 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Variational Causal Inference
Sep 13, 2022
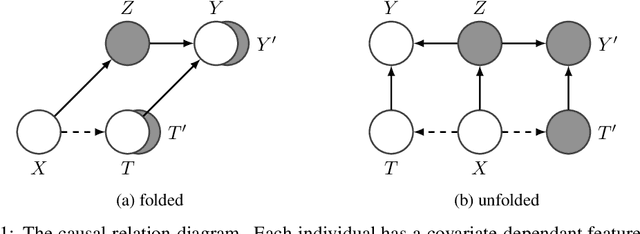
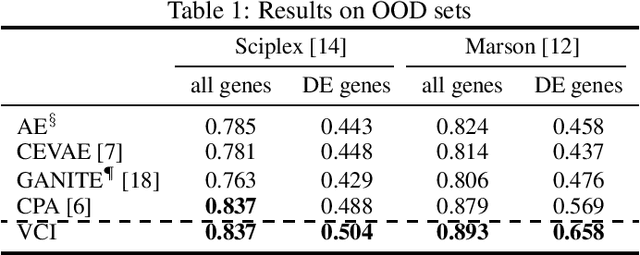
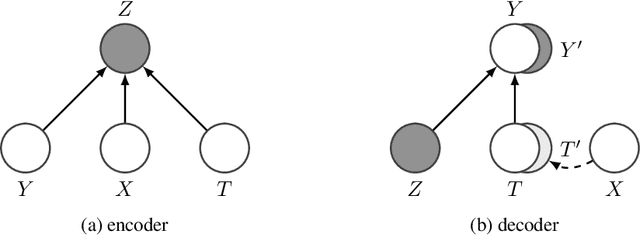
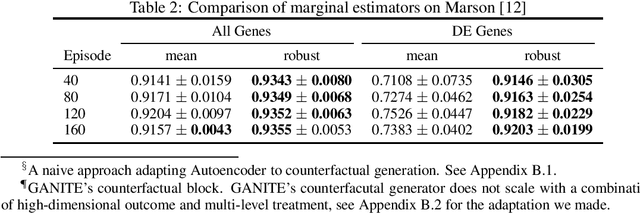
Estimating an individual's potential outcomes under counterfactual treatments is a challenging task for traditional causal inference and supervised learning approaches when the outcome is high-dimensional (e.g. gene expressions, impulse responses, human faces) and covariates are relatively limited. In this case, to construct one's outcome under a counterfactual treatment, it is crucial to leverage individual information contained in its observed factual outcome on top of the covariates. We propose a deep variational Bayesian framework that rigorously integrates two main sources of information for outcome construction under a counterfactual treatment: one source is the individual features embedded in the high-dimensional factual outcome; the other source is the response distribution of similar subjects (subjects with the same covariates) that factually received this treatment of interest.
Impact of annotation modality on label quality and model performance in the automatic assessment of laughter in-the-wild
Nov 02, 2022
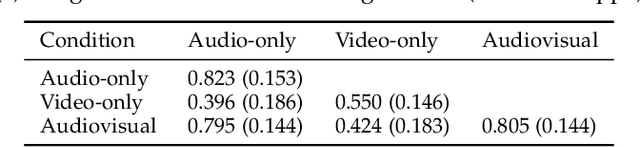
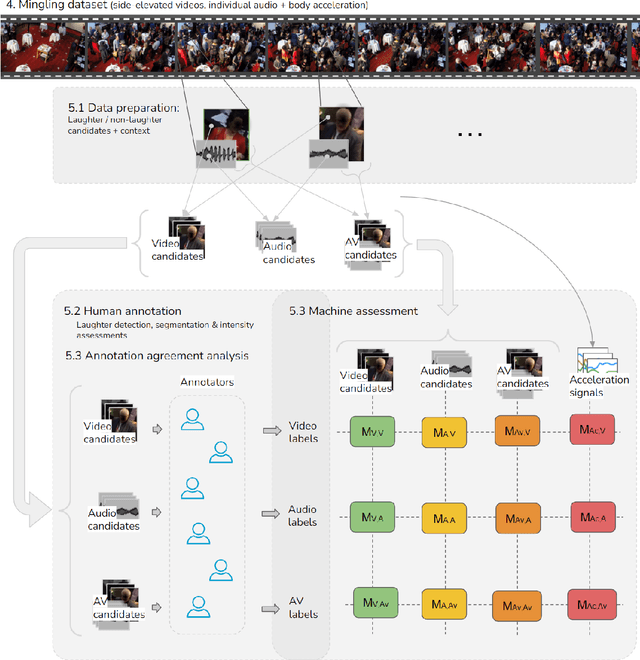
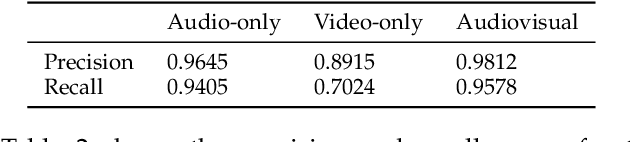
Laughter is considered one of the most overt signals of joy. Laughter is well-recognized as a multimodal phenomenon but is most commonly detected by sensing the sound of laughter. It is unclear how perception and annotation of laughter differ when annotated from other modalities like video, via the body movements of laughter. In this paper we take a first step in this direction by asking if and how well laughter can be annotated when only audio, only video (containing full body movement information) or audiovisual modalities are available to annotators. We ask whether annotations of laughter are congruent across modalities, and compare the effect that labeling modality has on machine learning model performance. We compare annotations and models for laughter detection, intensity estimation, and segmentation, three tasks common in previous studies of laughter. Our analysis of more than 4000 annotations acquired from 48 annotators revealed evidence for incongruity in the perception of laughter, and its intensity between modalities. Further analysis of annotations against consolidated audiovisual reference annotations revealed that recall was lower on average for video when compared to the audio condition, but tended to increase with the intensity of the laughter samples. Our machine learning experiments compared the performance of state-of-the-art unimodal (audio-based, video-based and acceleration-based) and multi-modal models for different combinations of input modalities, training label modality, and testing label modality. Models with video and acceleration inputs had similar performance regardless of training label modality, suggesting that it may be entirely appropriate to train models for laughter detection from body movements using video-acquired labels, despite their lower inter-rater agreement.
A study linking patient EHR data to external death data at Stanford Medicine
Nov 02, 2022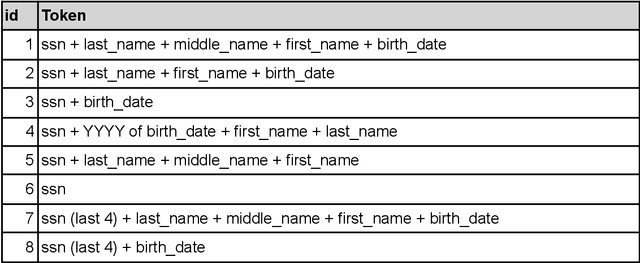
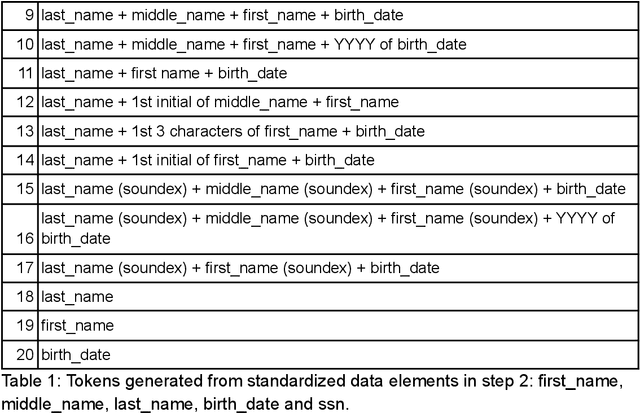
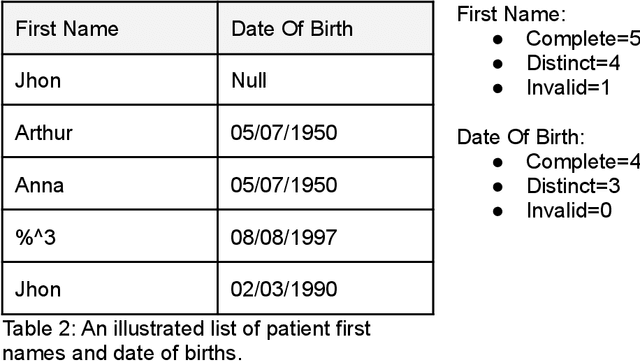
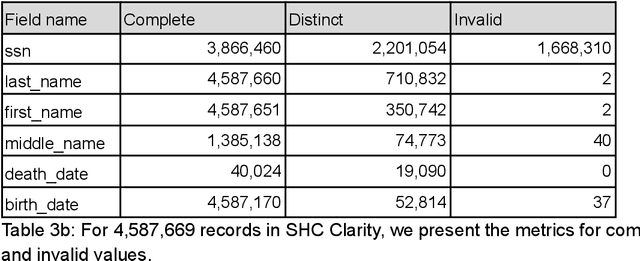
This manuscript explores linking real-world patient data with external death data in the context of research Clinical Data Warehouses (r-CDWs). We specifically present the linking of Electronic Health Records (EHR) data for Stanford Health Care (SHC) patients and data from the Social Security Administration (SSA) Limited Access Death Master File (LADMF) made available by the US Department of Commerce's National Technical Information Service (NTIS). The data analysis framework presented in this manuscript extends prior approaches and is generalizable to linking any two cross-organizational real-world patient data sources. Electronic Health Record (EHR) data and NTIS LADMF are heavily used resources at other medical centers and we expect that the methods and learnings presented here will be valuable to others. Our findings suggest that strong linkages are incomplete and weak linkages are noisy i.e., there is no good linkage rule that provides coverage and accuracy. Furthermore, the best linkage rule for any two datasets is different from the best linkage rule for two other datasets i.e., there is no generalization of linkage rules. Finally, LADMF, a commonly used external death data resource for r-CDWs, has a significant gap in death data making it necessary for r-CDWs to seek out more than one external death data source. We anticipate that presentation of multiple linkages will make it hard to present the linkage outcome to the end user. This manuscript is a resource in support of Stanford Medicine STARR (STAnford medicine Research data Repository) r-CDWs. The data are stored and analyzed as PHI in our HIPAA-compliant data center and are used under research and development (R&D) activities of STARR IRB.
Coordinated Transmit Beamforming for Multi-antenna Network Integrated Sensing and Communication
Nov 02, 2022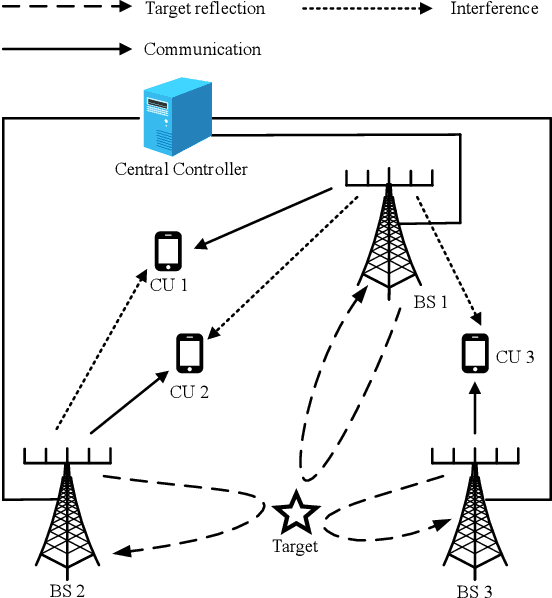
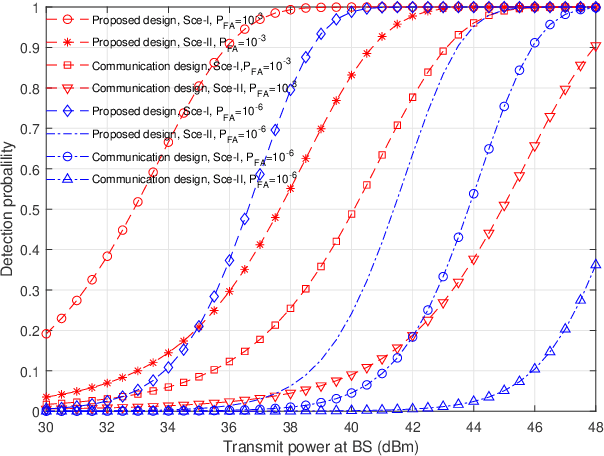
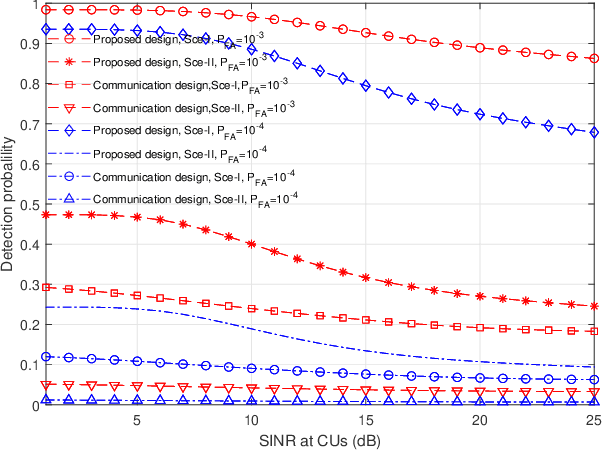
This paper studies a multi-antenna network integrated sensing and communication (ISAC) system, in which a set of multi-antenna base stations (BSs) employ the coordinated transmit beamforming to serve their respectively associated single-antenna communication users (CUs), and at the same time reuse the reflected information signals to perform joint target detection. In particular, we consider two target detection scenarios depending on the time synchronization among BSs. In Scenario \uppercase\expandafter{\romannumeral1}, these BSs are synchronized and can exploit the target-reflected signals over both the direct links (from each BS to target to itself) and the cross links (from each BS to target to other BSs) for joint detection. In Scenario \uppercase\expandafter{\romannumeral2}, these BSs are not synchronized and can only utilize target-reflected signals over the direct links for joint detection. For each scenario, we derive the detection probability under a specific false alarm probability at any given target location. Based on the derivation, we optimize the coordinated transmit beamforming at the BSs to maximize the minimum detection probability over a particular target area, while ensuring the minimum signal-to-interference-plus-noise ratio (SINR) constraints at the CUs, subject to the maximum transmit power constraints at the BSs. We use the semi-definite relaxation (SDR) technique to obtain highly-quality solutions to the formulated problems. Numerical results show that for each scenario, the proposed design achieves higher detection probability than the benchmark scheme based on communication design. It is also shown that the time synchronization among BSs is beneficial in enhancing the detection performance as more reflected signal paths are exploited.
Revisiting the Uniform Information Density Hypothesis
Sep 23, 2021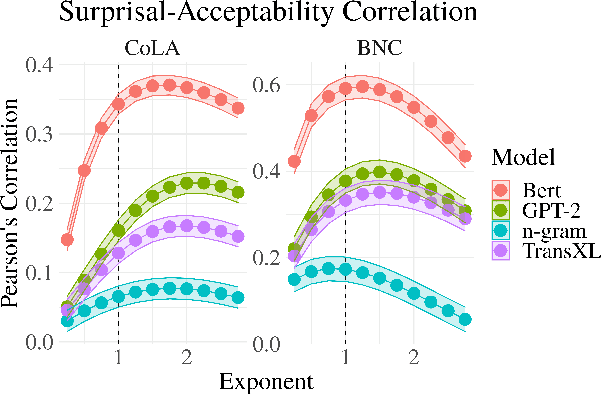
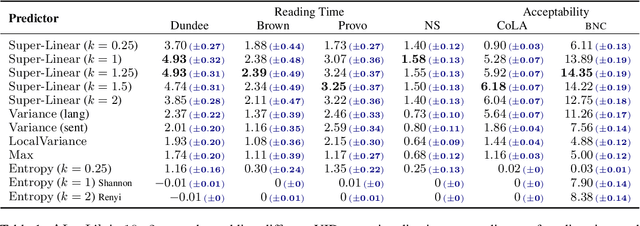
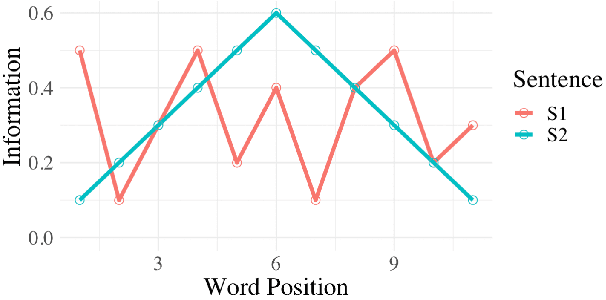
The uniform information density (UID) hypothesis posits a preference among language users for utterances structured such that information is distributed uniformly across a signal. While its implications on language production have been well explored, the hypothesis potentially makes predictions about language comprehension and linguistic acceptability as well. Further, it is unclear how uniformity in a linguistic signal -- or lack thereof -- should be measured, and over which linguistic unit, e.g., the sentence or language level, this uniformity should hold. Here we investigate these facets of the UID hypothesis using reading time and acceptability data. While our reading time results are generally consistent with previous work, they are also consistent with a weakly super-linear effect of surprisal, which would be compatible with UID's predictions. For acceptability judgments, we find clearer evidence that non-uniformity in information density is predictive of lower acceptability. We then explore multiple operationalizations of UID, motivated by different interpretations of the original hypothesis, and analyze the scope over which the pressure towards uniformity is exerted. The explanatory power of a subset of the proposed operationalizations suggests that the strongest trend may be a regression towards a mean surprisal across the language, rather than the phrase, sentence, or document -- a finding that supports a typical interpretation of UID, namely that it is the byproduct of language users maximizing the use of a (hypothetical) communication channel.
Deepfake Text Detection: Limitations and Opportunities
Oct 17, 2022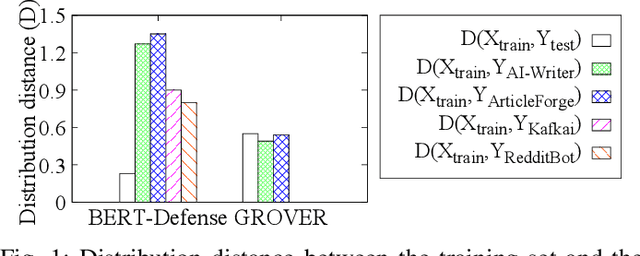
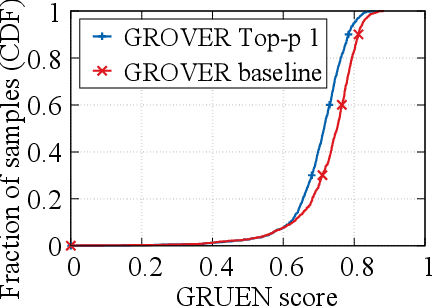
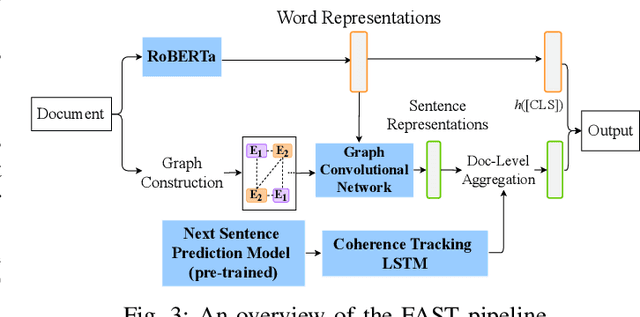
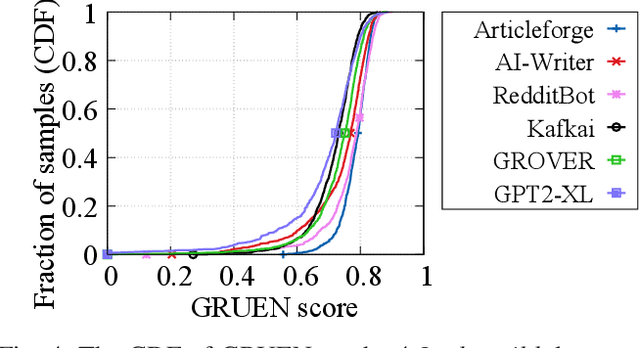
Recent advances in generative models for language have enabled the creation of convincing synthetic text or deepfake text. Prior work has demonstrated the potential for misuse of deepfake text to mislead content consumers. Therefore, deepfake text detection, the task of discriminating between human and machine-generated text, is becoming increasingly critical. Several defenses have been proposed for deepfake text detection. However, we lack a thorough understanding of their real-world applicability. In this paper, we collect deepfake text from 4 online services powered by Transformer-based tools to evaluate the generalization ability of the defenses on content in the wild. We develop several low-cost adversarial attacks, and investigate the robustness of existing defenses against an adaptive attacker. We find that many defenses show significant degradation in performance under our evaluation scenarios compared to their original claimed performance. Our evaluation shows that tapping into the semantic information in the text content is a promising approach for improving the robustness and generalization performance of deepfake text detection schemes.
Break The Spell Of Total Correlation In betaTCVAE
Oct 17, 2022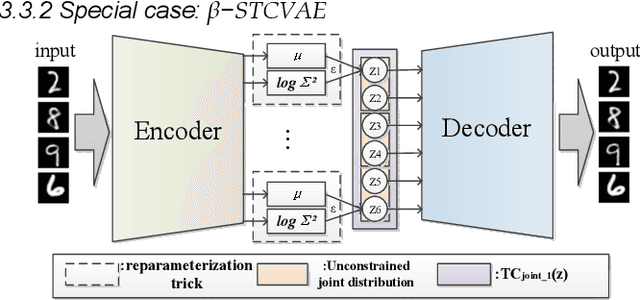
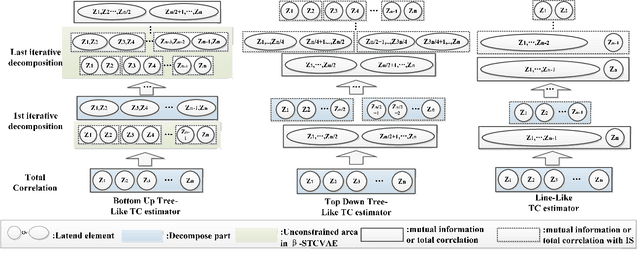

This paper proposes a way to break the spell of total correlation in betaTCVAE based on the motivation of the total correlation decomposition. An iterative decomposition path of total correlation is proposed, and an explanation for representation learning ability of VAE from the perspective of model capacity allocation. Newly developed objective function combines latent variable dimensions into joint distribution while relieving independent distribution constraint of the marginal distribution in combination, leading to latent variables with a more manipulable prior distribution. The novel model enables VAE to adjust the parameter capacity to divide dependent and independent data features flexibly. Experimental results on various datasets show an interesting relevance between model capacity and the latent variable grouping size, called the "V"-shaped best ELBO trajectory. Additional experiments demonstrate that the proposed method obtains better disentanglement performance with reasonable parameter capacity allocation. Finally, we design experiments to show the limitations of estimating total correlation with mutual information, identifying its source of estimation deviation.
S$^3$-NeRF: Neural Reflectance Field from Shading and Shadow under a Single Viewpoint
Oct 17, 2022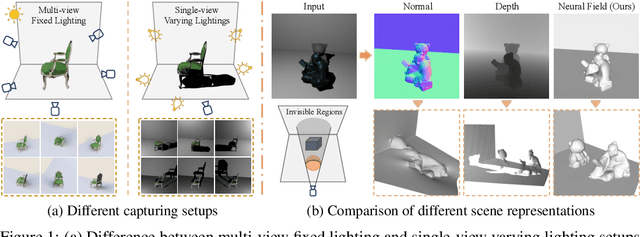
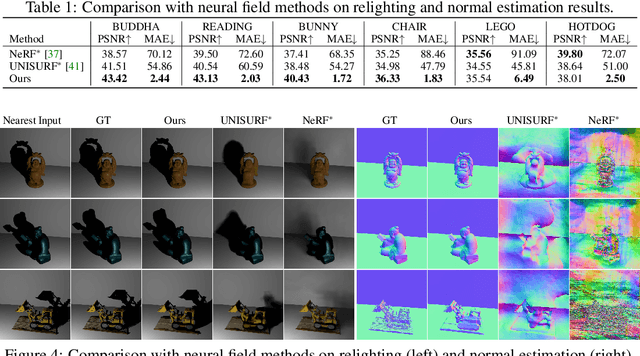
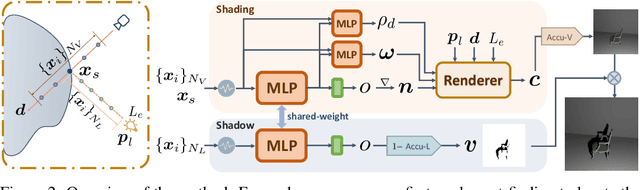
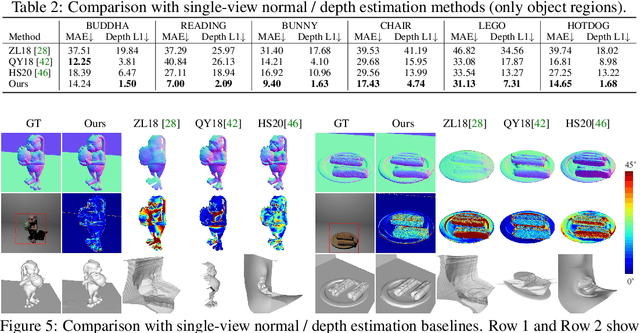
In this paper, we address the "dual problem" of multi-view scene reconstruction in which we utilize single-view images captured under different point lights to learn a neural scene representation. Different from existing single-view methods which can only recover a 2.5D scene representation (i.e., a normal / depth map for the visible surface), our method learns a neural reflectance field to represent the 3D geometry and BRDFs of a scene. Instead of relying on multi-view photo-consistency, our method exploits two information-rich monocular cues, namely shading and shadow, to infer scene geometry. Experiments on multiple challenging datasets show that our method is capable of recovering 3D geometry, including both visible and invisible parts, of a scene from single-view images. Thanks to the neural reflectance field representation, our method is robust to depth discontinuities. It supports applications like novel-view synthesis and relighting. Our code and model can be found at https://ywq.github.io/s3nerf.
A Symbolic Representation of Human Posture for Interpretable Learning and Reasoning
Oct 17, 2022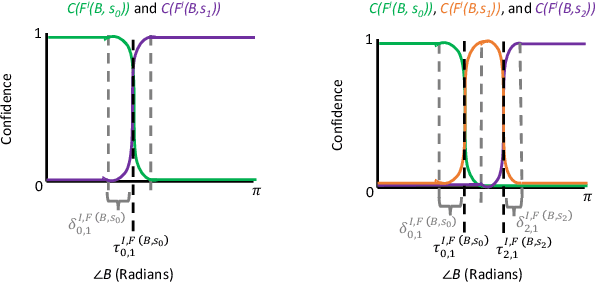
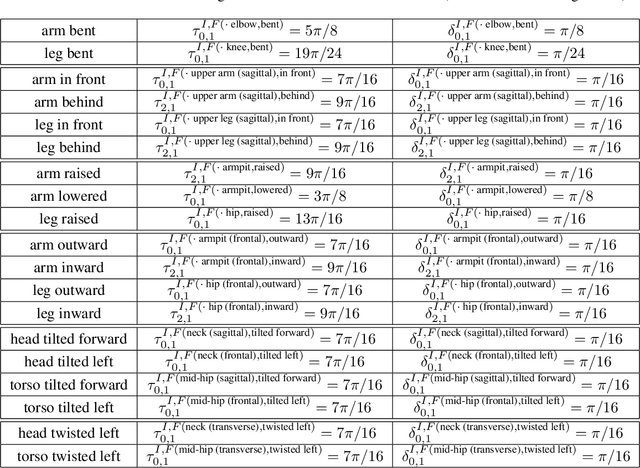
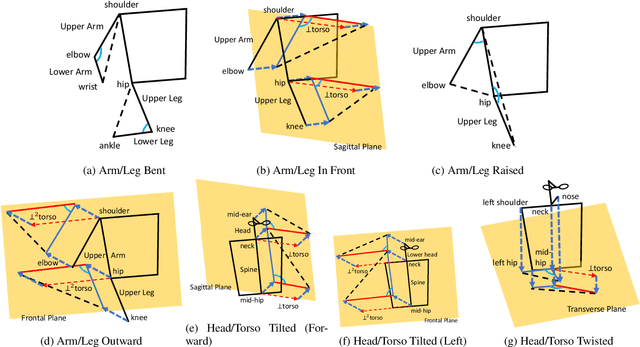

Robots that interact with humans in a physical space or application need to think about the person's posture, which typically comes from visual sensors like cameras and infra-red. Artificial intelligence and machine learning algorithms use information from these sensors either directly or after some level of symbolic abstraction, and the latter usually partitions the range of observed values to discretize the continuous signal data. Although these representations have been effective in a variety of algorithms with respect to accuracy and task completion, the underlying models are rarely interpretable, which also makes their outputs more difficult to explain to people who request them. Instead of focusing on the possible sensor values that are familiar to a machine, we introduce a qualitative spatial reasoning approach that describes the human posture in terms that are more familiar to people. This paper explores the derivation of our symbolic representation at two levels of detail and its preliminary use as features for interpretable activity recognition.
Confound-leakage: Confound Removal in Machine Learning Leads to Leakage
Oct 17, 2022Machine learning (ML) approaches to data analysis are now widely adopted in many fields including epidemiology and medicine. To apply these approaches, confounds must first be removed as is commonly done by featurewise removal of their variance by linear regression before applying ML. Here, we show this common approach to confound removal biases ML models, leading to misleading results. Specifically, this common deconfounding approach can leak information such that what are null or moderate effects become amplified to near-perfect prediction when nonlinear ML approaches are subsequently applied. We identify and evaluate possible mechanisms for such confound-leakage and provide practical guidance to mitigate its negative impact. We demonstrate the real-world importance of confound-leakage by analyzing a clinical dataset where accuracy is overestimated for predicting attention deficit hyperactivity disorder (ADHD) with depression as a confound. Our results have wide-reaching implications for implementation and deployment of ML workflows and beg caution against na\"ive use of standard confound removal approaches.