 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Generalized Decision Transformer for Offline Hindsight Information Matching
Nov 23, 2021
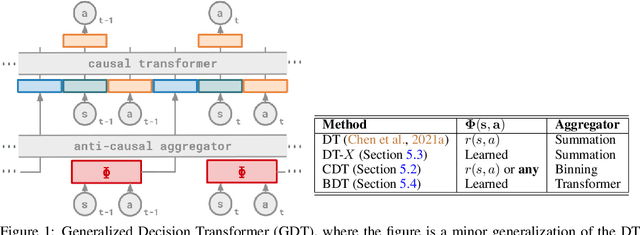
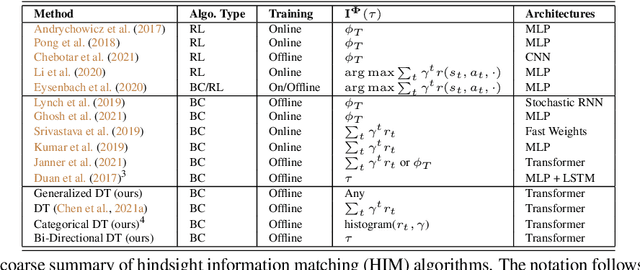

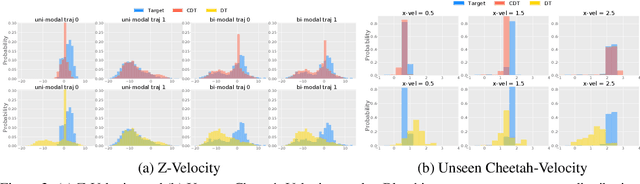
How to extract as much learning signal from each trajectory data has been a key problem in reinforcement learning (RL), where sample inefficiency has posed serious challenges for practical applications. Recent works have shown that using expressive policy function approximators and conditioning on future trajectory information -- such as future states in hindsight experience replay or returns-to-go in Decision Transformer (DT) -- enables efficient learning of multi-task policies, where at times online RL is fully replaced by offline behavioral cloning, e.g. sequence modeling. We demonstrate that all these approaches are doing hindsight information matching (HIM) -- training policies that can output the rest of trajectory that matches some statistics of future state information. We present Generalized Decision Transformer (GDT) for solving any HIM problem, and show how different choices for the feature function and the anti-causal aggregator not only recover DT as a special case, but also lead to novel Categorical DT (CDT) and Bi-directional DT (BDT) for matching different statistics of the future. For evaluating CDT and BDT, we define offline multi-task state-marginal matching (SMM) and imitation learning (IL) as two generic HIM problems, propose a Wasserstein distance loss as a metric for both, and empirically study them on MuJoCo continuous control benchmarks. CDT, which simply replaces anti-causal summation with anti-causal binning in DT, enables the first effective offline multi-task SMM algorithm that generalizes well to unseen and even synthetic multi-modal state-feature distributions. BDT, which uses an anti-causal second transformer as the aggregator, can learn to model any statistics of the future and outperforms DT variants in offline multi-task IL. Our generalized formulations from HIM and GDT greatly expand the role of powerful sequence modeling architectures in modern RL.
Improving Text-to-SQL Semantic Parsing with Fine-grained Query Understanding
Sep 28, 2022

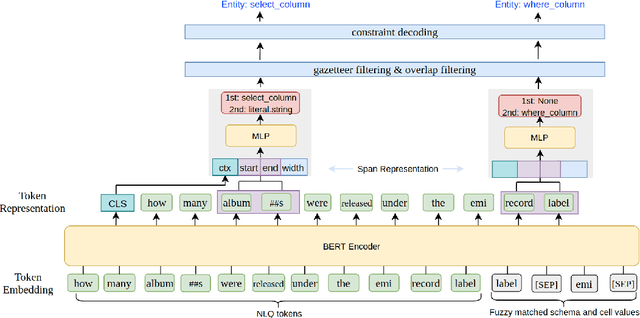
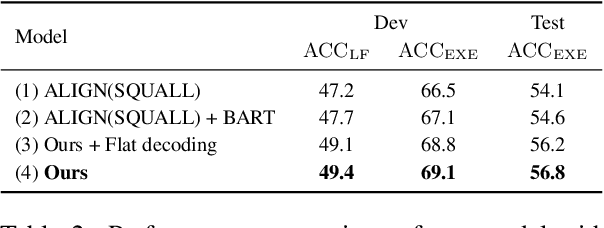
Most recent research on Text-to-SQL semantic parsing relies on either parser itself or simple heuristic based approach to understand natural language query (NLQ). When synthesizing a SQL query, there is no explicit semantic information of NLQ available to the parser which leads to undesirable generalization performance. In addition, without lexical-level fine-grained query understanding, linking between query and database can only rely on fuzzy string match which leads to suboptimal performance in real applications. In view of this, in this paper we present a general-purpose, modular neural semantic parsing framework that is based on token-level fine-grained query understanding. Our framework consists of three modules: named entity recognizer (NER), neural entity linker (NEL) and neural semantic parser (NSP). By jointly modeling query and database, NER model analyzes user intents and identifies entities in the query. NEL model links typed entities to schema and cell values in database. Parser model leverages available semantic information and linking results and synthesizes tree-structured SQL queries based on dynamically generated grammar. Experiments on SQUALL, a newly released semantic parsing dataset, show that we can achieve 56.8% execution accuracy on WikiTableQuestions (WTQ) test set, which outperforms the state-of-the-art model by 2.7%.
Faith: An Efficient Framework for Transformer Verification on GPUs
Sep 23, 2022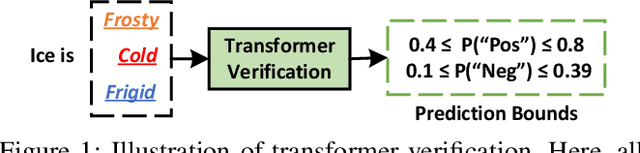

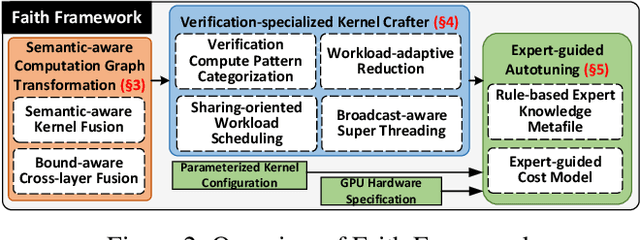
Transformer verification draws increasing attention in machine learning research and industry. It formally verifies the robustness of transformers against adversarial attacks such as exchanging words in a sentence with synonyms. However, the performance of transformer verification is still not satisfactory due to bound-centric computation which is significantly different from standard neural networks. In this paper, we propose Faith, an efficient framework for transformer verification on GPUs. We first propose a semantic-aware computation graph transformation to identify semantic information such as bound computation in transformer verification. We exploit such semantic information to enable efficient kernel fusion at the computation graph level. Second, we propose a verification-specialized kernel crafter to efficiently map transformer verification to modern GPUs. This crafter exploits a set of GPU hardware supports to accelerate verification specialized operations which are usually memory-intensive. Third, we propose an expert-guided autotuning to incorporate expert knowledge on GPU backends to facilitate large search space exploration. Extensive evaluations show that Faith achieves $2.1\times$ to $3.4\times$ ($2.6\times$ on average) speedup over state-of-the-art frameworks.
Preserving Domain Private Representation via Mutual Information Maximization
Jan 09, 2022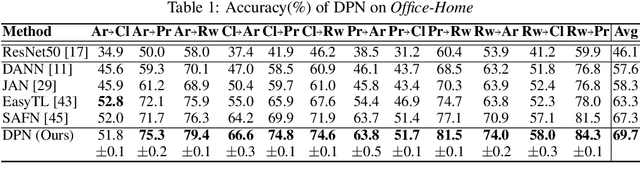
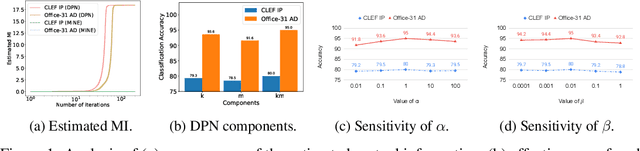
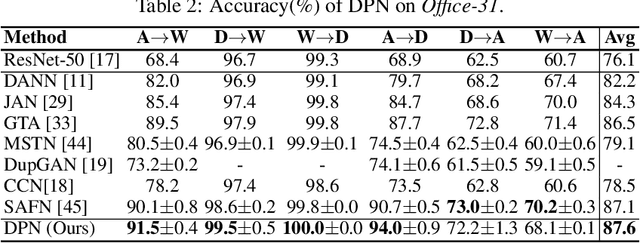
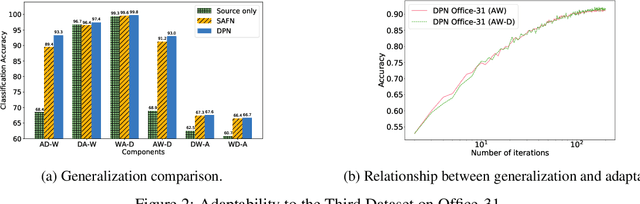
Recent advances in unsupervised domain adaptation have shown that mitigating the domain divergence by extracting the domain-invariant representation could significantly improve the generalization of a model to an unlabeled data domain. Nevertheless, the existing methods fail to effectively preserve the representation that is private to the label-missing domain, which could adversely affect the generalization. In this paper, we propose an approach to preserve such representation so that the latent distribution of the unlabeled domain could represent both the domain-invariant features and the individual characteristics that are private to the unlabeled domain. In particular, we demonstrate that maximizing the mutual information between the unlabeled domain and its latent space while mitigating the domain divergence can achieve such preservation. We also theoretically and empirically validate that preserving the representation that is private to the unlabeled domain is important and of necessity for the cross-domain generalization. Our approach outperforms state-of-the-art methods on several public datasets.
Graph Neural Networks for Molecules
Sep 12, 2022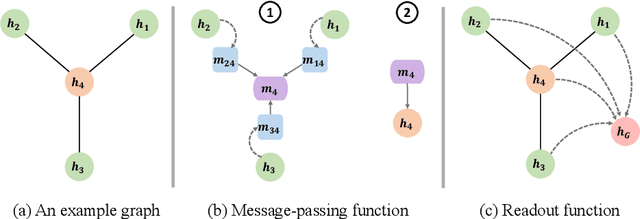
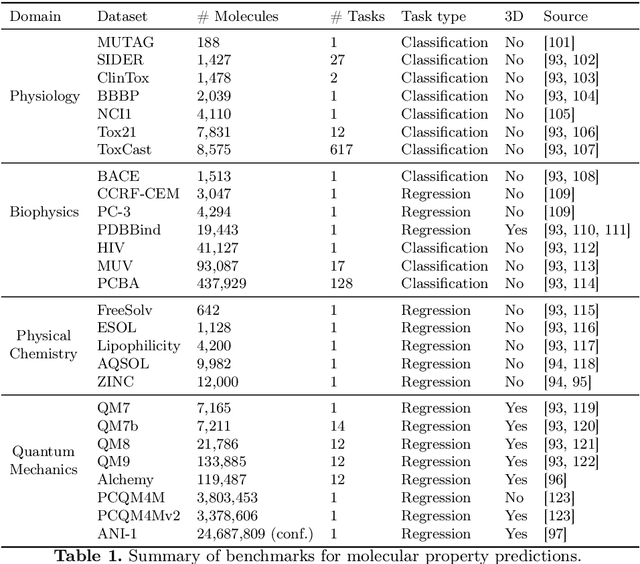
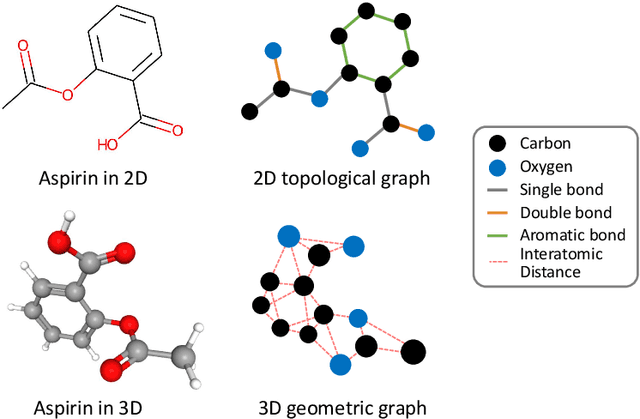
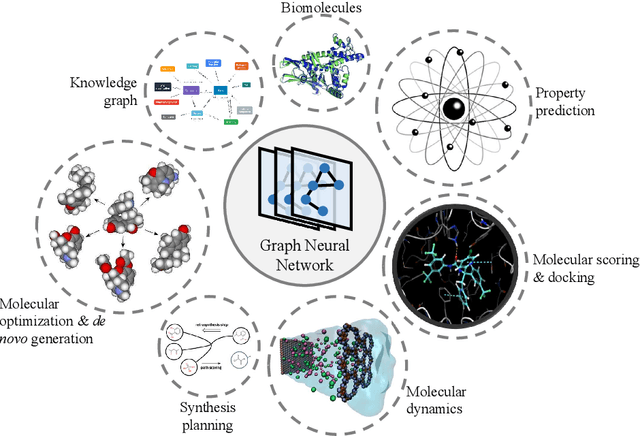
Graph neural networks (GNNs), which are capable of learning representations from graphical data, are naturally suitable for modeling molecular systems. This review introduces GNNs and their various applications for small organic molecules. GNNs rely on message-passing operations, a generic yet powerful framework, to update node features iteratively. Many researches design GNN architectures to effectively learn topological information of 2D molecule graphs as well as geometric information of 3D molecular systems. GNNs have been implemented in a wide variety of molecular applications, including molecular property prediction, molecular scoring and docking, molecular optimization and de novo generation, molecular dynamics simulation, etc. Besides, the review also summarizes the recent development of self-supervised learning for molecules with GNNs.
Open-vocabulary Queryable Scene Representations for Real World Planning
Sep 20, 2022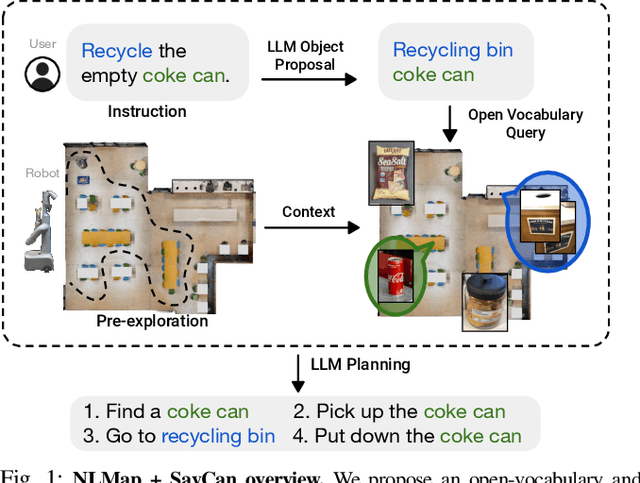
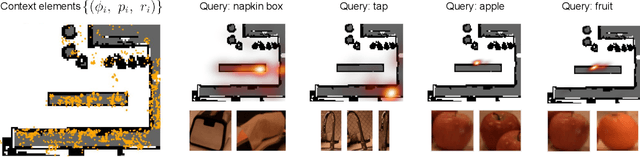
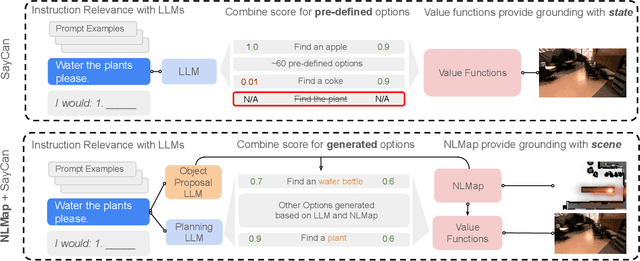
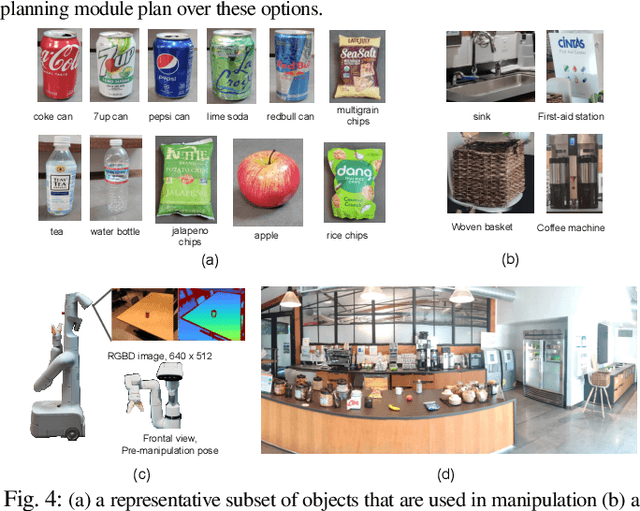
Large language models (LLMs) have unlocked new capabilities of task planning from human instructions. However, prior attempts to apply LLMs to real-world robotic tasks are limited by the lack of grounding in the surrounding scene. In this paper, we develop NLMap, an open-vocabulary and queryable scene representation to address this problem. NLMap serves as a framework to gather and integrate contextual information into LLM planners, allowing them to see and query available objects in the scene before generating a context-conditioned plan. NLMap first establishes a natural language queryable scene representation with Visual Language models (VLMs). An LLM based object proposal module parses instructions and proposes involved objects to query the scene representation for object availability and location. An LLM planner then plans with such information about the scene. NLMap allows robots to operate without a fixed list of objects nor executable options, enabling real robot operation unachievable by previous methods. Project website: https://nlmap-saycan.github.io
Fast Yet Effective Speech Emotion Recognition with Self-distillation
Oct 26, 2022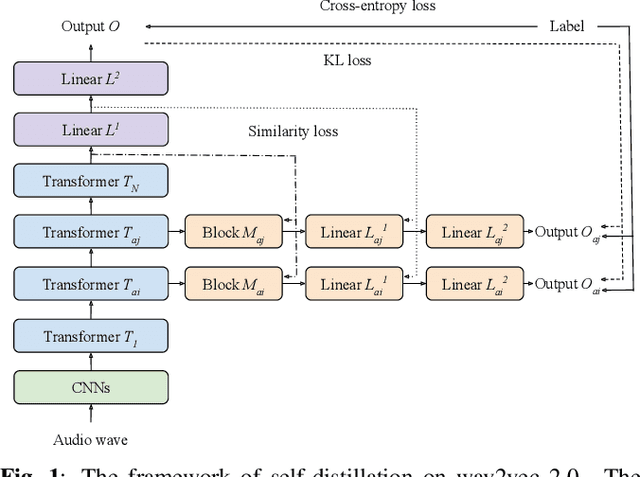
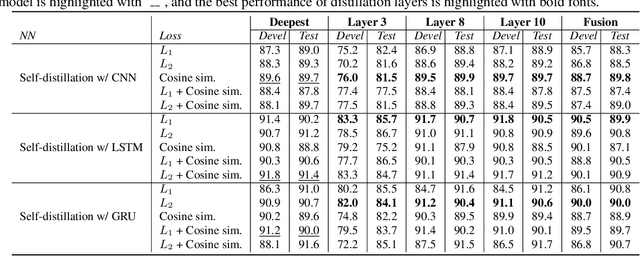
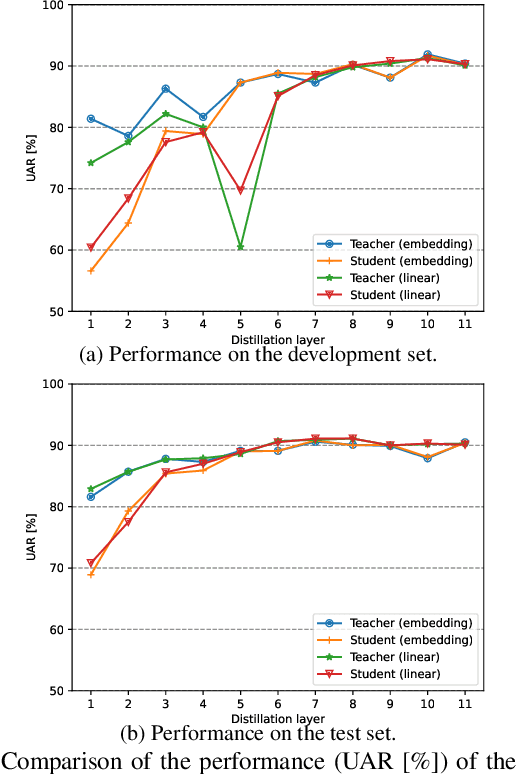
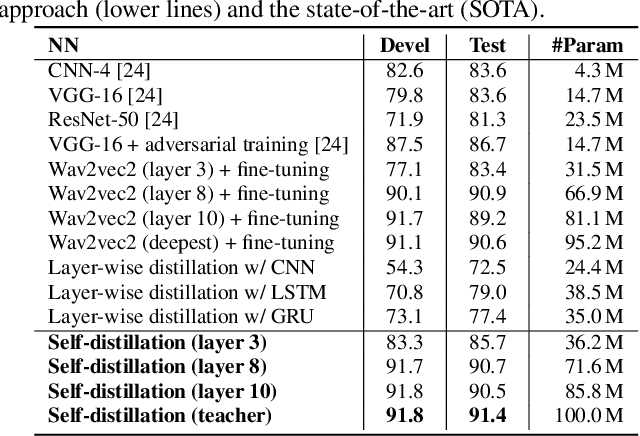
Speech emotion recognition (SER) is the task of recognising human's emotional states from speech. SER is extremely prevalent in helping dialogue systems to truly understand our emotions and become a trustworthy human conversational partner. Due to the lengthy nature of speech, SER also suffers from the lack of abundant labelled data for powerful models like deep neural networks. Pre-trained complex models on large-scale speech datasets have been successfully applied to SER via transfer learning. However, fine-tuning complex models still requires large memory space and results in low inference efficiency. In this paper, we argue achieving a fast yet effective SER is possible with self-distillation, a method of simultaneously fine-tuning a pretrained model and training shallower versions of itself. The benefits of our self-distillation framework are threefold: (1) the adoption of self-distillation method upon the acoustic modality breaks through the limited ground-truth of speech data, and outperforms the existing models' performance on an SER dataset; (2) executing powerful models at different depth can achieve adaptive accuracy-efficiency trade-offs on resource-limited edge devices; (3) a new fine-tuning process rather than training from scratch for self-distillation leads to faster learning time and the state-of-the-art accuracy on data with small quantities of label information.
Optimising Different Feature Types for Inpainting-based Image Representations
Oct 26, 2022


Inpainting-based image compression is a promising alternative to classical transform-based lossy codecs. Typically it stores a carefully selected subset of all pixel locations and their colour values. In the decoding phase the missing information is reconstructed by an inpainting process such as homogeneous diffusion inpainting. Optimising the stored data is the key for achieving good performance. A few heuristic approaches also advocate alternative feature types such as derivative data and construct dedicated inpainting concepts. However, one still lacks a general approach that allows to optimise and inpaint the data simultaneously w.r.t. a collection of different feature types, their locations, and their values. Our paper closes this gap. We introduce a generalised inpainting process that can handle arbitrary features which can be expressed as linear equality constraints. This includes e.g. colour values and derivatives of any order. We propose a fully automatic algorithm that aims at finding the optimal features from a given collection as well as their locations and their function values within a specified total feature density. Its performance is demonstrated with a novel set of features that also includes local averages. Our experiments show that it clearly outperforms the popular inpainting with optimised colour data with the same density.
Multi-Environment based Meta-Learning with CSI Fingerprints for Radio Based Positioning
Oct 26, 2022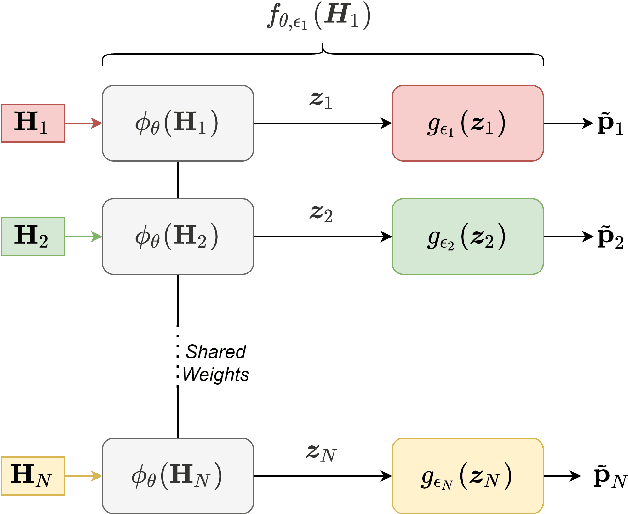
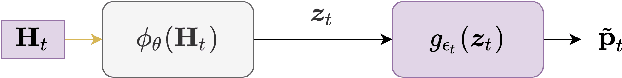
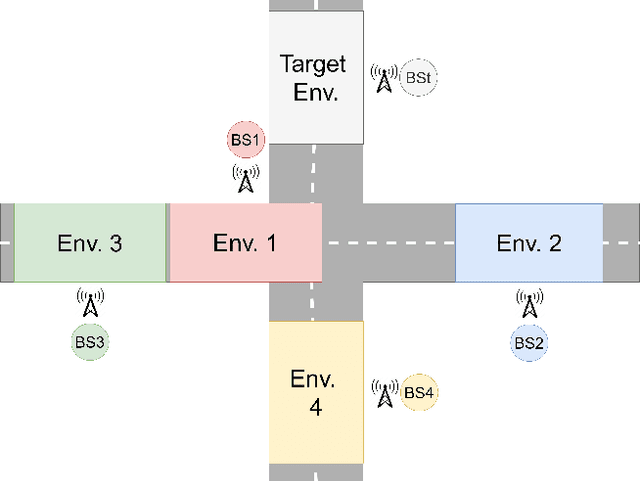
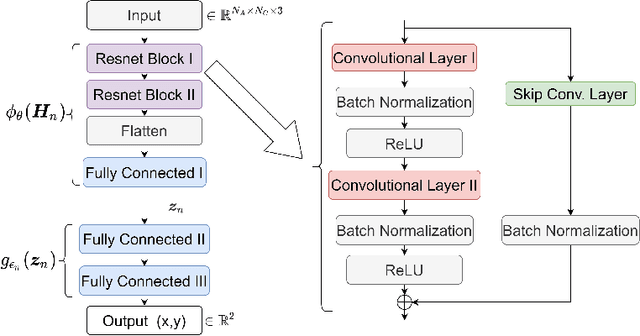
Radio based positioning of a user equipment (UE) based on deep learning (DL) methods using channel state information (CSI) fingerprints have shown promising results. DL models are able to capture complex properties embedded in the CSI about a particular environment and map UE's CSI to the UE's position. However, the CSI fingerprints and the DL models trained on such fingerprints are highly dependent on a particular propagation environment, which generally limits the transfer of knowledge of the DL models from one environment to another. In this paper, we propose a DL model consisting of two parts: the first part aims to learn environment independent features while the second part combines those features depending on the particular environment. To improve transfer learning, we propose a meta learning scheme for training the first part over multiple environments. We show that for positioning in a new environment, initializing a DL model with the meta learned environment independent function achieves higher UE positioning accuracy compared to regular transfer learning from one environment to the new environment, or compared to training the DL model from scratch with only fingerprints from the new environment. Our proposed scheme is able to create an environment independent function which can embed knowledge from multiple environments and more effectively learn from a new environment.
Long-tailed Food Classification
Oct 26, 2022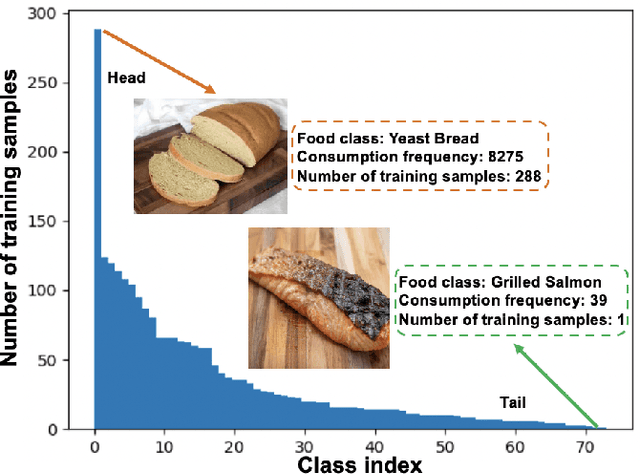
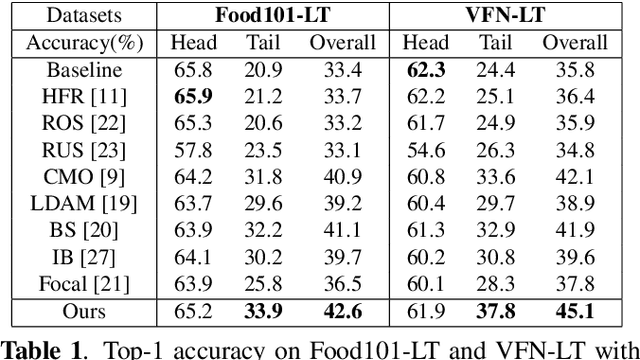
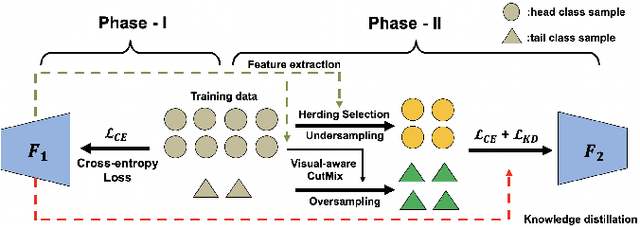
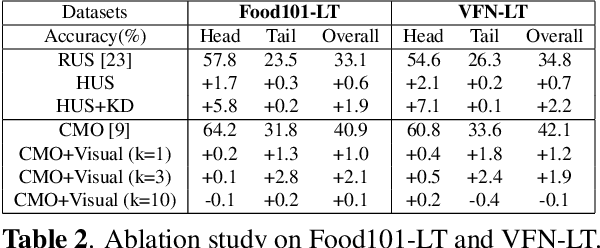
Food classification serves as the basic step of image-based dietary assessment to predict the types of foods in each input image. However, food image predictions in a real world scenario are usually long-tail distributed among different food classes, which cause heavy class-imbalance problems and a restricted performance. In addition, none of the existing long-tailed classification methods focus on food data, which can be more challenging due to the lower inter-class and higher intra-class similarity among foods. In this work, we first introduce two new benchmark datasets for long-tailed food classification including Food101-LT and VFN-LT where the number of samples in VFN-LT exhibits the real world long-tailed food distribution. Then we propose a novel 2-Phase framework to address the problem of class-imbalance by (1) undersampling the head classes to remove redundant samples along with maintaining the learned information through knowledge distillation, and (2) oversampling the tail classes by performing visual-aware data augmentation. We show the effectiveness of our method by comparing with existing state-of-the-art long-tailed classification methods and show improved performance on both Food101-LT and VFN-LT benchmarks. The results demonstrate the potential to apply our method to related real life applications.