 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ViTALiTy: Unifying Low-rank and Sparse Approximation for Vision Transformer Acceleration with a Linear Taylor Attention
Nov 09, 2022
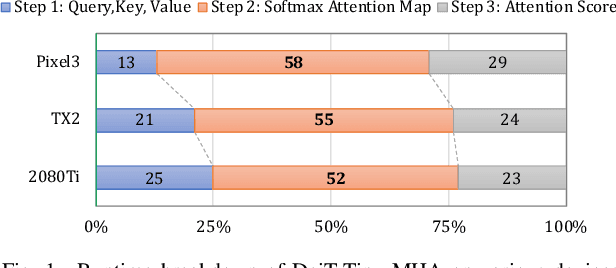
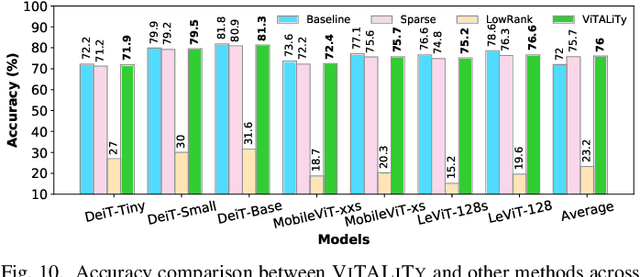
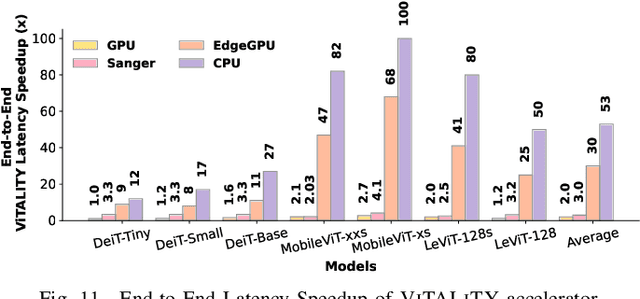
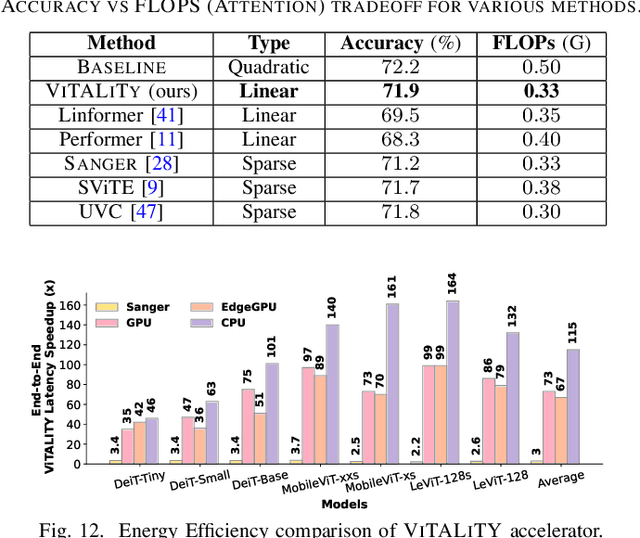
Vision Transformer (ViT) has emerged as a competitive alternative to convolutional neural networks for various computer vision applications. Specifically, ViT multi-head attention layers make it possible to embed information globally across the overall image. Nevertheless, computing and storing such attention matrices incurs a quadratic cost dependency on the number of patches, limiting its achievable efficiency and scalability and prohibiting more extensive real-world ViT applications on resource-constrained devices. Sparse attention has been shown to be a promising direction for improving hardware acceleration efficiency for NLP models. However, a systematic counterpart approach is still missing for accelerating ViT models. To close the above gap, we propose a first-of-its-kind algorithm-hardware codesigned framework, dubbed ViTALiTy, for boosting the inference efficiency of ViTs. Unlike sparsity-based Transformer accelerators for NLP, ViTALiTy unifies both low-rank and sparse components of the attention in ViTs. At the algorithm level, we approximate the dot-product softmax operation via first-order Taylor attention with row-mean centering as the low-rank component to linearize the cost of attention blocks and further boost the accuracy by incorporating a sparsity-based regularization. At the hardware level, we develop a dedicated accelerator to better leverage the resulting workload and pipeline from ViTALiTy's linear Taylor attention which requires the execution of only the low-rank component, to further boost the hardware efficiency. Extensive experiments and ablation studies validate that ViTALiTy offers boosted end-to-end efficiency (e.g., $3\times$ faster and $3\times$ energy-efficient) under comparable accuracy, with respect to the state-of-the-art solution.
Improving Chinese Named Entity Recognition by Search Engine Augmentation
Oct 23, 2022

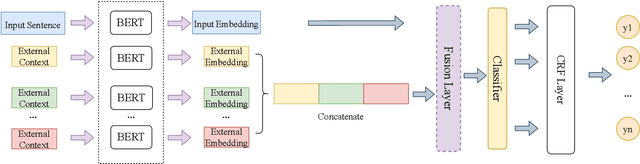

Compared with English, Chinese suffers from more grammatical ambiguities, like fuzzy word boundaries and polysemous words. In this case, contextual information is not sufficient to support Chinese named entity recognition (NER), especially for rare and emerging named entities. Semantic augmentation using external knowledge is a potential way to alleviate this problem, while how to obtain and leverage external knowledge for the NER task remains a challenge. In this paper, we propose a neural-based approach to perform semantic augmentation using external knowledge from search engine for Chinese NER. In particular, a multi-channel semantic fusion model is adopted to generate the augmented input representations, which aggregates external related texts retrieved from the search engine. Experiments have shown the superiority of our model across 4 NER datasets, including formal and social media language contexts, which further prove the effectiveness of our approach.
A Multi-task Model for Sentiment Aided Stance Detection of Climate Change Tweets
Nov 07, 2022
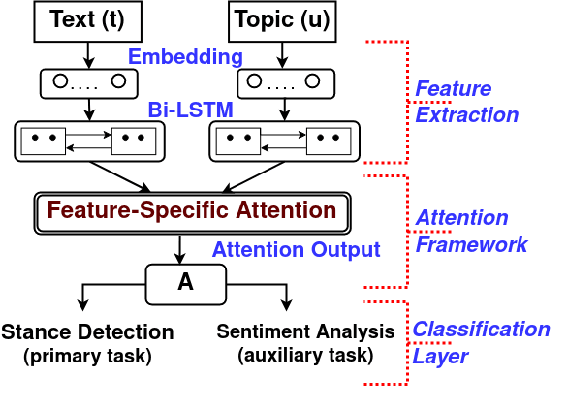
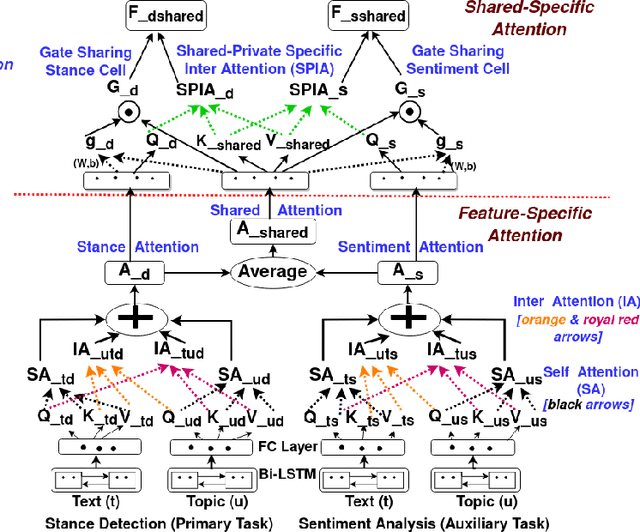
Climate change has become one of the biggest challenges of our time. Social media platforms such as Twitter play an important role in raising public awareness and spreading knowledge about the dangers of the current climate crisis. With the increasing number of campaigns and communication about climate change through social media, the information could create more awareness and reach the general public and policy makers. However, these Twitter communications lead to polarization of beliefs, opinion-dominated ideologies, and often a split into two communities of climate change deniers and believers. In this paper, we propose a framework that helps identify denier statements on Twitter and thus classifies the stance of the tweet into one of the two attitudes towards climate change (denier/believer). The sentimental aspects of Twitter data on climate change are deeply rooted in general public attitudes toward climate change. Therefore, our work focuses on learning two closely related tasks: Stance Detection and Sentiment Analysis of climate change tweets. We propose a multi-task framework that performs stance detection (primary task) and sentiment analysis (auxiliary task) simultaneously. The proposed model incorporates the feature-specific and shared-specific attention frameworks to fuse multiple features and learn the generalized features for both tasks. The experimental results show that the proposed framework increases the performance of the primary task, i.e., stance detection by benefiting from the auxiliary task, i.e., sentiment analysis compared to its uni-modal and single-task variants.
Learning Feature Descriptors for Pre- and Intra-operative Point Cloud Matching for Laparoscopic Liver Registration
Nov 07, 2022
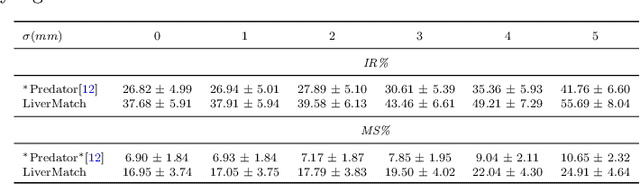
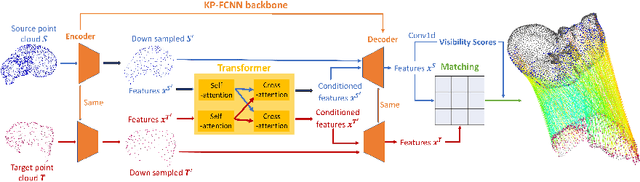
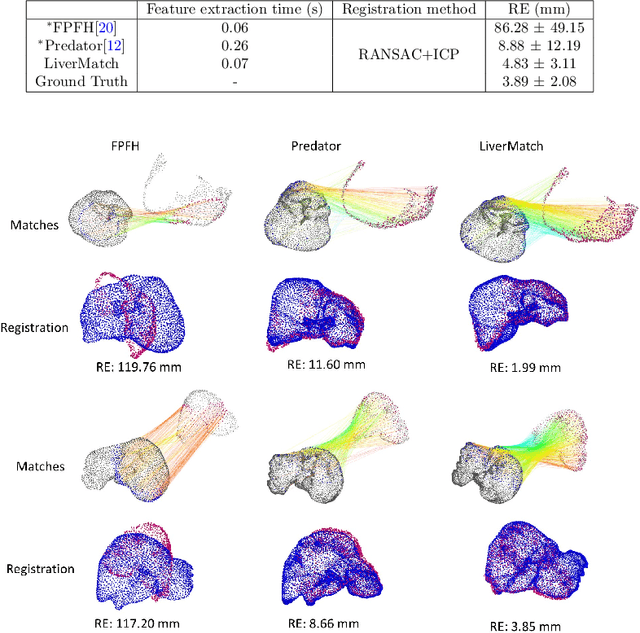
Purpose: In laparoscopic liver surgery (LLS), pre-operative information can be overlaid onto the intra-operative scene by registering a 3D pre-operative model to the intra-operative partial surface reconstructed from the laparoscopic video. To assist with this task, we explore the use of learning-based feature descriptors, which, to our best knowledge, have not been explored for use in laparoscopic liver registration. Furthermore, a dataset to train and evaluate the use of learning-based descriptors does not exist. Methods: We present the LiverMatch dataset consisting of 16 preoperative models and their simulated intra-operative 3D surfaces. We also propose the LiverMatch network designed for this task, which outputs per-point feature descriptors, visibility scores, and matched points. Results: We compare the proposed LiverMatch network with anetwork closest to LiverMatch, and a histogram-based 3D descriptor on the testing split of the LiverMatch dataset, which includes two unseen pre-operative models and 1400 intra-operative surfaces. Results suggest that our LiverMatch network can predict more accurate and dense matches than the other two methods and can be seamlessly integrated with a RANSAC-ICP-based registration algorithm to achieve an accurate initial alignment. Conclusion: The use of learning-based feature descriptors in LLR is promising, as it can help achieve an accurate initial rigid alignment, which, in turn, serves as an initialization for subsequent non-rigid registration. We will release the dataset and code upon acceptance.
Complete Cross-triplet Loss in Label Space for Audio-visual Cross-modal Retrieval
Nov 07, 2022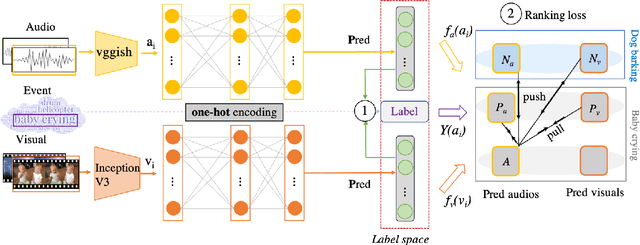
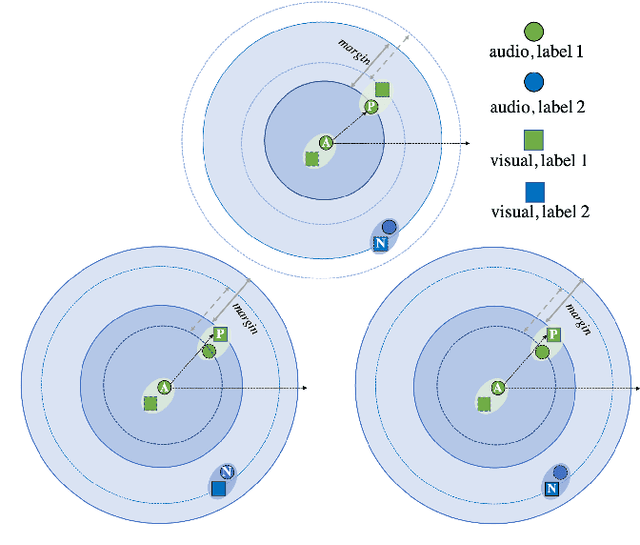
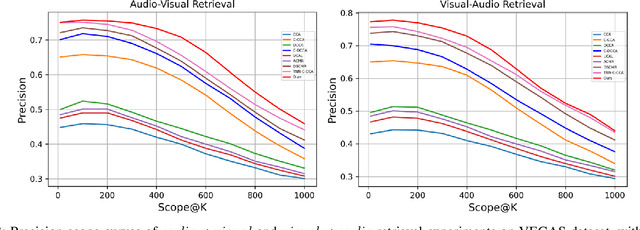
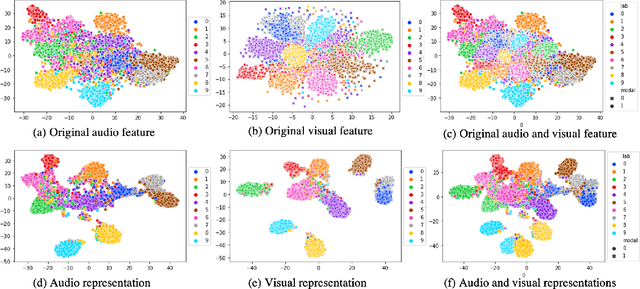
The heterogeneity gap problem is the main challenge in cross-modal retrieval. Because cross-modal data (e.g. audiovisual) have different distributions and representations that cannot be directly compared. To bridge the gap between audiovisual modalities, we learn a common subspace for them by utilizing the intrinsic correlation in the natural synchronization of audio-visual data with the aid of annotated labels. TNN-CCCA is the best audio-visual cross-modal retrieval (AV-CMR) model so far, but the model training is sensitive to hard negative samples when learning common subspace by applying triplet loss to predict the relative distance between inputs. In this paper, to reduce the interference of hard negative samples in representation learning, we propose a new AV-CMR model to optimize semantic features by directly predicting labels and then measuring the intrinsic correlation between audio-visual data using complete cross-triple loss. In particular, our model projects audio-visual features into label space by minimizing the distance between predicted label features after feature projection and ground label representations. Moreover, we adopt complete cross-triplet loss to optimize the predicted label features by leveraging the relationship between all possible similarity and dissimilarity semantic information across modalities. The extensive experimental results on two audio-visual double-checked datasets have shown an improvement of approximately 2.1% in terms of average MAP over the current state-of-the-art method TNN-CCCA for the AV-CMR task, which indicates the effectiveness of our proposed model.
Angular Center of Mass for Humanoid Robots
Oct 14, 2022
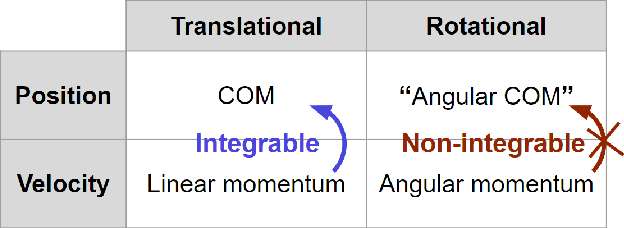
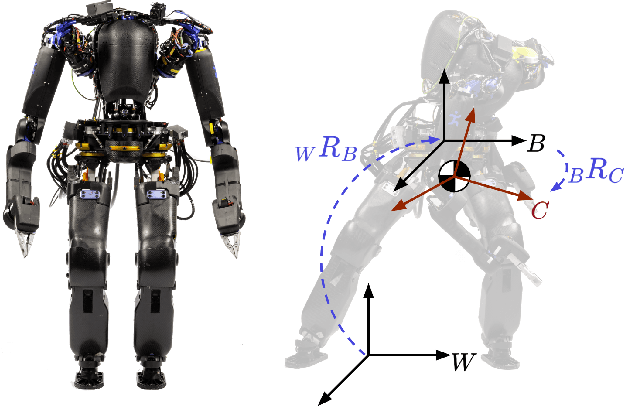
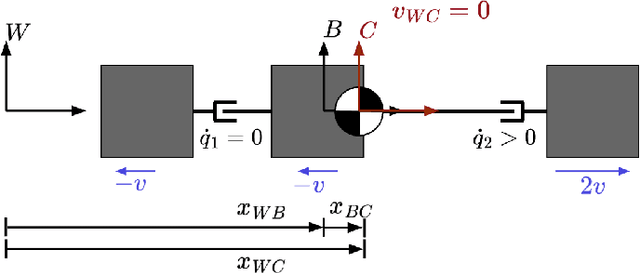
The center of mass (CoM) has been widely used in planning and control for humanoid locomotion, because it carries key information about the position of a robot. In contrast, an ''angular center of mass'' (ACoM), which provides an ''average'' orientation of a robot, is less well-known in the community, although the concept has been in the literature for about a decade. In this paper, we introduce the ACoM from a CoM perspective. We optimize for an ACoM on the humanoid robot Nadia, and demonstrate its application in walking with natural upper body motion on hardware.
Learning Algorithm Generalization Error Bounds via Auxiliary Distributions
Oct 02, 2022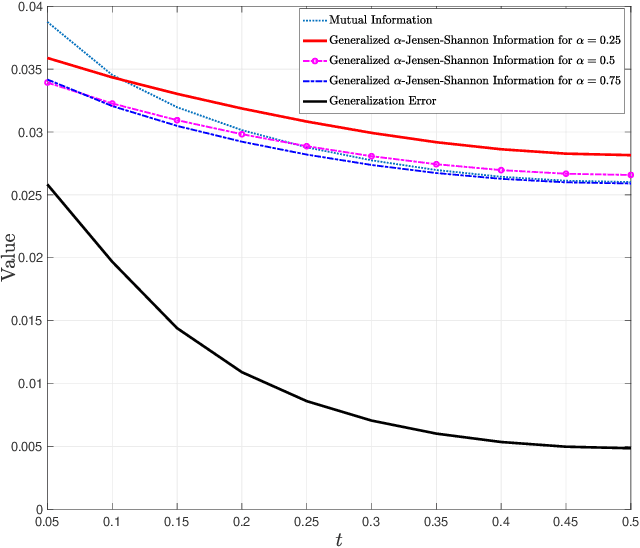
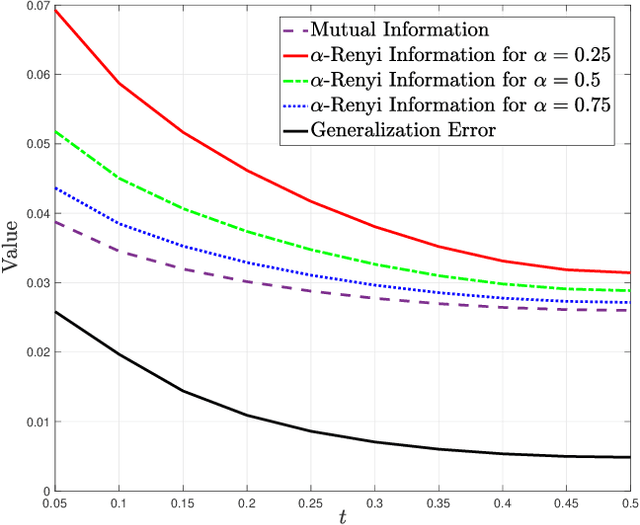
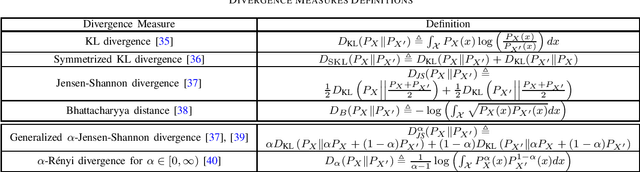
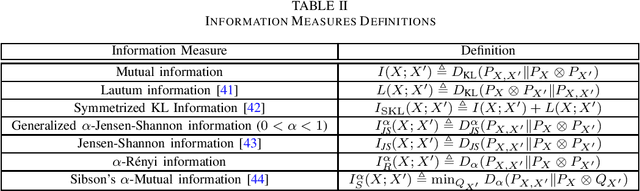
Generalization error boundaries are essential for comprehending how well machine learning models work. In this work, we suggest a creative method, i.e., the Auxiliary Distribution Method, that derives new upper bounds on generalization errors that are appropriate for supervised learning scenarios. We show that our general upper bounds can be specialized under some conditions to new bounds involving the generalized $\alpha$-Jensen-Shannon, $\alpha$-R\'enyi ($0< \alpha < 1$) information between random variable modeling the set of training samples and another random variable modeling the set of hypotheses. Our upper bounds based on generalized $\alpha$-Jensen-Shannon information are also finite. Additionally, we demonstrate how our auxiliary distribution method can be used to derive the upper bounds on generalization error under the distribution mismatch scenario in supervised learning algorithms, where the distributional mismatch is modeled as $\alpha$-Jensen-Shannon or $\alpha$-R\'enyi ($0< \alpha < 1$) between the distribution of test and training data samples. We also outline the circumstances in which our proposed upper bounds might be tighter than other earlier upper bounds.
Deep Learning Based Audio-Visual Multi-Speaker DOA Estimation Using Permutation-Free Loss Function
Oct 26, 2022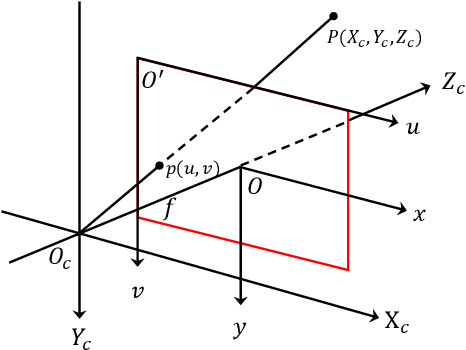


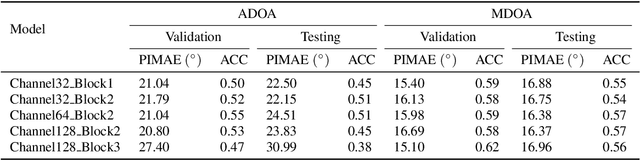
In this paper, we propose a deep learning based multi-speaker direction of arrival (DOA) estimation with audio and visual signals by using permutation-free loss function. We first collect a data set for multi-modal sound source localization (SSL) where both audio and visual signals are recorded in real-life home TV scenarios. Then we propose a novel spatial annotation method to produce the ground truth of DOA for each speaker with the video data by transformation between camera coordinate and pixel coordinate according to the pin-hole camera model. With spatial location information served as another input along with acoustic feature, multi-speaker DOA estimation could be solved as a classification task of active speaker detection. Label permutation problem in multi-speaker related tasks will be addressed since the locations of each speaker are used as input. Experiments conducted on both simulated data and real data show that the proposed audio-visual DOA estimation model outperforms audio-only DOA estimation model by a large margin.
Speaker Diarization Based on Multi-channel Microphone Array in Small-scale Meeting
Oct 26, 2022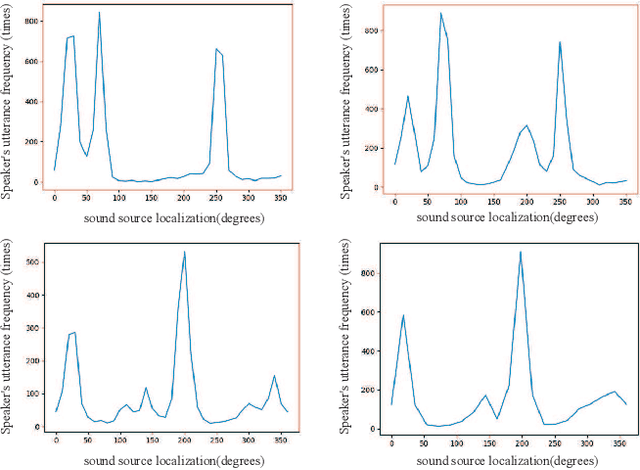
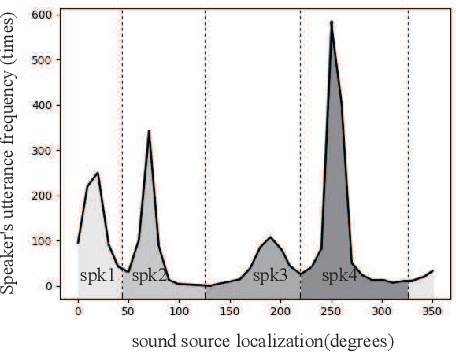
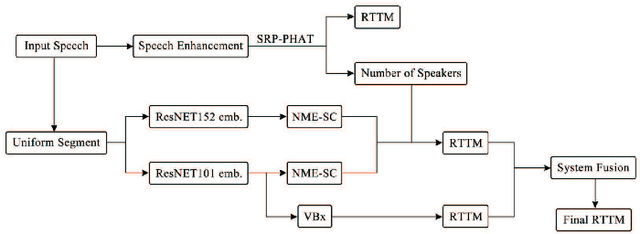

In the task of speaker diarization, the number of small-scale meetings accounts for a large proportion. When microphone arrays are employed as a recording device, its spatial information is usually ignored by most researchers. In this paper, inspired by the clustering method combining d-vector and microphone array spatial vector, we proposed a diarization method which using multi-channel microphone arrays for a meeting with no more than 4 speakers. We utilize speech enhancement to preprocess the audio from the microphone array. The Steered-Response Power Phase Transform (SRP-PHAT) algorithm are employed to get more accurate speakers, and apply the number of speakers to recluster the speech segments to achieve better performance. Finally, we fuse our system by DOVER-LAP to get the best result. We evaluated our system on the AMI corpus. Compared with the best experimental results so far, our system has achieved largely improvement in the diarization error rate (DER).
Multi-Viewpoint and Multi-Evaluation with Felicitous Inductive Bias Boost Machine Abstract Reasoning Ability
Oct 26, 2022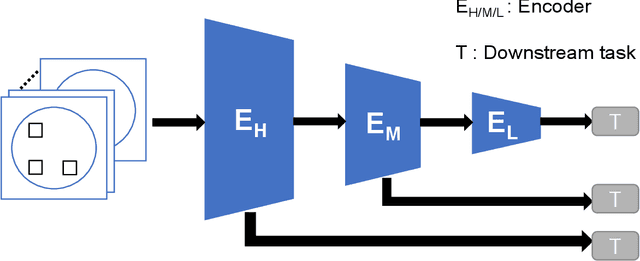
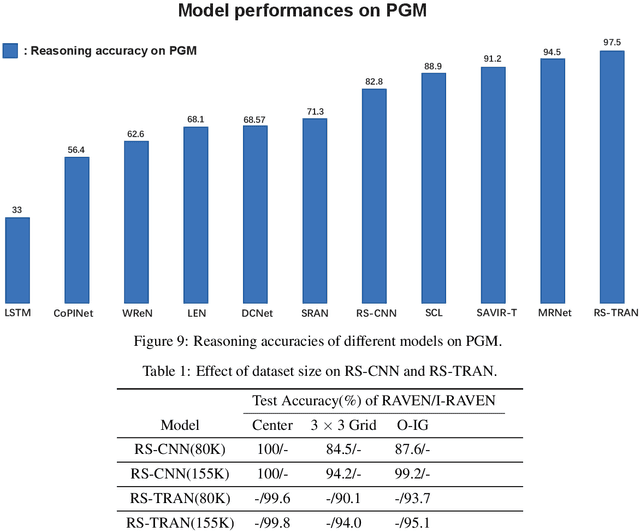
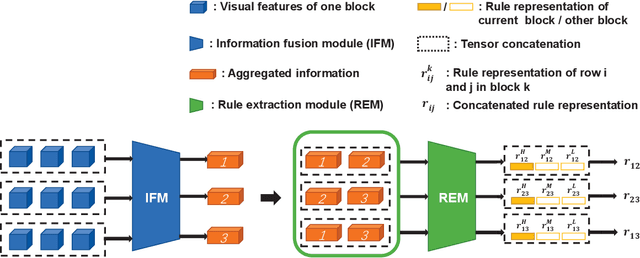
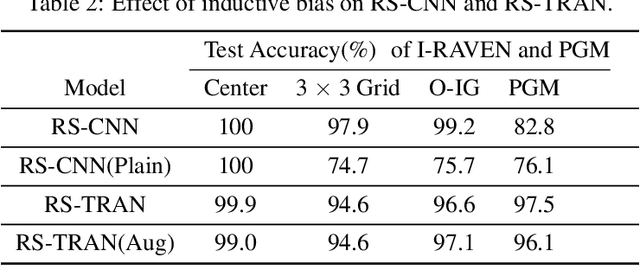
Great endeavors have been made to study AI's ability in abstract reasoning, along with which different versions of RAVEN's progressive matrices (RPM) are proposed as benchmarks. Previous works give inkling that without sophisticated design or extra meta-data containing semantic information, neural networks may still be indecisive in making decisions regarding RPM problems, after relentless training. Evidenced by thorough experiments and ablation studies, we showcase that end-to-end neural networks embodied with felicitous inductive bias, intentionally design or serendipitously match, can solve RPM problems elegantly, without the augment of any extra meta-data or preferences of any specific backbone. Our work also reveals that multi-viewpoint with multi-evaluation is a key learning strategy for successful reasoning. Finally, potential explanations for the failure of connectionist models in generalization are provided. We hope that these results will serve as inspections of AI's ability beyond perception and toward abstract reasoning. Source code can be found in https://github.com/QinglaiWeiCASIA/RavenSolver.