 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Question-Interlocutor Scope Realized Graph Modeling over Key Utterances for Dialogue Reading Comprehension
Oct 26, 2022
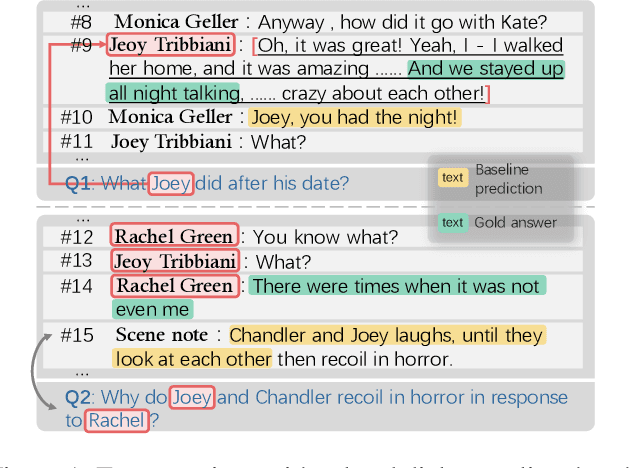
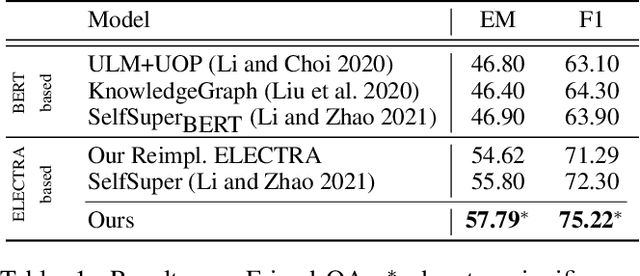
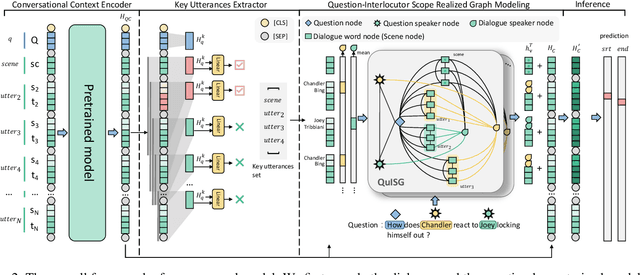
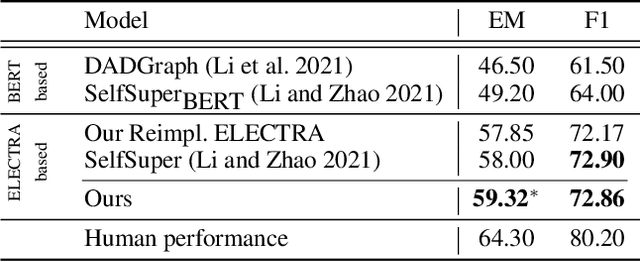
In this work, we focus on dialogue reading comprehension (DRC), a task extracting answer spans for questions from dialogues. Dialogue context modeling in DRC is tricky due to complex speaker information and noisy dialogue context. To solve the two problems, previous research proposes two self-supervised tasks respectively: guessing who a randomly masked speaker is according to the dialogue and predicting which utterance in the dialogue contains the answer. Although these tasks are effective, there are still urging problems: (1) randomly masking speakers regardless of the question cannot map the speaker mentioned in the question to the corresponding speaker in the dialogue, and ignores the speaker-centric nature of utterances. This leads to wrong answer extraction from utterances in unrelated interlocutors' scopes; (2) the single utterance prediction, preferring utterances similar to the question, is limited in finding answer-contained utterances not similar to the question. To alleviate these problems, we first propose a new key utterances extracting method. It performs prediction on the unit formed by several contiguous utterances, which can realize more answer-contained utterances. Based on utterances in the extracted units, we then propose Question-Interlocutor Scope Realized Graph (QuISG) modeling. As a graph constructed on the text of utterances, QuISG additionally involves the question and question-mentioning speaker names as nodes. To realize interlocutor scopes, speakers in the dialogue are connected with the words in their corresponding utterances. Experiments on the benchmarks show that our method can achieve better and competitive results against previous works.
Learning a Task-specific Descriptor for Robust Matching of 3D Point Clouds
Oct 26, 2022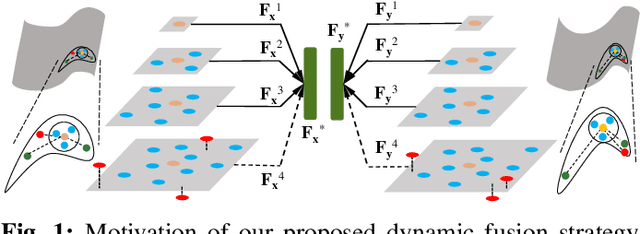
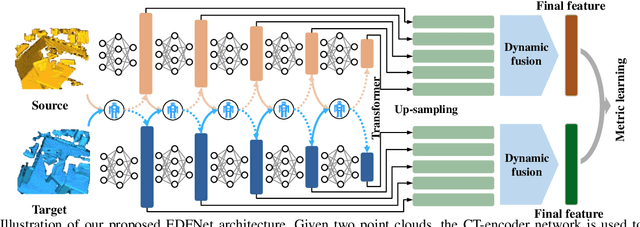
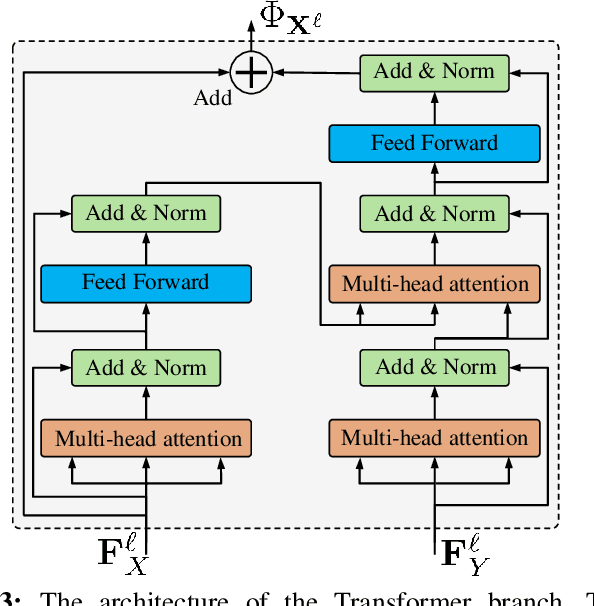
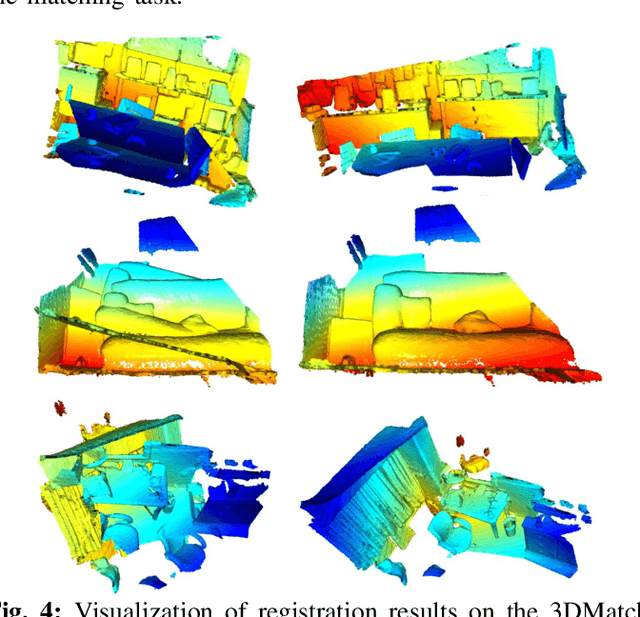
Existing learning-based point feature descriptors are usually task-agnostic, which pursue describing the individual 3D point clouds as accurate as possible. However, the matching task aims at describing the corresponding points consistently across different 3D point clouds. Therefore these too accurate features may play a counterproductive role due to the inconsistent point feature representations of correspondences caused by the unpredictable noise, partiality, deformation, \etc, in the local geometry. In this paper, we propose to learn a robust task-specific feature descriptor to consistently describe the correct point correspondence under interference. Born with an Encoder and a Dynamic Fusion module, our method EDFNet develops from two aspects. First, we augment the matchability of correspondences by utilizing their repetitive local structure. To this end, a special encoder is designed to exploit two input point clouds jointly for each point descriptor. It not only captures the local geometry of each point in the current point cloud by convolution, but also exploits the repetitive structure from paired point cloud by Transformer. Second, we propose a dynamical fusion module to jointly use different scale features. There is an inevitable struggle between robustness and discriminativeness of the single scale feature. Specifically, the small scale feature is robust since little interference exists in this small receptive field. But it is not sufficiently discriminative as there are many repetitive local structures within a point cloud. Thus the resultant descriptors will lead to many incorrect matches. In contrast, the large scale feature is more discriminative by integrating more neighborhood information. ...
Gemino: Practical and Robust Neural Compression for Video Conferencing
Sep 22, 2022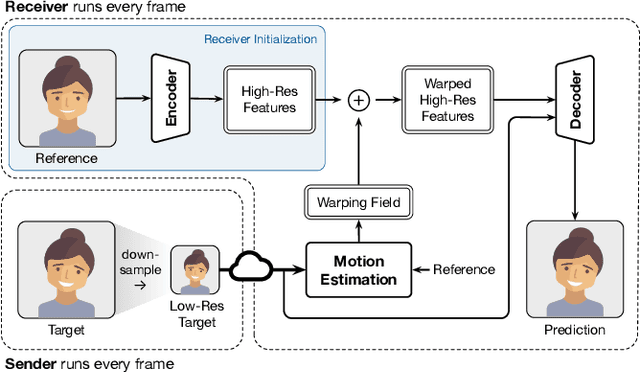
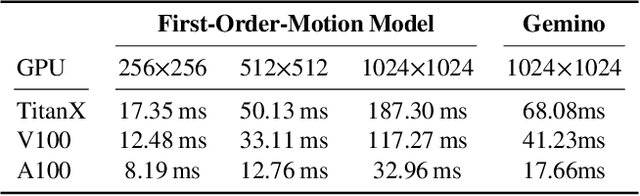


Video conferencing systems suffer from poor user experience when network conditions deteriorate because current video codecs simply cannot operate at extremely low bitrates. Recently, several neural alternatives have been proposed that reconstruct talking head videos at very low bitrates using sparse representations of each frame such as facial landmark information. However, these approaches produce poor reconstructions in scenarios with major movement or occlusions over the course of a call, and do not scale to higher resolutions. We design Gemino, a new neural compression system for video conferencing based on a novel high-frequency-conditional super-resolution pipeline. Gemino upsamples a very low-resolution version of each target frame while enhancing high-frequency details (e.g., skin texture, hair, etc.) based on information extracted from a single high-resolution reference image. We use a multi-scale architecture that runs different components of the model at different resolutions, allowing it to scale to resolutions comparable to 720p, and we personalize the model to learn specific details of each person, achieving much better fidelity at low bitrates. We implement Gemino atop aiortc, an open-source Python implementation of WebRTC, and show that it operates on 1024x1024 videos in real-time on a A100 GPU, and achieves 2.9x lower bitrate than traditional video codecs for the same perceptual quality.
360-MLC: Multi-view Layout Consistency for Self-training and Hyper-parameter Tuning
Oct 24, 2022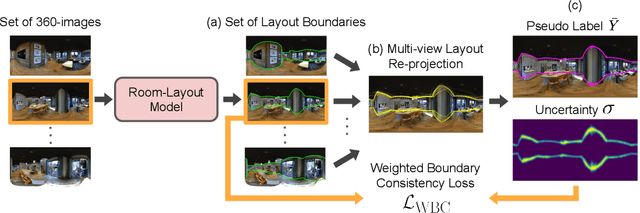
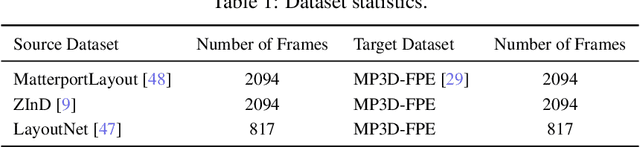
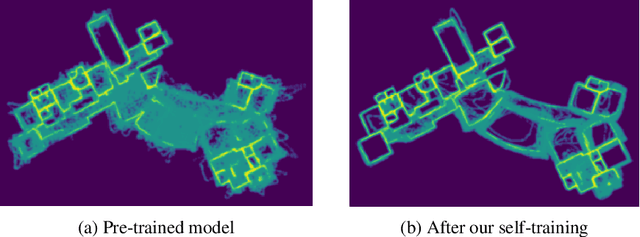
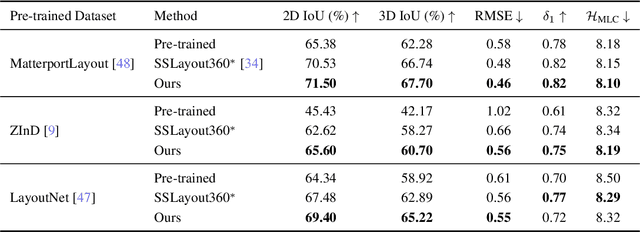
We present 360-MLC, a self-training method based on multi-view layout consistency for finetuning monocular room-layout models using unlabeled 360-images only. This can be valuable in practical scenarios where a pre-trained model needs to be adapted to a new data domain without using any ground truth annotations. Our simple yet effective assumption is that multiple layout estimations in the same scene must define a consistent geometry regardless of their camera positions. Based on this idea, we leverage a pre-trained model to project estimated layout boundaries from several camera views into the 3D world coordinate. Then, we re-project them back to the spherical coordinate and build a probability function, from which we sample the pseudo-labels for self-training. To handle unconfident pseudo-labels, we evaluate the variance in the re-projected boundaries as an uncertainty value to weight each pseudo-label in our loss function during training. In addition, since ground truth annotations are not available during training nor in testing, we leverage the entropy information in multiple layout estimations as a quantitative metric to measure the geometry consistency of the scene, allowing us to evaluate any layout estimator for hyper-parameter tuning, including model selection without ground truth annotations. Experimental results show that our solution achieves favorable performance against state-of-the-art methods when self-training from three publicly available source datasets to a unique, newly labeled dataset consisting of multi-view of the same scenes.
Multilingual Search with Subword TF-IDF
Sep 29, 2022

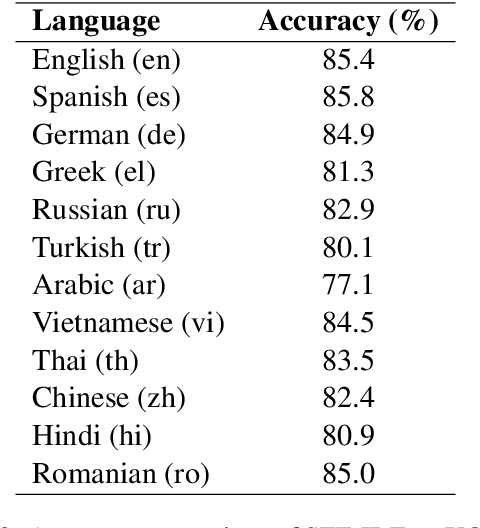
Multilingual search can be achieved with subword tokenization. The accuracy of traditional TF-IDF approaches depend on manually curated tokenization, stop words and stemming rules, whereas subword TF-IDF (STF-IDF) can offer higher accuracy without such heuristics. Moreover, multilingual support can be incorporated inherently as part of the subword tokenization model training. XQuAD evaluation demonstrates the advantages of STF-IDF: superior information retrieval accuracy of 85.4% for English and over 80% for 10 other languages without any heuristics-based preprocessing. The software to reproduce these results are open-sourced as a part of Text2Text: https://github.com/artitw/text2text
Approximate better, Attack stronger: Adversarial Example Generation via Asymptotically Gaussian Mixture Distribution
Sep 24, 2022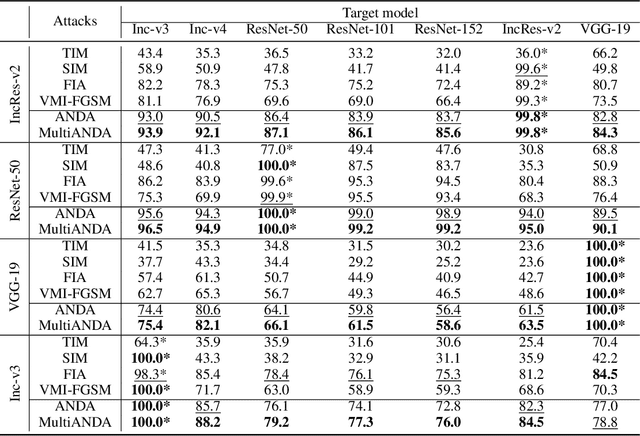
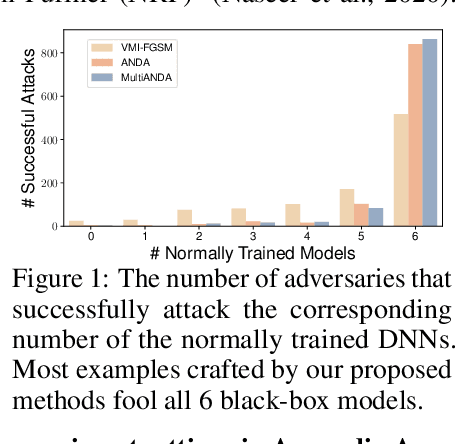
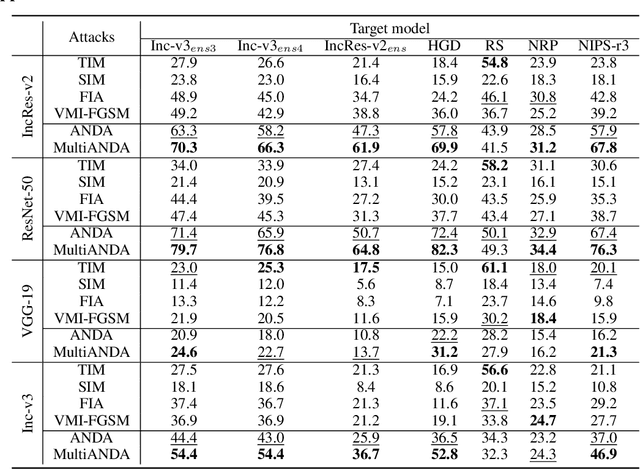
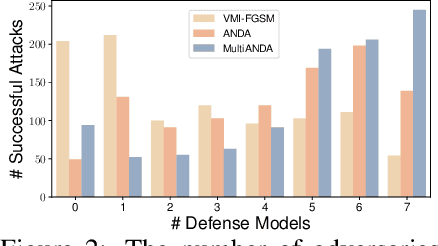
Strong adversarial examples are the keys to evaluating and enhancing the robustness of deep neural networks. The popular adversarial attack algorithms maximize the non-concave loss function using the gradient ascent. However, the performance of each attack is usually sensitive to, for instance, minor image transformations due to insufficient information (only one input example, few white-box source models and unknown defense strategies). Hence, the crafted adversarial examples are prone to overfit the source model, which limits their transferability to unidentified architectures. In this paper, we propose Multiple Asymptotically Normal Distribution Attacks (MultiANDA), a novel method that explicitly characterizes adversarial perturbations from a learned distribution. Specifically, we approximate the posterior distribution over the perturbations by taking advantage of the asymptotic normality property of stochastic gradient ascent (SGA), then apply the ensemble strategy on this procedure to estimate a Gaussian mixture model for a better exploration of the potential optimization space. Drawing perturbations from the learned distribution allow us to generate any number of adversarial examples for each input. The approximated posterior essentially describes the stationary distribution of SGA iterations, which captures the geometric information around the local optimum. Thus, the samples drawn from the distribution reliably maintain the transferability. Our proposed method outperforms nine state-of-the-art black-box attacks on deep learning models with or without defenses through extensive experiments on seven normally trained and seven defence models.
SANCL: Multimodal Review Helpfulness Prediction with Selective Attention and Natural Contrastive Learning
Sep 12, 2022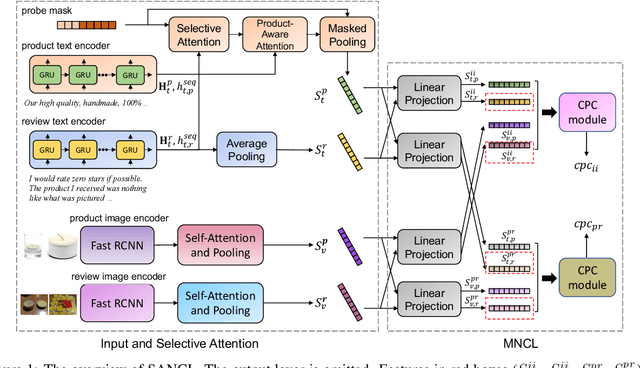
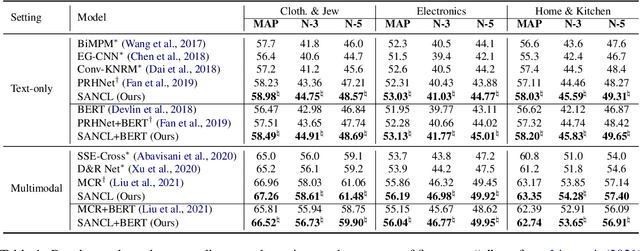
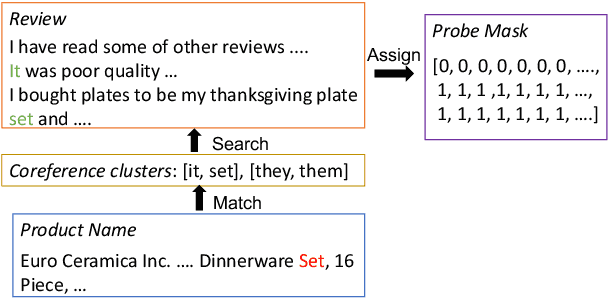
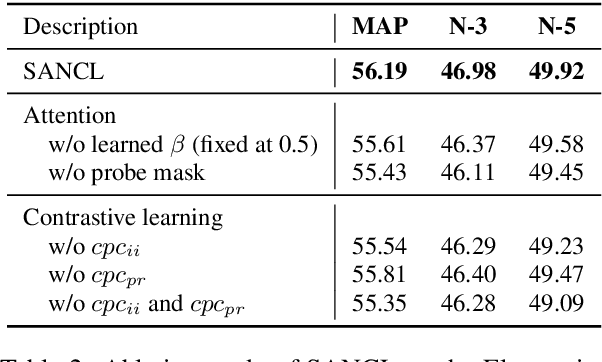
With the boom of e-commerce, Multimodal Review Helpfulness Prediction (MRHP), which aims to sort product reviews according to the predicted helpfulness scores has become a research hotspot. Previous work on this task focuses on attention-based modality fusion, information integration, and relation modeling, which primarily exposes the following drawbacks: 1) the model may fail to capture the really essential information due to its indiscriminate attention formulation; 2) lack appropriate modeling methods that take full advantage of correlation among provided data. In this paper, we propose SANCL: Selective Attention and Natural Contrastive Learning for MRHP. SANCL adopts a probe-based strategy to enforce high attention weights on the regions of greater significance. It also constructs a contrastive learning framework based on natural matching properties in the dataset. Experimental results on two benchmark datasets with three categories show that SANCL achieves state-of-the-art baseline performance with lower memory consumption.
Modeling the Lighting in Scenes as Style for Auto White-Balance Correction
Oct 17, 2022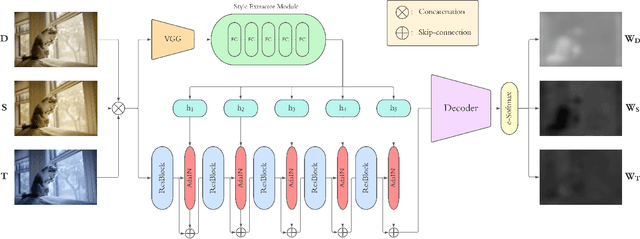
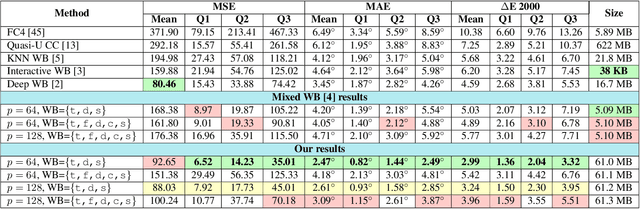

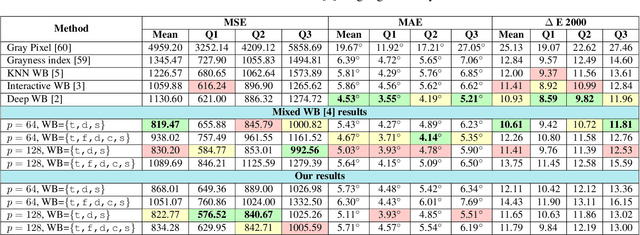
Style may refer to different concepts (e.g. painting style, hairstyle, texture, color, filter, etc.) depending on how the feature space is formed. In this work, we propose a novel idea of interpreting the lighting in the single- and multi-illuminant scenes as the concept of style. To verify this idea, we introduce an enhanced auto white-balance (AWB) method that models the lighting in single- and mixed-illuminant scenes as the style factor. Our AWB method does not require any illumination estimation step, yet contains a network learning to generate the weighting maps of the images with different WB settings. Proposed network utilizes the style information, extracted from the scene by a multi-head style extraction module. AWB correction is completed after blending these weighting maps and the scene. Experiments on single- and mixed-illuminant datasets demonstrate that our proposed method achieves promising correction results when compared to the recent works. This shows that the lighting in the scenes with multiple illuminations can be modeled by the concept of style. Source code and trained models are available on https://github.com/birdortyedi/lighting-as-style-awb-correction.
Risk-Sensitive Markov Decision Processes with Long-Run CVaR Criterion
Oct 17, 2022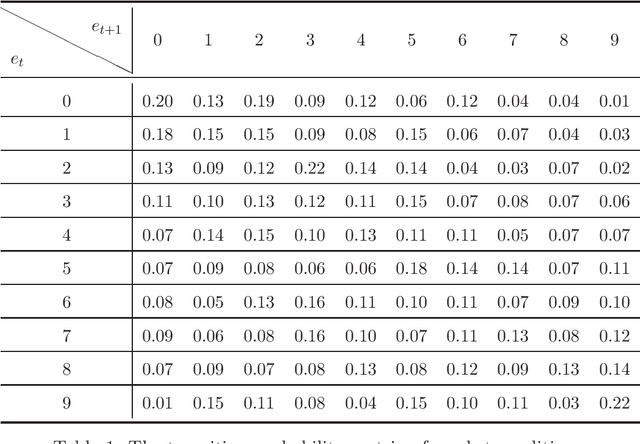
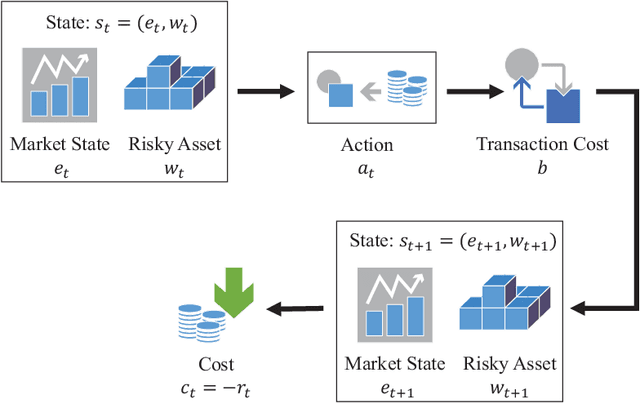

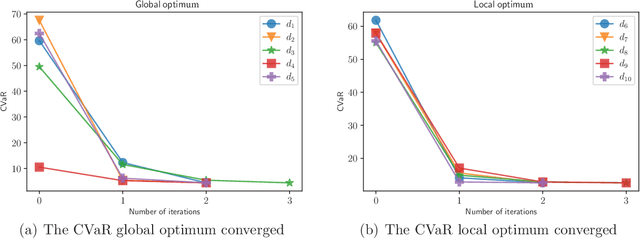
CVaR (Conditional Value at Risk) is a risk metric widely used in finance. However, dynamically optimizing CVaR is difficult since it is not a standard Markov decision process (MDP) and the principle of dynamic programming fails. In this paper, we study the infinite-horizon discrete-time MDP with a long-run CVaR criterion, from the view of sensitivity-based optimization. By introducing a pseudo CVaR metric, we derive a CVaR difference formula which quantifies the difference of long-run CVaR under any two policies. The optimality of deterministic policies is derived. We obtain a so-called Bellman local optimality equation for CVaR, which is a necessary and sufficient condition for local optimal policies and only necessary for global optimal policies. A CVaR derivative formula is also derived for providing more sensitivity information. Then we develop a policy iteration type algorithm to efficiently optimize CVaR, which is shown to converge to local optima in the mixed policy space. We further discuss some extensions including the mean-CVaR optimization and the maximization of CVaR. Finally, we conduct numerical experiments relating to portfolio management to demonstrate the main results. Our work may shed light on dynamically optimizing CVaR from a sensitivity viewpoint.
N-pad : Neighboring Pixel-based Industrial Anomaly Detection
Oct 17, 2022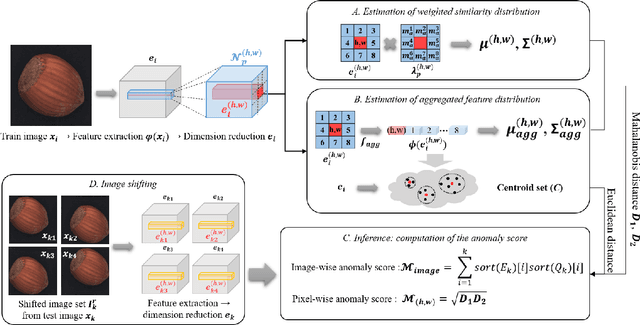
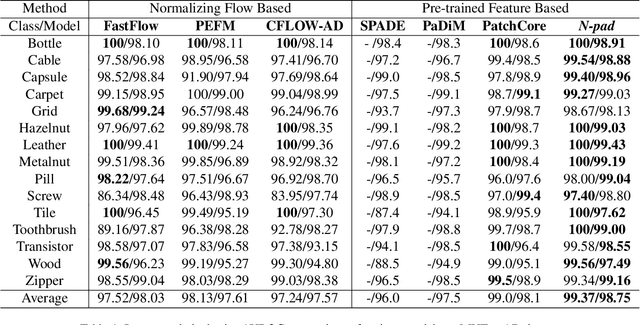

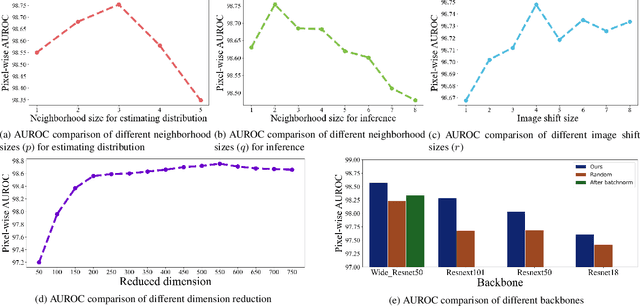
Identifying defects in the images of industrial products has been an important task to enhance quality control and reduce maintenance costs. In recent studies, industrial anomaly detection models were developed using pre-trained networks to learn nominal representations. To employ the relative positional information of each pixel, we present \textit{\textbf{N-pad}}, a novel method for anomaly detection and segmentation in a one-class learning setting that includes the neighborhood of the target pixel for model training and evaluation. Within the model architecture, pixel-wise nominal distributions are estimated by using the features of neighboring pixels with the target pixel to allow possible marginal misalignment. Moreover, the centroids from clusters of nominal features are identified as a representative nominal set. Accordingly, anomaly scores are inferred based on the Mahalanobis distances and Euclidean distances between the target pixel and the estimated distributions or the centroid set, respectively. Thus, we have achieved state-of-the-art performance in MVTec-AD with AUROC of 99.37 for anomaly detection and 98.75 for anomaly segmentation, reducing the error by 34\% compared to the next best performing model. Experiments in various settings further validate our model.