 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CycleFlow: Purify Information Factors by Cycle Loss
Oct 20, 2021
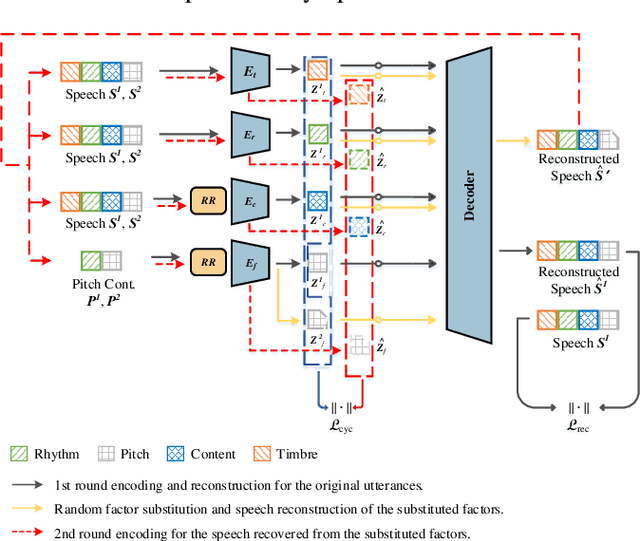
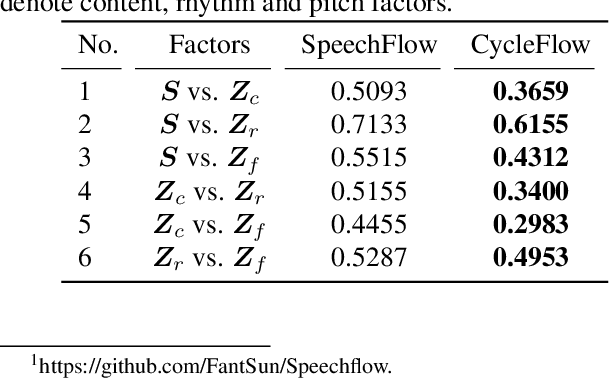
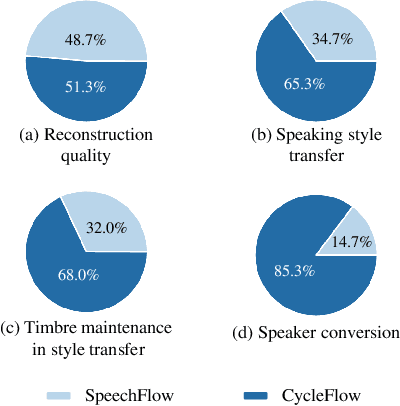
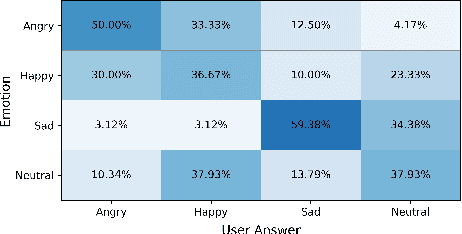
SpeechFlow is a powerful factorization model based on information bottleneck (IB), and its effectiveness has been reported by several studies. A potential problem of SpeechFlow, however, is that if the IB channels are not well designed, the resultant factors cannot be well disentangled. In this study, we propose a CycleFlow model that combines random factor substitution and cycle loss to solve this problem. Experiments on voice conversion tasks demonstrate that this simple technique can effectively reduce mutual information among individual factors, and produce clearly better conversion than the IB-based SpeechFlow. CycleFlow can also be used as a powerful tool for speech editing. We demonstrate this usage by an emotion perception experiment.
Seismic-phase detection using multiple deep learning models for global and local representations of waveforms
Nov 04, 2022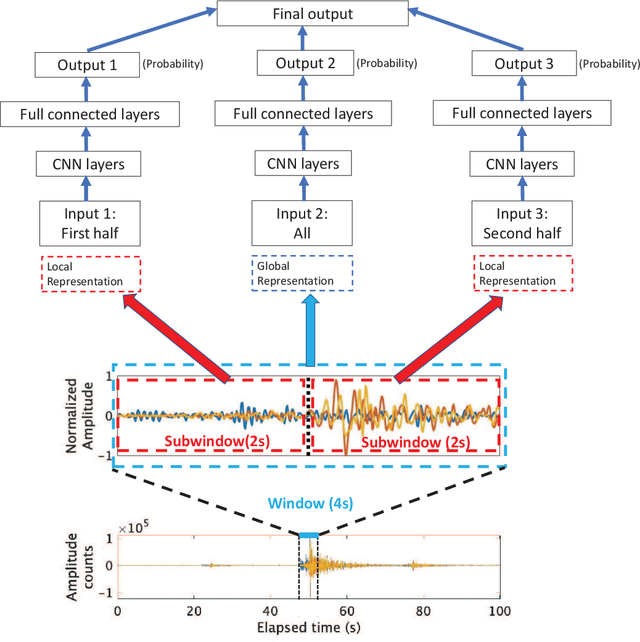
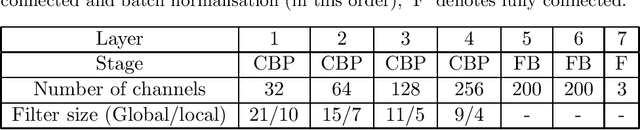
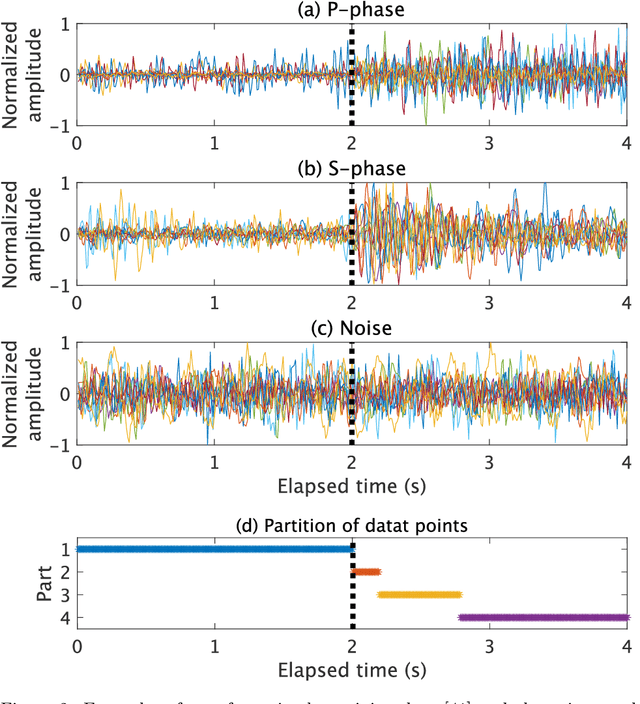
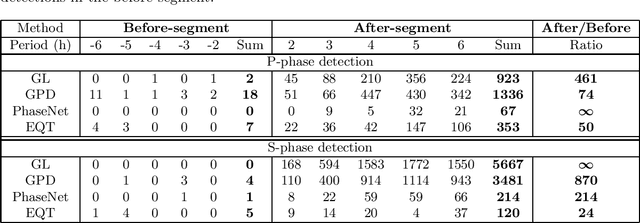
The detection of earthquakes is a fundamental prerequisite for seismology and contributes to various research areas, such as forecasting earthquakes and understanding the crust/mantle structure. Recent advances in machine learning technologies have enabled the automatic detection of earthquakes from waveform data. In particular, various state-of-the-art deep-learning methods have been applied to this endeavour. In this study, we proposed and tested a novel phase detection method employing deep learning, which is based on a standard convolutional neural network in a new framework. The novelty of the proposed method is its separate explicit learning strategy for global and local representations of waveforms, which enhances its robustness and flexibility. Prior to modelling the proposed method, we identified local representations of the waveform by the multiple clustering of waveforms, in which the data points were optimally partitioned. Based on this result, we considered a global representation and two local representations of the waveform. Subsequently, different phase detection models were trained for each global and local representation. For a new waveform, the overall phase probability was evaluated as a product of the phase probabilities of each model. This additional information on local representations makes the proposed method robust to noise, which is demonstrated by its application to the test data. Furthermore, an application to seismic swarm data demonstrated the robust performance of the proposed method compared with those of other deep learning methods. Finally, in an application to low-frequency earthquakes, we demonstrated the flexibility of the proposed method, which is readily adaptable for the detection of low-frequency earthquakes by retraining only a local model.
Toward 3D Spatial Reasoning for Human-like Text-based Visual Question Answering
Sep 21, 2022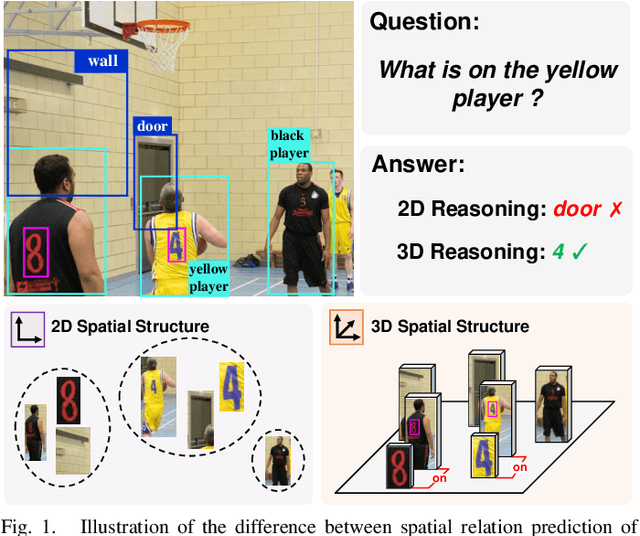
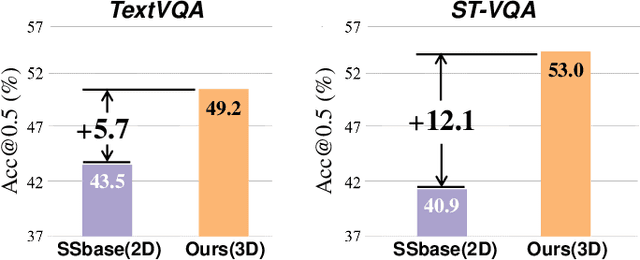
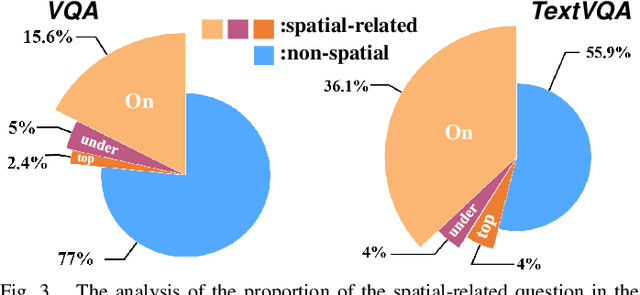
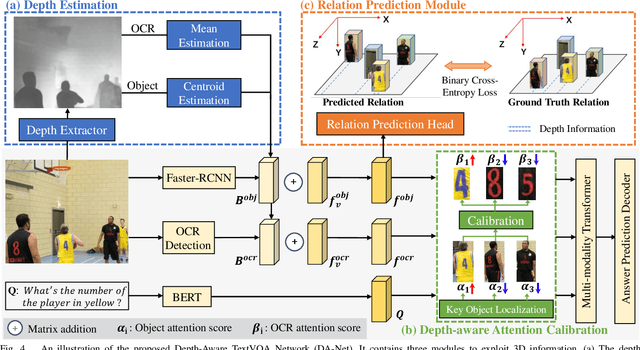
Text-based Visual Question Answering~(TextVQA) aims to produce correct answers for given questions about the images with multiple scene texts. In most cases, the texts naturally attach to the surface of the objects. Therefore, spatial reasoning between texts and objects is crucial in TextVQA. However, existing approaches are constrained within 2D spatial information learned from the input images and rely on transformer-based architectures to reason implicitly during the fusion process. Under this setting, these 2D spatial reasoning approaches cannot distinguish the fine-grain spatial relations between visual objects and scene texts on the same image plane, thereby impairing the interpretability and performance of TextVQA models. In this paper, we introduce 3D geometric information into a human-like spatial reasoning process to capture the contextual knowledge of key objects step-by-step. %we formulate a human-like spatial reasoning process by introducing 3D geometric information for capturing key objects' contextual knowledge. To enhance the model's understanding of 3D spatial relationships, Specifically, (i)~we propose a relation prediction module for accurately locating the region of interest of critical objects; (ii)~we design a depth-aware attention calibration module for calibrating the OCR tokens' attention according to critical objects. Extensive experiments show that our method achieves state-of-the-art performance on TextVQA and ST-VQA datasets. More encouragingly, our model surpasses others by clear margins of 5.7\% and 12.1\% on questions that involve spatial reasoning in TextVQA and ST-VQA valid split. Besides, we also verify the generalizability of our model on the text-based image captioning task.
Incorporating Context into Subword Vocabularies
Oct 13, 2022
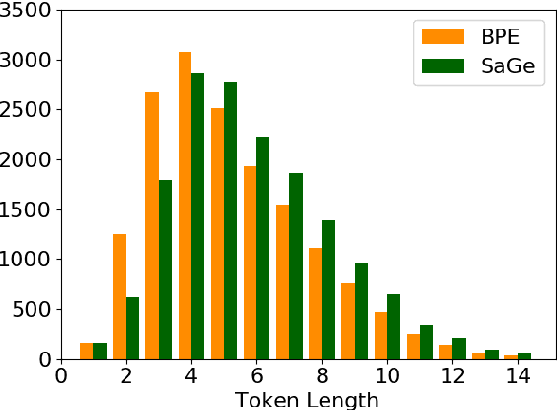

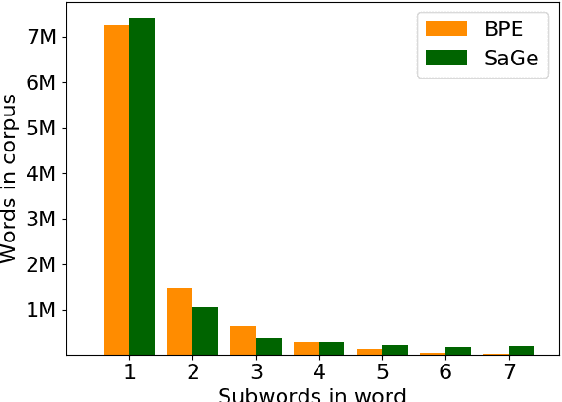
Most current popular subword tokenizers are trained based on word frequency statistics over a corpus, without considering information about co-occurrence or context. Nevertheless, the resulting vocabularies are used in language models' highly contextualized settings. We present SaGe, a tokenizer that tailors subwords for their downstream use by baking in the contextualized signal at the vocabulary creation phase. We show that SaGe does a better job than current widespread tokenizers in keeping token contexts cohesive, while not incurring a large price in terms of encoding efficiency or domain robustness. SaGe improves performance on English GLUE classification tasks as well as on NER, and on Inference and NER in Turkish, demonstrating its robustness to language properties such as morphological exponence and agglutination.
Behavior Cloned Transformers are Neurosymbolic Reasoners
Oct 13, 2022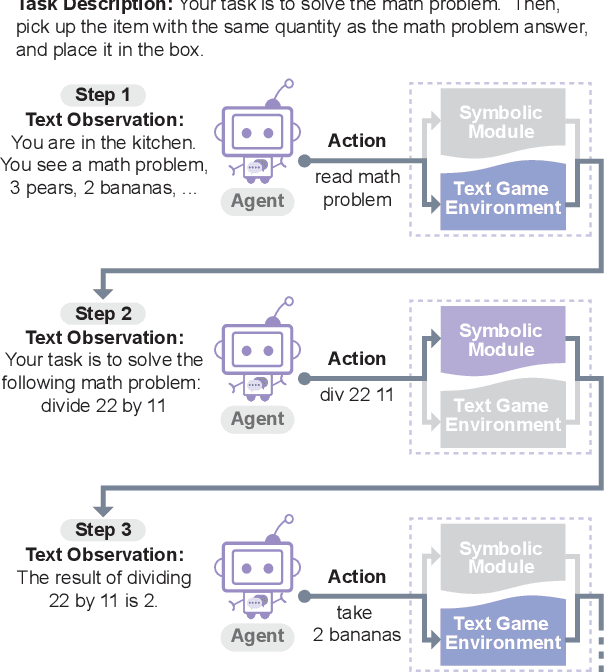

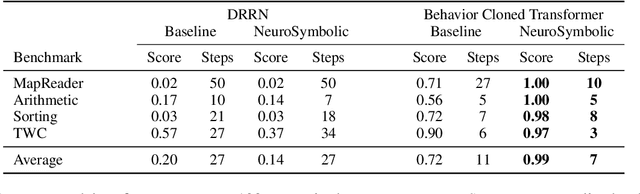
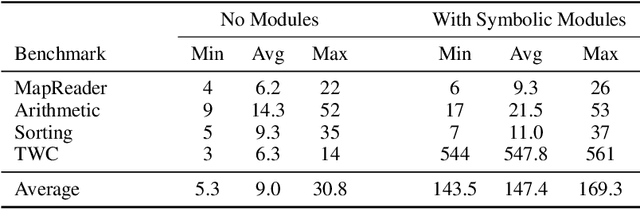
In this work, we explore techniques for augmenting interactive agents with information from symbolic modules, much like humans use tools like calculators and GPS systems to assist with arithmetic and navigation. We test our agent's abilities in text games -- challenging benchmarks for evaluating the multi-step reasoning abilities of game agents in grounded, language-based environments. Our experimental study indicates that injecting the actions from these symbolic modules into the action space of a behavior cloned transformer agent increases performance on four text game benchmarks that test arithmetic, navigation, sorting, and common sense reasoning by an average of 22%, allowing an agent to reach the highest possible performance on unseen games. This action injection technique is easily extended to new agents, environments, and symbolic modules.
Invertible Rescaling Network and Its Extensions
Oct 09, 2022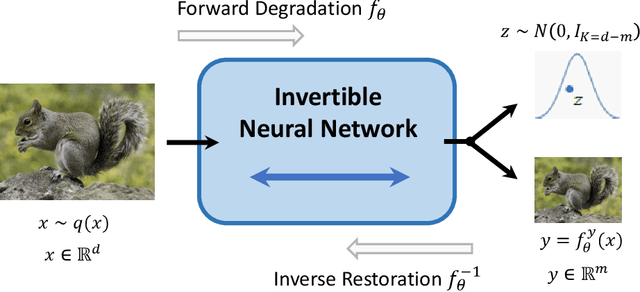
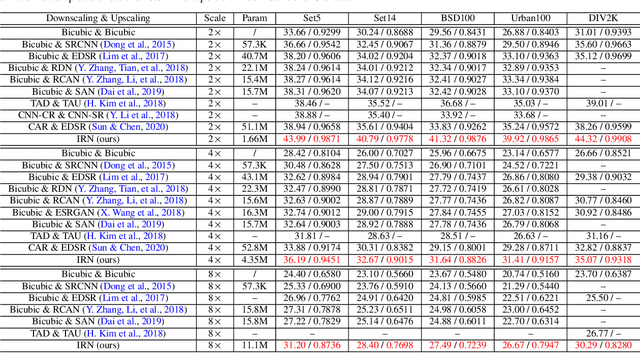
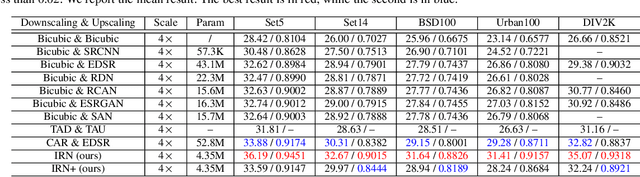
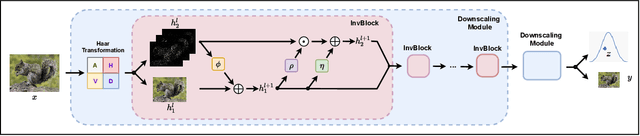
Image rescaling is a commonly used bidirectional operation, which first downscales high-resolution images to fit various display screens or to be storage- and bandwidth-friendly, and afterward upscales the corresponding low-resolution images to recover the original resolution or the details in the zoom-in images. However, the non-injective downscaling mapping discards high-frequency contents, leading to the ill-posed problem for the inverse restoration task. This can be abstracted as a general image degradation-restoration problem with information loss. In this work, we propose a novel invertible framework to handle this general problem, which models the bidirectional degradation and restoration from a new perspective, i.e. invertible bijective transformation. The invertibility enables the framework to model the information loss of pre-degradation in the form of distribution, which could mitigate the ill-posed problem during post-restoration. To be specific, we develop invertible models to generate valid degraded images and meanwhile transform the distribution of lost contents to the fixed distribution of a latent variable during the forward degradation. Then restoration is made tractable by applying the inverse transformation on the generated degraded image together with a randomly-drawn latent variable. We start from image rescaling and instantiate the model as Invertible Rescaling Network (IRN), which can be easily extended to the similar decolorization-colorization task. We further propose to combine the invertible framework with existing degradation methods such as image compression for wider applications. Experimental results demonstrate the significant improvement of our model over existing methods in terms of both quantitative and qualitative evaluations of upscaling and colorizing reconstruction from downscaled and decolorized images, and rate-distortion of image compression.
2T-UNET: A Two-Tower UNet with Depth Clues for Robust Stereo Depth Estimation
Oct 27, 2022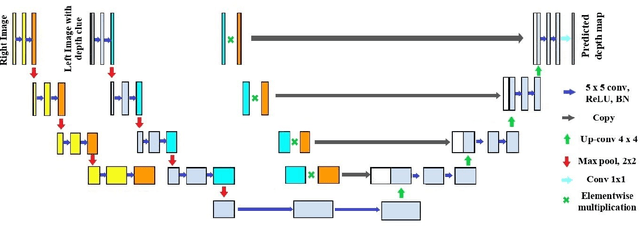
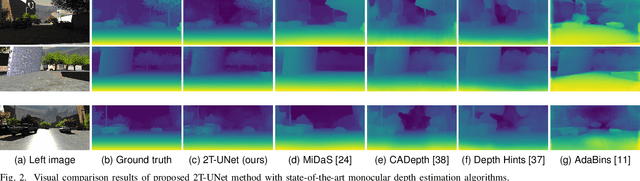
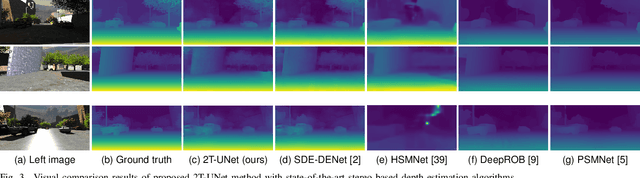

Stereo correspondence matching is an essential part of the multi-step stereo depth estimation process. This paper revisits the depth estimation problem, avoiding the explicit stereo matching step using a simple two-tower convolutional neural network. The proposed algorithm is entitled as 2T-UNet. The idea behind 2T-UNet is to replace cost volume construction with twin convolution towers. These towers have an allowance for different weights between them. Additionally, the input for twin encoders in 2T-UNet are different compared to the existing stereo methods. Generally, a stereo network takes a right and left image pair as input to determine the scene geometry. However, in the 2T-UNet model, the right stereo image is taken as one input and the left stereo image along with its monocular depth clue information, is taken as the other input. Depth clues provide complementary suggestions that help enhance the quality of predicted scene geometry. The 2T-UNet surpasses state-of-the-art monocular and stereo depth estimation methods on the challenging Scene flow dataset, both quantitatively and qualitatively. The architecture performs incredibly well on complex natural scenes, highlighting its usefulness for various real-time applications. Pretrained weights and code will be made readily available.
Modeling Inter-Dependence Between Time and Mark in Multivariate Temporal Point Processes
Oct 27, 2022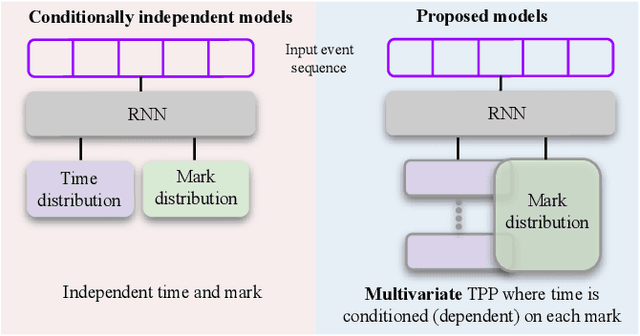

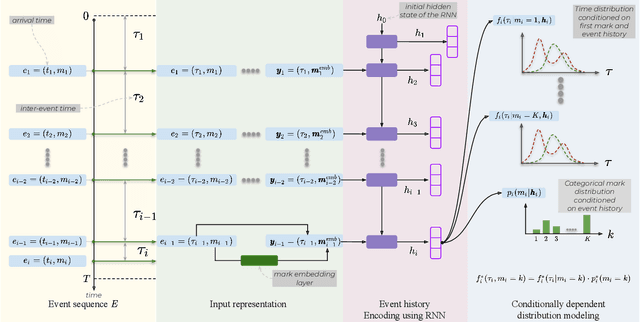
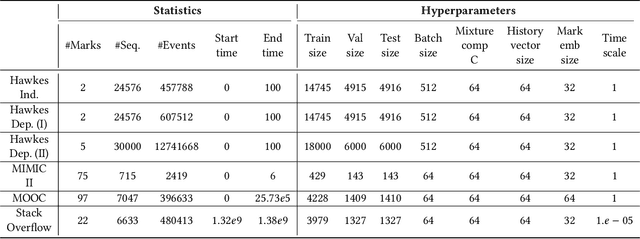
Temporal Point Processes (TPP) are probabilistic generative frameworks. They model discrete event sequences localized in continuous time. Generally, real-life events reveal descriptive information, known as marks. Marked TPPs model time and marks of the event together for practical relevance. Conditioned on past events, marked TPPs aim to learn the joint distribution of the time and the mark of the next event. For simplicity, conditionally independent TPP models assume time and marks are independent given event history. They factorize the conditional joint distribution of time and mark into the product of individual conditional distributions. This structural limitation in the design of TPP models hurt the predictive performance on entangled time and mark interactions. In this work, we model the conditional inter-dependence of time and mark to overcome the limitations of conditionally independent models. We construct a multivariate TPP conditioning the time distribution on the current event mark in addition to past events. Besides the conventional intensity-based models for conditional joint distribution, we also draw on flexible intensity-free TPP models from the literature. The proposed TPP models outperform conditionally independent and dependent models in standard prediction tasks. Our experimentation on various datasets with multiple evaluation metrics highlights the merit of the proposed approach.
Properties of Reddit News Topical Interactions
Sep 16, 2022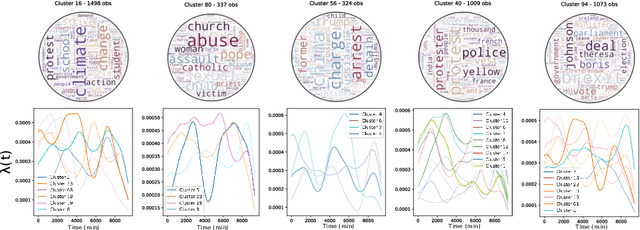
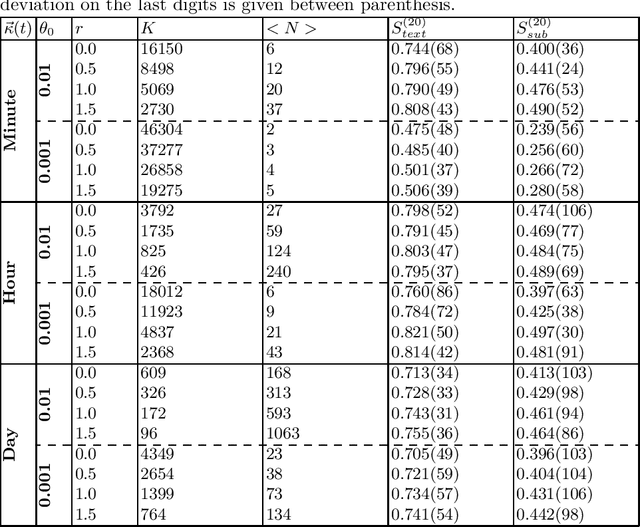
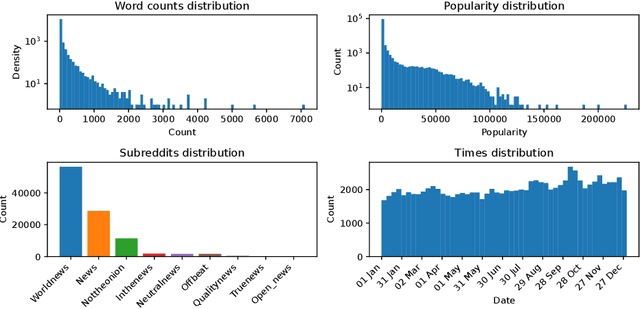
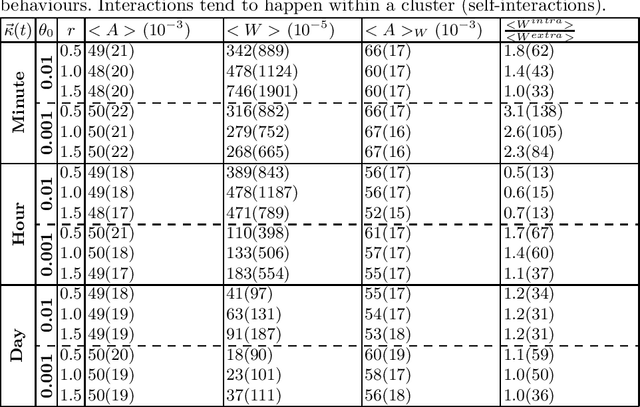
Most models of information diffusion online rely on the assumption that pieces of information spread independently from each other. However, several works pointed out the necessity of investigating the role of interactions in real-world processes, and highlighted possible difficulties in doing so: interactions are sparse and brief. As an answer, recent advances developed models to account for interactions in underlying publication dynamics. In this article, we propose to extend and apply one such model to determine whether interactions between news headlines on Reddit play a significant role in their underlying publication mechanisms. After conducting an in-depth case study on 100,000 news headline from 2019, we retrieve state-of-the-art conclusions about interactions and conclude that they play a minor role in this dataset.
* Published at the conference Complex Networks and their Applications
Habitat-Matterport 3D Semantics Dataset
Oct 11, 2022
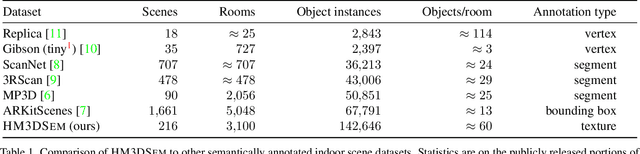

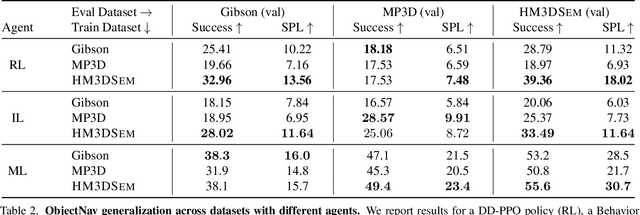
We present the Habitat-Matterport 3D Semantics (HM3DSEM) dataset. HM3DSEM is the largest dataset of 3D real-world spaces with densely annotated semantics that is currently available to the academic community. It consists of 142,646 object instance annotations across 216 3D spaces and 3,100 rooms within those spaces. The scale, quality, and diversity of object annotations far exceed those of datasets from prior work. A key difference setting apart HM3DSEM from other datasets is the use of texture information to annotate pixel-accurate object boundaries. We demonstrate the effectiveness of HM3DSEM dataset for the Object Goal Navigation task using different methods. Policies trained using HM3DSEM perform comparable or better than those trained on prior datasets.