deep learning-based neural network classification algorithms for categorizing four types of sleep stages: wake, rapid eye movement (REM) sleep, non-rapid eye movement (NREM) light sleep, and NREM deep sleep. This system overall classification accuracy can reach 95.925%
Null Hypothesis Test for Anomaly Detection
Oct 11, 2022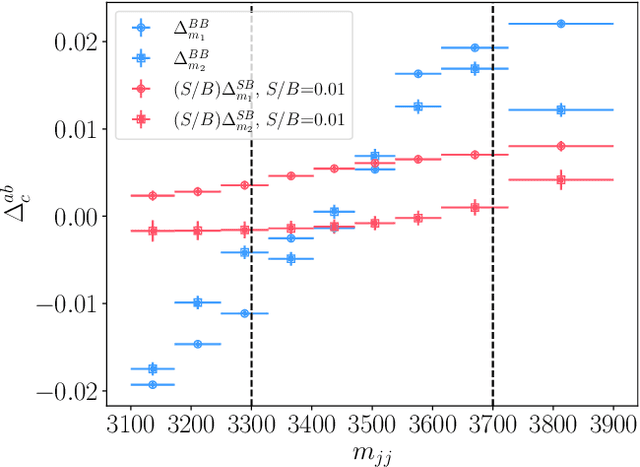
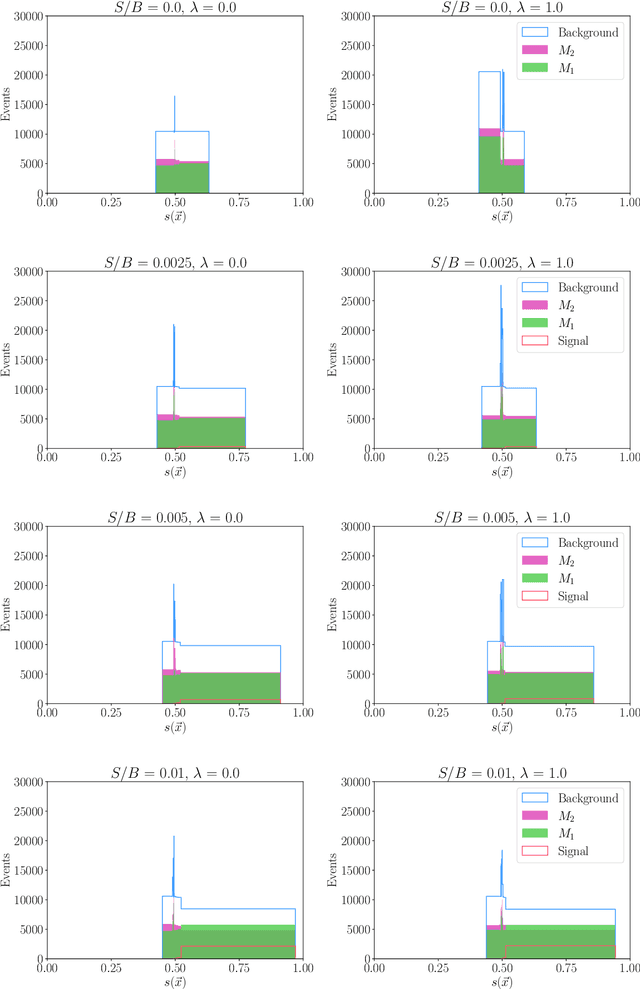
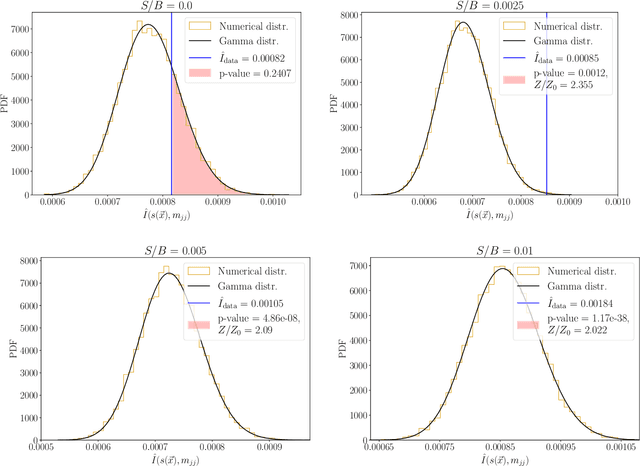
We extend the use of Classification Without Labels for anomaly detection with a hypothesis test designed to exclude the background-only hypothesis. By testing for statistical independence of the two discriminating dataset regions, we are able exclude the background-only hypothesis without relying on fixed anomaly score cuts or extrapolations of background estimates between regions. The method relies on the assumption of conditional independence of anomaly score features and dataset regions, which can be ensured using existing decorrelation techniques. As a benchmark example, we consider the LHC Olympics dataset where we show that mutual information represents a suitable test for statistical independence and our method exhibits excellent and robust performance at different signal fractions even in presence of realistic feature correlations.