 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Algorithm Generalization Error Bounds via Auxiliary Distributions
Oct 02, 2022
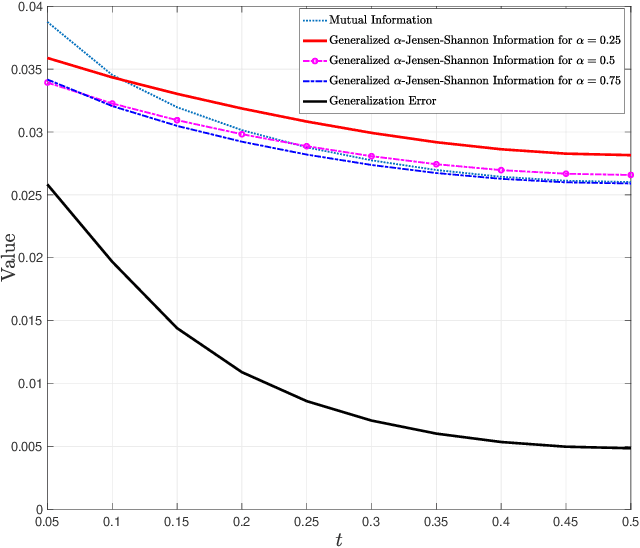
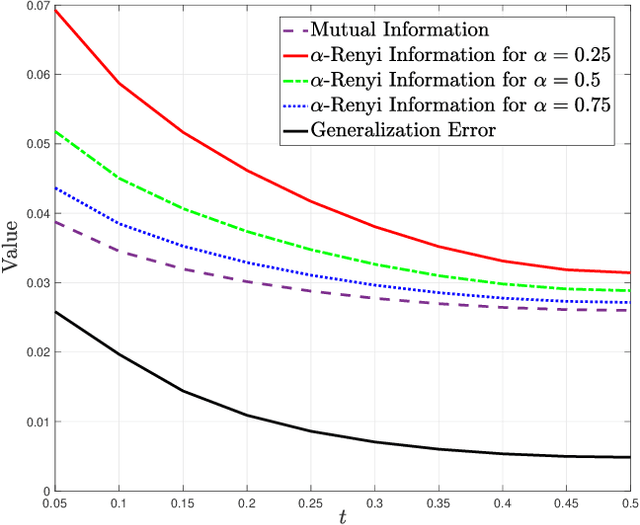
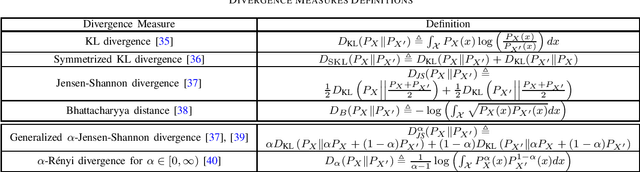
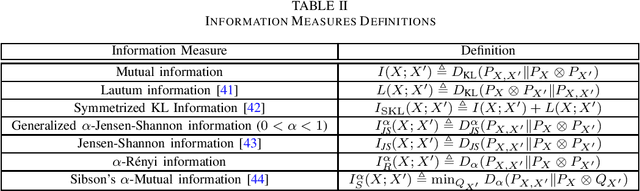
Generalization error boundaries are essential for comprehending how well machine learning models work. In this work, we suggest a creative method, i.e., the Auxiliary Distribution Method, that derives new upper bounds on generalization errors that are appropriate for supervised learning scenarios. We show that our general upper bounds can be specialized under some conditions to new bounds involving the generalized $\alpha$-Jensen-Shannon, $\alpha$-R\'enyi ($0< \alpha < 1$) information between random variable modeling the set of training samples and another random variable modeling the set of hypotheses. Our upper bounds based on generalized $\alpha$-Jensen-Shannon information are also finite. Additionally, we demonstrate how our auxiliary distribution method can be used to derive the upper bounds on generalization error under the distribution mismatch scenario in supervised learning algorithms, where the distributional mismatch is modeled as $\alpha$-Jensen-Shannon or $\alpha$-R\'enyi ($0< \alpha < 1$) between the distribution of test and training data samples. We also outline the circumstances in which our proposed upper bounds might be tighter than other earlier upper bounds.
Spatio-Temporal Learnable Proposals for End-to-End Video Object Detection
Oct 07, 2022
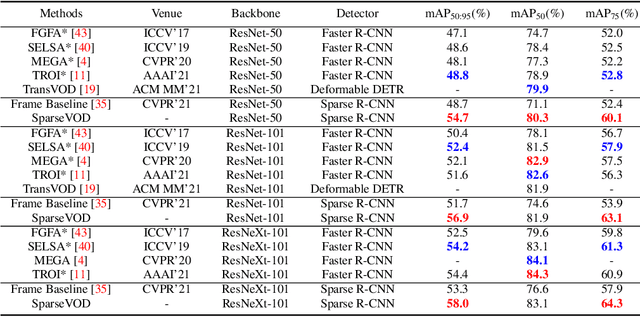

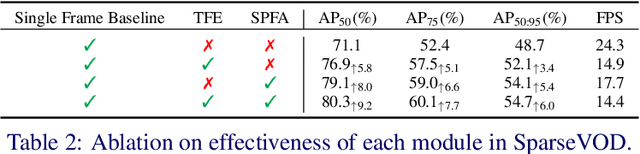
This paper presents the novel idea of generating object proposals by leveraging temporal information for video object detection. The feature aggregation in modern region-based video object detectors heavily relies on learned proposals generated from a single-frame RPN. This imminently introduces additional components like NMS and produces unreliable proposals on low-quality frames. To tackle these restrictions, we present SparseVOD, a novel video object detection pipeline that employs Sparse R-CNN to exploit temporal information. In particular, we introduce two modules in the dynamic head of Sparse R-CNN. First, the Temporal Feature Extraction module based on the Temporal RoI Align operation is added to extract the RoI proposal features. Second, motivated by sequence-level semantic aggregation, we incorporate the attention-guided Semantic Proposal Feature Aggregation module to enhance object feature representation before detection. The proposed SparseVOD effectively alleviates the overhead of complicated post-processing methods and makes the overall pipeline end-to-end trainable. Extensive experiments show that our method significantly improves the single-frame Sparse RCNN by 8%-9% in mAP. Furthermore, besides achieving state-of-the-art 80.3% mAP on the ImageNet VID dataset with ResNet-50 backbone, our SparseVOD outperforms existing proposal-based methods by a significant margin on increasing IoU thresholds (IoU > 0.5).
Tab2vox: CNN-Based Multivariate Multilevel Demand Forecasting Framework by Tabular-To-Voxel Image Conversion
Sep 21, 2022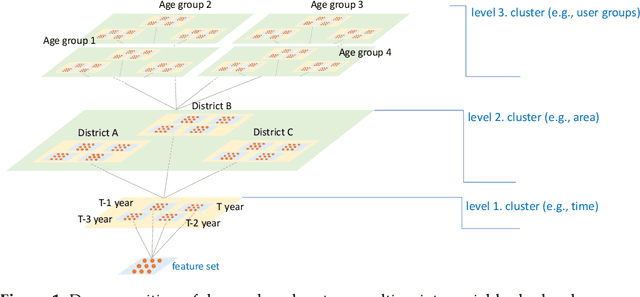
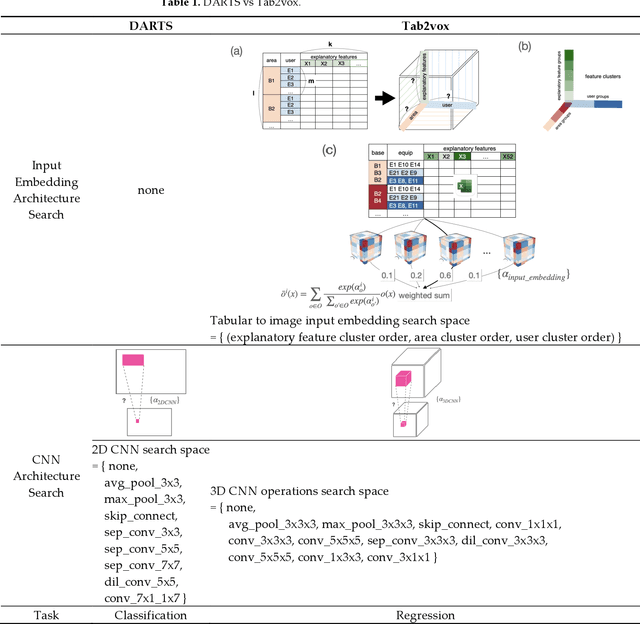
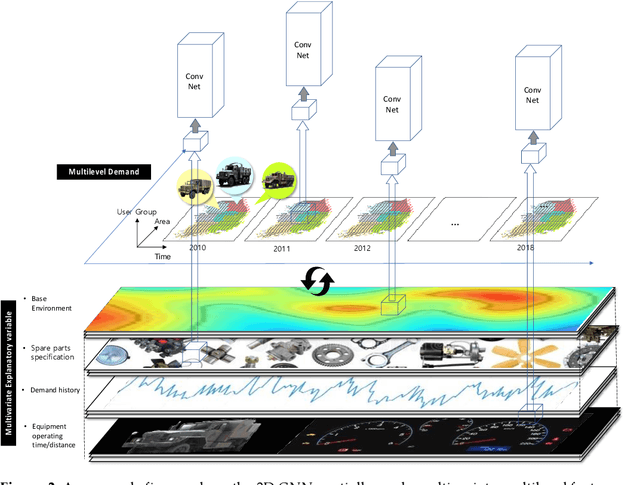
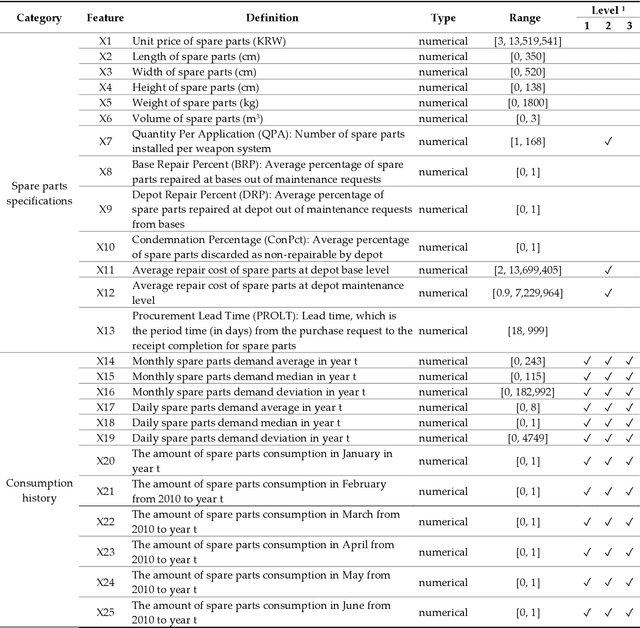
Since demand is influenced by a wide variety of causes, it is necessary to decompose the explana-tory variables into different levels, extract their relationships effectively, and reflect them in the forecast. In particular, this contextual information can be very useful in demand forecasting with large demand volatility or intermittent demand patterns. Convolutional neural networks (CNNs) have been successfully used in many fields where important information in data is represented by images. CNNs are powerful because they accept samples as images and use adjacent voxel sets to integrate multi-dimensional important information and learn important features. On the other hand, although the demand-forecasting model has been improved, the input data is still limited in its tabular form and is not suitable for CNN modeling. In this study, we propose a Tab2vox neural architecture search (NAS) model as a method to convert a high-dimensional tabular sam-ple into a well-formed 3D voxel image and use it in a 3D CNN network. For each image repre-sentation, the 3D CNN forecasting model proposed from the Tab2vox framework showed supe-rior performance, compared to the existing time series and machine learning techniques using tabular data, and the latest image transformation studies.
Reinforced Meta-path Selection for Recommendation on Heterogeneous Information Networks
Dec 23, 2021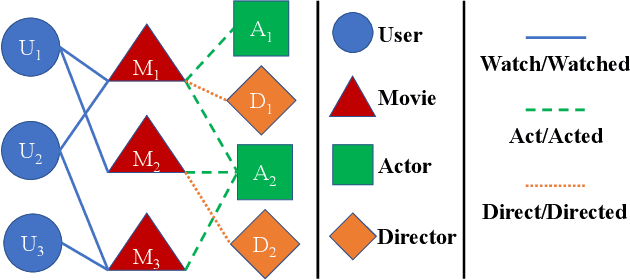
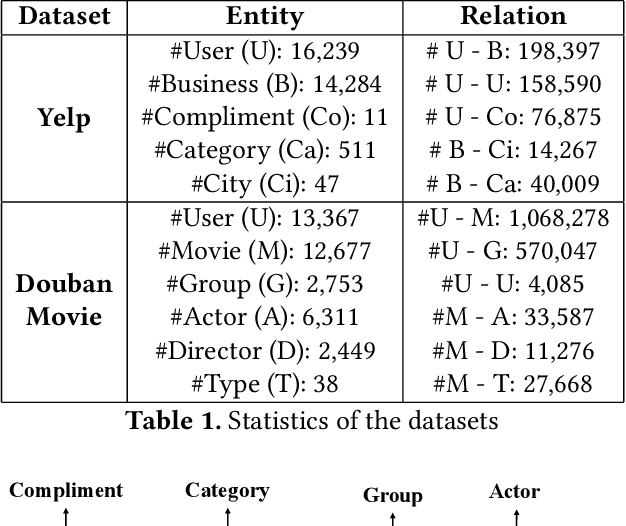
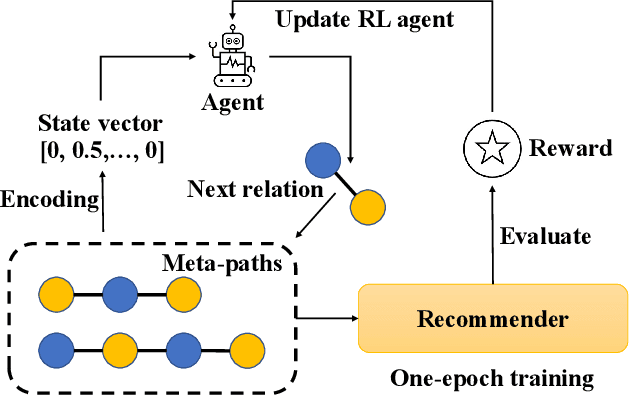
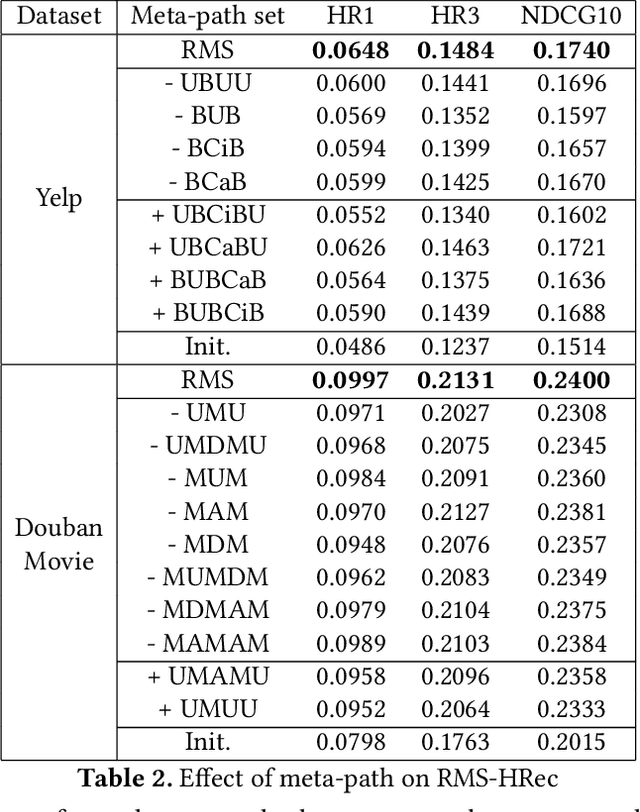
Heterogeneous Information Networks (HINs) capture complex relations among entities of various kinds and have been used extensively to improve the effectiveness of various data mining tasks, such as in recommender systems. Many existing HIN-based recommendation algorithms utilize hand-crafted meta-paths to extract semantic information from the networks. These algorithms rely on extensive domain knowledge with which the best set of meta-paths can be selected. For applications where the HINs are highly complex with numerous node and link types, the approach of hand-crafting a meta-path set is too tedious and error-prone. To tackle this problem, we propose the Reinforcement learning-based Meta-path Selection (RMS) framework to select effective meta-paths and to incorporate them into existing meta-path-based recommenders. To identify high-quality meta-paths, RMS trains a reinforcement learning (RL) based policy network(agent), which gets rewards from the performance on the downstream recommendation tasks. We design a HIN-based recommendation model, HRec, that effectively uses the meta-path information. We further integrate HRec with RMS and derive our recommendation solution, RMS-HRec, that automatically utilizes the effective meta-paths. Experiments on real datasets show that our algorithm can significantly improve the performance of recommendation models by capturing important meta-paths automatically.
Transfer Learning in Quantum Parametric Classifiers: An Information-Theoretic Generalization Analysis
Jan 17, 2022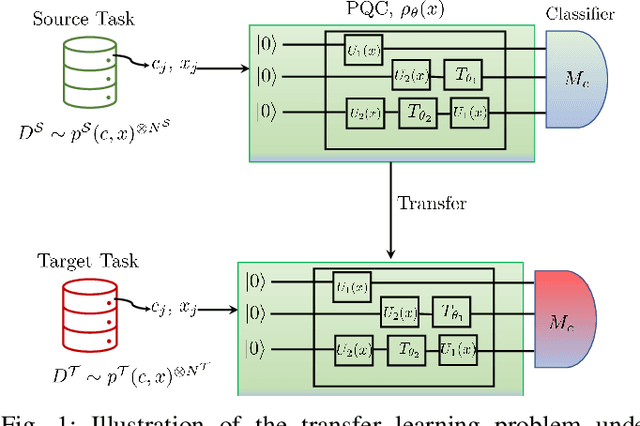
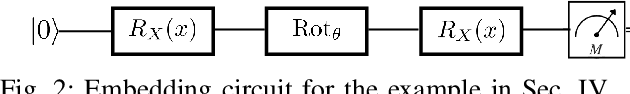
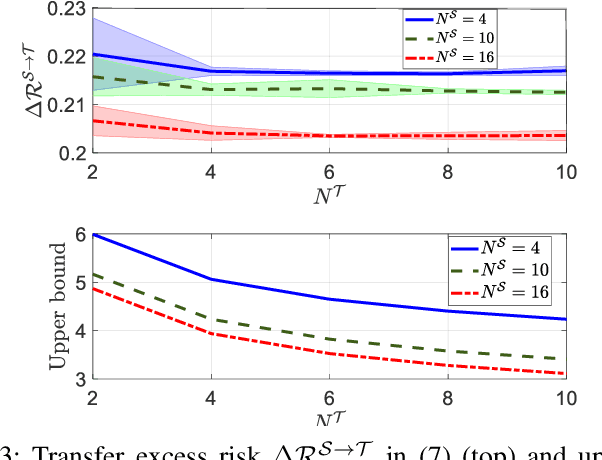
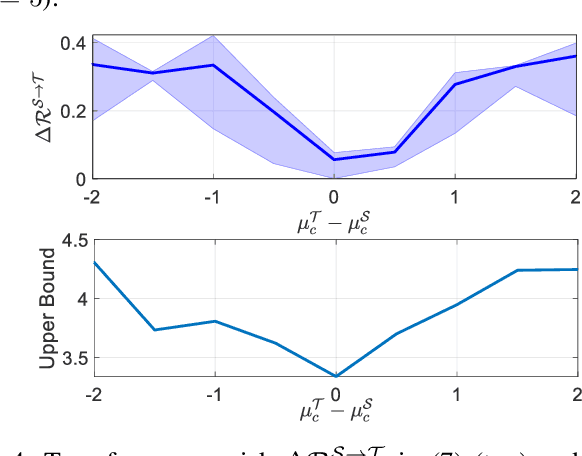
A key step in quantum machine learning with classical inputs is the design of an embedding circuit mapping inputs to a quantum state. This paper studies a transfer learning setting in which classical-to-quantum embedding is carried out by an arbitrary parametric quantum circuit that is pre-trained based on data from a source task. At run time, the binary classifier is then optimized based on data from the target task of interest. Using an information-theoretic approach, we demonstrate that the average excess risk, or optimality gap, can be bounded in terms of two R\'enyi mutual information terms between classical input and quantum embedding under source and target tasks, as well as in terms of a measure of similarity between the source and target tasks related to the trace distance. The main theoretical results are validated on a simple binary classification example.
Deep Learning for Multi-User MIMO Systems: Joint Design of Pilot, Limited Feedback, and Precoding
Sep 21, 2022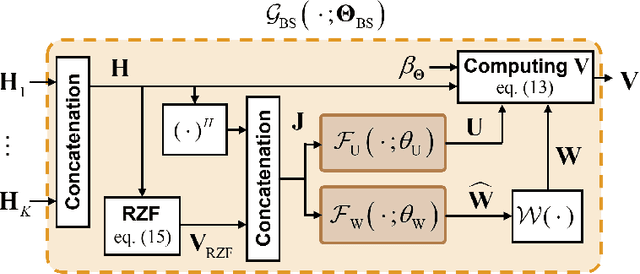
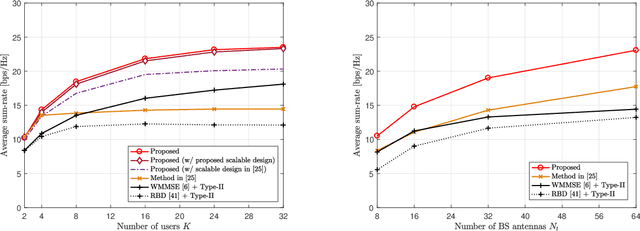
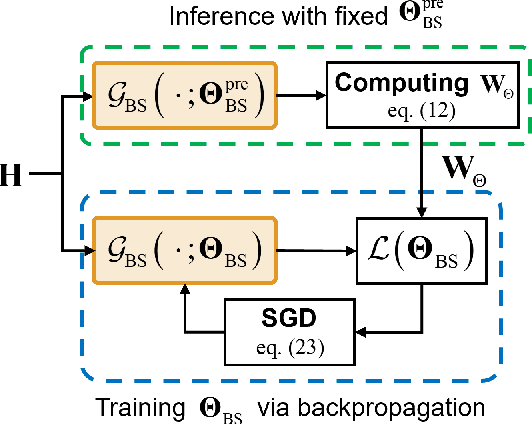
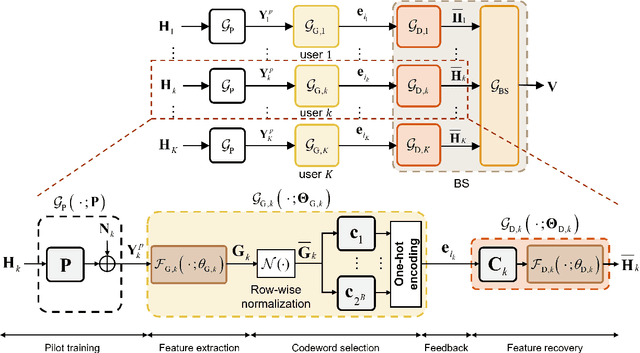
In conventional multi-user multiple-input multiple-output (MU-MIMO) systems with frequency division duplexing (FDD), channel acquisition and precoder optimization processes have been designed separately although they are highly coupled. This paper studies an end-to-end design of downlink MU-MIMO systems which include pilot sequences, limited feedback, and precoding. To address this problem, we propose a novel deep learning (DL) framework which jointly optimizes the feedback information generation at users and the precoder design at a base station (BS). Each procedure in the MU-MIMO systems is replaced by intelligently designed multiple deep neural networks (DNN) units. At the BS, a neural network generates pilot sequences and helps the users obtain accurate channel state information. At each user, the channel feedback operation is carried out in a distributed manner by an individual user DNN. Then, another BS DNN collects feedback information from the users and determines the MIMO precoding matrices. A joint training algorithm is proposed to optimize all DNN units in an end-to-end manner. In addition, a training strategy which can avoid retraining for different network sizes for a scalable design is proposed. Numerical results demonstrate the effectiveness of the proposed DL framework compared to classical optimization techniques and other conventional DNN schemes.
Blind Asynchronous Over-the-Air Federated Edge Learning
Oct 31, 2022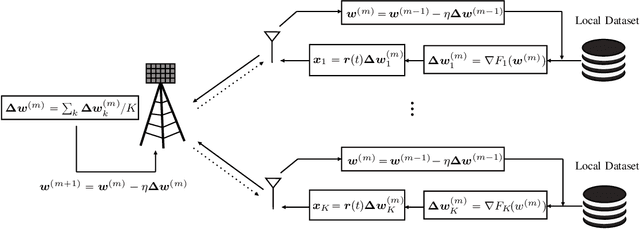

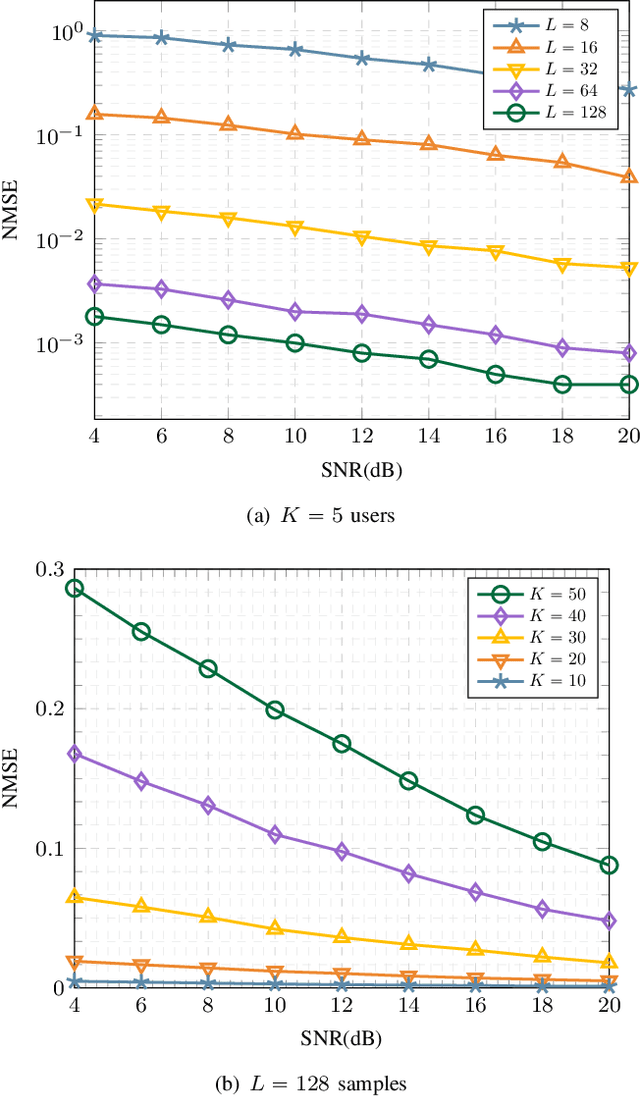
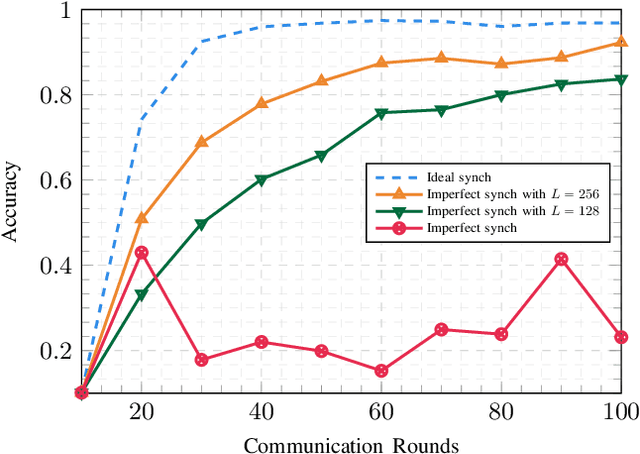
Federated Edge Learning (FEEL) is a distributed machine learning technique where each device contributes to training a global inference model by independently performing local computations with their data. More recently, FEEL has been merged with over-the-air computation (OAC), where the global model is calculated over the air by leveraging the superposition of analog signals. However, when implementing FEEL with OAC, there is the challenge on how to precode the analog signals to overcome any time misalignment at the receiver. In this work, we propose a novel synchronization-free method to recover the parameters of the global model over the air without requiring any prior information about the time misalignments. For that, we construct a convex optimization based on the norm minimization problem to directly recover the global model by solving a convex semi-definite program. The performance of the proposed method is evaluated in terms of accuracy and convergence via numerical experiments. We show that our proposed algorithm is close to the ideal synchronized scenario by $10\%$, and performs $4\times$ better than the simple case where no recovering method is used.
When Language Model Meets Private Library
Oct 31, 2022
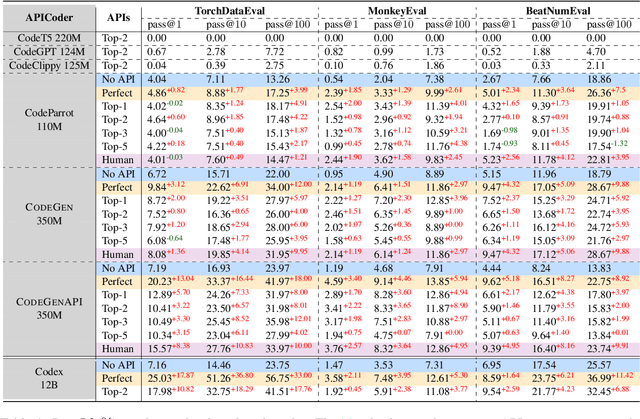
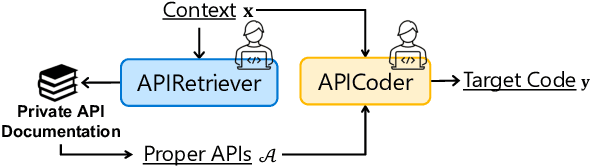

With the rapid development of pre-training techniques, a number of language models have been pre-trained on large-scale code corpora and perform well in code generation. In this paper, we investigate how to equip pre-trained language models with the ability of code generation for private libraries. In practice, it is common for programmers to write code using private libraries. However, this is a challenge for language models since they have never seen private APIs during training. Motivated by the fact that private libraries usually come with elaborate API documentation, we propose a novel framework with two modules: the APIRetriever finds useful APIs, and then the APICoder generates code using these APIs. For APIRetriever, we present a dense retrieval system and also design a friendly interaction to involve uses. For APICoder, we can directly use off-the-shelf language models, or continually pre-train the base model on a code corpus containing API information. Both modules are trained with data from public libraries and can be generalized to private ones. Furthermore, we craft three benchmarks for private libraries, named TorchDataEval, MonkeyEval, and BeatNumEval. Experimental results demonstrate the impressive performance of our framework.
Estimating Neural Reflectance Field from Radiance Field using Tree Structures
Oct 09, 2022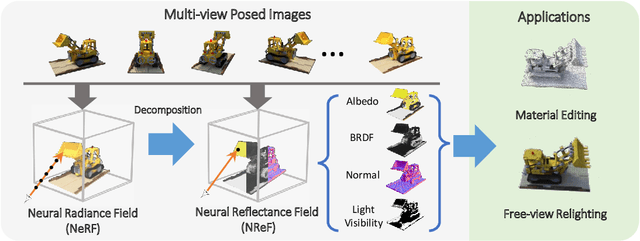


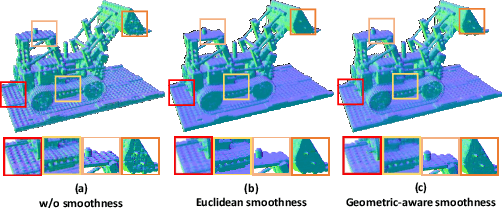
We present a new method for estimating the Neural Reflectance Field (NReF) of an object from a set of posed multi-view images under unknown lighting. NReF represents 3D geometry and appearance of objects in a disentangled manner, and are hard to be estimated from images only. Our method solves this problem by exploiting the Neural Radiance Field (NeRF) as a proxy representation, from which we perform further decomposition. A high-quality NeRF decomposition relies on good geometry information extraction as well as good prior terms to properly resolve ambiguities between different components. To extract high-quality geometry information from radiance fields, we re-design a new ray-casting based method for surface point extraction. To efficiently compute and apply prior terms, we convert different prior terms into different type of filter operations on the surface extracted from radiance field. We then employ two type of auxiliary data structures, namely Gaussian KD-tree and octree, to support fast querying of surface points and efficient computation of surface filters during training. Based on this, we design a multi-stage decomposition optimization pipeline for estimating neural reflectance field from neural radiance fields. Extensive experiments show our method outperforms other state-of-the-art methods on different data, and enable high-quality free-view relighting as well as material editing tasks.
Fairness Reprogramming
Sep 21, 2022
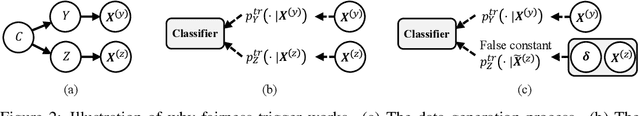
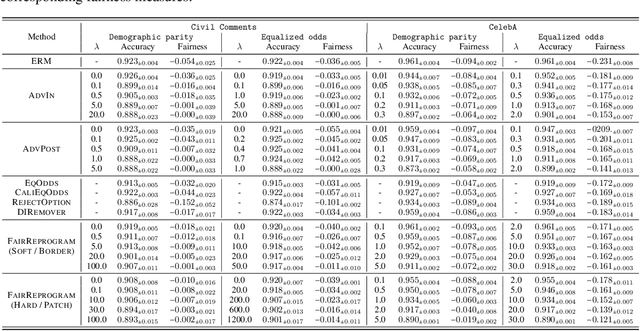
Despite a surge of recent advances in promoting machine Learning (ML) fairness, the existing mainstream approaches mostly require training or finetuning the entire weights of the neural network to meet the fairness criteria. However, this is often infeasible in practice for those large-scale trained models due to large computational and storage costs, low data efficiency, and model privacy issues. In this paper, we propose a new generic fairness learning paradigm, called FairReprogram, which incorporates the model reprogramming technique. Specifically, FairReprogram considers the neural model fixed, and instead appends to the input a set of perturbations, called the fairness trigger, which is tuned towards the fairness criteria under a min-max formulation. We further introduce an information-theoretic framework that explains why and under what conditions fairness goals can be achieved using the fairness trigger. We show both theoretically and empirically that the fairness trigger can effectively obscure demographic biases in the output prediction of fixed ML models by providing false demographic information that hinders the model from utilizing the correct demographic information to make the prediction. Extensive experiments on both NLP and CV datasets demonstrate that our method can achieve better fairness improvements than retraining-based methods with far less training cost and data dependency under two widely-used fairness criteria.