 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Reversed Image Signal Processing and RAW Reconstruction. AIM 2022 Challenge Report
Oct 20, 2022
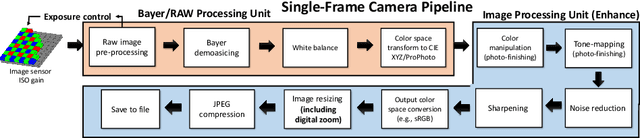
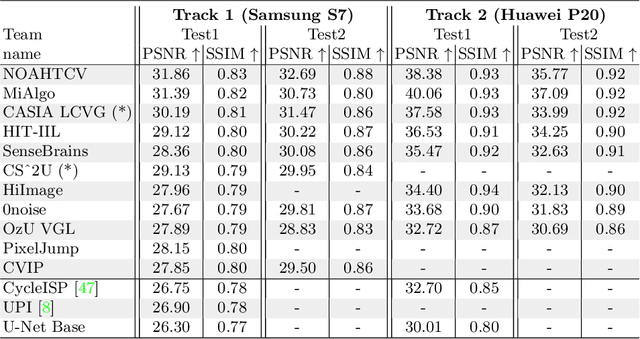
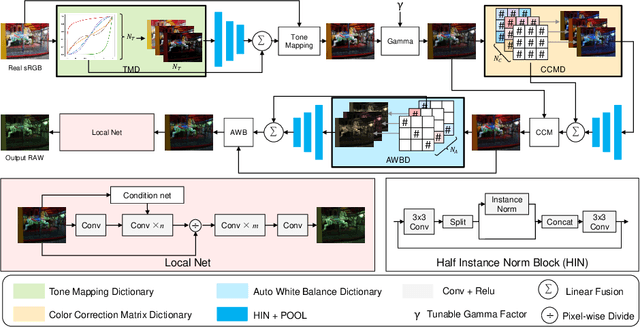
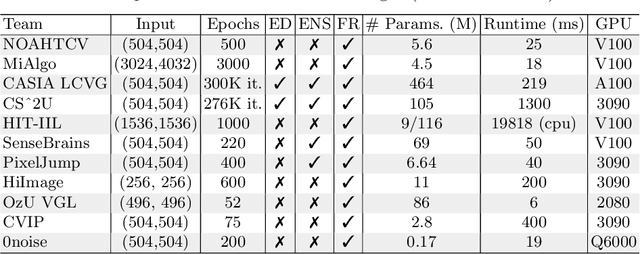
Cameras capture sensor RAW images and transform them into pleasant RGB images, suitable for the human eyes, using their integrated Image Signal Processor (ISP). Numerous low-level vision tasks operate in the RAW domain (e.g. image denoising, white balance) due to its linear relationship with the scene irradiance, wide-range of information at 12bits, and sensor designs. Despite this, RAW image datasets are scarce and more expensive to collect than the already large and public RGB datasets. This paper introduces the AIM 2022 Challenge on Reversed Image Signal Processing and RAW Reconstruction. We aim to recover raw sensor images from the corresponding RGBs without metadata and, by doing this, "reverse" the ISP transformation. The proposed methods and benchmark establish the state-of-the-art for this low-level vision inverse problem, and generating realistic raw sensor readings can potentially benefit other tasks such as denoising and super-resolution.
Learning Invariant Representation and Risk Minimized for Unsupervised Accent Domain Adaptation
Oct 15, 2022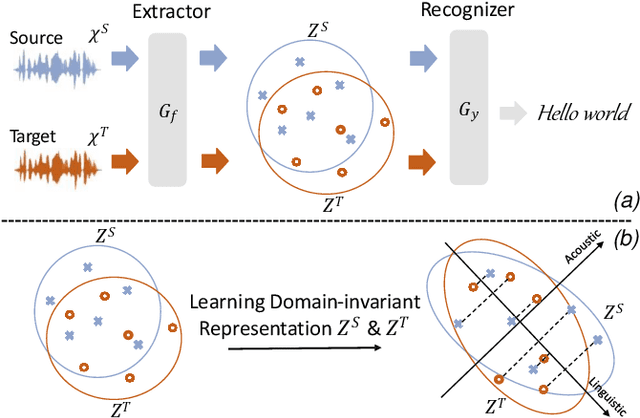
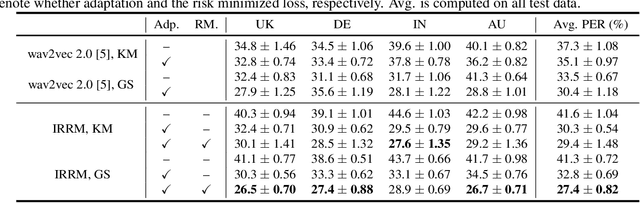
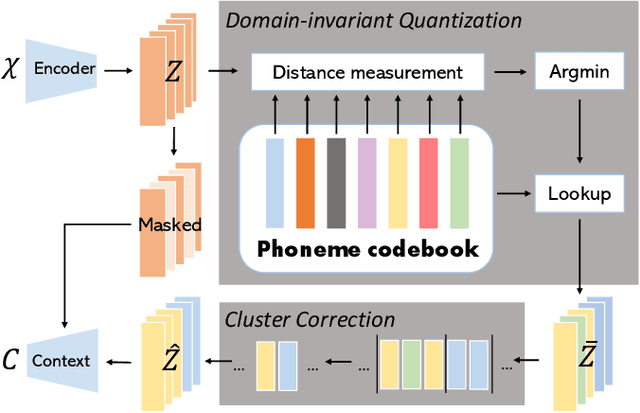

Unsupervised representation learning for speech audios attained impressive performances for speech recognition tasks, particularly when annotated speech is limited. However, the unsupervised paradigm needs to be carefully designed and little is known about what properties these representations acquire. There is no guarantee that the model learns meaningful representations for valuable information for recognition. Moreover, the adaptation ability of the learned representations to other domains still needs to be estimated. In this work, we explore learning domain-invariant representations via a direct mapping of speech representations to their corresponding high-level linguistic informations. Results prove that the learned latents not only capture the articulatory feature of each phoneme but also enhance the adaptation ability, outperforming the baseline largely on accented benchmarks.
Substructure-Atom Cross Attention for Molecular Representation Learning
Oct 15, 2022
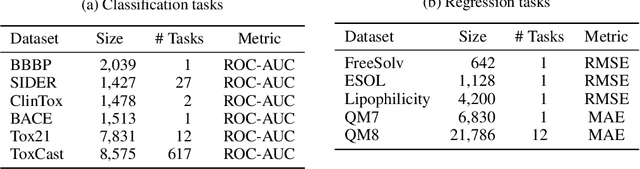
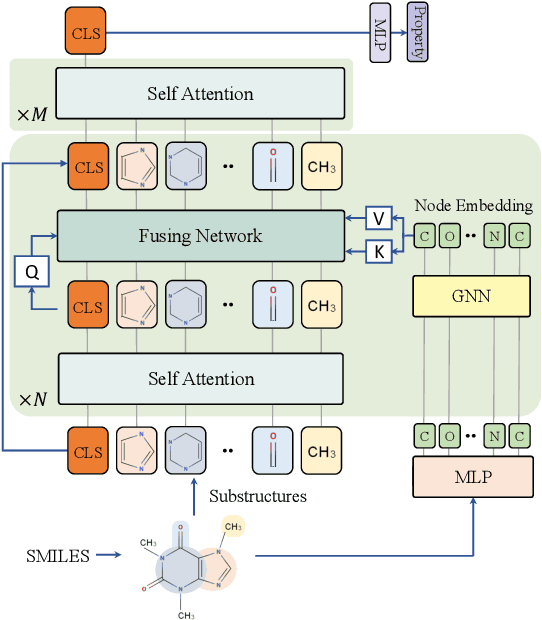
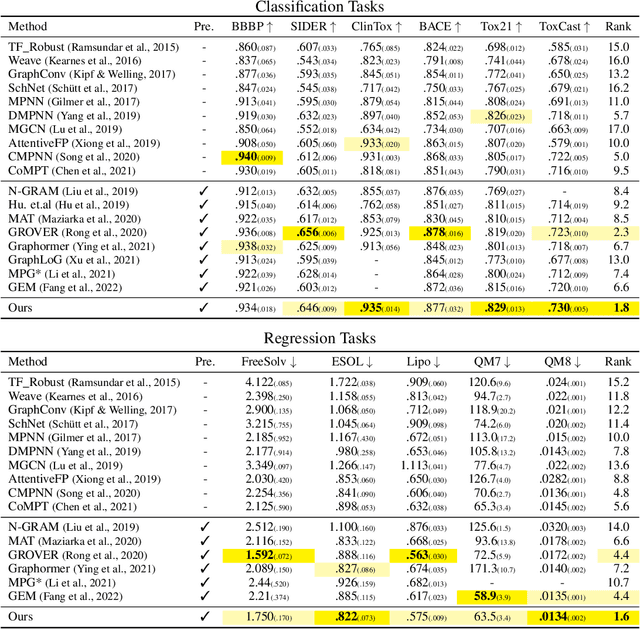
Designing a neural network architecture for molecular representation is crucial for AI-driven drug discovery and molecule design. In this work, we propose a new framework for molecular representation learning. Our contribution is threefold: (a) demonstrating the usefulness of incorporating substructures to node-wise features from molecules, (b) designing two branch networks consisting of a transformer and a graph neural network so that the networks fused with asymmetric attention, and (c) not requiring heuristic features and computationally-expensive information from molecules. Using 1.8 million molecules collected from ChEMBL and PubChem database, we pretrain our network to learn a general representation of molecules with minimal supervision. The experimental results show that our pretrained network achieves competitive performance on 11 downstream tasks for molecular property prediction.
COMBO: Pre-Training Representations of Binary Code Using Contrastive Learning
Oct 11, 2022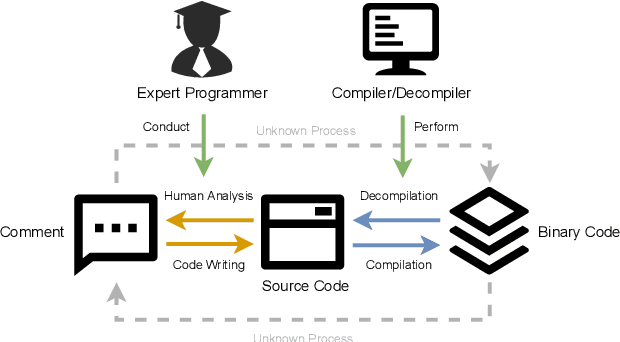
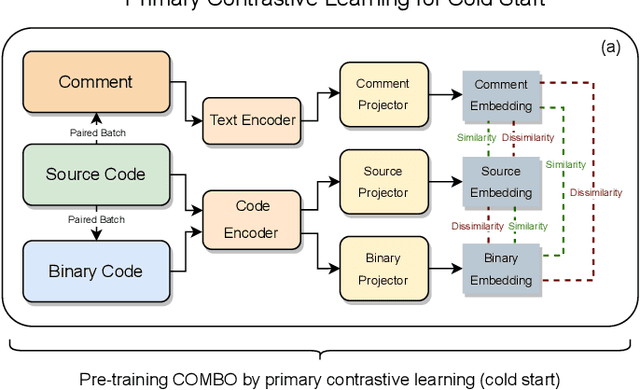
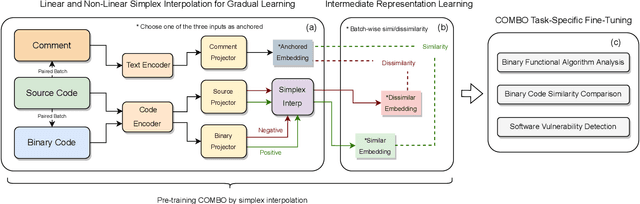
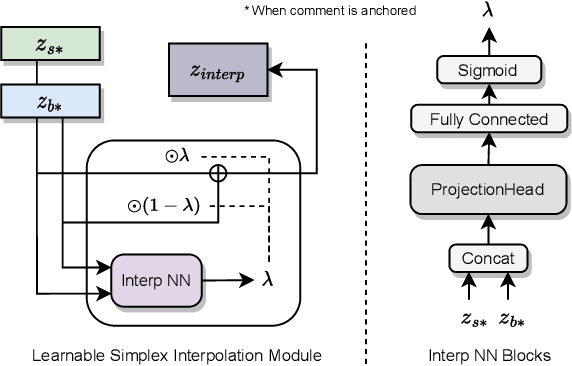
Compiled software is delivered as executable binary code. Developers write source code to express the software semantics, but the compiler converts it to a binary format that the CPU can directly execute. Therefore, binary code analysis is critical to applications in reverse engineering and computer security tasks where source code is not available. However, unlike source code and natural language that contain rich semantic information, binary code is typically difficult for human engineers to understand and analyze. While existing work uses AI models to assist source code analysis, few studies have considered binary code. In this paper, we propose a COntrastive learning Model for Binary cOde Analysis, or COMBO, that incorporates source code and comment information into binary code during representation learning. Specifically, we present three components in COMBO: (1) a primary contrastive learning method for cold-start pre-training, (2) a simplex interpolation method to incorporate source code, comments, and binary code, and (3) an intermediate representation learning algorithm to provide binary code embeddings. Finally, we evaluate the effectiveness of the pre-trained representations produced by COMBO using three indicative downstream tasks relating to binary code: algorithmic functionality classification, binary code similarity, and vulnerability detection. Our experimental results show that COMBO facilitates representation learning of binary code visualized by distribution analysis, and improves the performance on all three downstream tasks by 5.45% on average compared to state-of-the-art large-scale language representation models. To the best of our knowledge, COMBO is the first language representation model that incorporates source code, binary code, and comments into contrastive code representation learning and unifies multiple tasks for binary code analysis.
ForestQB: An Adaptive Query Builder to Support Wildlife Research
Oct 06, 2022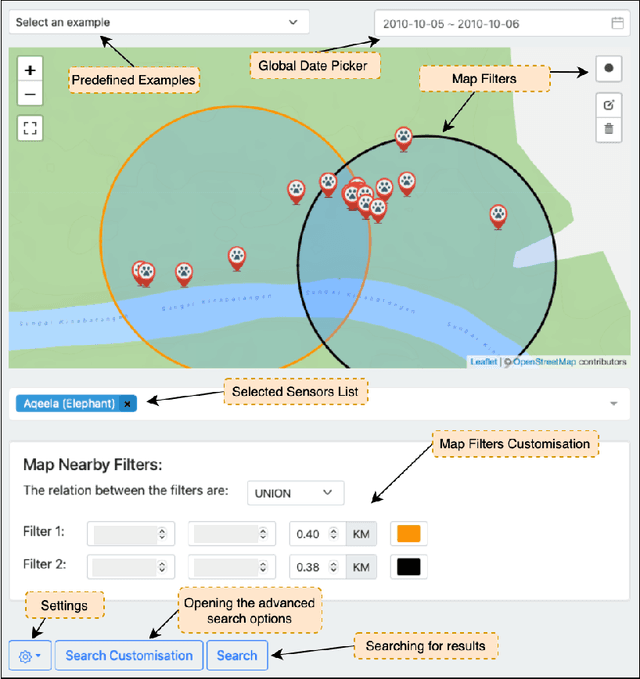
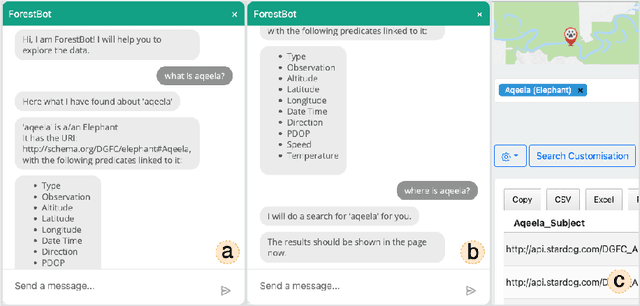
This paper presents ForestQB, a SPARQL query builder, to assist Bioscience and Wildlife Researchers in accessing Linked-Data. As they are unfamiliar with the Semantic Web and the data ontologies, ForestQB aims to empower them to benefit from using Linked-Data to extract valuable information without having to grasp the nature of the data and its underlying technologies. ForestQB is integrating Form-Based Query builders with Natural Language to simplify query construction to match the user requirements. Demo available at https://iotgarage.net/demo/forestQB
Explaining Cognitive Computing Through the Information Systems Lens
Jan 16, 2022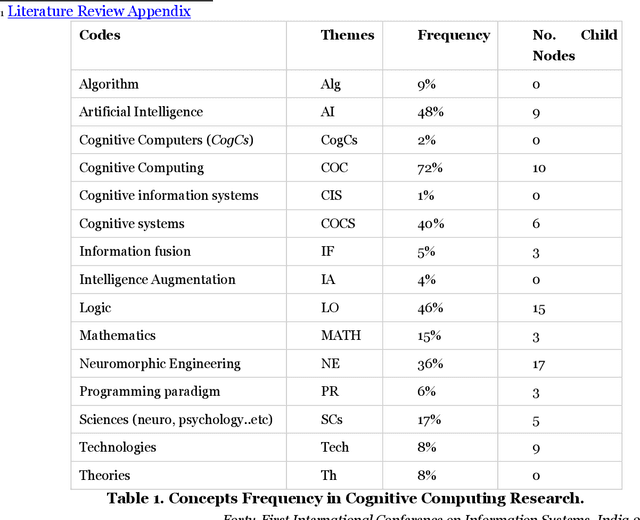
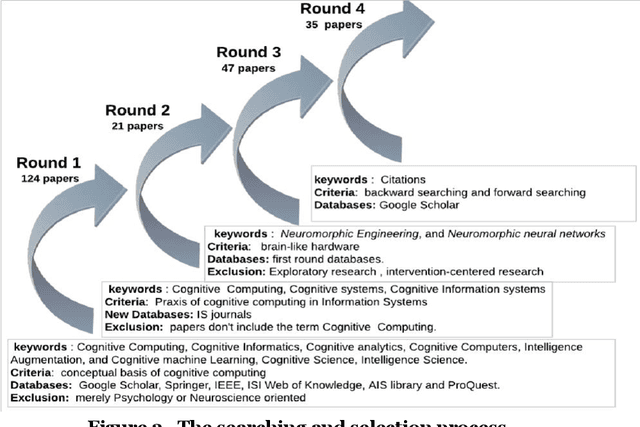

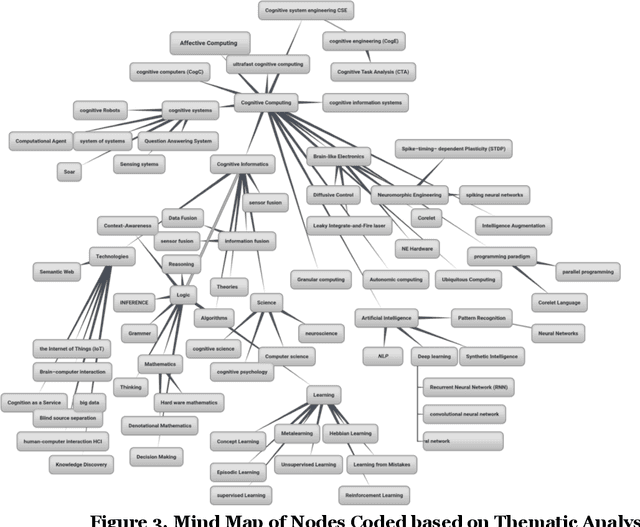
Cognitive computing (COC) aims to embed human cognition into computerized models. However, there is no scientific classification that delineates the nature of Cognitive Computing. Unlike the medical and computer science fields, Information Systems (IS) has conducted very little research on COC. Although the potential to make important research contributions in this area is great, we argue that the lack of a cohesive interpretation of what constitutes COC has led to inferior COC research in IS. Therefore, we need first to clearly identify COC as a phenomenon to be able to identify and guide prospective research areas in IS. In this research, a phenomenological approach is adopted using thematic analysis to the published literature in COC research. Then, we discuss how IS may contribute to the development of design science artifacts under the COC umbrella. In addition, the paper raises important questions for future research by highlighting how IS researchers could make meaningful contributions to this emerging topic.
Knowledge-grounded Dialog State Tracking
Oct 13, 2022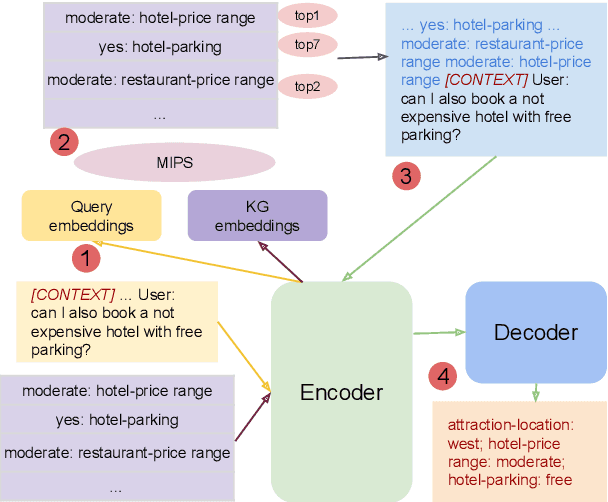
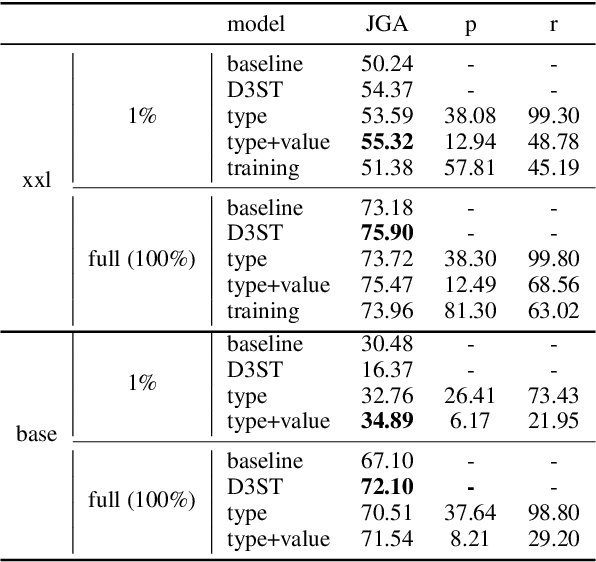
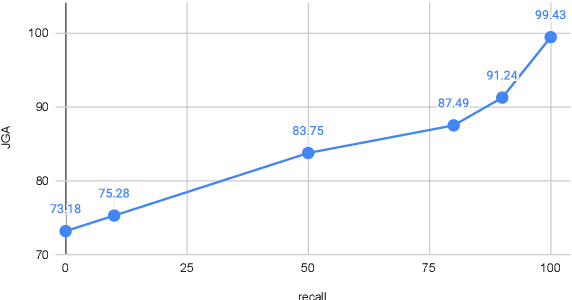
Knowledge (including structured knowledge such as schema and ontology, and unstructured knowledge such as web corpus) is a critical part of dialog understanding, especially for unseen tasks and domains. Traditionally, such domain-specific knowledge is encoded implicitly into model parameters for the execution of downstream tasks, which makes training inefficient. In addition, such models are not easily transferable to new tasks with different schemas. In this work, we propose to perform dialog state tracking grounded on knowledge encoded externally. We query relevant knowledge of various forms based on the dialog context where such information can ground the prediction of dialog states. We demonstrate superior performance of our proposed method over strong baselines, especially in the few-shot learning setting.
Chance-Constrained Motion Planning with Event-Triggered Estimation
Oct 13, 2022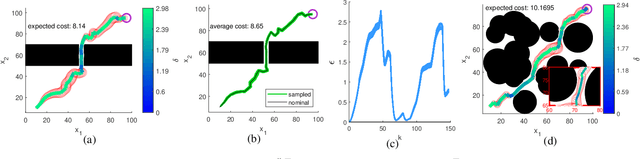
We consider the problem of autonomous navigation using limited information from a remote sensor network. Because the remote sensors are power and bandwidth limited, we use event-triggered (ET) estimation to manage communication costs. We introduce a fast and efficient sampling-based planner which computes motion plans coupled with ET communication strategies that minimize communication costs, while satisfying constraints on the probability of reaching the goal region and the point-wise probability of collision. We derive a novel method for offline propagation of the expected state distribution, and corresponding bounds on this distribution. These bounds are used to evaluate the chance constraints in the algorithm. Case studies establish the validity of our approach, demonstrating fast computation of optimal plans.
Speeding Up Action Recognition Using Dynamic Accumulation of Residuals in Compressed Domain
Sep 29, 2022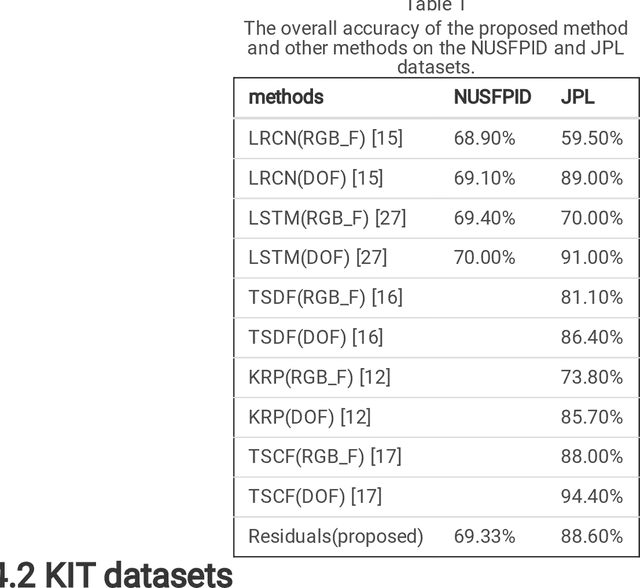
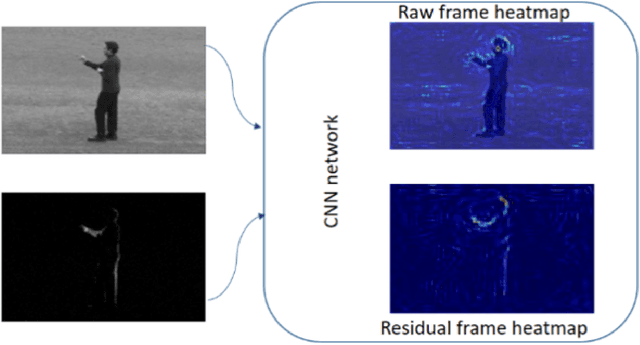

With the widespread use of installed cameras, video-based monitoring approaches have seized considerable attention for different purposes like assisted living. Temporal redundancy and the sheer size of raw videos are the two most common problematic issues related to video processing algorithms. Most of the existing methods mainly focused on increasing accuracy by exploring consecutive frames, which is laborious and cannot be considered for real-time applications. Since videos are mostly stored and transmitted in compressed format, these kinds of videos are available on many devices. Compressed videos contain a multitude of beneficial information, such as motion vectors and quantized coefficients. Proper use of this available information can greatly improve the video understanding methods' performance. This paper presents an approach for using residual data, available in compressed videos directly, which can be obtained by a light partially decoding procedure. In addition, a method for accumulating similar residuals is proposed, which dramatically reduces the number of processed frames for action recognition. Applying neural networks exclusively for accumulated residuals in the compressed domain accelerates performance, while the classification results are highly competitive with raw video approaches.
A Novel Frame Structure for Cloud-Based Audio-Visual Speech Enhancement in Multimodal Hearing-aids
Oct 24, 2022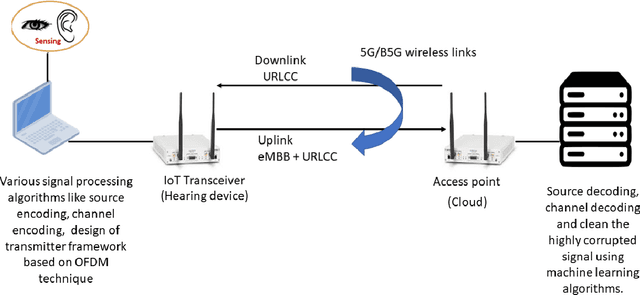
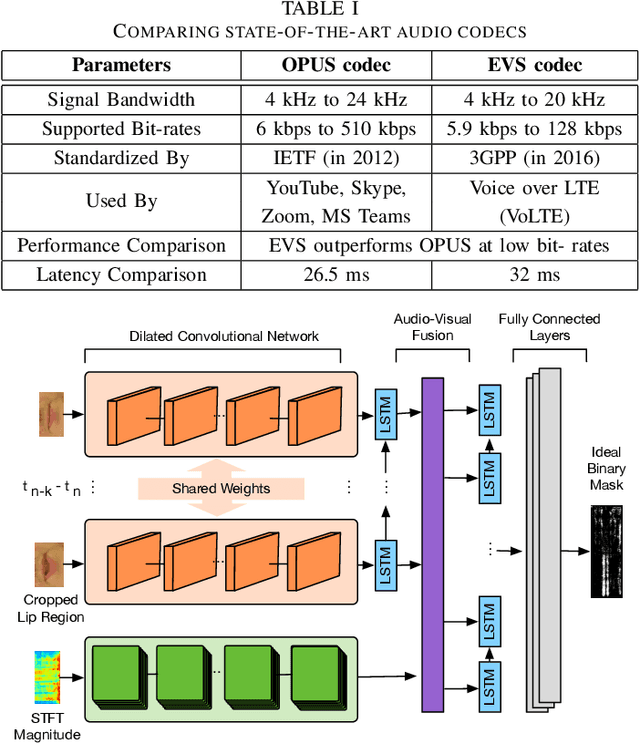
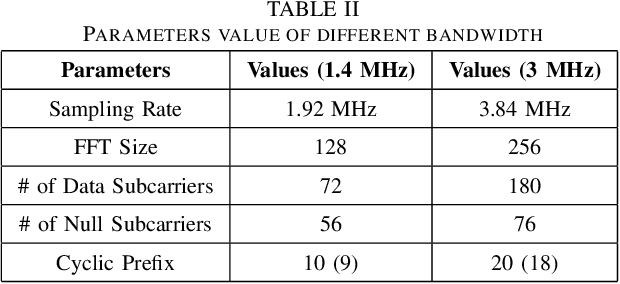
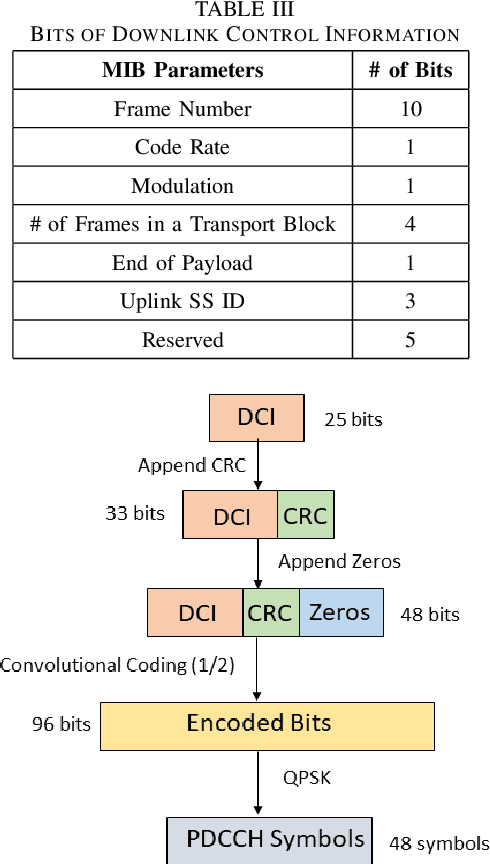
In this paper, we design a first of its kind transceiver (PHY layer) prototype for cloud-based audio-visual (AV) speech enhancement (SE) complying with high data rate and low latency requirements of future multimodal hearing assistive technology. The innovative design needs to meet multiple challenging constraints including up/down link communications, delay of transmission and signal processing, and real-time AV SE models processing. The transceiver includes device detection, frame detection, frequency offset estimation, and channel estimation capabilities. We develop both uplink (hearing aid to the cloud) and downlink (cloud to hearing aid) frame structures based on the data rate and latency requirements. Due to the varying nature of uplink information (audio and lip-reading), the uplink channel supports multiple data rate frame structure, while the downlink channel has a fixed data rate frame structure. In addition, we evaluate the latency of different PHY layer blocks of the transceiver for developed frame structures using LabVIEW NXG. This can be used with software defined radio (such as Universal Software Radio Peripheral) for real-time demonstration scenarios.