 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AdaComm: Tracing Channel Dynamics for Reliable Cross-Technology Communication
Sep 30, 2022
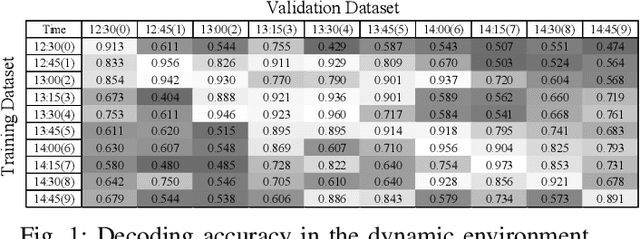
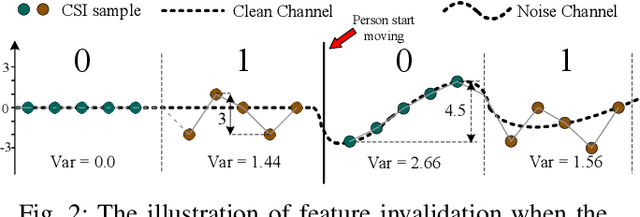
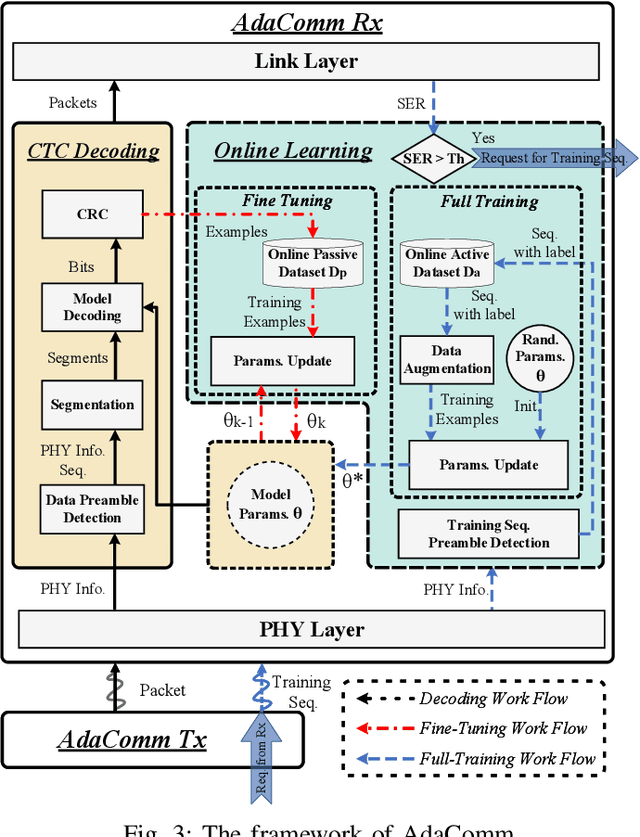
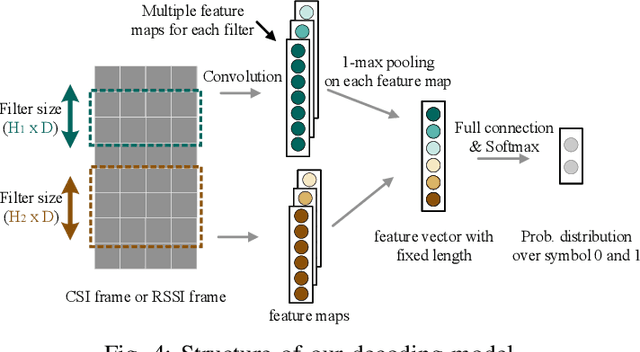
Cross-Technology Communication (CTC) is an emerging technology to support direct communication between wireless devices that follow different standards. In spite of the many different proposals from the community to enable CTC, the performance aspect of CTC is an equally important problem but has seldom been studied before. We find this problem is extremely challenging, due to the following reasons: on one hand, a link for CTC is essentially different from a conventional wireless link. The conventional link indicators like RSSI (received signal strength indicator) and SNR (signal to noise ratio) cannot be used to directly characterize a CTC link. On the other hand, the indirect indicators like PER (packet error rate), which is adopted by many existing CTC proposals, cannot capture the short-term link behavior. As a result, the existing CTC proposals fail to keep reliable performance under dynamic channel conditions. In order to address the above challenge, we in this paper propose AdaComm, a generic framework to achieve self-adaptive CTC in dynamic channels. Instead of reactively adjusting the CTC sender, AdaComm adopts online learning mechanism to adaptively adjust the decoding model at the CTC receiver. The self-adaptive decoding model automatically learns the effective features directly from the raw received signals that are embedded with the current channel state. With the lossless channel information, AdaComm further adopts the fine tuning and full training modes to cope with the continuous and abrupt channel dynamics. We implement AdaComm and integrate it with two existing CTC approaches that respectively employ CSI (channel state information) and RSSI as the information carrier. The evaluation results demonstrate that AdaComm can significantly reduce the SER (symbol error rate) by 72.9% and 49.2%, respectively, compared with the existing approaches.
Information-Theoretic Bayes Risk Lower Bounds for Realizable Models
Nov 08, 2021We derive information-theoretic lower bounds on the Bayes risk and generalization error of realizable machine learning models. In particular, we employ an analysis in which the rate-distortion function of the model parameters bounds the required mutual information between the training samples and the model parameters in order to learn a model up to a Bayes risk constraint. For realizable models, we show that both the rate distortion function and mutual information admit expressions that are convenient for analysis. For models that are (roughly) lower Lipschitz in their parameters, we bound the rate distortion function from below, whereas for VC classes, the mutual information is bounded above by $d_\mathrm{vc}\log(n)$. When these conditions match, the Bayes risk with respect to the zero-one loss scales no faster than $\Omega(d_\mathrm{vc}/n)$, which matches known outer bounds and minimax lower bounds up to logarithmic factors. We also consider the impact of label noise, providing lower bounds when training and/or test samples are corrupted.
Multi-task Self-supervised Graph Neural Networks Enable Stronger Task Generalization
Oct 05, 2022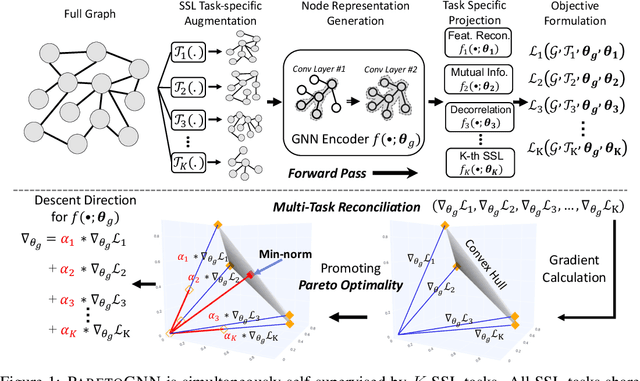
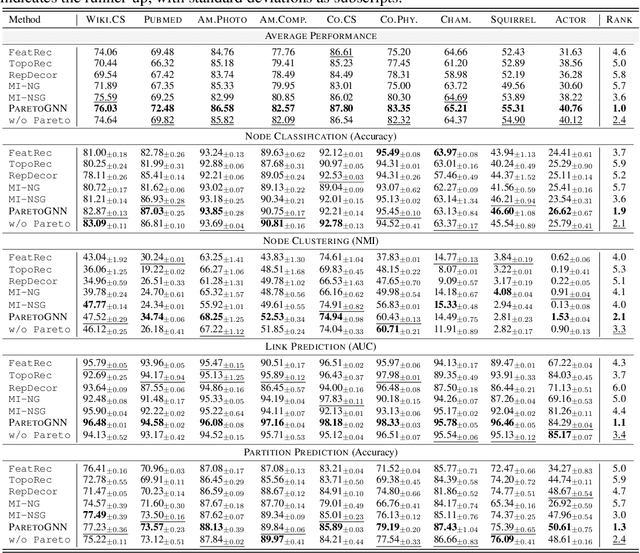
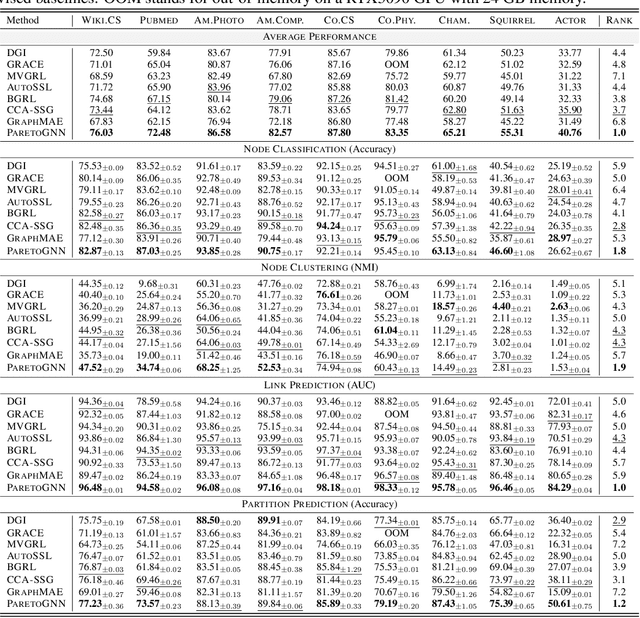
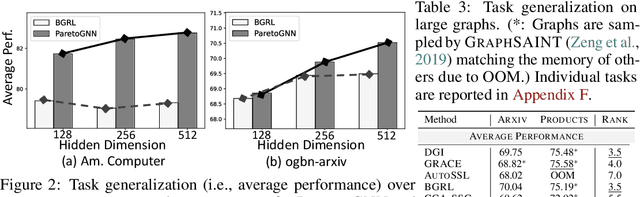
Self-supervised learning (SSL) for graph neural networks (GNNs) has attracted increasing attention from the graph machine learning community in recent years, owing to its capability to learn performant node embeddings without costly label information. One weakness of conventional SSL frameworks for GNNs is that they learn through a single philosophy, such as mutual information maximization or generative reconstruction. When applied to various downstream tasks, these frameworks rarely perform equally well for every task, because one philosophy may not span the extensive knowledge required for all tasks. In light of this, we introduce ParetoGNN, a multi-task SSL framework for node representation learning over graphs. Specifically, ParetoGNN is self-supervised by manifold pretext tasks observing multiple philosophies. To reconcile different philosophies, we explore a multiple-gradient descent algorithm, such that ParetoGNN actively learns from every pretext task while minimizing potential conflicts. We conduct comprehensive experiments over four downstream tasks (i.e., node classification, node clustering, link prediction, and partition prediction), and our proposal achieves the best overall performance across tasks on 11 widely adopted benchmark datasets. Besides, we observe that learning from multiple philosophies enhances not only the task generalization but also the single task performance, demonstrating that ParetoGNN achieves better task generalization via the disjoint yet complementary knowledge learned from different philosophies.
Evolving Neural Networks with Optimal Balance between Information Flow and Connections Cost
Mar 14, 2022
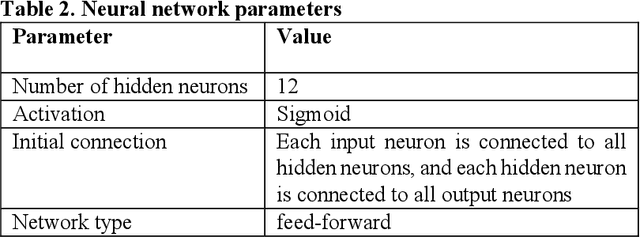
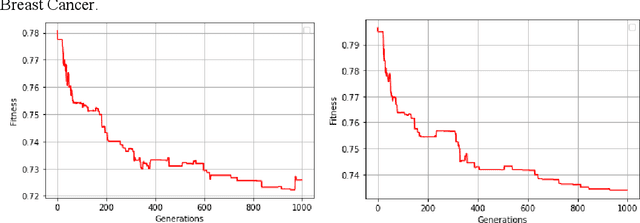
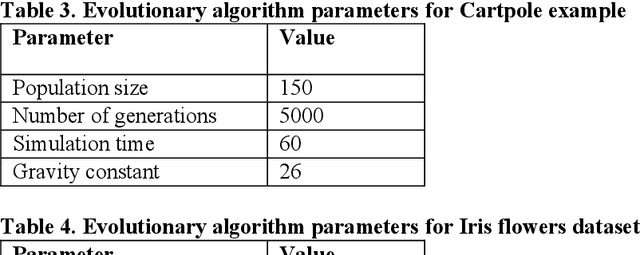
Evolving Neural Networks (NNs) has recently seen an increasing interest as an alternative path that might be more successful. It has many advantages compared to other approaches, such as learning the architecture of the NNs. However, the extremely large search space and the existence of many complex interacting parts still represent a major obstacle. Many criteria were recently investigated to help guide the algorithm and to cut down the large search space. Recently there has been growing research bringing insights from network science to improve the design of NNs. In this paper, we investigate evolving NNs architectures that have one of the most fundamental characteristics of real-world networks, namely the optimal balance between connections cost and information flow. The performance of different metrics that represent this balance is evaluated and the improvement in the accuracy of putting more selection pressure toward this balance is demonstrated on three datasets.
Camera Alignment and Weighted Contrastive Learning for Domain Adaptation in Video Person ReID
Nov 07, 2022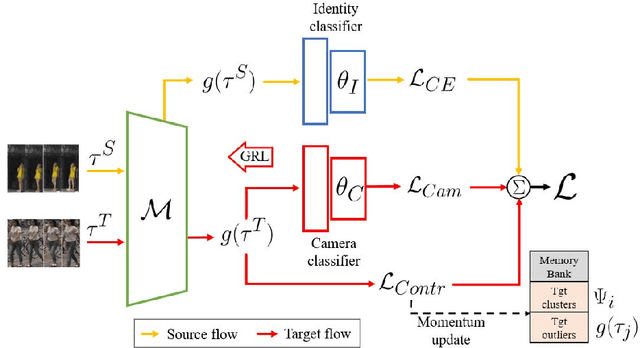
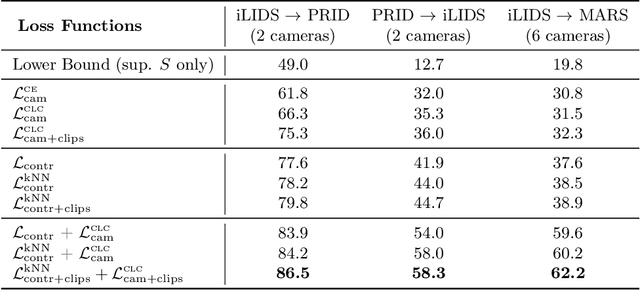
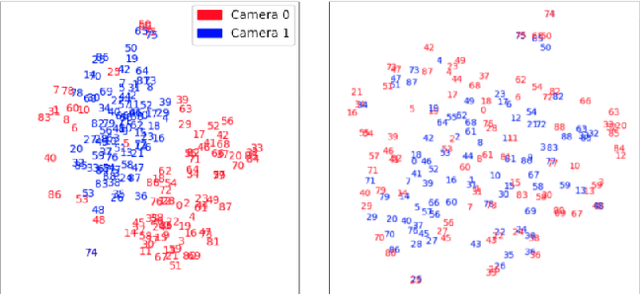
Systems for person re-identification (ReID) can achieve a high accuracy when trained on large fully-labeled image datasets. However, the domain shift typically associated with diverse operational capture conditions (e.g., camera viewpoints and lighting) may translate to a significant decline in performance. This paper focuses on unsupervised domain adaptation (UDA) for video-based ReID - a relevant scenario that is less explored in the literature. In this scenario, the ReID model must adapt to a complex target domain defined by a network of diverse video cameras based on tracklet information. State-of-art methods cluster unlabeled target data, yet domain shifts across target cameras (sub-domains) can lead to poor initialization of clustering methods that propagates noise across epochs, thus preventing the ReID model to accurately associate samples of same identity. In this paper, an UDA method is introduced for video person ReID that leverages knowledge on video tracklets, and on the distribution of frames captured over target cameras to improve the performance of CNN backbones trained using pseudo-labels. Our method relies on an adversarial approach, where a camera-discriminator network is introduced to extract discriminant camera-independent representations, facilitating the subsequent clustering. In addition, a weighted contrastive loss is proposed to leverage the confidence of clusters, and mitigate the risk of incorrect identity associations. Experimental results obtained on three challenging video-based person ReID datasets - PRID2011, iLIDS-VID, and MARS - indicate that our proposed method can outperform related state-of-the-art methods. Our code is available at: \url{https://github.com/dmekhazni/CAWCL-ReID}
BuildMapper: A Fully Learnable Framework for Vectorized Building Contour Extraction
Nov 07, 2022
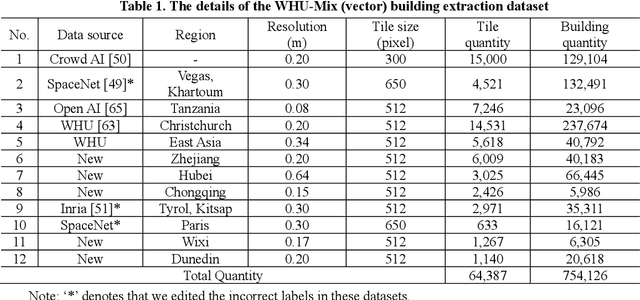
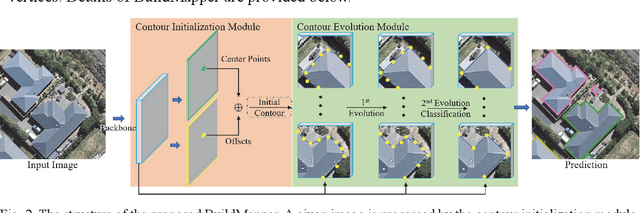

Deep learning based methods have significantly boosted the study of automatic building extraction from remote sensing images. However, delineating vectorized and regular building contours like a human does remains very challenging, due to the difficulty of the methodology, the diversity of building structures, and the imperfect imaging conditions. In this paper, we propose the first end-to-end learnable building contour extraction framework, named BuildMapper, which can directly and efficiently delineate building polygons just as a human does. BuildMapper consists of two main components: 1) a contour initialization module that generates initial building contours; and 2) a contour evolution module that performs both contour vertex deformation and reduction, which removes the need for complex empirical post-processing used in existing methods. In both components, we provide new ideas, including a learnable contour initialization method to replace the empirical methods, dynamic predicted and ground truth vertex pairing for the static vertex correspondence problem, and a lightweight encoder for vertex information extraction and aggregation, which benefit a general contour-based method; and a well-designed vertex classification head for building corner vertices detection, which casts light on direct structured building contour extraction. We also built a suitable large-scale building dataset, the WHU-Mix (vector) building dataset, to benefit the study of contour-based building extraction methods. The extensive experiments conducted on the WHU-Mix (vector) dataset, the WHU dataset, and the CrowdAI dataset verified that BuildMapper can achieve a state-of-the-art performance, with a higher mask average precision (AP) and boundary AP than both segmentation-based and contour-based methods.
Lipschitz regularized gradient flows and latent generative particles
Nov 07, 2022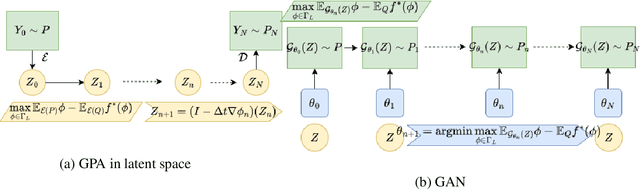

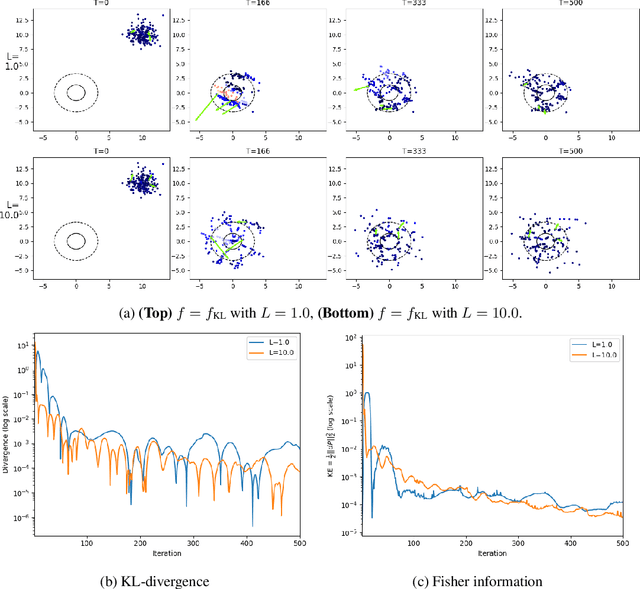
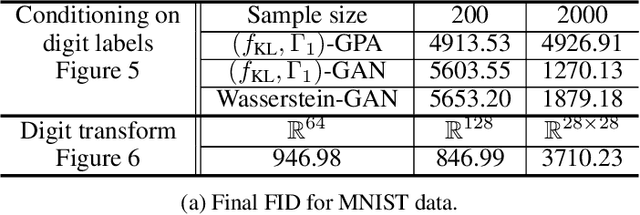
Lipschitz regularized f-divergences are constructed by imposing a bound on the Lipschitz constant of the discriminator in the variational representation. They interpolate between the Wasserstein metric and f-divergences and provide a flexible family of loss functions for non-absolutely continuous (e.g. empirical) distributions, possibly with heavy tails. We construct Lipschitz regularized gradient flows on the space of probability measures based on these divergences. Examples of such gradient flows are Lipschitz regularized Fokker-Planck and porous medium partial differential equations (PDEs) for the Kullback-Leibler and alpha-divergences, respectively. The regularization corresponds to imposing a Courant-Friedrichs-Lewy numerical stability condition on the PDEs. For empirical measures, the Lipschitz regularization on gradient flows induces a numerically stable transporter/discriminator particle algorithm, where the generative particles are transported along the gradient of the discriminator. The gradient structure leads to a regularized Fisher information (particle kinetic energy) used to track the convergence of the algorithm. The Lipschitz regularized discriminator can be implemented via neural network spectral normalization and the particle algorithm generates approximate samples from possibly high-dimensional distributions known only from data. Notably, our particle algorithm can generate synthetic data even in small sample size regimes. A new data processing inequality for the regularized divergence allows us to combine our particle algorithm with representation learning, e.g. autoencoder architectures. The resulting algorithm yields markedly improved generative properties in terms of efficiency and quality of the synthetic samples. From a statistical mechanics perspective the encoding can be interpreted dynamically as learning a better mobility for the generative particles.
PROB-SLAM: Real-time Visual SLAM Based on Probabilistic Graph Optimization
Sep 15, 2022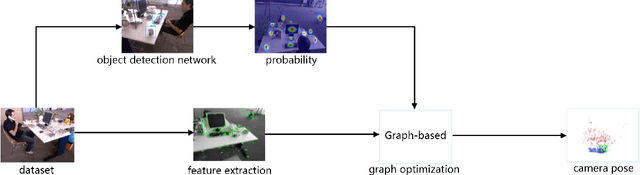
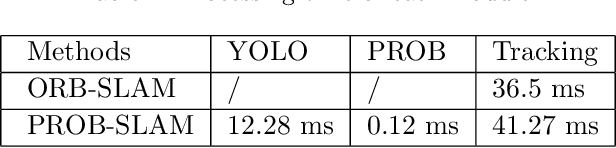
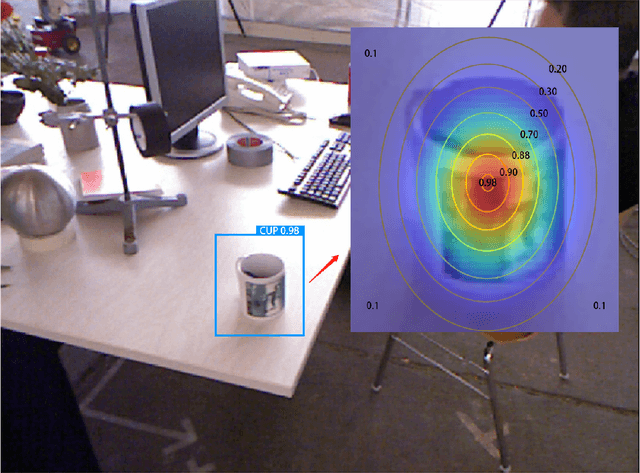

Traditional SLAM algorithms are typically based on artificial features, which lack high-level information. By introducing semantic information, SLAM can own higher stability and robustness rather than purely hand-crafted features. However, the high uncertainty of semantic detection networks prohibits the practical functionality of high-level information. To solve the uncertainty property introduced by semantics, this paper proposed a novel probability map based on the Gaussian distribution assumption. This map transforms the semantic binary object detection into probability results, which help establish a probabilistic data association between artificial features and semantic info. Through our algorithm, the higher confidence will be given higher weights in each update step while the edge of the detection area will be endowed with lower confidence. Then the uncertainty is undermined and has less effect on nonlinear optimization. The experiments are carried out in the TUM RGBD dataset, results show that our system improves ORB-SLAM2 by about 15% in indoor environments' errors. We have demonstrated that the method can be successfully applied to environments containing dynamic objects.
Multimodality Multi-Lead ECG Arrhythmia Classification using Self-Supervised Learning
Sep 30, 2022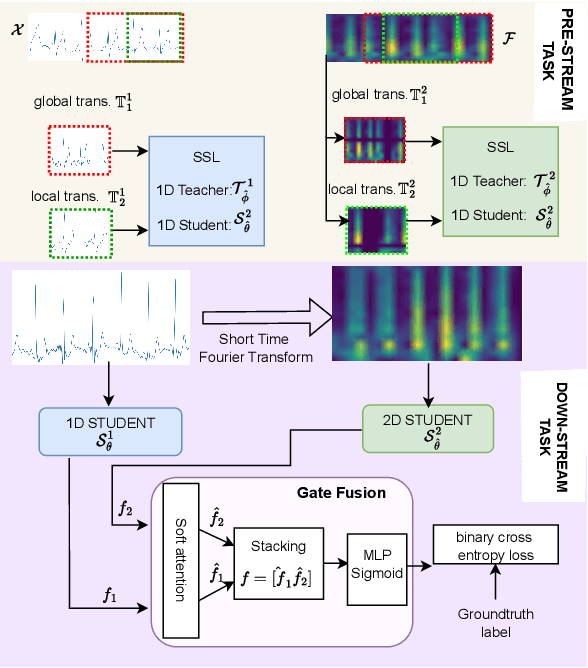
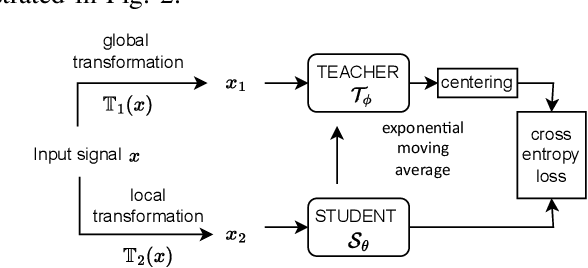
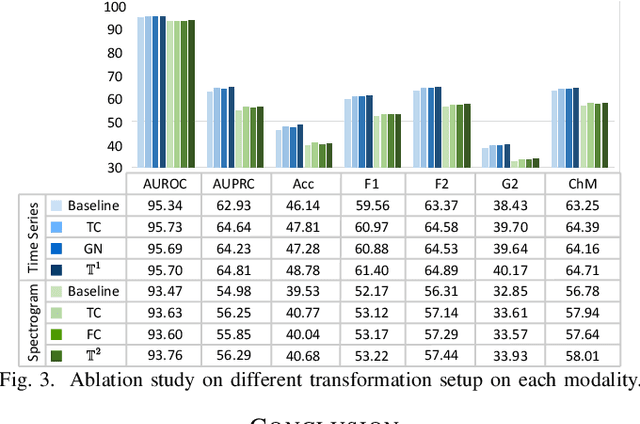
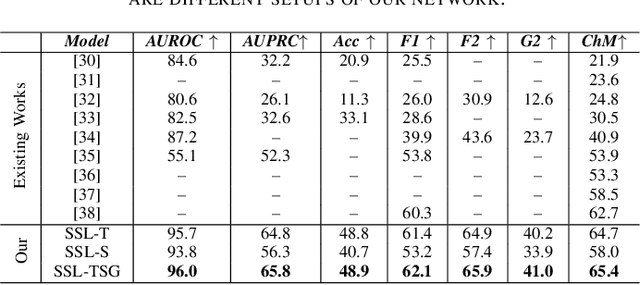
Electrocardiogram (ECG) signal is one of the most effective sources of information mainly employed for the diagnosis and prediction of cardiovascular diseases (CVDs) connected with the abnormalities in heart rhythm. Clearly, single modality ECG (i.e. time series) cannot convey its complete characteristics, thus, exploiting both time and time-frequency modalities in the form of time-series data and spectrogram is needed. Leveraging the cutting-edge self-supervised learning (SSL) technique on unlabeled data, we propose SSL-based multimodality ECG classification. Our proposed network follows SSL learning paradigm and consists of two modules corresponding to pre-stream task, and down-stream task, respectively. In the SSL-pre-stream task, we utilize self-knowledge distillation (KD) techniques with no labeled data, on various transformations and in both time and frequency domains. In the down-stream task, which is trained on labeled data, we propose a gate fusion mechanism to fuse information from multimodality.To evaluate the effectiveness of our approach, ten-fold cross validation on the 12-lead PhysioNet 2020 dataset has been conducted.
Reliable Malware Analysis and Detection using Topology Data Analysis
Nov 03, 2022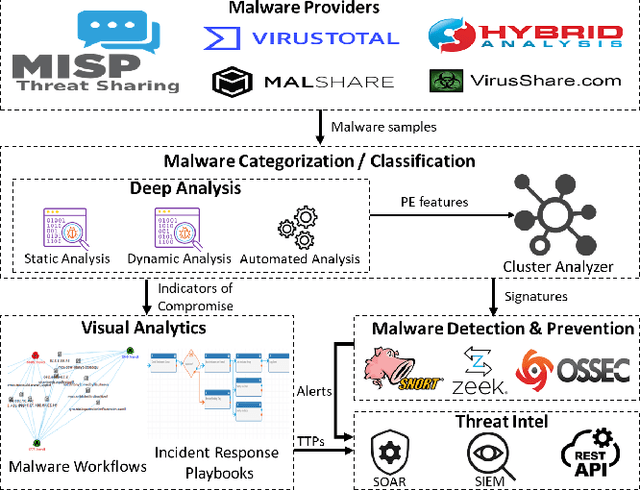
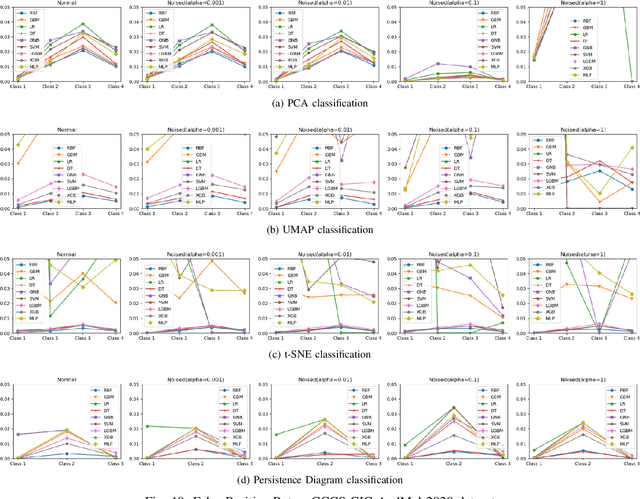
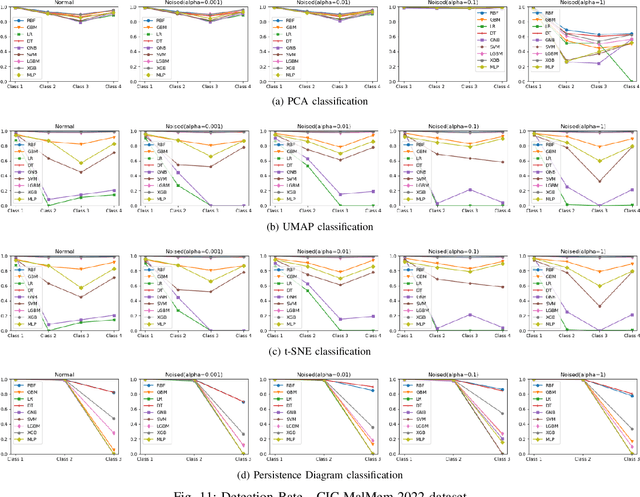
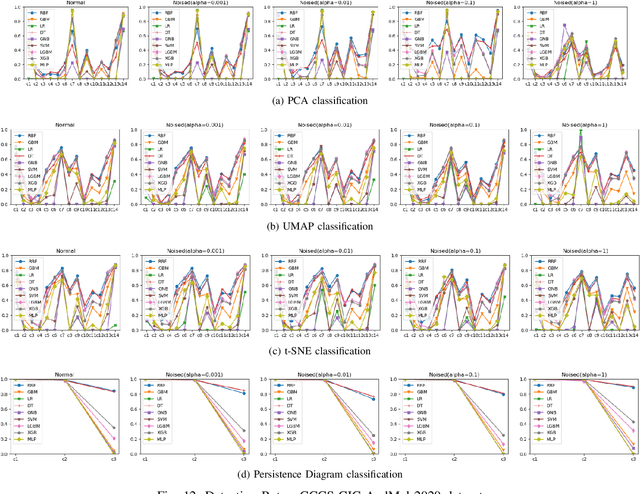
Increasingly, malwares are becoming complex and they are spreading on networks targeting different infrastructures and personal-end devices to collect, modify, and destroy victim information. Malware behaviors are polymorphic, metamorphic, persistent, able to hide to bypass detectors and adapt to new environments, and even leverage machine learning techniques to better damage targets. Thus, it makes them difficult to analyze and detect with traditional endpoint detection and response, intrusion detection and prevention systems. To defend against malwares, recent work has proposed different techniques based on signatures and machine learning. In this paper, we propose to use an algebraic topological approach called topological-based data analysis (TDA) to efficiently analyze and detect complex malware patterns. Next, we compare the different TDA techniques (i.e., persistence homology, tomato, TDA Mapper) and existing techniques (i.e., PCA, UMAP, t-SNE) using different classifiers including random forest, decision tree, xgboost, and lightgbm. We also propose some recommendations to deploy the best-identified models for malware detection at scale. Results show that TDA Mapper (combined with PCA) is better for clustering and for identifying hidden relationships between malware clusters compared to PCA. Persistent diagrams are better to identify overlapping malware clusters with low execution time compared to UMAP and t-SNE. For malware detection, malware analysts can use Random Forest and Decision Tree with t-SNE and Persistent Diagram to achieve better performance and robustness on noised data.