 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Waveformer: Linear-Time Attention with Forward and Backward Wavelet Transform
Oct 05, 2022
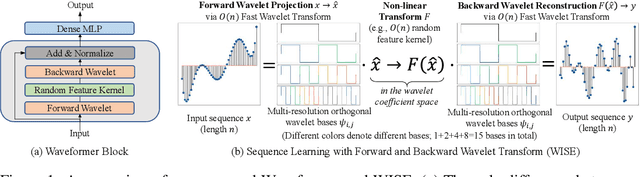
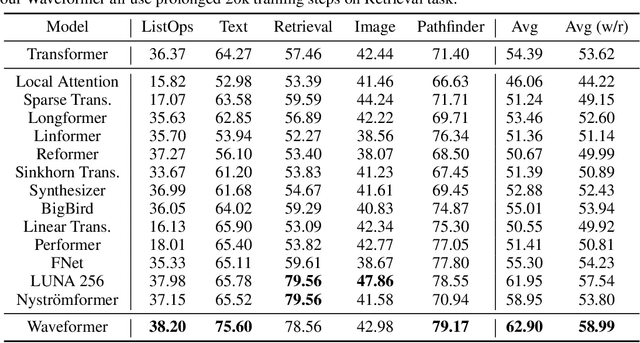
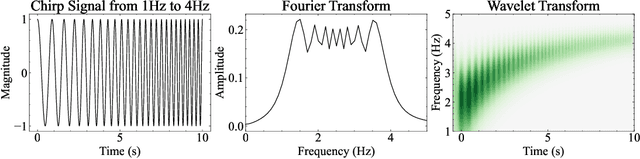

We propose Waveformer that learns attention mechanism in the wavelet coefficient space, requires only linear time complexity, and enjoys universal approximating power. Specifically, we first apply forward wavelet transform to project the input sequences to multi-resolution orthogonal wavelet bases, then conduct nonlinear transformations (in this case, a random feature kernel) in the wavelet coefficient space, and finally reconstruct the representation in input space via backward wavelet transform. We note that other non-linear transformations may be used, hence we name the learning paradigm Wavelet transformatIon for Sequence lEarning (WISE). We emphasize the importance of backward reconstruction in the WISE paradigm -- without it, one would be mixing information from both the input space and coefficient space through skip connections, which shall not be considered as mathematically sound. Compared with Fourier transform in recent works, wavelet transform is more efficient in time complexity and better captures local and positional information; we further support this through our ablation studies. Extensive experiments on seven long-range understanding datasets from the Long Range Arena benchmark and code understanding tasks demonstrate that (1) Waveformer achieves competitive and even better accuracy than a number of state-of-the-art Transformer variants and (2) WISE can boost accuracies of various attention approximation methods without increasing the time complexity. These together showcase the superiority of learning attention in a wavelet coefficient space over the input space.
Applying Word Embeddings to Measure Valence in Information Operations Targeting Journalists in Brazil
Jan 06, 2022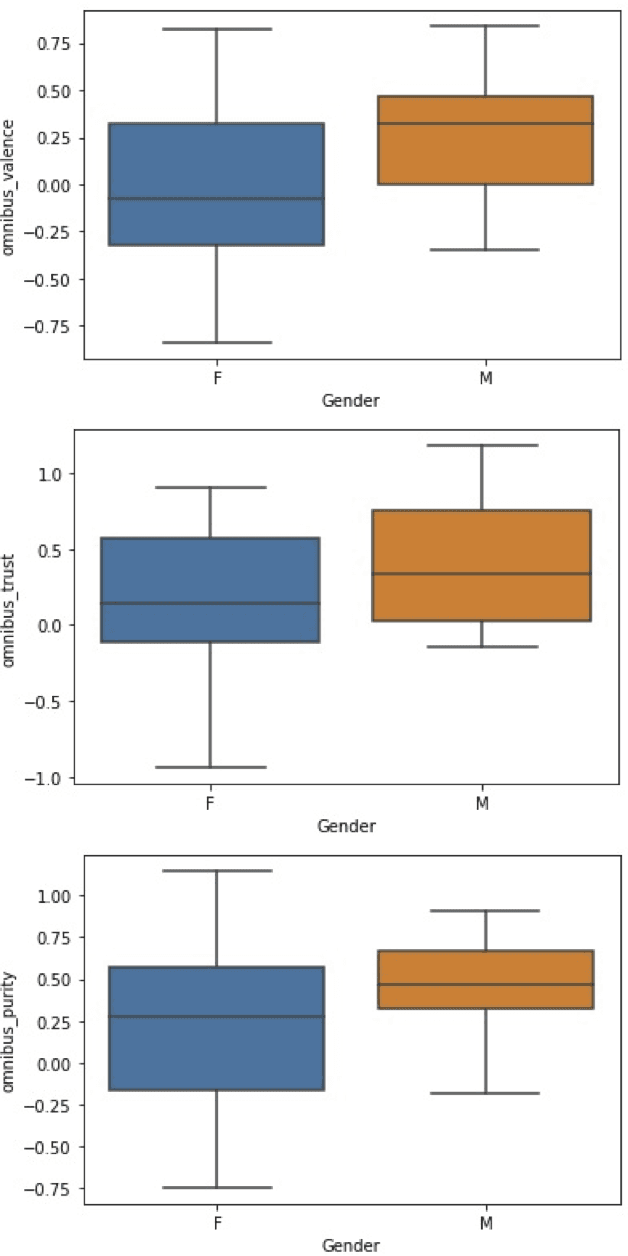
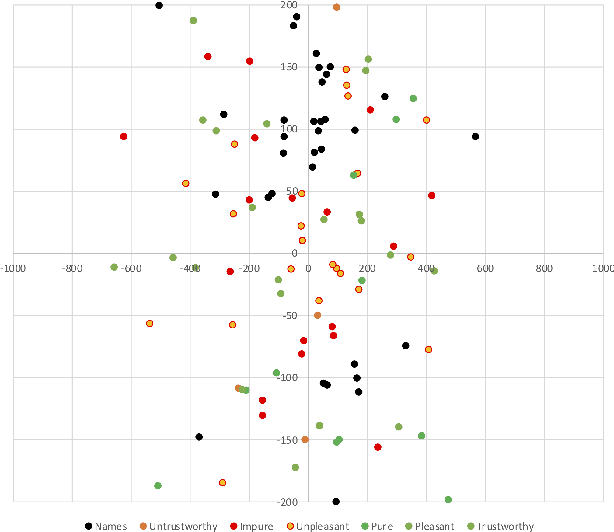
Among the goals of information operations are to change the overall information environment vis-\'a-vis specific actors. For example, "trolling campaigns" seek to undermine the credibility of specific public figures, leading others to distrust them and intimidating these figures into silence. To accomplish these aims, information operations frequently make use of "trolls" -- malicious online actors who target verbal abuse at these figures. In Brazil, in particular, allies of Brazil's current president have been accused of operating a "hate cabinet" -- a trolling operation that targets journalists who have alleged corruption by this politician and other members of his regime. Leading approaches to detecting harmful speech, such as Google's Perspective API, seek to identify specific messages with harmful content. While this approach is helpful in identifying content to downrank, flag, or remove, it is known to be brittle, and may miss attempts to introduce more subtle biases into the discourse. Here, we aim to develop a measure that might be used to assess how targeted information operations seek to change the overall valence, or appraisal, of specific actors. Preliminary results suggest known campaigns target female journalists more so than male journalists, and that these campaigns may leave detectable traces in overall Twitter discourse.
Towards Multi-spatiotemporal-scale Generalized PDE Modeling
Sep 30, 2022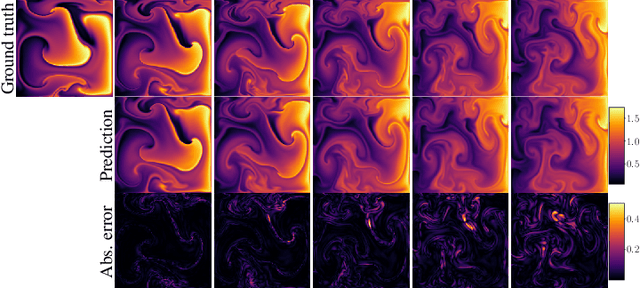
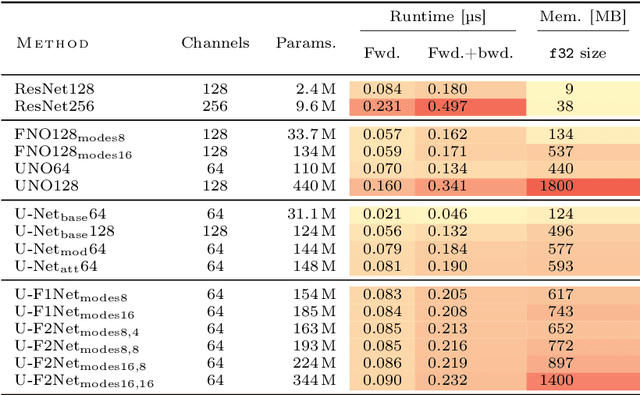
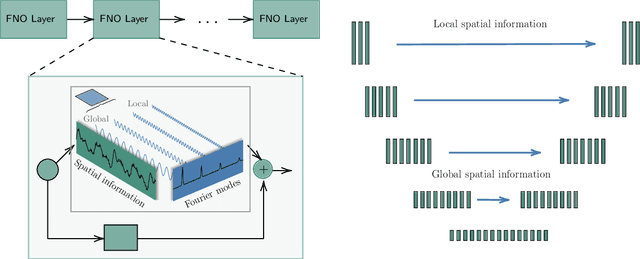
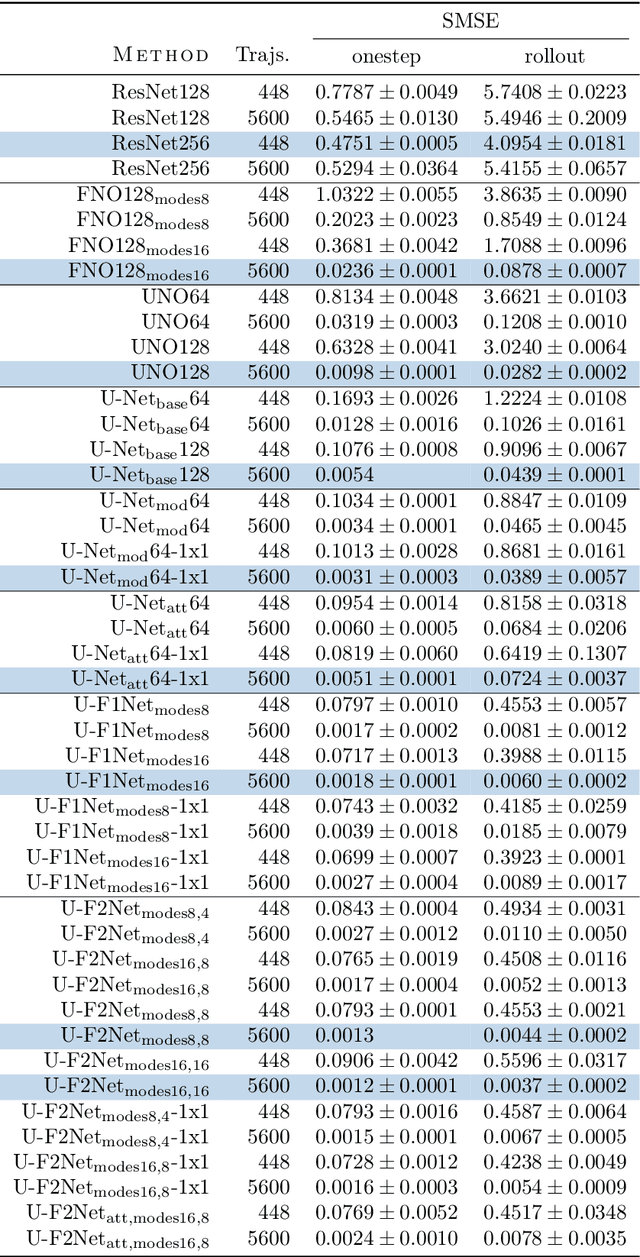
Partial differential equations (PDEs) are central to describing complex physical system simulations. Their expensive solution techniques have led to an increased interest in deep neural network based surrogates. However, the practical utility of training such surrogates is contingent on their ability to model complex multi-scale spatio-temporal phenomena. Various neural network architectures have been proposed to target such phenomena, most notably Fourier Neural Operators (FNOs) which give a natural handle over local \& global spatial information via parameterization of different Fourier modes, and U-Nets which treat local and global information via downsampling and upsampling paths. However, generalizing across different equation parameters or different time-scales still remains a challenge. In this work, we make a comprehensive comparison between various FNO and U-Net like approaches on fluid mechanics problems in both vorticity-stream and velocity function form. For U-Nets, we transfer recent architectural improvements from computer vision, most notably from object segmentation and generative modeling. We further analyze the design considerations for using FNO layers to improve performance of U-Net architectures without major degradation of computational performance. Finally, we show promising results on generalization to different PDE parameters and time-scales with a single surrogate model.
Visual Semantic Parsing: From Images to Abstract Meaning Representation
Oct 27, 2022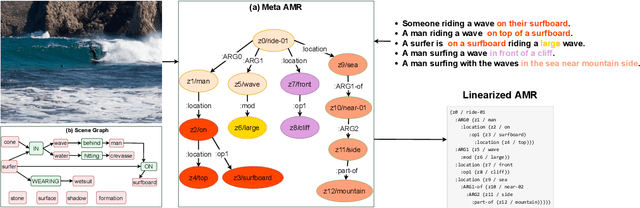
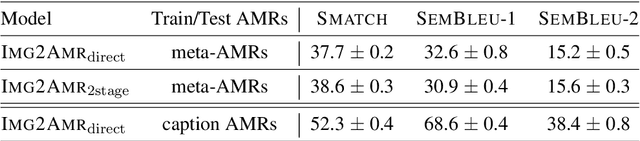
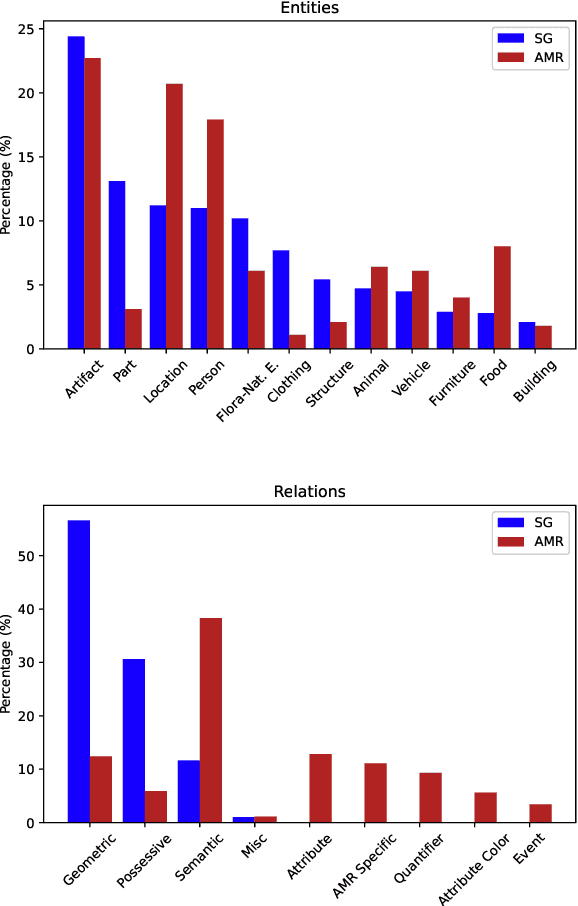

The success of scene graphs for visual scene understanding has brought attention to the benefits of abstracting a visual input (e.g., image) into a structured representation, where entities (people and objects) are nodes connected by edges specifying their relations. Building these representations, however, requires expensive manual annotation in the form of images paired with their scene graphs or frames. These formalisms remain limited in the nature of entities and relations they can capture. In this paper, we propose to leverage a widely-used meaning representation in the field of natural language processing, the Abstract Meaning Representation (AMR), to address these shortcomings. Compared to scene graphs, which largely emphasize spatial relationships, our visual AMR graphs are more linguistically informed, with a focus on higher-level semantic concepts extrapolated from visual input. Moreover, they allow us to generate meta-AMR graphs to unify information contained in multiple image descriptions under one representation. Through extensive experimentation and analysis, we demonstrate that we can re-purpose an existing text-to-AMR parser to parse images into AMRs. Our findings point to important future research directions for improved scene understanding.
Contextual-Utterance Training for Automatic Speech Recognition
Oct 27, 2022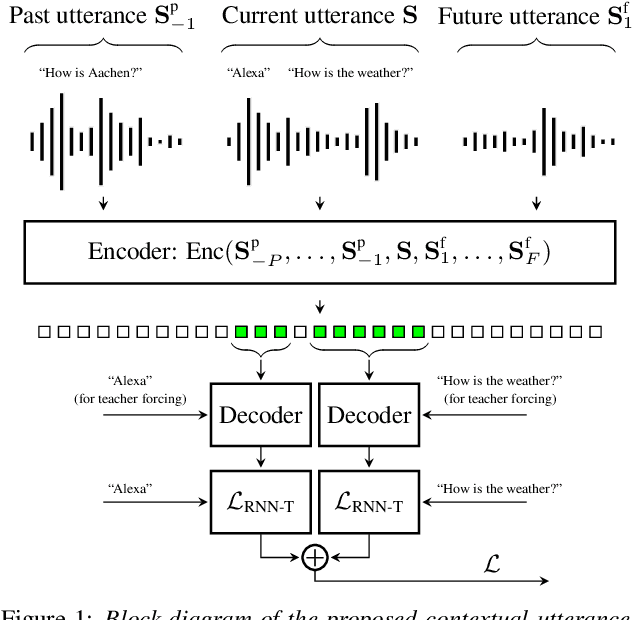
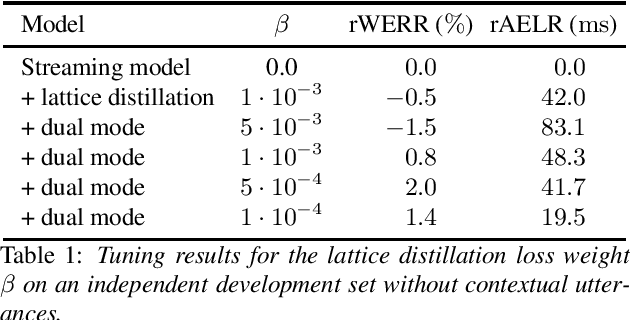
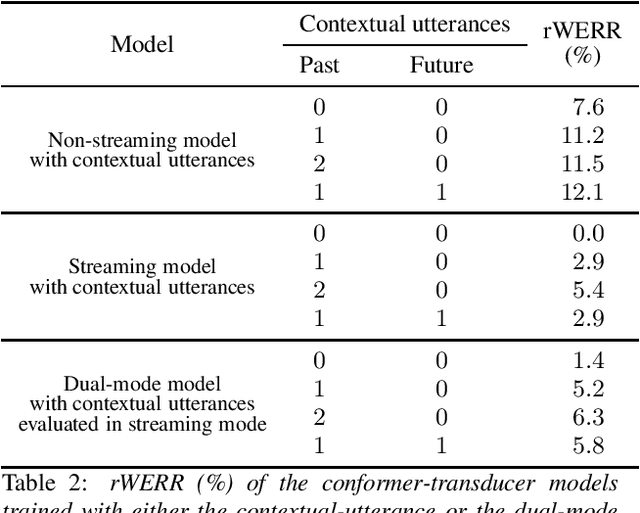

Recent studies of streaming automatic speech recognition (ASR) recurrent neural network transducer (RNN-T)-based systems have fed the encoder with past contextual information in order to improve its word error rate (WER) performance. In this paper, we first propose a contextual-utterance training technique which makes use of the previous and future contextual utterances in order to do an implicit adaptation to the speaker, topic and acoustic environment. Also, we propose a dual-mode contextual-utterance training technique for streaming automatic speech recognition (ASR) systems. This proposed approach allows to make a better use of the available acoustic context in streaming models by distilling "in-place" the knowledge of a teacher, which is able to see both past and future contextual utterances, to the student which can only see the current and past contextual utterances. The experimental results show that a conformer-transducer system trained with the proposed techniques outperforms the same system trained with the classical RNN-T loss. Specifically, the proposed technique is able to reduce both the WER and the average last token emission latency by more than 6% and 40ms relative, respectively.
Joint Localization and Beamforming for Reconfigurable Intelligent Surface Aided 5G mmWave Communication Systems
Oct 27, 2022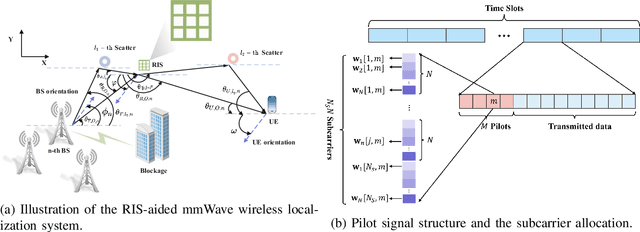
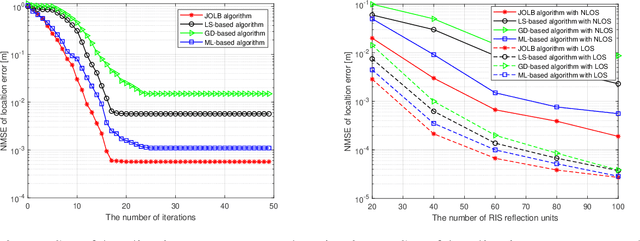
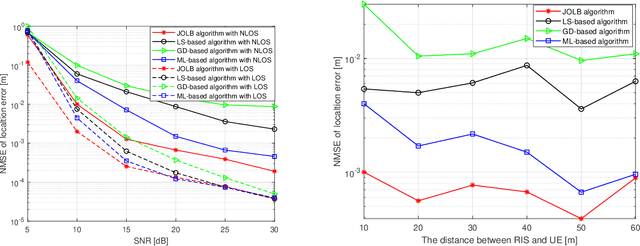
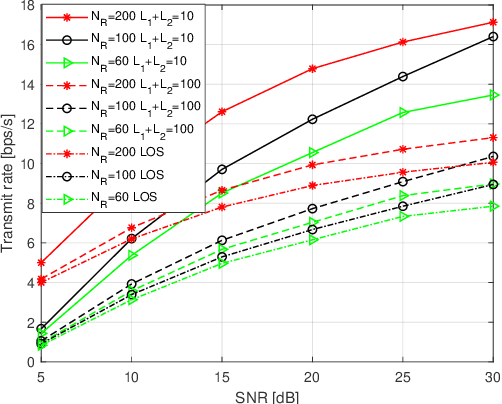
Reconfigurable intelligent surface (RIS) is an attractive technology to improve the transmission rate of millimetre-wave (mmWave) communication systems. The previous {research} on RIS technology mainly focused on improving the transmission rate and security rate of the mmWave communication systems. Since the emergence of RIS technology creates the conditions for generating an intelligent radio environment, it also has potential advantages on improving the localization accuracy of the mmWave communication systems. Deployed on walls and objects, RISs are capable of significantly improving communications and positioning coverage by controlling the multi-path reflection. This paper considers the RIS-aided mmWave localization system and proposes a joint beamforming and localization problem. However, since the objective function depends on the unknown UE's position and instantaneous channel state information (CSI), this beamforming and localization technology based on RIS assistance is challenging. To solve this problem, we propose a new joint localization and beamforming optimization (JLBO) algorithm, and give the proof of its convergence. The simulation results show that the RIS can improve the user localization accuracy of the system and the proposed scheme has a significant performance improvement compared with the traditional schemes.
Masked Transformer for image Anomaly Localization
Oct 27, 2022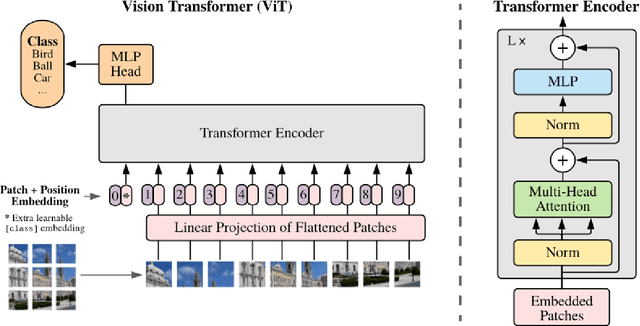
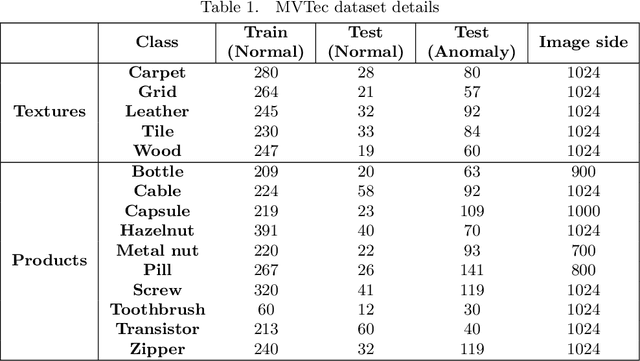
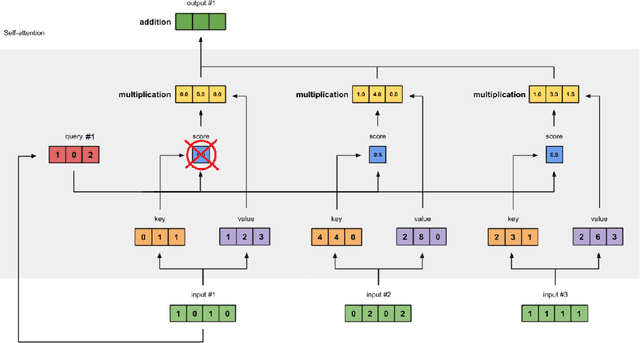

Image anomaly detection consists in detecting images or image portions that are visually different from the majority of the samples in a dataset. The task is of practical importance for various real-life applications like biomedical image analysis, visual inspection in industrial production, banking, traffic management, etc. Most of the current deep learning approaches rely on image reconstruction: the input image is projected in some latent space and then reconstructed, assuming that the network (mostly trained on normal data) will not be able to reconstruct the anomalous portions. However, this assumption does not always hold. We thus propose a new model based on the Vision Transformer architecture with patch masking: the input image is split in several patches, and each patch is reconstructed only from the surrounding data, thus ignoring the potentially anomalous information contained in the patch itself. We then show that multi-resolution patches and their collective embeddings provide a large improvement in the model's performance compared to the exclusive use of the traditional square patches. The proposed model has been tested on popular anomaly detection datasets such as MVTec and head CT and achieved good results when compared to other state-of-the-art approaches.
Multi-stage image denoising with the wavelet transform
Sep 27, 2022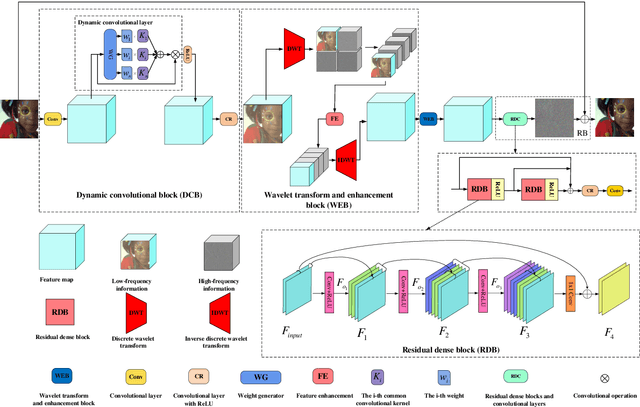
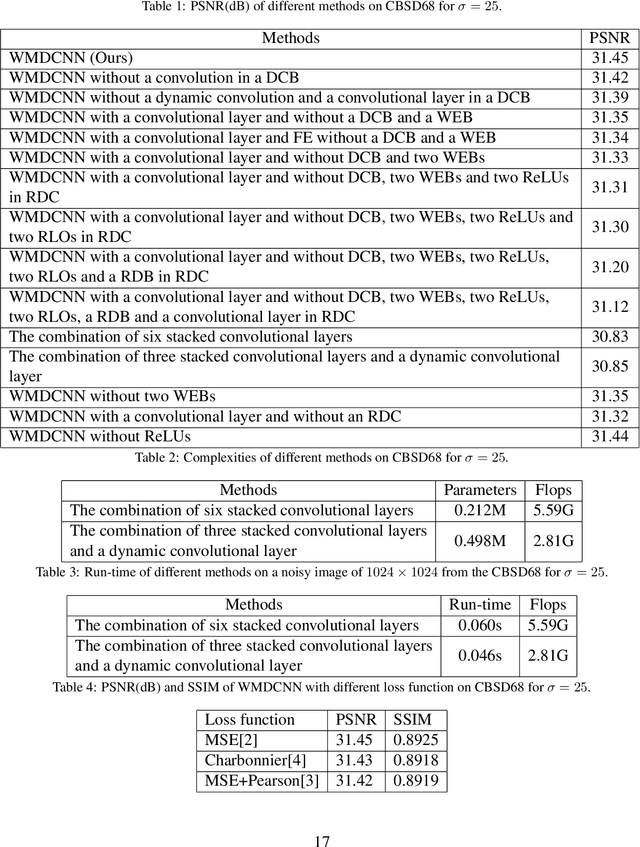
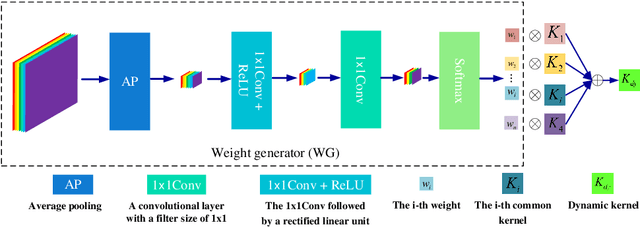
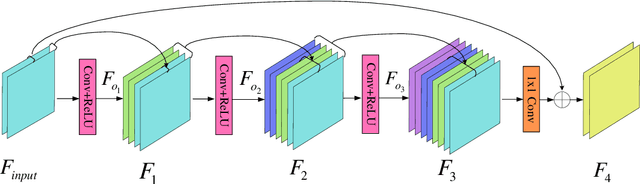
Deep convolutional neural networks (CNNs) are used for image denoising via automatically mining accurate structure information. However, most of existing CNNs depend on enlarging depth of designed networks to obtain better denoising performance, which may cause training difficulty. In this paper, we propose a multi-stage image denoising CNN with the wavelet transform (MWDCNN) via three stages, i.e., a dynamic convolutional block (DCB), two cascaded wavelet transform and enhancement blocks (WEBs) and residual block (RB). DCB uses a dynamic convolution to dynamically adjust parameters of several convolutions for making a tradeoff between denoising performance and computational costs. WEB uses a combination of signal processing technique (i.e., wavelet transformation) and discriminative learning to suppress noise for recovering more detailed information in image denoising. To further remove redundant features, RB is used to refine obtained features for improving denoising effects and reconstruct clean images via improved residual dense architectures. Experimental results show that the proposed MWDCNN outperforms some popular denoising methods in terms of quantitative and qualitative analysis. Codes are available at https://github.com/hellloxiaotian/MWDCNN.
CycleFlow: Purify Information Factors by Cycle Loss
Oct 20, 2021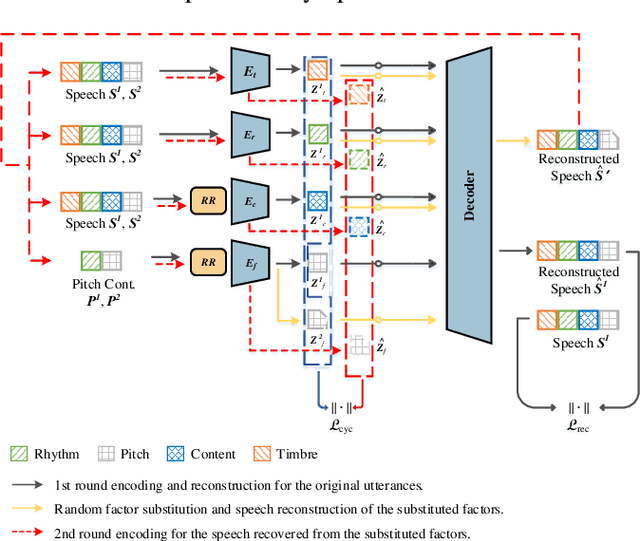
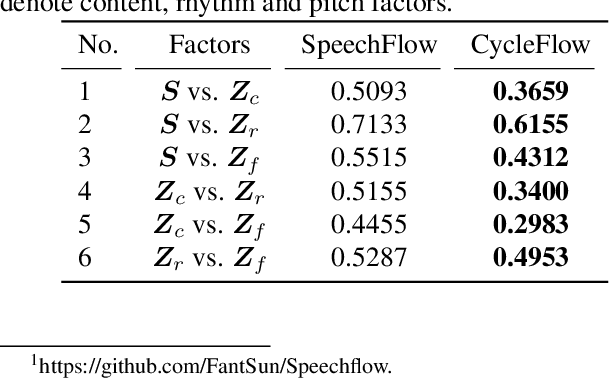
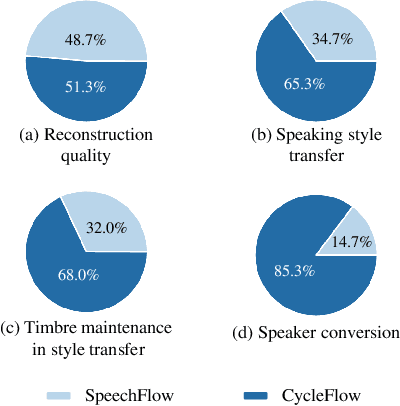
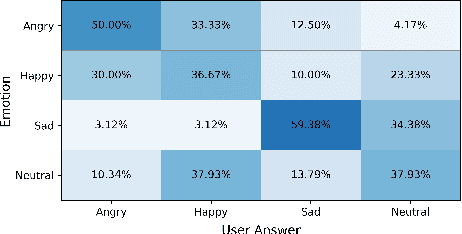
SpeechFlow is a powerful factorization model based on information bottleneck (IB), and its effectiveness has been reported by several studies. A potential problem of SpeechFlow, however, is that if the IB channels are not well designed, the resultant factors cannot be well disentangled. In this study, we propose a CycleFlow model that combines random factor substitution and cycle loss to solve this problem. Experiments on voice conversion tasks demonstrate that this simple technique can effectively reduce mutual information among individual factors, and produce clearly better conversion than the IB-based SpeechFlow. CycleFlow can also be used as a powerful tool for speech editing. We demonstrate this usage by an emotion perception experiment.
$BT^2$: Backward-compatible Training with Basis Transformation
Nov 08, 2022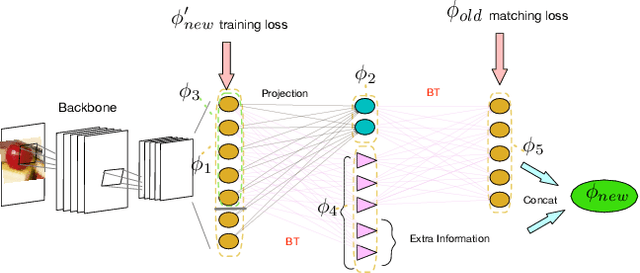
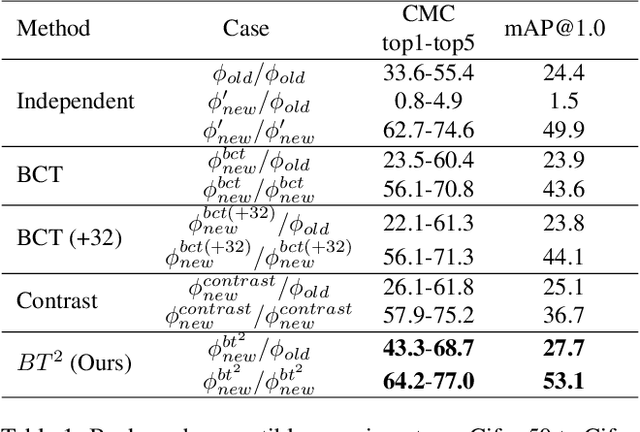
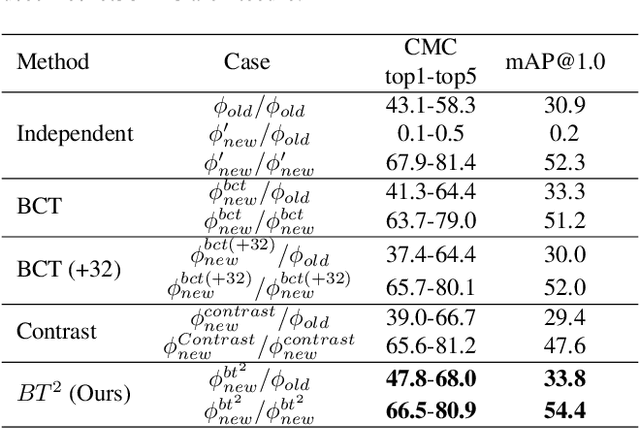
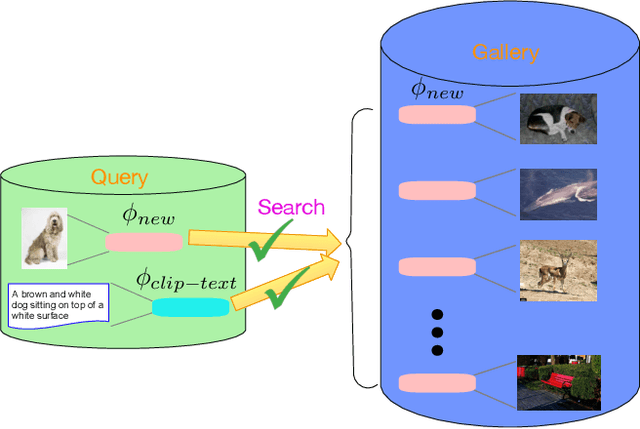
Modern retrieval system often requires recomputing the representation of every piece of data in the gallery when updating to a better representation model. This process is known as backfilling and can be especially costly in the real world where the gallery often contains billions of samples. Recently, researchers have proposed the idea of Backward Compatible Training (BCT) where the new representation model can be trained with an auxiliary loss to make it backward compatible with the old representation. In this way, the new representation can be directly compared with the old representation, in principle avoiding the need for any backfilling. However, followup work shows that there is an inherent tradeoff where a backward compatible representation model cannot simultaneously maintain the performance of the new model itself. This paper reports our ``not-so-surprising'' finding that adding extra dimensions to the representation can help here. However, we also found that naively increasing the dimension of the representation did not work. To deal with this, we propose Backward-compatible Training with a novel Basis Transformation ($BT^2$). A basis transformation (BT) is basically a learnable set of parameters that applies an orthonormal transformation. Such a transformation possesses an important property whereby the original information contained in its input is retained in its output. We show in this paper how a BT can be utilized to add only the necessary amount of additional dimensions. We empirically verify the advantage of $BT^2$ over other state-of-the-art methods in a wide range of settings. We then further extend $BT^2$ to other challenging yet more practical settings, including significant change in model architecture (CNN to Transformers), modality change, and even a series of updates in the model architecture mimicking the evolution of deep learning models.