 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fairness Reprogramming
Sep 21, 2022

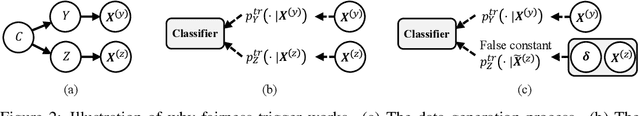
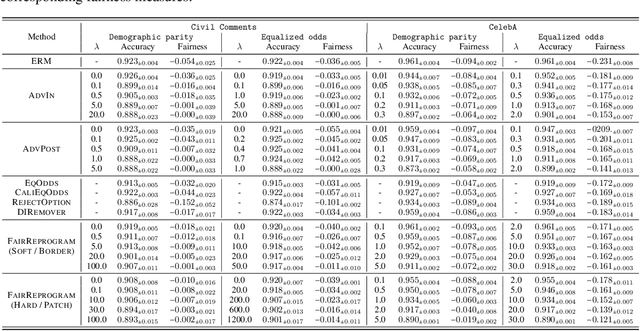
Despite a surge of recent advances in promoting machine Learning (ML) fairness, the existing mainstream approaches mostly require training or finetuning the entire weights of the neural network to meet the fairness criteria. However, this is often infeasible in practice for those large-scale trained models due to large computational and storage costs, low data efficiency, and model privacy issues. In this paper, we propose a new generic fairness learning paradigm, called FairReprogram, which incorporates the model reprogramming technique. Specifically, FairReprogram considers the neural model fixed, and instead appends to the input a set of perturbations, called the fairness trigger, which is tuned towards the fairness criteria under a min-max formulation. We further introduce an information-theoretic framework that explains why and under what conditions fairness goals can be achieved using the fairness trigger. We show both theoretically and empirically that the fairness trigger can effectively obscure demographic biases in the output prediction of fixed ML models by providing false demographic information that hinders the model from utilizing the correct demographic information to make the prediction. Extensive experiments on both NLP and CV datasets demonstrate that our method can achieve better fairness improvements than retraining-based methods with far less training cost and data dependency under two widely-used fairness criteria.
Semantic Visual Simultaneous Localization and Mapping: A Survey
Sep 14, 2022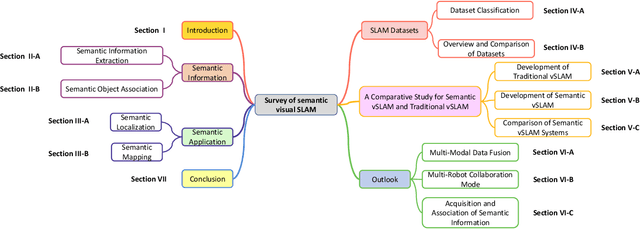
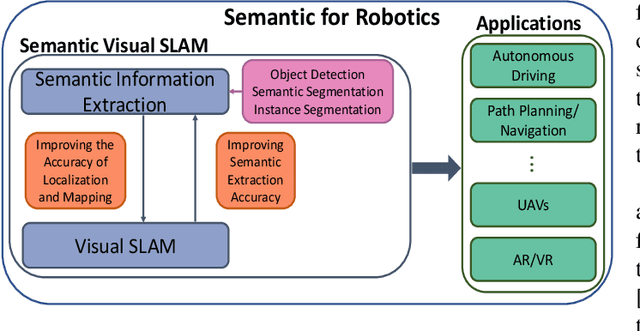

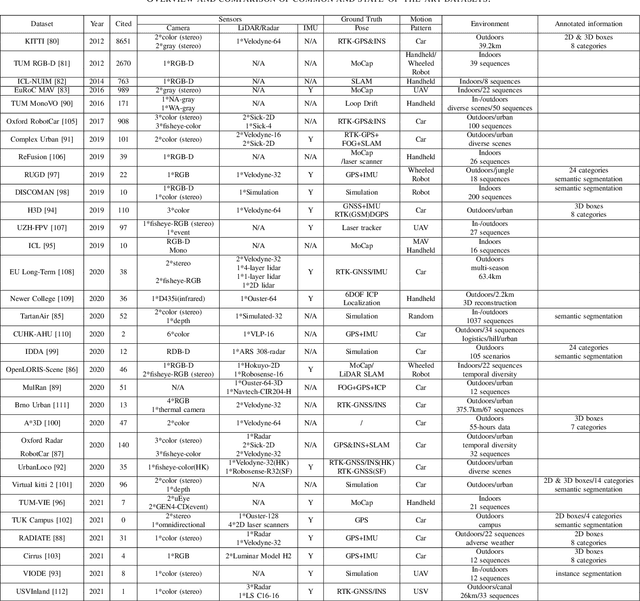
Visual Simultaneous Localization and Mapping (vSLAM) has achieved great progress in the computer vision and robotics communities, and has been successfully used in many fields such as autonomous robot navigation and AR/VR. However, vSLAM cannot achieve good localization in dynamic and complex environments. Numerous publications have reported that, by combining with the semantic information with vSLAM, the semantic vSLAM systems have the capability of solving the above problems in recent years. Nevertheless, there is no comprehensive survey about semantic vSLAM. To fill the gap, this paper first reviews the development of semantic vSLAM, explicitly focusing on its strengths and differences. Secondly, we explore three main issues of semantic vSLAM: the extraction and association of semantic information, the application of semantic information, and the advantages of semantic vSLAM. Then, we collect and analyze the current state-of-the-art SLAM datasets which have been widely used in semantic vSLAM systems. Finally, we discuss future directions that will provide a blueprint for the future development of semantic vSLAM.
An Adaptive Threshold for the Canny Edge Detection with Actor-Critic Algorithm
Sep 19, 2022


Visual surveillance aims to perform robust foreground object detection regardless of the time and place. Object detection shows good results using only spatial information, but foreground object detection in visual surveillance requires proper temporal and spatial information processing. In deep learning-based foreground object detection algorithms, the detection ability is superior to classical background subtraction (BGS) algorithms in an environment similar to training. However, the performance is lower than that of the classical BGS algorithm in the environment different from training. This paper proposes a spatio-temporal fusion network (STFN) that could extract temporal and spatial information using a temporal network and a spatial network. We suggest a method using a semi-foreground map for stable training of the proposed STFN. The proposed algorithm shows excellent performance in an environment different from training, and we show it through experiments with various public datasets. Also, STFN can generate a compliant background image in a semi-supervised method, and it can operate in real-time on a desktop with GPU. The proposed method shows 11.28% and 18.33% higher FM than the latest deep learning method in the LASIESTA and SBI dataset, respectively.
Stimulus-Informed Generalized Canonical Correlation Analysis of Stimulus-Following Brain Responses
Oct 24, 2022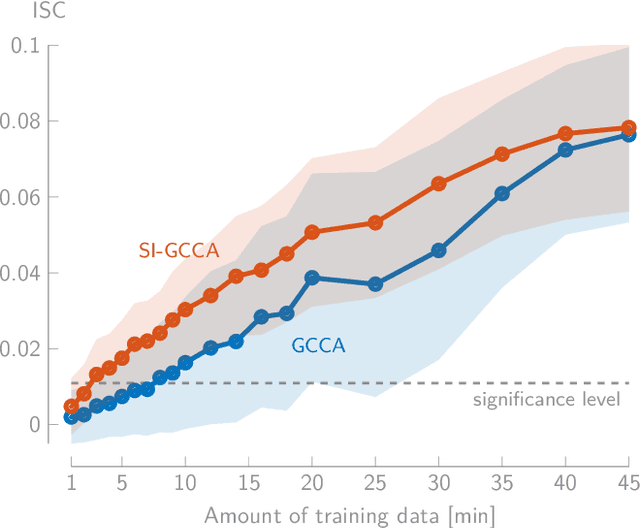
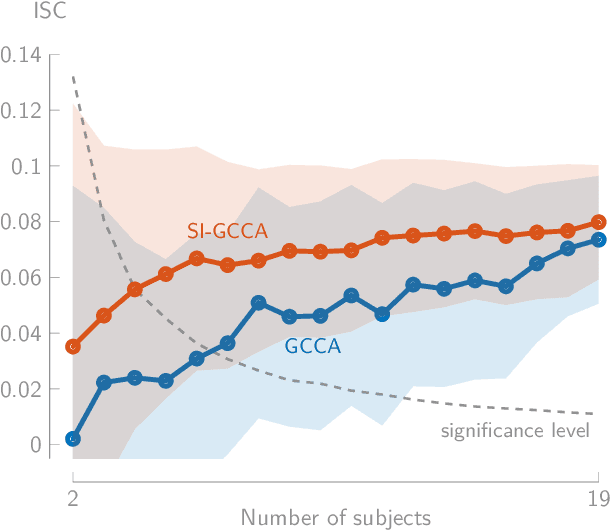
In brain-computer interface or neuroscience applications, generalized canonical correlation analysis (GCCA) is often used to extract correlated signal components in the neural activity of different subjects attending to the same stimulus. This allows quantifying the so-called inter-subject correlation or boosting the signal-to-noise ratio of the stimulus-following brain responses with respect to other (non-)neural activity. GCCA is, however, stimulus-unaware: it does not take the stimulus information into account and does therefore not cope well with lower amounts of data or smaller groups of subjects. We propose a novel stimulus-informed GCCA algorithm based on the MAXVAR-GCCA framework. We show the superiority of the proposed stimulus-informed GCCA method based on the inter-subject correlation between electroencephalography responses of a group of subjects listening to the same speech stimulus, especially for lower amounts of data or smaller groups of subjects.
ImmFusion: Robust mmWave-RGB Fusion for 3D Human Body Reconstruction in All Weather Conditions
Oct 04, 2022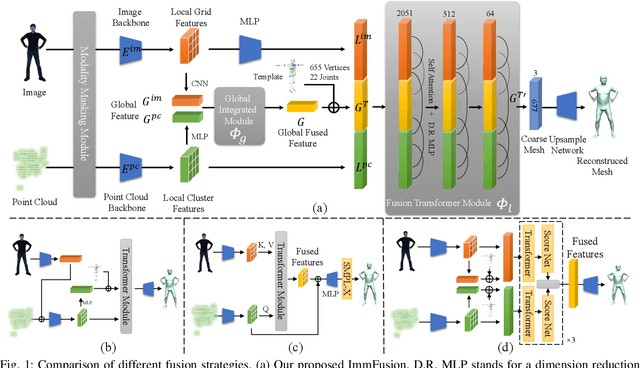
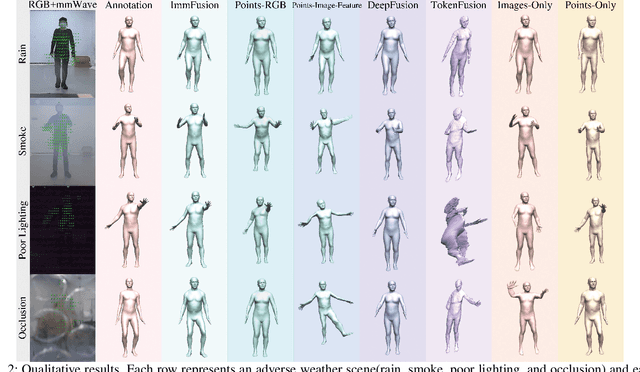


3D human reconstruction from RGB images achieves decent results in good weather conditions but degrades dramatically in rough weather. Complementary, mmWave radars have been employed to reconstruct 3D human joints and meshes in rough weather. However, combining RGB and mmWave signals for robust all-weather 3D human reconstruction is still an open challenge, given the sparse nature of mmWave and the vulnerability of RGB images. In this paper, we present ImmFusion, the first mmWave-RGB fusion solution to reconstruct 3D human bodies in all weather conditions robustly. Specifically, our ImmFusion consists of image and point backbones for token feature extraction and a Transformer module for token fusion. The image and point backbones refine global and local features from original data, and the Fusion Transformer Module aims for effective information fusion of two modalities by dynamically selecting informative tokens. Extensive experiments on a large-scale dataset, mmBody, captured in various environments demonstrate that ImmFusion can efficiently utilize the information of two modalities to achieve a robust 3D human body reconstruction in all weather conditions. In addition, our method's accuracy is significantly superior to that of state-of-the-art Transformer-based LiDAR-camera fusion methods.
Context-aware Bayesian choice models
Oct 11, 2022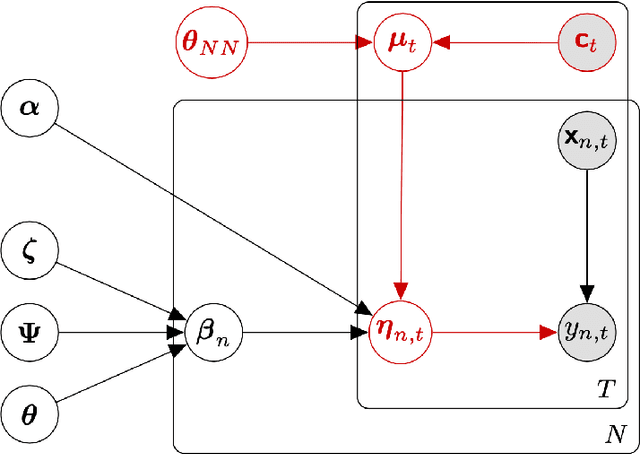
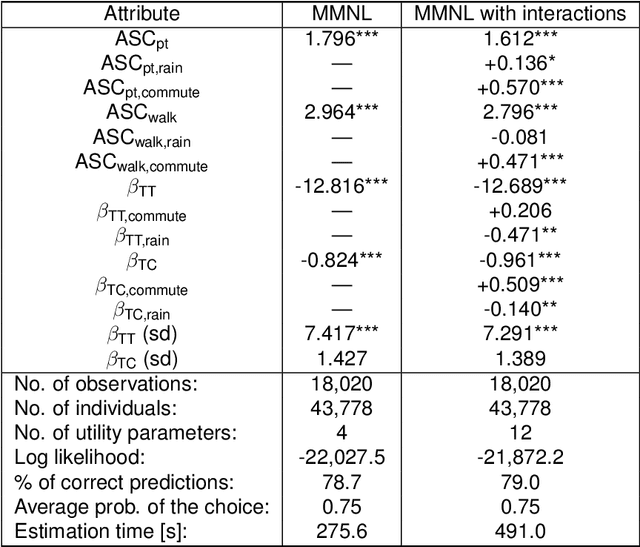
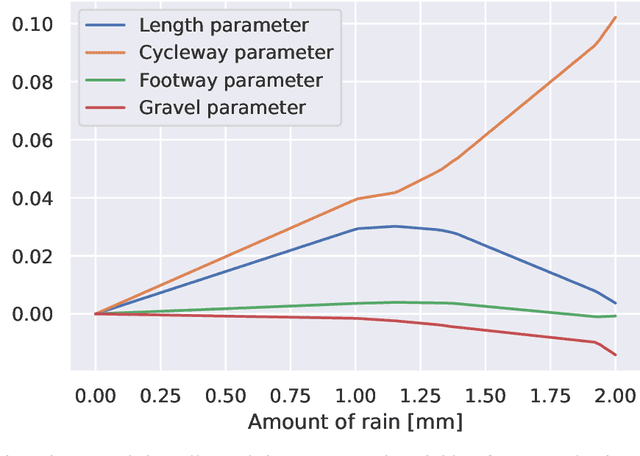
The mixed multinomial logit (MMNL) model assumes constant preference parameters of a decision-maker throughout different choice situations, which may be considered too strong for certain choice modelling applications. This paper proposes an effective approach to model context-dependent intra-respondent heterogeneity and introduces the idea of Context-aware Bayesian Mixed Multinomial Logit (C-MMNL) Model, where a neural network maps contextual information to shifts in the preference parameters of each individual in each choice occasion. The proposed model offers several key advantages. First, it supports for both continuous and discrete variables, as well as complex non-linear interactions between both types of variables. Secondly, each specification of the context is considered jointly as a whole by the neural network rather than each variable being considered independently. Finally, since the parameters of the neural network are shared across all decision-makers, it can leverage information from other decision-makers and use it to infer the effect of a particular context. Even though the C-MMNL model allows for flexible interactions between attributes, there is hardly an increase in the complexity of the model and the computation time, compared to the MMNL model. We present two real-world case studies from travel behaviour domain - a travel mode choice model and a bicycle route choice model. The bicycle route choice model is based on a large-scale, crowdsourced dataset of GPS trajectories including 110,083 trips made by 8,555 cyclists.
Joint localization and classification of breast tumors on ultrasound images using a novel auxiliary attention-based framework
Oct 11, 2022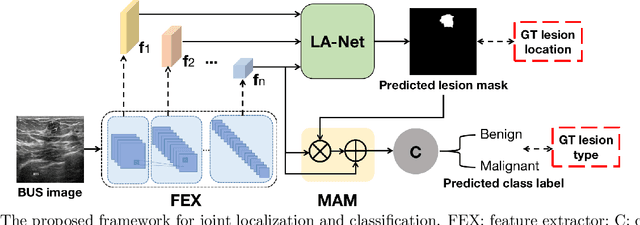
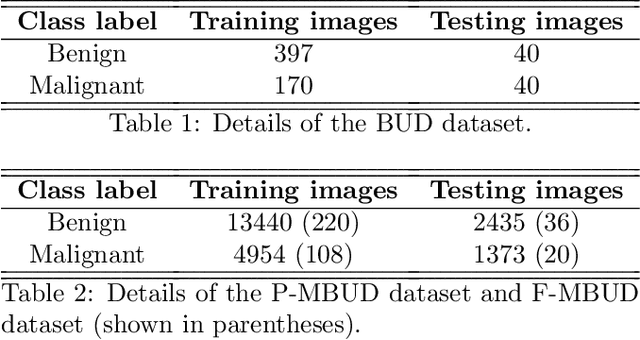
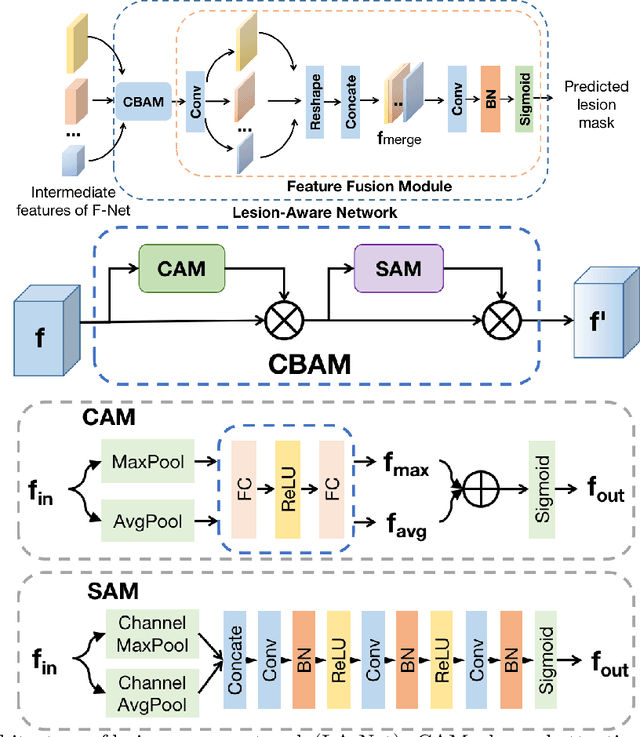
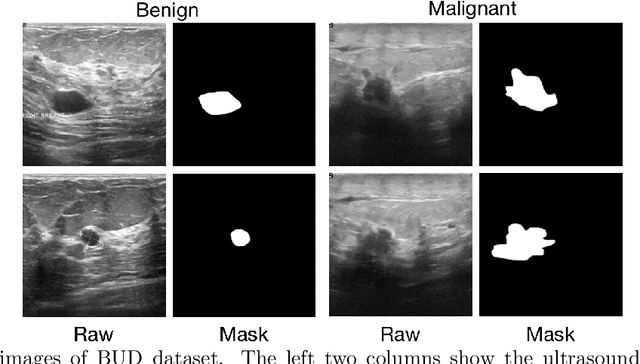
Automatic breast lesion detection and classification is an important task in computer-aided diagnosis, in which breast ultrasound (BUS) imaging is a common and frequently used screening tool. Recently, a number of deep learning-based methods have been proposed for joint localization and classification of breast lesions using BUS images. In these methods, features extracted by a shared network trunk are appended by two independent network branches to achieve classification and localization. Improper information sharing might cause conflicts in feature optimization in the two branches and leads to performance degradation. Also, these methods generally require large amounts of pixel-level annotated data for model training. To overcome these limitations, we proposed a novel joint localization and classification model based on the attention mechanism and disentangled semi-supervised learning strategy. The model used in this study is composed of a classification network and an auxiliary lesion-aware network. By use of the attention mechanism, the auxiliary lesion-aware network can optimize multi-scale intermediate feature maps and extract rich semantic information to improve classification and localization performance. The disentangled semi-supervised learning strategy only requires incomplete training datasets for model training. The proposed modularized framework allows flexible network replacement to be generalized for various applications. Experimental results on two different breast ultrasound image datasets demonstrate the effectiveness of the proposed method. The impacts of various network factors on model performance are also investigated to gain deep insights into the designed framework.
Channel-driven Decentralized Bayesian Federated Learning for Trustworthy Decision Making in D2D Networks
Oct 19, 2022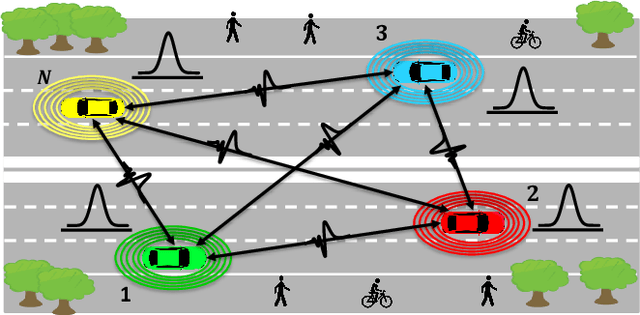
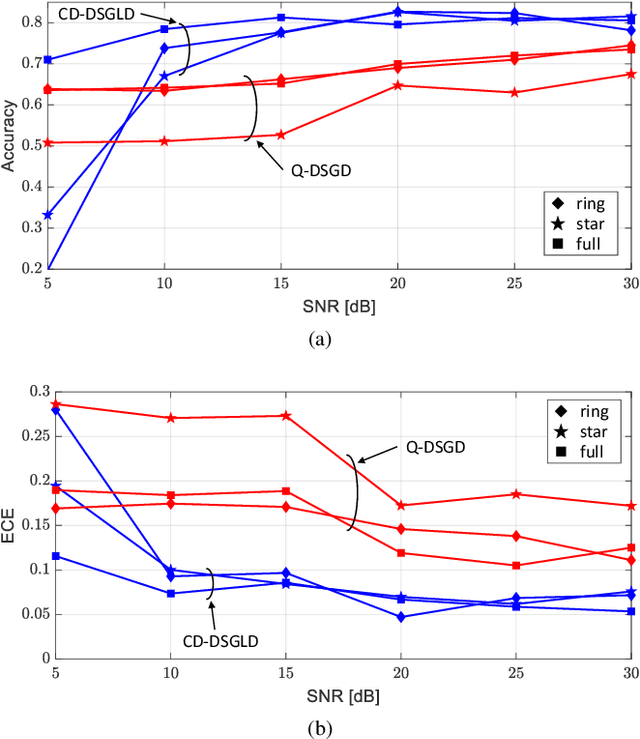
Bayesian Federated Learning (FL) offers a principled framework to account for the uncertainty caused by limitations in the data available at the nodes implementing collaborative training. In Bayesian FL, nodes exchange information about local posterior distributions over the model parameters space. This paper focuses on Bayesian FL implemented in a device-to-device (D2D) network via Decentralized Stochastic Gradient Langevin Dynamics (DSGLD), a recently introduced gradient-based Markov Chain Monte Carlo (MCMC) method. Based on the observation that DSGLD applies random Gaussian perturbations of model parameters, we propose to leverage channel noise on the D2D links as a mechanism for MCMC sampling. The proposed approach is compared against a conventional implementation of frequentist FL based on compression and digital transmission, highlighting advantages and limitations.
Behavioral graph fraud detection in E-commerce
Oct 13, 2022

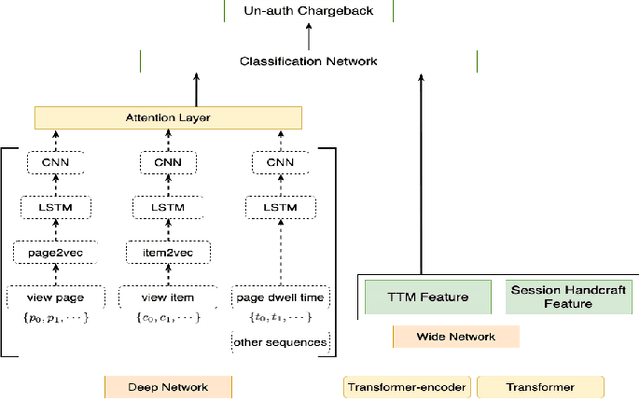
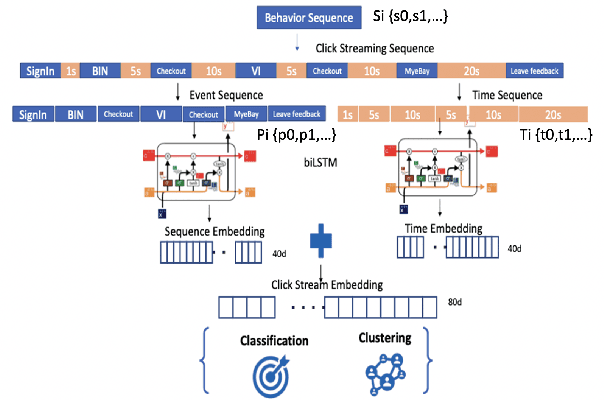
In e-commerce industry, graph neural network methods are the new trends for transaction risk modeling.The power of graph algorithms lie in the capability to catch transaction linking network information, which is very hard to be captured by other algorithms.However, in most existing approaches, transaction or user connections are defined by hard link strategies on shared properties, such as same credit card, same device, same ip address, same shipping address, etc. Those types of strategies will result in sparse linkages by entities with strong identification characteristics (ie. device) and over-linkages by entities that could be widely shared (ie. ip address), making it more difficult to learn useful information from graph. To address aforementioned problems, we present a novel behavioral biometric based method to establish transaction linkings based on user behavioral similarities, then train an unsupervised GNN to extract embedding features for downstream fraud prediction tasks. To our knowledge, this is the first time similarity based soft link has been used in graph embedding applications. To speed up similarity calculation, we apply an in-house GPU based HDBSCAN clustering method to remove highly concentrated and isolated nodes before graph construction. Our experiments show that embedding features learned from similarity based behavioral graph have achieved significant performance increase to the baseline fraud detection model in various business scenarios. In new guest buyer transaction scenario, this segment is a challenge for traditional method, we can make precision increase from 0.82 to 0.86 at the same recall of 0.27, which means we can decrease false positive rate using this method.
Optimizing the Age of Information in RIS-aided SWIPT Networks
Nov 14, 2021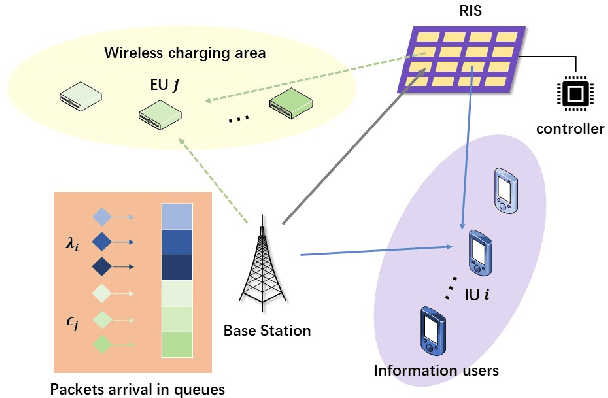

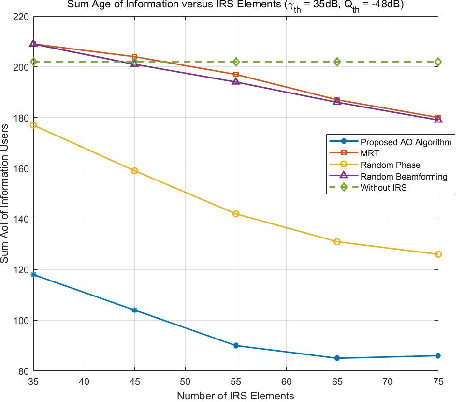
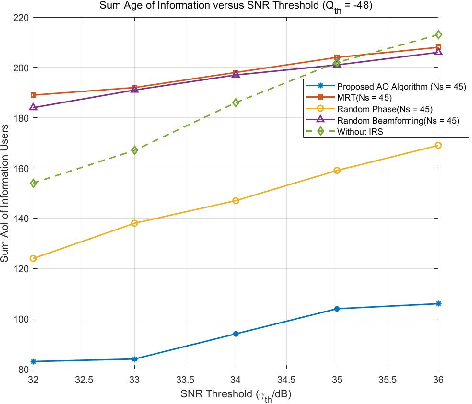
In this letter, a reconfigurable intelligent surface (RIS)-assisted simultaneous wireless information and power transfer (SWIPT) network is investigated. To quantify the freshness of the data packets at the information receiver, the concept of age of information (AoI) is considered. The AoI is decided as the time elapsed since the generation of the last successfully delivered signal containing status update information about the system. To minimize the total AoI for the information users while ensuring that the power transferred to energy harvesting users is greater than the demanded value, we formulate a scheduling scheme at the base station (BS), and a joint transmit beamforming and phase shift optimization at the BS and RIS, respectively. Specifically, the alternative optimization (AO) algorithm is proposed for handling the coupled variables of the joint active and passive beamforming design, and the successive convex approximation (SCA) algorithm is utilized for tackling the non-convexity of the formulated problems. The improvement in terms of AoI provided by the proposed algorithm is quantified by the numerical simulation results.