 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Identifying patterns of main causes of death in the young EU population
Oct 11, 2022
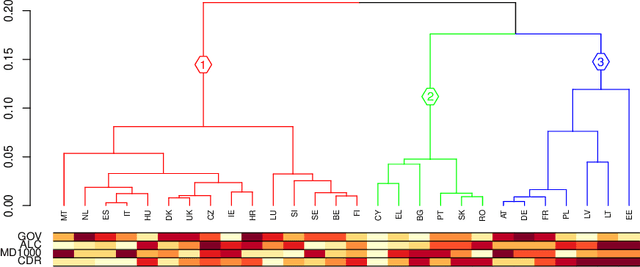
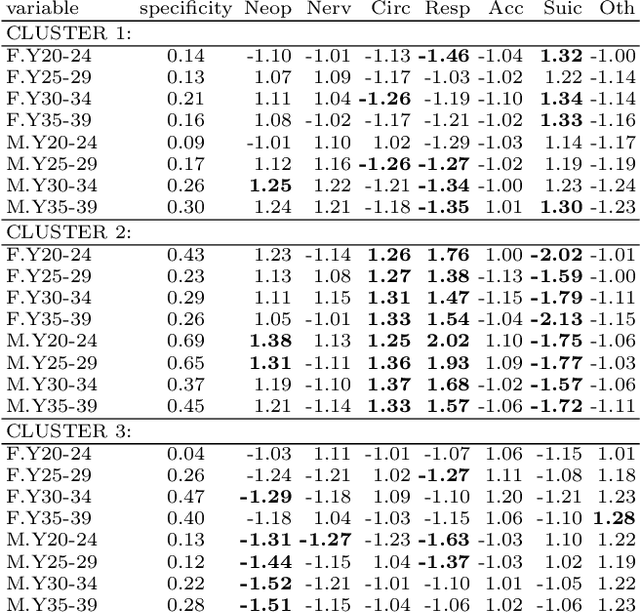
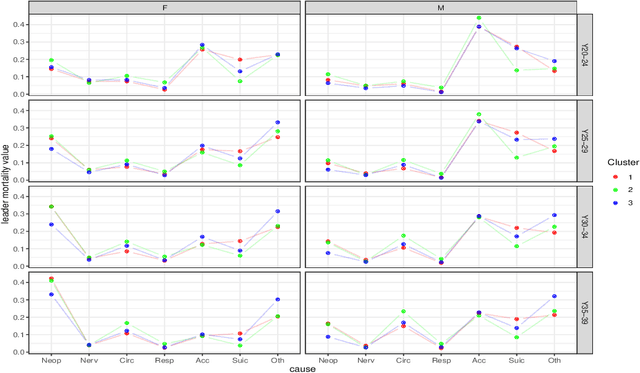
The study of mortality patterns is a popular research topic in many areas. We are particularly interested in mortality patterns among main causes of death associated with age-gender combinations. We use symbolic data analysis (SDA) and include three dimensions: age, gender, and patterns across main causes of death. In this study, we present an alternative method to identify clusters of EU countries with similar mortality patterns in the young population, while considering comprehensive information on the distribution of deaths among the main causes of death by different age-gender groups. We explore possible relationships between mortality patterns in the identified clusters and some other sociodemographic indicators. We use EU data of crude mortality rates from 2016, as the most recent complete data available.
Graph Neural Networks for Molecules
Sep 12, 2022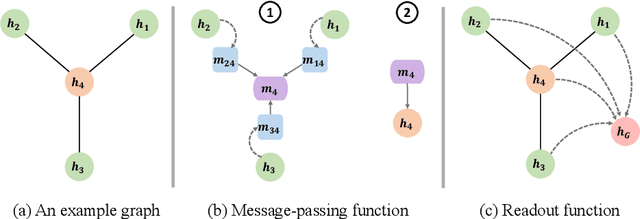
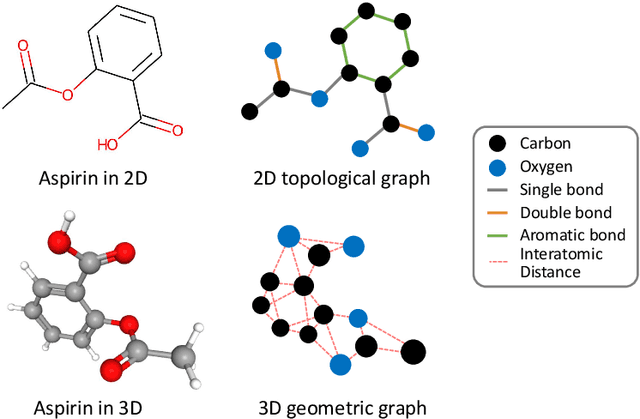
Graph neural networks (GNNs), which are capable of learning representations from graphical data, are naturally suitable for modeling molecular systems. This review introduces GNNs and their various applications for small organic molecules. GNNs rely on message-passing operations, a generic yet powerful framework, to update node features iteratively. Many researches design GNN architectures to effectively learn topological information of 2D molecule graphs as well as geometric information of 3D molecular systems. GNNs have been implemented in a wide variety of molecular applications, including molecular property prediction, molecular scoring and docking, molecular optimization and de novo generation, molecular dynamics simulation, etc. Besides, the review also summarizes the recent development of self-supervised learning for molecules with GNNs.
Impact of annotation modality on label quality and model performance in the automatic assessment of laughter in-the-wild
Nov 02, 2022
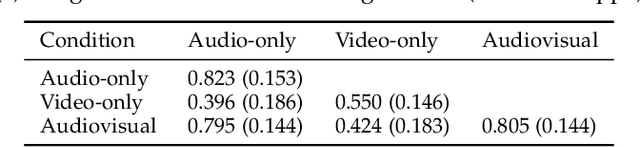
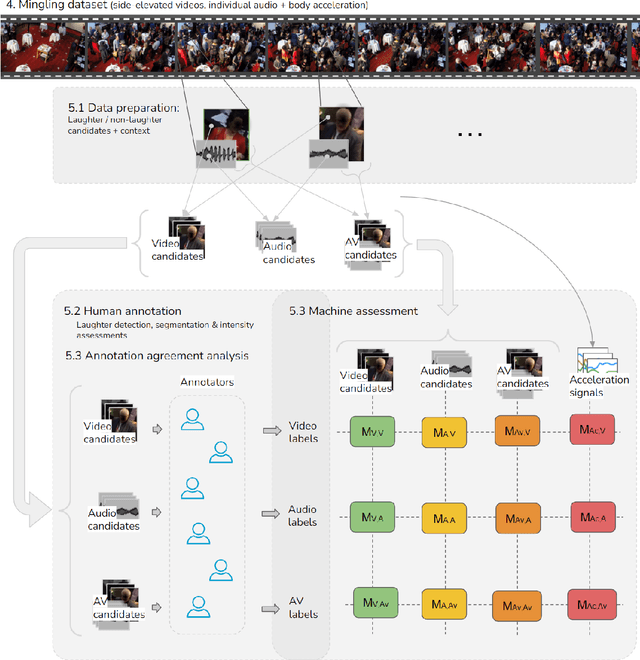
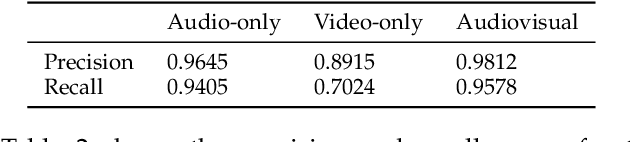
Laughter is considered one of the most overt signals of joy. Laughter is well-recognized as a multimodal phenomenon but is most commonly detected by sensing the sound of laughter. It is unclear how perception and annotation of laughter differ when annotated from other modalities like video, via the body movements of laughter. In this paper we take a first step in this direction by asking if and how well laughter can be annotated when only audio, only video (containing full body movement information) or audiovisual modalities are available to annotators. We ask whether annotations of laughter are congruent across modalities, and compare the effect that labeling modality has on machine learning model performance. We compare annotations and models for laughter detection, intensity estimation, and segmentation, three tasks common in previous studies of laughter. Our analysis of more than 4000 annotations acquired from 48 annotators revealed evidence for incongruity in the perception of laughter, and its intensity between modalities. Further analysis of annotations against consolidated audiovisual reference annotations revealed that recall was lower on average for video when compared to the audio condition, but tended to increase with the intensity of the laughter samples. Our machine learning experiments compared the performance of state-of-the-art unimodal (audio-based, video-based and acceleration-based) and multi-modal models for different combinations of input modalities, training label modality, and testing label modality. Models with video and acceleration inputs had similar performance regardless of training label modality, suggesting that it may be entirely appropriate to train models for laughter detection from body movements using video-acquired labels, despite their lower inter-rater agreement.
Coordinated Transmit Beamforming for Multi-antenna Network Integrated Sensing and Communication
Nov 02, 2022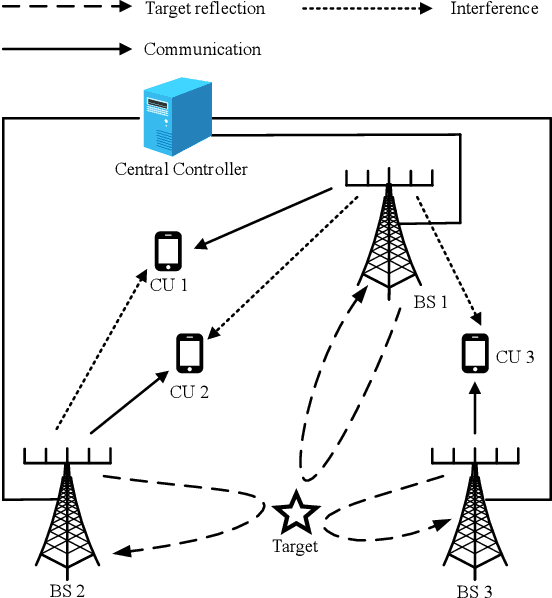
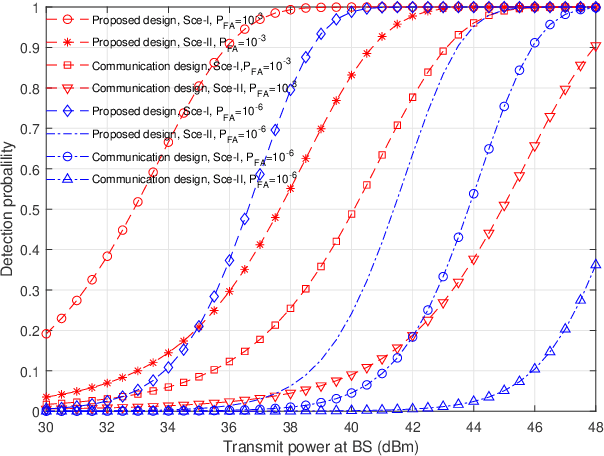
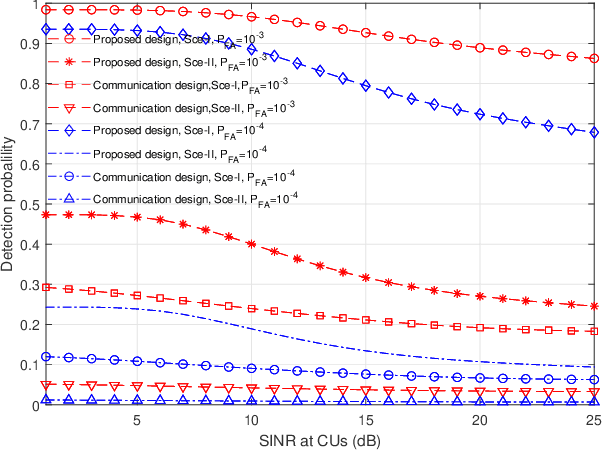
This paper studies a multi-antenna network integrated sensing and communication (ISAC) system, in which a set of multi-antenna base stations (BSs) employ the coordinated transmit beamforming to serve their respectively associated single-antenna communication users (CUs), and at the same time reuse the reflected information signals to perform joint target detection. In particular, we consider two target detection scenarios depending on the time synchronization among BSs. In Scenario \uppercase\expandafter{\romannumeral1}, these BSs are synchronized and can exploit the target-reflected signals over both the direct links (from each BS to target to itself) and the cross links (from each BS to target to other BSs) for joint detection. In Scenario \uppercase\expandafter{\romannumeral2}, these BSs are not synchronized and can only utilize target-reflected signals over the direct links for joint detection. For each scenario, we derive the detection probability under a specific false alarm probability at any given target location. Based on the derivation, we optimize the coordinated transmit beamforming at the BSs to maximize the minimum detection probability over a particular target area, while ensuring the minimum signal-to-interference-plus-noise ratio (SINR) constraints at the CUs, subject to the maximum transmit power constraints at the BSs. We use the semi-definite relaxation (SDR) technique to obtain highly-quality solutions to the formulated problems. Numerical results show that for each scenario, the proposed design achieves higher detection probability than the benchmark scheme based on communication design. It is also shown that the time synchronization among BSs is beneficial in enhancing the detection performance as more reflected signal paths are exploited.
A study linking patient EHR data to external death data at Stanford Medicine
Nov 02, 2022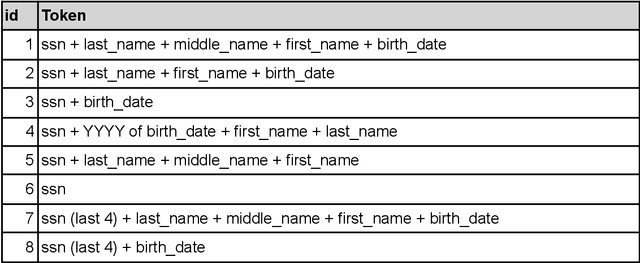
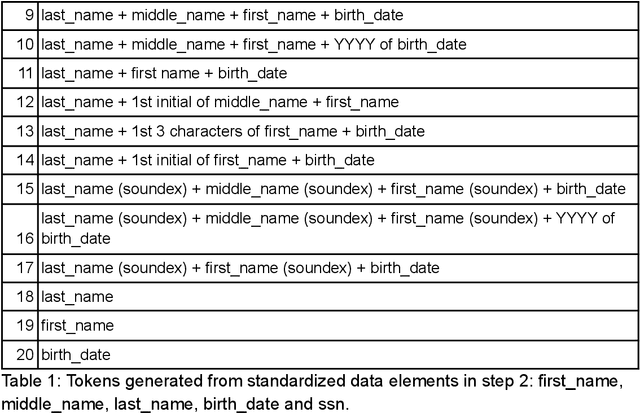
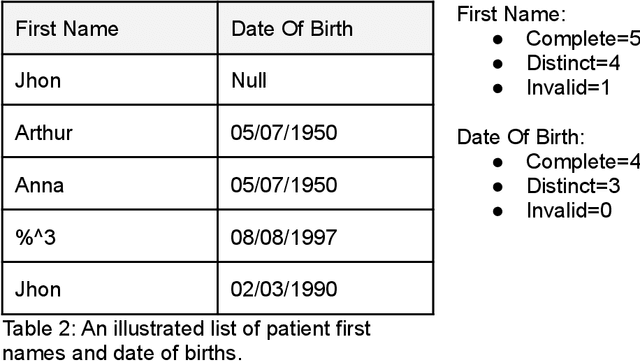
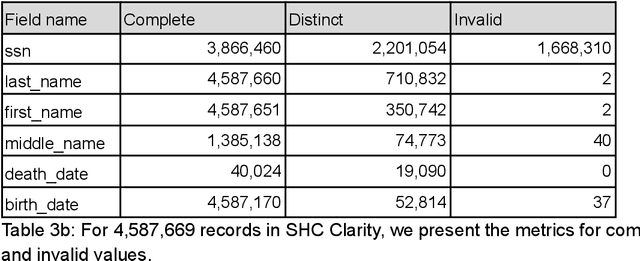
This manuscript explores linking real-world patient data with external death data in the context of research Clinical Data Warehouses (r-CDWs). We specifically present the linking of Electronic Health Records (EHR) data for Stanford Health Care (SHC) patients and data from the Social Security Administration (SSA) Limited Access Death Master File (LADMF) made available by the US Department of Commerce's National Technical Information Service (NTIS). The data analysis framework presented in this manuscript extends prior approaches and is generalizable to linking any two cross-organizational real-world patient data sources. Electronic Health Record (EHR) data and NTIS LADMF are heavily used resources at other medical centers and we expect that the methods and learnings presented here will be valuable to others. Our findings suggest that strong linkages are incomplete and weak linkages are noisy i.e., there is no good linkage rule that provides coverage and accuracy. Furthermore, the best linkage rule for any two datasets is different from the best linkage rule for two other datasets i.e., there is no generalization of linkage rules. Finally, LADMF, a commonly used external death data resource for r-CDWs, has a significant gap in death data making it necessary for r-CDWs to seek out more than one external death data source. We anticipate that presentation of multiple linkages will make it hard to present the linkage outcome to the end user. This manuscript is a resource in support of Stanford Medicine STARR (STAnford medicine Research data Repository) r-CDWs. The data are stored and analyzed as PHI in our HIPAA-compliant data center and are used under research and development (R&D) activities of STARR IRB.
Joint Language Semantic and Structure Embedding for Knowledge Graph Completion
Sep 19, 2022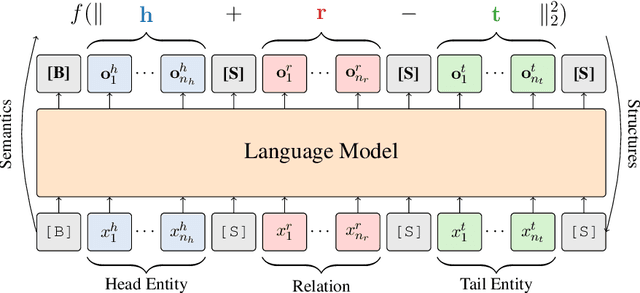
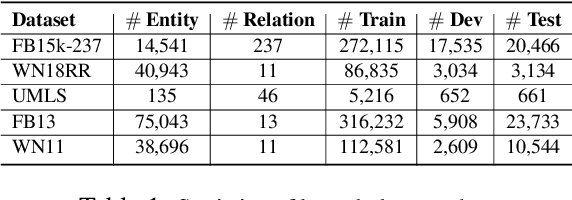
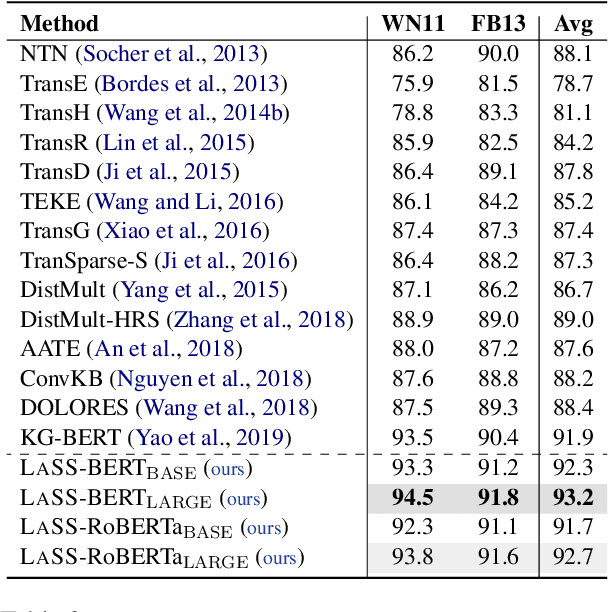
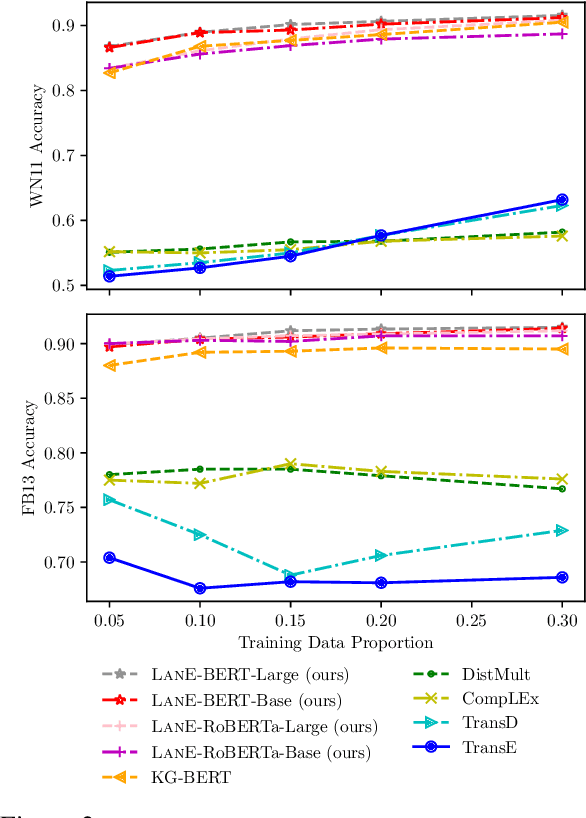
The task of completing knowledge triplets has broad downstream applications. Both structural and semantic information plays an important role in knowledge graph completion. Unlike previous approaches that rely on either the structures or semantics of the knowledge graphs, we propose to jointly embed the semantics in the natural language description of the knowledge triplets with their structure information. Our method embeds knowledge graphs for the completion task via fine-tuning pre-trained language models with respect to a probabilistic structured loss, where the forward pass of the language models captures semantics and the loss reconstructs structures. Our extensive experiments on a variety of knowledge graph benchmarks have demonstrated the state-of-the-art performance of our method. We also show that our method can significantly improve the performance in a low-resource regime, thanks to the better use of semantics. The code and datasets are available at https://github.com/pkusjh/LASS.
Data-Centric Machine Learning in Quantum Information Science
Jan 22, 2022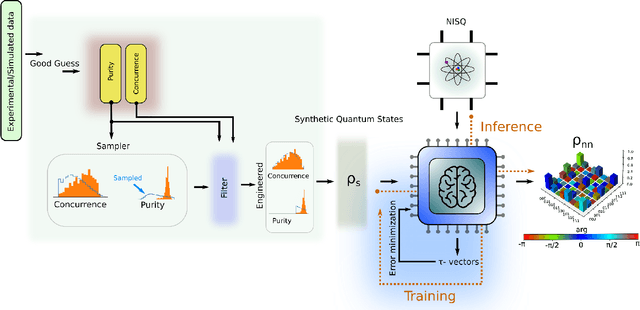
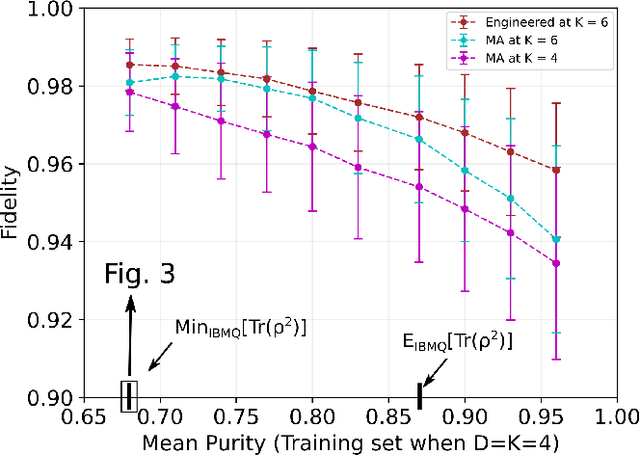
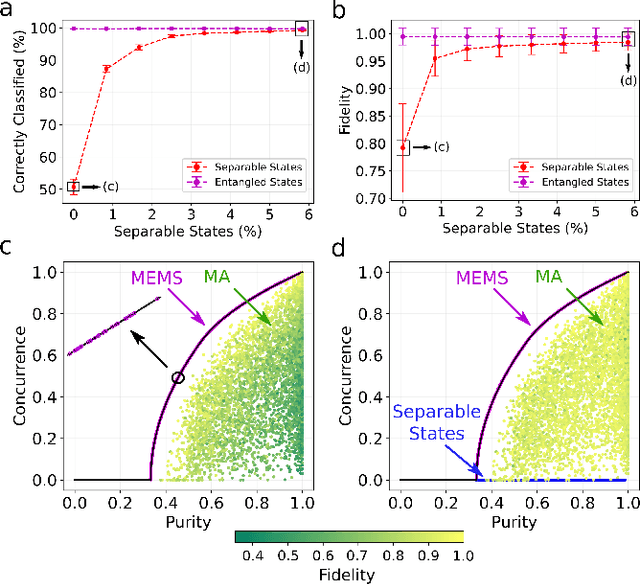
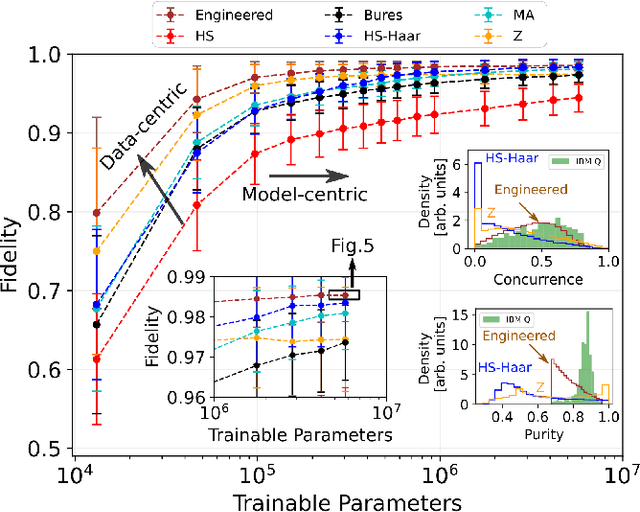
We propose a series of data-centric heuristics for improving the performance of machine learning systems when applied to problems in quantum information science. In particular, we consider how systematic engineering of training sets can significantly enhance the accuracy of pre-trained neural networks used for quantum state reconstruction without altering the underlying architecture. We find that it is not always optimal to engineer training sets to exactly match the expected distribution of a target scenario, and instead, performance can be further improved by biasing the training set to be slightly more mixed than the target. This is due to the heterogeneity in the number of free variables required to describe states of different purity, and as a result, overall accuracy of the network improves when training sets of a fixed size focus on states with the least constrained free variables. For further clarity, we also include a "toy model" demonstration of how spurious correlations can inadvertently enter synthetic data sets used for training, how the performance of systems trained with these correlations can degrade dramatically, and how the inclusion of even relatively few counterexamples can effectively remedy such problems.
Missing Counter-Evidence Renders NLP Fact-Checking Unrealistic for Misinformation
Oct 25, 2022

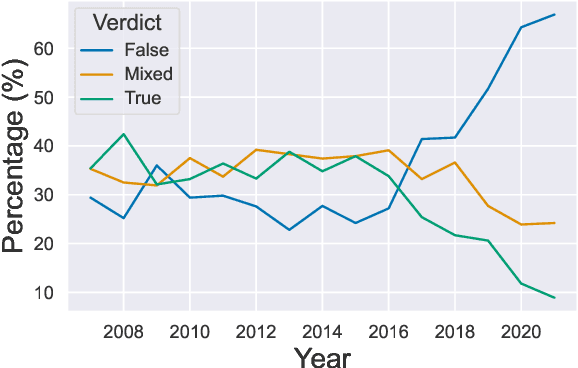
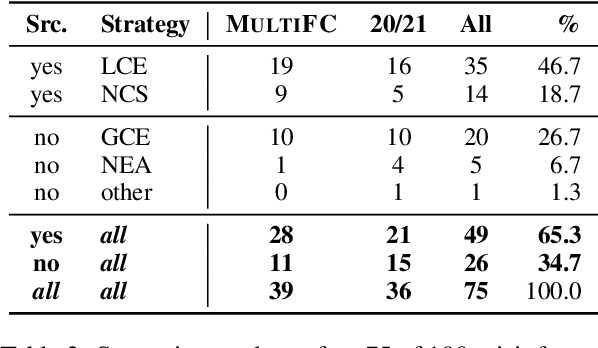
Misinformation emerges in times of uncertainty when credible information is limited. This is challenging for NLP-based fact-checking as it relies on counter-evidence, which may not yet be available. Despite increasing interest in automatic fact-checking, it is still unclear if automated approaches can realistically refute harmful real-world misinformation. Here, we contrast and compare NLP fact-checking with how professional fact-checkers combat misinformation in the absence of counter-evidence. In our analysis, we show that, by design, existing NLP task definitions for fact-checking cannot refute misinformation as professional fact-checkers do for the majority of claims. We then define two requirements that the evidence in datasets must fulfill for realistic fact-checking: It must be (1) sufficient to refute the claim and (2) not leaked from existing fact-checking articles. We survey existing fact-checking datasets and find that all of them fail to satisfy both criteria. Finally, we perform experiments to demonstrate that models trained on a large-scale fact-checking dataset rely on leaked evidence, which makes them unsuitable in real-world scenarios. Taken together, we show that current NLP fact-checking cannot realistically combat real-world misinformation because it depends on unrealistic assumptions about counter-evidence in the data.
Emotion Recognition With Temporarily Localized 'Emotional Events' in Naturalistic Context
Oct 25, 2022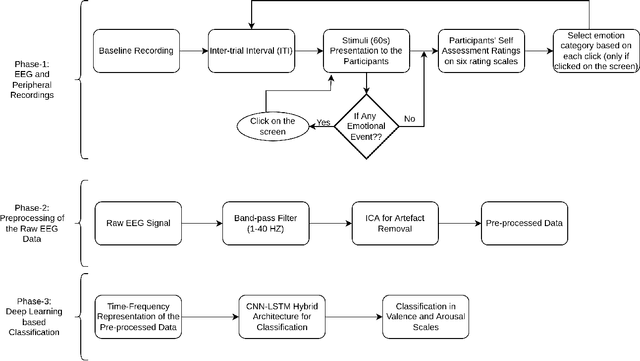

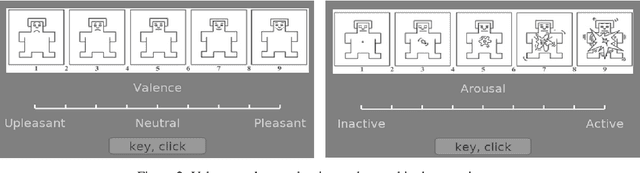

Emotion recognition using EEG signals is an emerging area of research due to its broad applicability in BCI. Emotional feelings are hard to stimulate in the lab. Emotions do not last long, yet they need enough context to be perceived and felt. However, most EEG-related emotion databases either suffer from emotionally irrelevant details (due to prolonged duration stimulus) or have minimal context doubting the feeling of any emotion using the stimulus. We tried to reduce the impact of this trade-off by designing an experiment in which participants are free to report their emotional feelings simultaneously watching the emotional stimulus. We called these reported emotional feelings "Emotional Events" in our Dataset on Emotion with Naturalistic Stimuli (DENS). We used EEG signals to classify emotional events on different combinations of Valence(V) and Arousal(A) dimensions and compared the results with benchmark datasets of DEAP and SEED. STFT is used for feature extraction and used in the classification model consisting of CNN-LSTM hybrid layers. We achieved significantly higher accuracy with our data compared to DEEP and SEED data. We conclude that having precise information about emotional feelings improves the classification accuracy compared to long-duration EEG signals which might be contaminated by mind-wandering.
Similarity between Units of Natural Language: The Transition from Coarse to Fine Estimation
Oct 25, 2022Capturing the similarities between human language units is crucial for explaining how humans associate different objects, and therefore its computation has received extensive attention, research, and applications. With the ever-increasing amount of information around us, calculating similarity becomes increasingly complex, especially in many cases, such as legal or medical affairs, measuring similarity requires extra care and precision, as small acts within a language unit can have significant real-world effects. My research goal in this thesis is to develop regression models that account for similarities between language units in a more refined way. Computation of similarity has come a long way, but approaches to debugging the measures are often based on continually fitting human judgment values. To this end, my goal is to develop an algorithm that precisely catches loopholes in a similarity calculation. Furthermore, most methods have vague definitions of the similarities they compute and are often difficult to interpret. The proposed framework addresses both shortcomings. It constantly improves the model through catching different loopholes. In addition, every refinement of the model provides a reasonable explanation. The regression model introduced in this thesis is called progressively refined similarity computation, which combines attack testing with adversarial training. The similarity regression model of this thesis achieves state-of-the-art performance in handling edge cases.