 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CMR3D: Contextualized Multi-Stage Refinement for 3D Object Detection
Sep 13, 2022
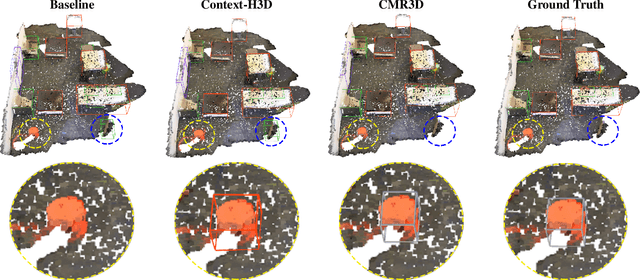
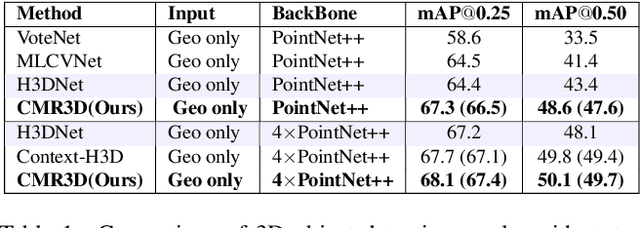
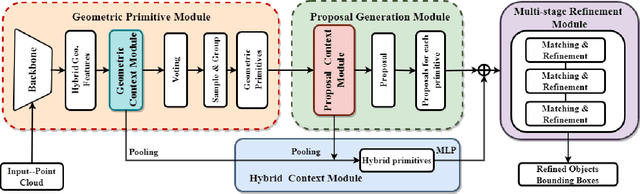

Existing deep learning-based 3D object detectors typically rely on the appearance of individual objects and do not explicitly pay attention to the rich contextual information of the scene. In this work, we propose Contextualized Multi-Stage Refinement for 3D Object Detection (CMR3D) framework, which takes a 3D scene as input and strives to explicitly integrate useful contextual information of the scene at multiple levels to predict a set of object bounding-boxes along with their corresponding semantic labels. To this end, we propose to utilize a context enhancement network that captures the contextual information at different levels of granularity followed by a multi-stage refinement module to progressively refine the box positions and class predictions. Extensive experiments on the large-scale ScanNetV2 benchmark reveal the benefits of our proposed method, leading to an absolute improvement of 2.0% over the baseline. In addition to 3D object detection, we investigate the effectiveness of our CMR3D framework for the problem of 3D object counting. Our source code will be publicly released.
Meta-Gradients in Non-Stationary Environments
Sep 13, 2022
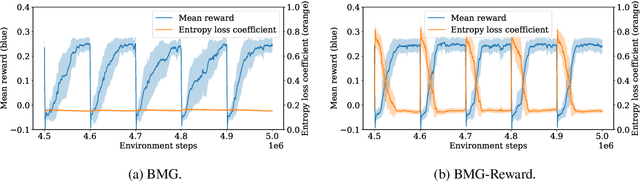
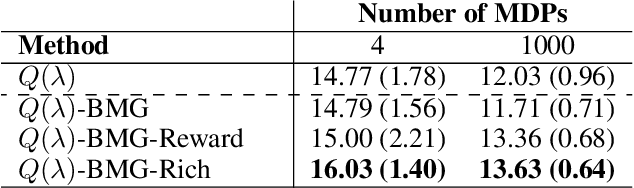
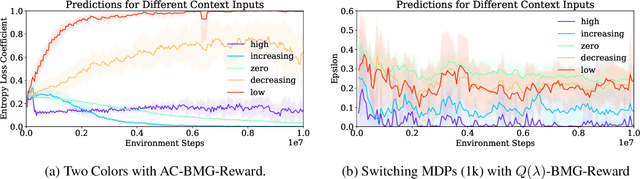
Meta-gradient methods (Xu et al., 2018; Zahavy et al., 2020) offer a promising solution to the problem of hyperparameter selection and adaptation in non-stationary reinforcement learning problems. However, the properties of meta-gradients in such environments have not been systematically studied. In this work, we bring new clarity to meta-gradients in non-stationary environments. Concretely, we ask: (i) how much information should be given to the learned optimizers, so as to enable faster adaptation and generalization over a lifetime, (ii) what meta-optimizer functions are learned in this process, and (iii) whether meta-gradient methods provide a bigger advantage in highly non-stationary environments. To study the effect of information provided to the meta-optimizer, as in recent works (Flennerhag et al., 2021; Almeida et al., 2021), we replace the tuned meta-parameters of fixed update rules with learned meta-parameter functions of selected context features. The context features carry information about agent performance and changes in the environment and hence can inform learned meta-parameter schedules. We find that adding more contextual information is generally beneficial, leading to faster adaptation of meta-parameter values and increased performance over a lifetime. We support these results with a qualitative analysis of resulting meta-parameter schedules and learned functions of context features. Lastly, we find that without context, meta-gradients do not provide a consistent advantage over the baseline in highly non-stationary environments. Our findings suggest that contextualizing meta-gradients can play a pivotal role in extracting high performance from meta-gradients in non-stationary settings.
An Information-theoretical Approach to Semi-supervised Learning under Covariate-shift
Feb 24, 2022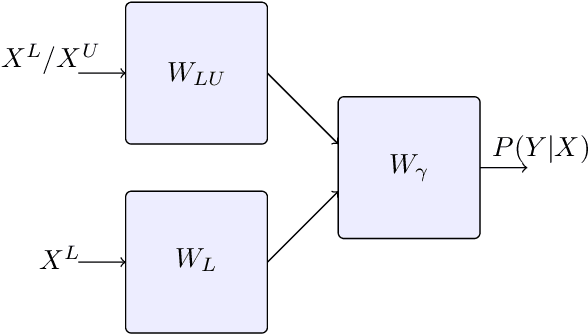

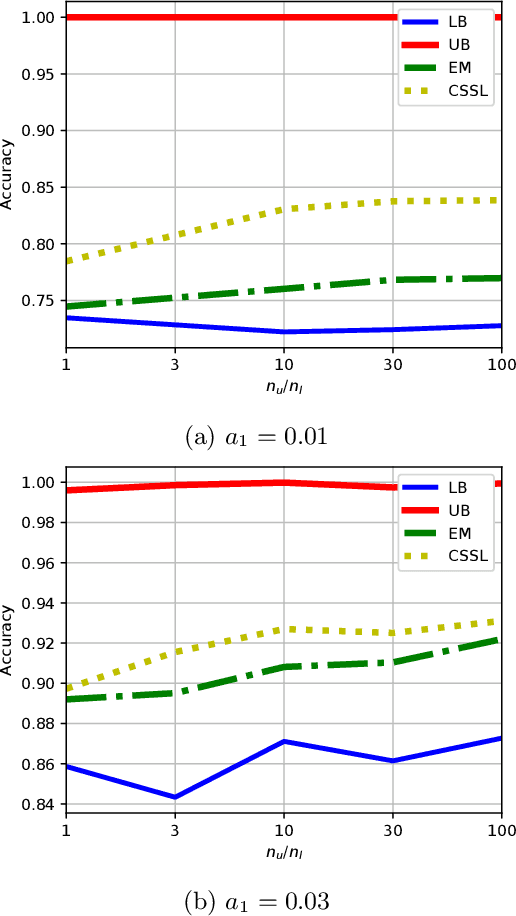
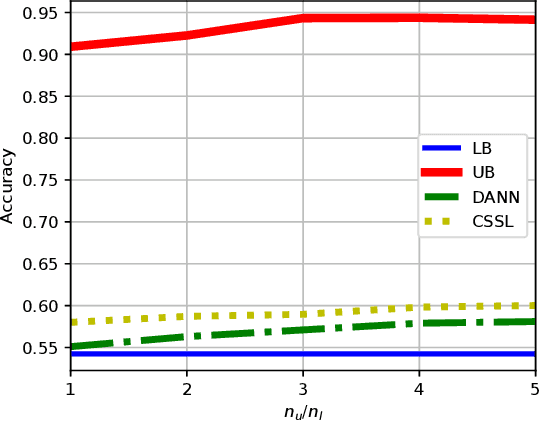
A common assumption in semi-supervised learning is that the labeled, unlabeled, and test data are drawn from the same distribution. However, this assumption is not satisfied in many applications. In many scenarios, the data is collected sequentially (e.g., healthcare) and the distribution of the data may change over time often exhibiting so-called covariate shifts. In this paper, we propose an approach for semi-supervised learning algorithms that is capable of addressing this issue. Our framework also recovers some popular methods, including entropy minimization and pseudo-labeling. We provide new information-theoretical based generalization error upper bounds inspired by our novel framework. Our bounds are applicable to both general semi-supervised learning and the covariate-shift scenario. Finally, we show numerically that our method outperforms previous approaches proposed for semi-supervised learning under the covariate shift.
FusionRCNN: LiDAR-Camera Fusion for Two-stage 3D Object Detection
Sep 22, 2022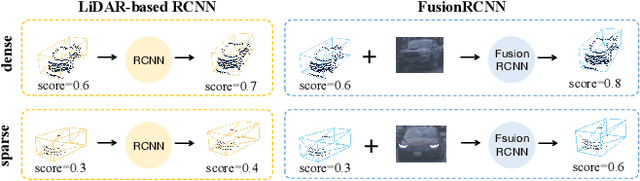
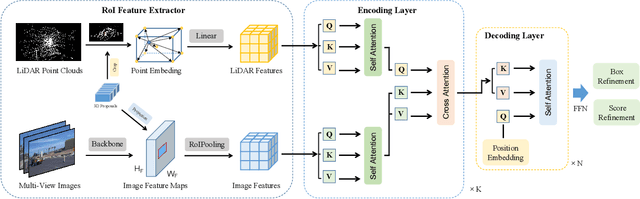
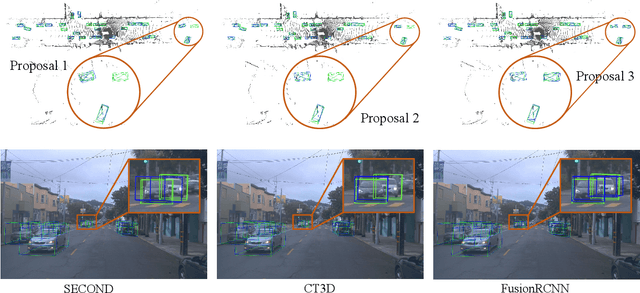
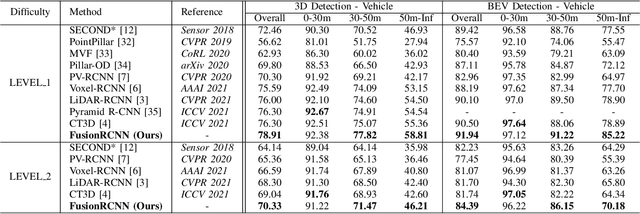
3D object detection with multi-sensors is essential for an accurate and reliable perception system of autonomous driving and robotics. Existing 3D detectors significantly improve the accuracy by adopting a two-stage paradigm which merely relies on LiDAR point clouds for 3D proposal refinement. Though impressive, the sparsity of point clouds, especially for the points far away, making it difficult for the LiDAR-only refinement module to accurately recognize and locate objects.To address this problem, we propose a novel multi-modality two-stage approach named FusionRCNN, which effectively and efficiently fuses point clouds and camera images in the Regions of Interest(RoI). FusionRCNN adaptively integrates both sparse geometry information from LiDAR and dense texture information from camera in a unified attention mechanism. Specifically, it first utilizes RoIPooling to obtain an image set with a unified size and gets the point set by sampling raw points within proposals in the RoI extraction step; then leverages an intra-modality self-attention to enhance the domain-specific features, following by a well-designed cross-attention to fuse the information from two modalities.FusionRCNN is fundamentally plug-and-play and supports different one-stage methods with almost no architectural changes. Extensive experiments on KITTI and Waymo benchmarks demonstrate that our method significantly boosts the performances of popular detectors.Remarkably, FusionRCNN significantly improves the strong SECOND baseline by 6.14% mAP on Waymo, and outperforms competing two-stage approaches. Code will be released soon at https://github.com/xxlbigbrother/Fusion-RCNN.
Deep Learning Based Detection of Enlarged Perivascular Spaces on Brain MRI
Sep 27, 2022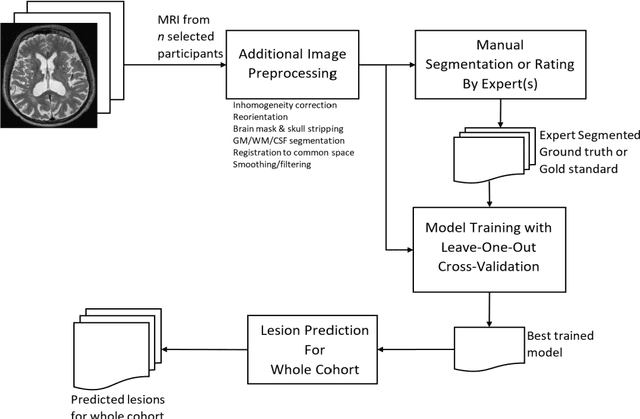
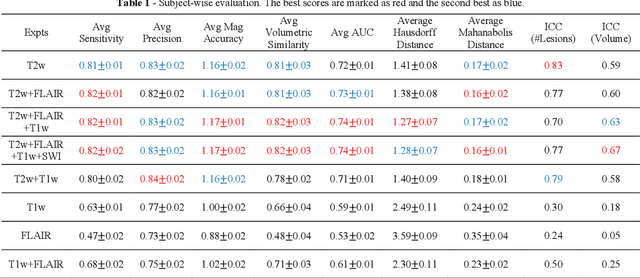
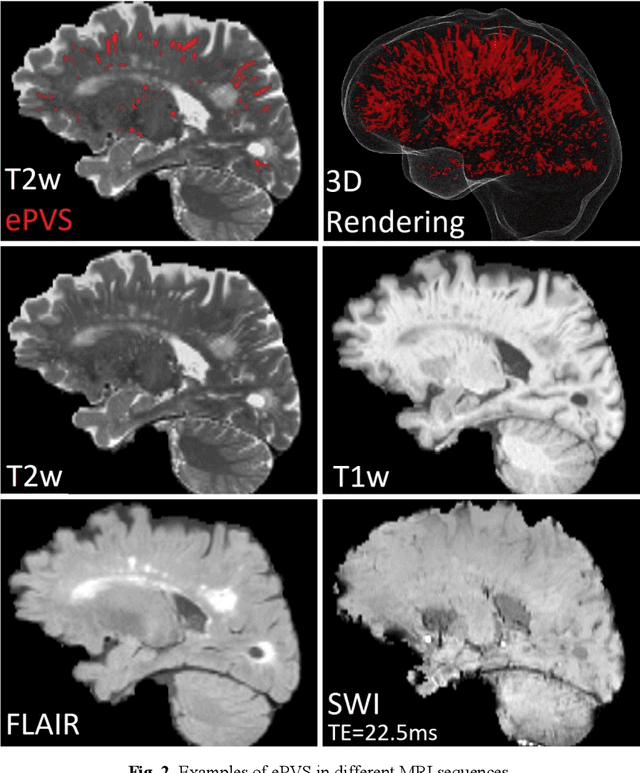
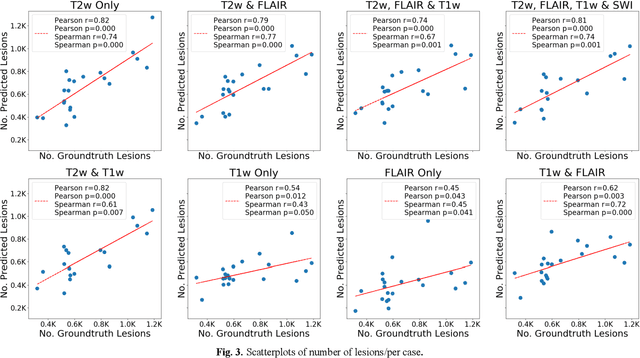
Deep learning has been demonstrated effective in many neuroimaging applications. However, in many scenarios the number of imaging sequences capturing information related to small vessel disease lesions is insufficient to support data-driven techniques. Additionally, cohort-based studies may not always have the optimal or essential imaging sequences for accurate lesion detection. Therefore, it is necessary to determine which of these imaging sequences are essential for accurate detection. In this study we aimed to find the optimal combination of magnetic resonance imaging (MRI) sequences for deep learning-based detection of enlarged perivascular spaces (ePVS). To this end, we implemented an effective light-weight U-Net adapted for ePVS detection and comprehensively investigated different combinations of information from susceptibility weighted imaging (SWI), fluid-attenuated inversion recovery (FLAIR), T1-weighted (T1w) and T2-weighted (T2w) MRI sequences. We conclude that T2w MRI is the most important for accurate ePVS detection, and the incorporation of SWI, FLAIR and T1w MRI in the deep neural network could make insignificant improvements in accuracy.
Dataset Distillation via Factorization
Oct 30, 2022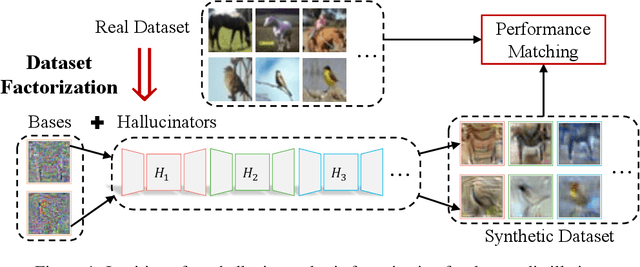
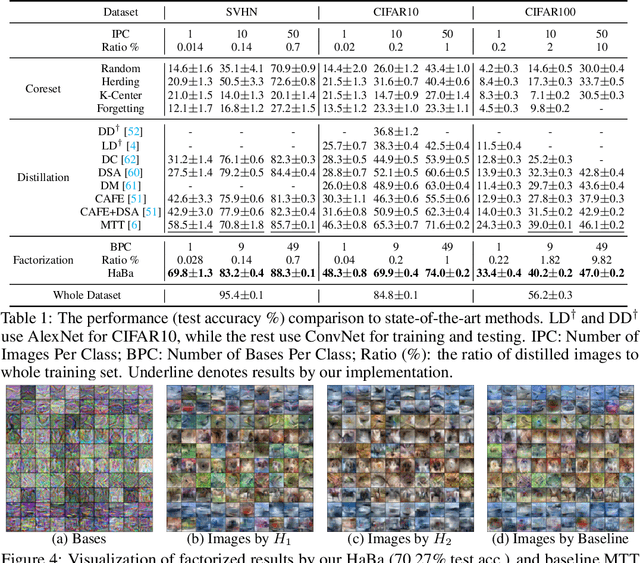
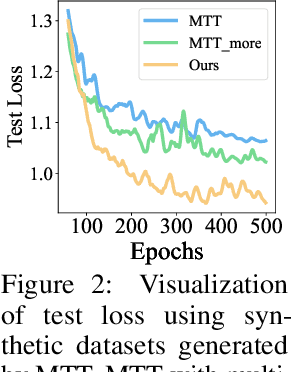
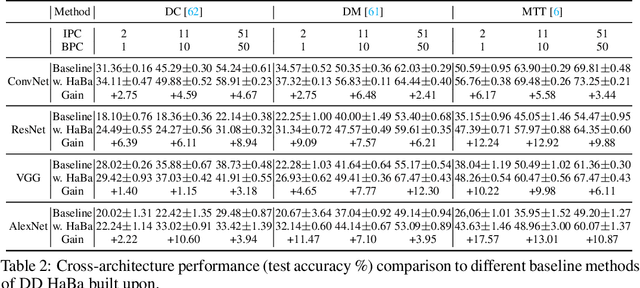
In this paper, we study \xw{dataset distillation (DD)}, from a novel perspective and introduce a \emph{dataset factorization} approach, termed \emph{HaBa}, which is a plug-and-play strategy portable to any existing DD baseline. Unlike conventional DD approaches that aim to produce distilled and representative samples, \emph{HaBa} explores decomposing a dataset into two components: data \emph{Ha}llucination networks and \emph{Ba}ses, where the latter is fed into the former to reconstruct image samples. The flexible combinations between bases and hallucination networks, therefore, equip the distilled data with exponential informativeness gain, which largely increase the representation capability of distilled datasets. To furthermore increase the data efficiency of compression results, we further introduce a pair of adversarial contrastive constraints on the resultant hallucination networks and bases, which increase the diversity of generated images and inject more discriminant information into the factorization. Extensive comparisons and experiments demonstrate that our method can yield significant improvement on downstream classification tasks compared with previous state of the arts, while reducing the total number of compressed parameters by up to 65\%. Moreover, distilled datasets by our approach also achieve \textasciitilde10\% higher accuracy than baseline methods in cross-architecture generalization. Our code is available \href{https://github.com/Huage001/DatasetFactorization}{here}.
Benchmarking Adversarial Patch Against Aerial Detection
Oct 30, 2022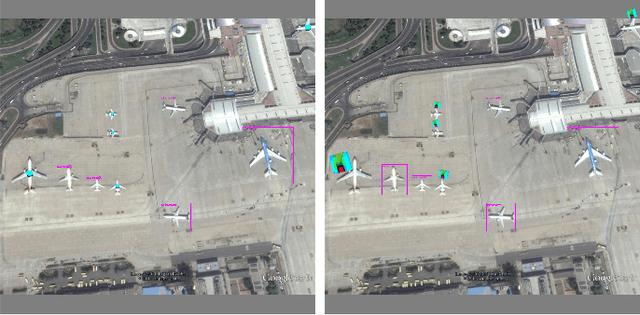
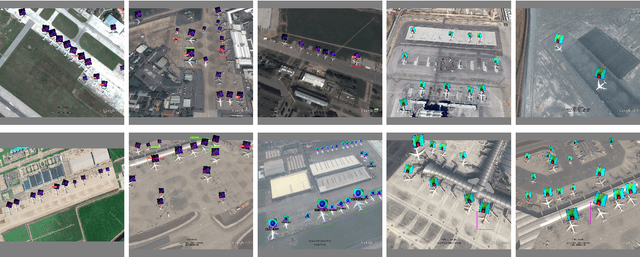


DNNs are vulnerable to adversarial examples, which poses great security concerns for security-critical systems. In this paper, a novel adaptive-patch-based physical attack (AP-PA) framework is proposed, which aims to generate adversarial patches that are adaptive in both physical dynamics and varying scales, and by which the particular targets can be hidden from being detected. Furthermore, the adversarial patch is also gifted with attack effectiveness against all targets of the same class with a patch outside the target (No need to smear targeted objects) and robust enough in the physical world. In addition, a new loss is devised to consider more available information of detected objects to optimize the adversarial patch, which can significantly improve the patch's attack efficacy (Average precision drop up to 87.86% and 85.48% in white-box and black-box settings, respectively) and optimizing efficiency. We also establish one of the first comprehensive, coherent, and rigorous benchmarks to evaluate the attack efficacy of adversarial patches on aerial detection tasks. Finally, several proportionally scaled experiments are performed physically to demonstrate that the elaborated adversarial patches can successfully deceive aerial detection algorithms in dynamic physical circumstances. The code is available at https://github.com/JiaweiLian/AP-PA.
token2vec: A Joint Self-Supervised Pre-training Framework Using Unpaired Speech and Text
Oct 30, 2022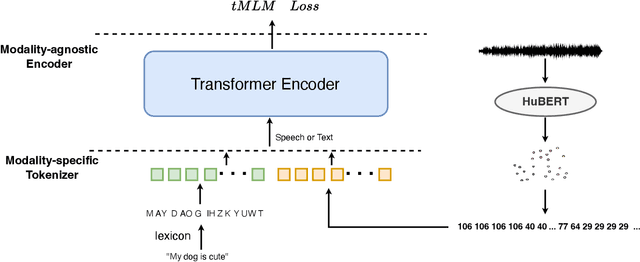
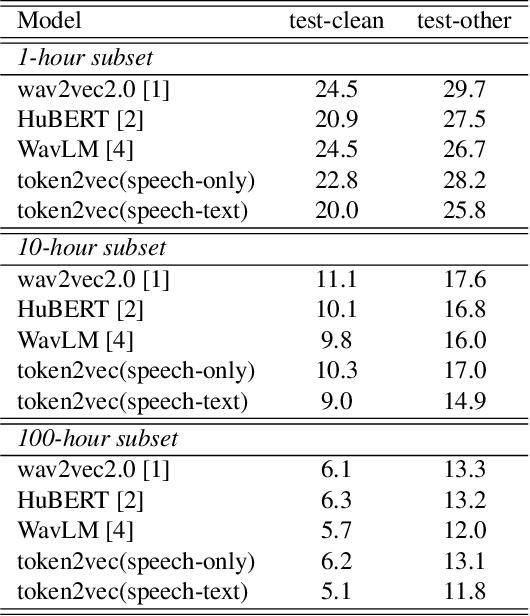
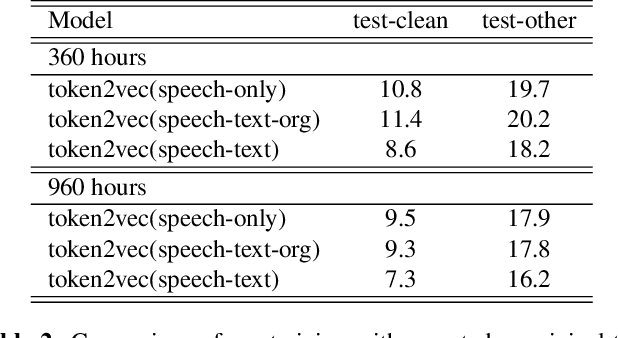
Self-supervised pre-training has been successful in both text and speech processing. Speech and text offer different but complementary information. The question is whether we are able to perform a speech-text joint pre-training on unpaired speech and text. In this paper, we take the idea of self-supervised pre-training one step further and propose token2vec, a novel joint pre-training framework for unpaired speech and text based on discrete representations of speech. Firstly, due to the distinct characteristics between speech and text modalities, where speech is continuous while text is discrete, we first discretize speech into a sequence of discrete speech tokens to solve the modality mismatch problem. Secondly, to solve the length mismatch problem, where the speech sequence is usually much longer than text sequence, we convert the words of text into phoneme sequences and randomly repeat each phoneme in the sequences. Finally, we feed the discrete speech and text tokens into a modality-agnostic Transformer encoder and pre-train with token-level masking language modeling (tMLM). Experiments show that token2vec is significantly superior to various speech-only pre-training baselines, with up to 17.7% relative WER reduction. Token2vec model is also validated on a non-ASR task, i.e., spoken intent classification, and shows good transferability.
Online Convex Optimization with Long Term Constraints for Predictable Sequences
Oct 30, 2022In this paper, we investigate the framework of Online Convex Optimization (OCO) for online learning. OCO offers a very powerful online learning framework for many applications. In this context, we study a specific framework of OCO called {\it OCO with long term constraints}. Long term constraints are introduced typically as an alternative to reduce the complexity of the projection at every update step in online optimization. While many algorithmic advances have been made towards online optimization with long term constraints, these algorithms typically assume that the sequence of cost functions over a certain $T$ finite steps that determine the cost to the online learner are adversarially generated. In many circumstances, the sequence of cost functions may not be unrelated, and thus predictable from those observed till a point of time. In this paper, we study the setting where the sequences are predictable. We present a novel online optimization algorithm for online optimization with long term constraints that can leverage such predictability. We show that, with a predictor that can supply the gradient information of the next function in the sequence, our algorithm can achieve an overall regret and constraint violation rate that is strictly less than the rate that is achievable without prediction.
Useful Confidence Measures: Beyond the Max Score
Oct 25, 2022


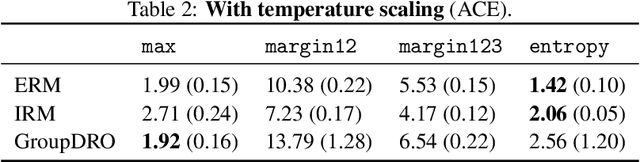
An important component in deploying machine learning (ML) in safety-critic applications is having a reliable measure of confidence in the ML model's predictions. For a classifier $f$ producing a probability vector $f(x)$ over the candidate classes, the confidence is typically taken to be $\max_i f(x)_i$. This approach is potentially limited, as it disregards the rest of the probability vector. In this work, we derive several confidence measures that depend on information beyond the maximum score, such as margin-based and entropy-based measures, and empirically evaluate their usefulness, focusing on NLP tasks with distribution shifts and Transformer-based models. We show that when models are evaluated on the out-of-distribution data ``out of the box'', using only the maximum score to inform the confidence measure is highly suboptimal. In the post-processing regime (where the scores of $f$ can be improved using additional in-distribution held-out data), this remains true, albeit less significant. Overall, our results suggest that entropy-based confidence is a surprisingly useful measure.