 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Null Hypothesis Test for Anomaly Detection
Oct 05, 2022
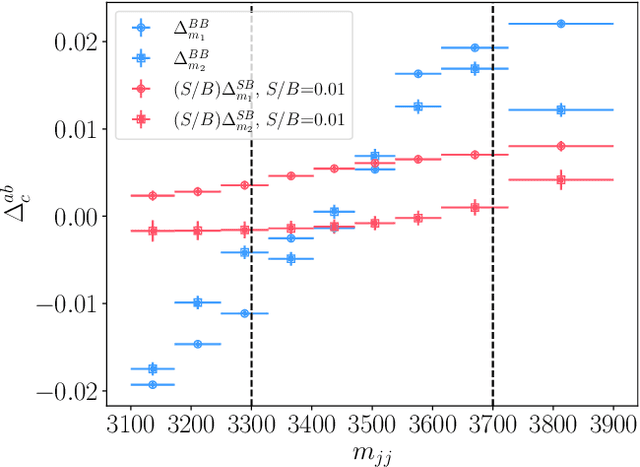
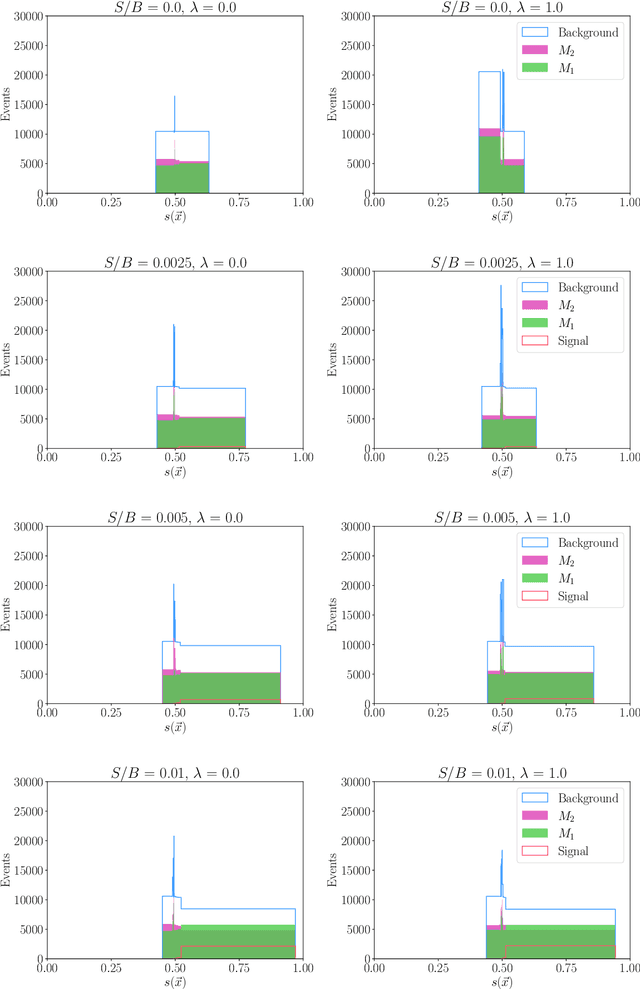
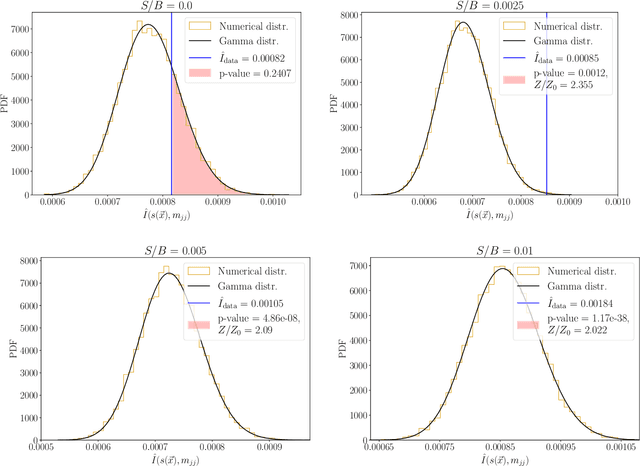
We extend the use of Classification Without Labels for anomaly detection with a hypothesis test designed to exclude the background-only hypothesis. By testing for statistical independence of the two discriminating dataset regions, we are able exclude the background-only hypothesis without relying on fixed anomaly score cuts or extrapolations of background estimates between regions. The method relies on the assumption of conditional independence of anomaly score features and dataset regions, which can be ensured using existing decorrelation techniques. As a benchmark example, we consider the LHC Olympics dataset where we show that mutual information represents a suitable test for statistical independence and our method exhibits excellent and robust performance at different signal fractions even in presence of realistic feature correlations.
Model of rough surfaces with Gaussian processes
Oct 15, 2022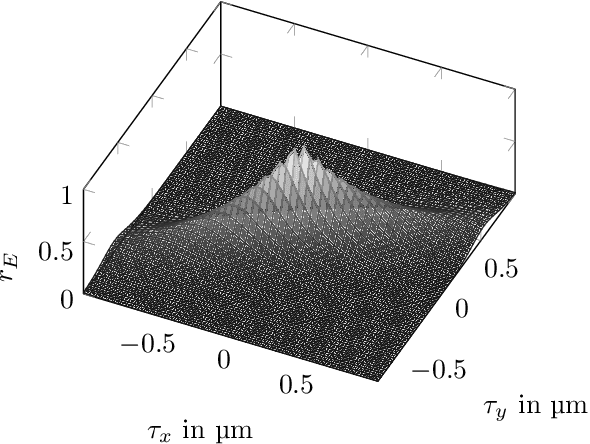

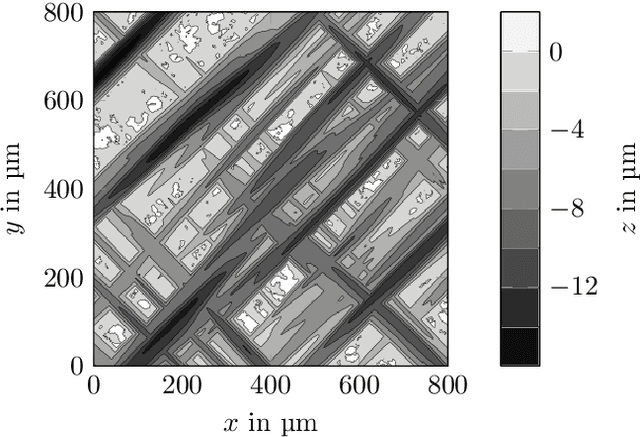
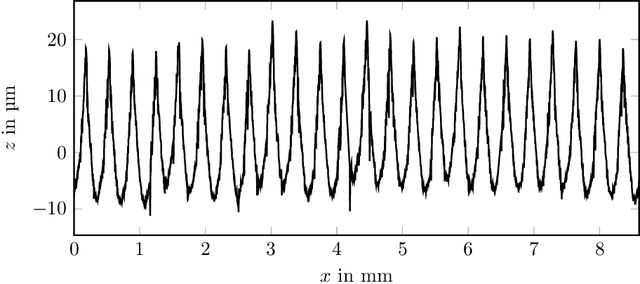
Surface roughness plays a critical role and has effects in, e.g., fluid dynamics or contact mechanics. For example, to evaluate fluid behavior at different roughness properties, real-world or numerical experiments are performed. Numerical simulations of rough surfaces can speed up these studies because they can help collect more and relevant information. However, it is hard to simulate rough surfaces with deterministic or structured components in current methods. In this work, we present a novel approach to simulate rough surfaces with Gaussian processes (GPs) because they have been capable of modeling structured or periodic elements in recent studies. Compared to traditional methods, GPs are not restricted to stationarity so they can simulate a wider range of rough surfaces. They are also able to interpolate invalid points in surface measurements. In this paper, we also summarize theoretical similarities of GPs with auto-regressive moving-average processes and introduce a linear process view of GPs. We particularly show that GPs can be used to model turned rough surfaces with only stationary assumptions from data.
Taxonomy of A Decision Support System for Adaptive Experimental Design in Field Robotics
Oct 15, 2022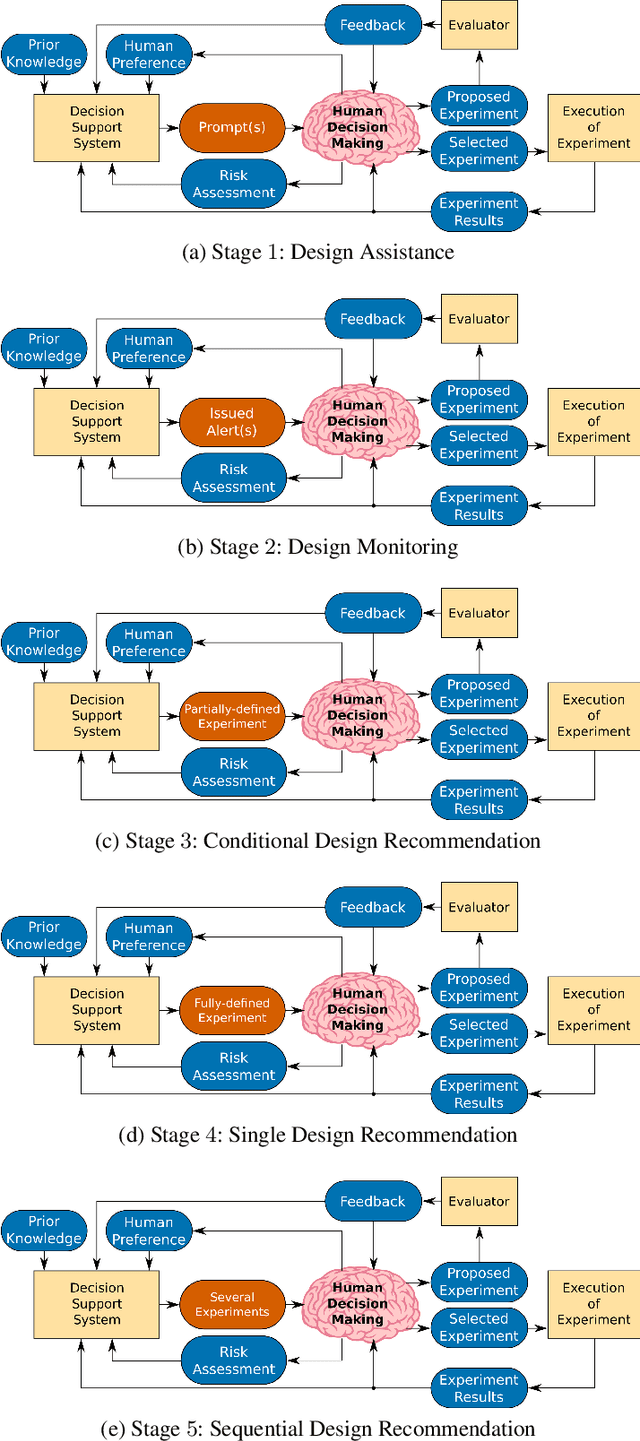
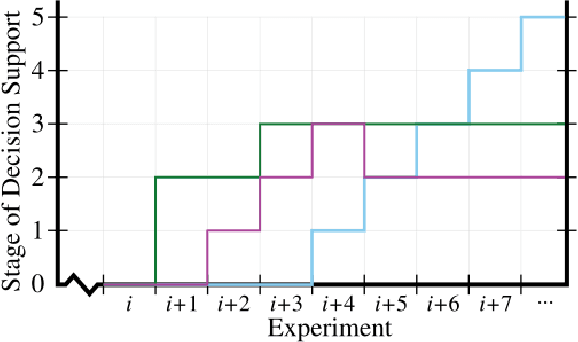
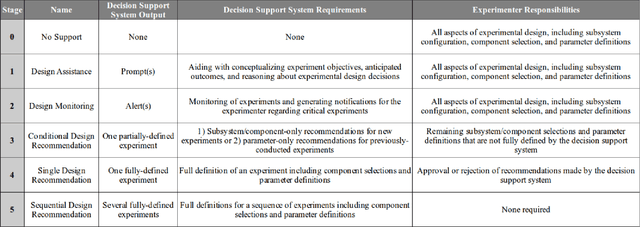
Experimental design in field robotics is an adaptive human-in-the-loop decision-making process in which an experimenter learns about system performance and limitations through interactions with a robot in the form of constructed experiments. This can be challenging because of system complexity, the need to operate in unstructured environments, and the competing objectives of maximizing information gain while simultaneously minimizing experimental costs. Based on the successes in other domains, we propose the use of a Decision Support System (DSS) to amplify the human's decision-making abilities, overcome their inherent shortcomings, and enable principled decision-making in field experiments. In this work, we propose common terminology and a six-stage taxonomy of DSSs specifically for adaptive experimental design of more informative tests and reduced experimental costs. We construct and present our taxonomy using examples and trends from DSS literature, including works involving artificial intelligence and Intelligent DSSs. Finally, we identify critical technical gaps and opportunities for future research to direct the scientific community in the pursuit of next-generation DSSs for experimental design.
Value Functions Factorization with Latent State Information Sharing in Decentralized Multi-Agent Policy Gradients
Jan 04, 2022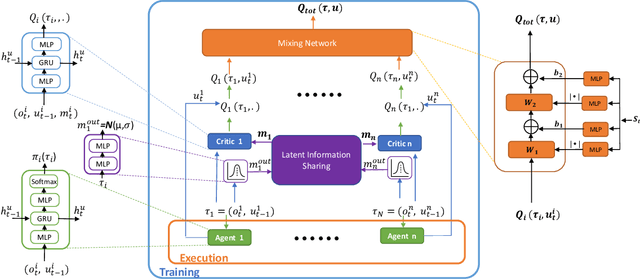
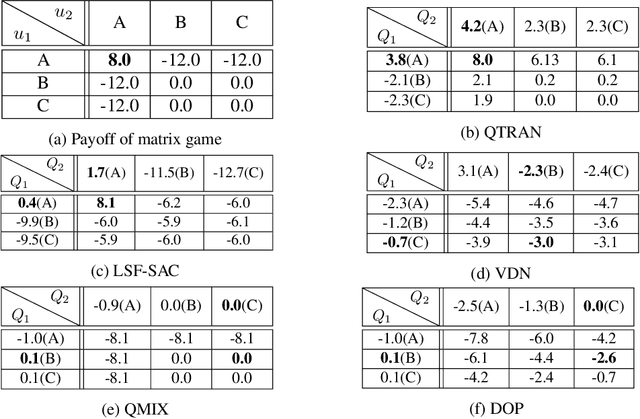
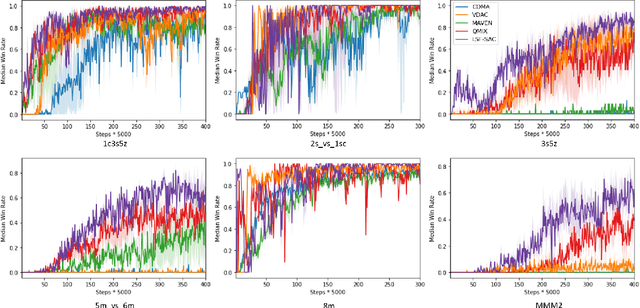
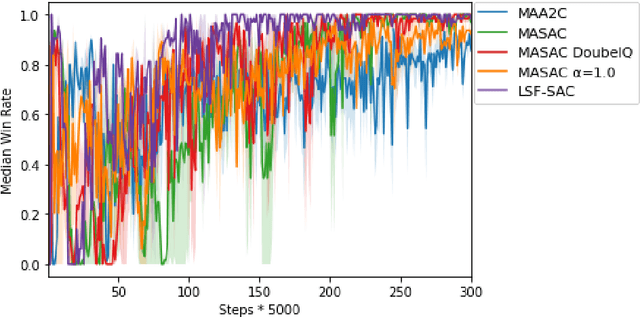
Value function factorization via centralized training and decentralized execution is promising for solving cooperative multi-agent reinforcement tasks. One of the approaches in this area, QMIX, has become state-of-the-art and achieved the best performance on the StarCraft II micromanagement benchmark. However, the monotonic-mixing of per agent estimates in QMIX is known to restrict the joint action Q-values it can represent, as well as the insufficient global state information for single agent value function estimation, often resulting in suboptimality. To this end, we present LSF-SAC, a novel framework that features a variational inference-based information-sharing mechanism as extra state information to assist individual agents in the value function factorization. We demonstrate that such latent individual state information sharing can significantly expand the power of value function factorization, while fully decentralized execution can still be maintained in LSF-SAC through a soft-actor-critic design. We evaluate LSF-SAC on the StarCraft II micromanagement challenge and demonstrate that it outperforms several state-of-the-art methods in challenging collaborative tasks. We further set extensive ablation studies for locating the key factors accounting for its performance improvements. We believe that this new insight can lead to new local value estimation methods and variational deep learning algorithms. A demo video and code of implementation can be found at https://sites.google.com/view/sacmm.
LINDA: Multi-Agent Local Information Decomposition for Awareness of Teammates
Oct 15, 2021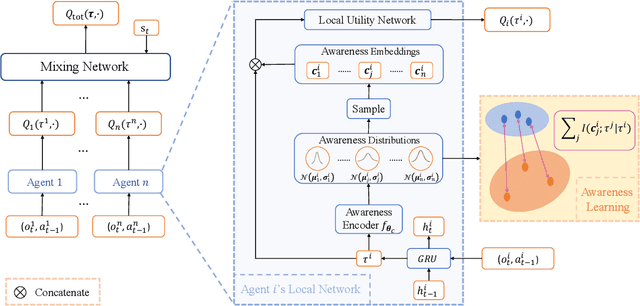
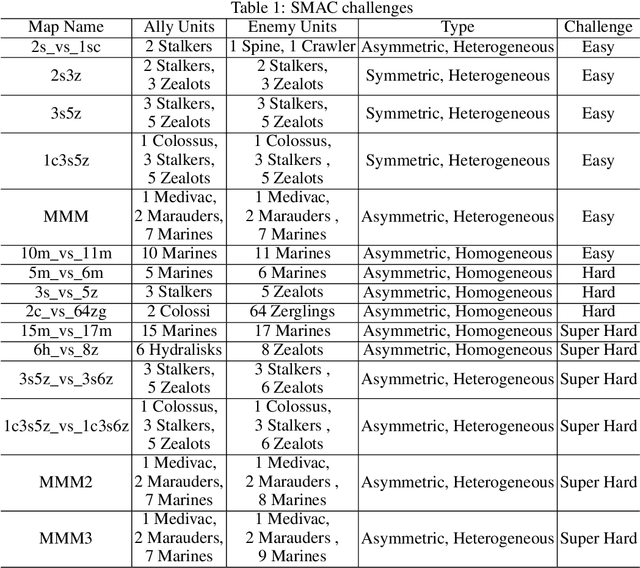

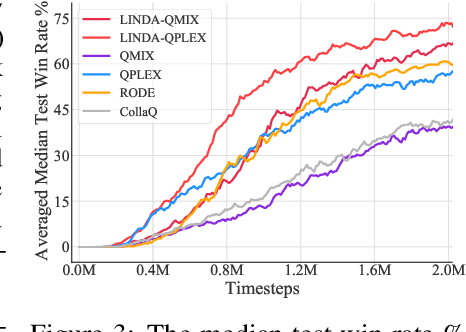
In cooperative multi-agent reinforcement learning (MARL), where agents only have access to partial observations, efficiently leveraging local information is critical. During long-time observations, agents can build \textit{awareness} for teammates to alleviate the problem of partial observability. However, previous MARL methods usually neglect this kind of utilization of local information. To address this problem, we propose a novel framework, multi-agent \textit{Local INformation Decomposition for Awareness of teammates} (LINDA), with which agents learn to decompose local information and build awareness for each teammate. We model the awareness as stochastic random variables and perform representation learning to ensure the informativeness of awareness representations by maximizing the mutual information between awareness and the actual trajectory of the corresponding agent. LINDA is agnostic to specific algorithms and can be flexibly integrated to different MARL methods. Sufficient experiments show that the proposed framework learns informative awareness from local partial observations for better collaboration and significantly improves the learning performance, especially on challenging tasks.
Active Altruism Learning and Information Sufficiency for Autonomous Driving
Oct 09, 2021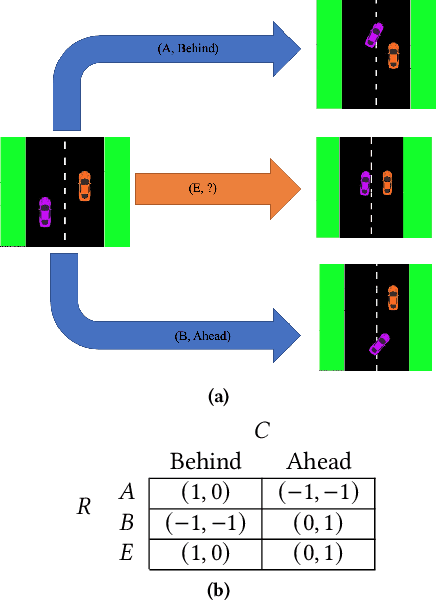
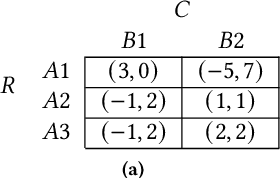
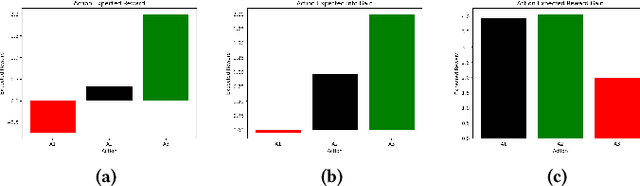
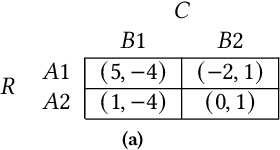
Safe interaction between vehicles requires the ability to choose actions that reveal the preferences of the other vehicles. Since exploratory actions often do not directly contribute to their objective, an interactive vehicle must also able to identify when it is appropriate to perform them. In this work we demonstrate how Active Learning methods can be used to incentivise an autonomous vehicle (AV) to choose actions that reveal information about the altruistic inclinations of another vehicle. We identify a property, Information Sufficiency, that a reward function should have in order to keep exploration from unnecessarily interfering with the pursuit of an objective. We empirically demonstrate that reward functions that do not have Information Sufficiency are prone to inadequate exploration, which can result in sub-optimal behaviour. We propose a reward definition that has Information Sufficiency, and show that it facilitates an AV choosing exploratory actions to estimate altruistic tendency, whilst also compensating for the possibility of conflicting beliefs between vehicles.
Code Recommendation for Open Source Software Developers
Oct 20, 2022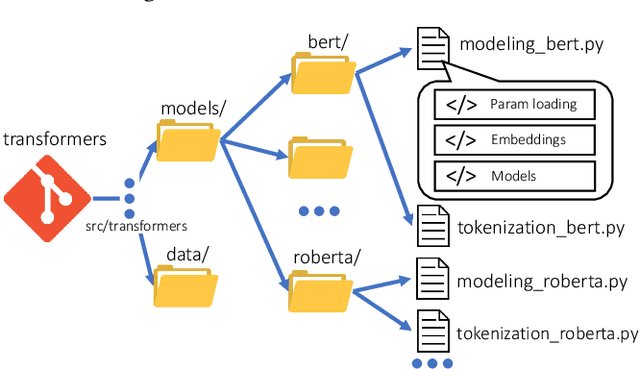
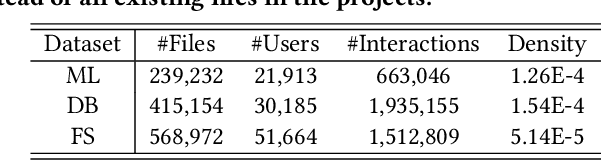
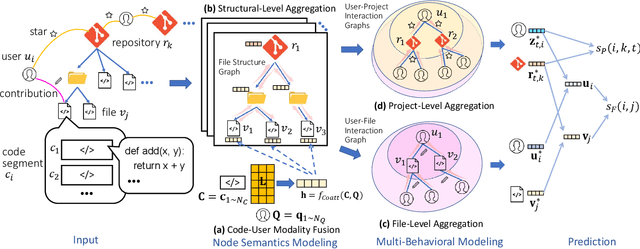
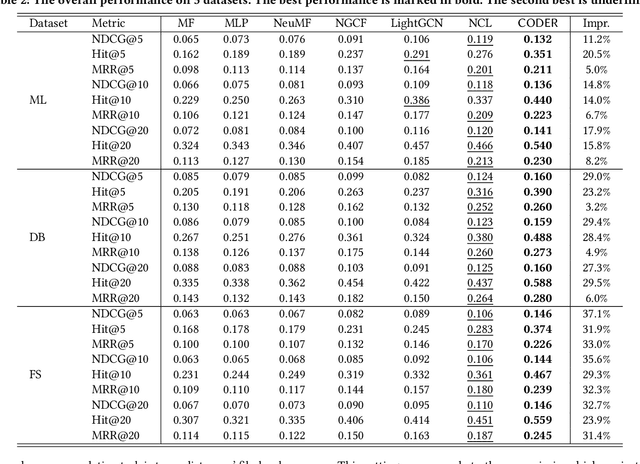
Open Source Software (OSS) is forming the spines of technology infrastructures, attracting millions of talents to contribute. Notably, it is challenging and critical to consider both the developers' interests and the semantic features of the project code to recommend appropriate development tasks to OSS developers. In this paper, we formulate the novel problem of code recommendation, whose purpose is to predict the future contribution behaviors of developers given their interaction history, the semantic features of source code, and the hierarchical file structures of projects. Considering the complex interactions among multiple parties within the system, we propose CODER, a novel graph-based code recommendation framework for open source software developers. CODER jointly models microscopic user-code interactions and macroscopic user-project interactions via a heterogeneous graph and further bridges the two levels of information through aggregation on file-structure graphs that reflect the project hierarchy. Moreover, due to the lack of reliable benchmarks, we construct three large-scale datasets to facilitate future research in this direction. Extensive experiments show that our CODER framework achieves superior performance under various experimental settings, including intra-project, cross-project, and cold-start recommendation. We will release all the datasets, code, and utilities for data retrieval upon the acceptance of this work.
Extracting or Guessing? Improving Faithfulness of Event Temporal Relation Extraction
Oct 12, 2022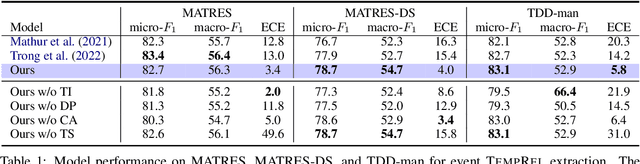
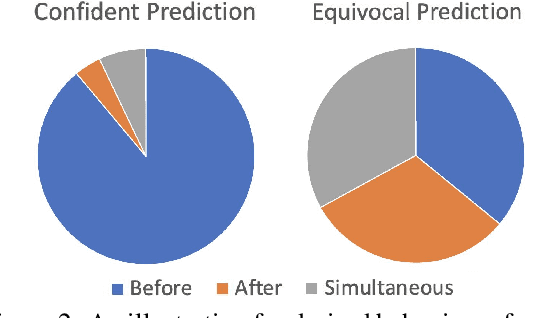
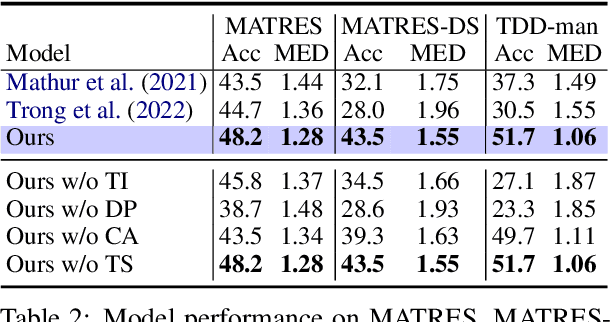
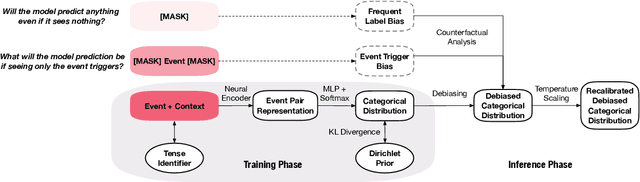
In this paper, we seek to improve the faithfulness of TempRel extraction models from two perspectives. The first perspective is to extract genuinely based on contextual description. To achieve this, we propose to conduct counterfactual analysis to attenuate the effects of two significant types of training biases: the event trigger bias and the frequent label bias. We also add tense information into event representations to explicitly place an emphasis on the contextual description. The second perspective is to provide proper uncertainty estimation and abstain from extraction when no relation is described in the text. By parameterization of Dirichlet Prior over the model-predicted categorical distribution, we improve the model estimates of the correctness likelihood and make TempRel predictions more selective. We also employ temperature scaling to recalibrate the model confidence measure after bias mitigation. Through experimental analysis on MATRES, MATRES-DS, and TDDiscourse, we demonstrate that our model extracts TempRel and timelines more faithfully compared to SOTA methods, especially under distribution shifts.
FontTransformer: Few-shot High-resolution Chinese Glyph Image Synthesis via Stacked Transformers
Oct 12, 2022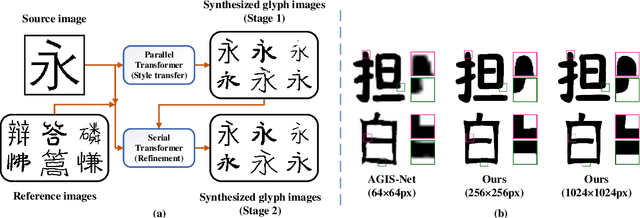
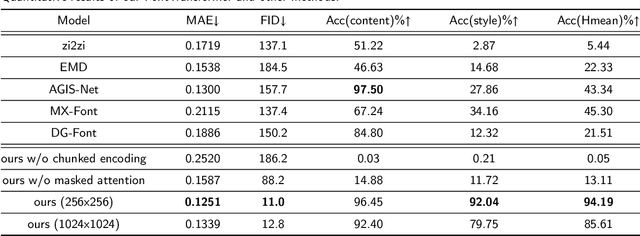
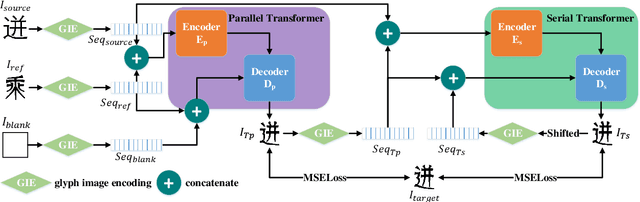
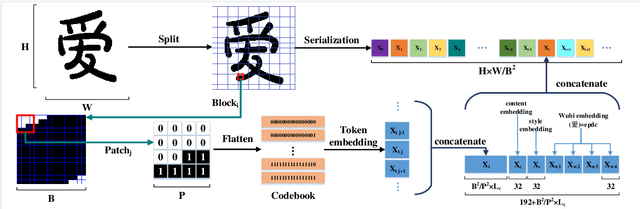
Automatic generation of high-quality Chinese fonts from a few online training samples is a challenging task, especially when the amount of samples is very small. Existing few-shot font generation methods can only synthesize low-resolution glyph images that often possess incorrect topological structures or/and incomplete strokes. To address the problem, this paper proposes FontTransformer, a novel few-shot learning model, for high-resolution Chinese glyph image synthesis by using stacked Transformers. The key idea is to apply the parallel Transformer to avoid the accumulation of prediction errors and utilize the serial Transformer to enhance the quality of synthesized strokes. Meanwhile, we also design a novel encoding scheme to feed more glyph information and prior knowledge to our model, which further enables the generation of high-resolution and visually-pleasing glyph images. Both qualitative and quantitative experimental results demonstrate the superiority of our method compared to other existing approaches in the few-shot Chinese font synthesis task.
Robust Action Segmentation from Timestamp Supervision
Oct 12, 2022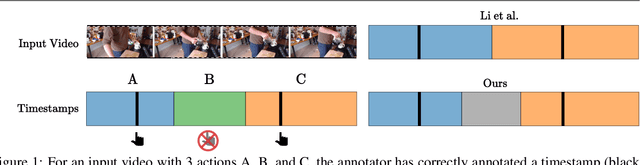
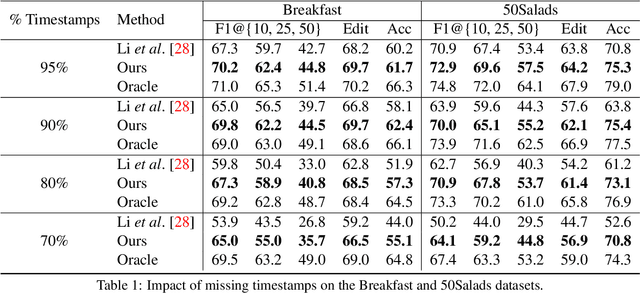
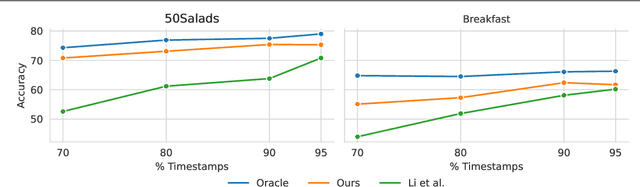
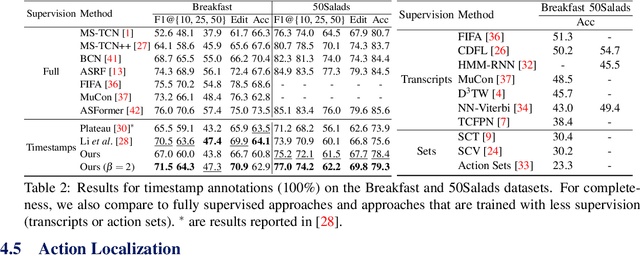
Action segmentation is the task of predicting an action label for each frame of an untrimmed video. As obtaining annotations to train an approach for action segmentation in a fully supervised way is expensive, various approaches have been proposed to train action segmentation models using different forms of weak supervision, e.g., action transcripts, action sets, or more recently timestamps. Timestamp supervision is a promising type of weak supervision as obtaining one timestamp per action is less expensive than annotating all frames, but it provides more information than other forms of weak supervision. However, previous works assume that every action instance is annotated with a timestamp, which is a restrictive assumption since it assumes that annotators do not miss any action. In this work, we relax this restrictive assumption and take missing annotations for some action instances into account. We show that our approach is more robust to missing annotations compared to other approaches and various baselines.