 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Re3: Generating Longer Stories With Recursive Reprompting and Revision
Oct 14, 2022
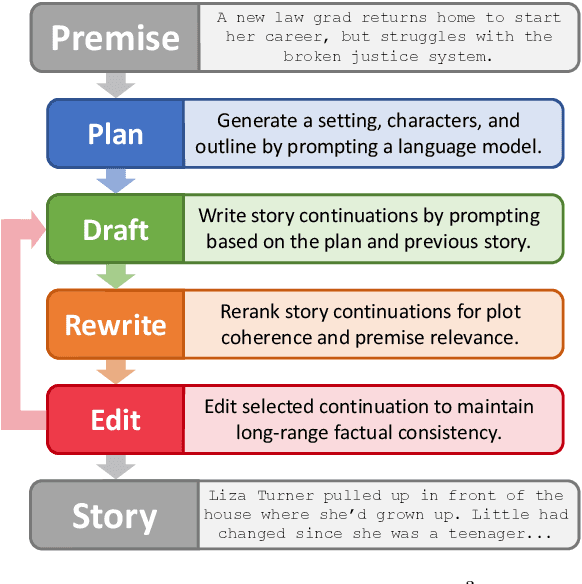
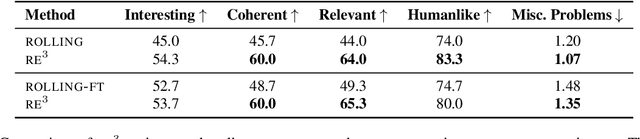
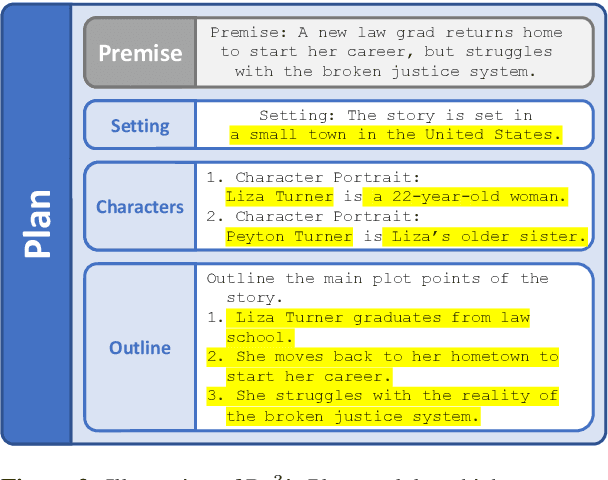

We consider the problem of automatically generating longer stories of over two thousand words. Compared to prior work on shorter stories, long-range plot coherence and relevance are more central challenges here. We propose the Recursive Reprompting and Revision framework (Re3) to address these challenges by (a) prompting a general-purpose language model to construct a structured overarching plan, and (b) generating story passages by repeatedly injecting contextual information from both the plan and current story state into a language model prompt. We then revise by (c) reranking different continuations for plot coherence and premise relevance, and finally (d) editing the best continuation for factual consistency. Compared to similar-length stories generated directly from the same base model, human evaluators judged substantially more of Re3's stories as having a coherent overarching plot (by 14% absolute increase), and relevant to the given initial premise (by 20%).
Carrying the uncarriable: a deformation-agnostic and human-cooperative framework for unwieldy objects using multiple robots
Sep 28, 2022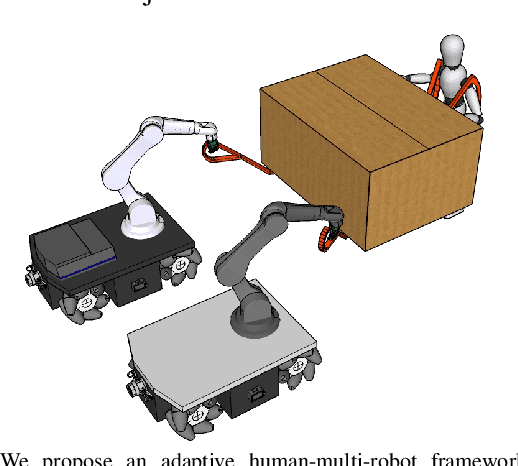
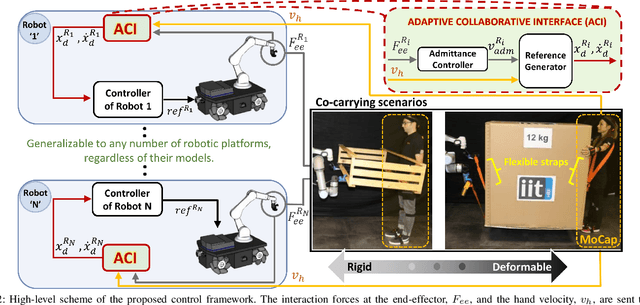
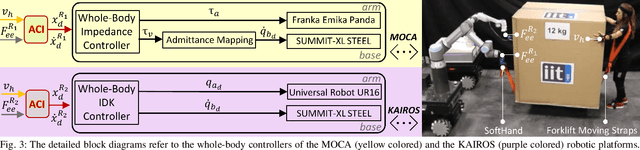
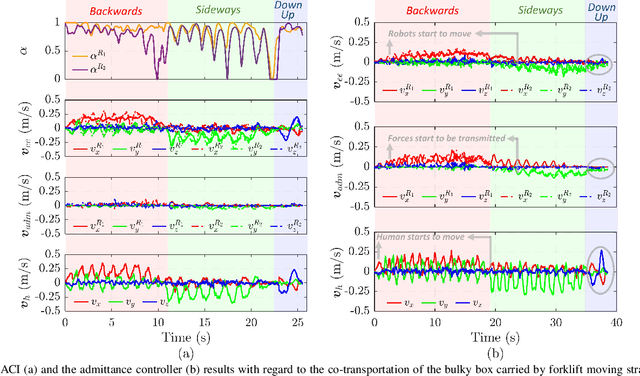
This manuscript introduces an object deformability-agnostic framework for co-carrying tasks that are shared between a person and multiple robots. Our approach allows the full control of the co-carrying trajectories by the person while sharing the load with multiple robots depending on the size and the weight of the object. This is achieved by merging the haptic information transferred through the object and the human motion information obtained from a motion capture system. One important advantage of the framework is that no strict internal communication is required between the robots, regardless of the object size and deformation characteristics. We validate the framework with two challenging real-world scenarios: co-transportation of a wooden rigid closet and a bulky box on top of forklift moving straps, with the latter characterizing deformable objects. In order to evaluate the generalizability of the proposed framework, a heterogenous team of two mobile manipulators that consist of an Omni-directional mobile base and a collaborative robotic arm with different DoFs is chosen for the experiments. The qualitative comparison between our controller and the baseline controller (i.e., an admittance controller) during these experiments demonstrated the effectiveness of the proposed framework especially when co-carrying deformable objects. Furthermore, we believe that the performance of our framework during the experiment with the lifting straps offers a promising solution for the co-transportation of bulky and ungraspable objects.
End-to-end Multilingual Coreference Resolution with Mention Head Prediction
Sep 26, 2022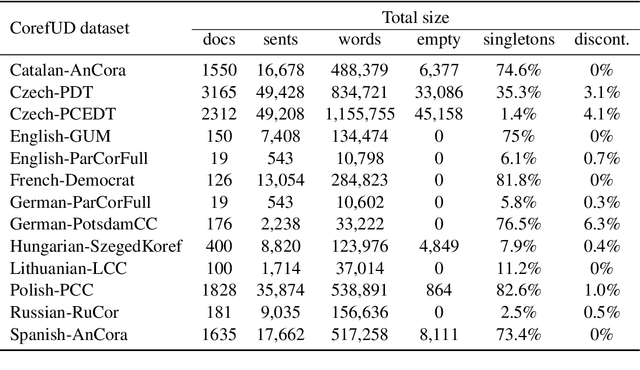

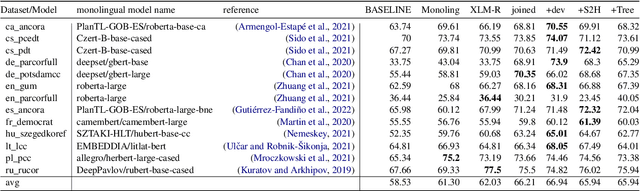
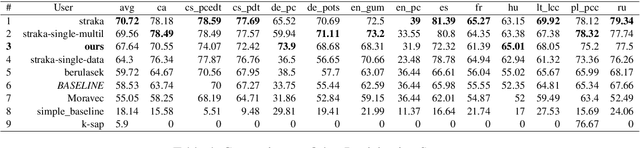
This paper describes our approach to the CRAC 2022 Shared Task on Multilingual Coreference Resolution. Our model is based on a state-of-the-art end-to-end coreference resolution system. Apart from joined multilingual training, we improved our results with mention head prediction. We also tried to integrate dependency information into our model. Our system ended up in $3^{rd}$ place. Moreover, we reached the best performance on two datasets out of 13.
Monitoring and mapping of crop fields with UAV swarms based on information gain
Mar 22, 2022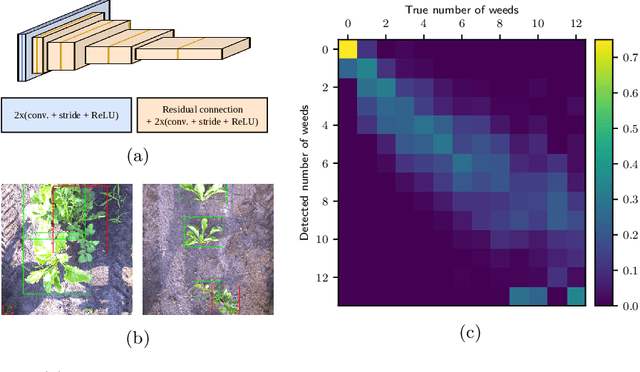
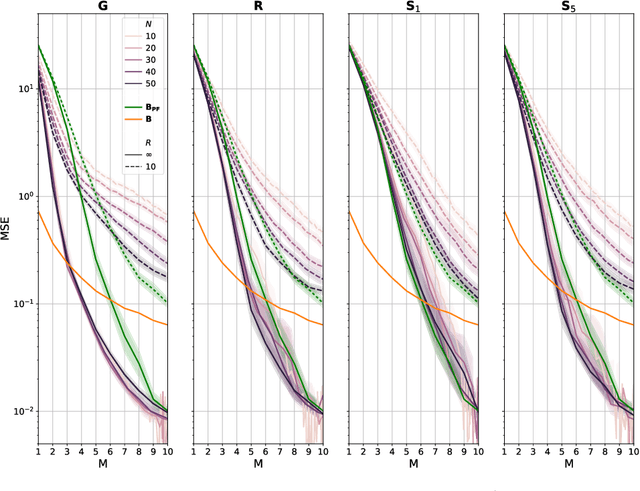
Monitoring crop fields to map features like weeds can be efficiently performed with unmanned aerial vehicles (UAVs) that can cover large areas in a short time due to their privileged perspective and motion speed. However, the need for high-resolution images for precise classification of features (e.g., detecting even the smallest weeds in the field) contrasts with the limited payload and ight time of current UAVs. Thus, it requires several flights to cover a large field uniformly. However, the assumption that the whole field must be observed with the same precision is unnecessary when features are heterogeneously distributed, like weeds appearing in patches over the field. In this case, an adaptive approach that focuses only on relevant areas can perform better, especially when multiple UAVs are employed simultaneously. Leveraging on a swarm-robotics approach, we propose a monitoring and mapping strategy that adaptively chooses the target areas based on the expected information gain, which measures the potential for uncertainty reduction due to further observations. The proposed strategy scales well with group size and leads to smaller mapping errors than optimal pre-planned monitoring approaches.
Learning based Age of Information Minimization in UAV-relayed IoT Networks
Mar 08, 2022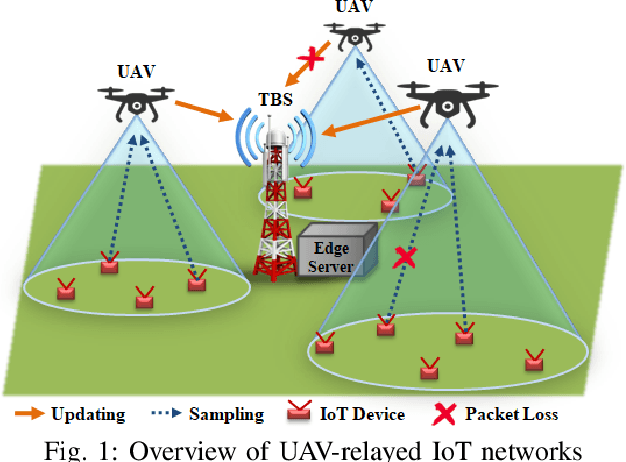
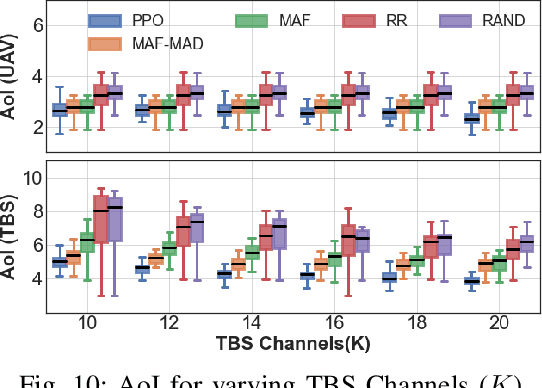
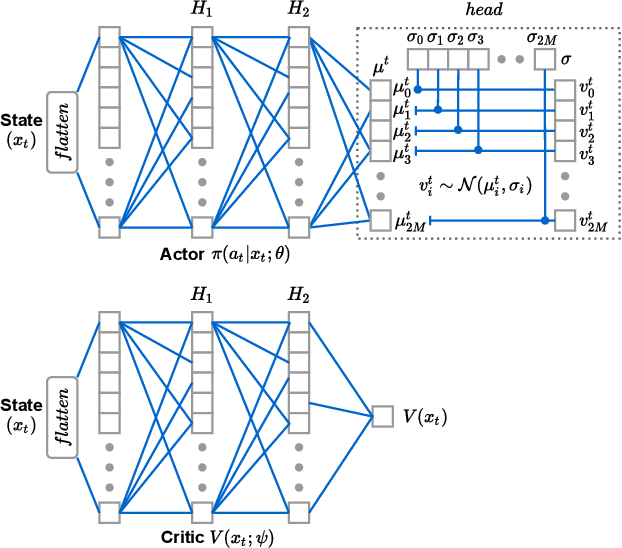
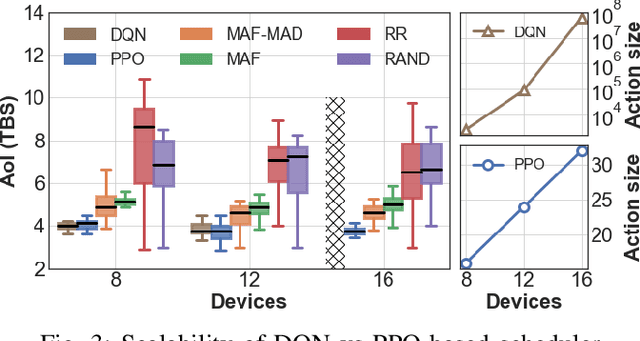
Unmanned Aerial Vehicles (UAVs) are used as aerial base-stations to relay time-sensitive packets from IoT devices to the nearby terrestrial base-station (TBS). Scheduling of packets in such UAV-relayed IoT-networks to ensure fresh (or up-to-date) IoT devices' packets at the TBS is a challenging problem as it involves two simultaneous steps of (i) sampling of packets generated at IoT devices by the UAVs [hop-1] and (ii) updating of sampled packets from UAVs to the TBS [hop-2]. To address this, we propose Age-of-Information (AoI) scheduling algorithms for two-hop UAV-relayed IoT-networks. First, we propose a low-complexity AoI scheduler, termed, MAF-MAD that employs Maximum AoI First (MAF) policy for sampling of IoT devices at UAV (hop-1) and Maximum AoI Difference (MAD) policy for updating sampled packets from UAV to the TBS (hop-2). We prove that MAF-MAD is the optimal AoI scheduler under ideal conditions (lossless wireless channels and generate-at-will traffic-generation at IoT devices). On the contrary, for general conditions (lossy channel conditions and varying periodic traffic-generation at IoT devices), a deep reinforcement learning algorithm, namely, Proximal Policy Optimization (PPO)-based scheduler is proposed. Simulation results show that the proposed PPO-based scheduler outperforms other schedulers like MAF-MAD, MAF, and round-robin in all considered general scenarios.
CMGAN: Conformer-Based Metric-GAN for Monaural Speech Enhancement
Sep 23, 2022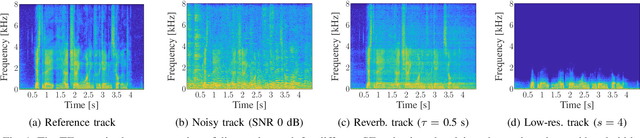
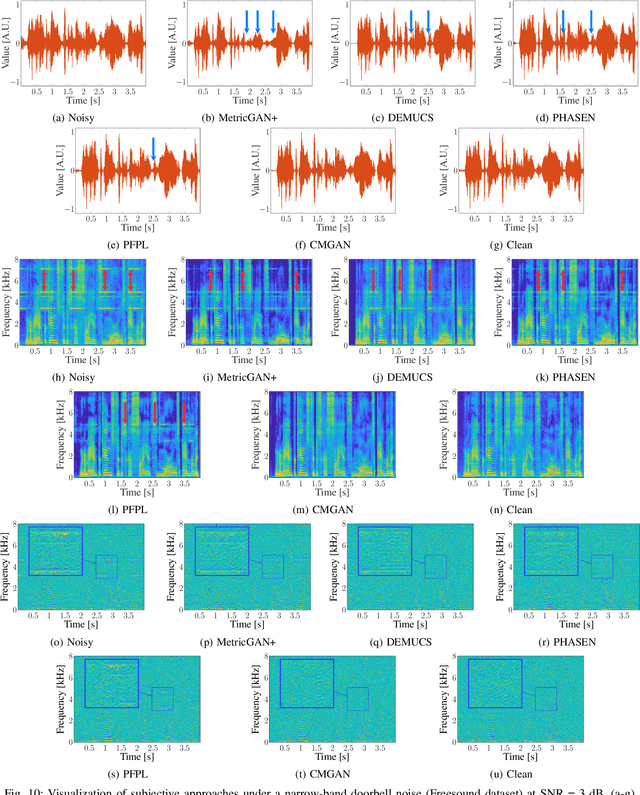
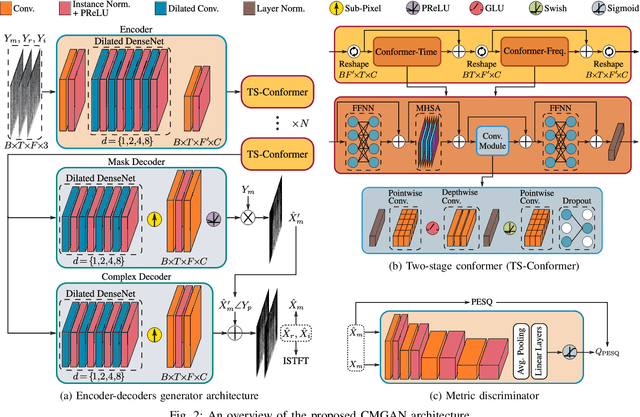
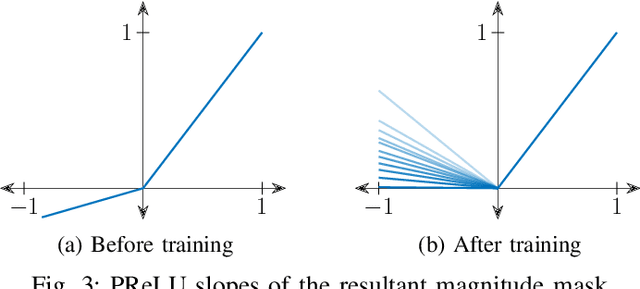
Convolution-augmented transformers (Conformers) are recently proposed in various speech-domain applications, such as automatic speech recognition (ASR) and speech separation, as they can capture both local and global dependencies. In this paper, we propose a conformer-based metric generative adversarial network (CMGAN) for speech enhancement (SE) in the time-frequency (TF) domain. The generator encodes the magnitude and complex spectrogram information using two-stage conformer blocks to model both time and frequency dependencies. The decoder then decouples the estimation into a magnitude mask decoder branch to filter out unwanted distortions and a complex refinement branch to further improve the magnitude estimation and implicitly enhance the phase information. Additionally, we include a metric discriminator to alleviate metric mismatch by optimizing the generator with respect to a corresponding evaluation score. Objective and subjective evaluations illustrate that CMGAN is able to show superior performance compared to state-of-the-art methods in three speech enhancement tasks (denoising, dereverberation and super-resolution). For instance, quantitative denoising analysis on Voice Bank+DEMAND dataset indicates that CMGAN outperforms various previous models with a margin, i.e., PESQ of 3.41 and SSNR of 11.10 dB.
Certified machine learning: Rigorous a posteriori error bounds for PDE defined PINNs
Oct 07, 2022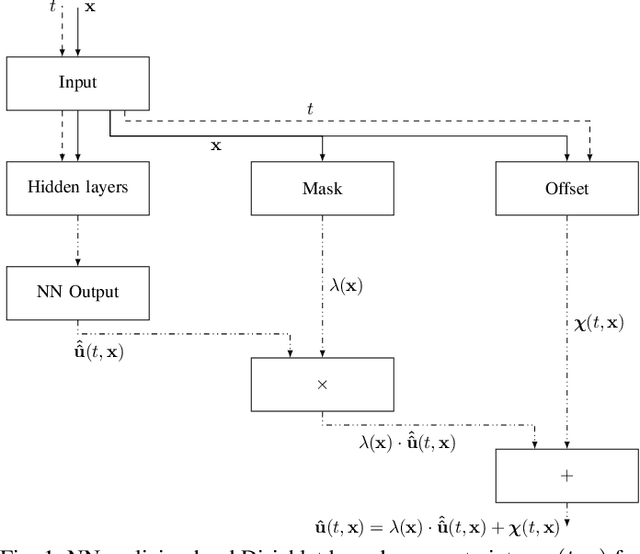
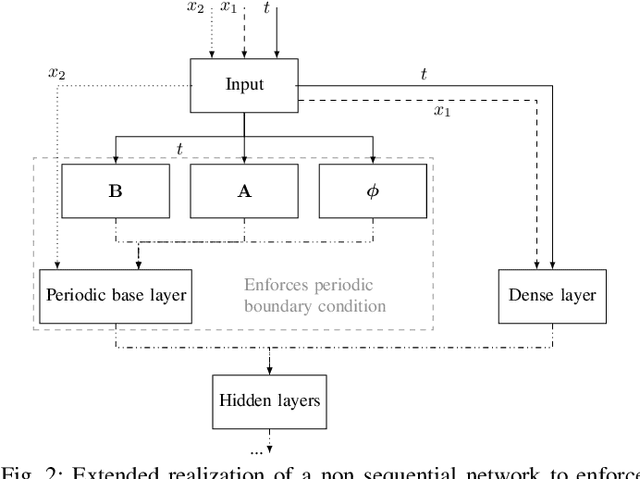
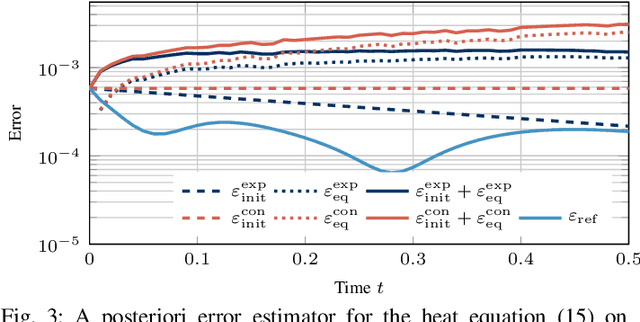
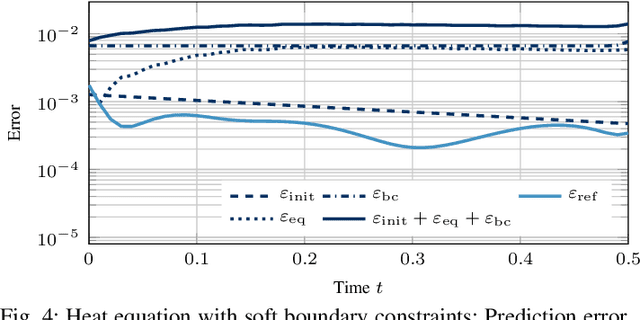
Prediction error quantification in machine learning has been left out of most methodological investigations of neural networks, for both purely data-driven and physics-informed approaches. Beyond statistical investigations and generic results on the approximation capabilities of neural networks, we present a rigorous upper bound on the prediction error of physics-informed neural networks. This bound can be calculated without the knowledge of the true solution and only with a priori available information about the characteristics of the underlying dynamical system governed by a partial differential equation. We apply this a posteriori error bound exemplarily to four problems: the transport equation, the heat equation, the Navier-Stokes equation and the Klein-Gordon equation.
Privacy-Preserving Distributed Expectation Maximization for Gaussian Mixture Model using Subspace Perturbation
Sep 16, 2022
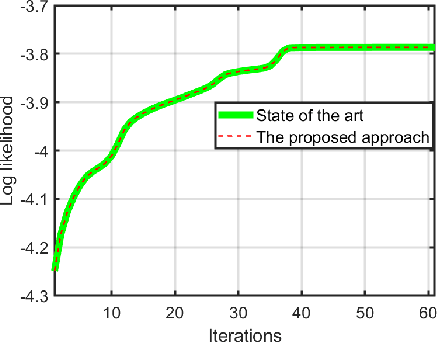
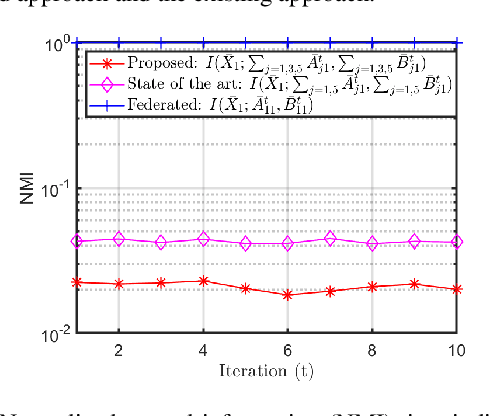
Privacy has become a major concern in machine learning. In fact, the federated learning is motivated by the privacy concern as it does not allow to transmit the private data but only intermediate updates. However, federated learning does not always guarantee privacy-preservation as the intermediate updates may also reveal sensitive information. In this paper, we give an explicit information-theoretical analysis of a federated expectation maximization algorithm for Gaussian mixture model and prove that the intermediate updates can cause severe privacy leakage. To address the privacy issue, we propose a fully decentralized privacy-preserving solution, which is able to securely compute the updates in each maximization step. Additionally, we consider two different types of security attacks: the honest-but-curious and eavesdropping adversary models. Numerical validation shows that the proposed approach has superior performance compared to the existing approach in terms of both the accuracy and privacy level.
Hierarchical MixUp Multi-label Classification with Imbalanced Interdisciplinary Research Proposals
Sep 28, 2022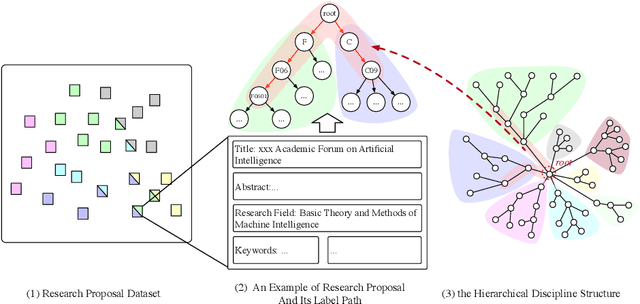
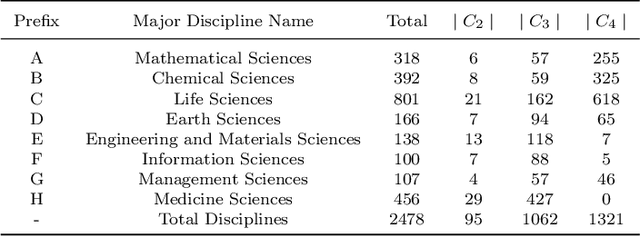
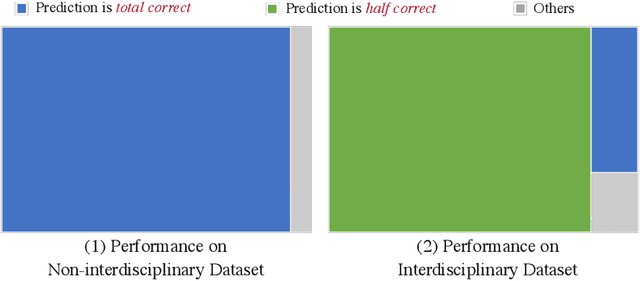
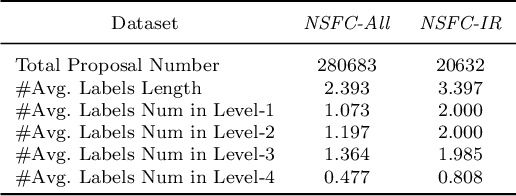
Funding agencies are largely relied on a topic matching between domain experts and research proposals to assign proposal reviewers. As proposals are increasingly interdisciplinary, it is challenging to profile the interdisciplinary nature of a proposal, and, thereafter, find expert reviewers with an appropriate set of expertise. An essential step in solving this challenge is to accurately model and classify the interdisciplinary labels of a proposal. Existing methodological and application-related literature, such as textual classification and proposal classification, are insufficient in jointly addressing the three key unique issues introduced by interdisciplinary proposal data: 1) the hierarchical structure of discipline labels of a proposal from coarse-grain to fine-grain, e.g., from information science to AI to fundamentals of AI. 2) the heterogeneous semantics of various main textual parts that play different roles in a proposal; 3) the number of proposals is imbalanced between non-interdisciplinary and interdisciplinary research. Can we simultaneously address the three issues in understanding the proposal's interdisciplinary nature? In response to this question, we propose a hierarchical mixup multiple-label classification framework, which we called H-MixUp. H-MixUp leverages a transformer-based semantic information extractor and a GCN-based interdisciplinary knowledge extractor for the first and second issues. H-MixUp develops a fused training method of Wold-level MixUp, Word-level CutMix, Manifold MixUp, and Document-level MixUp to address the third issue.
Implicit Neural Representation as a Differentiable Surrogate for Photon Propagation in a Monolithic Neutrino Detector
Nov 02, 2022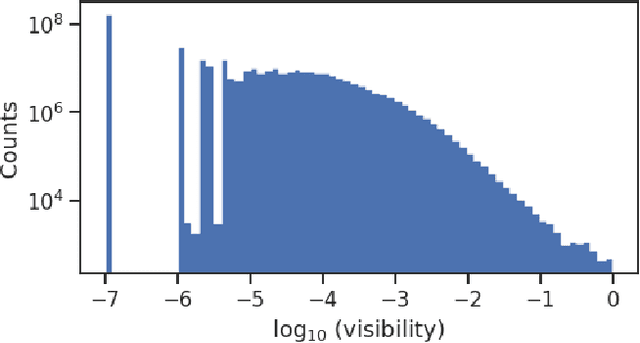
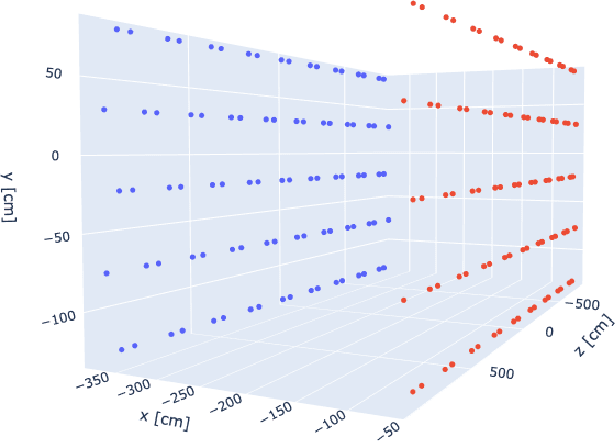

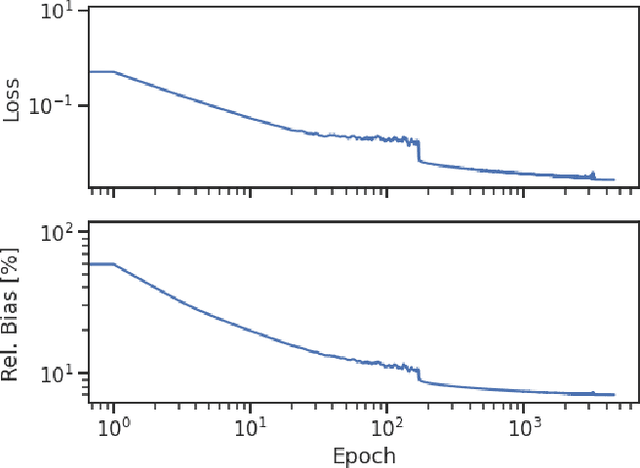
Optical photons are used as signal in a wide variety of particle detectors. Modern neutrino experiments employ hundreds to tens of thousands of photon detectors to observe signal from millions to billions of scintillation photons produced from energy deposition of charged particles. These neutrino detectors are typically large, containing kilotons of target volume, with different optical properties. Modeling individual photon propagation in form of look-up table requires huge computational resources. As the size of a table increases with detector volume for a fixed resolution, this method scales poorly for future larger detectors. Alternative approaches such as fitting a polynomial to the model could address the memory issue, but results in poorer performance. Both look-up table and fitting approaches are prone to discrepancies between the detector simulation and the data collected. We propose a new approach using SIREN, an implicit neural representation with periodic activation functions, to model the look-up table as a 3D scene and reproduces the acceptance map with high accuracy. The number of parameters in our SIREN model is orders of magnitude smaller than the number of voxels in the look-up table. As it models an underlying functional shape, SIREN is scalable to a larger detector. Furthermore, SIREN can successfully learn the spatial gradients of the photon library, providing additional information for downstream applications. Finally, as SIREN is a neural network representation, it is differentiable with respect to its parameters, and therefore tunable via gradient descent. We demonstrate the potential of optimizing SIREN directly on real data, which mitigates the concern of data vs. simulation discrepancies. We further present an application for data reconstruction where SIREN is used to form a likelihood function for photon statistics.