 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Taxonomy of A Decision Support System for Adaptive Experimental Design in Field Robotics
Oct 15, 2022
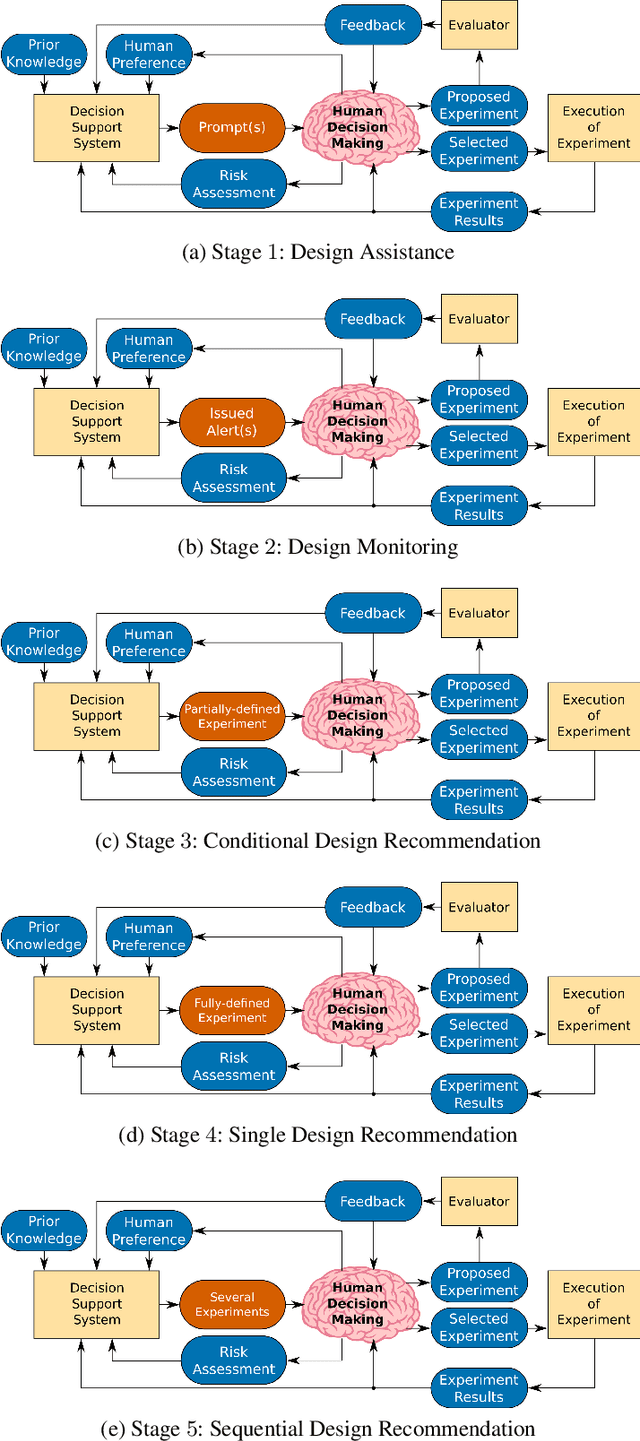
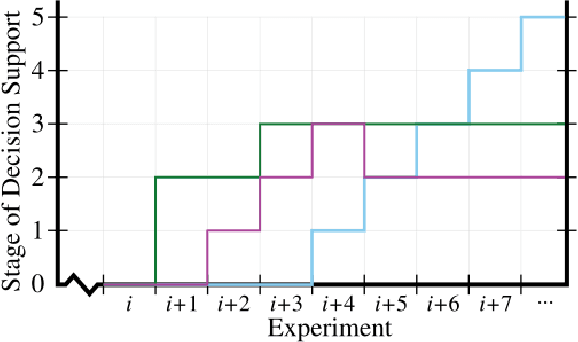
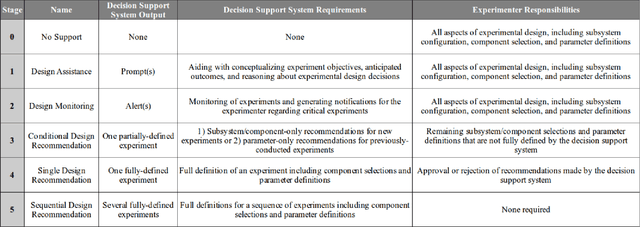
Experimental design in field robotics is an adaptive human-in-the-loop decision-making process in which an experimenter learns about system performance and limitations through interactions with a robot in the form of constructed experiments. This can be challenging because of system complexity, the need to operate in unstructured environments, and the competing objectives of maximizing information gain while simultaneously minimizing experimental costs. Based on the successes in other domains, we propose the use of a Decision Support System (DSS) to amplify the human's decision-making abilities, overcome their inherent shortcomings, and enable principled decision-making in field experiments. In this work, we propose common terminology and a six-stage taxonomy of DSSs specifically for adaptive experimental design of more informative tests and reduced experimental costs. We construct and present our taxonomy using examples and trends from DSS literature, including works involving artificial intelligence and Intelligent DSSs. Finally, we identify critical technical gaps and opportunities for future research to direct the scientific community in the pursuit of next-generation DSSs for experimental design.
Model of rough surfaces with Gaussian processes
Oct 15, 2022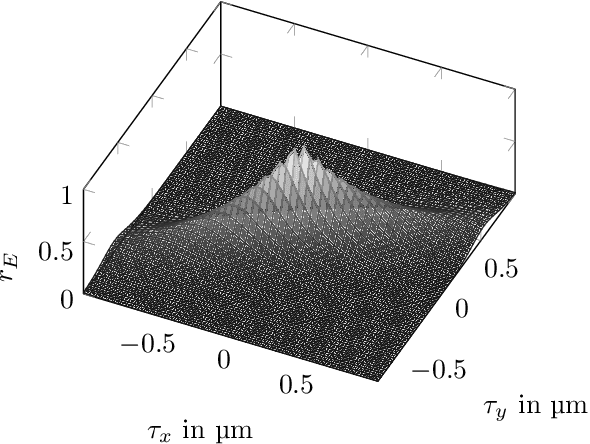

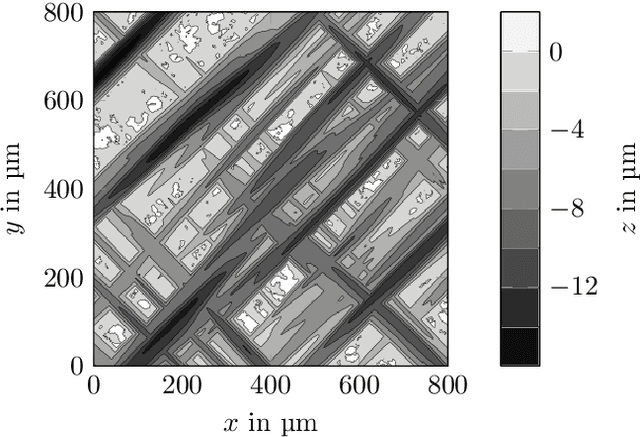
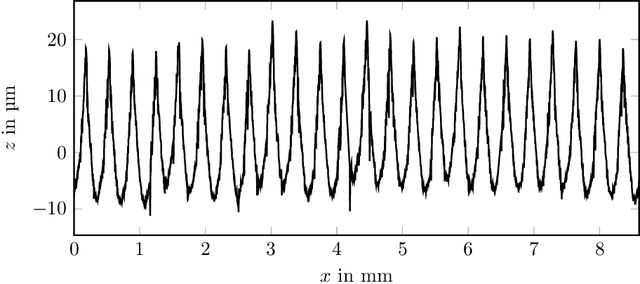
Surface roughness plays a critical role and has effects in, e.g., fluid dynamics or contact mechanics. For example, to evaluate fluid behavior at different roughness properties, real-world or numerical experiments are performed. Numerical simulations of rough surfaces can speed up these studies because they can help collect more and relevant information. However, it is hard to simulate rough surfaces with deterministic or structured components in current methods. In this work, we present a novel approach to simulate rough surfaces with Gaussian processes (GPs) because they have been capable of modeling structured or periodic elements in recent studies. Compared to traditional methods, GPs are not restricted to stationarity so they can simulate a wider range of rough surfaces. They are also able to interpolate invalid points in surface measurements. In this paper, we also summarize theoretical similarities of GPs with auto-regressive moving-average processes and introduce a linear process view of GPs. We particularly show that GPs can be used to model turned rough surfaces with only stationary assumptions from data.
Code Recommendation for Open Source Software Developers
Oct 20, 2022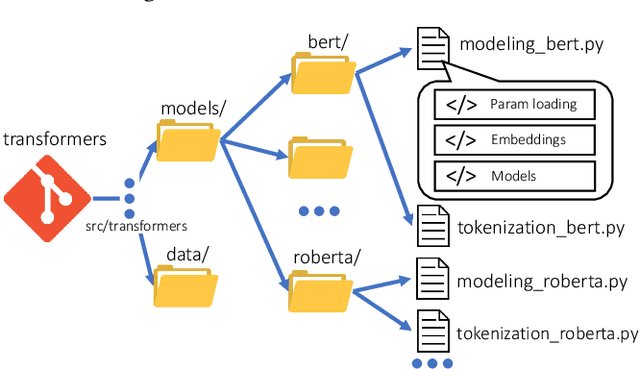
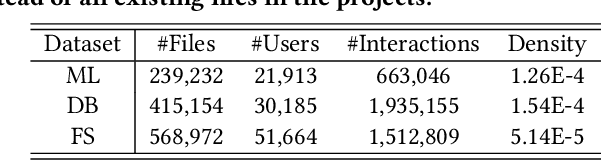
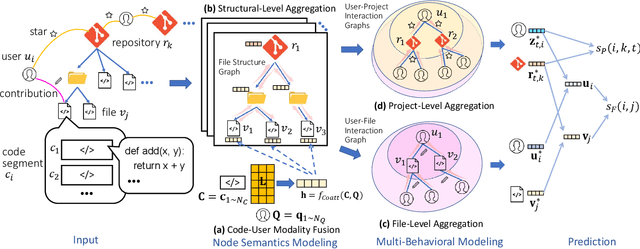
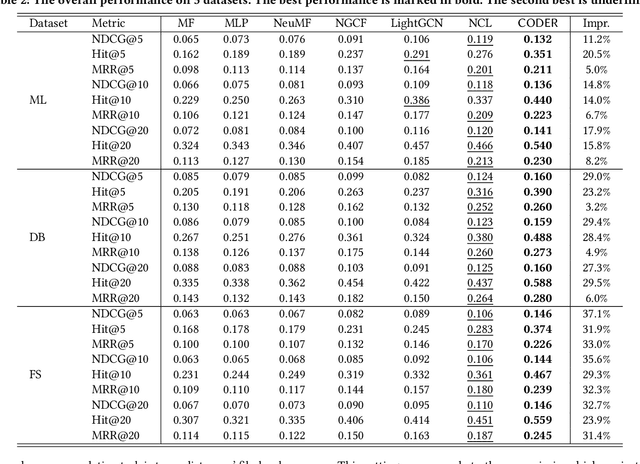
Open Source Software (OSS) is forming the spines of technology infrastructures, attracting millions of talents to contribute. Notably, it is challenging and critical to consider both the developers' interests and the semantic features of the project code to recommend appropriate development tasks to OSS developers. In this paper, we formulate the novel problem of code recommendation, whose purpose is to predict the future contribution behaviors of developers given their interaction history, the semantic features of source code, and the hierarchical file structures of projects. Considering the complex interactions among multiple parties within the system, we propose CODER, a novel graph-based code recommendation framework for open source software developers. CODER jointly models microscopic user-code interactions and macroscopic user-project interactions via a heterogeneous graph and further bridges the two levels of information through aggregation on file-structure graphs that reflect the project hierarchy. Moreover, due to the lack of reliable benchmarks, we construct three large-scale datasets to facilitate future research in this direction. Extensive experiments show that our CODER framework achieves superior performance under various experimental settings, including intra-project, cross-project, and cold-start recommendation. We will release all the datasets, code, and utilities for data retrieval upon the acceptance of this work.
End-to-end Ensemble-based Feature Selection for Paralinguistics Tasks
Oct 28, 2022
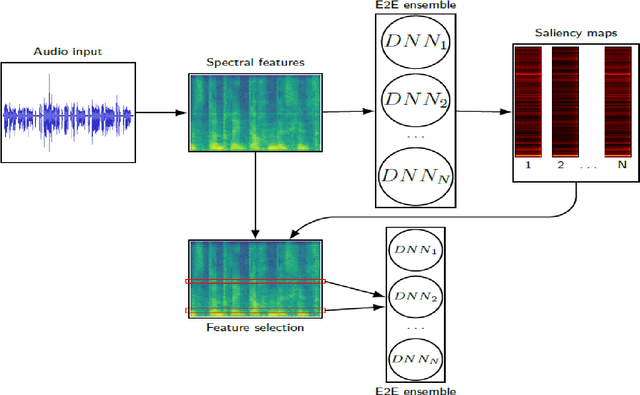
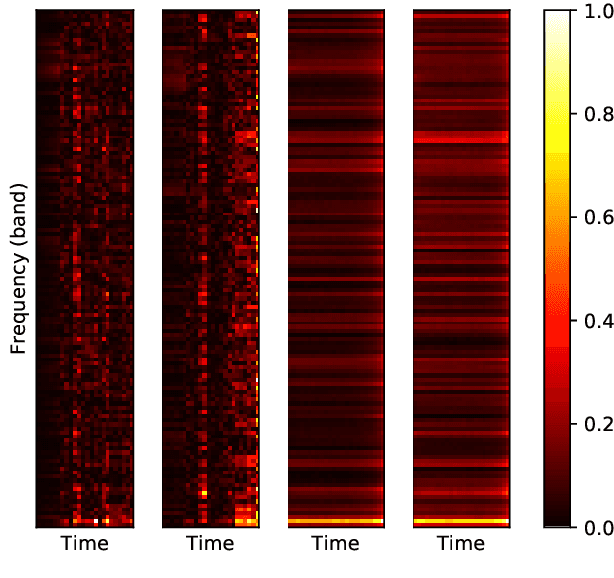
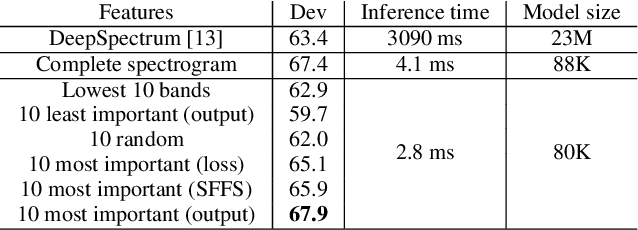
The events of recent years have highlighted the importance of telemedicine solutions which could potentially allow remote treatment and diagnosis. Relatedly, Computational Paralinguistics, a unique subfield of Speech Processing, aims to extract information about the speaker and form an important part of telemedicine applications. In this work, we focus on two paralinguistic problems: mask detection and breathing state prediction. Solutions developed for these tasks could be invaluable and have the potential to help monitor and limit the spread of a virus like COVID-19. The current state-of-the-art methods proposed for these tasks are ensembles based on deep neural networks like ResNets in conjunction with feature engineering. Although these ensembles can achieve high accuracy, they also have a large footprint and require substantial computational power reducing portability to devices with limited resources. These drawbacks also mean that the previously proposed solutions are infeasible to be used in a telemedicine system due to their size and speed. On the other hand, employing lighter feature-engineered systems can be laborious and add further complexity making them difficult to create a deployable system quickly. This work proposes an ensemble-based automatic feature selection method to enable the development of fast and memory-efficient systems. In particular, we propose an output-gradient-based method to discover essential features using large, well-performing ensembles before training a smaller one. In our experiments, we observed considerable (25-32%) reductions in inference times using neural network ensembles based on output-gradient-based features. Our method offers a simple way to increase the speed of the system and enable real-time usage while maintaining competitive results with larger-footprint ensemble using all spectral features.
DR.BENCH: Diagnostic Reasoning Benchmark for Clinical Natural Language Processing
Sep 29, 2022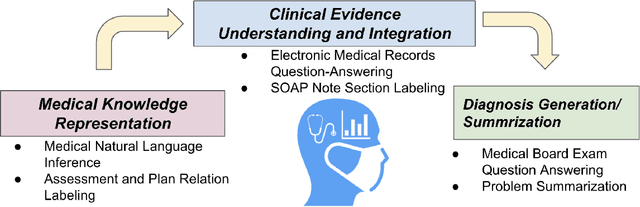
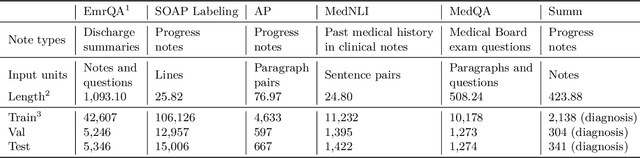
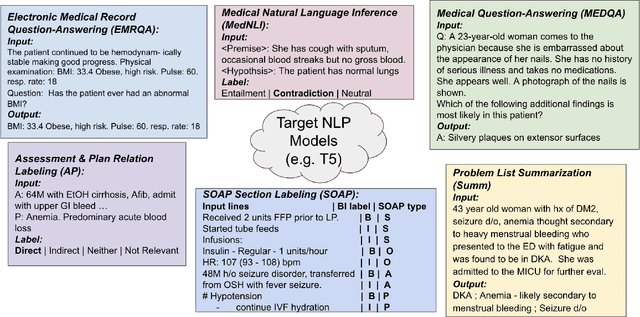
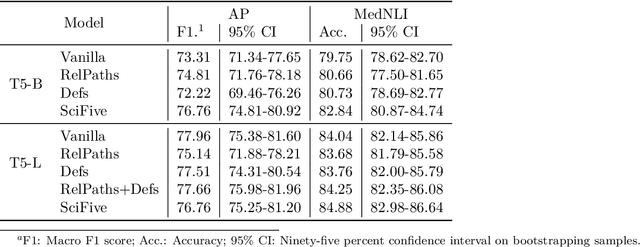
The meaningful use of electronic health records (EHR) continues to progress in the digital era with clinical decision support systems augmented by artificial intelligence. A priority in improving provider experience is to overcome information overload and reduce the cognitive burden so fewer medical errors and cognitive biases are introduced during patient care. One major type of medical error is diagnostic error due to systematic or predictable errors in judgment that rely on heuristics. The potential for clinical natural language processing (cNLP) to model diagnostic reasoning in humans with forward reasoning from data to diagnosis and potentially reduce the cognitive burden and medical error has not been investigated. Existing tasks to advance the science in cNLP have largely focused on information extraction and named entity recognition through classification tasks. We introduce a novel suite of tasks coined as Diagnostic Reasoning Benchmarks, DR.BENCH, as a new benchmark for developing and evaluating cNLP models with clinical diagnostic reasoning ability. The suite includes six tasks from ten publicly available datasets addressing clinical text understanding, medical knowledge reasoning, and diagnosis generation. DR.BENCH is the first clinical suite of tasks designed to be a natural language generation framework to evaluate pre-trained language models. Experiments with state-of-the-art pre-trained generative language models using large general domain models and models that were continually trained on a medical corpus demonstrate opportunities for improvement when evaluated in DR. BENCH. We share DR. BENCH as a publicly available GitLab repository with a systematic approach to load and evaluate models for the cNLP community.
Nonlinear Sufficient Dimension Reduction with a Stochastic Neural Network
Oct 09, 2022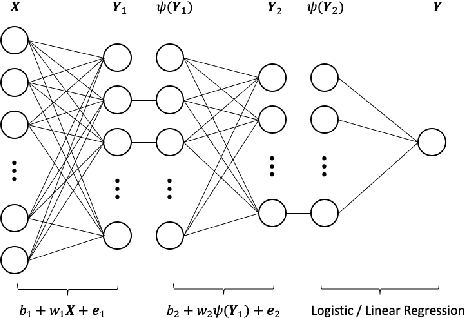
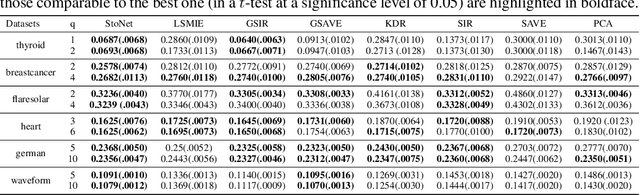
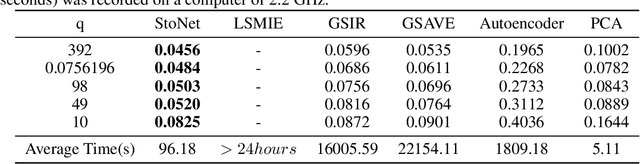
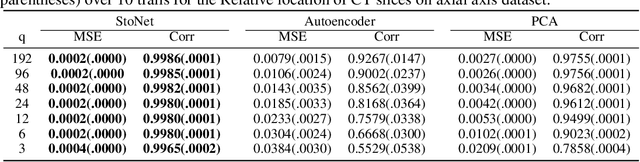
Sufficient dimension reduction is a powerful tool to extract core information hidden in the high-dimensional data and has potentially many important applications in machine learning tasks. However, the existing nonlinear sufficient dimension reduction methods often lack the scalability necessary for dealing with large-scale data. We propose a new type of stochastic neural network under a rigorous probabilistic framework and show that it can be used for sufficient dimension reduction for large-scale data. The proposed stochastic neural network is trained using an adaptive stochastic gradient Markov chain Monte Carlo algorithm, whose convergence is rigorously studied in the paper as well. Through extensive experiments on real-world classification and regression problems, we show that the proposed method compares favorably with the existing state-of-the-art sufficient dimension reduction methods and is computationally more efficient for large-scale data.
MIntRec: A New Dataset for Multimodal Intent Recognition
Sep 09, 2022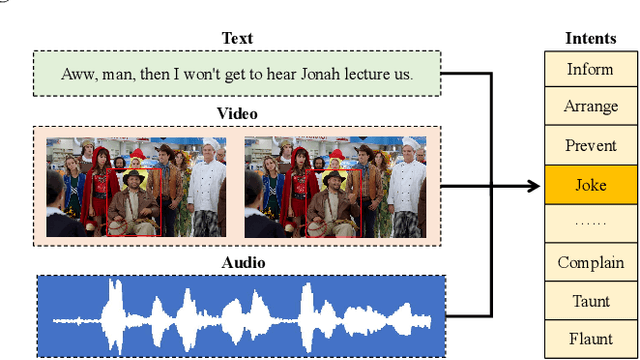

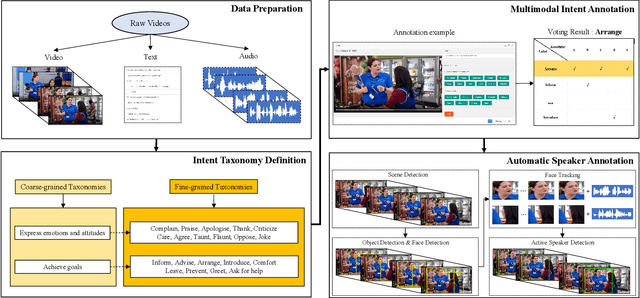
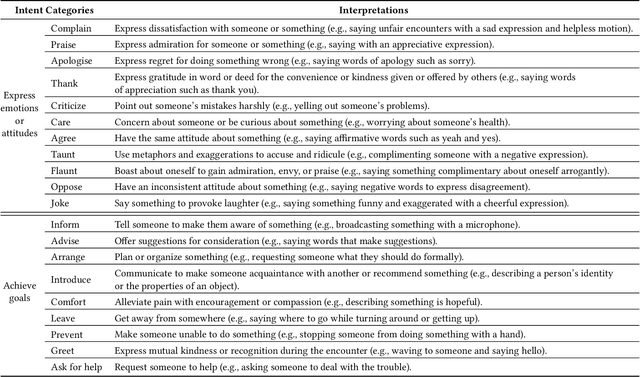
Multimodal intent recognition is a significant task for understanding human language in real-world multimodal scenes. Most existing intent recognition methods have limitations in leveraging the multimodal information due to the restrictions of the benchmark datasets with only text information. This paper introduces a novel dataset for multimodal intent recognition (MIntRec) to address this issue. It formulates coarse-grained and fine-grained intent taxonomies based on the data collected from the TV series Superstore. The dataset consists of 2,224 high-quality samples with text, video, and audio modalities and has multimodal annotations among twenty intent categories. Furthermore, we provide annotated bounding boxes of speakers in each video segment and achieve an automatic process for speaker annotation. MIntRec is helpful for researchers to mine relationships between different modalities to enhance the capability of intent recognition. We extract features from each modality and model cross-modal interactions by adapting three powerful multimodal fusion methods to build baselines. Extensive experiments show that employing the non-verbal modalities achieves substantial improvements compared with the text-only modality, demonstrating the effectiveness of using multimodal information for intent recognition. The gap between the best-performing methods and humans indicates the challenge and importance of this task for the community. The full dataset and codes are available for use at https://github.com/thuiar/MIntRec.
Towards Data-driven GIM tools: Two Prototypes
Sep 26, 2022Here we describe two approaches to improve group information management (GIM) and draw on the results of prior works to implement them in software prototypes. The first aids browsing and retrieving from large and unfamiliar collections like shared drives by dynamically reducing and re-organising them. The second supports the transfer and re-use of collections (e.g. to/by successors, descendants, or curators) by integrating novel sorting and annotation features. The prototypes' source code is shared online and screenshots are presented in the accompanying poster.
Prototype-Aware Heterogeneous Task for Point Cloud Completion
Sep 05, 2022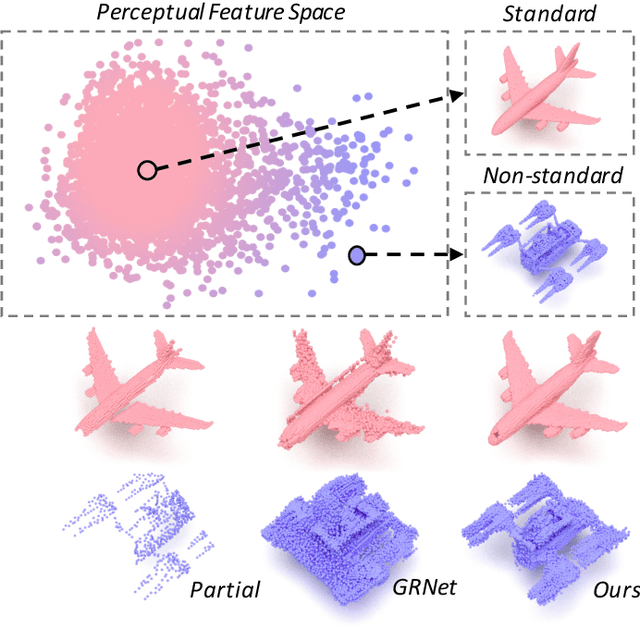
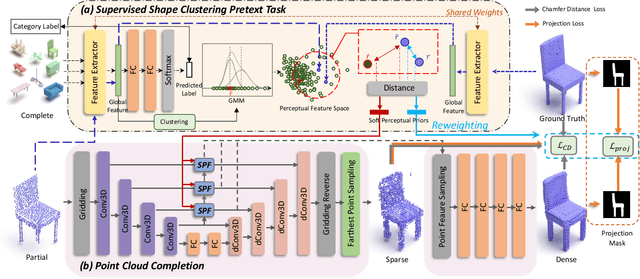

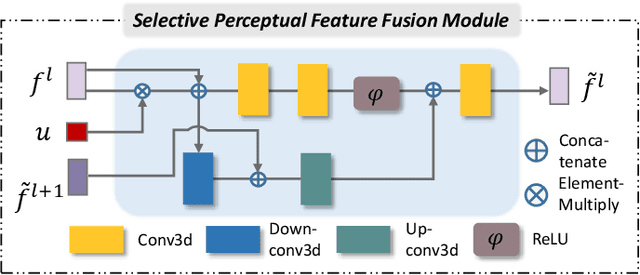
Point cloud completion, which aims at recovering original shape information from partial point clouds, has attracted attention on 3D vision community. Existing methods usually succeed in completion for standard shape, while failing to generate local details of point clouds for some non-standard shapes. To achieve desirable local details, guidance from global shape information is of critical importance. In this work, we design an effective way to distinguish standard/non-standard shapes with the help of intra-class shape prototypical representation, which can be calculated by the proposed supervised shape clustering pretext task, resulting in a heterogeneous component w.r.t completion network. The representative prototype, defined as feature centroid of shape categories, can provide global shape guidance, which is referred to as soft-perceptual prior, to inject into downstream completion network by the desired selective perceptual feature fusion module in a multi-scale manner. Moreover, for effective training, we consider difficulty-based sampling strategy to encourage the network to pay more attention to some partial point clouds with fewer geometric information. Experimental results show that our method outperforms other state-of-the-art methods and has strong ability on completing complex geometric shapes.
Null Hypothesis Test for Anomaly Detection
Oct 05, 2022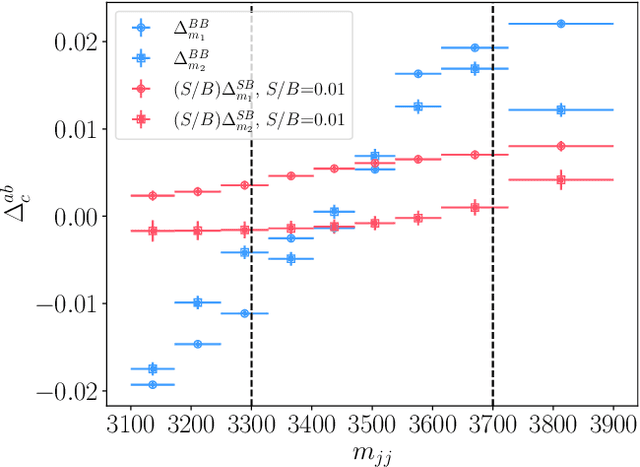
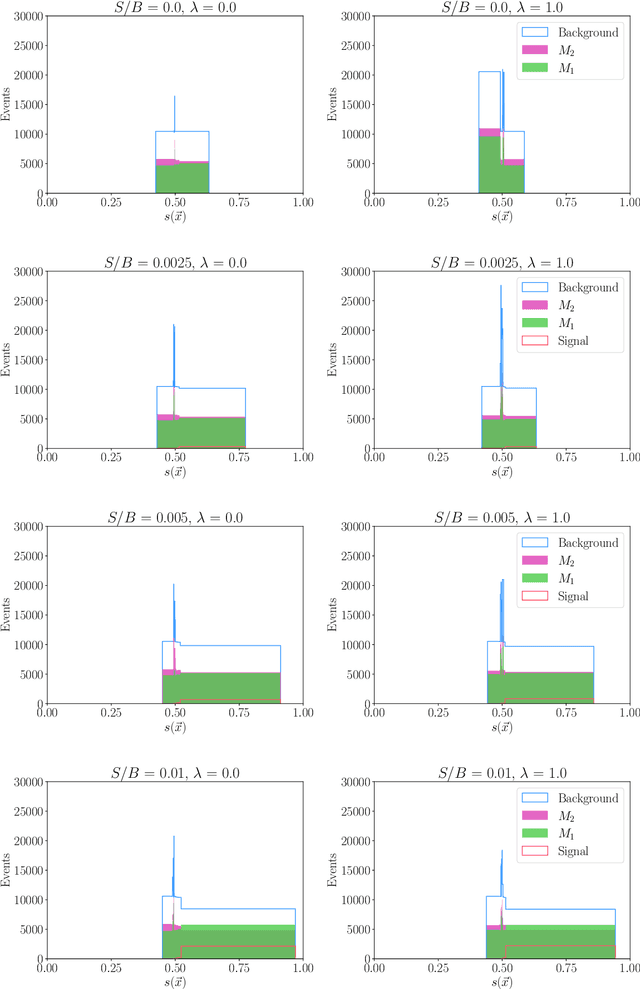
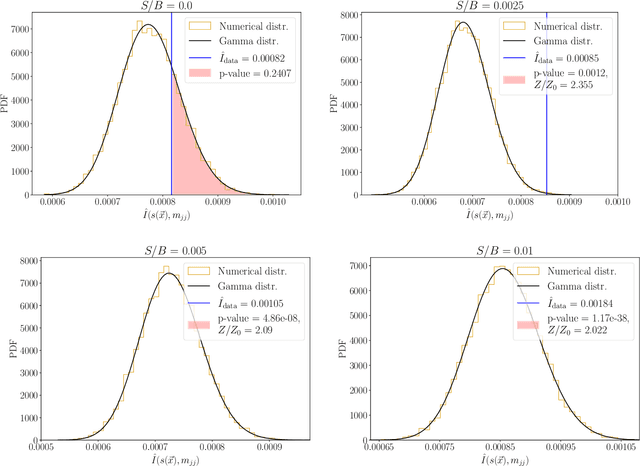
We extend the use of Classification Without Labels for anomaly detection with a hypothesis test designed to exclude the background-only hypothesis. By testing for statistical independence of the two discriminating dataset regions, we are able exclude the background-only hypothesis without relying on fixed anomaly score cuts or extrapolations of background estimates between regions. The method relies on the assumption of conditional independence of anomaly score features and dataset regions, which can be ensured using existing decorrelation techniques. As a benchmark example, we consider the LHC Olympics dataset where we show that mutual information represents a suitable test for statistical independence and our method exhibits excellent and robust performance at different signal fractions even in presence of realistic feature correlations.