 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Clustering-based Tile Embedding (CTE): A General Representation for Level Design with Skewed Tile Distributions
Oct 23, 2022


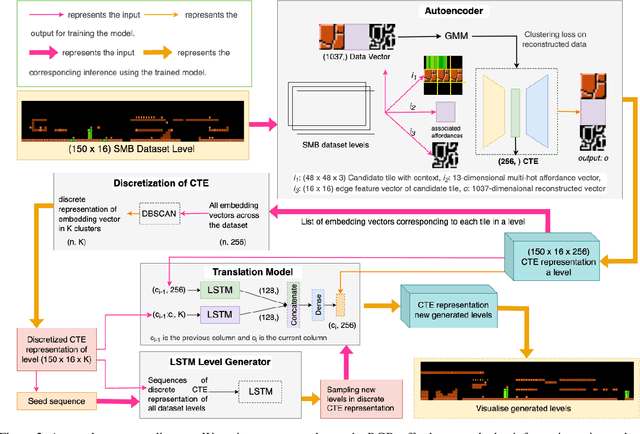
There has been significant research interest in Procedural Level Generation via Machine Learning (PLGML), applying ML techniques to automated level generation. One recent trend is in the direction of learning representations for level design via embeddings, such as tile embeddings. Tile Embeddings are continuous vector representations of game levels unifying their visual, contextual and behavioural information. However, the original tile embedding struggled to generate levels with skewed tile distributions. For instance, Super Mario Bros. (SMB) wherein a majority of tiles represent the background. To remedy this, we present a modified tile embedding representation referred to as Clustering-based Tile Embedding (CTE). Further, we employ clustering to discretize the continuous CTE representation and present a novel two-step level generation to leverage both these representations. We evaluate the performance of our approach in generating levels for seen and unseen games with skewed tile distributions and outperform the original tile embeddings.
Accelerating the training of single-layer binary neural networks using the HHL quantum algorithm
Oct 23, 2022

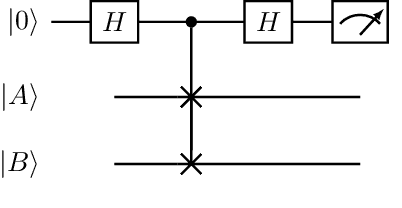
Binary Neural Networks are a promising technique for implementing efficient deep models with reduced storage and computational requirements. The training of these is however, still a compute-intensive problem that grows drastically with the layer size and data input. At the core of this calculation is the linear regression problem. The Harrow-Hassidim-Lloyd (HHL) quantum algorithm has gained relevance thanks to its promise of providing a quantum state containing the solution of a linear system of equations. The solution is encoded in superposition at the output of a quantum circuit. Although this seems to provide the answer to the linear regression problem for the training neural networks, it also comes with multiple, difficult-to-avoid hurdles. This paper shows, however, that useful information can be extracted from the quantum-mechanical implementation of HHL, and used to reduce the complexity of finding the solution on the classical side.
TokenFlow: Rethinking Fine-grained Cross-modal Alignment in Vision-Language Retrieval
Oct 03, 2022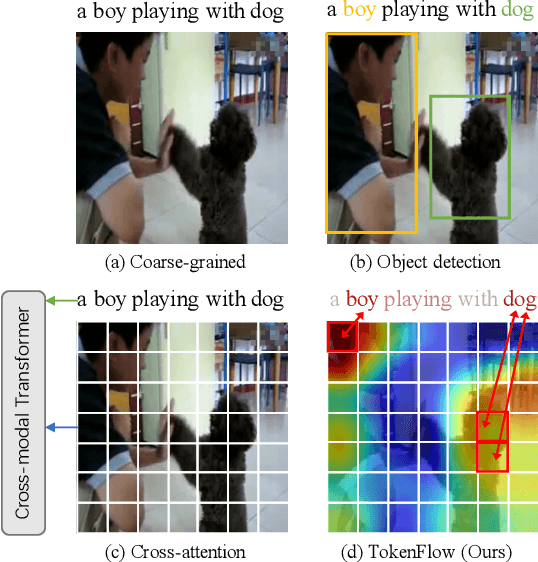
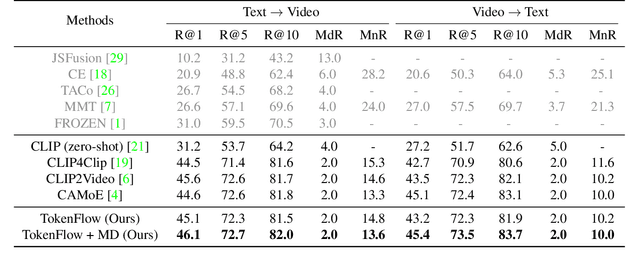
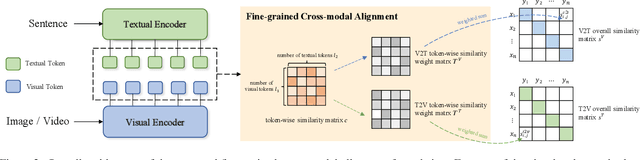
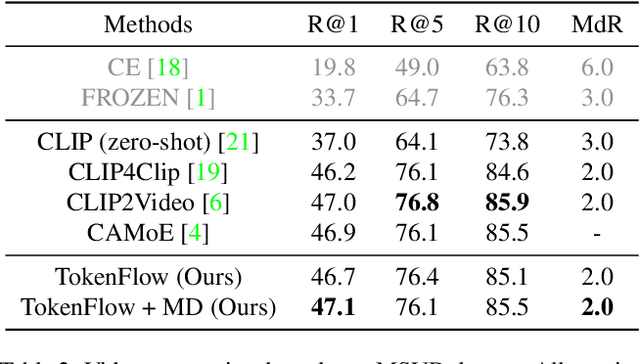
Most existing methods in vision-language retrieval match two modalities by either comparing their global feature vectors which misses sufficient information and lacks interpretability, detecting objects in images or videos and aligning the text with fine-grained features which relies on complicated model designs, or modeling fine-grained interaction via cross-attention upon visual and textual tokens which suffers from inferior efficiency. To address these limitations, some recent works simply aggregate the token-wise similarities to achieve fine-grained alignment, but they lack intuitive explanations as well as neglect the relationships between token-level features and global representations with high-level semantics. In this work, we rethink fine-grained cross-modal alignment and devise a new model-agnostic formulation for it. We additionally demystify the recent popular works and subsume them into our scheme. Furthermore, inspired by optimal transport theory, we introduce TokenFlow, an instantiation of the proposed scheme. By modifying only the similarity function, the performance of our method is comparable to the SoTA algorithms with heavy model designs on major video-text retrieval benchmarks. The visualization further indicates that TokenFlow successfully leverages the fine-grained information and achieves better interpretability.
Covered Information Disentanglement: Model Transparency via Unbiased Permutation Importance
Nov 21, 2021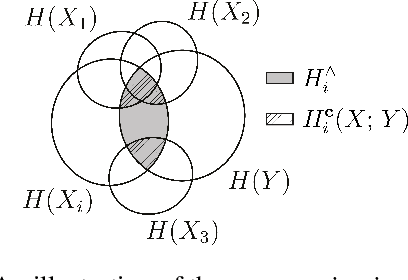
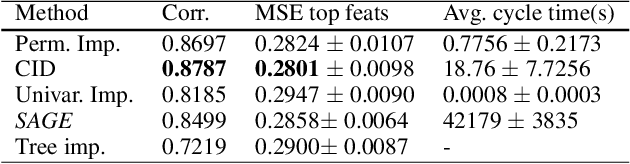
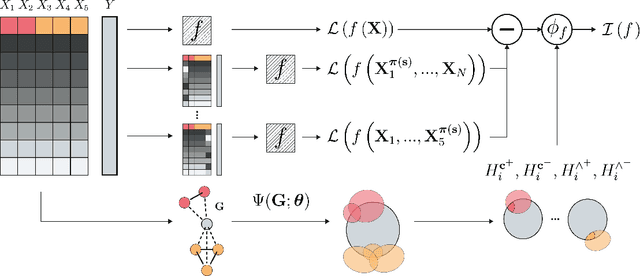
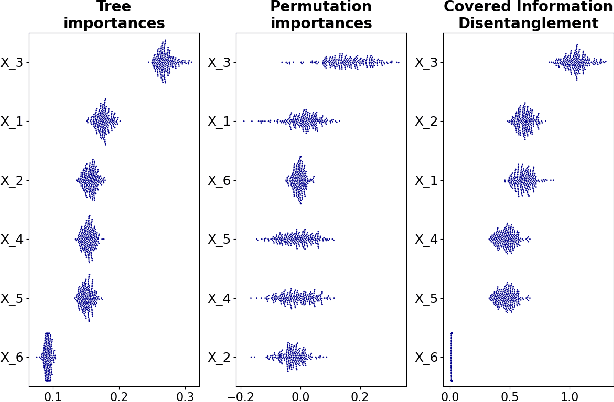
Model transparency is a prerequisite in many domains and an increasingly popular area in machine learning research. In the medical domain, for instance, unveiling the mechanisms behind a disease often has higher priority than the diagnostic itself since it might dictate or guide potential treatments and research directions. One of the most popular approaches to explain model global predictions is the permutation importance where the performance on permuted data is benchmarked against the baseline. However, this method and other related approaches will undervalue the importance of a feature in the presence of covariates since these cover part of its provided information. To address this issue, we propose Covered Information Disentanglement (CID), a method that considers all feature information overlap to correct the values provided by permutation importance. We further show how to compute CID efficiently when coupled with Markov random fields. We demonstrate its efficacy in adjusting permutation importance first on a controlled toy dataset and discuss its effect on real-world medical data.
Integrative Feature and Cost Aggregation with Transformers for Dense Correspondence
Sep 20, 2022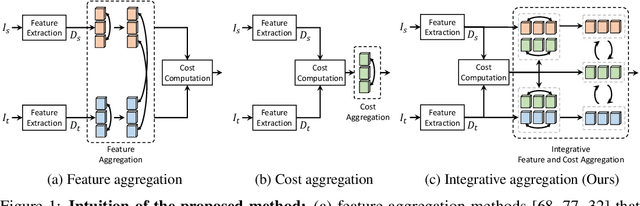
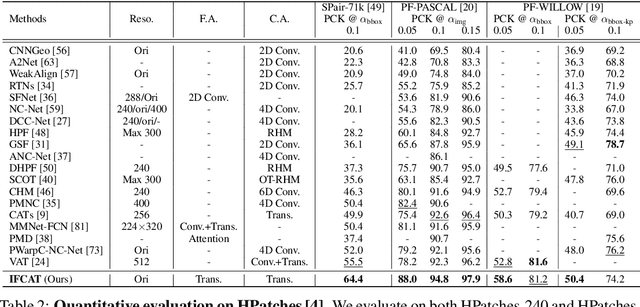

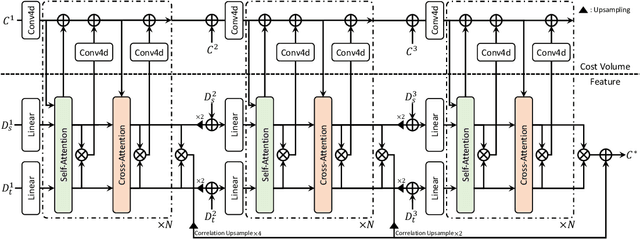
We present a novel architecture for dense correspondence. The current state-of-the-art are Transformer-based approaches that focus on either feature descriptors or cost volume aggregation. However, they generally aggregate one or the other but not both, though joint aggregation would boost each other by providing information that one has but other lacks, i.e., structural or semantic information of an image, or pixel-wise matching similarity. In this work, we propose a novel Transformer-based network that interleaves both forms of aggregations in a way that exploits their complementary information. Specifically, we design a self-attention layer that leverages the descriptor to disambiguate the noisy cost volume and that also utilizes the cost volume to aggregate features in a manner that promotes accurate matching. A subsequent cross-attention layer performs further aggregation conditioned on the descriptors of both images and aided by the aggregated outputs of earlier layers. We further boost the performance with hierarchical processing, in which coarser level aggregations guide those at finer levels. We evaluate the effectiveness of the proposed method on dense matching tasks and achieve state-of-the-art performance on all the major benchmarks. Extensive ablation studies are also provided to validate our design choices.
Information-Theoretic Bayes Risk Lower Bounds for Realizable Models
Nov 08, 2021We derive information-theoretic lower bounds on the Bayes risk and generalization error of realizable machine learning models. In particular, we employ an analysis in which the rate-distortion function of the model parameters bounds the required mutual information between the training samples and the model parameters in order to learn a model up to a Bayes risk constraint. For realizable models, we show that both the rate distortion function and mutual information admit expressions that are convenient for analysis. For models that are (roughly) lower Lipschitz in their parameters, we bound the rate distortion function from below, whereas for VC classes, the mutual information is bounded above by $d_\mathrm{vc}\log(n)$. When these conditions match, the Bayes risk with respect to the zero-one loss scales no faster than $\Omega(d_\mathrm{vc}/n)$, which matches known outer bounds and minimax lower bounds up to logarithmic factors. We also consider the impact of label noise, providing lower bounds when training and/or test samples are corrupted.
Graph Perceiver IO: A General Architecture for Graph Structured Data
Sep 14, 2022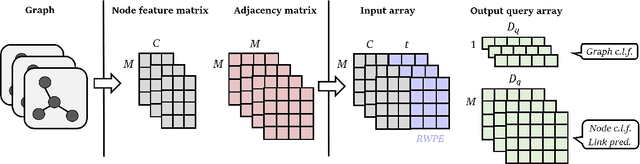
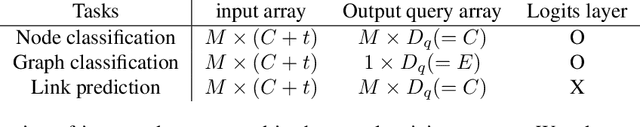
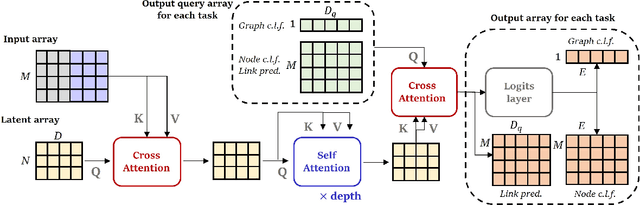
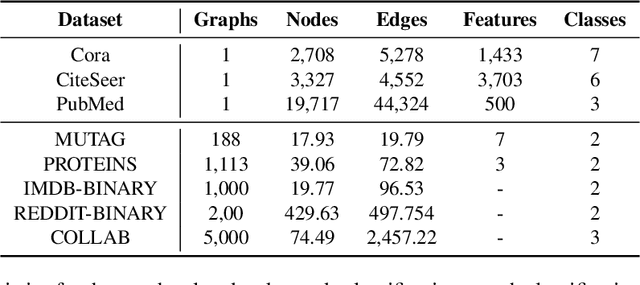
Multimodal machine learning has been widely studied for the development of general intelligence. Recently, the remarkable multimodal algorithms, the Perceiver and Perceiver IO, show competitive results for diverse dataset domains and tasks. However, recent works, Perceiver and Perceiver IO, have focused on heterogeneous modalities, including image, text, and speech, and there are few research works for graph structured datasets. A graph is one of the most generalized dataset structures, and we can represent the other dataset, including images, text, and speech, as graph structured data. A graph has an adjacency matrix different from other dataset domains such as text and image, and it is not trivial to handle the topological information, relational information, and canonical positional information. In this study, we provide a Graph Perceiver IO, the Perceiver IO for the graph structured dataset. We keep the main structure of the Graph Perceiver IO as the Perceiver IO because the Perceiver IO already handles the diverse dataset well, except for the graph structured dataset. The Graph Perceiver IO is a general method, and it can handle diverse datasets such as graph structured data as well as text and images. Comparing the graph neural networks, the Graph Perceiver IO requires a lower complexity, and it can incorporate the local and global information efficiently. We show that Graph Perceiver IO shows competitive results for diverse graph-related tasks, including node classification, graph classification, and link prediction.
Mapping the Ictal-Interictal-Injury Continuum Using Interpretable Machine Learning
Nov 09, 2022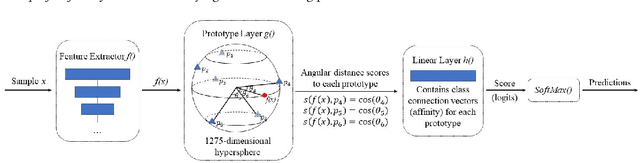

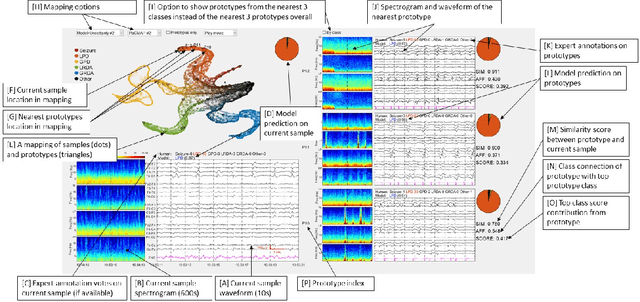

IMPORTANCE: An interpretable machine learning model can provide faithful explanations of each prediction and yet maintain higher performance than its black box counterpart. OBJECTIVE: To design an interpretable machine learning model which accurately predicts EEG protopatterns while providing an explanation of its predictions with assistance of a specialized GUI. To map the cEEG latent features to a 2D space in order to visualize the ictal-interictal-injury continuum and gain insight into its high-dimensional structure. DESIGN, SETTING, AND PARTICIPANTS: 50,697 50-second cEEG samples from 2,711 ICU patients collected between July 2006 and March 2020 at Massachusetts General Hospital. Samples were labeled as one of 6 EEG activities by domain experts, with 124 different experts providing annotations. MAIN OUTCOMES AND MEASURES: Our neural network is interpretable because it uses case-based reasoning: it compares a new EEG reading to a set of learned prototypical EEG samples from the training dataset. Interpretability was measured with task-specific neighborhood agreement statistics. Discriminatory performance was evaluated with AUROC and AUPRC. RESULTS: The model achieves AUROCs of 0.87, 0.93, 0.96, 0.92, 0.93, 0.80 for classes Seizure, LPD, GPD, LRDA, GRDA, Other respectively. This performance is statistically significantly higher than that of the corresponding uninterpretable (black box) model with p<0.0001. Videos of the ictal-interictal-injury continuum are provided. CONCLUSION AND RELEVANCE: Our interpretable model and GUI can act as a reference for practitioners who work with cEEG patterns. We can now better understand the relationships between different types of cEEG patterns. In the future, this system may allow for targeted intervention and training in clinical settings. It could also be used for re-confirming or providing additional information for diagnostics.
M$^3$Video: Masked Motion Modeling for Self-Supervised Video Representation Learning
Oct 12, 2022
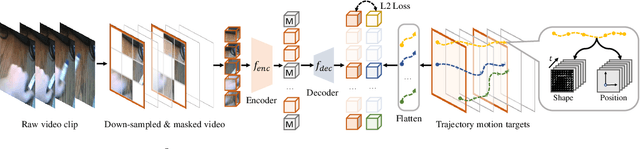

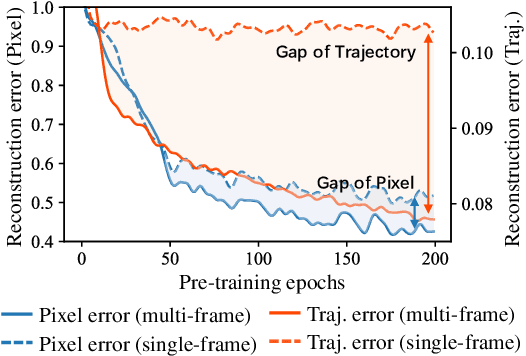
We study self-supervised video representation learning that seeks to learn video features from unlabeled videos, which is widely used for video analysis as labeling videos is labor-intensive. Current methods often mask some video regions and then train a model to reconstruct spatial information in these regions (e.g., original pixels). However, the model is easy to reconstruct this information by considering content in a single frame. As a result, it may neglect to learn the interactions between frames, which are critical for video analysis. In this paper, we present a new self-supervised learning task, called Masked Motion Modeling (M$^3$Video), for learning representation by enforcing the model to predict the motion of moving objects in the masked regions. To generate motion targets for this task, we track the objects using optical flow. The motion targets consist of position transitions and shape changes of the tracked objects, thus the model has to consider multiple frames comprehensively. Besides, to help the model capture fine-grained motion details, we enforce the model to predict trajectory motion targets in high temporal resolution based on a video in low temporal resolution. After pre-training using our M$^3$Video task, the model is able to anticipate fine-grained motion details even taking a sparsely sampled video as input. We conduct extensive experiments on four benchmark datasets. Remarkably, when doing pre-training with 400 epochs, we improve the accuracy from 67.6\% to 69.2\% and from 78.8\% to 79.7\% on Something-Something V2 and Kinetics-400 datasets, respectively.
Evolving Neural Networks with Optimal Balance between Information Flow and Connections Cost
Mar 14, 2022
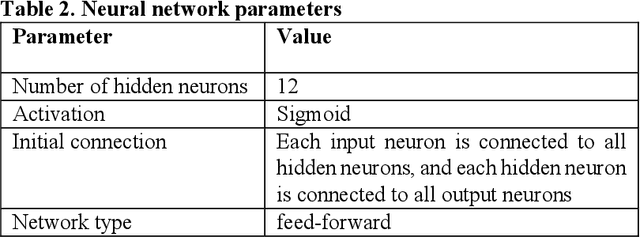
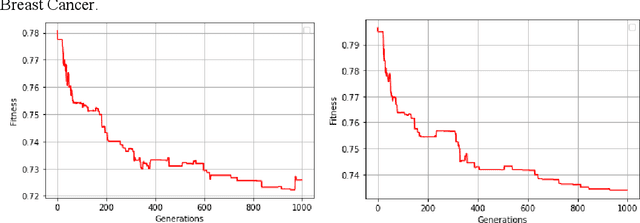
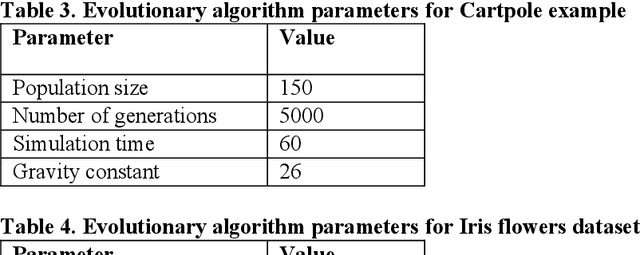
Evolving Neural Networks (NNs) has recently seen an increasing interest as an alternative path that might be more successful. It has many advantages compared to other approaches, such as learning the architecture of the NNs. However, the extremely large search space and the existence of many complex interacting parts still represent a major obstacle. Many criteria were recently investigated to help guide the algorithm and to cut down the large search space. Recently there has been growing research bringing insights from network science to improve the design of NNs. In this paper, we investigate evolving NNs architectures that have one of the most fundamental characteristics of real-world networks, namely the optimal balance between connections cost and information flow. The performance of different metrics that represent this balance is evaluated and the improvement in the accuracy of putting more selection pressure toward this balance is demonstrated on three datasets.