 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Wireless Transmission of Images With The Assistance of Multi-level Semantic Information
Feb 08, 2022
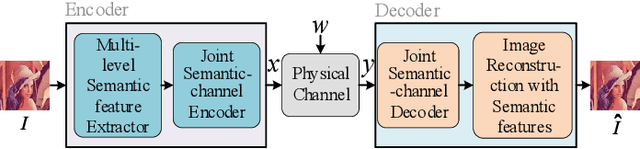
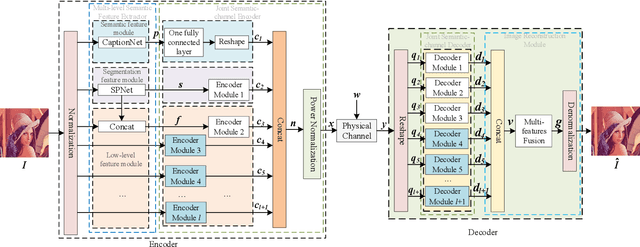
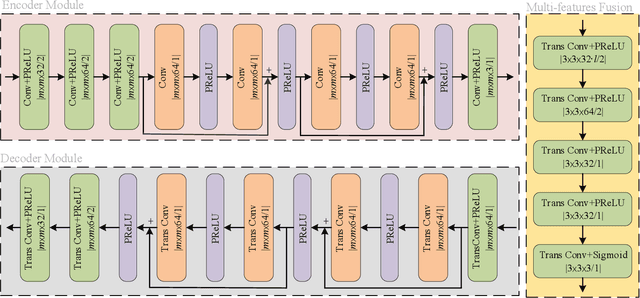
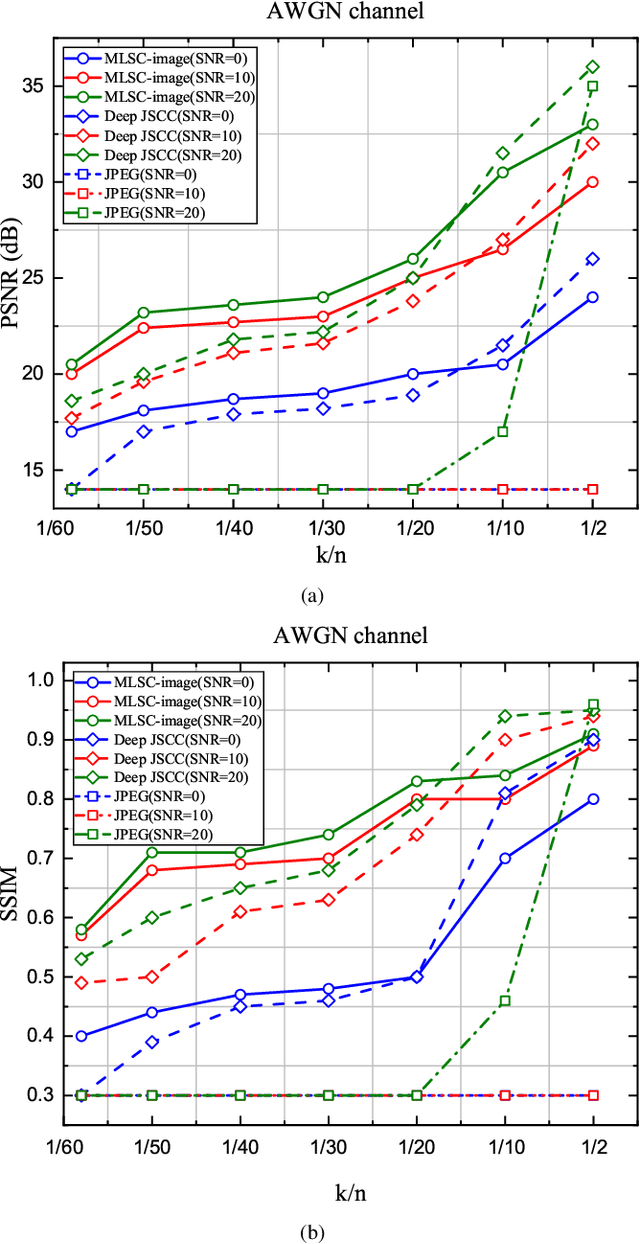
Semantic-oriented communication has been considered as a promising to boost the bandwidth efficiency by only transmitting the semantics of the data. In this paper, we propose a multi-level semantic aware communication system for wireless image transmission, named MLSC-image, which is based on the deep learning techniques and trained in an end to end manner. In particular, the proposed model includes a multilevel semantic feature extractor, that extracts both the highlevel semantic information, such as the text semantics and the segmentation semantics, and the low-level semantic information, such as local spatial details of the images. We employ a pretrained image caption to capture the text semantics and a pretrained image segmentation model to obtain the segmentation semantics. These high-level and low-level semantic features are then combined and encoded by a joint semantic and channel encoder into symbols to transmit over the physical channel. The numerical results validate the effectiveness and efficiency of the proposed semantic communication system, especially under the limited bandwidth condition, which indicates the advantages of the high-level semantics in the compression of images.
Personalization of Web Search During the 2020 US Elections
Sep 28, 2022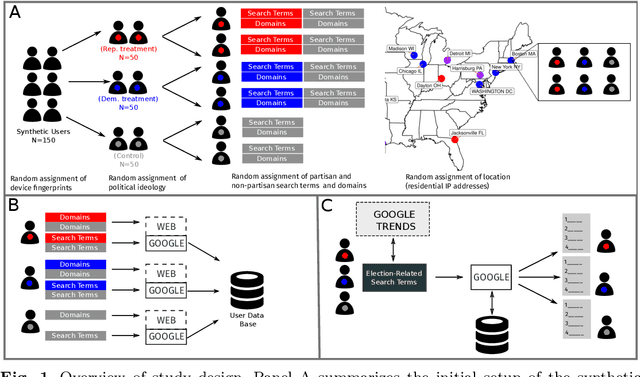
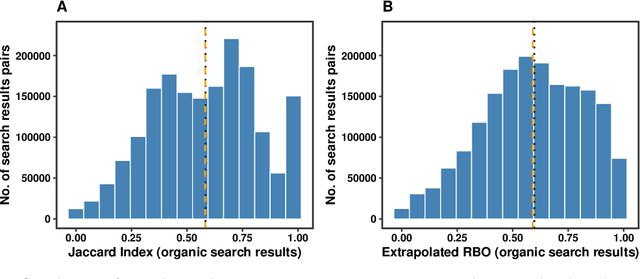
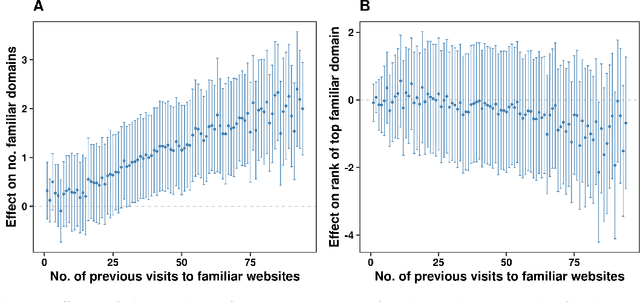
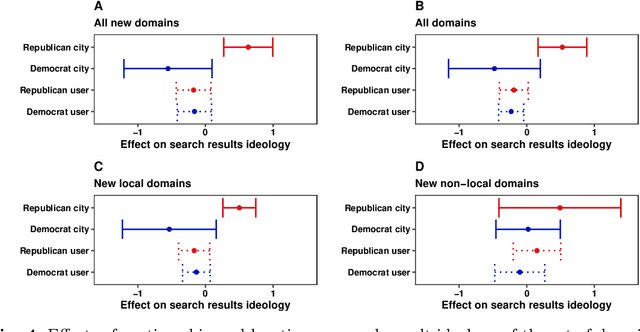
Search engines play a central role in routing political information to citizens. The algorithmic personalization of search results by large search engines like Google implies that different users may be offered systematically different information. However, measuring the causal effect of user characteristics and behavior on search results in a politically relevant context is challenging. We set up a population of 150 synthetic internet users ("bots") who are randomly located across 25 US cities and are active for several months during the 2020 US Elections and their aftermath. These users differ in their browsing preferences and political ideology, and they build up realistic browsing and search histories. We run daily experiments in which all users enter the same election-related queries. Search results to these queries differ substantially across users. Google prioritizes previously visited websites and local news sites. Yet, it does not generally prioritize websites featuring the user's ideology.
Spatio-temporal Tendency Reasoning for Human Body Pose and Shape Estimation from Videos
Oct 10, 2022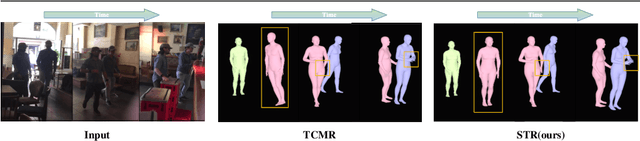
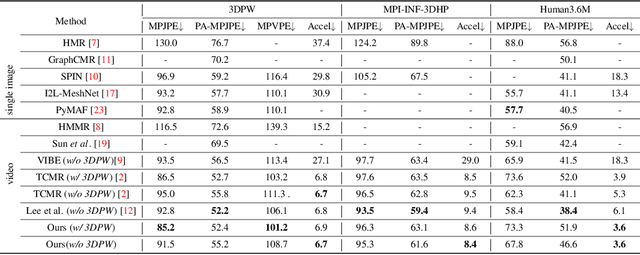
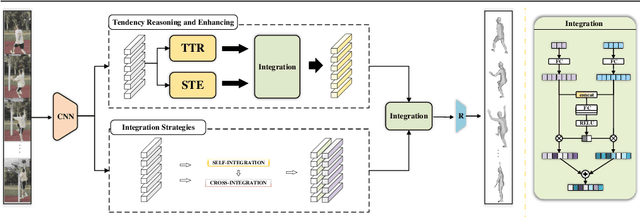
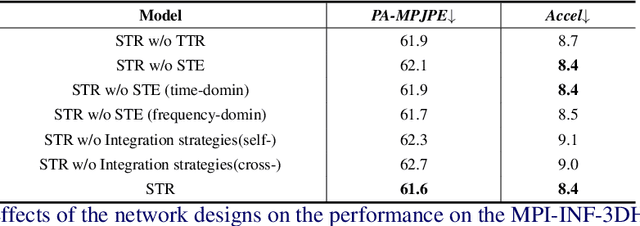
In this paper, we present a spatio-temporal tendency reasoning (STR) network for recovering human body pose and shape from videos. Previous approaches have focused on how to extend 3D human datasets and temporal-based learning to promote accuracy and temporal smoothing. Different from them, our STR aims to learn accurate and natural motion sequences in an unconstrained environment through temporal and spatial tendency and to fully excavate the spatio-temporal features of existing video data. To this end, our STR learns the representation of features in the temporal and spatial dimensions respectively, to concentrate on a more robust representation of spatio-temporal features. More specifically, for efficient temporal modeling, we first propose a temporal tendency reasoning (TTR) module. TTR constructs a time-dimensional hierarchical residual connection representation within a video sequence to effectively reason temporal sequences' tendencies and retain effective dissemination of human information. Meanwhile, for enhancing the spatial representation, we design a spatial tendency enhancing (STE) module to further learns to excite spatially time-frequency domain sensitive features in human motion information representations. Finally, we introduce integration strategies to integrate and refine the spatio-temporal feature representations. Extensive experimental findings on large-scale publically available datasets reveal that our STR remains competitive with the state-of-the-art on three datasets. Our code are available at https://github.com/Changboyang/STR.git.
Reducing Information Bottleneck for Weakly Supervised Semantic Segmentation
Oct 13, 2021
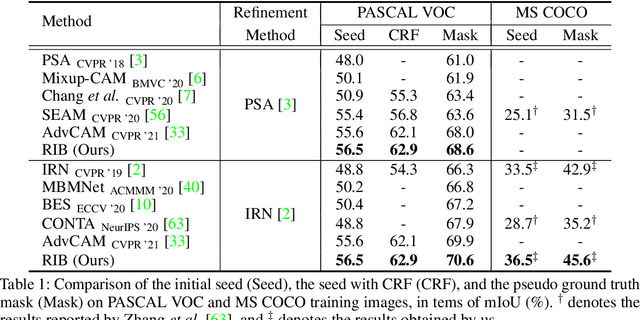
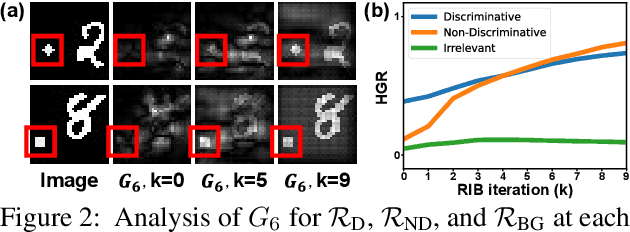
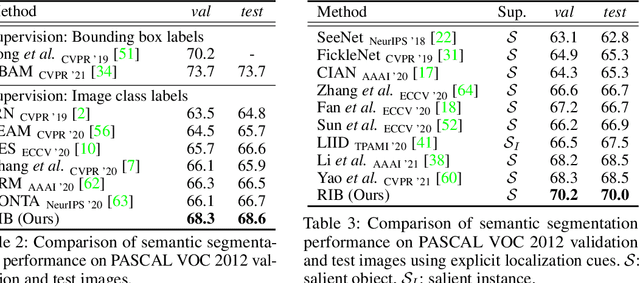
Weakly supervised semantic segmentation produces pixel-level localization from class labels; however, a classifier trained on such labels is likely to focus on a small discriminative region of the target object. We interpret this phenomenon using the information bottleneck principle: the final layer of a deep neural network, activated by the sigmoid or softmax activation functions, causes an information bottleneck, and as a result, only a subset of the task-relevant information is passed on to the output. We first support this argument through a simulated toy experiment and then propose a method to reduce the information bottleneck by removing the last activation function. In addition, we introduce a new pooling method that further encourages the transmission of information from non-discriminative regions to the classification. Our experimental evaluations demonstrate that this simple modification significantly improves the quality of localization maps on both the PASCAL VOC 2012 and MS COCO 2014 datasets, exhibiting a new state-of-the-art performance for weakly supervised semantic segmentation. The code is available at: https://github.com/jbeomlee93/RIB.
Soil moisture estimation from Sentinel-1 interferometric observations over arid regions
Oct 18, 2022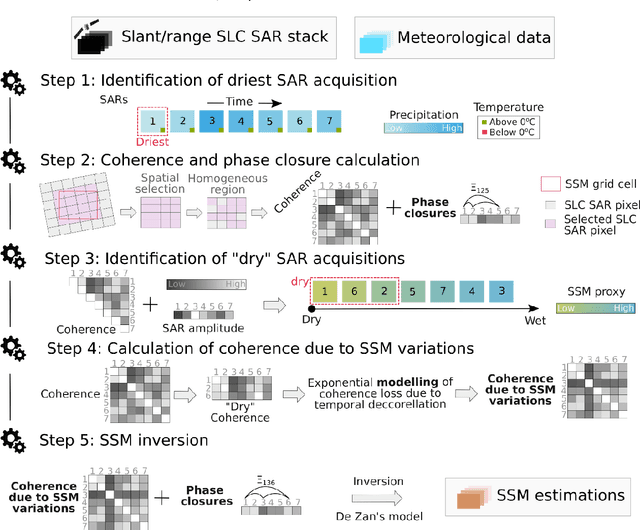
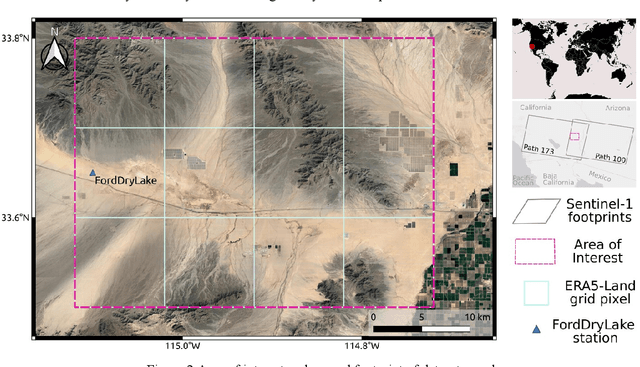
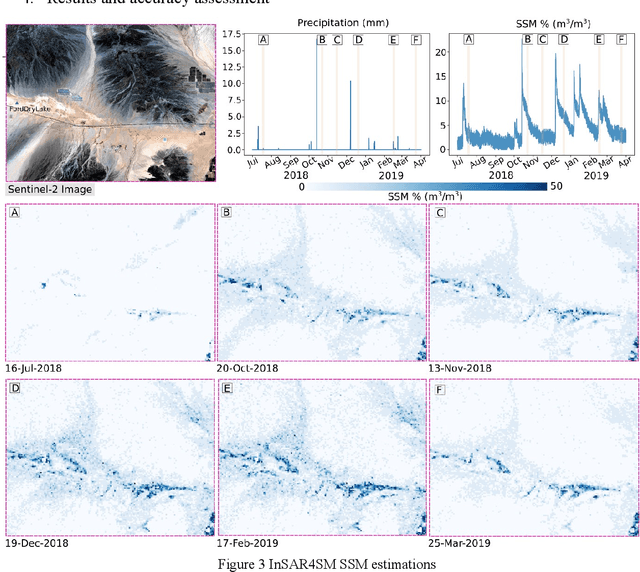
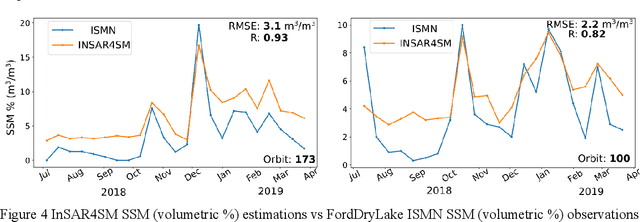
We present a methodology based on interferometric synthetic aperture radar (InSAR) time series analysis that can provide surface (top 5 cm) soil moisture (SSM) estimations. The InSAR time series analysis consists of five processing steps. A co-registered Single Look Complex (SLC) SAR stack as well as meteorological information are required as input of the proposed workflow. In the first step, ice/snow-free and zero-precipitation SAR images are identified using meteorological data. In the second step, construction and phase extraction of distributed scatterers (DSs) (over bare land) is performed. In the third step, for each DS the ordering of surface soil moisture (SSM) levels of SAR acquisitions based on interferometric coherence is calculated. In the fourth step, for each DS the coherence due to SSM variations is calculated. In the fifth step, SSM is estimated by a constrained inversion of an analytical interferometric model using coherence and phase closure information. The implementation of the proposed approach is provided as an open-source software toolbox (INSAR4SM) available at www.github.com/kleok/INSAR4SM. A case study over an arid region in California/Arizona is presented. The proposed workflow was applied in Sentinel- 1 (C-band) VV-polarized InSAR observations. The estimated SSM results were assessed with independent SSM observations from a station of the International Soil Moisture Network (ISMN) (RMSE: 0.027 $m^3/m^3$ R: 0.88) and ERA5-Land reanalysis model data (RMSE: 0.035 $m^3/m^3$ R: 0.71). The proposed methodology was able to provide accurate SSM estimations at high spatial resolution (~250 m). A discussion of the benefits and the limitations of the proposed methodology highlighted the potential of interferometric observables for SSM estimation over arid regions.
Probing Linguistic Information For Logical Inference In Pre-trained Language Models
Dec 03, 2021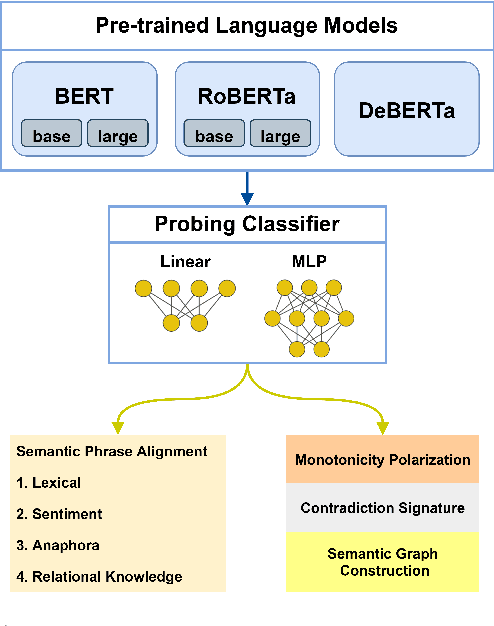
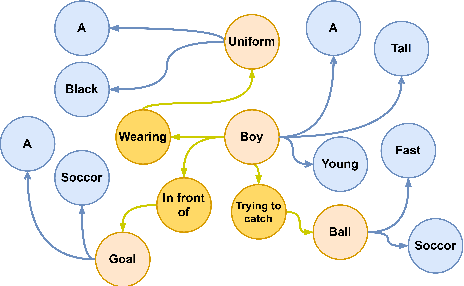

Progress in pre-trained language models has led to a surge of impressive results on downstream tasks for natural language understanding. Recent work on probing pre-trained language models uncovered a wide range of linguistic properties encoded in their contextualized representations. However, it is unclear whether they encode semantic knowledge that is crucial to symbolic inference methods. We propose a methodology for probing linguistic information for logical inference in pre-trained language model representations. Our probing datasets cover a list of linguistic phenomena required by major symbolic inference systems. We find that (i) pre-trained language models do encode several types of linguistic information for inference, but there are also some types of information that are weakly encoded, (ii) language models can effectively learn missing linguistic information through fine-tuning. Overall, our findings provide insights into which aspects of linguistic information for logical inference do language models and their pre-training procedures capture. Moreover, we have demonstrated language models' potential as semantic and background knowledge bases for supporting symbolic inference methods.
MFFN: Multi-view Feature Fusion Network for Camouflaged Object Detection
Oct 12, 2022
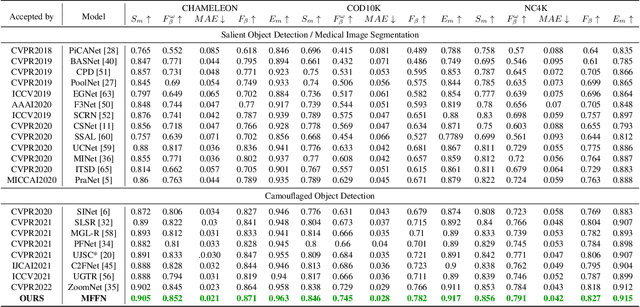
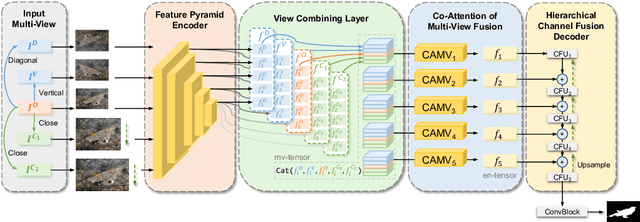

Recent research about camouflaged object detection (COD) aims to segment highly concealed objects hidden in complex surroundings. The tiny, fuzzy camouflaged objects result in visually indistinguishable properties. However, current single-view COD detectors are sensitive to background distractors. Therefore, blurred boundaries and variable shapes of the camouflaged objects are challenging to be fully captured with a single-view detector. To overcome these obstacles, we propose a behavior-inspired framework, called Multi-view Feature Fusion Network (MFFN), which mimics the human behaviors of finding indistinct objects in images, i.e., observing from multiple angles, distances, perspectives. Specifically, the key idea behind it is to generate multiple ways of observation (multi-view) by data augmentation and apply them as inputs. MFFN captures critical edge and semantic information by comparing and fusing extracted multi-view features. In addition, our MFFN exploits the dependence and interaction between views by the designed hierarchical view and channel integration modules. Furthermore, our methods leverage the complementary information between different views through a two-stage attention module called Co-attention of Multi-view (CAMV). And we designed a local-overall module called Channel Fusion Unit (CFU) to explore the channel-wise contextual clues of diverse feature maps in an iterative manner. The experiment results show that our method performs favorably against existing state-of-the-art methods via training with the same data. The code will be available at https: //github.com/dwardzheng/MFFN_COD.
Grounding Scene Graphs on Natural Images via Visio-Lingual Message Passing
Nov 03, 2022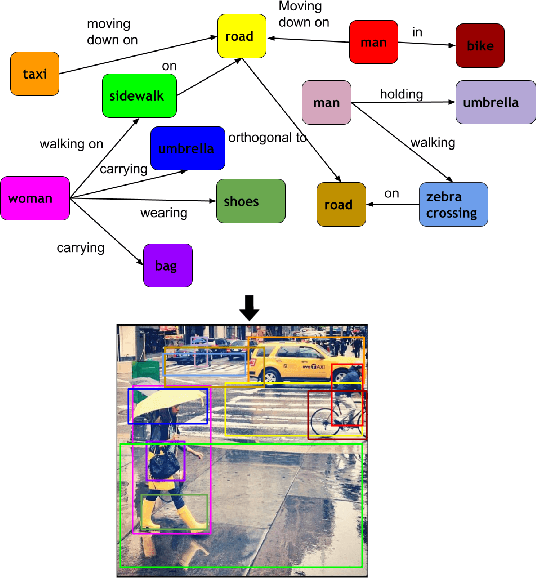
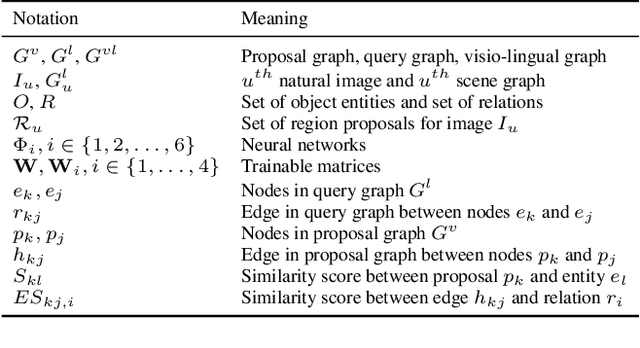
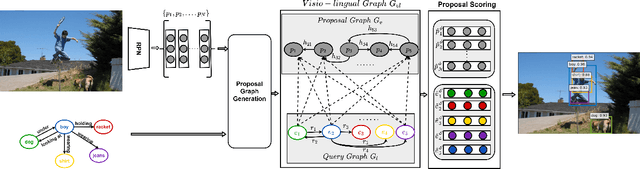
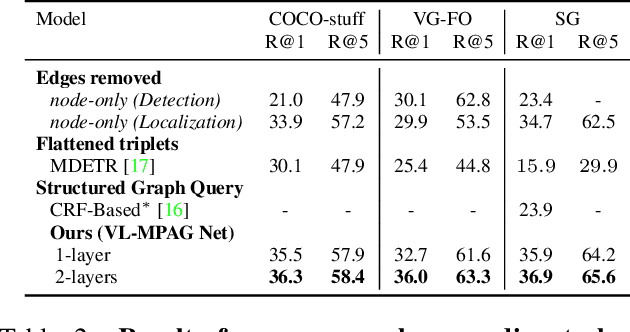
This paper presents a framework for jointly grounding objects that follow certain semantic relationship constraints given in a scene graph. A typical natural scene contains several objects, often exhibiting visual relationships of varied complexities between them. These inter-object relationships provide strong contextual cues toward improving grounding performance compared to a traditional object query-only-based localization task. A scene graph is an efficient and structured way to represent all the objects and their semantic relationships in the image. In an attempt towards bridging these two modalities representing scenes and utilizing contextual information for improving object localization, we rigorously study the problem of grounding scene graphs on natural images. To this end, we propose a novel graph neural network-based approach referred to as Visio-Lingual Message PAssing Graph Neural Network (VL-MPAG Net). In VL-MPAG Net, we first construct a directed graph with object proposals as nodes and an edge between a pair of nodes representing a plausible relation between them. Then a three-step inter-graph and intra-graph message passing is performed to learn the context-dependent representation of the proposals and query objects. These object representations are used to score the proposals to generate object localization. The proposed method significantly outperforms the baselines on four public datasets.
Could Giant Pretrained Image Models Extract Universal Representations?
Nov 03, 2022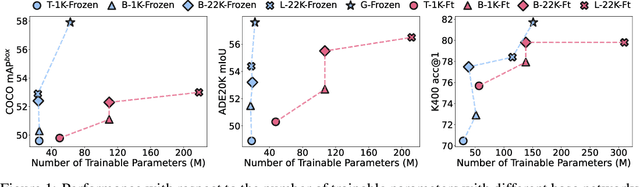
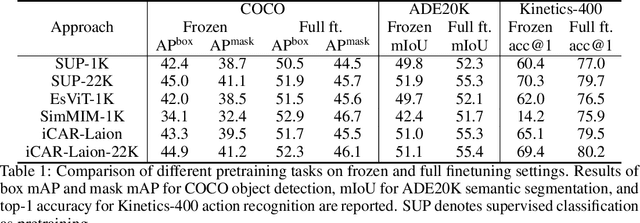
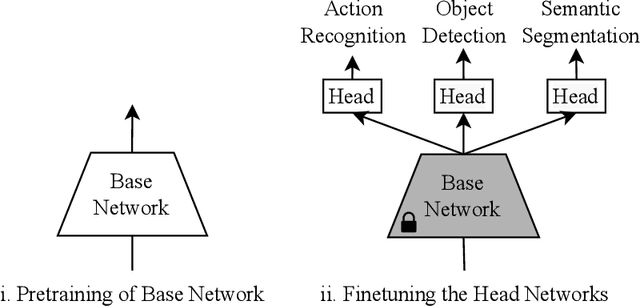
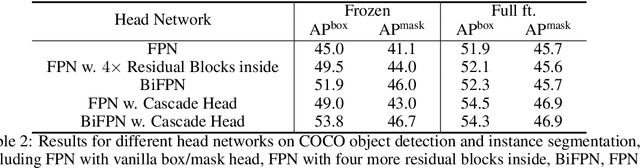
Frozen pretrained models have become a viable alternative to the pretraining-then-finetuning paradigm for transfer learning. However, with frozen models there are relatively few parameters available for adapting to downstream tasks, which is problematic in computer vision where tasks vary significantly in input/output format and the type of information that is of value. In this paper, we present a study of frozen pretrained models when applied to diverse and representative computer vision tasks, including object detection, semantic segmentation and video action recognition. From this empirical analysis, our work answers the questions of what pretraining task fits best with this frozen setting, how to make the frozen setting more flexible to various downstream tasks, and the effect of larger model sizes. We additionally examine the upper bound of performance using a giant frozen pretrained model with 3 billion parameters (SwinV2-G) and find that it reaches competitive performance on a varied set of major benchmarks with only one shared frozen base network: 60.0 box mAP and 52.2 mask mAP on COCO object detection test-dev, 57.6 val mIoU on ADE20K semantic segmentation, and 81.7 top-1 accuracy on Kinetics-400 action recognition. With this work, we hope to bring greater attention to this promising path of freezing pretrained image models.
Enhancing Patent Retrieval using Text and Knowledge Graph Embeddings: A Technical Note
Nov 03, 2022
Patent retrieval influences several applications within engineering design research, education, and practice as well as applications that concern innovation, intellectual property, and knowledge management etc. In this article, we propose a method to retrieve patents relevant to an initial set of patents, by synthesizing state-of-the-art techniques among natural language processing and knowledge graph embedding. Our method involves a patent embedding that captures text, citation, and inventor information, which individually represent different facets of knowledge communicated through a patent document. We obtain text embeddings using Sentence-BERT applied to titles and abstracts. We obtain citation and inventor embeddings through TransE that is trained using the corresponding knowledge graphs. We identify using a classification task that the concatenation of text, citation, and inventor embeddings offers a plausible representation of a patent. While the proposed patent embedding could be used to associate a pair of patents, we observe using a recall task that multiple initial patents could be associated with a target patent using mean cosine similarity, which could then be utilized to rank all target patents and retrieve the most relevant ones. We apply the proposed patent retrieval method to a set of patents corresponding to a product family and an inventor's portfolio.