 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On the Transformation of Latent Space in Fine-Tuned NLP Models
Oct 23, 2022
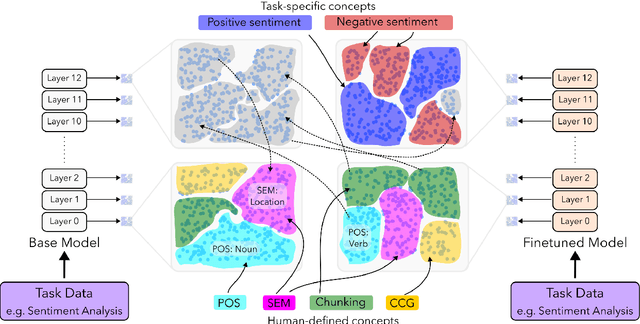
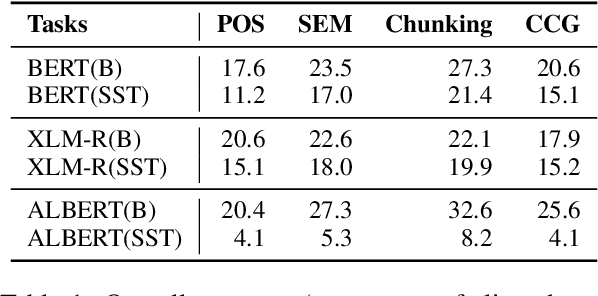

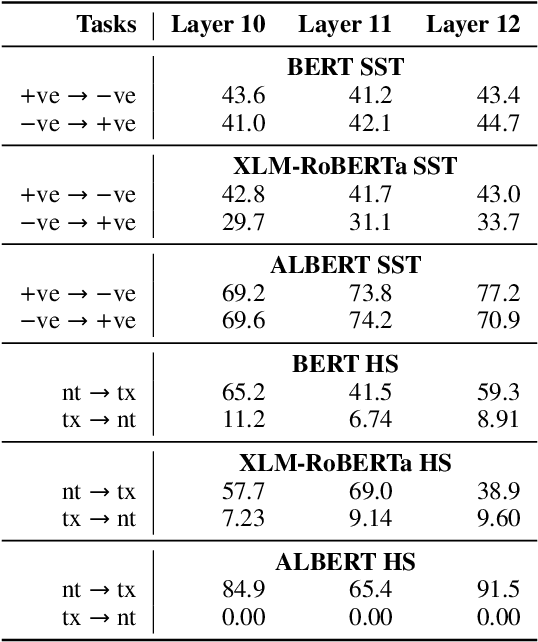
We study the evolution of latent space in fine-tuned NLP models. Different from the commonly used probing-framework, we opt for an unsupervised method to analyze representations. More specifically, we discover latent concepts in the representational space using hierarchical clustering. We then use an alignment function to gauge the similarity between the latent space of a pre-trained model and its fine-tuned version. We use traditional linguistic concepts to facilitate our understanding and also study how the model space transforms towards task-specific information. We perform a thorough analysis, comparing pre-trained and fine-tuned models across three models and three downstream tasks. The notable findings of our work are: i) the latent space of the higher layers evolve towards task-specific concepts, ii) whereas the lower layers retain generic concepts acquired in the pre-trained model, iii) we discovered that some concepts in the higher layers acquire polarity towards the output class, and iv) that these concepts can be used for generating adversarial triggers.
Face Emotion Recognization Using Dataset Augmentation Based on Neural Network
Oct 23, 2022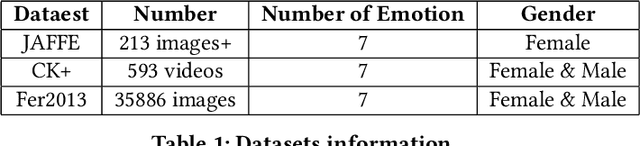
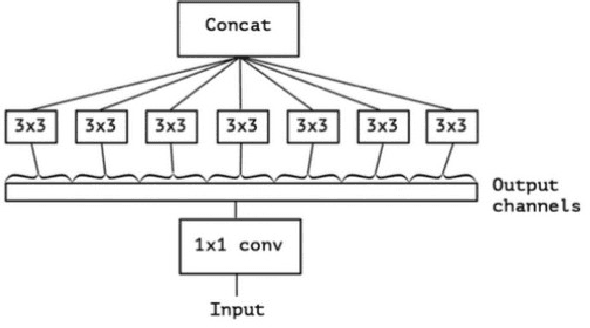

Facial expression is one of the most external indications of a person's feelings and emotions. In daily conversation, according to the psychologist, only 7\% and 38\% of information is communicated through words and sounds respective, while up to 55\% is through facial expression. It plays an important role in coordinating interpersonal relationships. Ekman and Friesen recognized six essential emotions in the nineteenth century depending on a cross-cultural study, which indicated that people feel each basic emotion in the same fashion despite culture. As a branch of the field of analyzing sentiment, facial expression recognition offers broad application prospects in a variety of domains, including the interaction between humans and computers, healthcare, and behavior monitoring. Therefore, many researchers have devoted themselves to facial expression recognition. In this paper, an effective hybrid data augmentation method is used. This approach is operated on two public datasets, and four benchmark models see some remarkable results.
Convolutional Learning on Multigraphs
Sep 23, 2022

Graph convolutional learning has led to many exciting discoveries in diverse areas. However, in some applications, traditional graphs are insufficient to capture the structure and intricacies of the data. In such scenarios, multigraphs arise naturally as discrete structures in which complex dynamics can be embedded. In this paper, we develop convolutional information processing on multigraphs and introduce convolutional multigraph neural networks (MGNNs). To capture the complex dynamics of information diffusion within and across each of the multigraph's classes of edges, we formalize a convolutional signal processing model, defining the notions of signals, filtering, and frequency representations on multigraphs. Leveraging this model, we develop a multigraph learning architecture, including a sampling procedure to reduce computational complexity. The introduced architecture is applied towards optimal wireless resource allocation and a hate speech localization task, offering improved performance over traditional graph neural networks.
Contact Information Flow and Design of Compliance
Oct 24, 2021
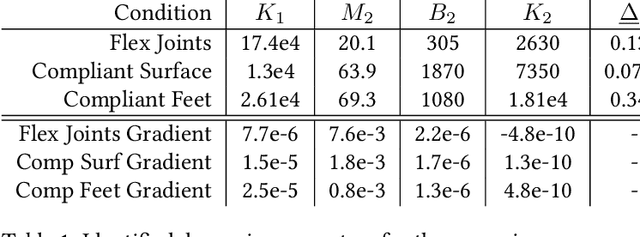
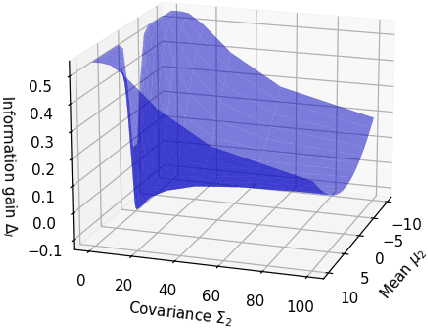
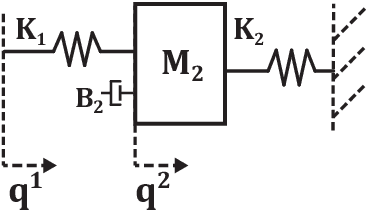
The objective of many contact-rich manipulation tasks can be expressed as desired contacts between environmental objects. Simulation and planning for rigid-body contact continues to advance, but the achievable performance is significantly impacted by hardware design, such as physical compliance and sensor placement. Much of mechatronic design for contact is done from a continuous controls perspective (e.g. peak collision force, contact stability), but hardware also affects the ability to infer discrete changes in contact. Robustly detecting contact state can support the correction of errors, both online and in trial-and-error learning. Here, discrete contact states are considered as changes in environmental dynamics, and the ability to infer this with proprioception (motor position and force sensors) is investigated. A metric of information gain is proposed, measuring the reduction in contact belief uncertainty from force/position measurements, and developed for fully- and partially-observed systems. The information gain depends on the coupled robot/environment dynamics and sensor placement, especially the location and degree of compliance. Hardware experiments over a range of physical compliance conditions validate that information gain predicts the speed and certainty with which contact is detected in (i) monitoring of contact-rich assembly and (ii) collision detection. Compliant environmental structures are then optimized to allow industrial robots to achieve safe, higher-speed contact.
Tutorial and Practice in Linear Programming: Optimization Problems in Supply Chain and Transport Logistics
Nov 04, 2022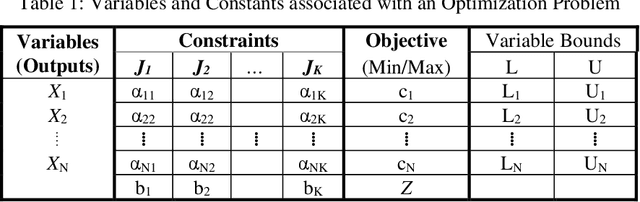
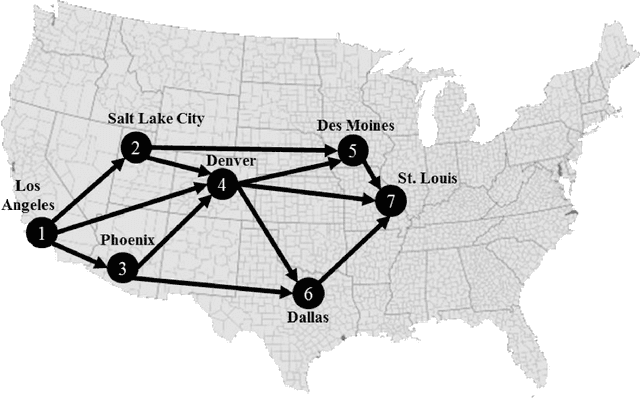
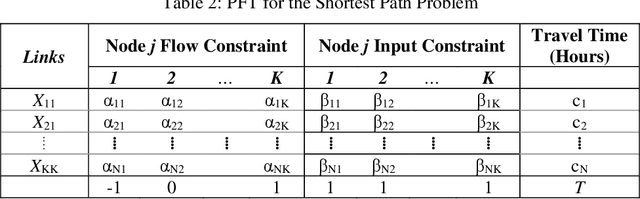
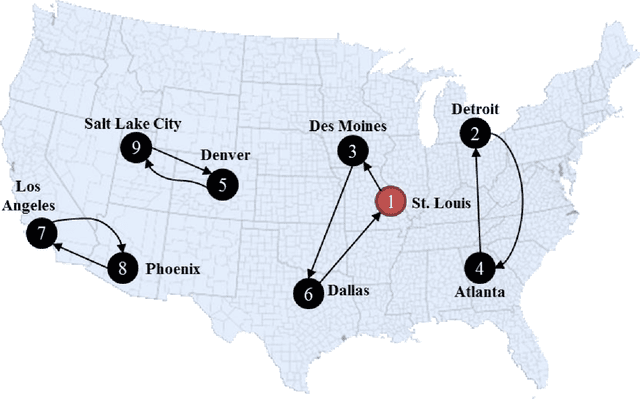
This tutorial is an andragogical guide for students and practitioners seeking to understand the fundamentals and practice of linear programming. The exercises demonstrate how to solve classical optimization problems with an emphasis on spatial analysis in supply chain management and transport logistics. All exercises display the Python programs and optimization libraries used to solve them. The first chapter introduces key concepts in linear programming and contributes a new cognitive framework to help students and practitioners set up each optimization problem. The cognitive framework organizes the decision variables, constraints, the objective function, and variable bounds in a format for direct application to optimization software. The second chapter introduces two types of mobility optimization problems (shortest path in a network and minimum cost tour) in the context of delivery and service planning logistics. The third chapter introduces four types of spatial optimization problems (neighborhood coverage, flow capturing, zone heterogeneity, service coverage) and contributes a workflow to visualize the optimized solutions in maps. The workflow creates decision variables from maps by using the free geographic information systems (GIS) programs QGIS and GeoDA. The fourth chapter introduces three types of spatial logistical problems (spatial distribution, flow maximization, warehouse location optimization) and demonstrates how to scale the cognitive framework in software to reach solutions. The final chapter summarizes lessons learned and provides insights about how students and practitioners can modify the Phyton programs and GIS workflows to solve their own optimization problem and visualize the results.
Domain Adaptation via Maximizing Surrogate Mutual Information
Oct 23, 2021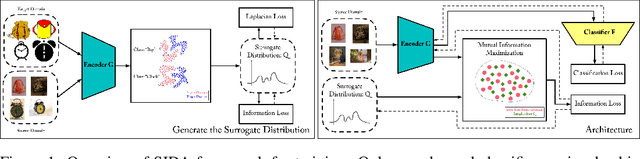
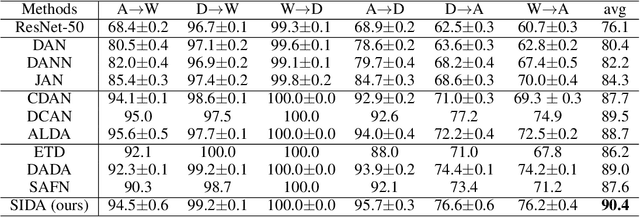

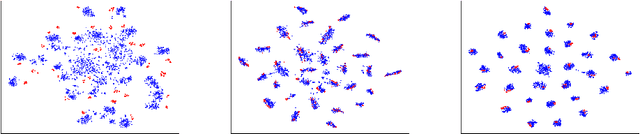
Unsupervised domain adaptation (UDA), which is an important topic in transfer learning, aims to predict unlabeled data from target domain with access to labeled data from the source domain. In this work, we propose a novel framework called SIDA (Surrogate Mutual Information Maximization Domain Adaptation) with strong theoretical guarantees. To be specific, SIDA implements adaptation by maximizing mutual information (MI) between features. In the framework, a surrogate joint distribution models the underlying joint distribution of the unlabeled target domain. Our theoretical analysis validates SIDA by bounding the expected risk on target domain with MI and surrogate distribution bias. Experiments show that our approach is comparable with state-of-the-art unsupervised adaptation methods on standard UDA tasks.
Cem Mil Podcasts: A Spoken Portuguese Document Corpus
Sep 23, 2022
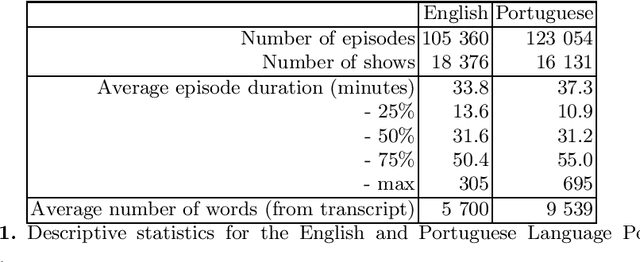
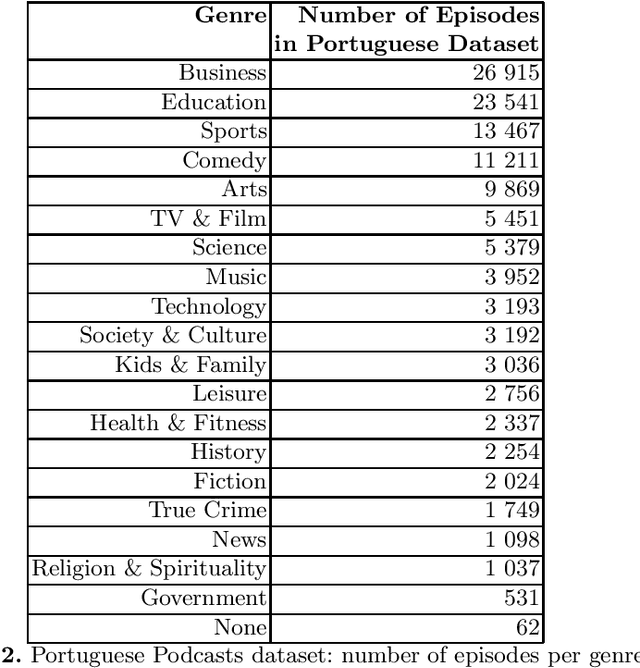
This document describes the Portuguese language podcast dataset released by Spotify for academic research purposes. We give an overview of how the data was sampled, some basic statistics over the collection, as well as brief information of distribution over Brazilian and Portuguese dialects.
RIS Assisted Device Activity Detection with Statistical Channel State Information
Jun 14, 2022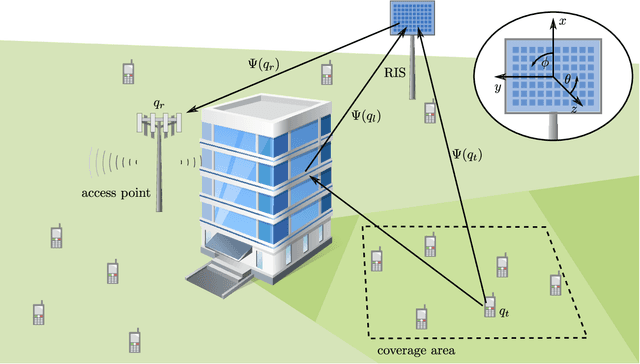
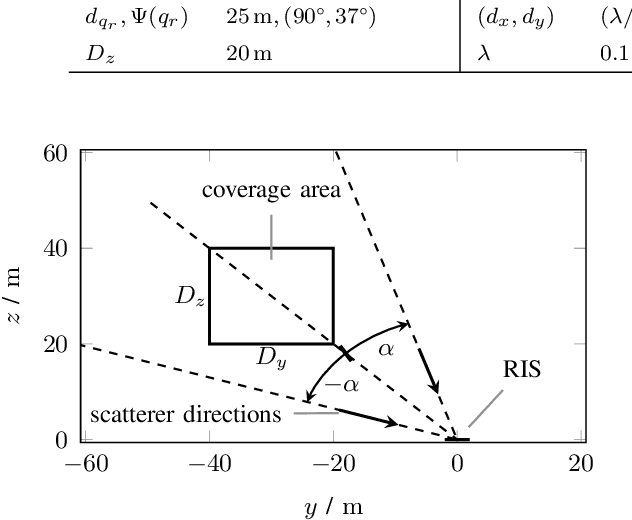
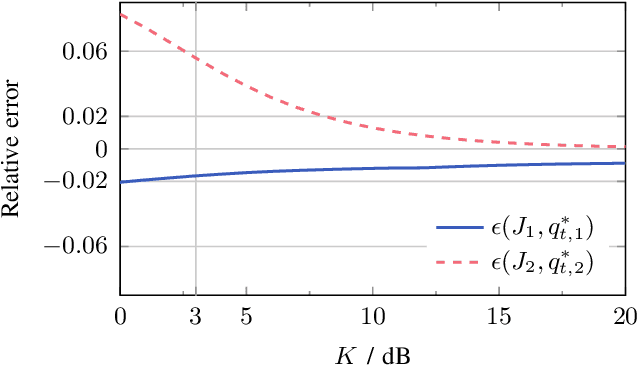
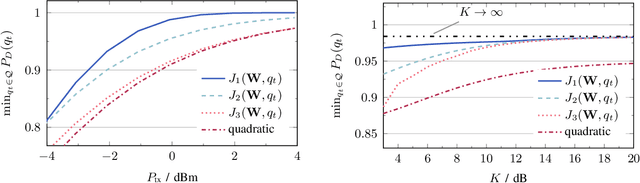
This paper studies reconfigurable intelligent surface (RIS) assisted device activity detection for grant-free (GF) uplink transmission in wireless communication networks. In particular, we consider mobile devices located in an area where the direct link to an access point (AP) is blocked. Thus, the devices try to connect to the AP via a reflected link provided by an RIS. Therefore, a RIS phase-shift design is desired that covers the entire blocked area with a wide reflection beam because the exact locations and times of activity of the devices are unknown in GF transmission. In order to study the impact of the phase-shift design on the device activity detection, we derive a generalized likelihood ratio test (GLRT) based detector and present an analytical expression for the probability of detection. Assuming knowledge of statistical CSI, we formulate an optimization problem for the phase-shift design for maximization of the guaranteed probability of detection for all locations within a given coverage area. To tackle the non-convexity of the problem, we propose two different approximations of the objective function. The first approximation leads to a design that aims to reduce the variations of the end-to-end channel while taking system parameters such as transmit power, noise power, and probability of false alarm into account. The second approximation can be adopted for versatile RIS deployments because it only depends on the line-of-sight component of the end-to-end channel and is not affected by system parameters. For comparison, we also consider a phase-shift design maximizing the average channel gain and a baseline analytical phase-shift design for large blocked areas. Our performance evaluation shows that the proposed approximations result in phase-shift designs that guarantee high probability of detection across the coverage area and outperform the baseline designs.
SR-DCSK Cooperative Communication System with Code Index Modulation: A New Design for 6G New Radios
Aug 27, 2022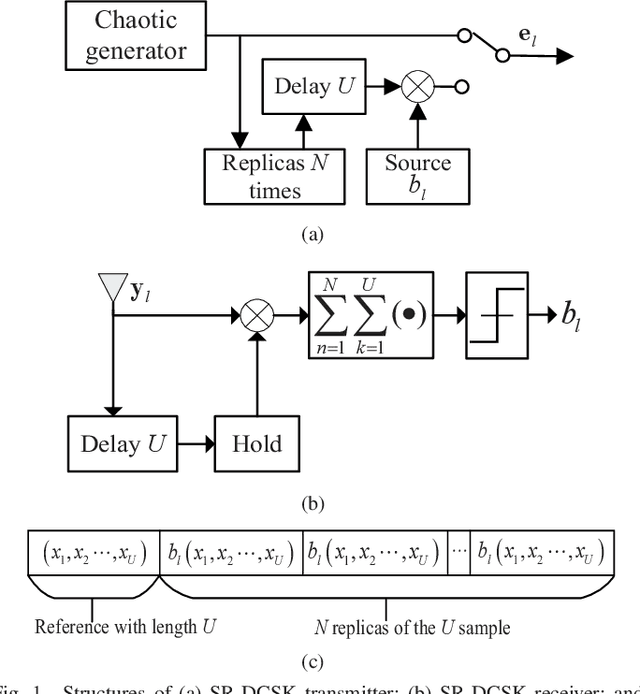
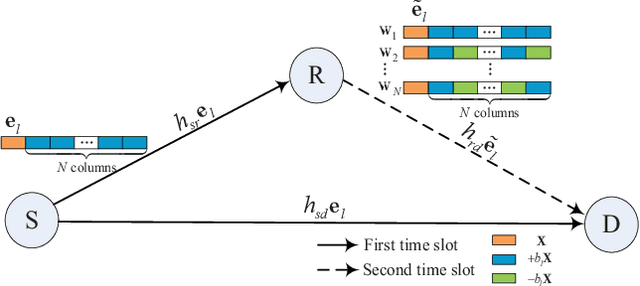
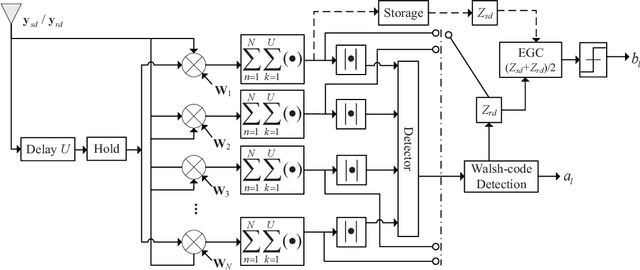
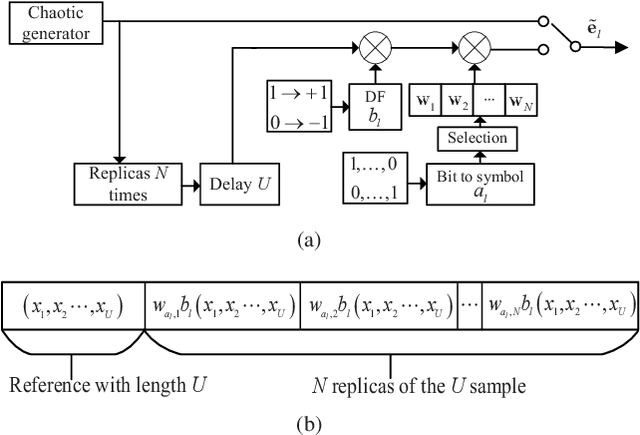
This paper proposes a high-throughput short reference differential chaos shift keying cooperative communication system with the aid of code index modulation, referred to as CIM-SR-DCSK-CC system. In the proposed CIM-SR-DCSK-CC system, the source transmits information bits to both the relay and destination in the first time slot, while the relay not only forwards the source information bits but also sends new information bits to the destination in the second time slot. To be specific, the relay employs an $N$-order Walsh code to carry additional ${{\log }_{2}}N$ information bits, which are superimposed onto the SR-DCSK signal carrying the decoded source information bits. Subsequently, the superimposed signal carrying both the source and relay information bits is transmitted to the destination. Moreover, the theoretical bit error rate (BER) expressions of the proposed CIM-SR-DCSK-CC system are derived over additive white Gaussian noise (AWGN) and multipath Rayleigh fading channels. Compared with the conventional DCSK-CC system and SR-DCSK-CC system, the proposed CIM-SR-DCSK-CC system can significantly improve the throughput without deteriorating any BER performance. As a consequence, the proposed system is very promising for the applications of the 6G-enabled low-power and high-rate communication.
The Value of Information When Deciding What to Learn
Oct 26, 2021
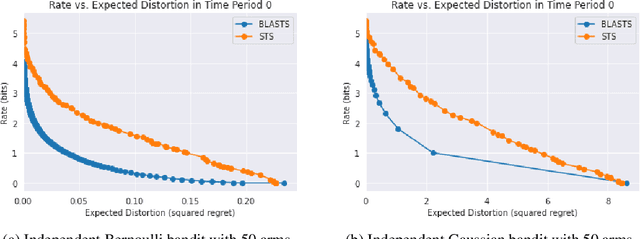
All sequential decision-making agents explore so as to acquire knowledge about a particular target. It is often the responsibility of the agent designer to construct this target which, in rich and complex environments, constitutes a onerous burden; without full knowledge of the environment itself, a designer may forge a sub-optimal learning target that poorly balances the amount of information an agent must acquire to identify the target against the target's associated performance shortfall. While recent work has developed a connection between learning targets and rate-distortion theory to address this challenge and empower agents that decide what to learn in an automated fashion, the proposed algorithm does not optimally tackle the equally important challenge of efficient information acquisition. In this work, building upon the seminal design principle of information-directed sampling (Russo & Van Roy, 2014), we address this shortcoming directly to couple optimal information acquisition with the optimal design of learning targets. Along the way, we offer new insights into learning targets from the literature on rate-distortion theory before turning to empirical results that confirm the value of information when deciding what to learn.