 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Temporally Disentangled Representation Learning
Oct 24, 2022

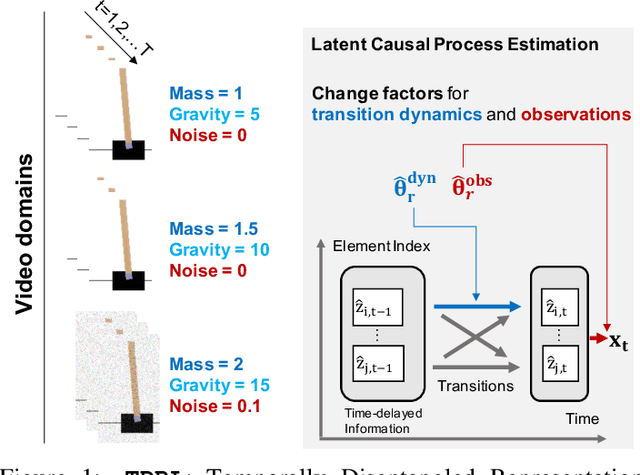
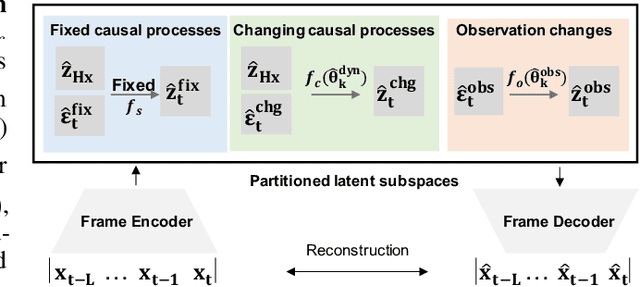

Recently in the field of unsupervised representation learning, strong identifiability results for disentanglement of causally-related latent variables have been established by exploiting certain side information, such as class labels, in addition to independence. However, most existing work is constrained by functional form assumptions such as independent sources or further with linear transitions, and distribution assumptions such as stationary, exponential family distribution. It is unknown whether the underlying latent variables and their causal relations are identifiable if they have arbitrary, nonparametric causal influences in between. In this work, we establish the identifiability theories of nonparametric latent causal processes from their nonlinear mixtures under fixed temporal causal influences and analyze how distribution changes can further benefit the disentanglement. We propose \textbf{\texttt{TDRL}}, a principled framework to recover time-delayed latent causal variables and identify their relations from measured sequential data under stationary environments and under different distribution shifts. Specifically, the framework can factorize unknown distribution shifts into transition distribution changes under fixed and time-varying latent causal relations, and under observation changes in observation. Through experiments, we show that time-delayed latent causal influences are reliably identified and that our approach considerably outperforms existing baselines that do not correctly exploit this modular representation of changes. Our code is available at: \url{https://github.com/weirayao/tdrl}.
Boosting Kidney Stone Identification in Endoscopic Images Using Two-Step Transfer Learning
Oct 24, 2022
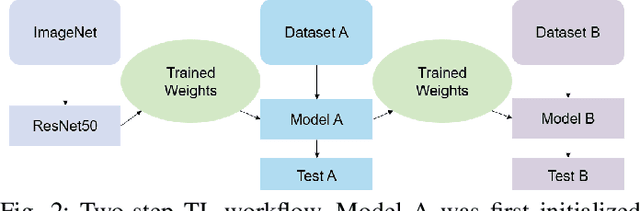

Knowing the cause of kidney stone formation is crucial to establish treatments that prevent recurrence. There are currently different approaches for determining the kidney stone type. However, the reference ex-vivo identification procedure can take up to several weeks, while an in-vivo visual recognition requires highly trained specialists. Machine learning models have been developed to provide urologists with an automated classification of kidney stones during an ureteroscopy; however, there is a general lack in terms of quality of the training data and methods. In this work, a two-step transfer learning approach is used to train the kidney stone classifier. The proposed approach transfers knowledge learned on a set of images of kidney stones acquired with a CCD camera (ex-vivo dataset) to a final model that classifies images from endoscopic images (ex-vivo dataset). The results show that learning features from different domains with similar information helps to improve the performance of a model that performs classification in real conditions (for instance, uncontrolled lighting conditions and blur). Finally, in comparison to models that are trained from scratch or by initializing ImageNet weights, the obtained results suggest that the two-step approach extracts features improving the identification of kidney stones in endoscopic images.
Is the Envelope Beneficial to Non-Orthogonal Multiple Access?
Oct 24, 2022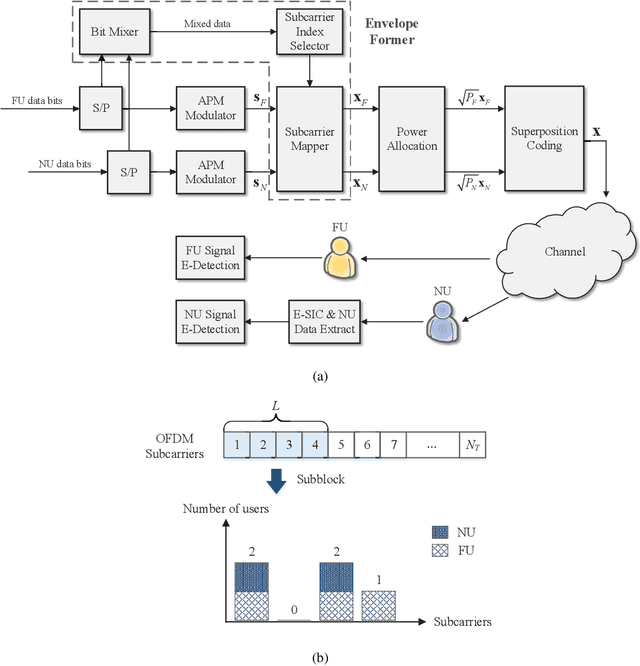
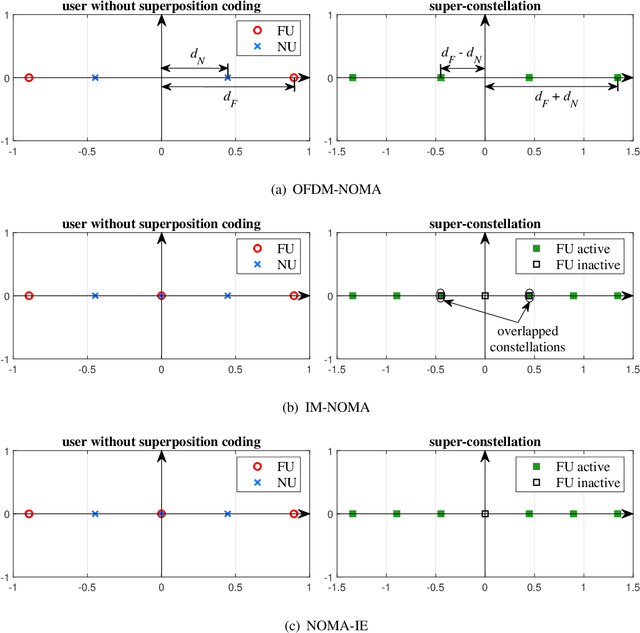
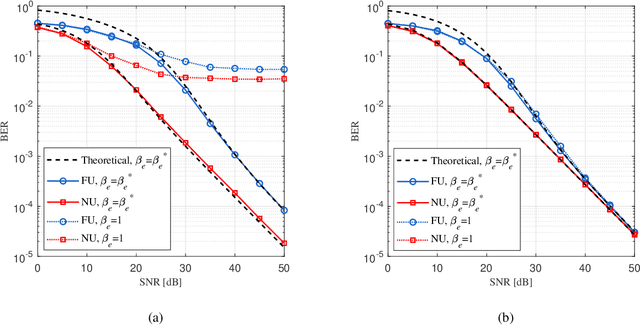
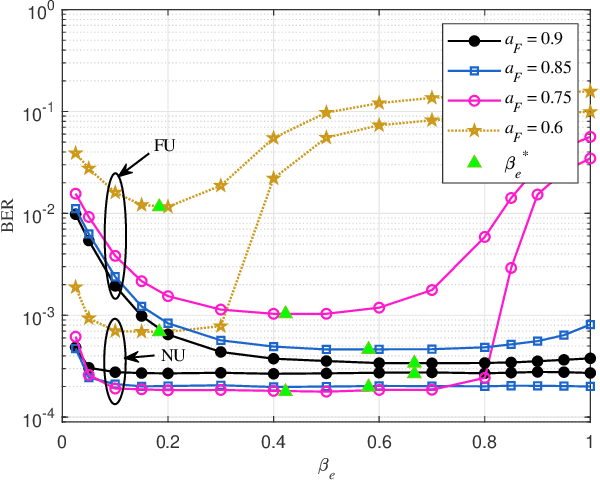
Non-orthogonal multiple access (NOMA) is capable of serving different numbers of users in the same time-frequency resource element, and this feature can be leveraged to carry additional information. In the orthogonal frequency division multiplexing (OFDM) system, we propose a novel enhanced NOMA scheme, called NOMA with informative envelope (NOMA-IE), to explore the flexibility of the envelope of NOMA signals. In this scheme, data bits are conveyed by the quantified signal envelope in addition to classic signal constellations. The subcarrier activation patterns of different users are jointly decided by the envelope former. At the receiver, successive interference cancellation (SIC) is employed, and we also introduce the envelope detection coefficient to eliminate the error floor. Theoretical expressions of spectral efficiency and energy efficiency are provided for the NOMA-IE. Then, considering the binary phase shift keying modulation, we derive the asymptotic bit error rate for the two-subcarrier OFDM subblock. Afterwards, the expressions are extended to the four-subcarrier case. The analytical results reveal that the imperfect SIC and the index error are the main factors degrading the error performance. The numerical results demonstrate the superiority of the NOMA-IE over the OFDM and OFDM-NOMA, especially in the high signal-to-noise ratio (SNR) regime.
Controlled Text Reduction
Oct 24, 2022

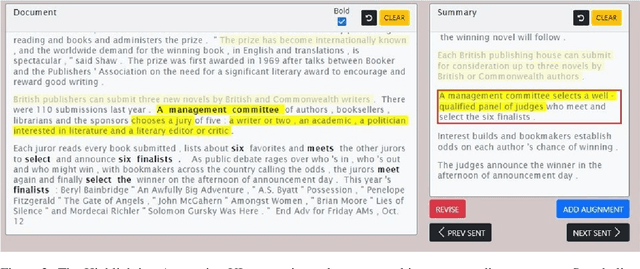

Producing a reduced version of a source text, as in generic or focused summarization, inherently involves two distinct subtasks: deciding on targeted content and generating a coherent text conveying it. While some popular approaches address summarization as a single end-to-end task, prominent works support decomposed modeling for individual subtasks. Further, semi-automated text reduction is also very appealing, where users may identify targeted content while models would generate a corresponding coherent summary. In this paper, we focus on the second subtask, of generating coherent text given pre-selected content. Concretely, we formalize \textit{Controlled Text Reduction} as a standalone task, whose input is a source text with marked spans of targeted content ("highlighting"). A model then needs to generate a coherent text that includes all and only the target information. We advocate the potential of such models, both for modular fully-automatic summarization, as well as for semi-automated human-in-the-loop use cases. Facilitating proper research, we crowdsource high-quality dev and test datasets for the task. Further, we automatically generate a larger "silver" training dataset from available summarization benchmarks, leveraging a pretrained summary-source alignment model. Finally, employing these datasets, we present a supervised baseline model, showing promising results and insightful analyses.
End-to-End Affordance Learning for Robotic Manipulation
Sep 26, 2022
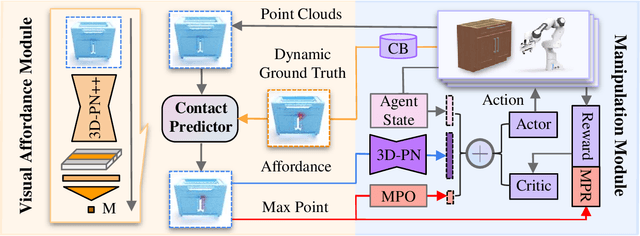

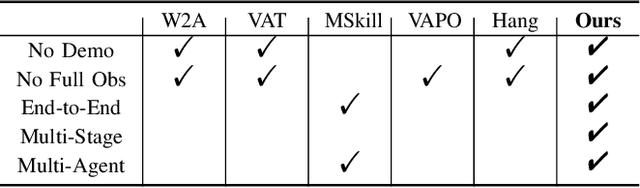
Learning to manipulate 3D objects in an interactive environment has been a challenging problem in Reinforcement Learning (RL). In particular, it is hard to train a policy that can generalize over objects with different semantic categories, diverse shape geometry and versatile functionality. Recently, the technique of visual affordance has shown great prospects in providing object-centric information priors with effective actionable semantics. As such, an effective policy can be trained to open a door by knowing how to exert force on the handle. However, to learn the affordance, it often requires human-defined action primitives, which limits the range of applicable tasks. In this study, we take advantage of visual affordance by using the contact information generated during the RL training process to predict contact maps of interest. Such contact prediction process then leads to an end-to-end affordance learning framework that can generalize over different types of manipulation tasks. Surprisingly, the effectiveness of such framework holds even under the multi-stage and the multi-agent scenarios. We tested our method on eight types of manipulation tasks. Results showed that our methods outperform baseline algorithms, including visual-based affordance methods and RL methods, by a large margin on the success rate. The demonstration can be found at https://sites.google.com/view/rlafford/.
GRAPHYP: A Scientific Knowledge Graph with Manifold Subnetworks of Communities. Detection of Scholarly Disputes in Adversarial Information Routes
May 03, 2022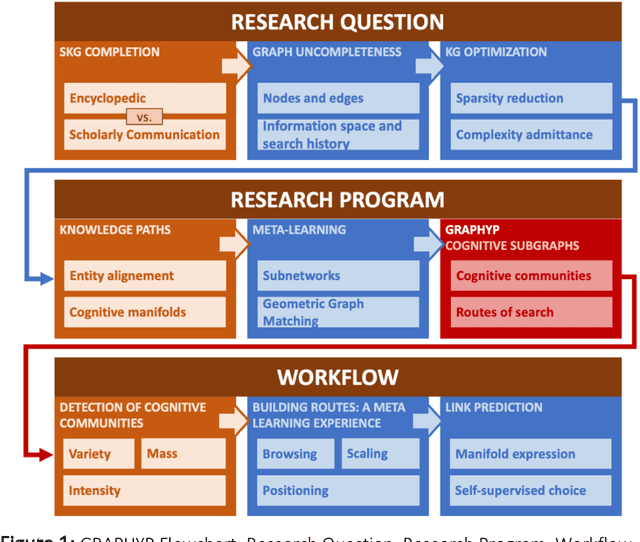

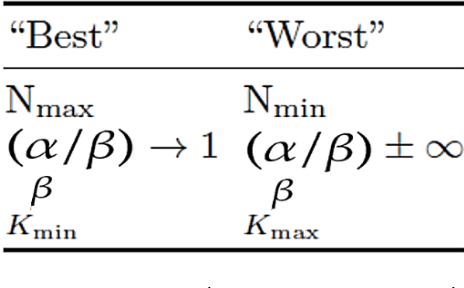
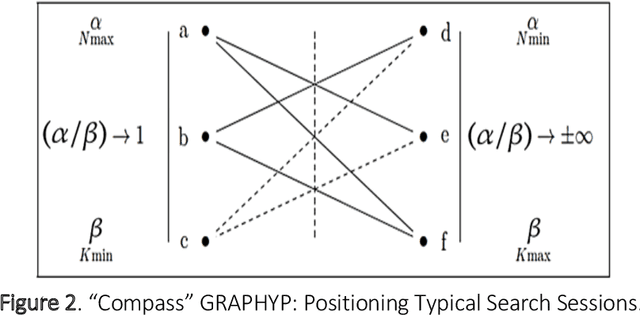
The cognitive manifold of published content is currently expanding in all areas of science. However, Scientific Knowledge Graphs (SKGs) only provide poor pictures of the adversarial directions and scientific controversies that feed the production of knowledge. In this Article, we tackle the understanding of the design of the information space of a cognitive representation of research activities, and of related bottlenecks that affect search interfaces, in the mapping of structured objects into graphs. We propose, with SKG GRAPHYP, a novel graph designed geometric architecture which optimizes both the detection of the knowledge manifold of "cognitive communities", and the representation of alternative paths to adversarial answers to a research question, for instance in the context of academic disputes. With a methodology for designing "Manifold Subnetworks of Cognitive Communities", GRAPHYP provides a classification of distinct search paths in a research field. Users are detected from the variety of their search practices and classified in "Cognitive communities" from the analysis of the search history of their logs of scientific documentation. The manifold of practices is expressed from metrics of differentiated uses by triplets of nodes shaped into symmetrical graph subnetworks, with the following three parameters: Mass, Intensity, and Variety.
LinkFormer: Automatic Contextualised Link Recovery of Software Artifacts in both Project-based and Transfer Learning Settings
Nov 01, 2022
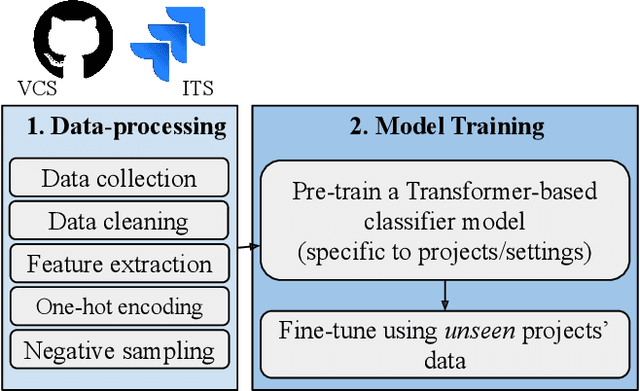
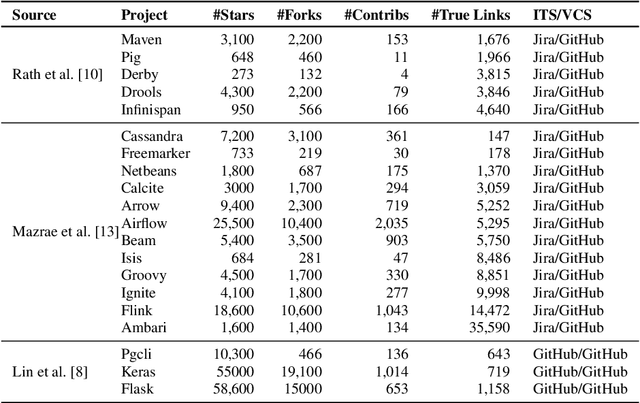
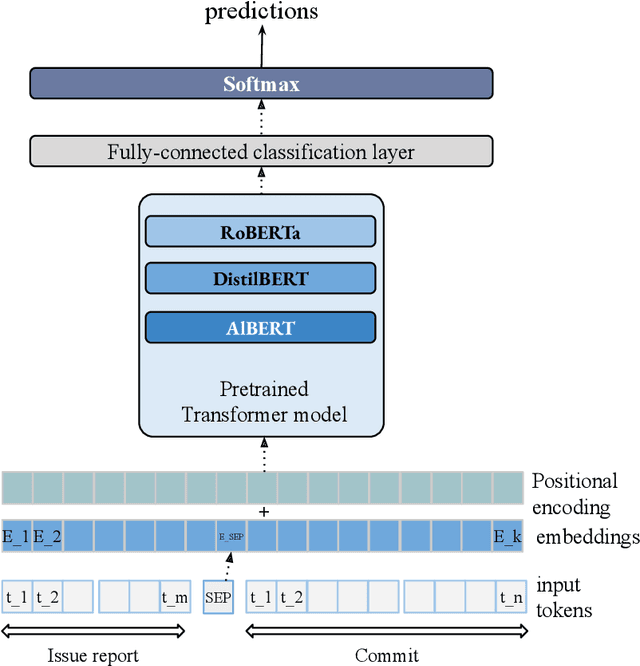
Software artifacts often interact with each other throughout the software development cycle. Associating related artifacts is a common practice for effective documentation and maintenance of software projects. Conventionally, to register the link between an issue report and its associated commit, developers manually include the issue identifier in the message of the relevant commit. Research has shown that developers tend to forget to connect said artifacts manually, resulting in a loss of links. Hence, several link recovery techniques were proposed to discover and revive such links automatically. However, the literature mainly focuses on improving the prediction accuracy on a randomly-split test set, while neglecting other important aspects of this problem, including the effect of time and generalizability of the predictive models. In this paper, we propose LinkFormer to address this problem from three aspects; 1) Accuracy: To better utilize contextual information for prediction, we employ the Transformer architecture and fine-tune multiple pre-trained models on textual and metadata of issues and commits. 2) Data leakage: To empirically assess the impact of time through the splitting policy, we train and test our proposed model along with several existing approaches on both randomly- and temporally split data. 3) Generalizability: To provide a generic model that can perform well across different projects, we further fine-tune LinkFormer in two transfer learning settings. We empirically show that researchers should preserve the temporal flow of data when training learning-based models to resemble the real-world setting. In addition, LinkFormer significantly outperforms the state-of-the-art by large margins. LinkFormer is also capable of extending the knowledge it learned to unseen projects with little to no historical data.
TOE: A Grid-Tagging Discontinuous NER Model Enhanced by Embedding Tag/Word Relations and More Fine-Grained Tags
Nov 01, 2022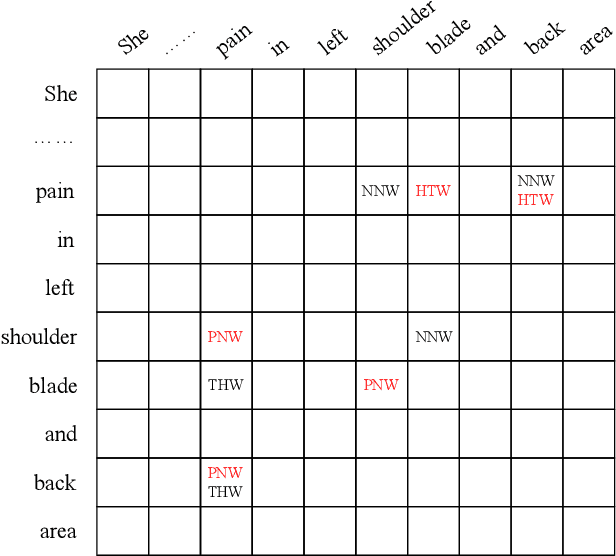
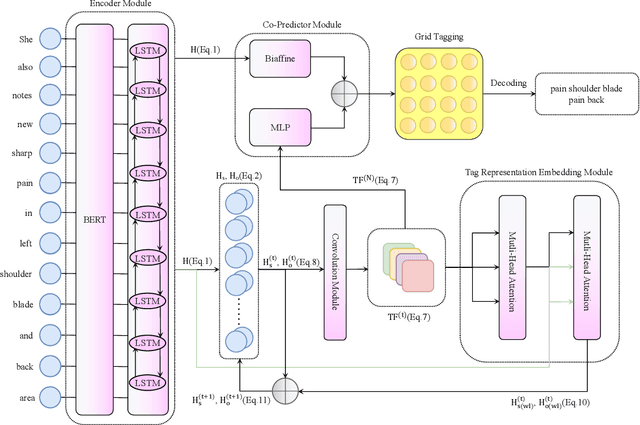
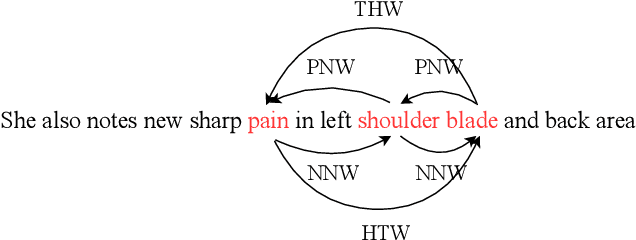
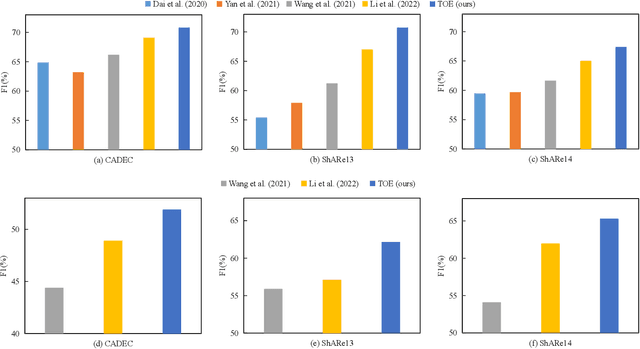
So far, discontinuous named entity recognition (NER) has received increasing research attention and many related methods have surged such as hypergraph-based methods, span-based methods, and sequence-to-sequence (Seq2Seq) methods, etc. However, these methods more or less suffer from some problems such as decoding ambiguity and efficiency, which limit their performance. Recently, grid-tagging methods, which benefit from the flexible design of tagging systems and model architectures, have shown superiority to adapt for various information extraction tasks. In this paper, we follow the line of such methods and propose a competitive grid-tagging model for discontinuous NER. We call our model TOE because we incorporate two kinds of Tag-Oriented Enhancement mechanisms into a state-of-the-art (SOTA) grid-tagging model that casts the NER problem into word-word relationship prediction. First, we design a Tag Representation Embedding Module (TREM) to force our model to consider not only word-word relationships but also word-tag and tag-tag relationships. Concretely, we construct tag representations and embed them into TREM, so that TREM can treat tag and word representations as queries/keys/values and utilize self-attention to model their relationships. On the other hand, motivated by the Next-Neighboring-Word (NNW) and Tail-Head-Word (THW) tags in the SOTA model, we add two new symmetric tags, namely Previous-Neighboring-Word (PNW) and Head-Tail-Word (HTW), to model more fine-grained word-word relationships and alleviate error propagation from tag prediction. In the experiments of three benchmark datasets, namely CADEC, ShARe13 and ShARe14, our TOE model pushes the SOTA results by about 0.83%, 0.05% and 0.66% in F1, demonstrating its effectiveness.
Class Distribution Monitoring for Concept Drift Detection
Oct 16, 2022
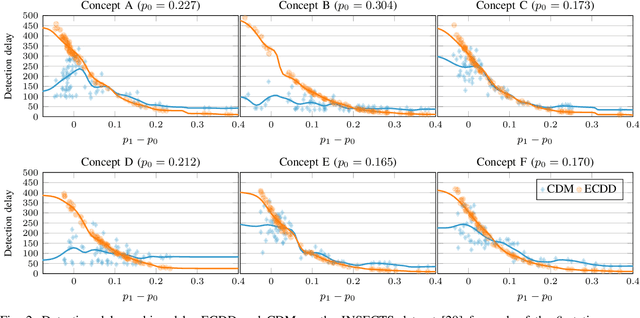
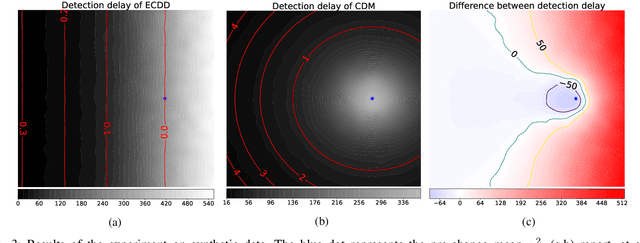

We introduce Class Distribution Monitoring (CDM), an effective concept-drift detection scheme that monitors the class-conditional distributions of a datastream. In particular, our solution leverages multiple instances of an online and nonparametric change-detection algorithm based on QuantTree. CDM reports a concept drift after detecting a distribution change in any class, thus identifying which classes are affected by the concept drift. This can be precious information for diagnostics and adaptation. Our experiments on synthetic and real-world datastreams show that when the concept drift affects a few classes, CDM outperforms algorithms monitoring the overall data distribution, while achieving similar detection delays when the drift affects all the classes. Moreover, CDM outperforms comparable approaches that monitor the classification error, particularly when the change is not very apparent. Finally, we demonstrate that CDM inherits the properties of the underlying change detector, yielding an effective control over the expected time before a false alarm, or Average Run Length (ARL$_0$).
PTab: Using the Pre-trained Language Model for Modeling Tabular Data
Sep 15, 2022

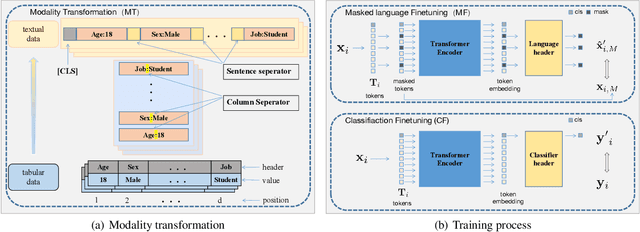
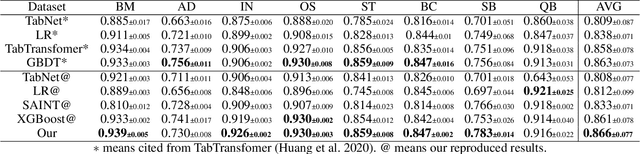
Tabular data is the foundation of the information age and has been extensively studied. Recent studies show that neural-based models are effective in learning contextual representation for tabular data. The learning of an effective contextual representation requires meaningful features and a large amount of data. However, current methods often fail to properly learn a contextual representation from the features without semantic information. In addition, it's intractable to enlarge the training set through mixed tabular datasets due to the difference between datasets. To address these problems, we propose a novel framework PTab, using the Pre-trained language model to model Tabular data. PTab learns a contextual representation of tabular data through a three-stage processing: Modality Transformation(MT), Masked-Language Fine-tuning(MF), and Classification Fine-tuning(CF). We initialize our model with a pre-trained Model (PTM) which contains semantic information learned from the large-scale language data. Consequently, contextual representation can be learned effectively during the fine-tuning stages. In addition, we can naturally mix the textualized tabular data to enlarge the training set to further improve representation learning. We evaluate PTab on eight popular tabular classification datasets. Experimental results show that our method has achieved a better average AUC score in supervised settings compared to the state-of-the-art baselines(e.g. XGBoost), and outperforms counterpart methods under semi-supervised settings. We present visualization results that show PTab has well instance-based interpretability.