 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LUM-ViT: Learnable Under-sampling Mask Vision Transformer for Bandwidth Limited Optical Signal Acquisition
Mar 03, 2024
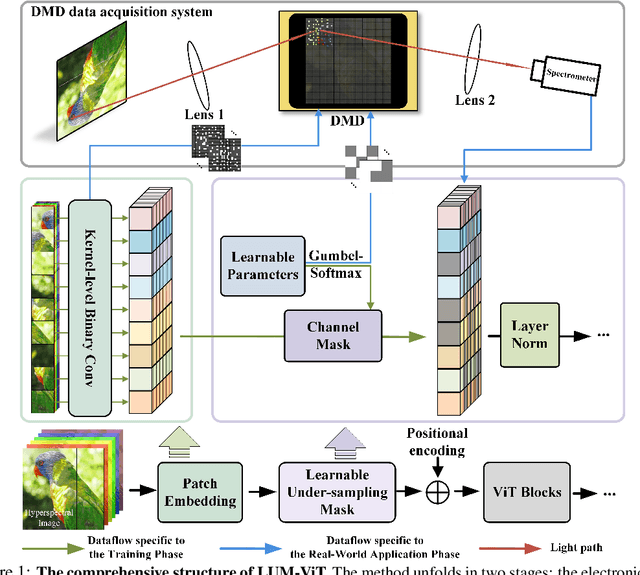

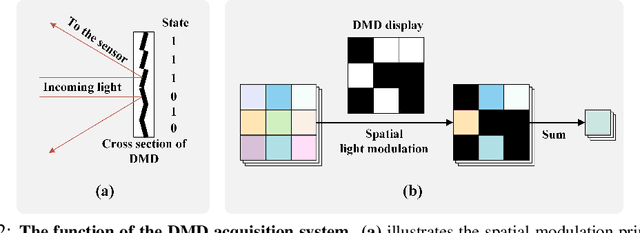
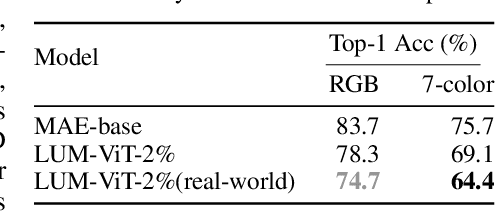
Bandwidth constraints during signal acquisition frequently impede real-time detection applications. Hyperspectral data is a notable example, whose vast volume compromises real-time hyperspectral detection. To tackle this hurdle, we introduce a novel approach leveraging pre-acquisition modulation to reduce the acquisition volume. This modulation process is governed by a deep learning model, utilizing prior information. Central to our approach is LUM-ViT, a Vision Transformer variant. Uniquely, LUM-ViT incorporates a learnable under-sampling mask tailored for pre-acquisition modulation. To further optimize for optical calculations, we propose a kernel-level weight binarization technique and a three-stage fine-tuning strategy. Our evaluations reveal that, by sampling a mere 10% of the original image pixels, LUM-ViT maintains the accuracy loss within 1.8% on the ImageNet classification task. The method sustains near-original accuracy when implemented on real-world optical hardware, demonstrating its practicality. Code will be available at https://github.com/MaxLLF/LUM-ViT.
Utilizing Local Hierarchy with Adversarial Training for Hierarchical Text Classification
Feb 29, 2024Hierarchical text classification (HTC) is a challenging subtask of multi-label classification due to its complex taxonomic structure. Nearly all recent HTC works focus on how the labels are structured but ignore the sub-structure of ground-truth labels according to each input text which contains fruitful label co-occurrence information. In this work, we introduce this local hierarchy with an adversarial framework. We propose a HiAdv framework that can fit in nearly all HTC models and optimize them with the local hierarchy as auxiliary information. We test on two typical HTC models and find that HiAdv is effective in all scenarios and is adept at dealing with complex taxonomic hierarchies. Further experiments demonstrate that the promotion of our framework indeed comes from the local hierarchy and the local hierarchy is beneficial for rare classes which have insufficient training data.
Information That Matters: Exploring Information Needs of People Affected by Algorithmic Decisions
Jan 29, 2024Explanations of AI systems rarely address the information needs of people affected by algorithmic decision-making (ADM). This gap between conveyed information and information that matters to affected stakeholders can impede understanding and adherence to regulatory frameworks such as the AI Act. To address this gap, we present the "XAI Novice Question Bank": A catalog of affected stakeholders' information needs in two ADM use cases (employment prediction and health monitoring), covering the categories data, system context, system usage, and system specifications. Information needs were gathered in an interview study where participants received explanations in response to their inquiries. Participants further reported their understanding and decision confidence, showing that while confidence tended to increase after receiving explanations, participants also met understanding challenges, such as being unable to tell why their understanding felt incomplete. Explanations further influenced participants' perceptions of the systems' risks and benefits, which they confirmed or changed depending on the use case. When risks were perceived as high, participants expressed particular interest in explanations about intention, such as why and to what end a system was put in place. With this work, we aim to support the inclusion of affected stakeholders into explainability by contributing an overview of information and challenges relevant to them when deciding on the adoption of ADM systems. We close by summarizing our findings in a list of six key implications that inform the design of future explanations for affected stakeholder audiences.
PowerSkel: A Device-Free Framework Using CSI Signal for Human Skeleton Estimation in Power Station
Mar 04, 2024
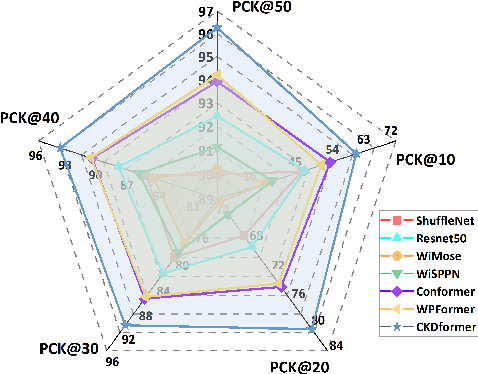
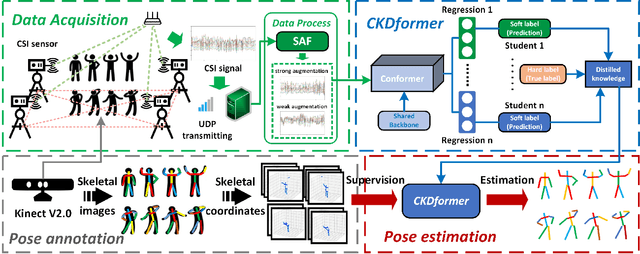
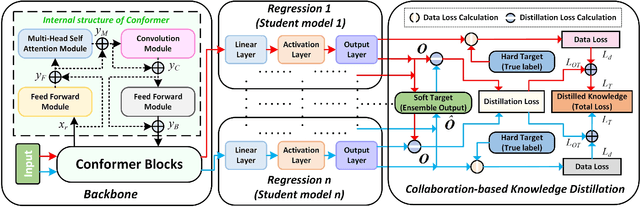
Safety monitoring of power operations in power stations is crucial for preventing accidents and ensuring stable power supply. However, conventional methods such as wearable devices and video surveillance have limitations such as high cost, dependence on light, and visual blind spots. WiFi-based human pose estimation is a suitable method for monitoring power operations due to its low cost, device-free, and robustness to various illumination conditions.In this paper, a novel Channel State Information (CSI)-based pose estimation framework, namely PowerSkel, is developed to address these challenges. PowerSkel utilizes self-developed CSI sensors to form a mutual sensing network and constructs a CSI acquisition scheme specialized for power scenarios. It significantly reduces the deployment cost and complexity compared to the existing solutions. To reduce interference with CSI in the electricity scenario, a sparse adaptive filtering algorithm is designed to preprocess the CSI. CKDformer, a knowledge distillation network based on collaborative learning and self-attention, is proposed to extract the features from CSI and establish the mapping relationship between CSI and keypoints. The experiments are conducted in a real-world power station, and the results show that the PowerSkel achieves high performance with a PCK@50 of 96.27%, and realizes a significant visualization on pose estimation, even in dark environments. Our work provides a novel low-cost and high-precision pose estimation solution for power operation.
SMAUG: A Sliding Multidimensional Task Window-Based MARL Framework for Adaptive Real-Time Subtask Recognition
Mar 04, 2024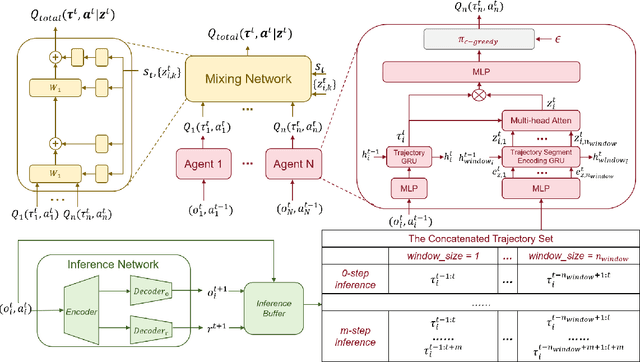
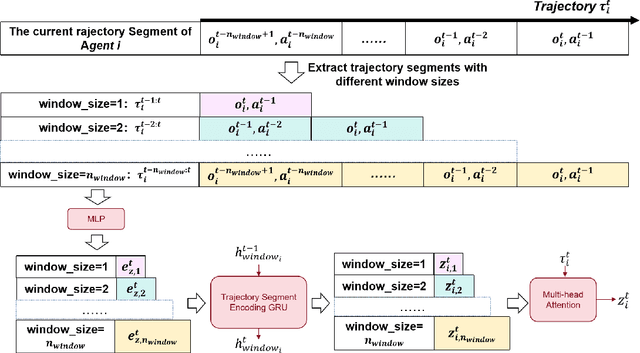
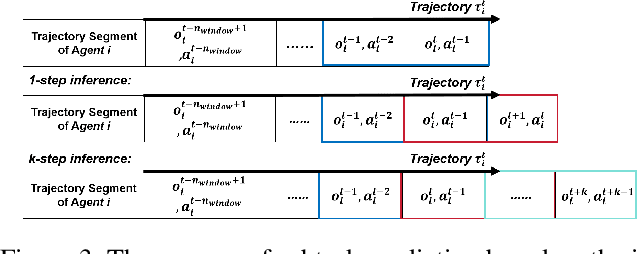
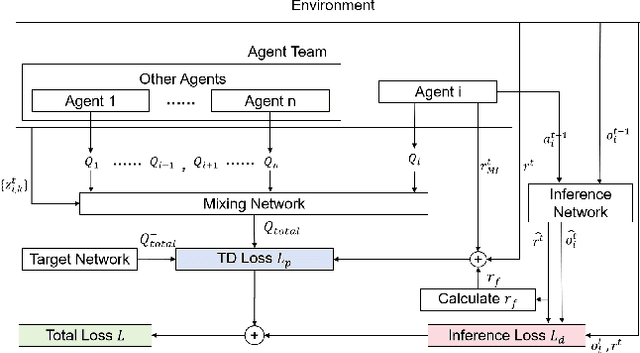
Instead of making behavioral decisions directly from the exponentially expanding joint observational-action space, subtask-based multi-agent reinforcement learning (MARL) methods enable agents to learn how to tackle different subtasks. Most existing subtask-based MARL methods are based on hierarchical reinforcement learning (HRL). However, these approaches often limit the number of subtasks, perform subtask recognition periodically, and can only identify and execute a specific subtask within the predefined fixed time period, which makes them inflexible and not suitable for diverse and dynamic scenarios with constantly changing subtasks. To break through above restrictions, a \textbf{S}liding \textbf{M}ultidimensional t\textbf{A}sk window based m\textbf{U}ti-agent reinforcement learnin\textbf{G} framework (SMAUG) is proposed for adaptive real-time subtask recognition. It leverages a sliding multidimensional task window to extract essential information of subtasks from trajectory segments concatenated based on observed and predicted trajectories in varying lengths. An inference network is designed to iteratively predict future trajectories with the subtask-oriented policy network. Furthermore, intrinsic motivation rewards are defined to promote subtask exploration and behavior diversity. SMAUG can be integrated with any Q-learning-based approach. Experiments on StarCraft II show that SMAUG not only demonstrates performance superiority in comparison with all baselines but also presents a more prominent and swift rise in rewards during the initial training stage.
Neural Network Assisted Lifting Steps For Improved Fully Scalable Lossy Image Compression in JPEG 2000
Mar 04, 2024
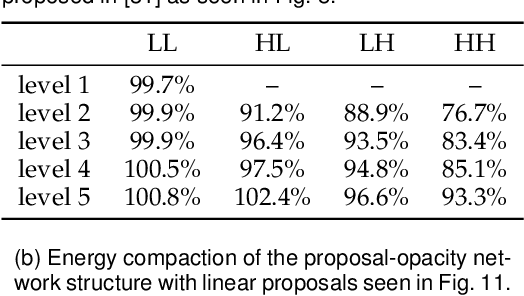
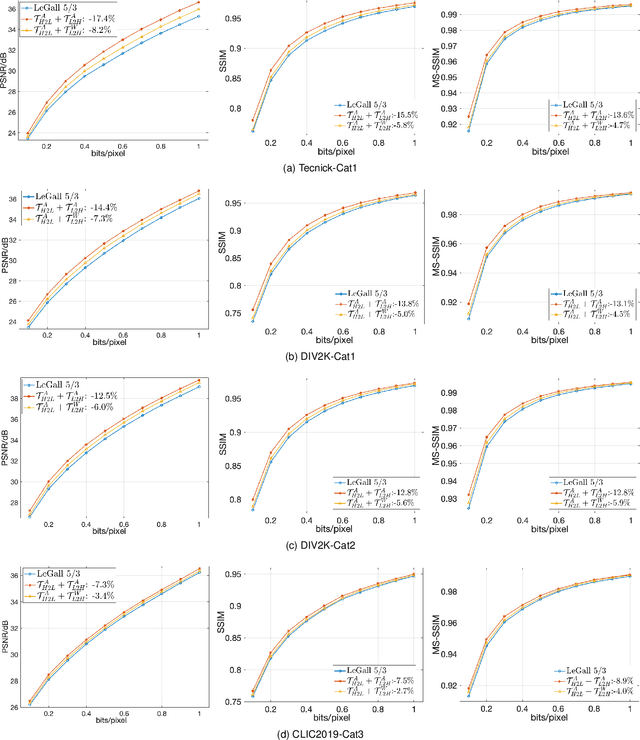
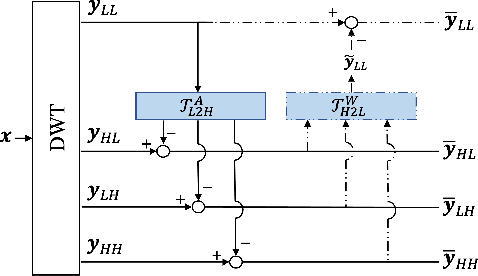
This work proposes to augment the lifting steps of the conventional wavelet transform with additional neural network assisted lifting steps. These additional steps reduce residual redundancy (notably aliasing information) amongst the wavelet subbands, and also improve the visual quality of reconstructed images at reduced resolutions. The proposed approach involves two steps, a high-to-low step followed by a low-to-high step. The high-to-low step suppresses aliasing in the low-pass band by using the detail bands at the same resolution, while the low-to-high step aims to further remove redundancy from detail bands, so as to achieve higher energy compaction. The proposed two lifting steps are trained in an end-to-end fashion; we employ a backward annealing approach to overcome the non-differentiability of the quantization and cost functions during back-propagation. Importantly, the networks employed in this paper are compact and with limited non-linearities, allowing a fully scalable system; one pair of trained network parameters are applied for all levels of decomposition and for all bit-rates of interest. By employing the proposed approach within the JPEG 2000 image coding standard, our method can achieve up to 17.4% average BD bit-rate saving over a wide range of bit-rates, while retaining quality and resolution scalability features of JPEG 2000.
Playing NetHack with LLMs: Potential & Limitations as Zero-Shot Agents
Mar 01, 2024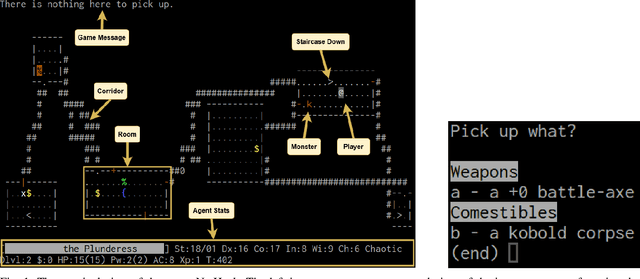
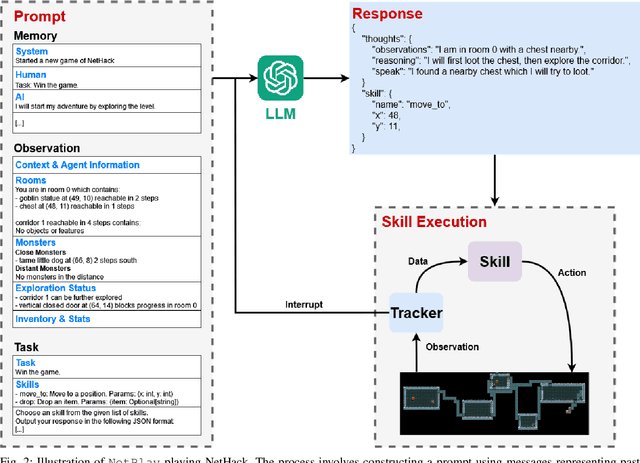


Large Language Models (LLMs) have shown great success as high-level planners for zero-shot game-playing agents. However, these agents are primarily evaluated on Minecraft, where long-term planning is relatively straightforward. In contrast, agents tested in dynamic robot environments face limitations due to simplistic environments with only a few objects and interactions. To fill this gap in the literature, we present NetPlay, the first LLM-powered zero-shot agent for the challenging roguelike NetHack. NetHack is a particularly challenging environment due to its diverse set of items and monsters, complex interactions, and many ways to die. NetPlay uses an architecture designed for dynamic robot environments, modified for NetHack. Like previous approaches, it prompts the LLM to choose from predefined skills and tracks past interactions to enhance decision-making. Given NetHack's unpredictable nature, NetPlay detects important game events to interrupt running skills, enabling it to react to unforeseen circumstances. While NetPlay demonstrates considerable flexibility and proficiency in interacting with NetHack's mechanics, it struggles with ambiguous task descriptions and a lack of explicit feedback. Our findings demonstrate that NetPlay performs best with detailed context information, indicating the necessity for dynamic methods in supplying context information for complex games such as NetHack.
Entity-Aware Multimodal Alignment Framework for News Image Captioning
Feb 29, 2024News image captioning task is a variant of image captioning task which requires model to generate a more informative caption with news image and the associated news article. Multimodal Large Language models have developed rapidly in recent years and is promising in news image captioning task. However, according to our experiments, common MLLMs are not good at generating the entities in zero-shot setting. Their abilities to deal with the entities information are still limited after simply fine-tuned on news image captioning dataset. To obtain a more powerful model to handle the multimodal entity information, we design two multimodal entity-aware alignment tasks and an alignment framework to align the model and generate the news image captions. Our method achieves better results than previous state-of-the-art models in CIDEr score (72.33 -> 86.29) on GoodNews dataset and (70.83 -> 85.61) on NYTimes800k dataset.
Greed is All You Need: An Evaluation of Tokenizer Inference Methods
Mar 02, 2024
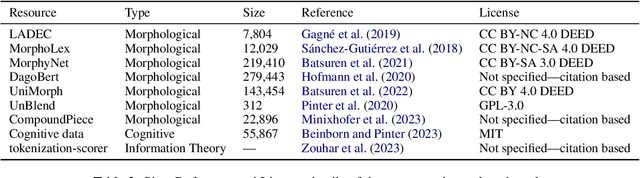
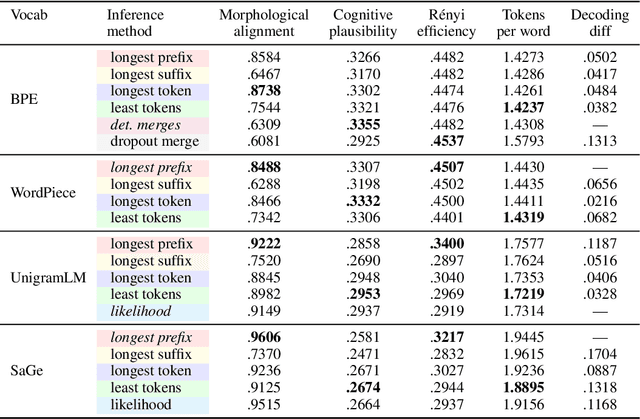
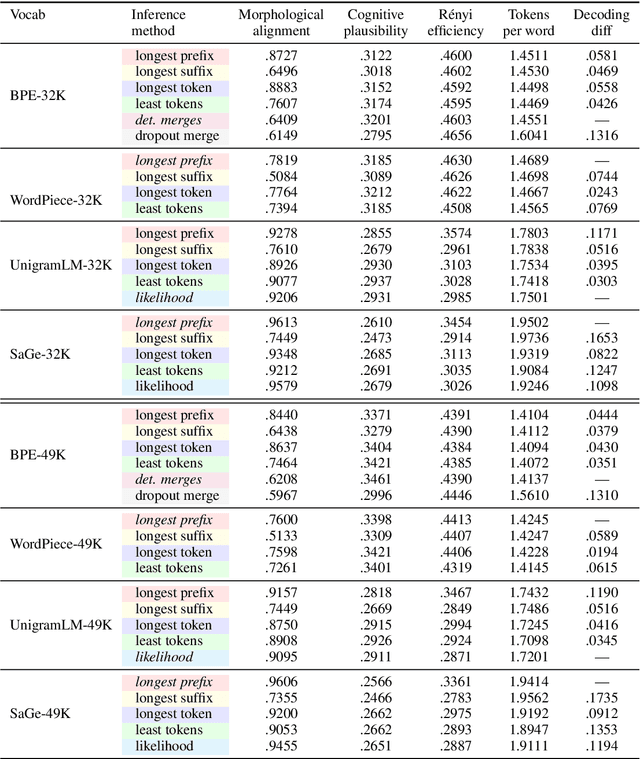
While subword tokenizers such as BPE and WordPiece are typically used to build vocabularies for NLP models, the method of decoding text into a sequence of tokens from these vocabularies is often left unspecified, or ill-suited to the method in which they were constructed. We provide a controlled analysis of seven tokenizer inference methods across four different algorithms and three vocabulary sizes, performed on a novel intrinsic evaluation suite we curated for English, combining measures rooted in morphology, cognition, and information theory. We show that for the most commonly used tokenizers, greedy inference performs surprisingly well; and that SaGe, a recently-introduced contextually-informed tokenizer, outperforms all others on morphological alignment.
NiteDR: Nighttime Image De-Raining with Cross-View Sensor Cooperative Learning for Dynamic Driving Scenes
Feb 28, 2024In real-world environments, outdoor imaging systems are often affected by disturbances such as rain degradation. Especially, in nighttime driving scenes, insufficient and uneven lighting shrouds the scenes in darkness, resulting degradation of both the image quality and visibility. Particularly, in the field of autonomous driving, the visual perception ability of RGB sensors experiences a sharp decline in such harsh scenarios. Additionally, driving assistance systems suffer from reduced capabilities in capturing and discerning the surrounding environment, posing a threat to driving safety. Single-view information captured by single-modal sensors cannot comprehensively depict the entire scene. To address these challenges, we developed an image de-raining framework tailored for rainy nighttime driving scenes. It aims to remove rain artifacts, enrich scene representation, and restore useful information. Specifically, we introduce cooperative learning between visible and infrared images captured by different sensors. By cross-view fusion of these multi-source data, the scene within the images gains richer texture details and enhanced contrast. We constructed an information cleaning module called CleanNet as the first stage of our framework. Moreover, we designed an information fusion module called FusionNet as the second stage to fuse the clean visible images with infrared images. Using this stage-by-stage learning strategy, we obtain de-rained fusion images with higher quality and better visual perception. Extensive experiments demonstrate the effectiveness of our proposed Cross-View Cooperative Learning (CVCL) in adverse driving scenarios in low-light rainy environments. The proposed approach addresses the gap in the utilization of existing rain removal algorithms in specific low-light conditions.