 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Sar Ship Detection based on Swin Transformer and Feature Enhancement Feature Pyramid Network
Sep 21, 2022
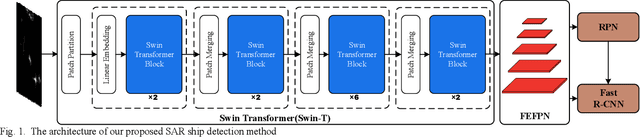

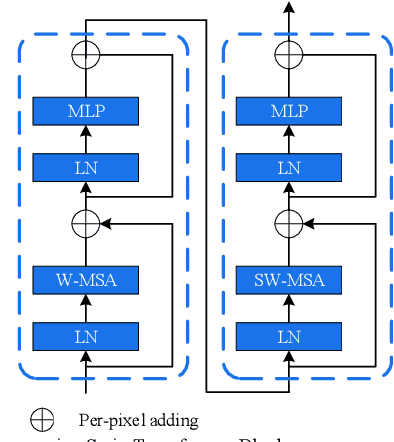

With the booming of Convolutional Neural Networks (CNNs), CNNs such as VGG-16 and ResNet-50 widely serve as backbone in SAR ship detection. However, CNN based backbone is hard to model long-range dependencies, and causes the lack of enough high-quality semantic information in feature maps of shallow layers, which leads to poor detection performance in complicated background and small-sized ships cases. To address these problems, we propose a SAR ship detection method based on Swin Transformer and Feature Enhancement Feature Pyramid Network (FEFPN). Swin Transformer serves as backbone to model long-range dependencies and generates hierarchical features maps. FEFPN is proposed to further improve the quality of feature maps by gradually enhancing the semantic information of feature maps at all levels, especially feature maps in shallow layers. Experiments conducted on SAR ship detection dataset (SSDD) reveal the advantage of our proposed methods.
E-VFIA : Event-Based Video Frame Interpolation with Attention
Sep 19, 2022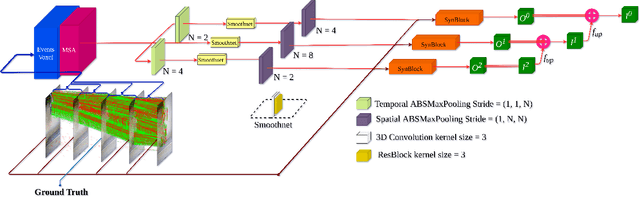
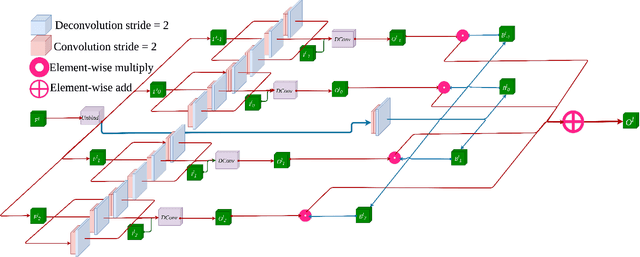
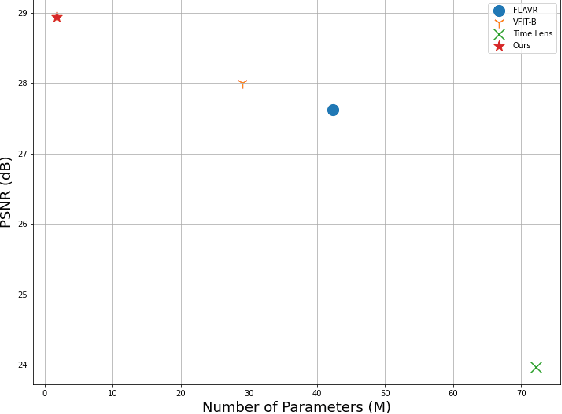
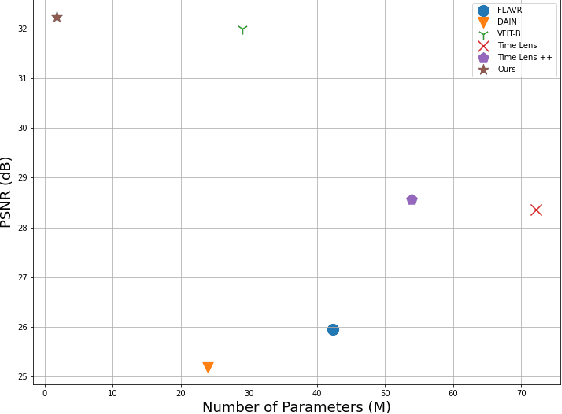
Video frame interpolation (VFI) is a fundamental vision task that aims to synthesize several frames between two consecutive original video images. Most algorithms aim to accomplish VFI by using only keyframes, which is an ill-posed problem since the keyframes usually do not yield any accurate precision about the trajectories of the objects in the scene. On the other hand, event-based cameras provide more precise information between the keyframes of a video. Some recent state-of-the-art event-based methods approach this problem by utilizing event data for better optical flow estimation to interpolate for video frame by warping. Nonetheless, those methods heavily suffer from the ghosting effect. On the other hand, some of kernel-based VFI methods that only use frames as input, have shown that deformable convolutions, when backed up with transformers, can be a reliable way of dealing with long-range dependencies. We propose event-based video frame interpolation with attention (E-VFIA), as a lightweight kernel-based method. E-VFIA fuses event information with standard video frames by deformable convolutions to generate high quality interpolated frames. The proposed method represents events with high temporal resolution and uses a multi-head self-attention mechanism to better encode event-based information, while being less vulnerable to blurring and ghosting artifacts; thus, generating crispier frames. The simulation results show that the proposed technique outperforms current state-of-the-art methods (both frame and event-based) with a significantly smaller model size.
SciFact-Open: Towards open-domain scientific claim verification
Oct 25, 2022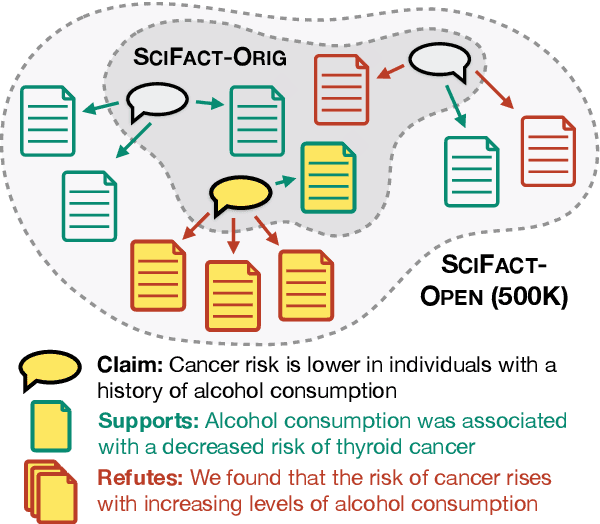
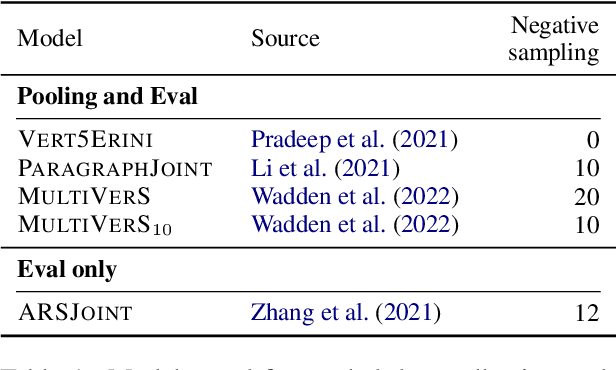


While research on scientific claim verification has led to the development of powerful systems that appear to approach human performance, these approaches have yet to be tested in a realistic setting against large corpora of scientific literature. Moving to this open-domain evaluation setting, however, poses unique challenges; in particular, it is infeasible to exhaustively annotate all evidence documents. In this work, we present SciFact-Open, a new test collection designed to evaluate the performance of scientific claim verification systems on a corpus of 500K research abstracts. Drawing upon pooling techniques from information retrieval, we collect evidence for scientific claims by pooling and annotating the top predictions of four state-of-the-art scientific claim verification models. We find that systems developed on smaller corpora struggle to generalize to SciFact-Open, exhibiting performance drops of at least 15 F1. In addition, analysis of the evidence in SciFact-Open reveals interesting phenomena likely to appear when claim verification systems are deployed in practice, e.g., cases where the evidence supports only a special case of the claim. Our dataset is available at https://github.com/dwadden/scifact-open.
Predicting Survival Outcomes in the Presence of Unlabeled Data
Oct 25, 2022Many clinical studies require the follow-up of patients over time. This is challenging: apart from frequently observed drop-out, there are often also organizational and financial challenges, which can lead to reduced data collection and, in turn, can complicate subsequent analyses. In contrast, there is often plenty of baseline data available of patients with similar characteristics and background information, e.g., from patients that fall outside the study time window. In this article, we investigate whether we can benefit from the inclusion of such unlabeled data instances to predict accurate survival times. In other words, we introduce a third level of supervision in the context of survival analysis, apart from fully observed and censored instances, we also include unlabeled instances. We propose three approaches to deal with this novel setting and provide an empirical comparison over fifteen real-life clinical and gene expression survival datasets. Our results demonstrate that all approaches are able to increase the predictive performance over independent test data. We also show that integrating the partial supervision provided by censored data in a semi-supervised wrapper approach generally provides the best results, often achieving high improvements, compared to not using unlabeled data.
Referee: Reference-Free Sentence Summarization with Sharper Controllability through Symbolic Knowledge Distillation
Oct 25, 2022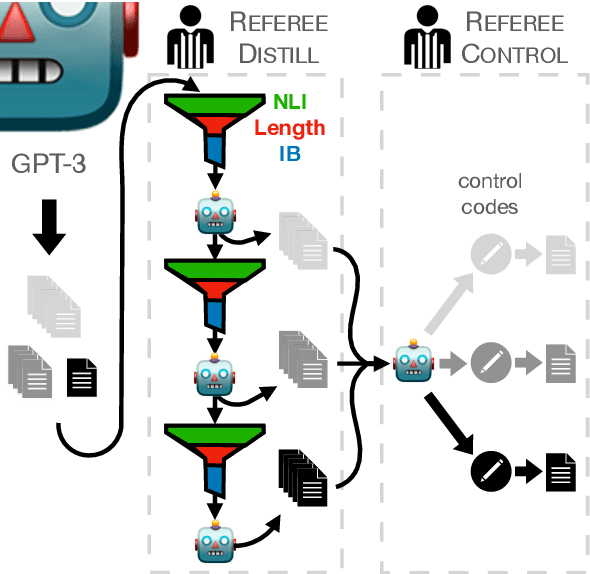
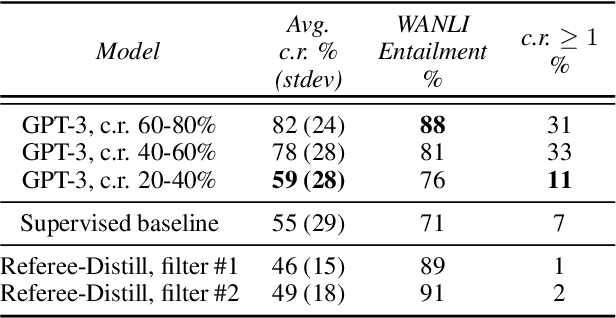
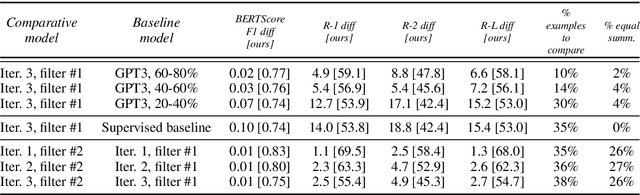
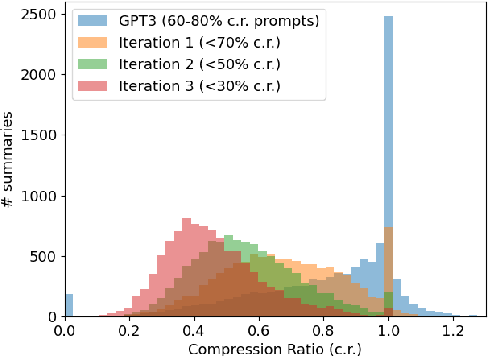
We present Referee, a novel framework for sentence summarization that can be trained reference-free (i.e., requiring no gold summaries for supervision), while allowing direct control for compression ratio. Our work is the first to demonstrate that reference-free, controlled sentence summarization is feasible via the conceptual framework of Symbolic Knowledge Distillation (West et al., 2022), where latent knowledge in pre-trained language models is distilled via explicit examples sampled from the teacher models, further purified with three types of filters: length, fidelity, and Information Bottleneck. Moreover, we uniquely propose iterative distillation of knowledge, where student models from the previous iteration of distillation serve as teacher models in the next iteration. Starting off from a relatively modest set of GPT3-generated summaries, we demonstrate how iterative knowledge distillation can lead to considerably smaller, but better summarizers with sharper controllability. A useful by-product of this iterative distillation process is a high-quality dataset of sentence-summary pairs with varying degrees of compression ratios. Empirical results demonstrate that the final student models vastly outperform the much larger GPT3-Instruct model in terms of the controllability of compression ratios, without compromising the quality of resulting summarization.
MEW-UNet: Multi-axis representation learning in frequency domain for medical image segmentation
Oct 25, 2022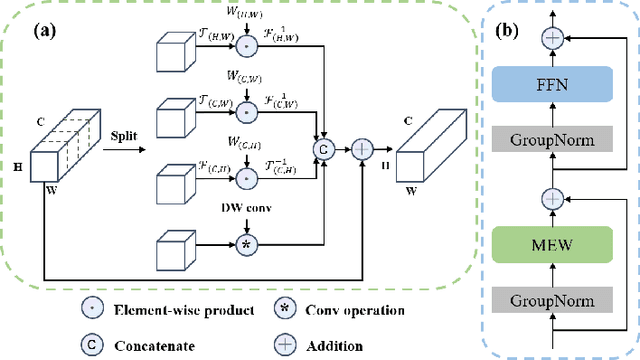
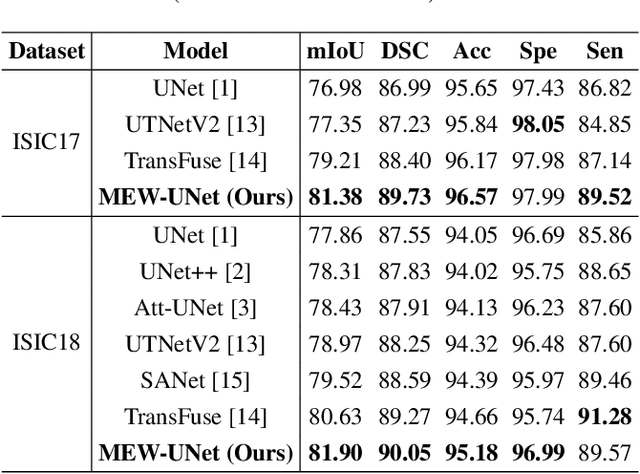
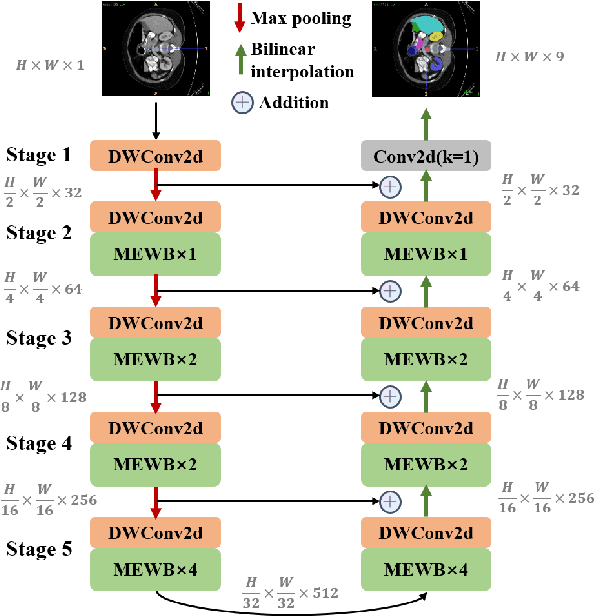
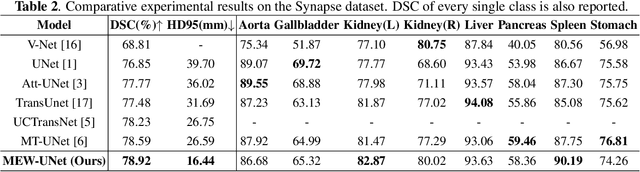
Recently, Visual Transformer (ViT) has been widely used in various fields of computer vision due to applying self-attention mechanism in the spatial domain to modeling global knowledge. Especially in medical image segmentation (MIS), many works are devoted to combining ViT and CNN, and even some works directly utilize pure ViT-based models. However, recent works improved models in the aspect of spatial domain while ignoring the importance of frequency domain information. Therefore, we propose Multi-axis External Weights UNet (MEW-UNet) for MIS based on the U-shape architecture by replacing self-attention in ViT with our Multi-axis External Weights block. Specifically, our block performs a Fourier transform on the three axes of the input feature and assigns the external weight in the frequency domain, which is generated by our Weights Generator. Then, an inverse Fourier transform is performed to change the features back to the spatial domain. We evaluate our model on four datasets and achieve state-of-the-art performances. In particular, on the Synapse dataset, our method outperforms MT-UNet by 10.15mm in terms of HD95. Code is available at https://github.com/JCruan519/MEW-UNet.
Geo-SIC: Learning Deformable Geometric Shapes in Deep Image Classifiers
Oct 25, 2022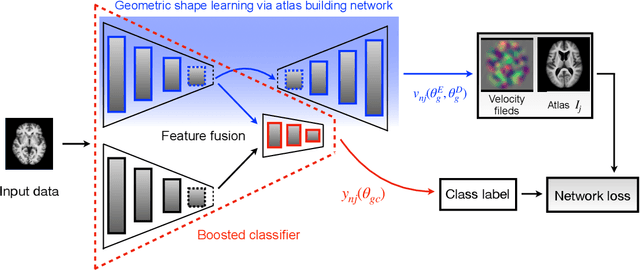
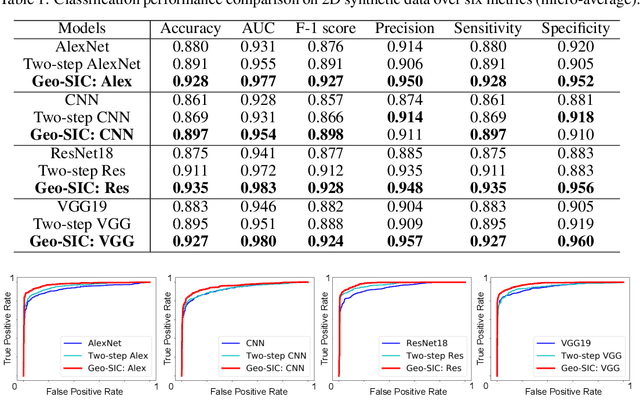
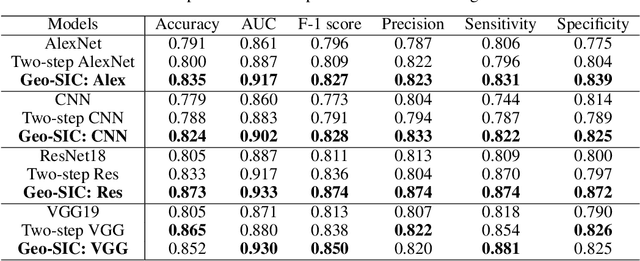
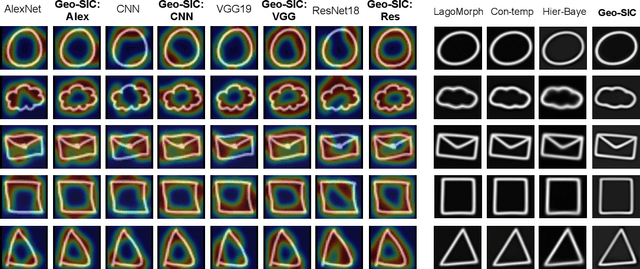
Deformable shapes provide important and complex geometric features of objects presented in images. However, such information is oftentimes missing or underutilized as implicit knowledge in many image analysis tasks. This paper presents Geo-SIC, the first deep learning model to learn deformable shapes in a deformation space for an improved performance of image classification. We introduce a newly designed framework that (i) simultaneously derives features from both image and latent shape spaces with large intra-class variations; and (ii) gains increased model interpretability by allowing direct access to the underlying geometric features of image data. In particular, we develop a boosted classification network, equipped with an unsupervised learning of geometric shape representations characterized by diffeomorphic transformations within each class. In contrast to previous approaches using pre-extracted shapes, our model provides a more fundamental approach by naturally learning the most relevant shape features jointly with an image classifier. We demonstrate the effectiveness of our method on both simulated 2D images and real 3D brain magnetic resonance (MR) images. Experimental results show that our model substantially improves the image classification accuracy with an additional benefit of increased model interpretability. Our code is publicly available at https://github.com/jw4hv/Geo-SIC
S3E: A Large-scale Multimodal Dataset for Collaborative SLAM
Oct 25, 2022
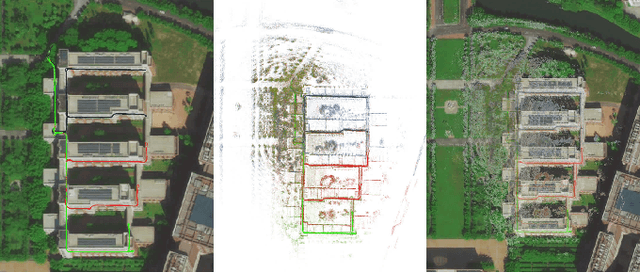
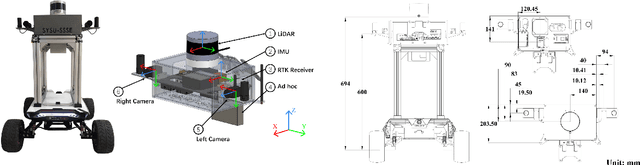
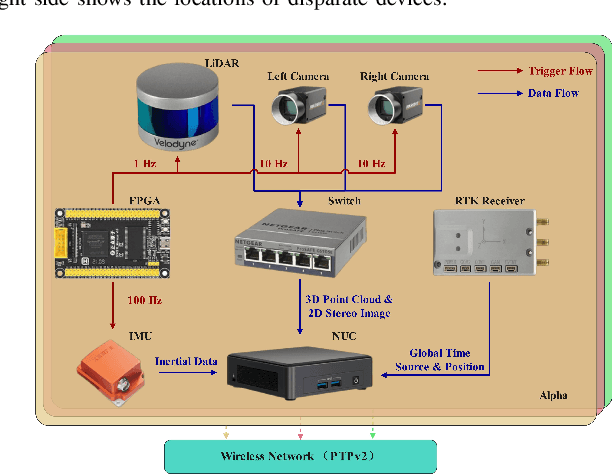
With the advanced request to employ a team of robots to perform a task collaboratively, the research community has become increasingly interested in collaborative simultaneous localization and mapping. Unfortunately, existing datasets are limited in the scale and variation of the collaborative trajectories they capture, even though generalization between inter-trajectories among different agents is crucial to the overall viability of collaborative tasks. To help align the research community's contributions with real-world multiagent ordinated SLAM problems, we introduce S3E, a novel large-scale multimodal dataset captured by a fleet of unmanned ground vehicles along four designed collaborative trajectory paradigms. S3E consists of 7 outdoor and 5 indoor scenes that each exceed 200 seconds, consisting of well synchronized and calibrated high-quality stereo camera, LiDAR, and high-frequency IMU data. Crucially, our effort exceeds previous attempts regarding dataset size, scene variability, and complexity. It has 4x as much average recording time as the pioneering EuRoC dataset. We also provide careful dataset analysis as well as baselines for collaborative SLAM and single counterparts. Find data, code, and more up-to-date information at https://github.com/PengYu-Team/S3E.
Sequential Decision Making on Unmatched Data using Bayesian Kernel Embeddings
Oct 25, 2022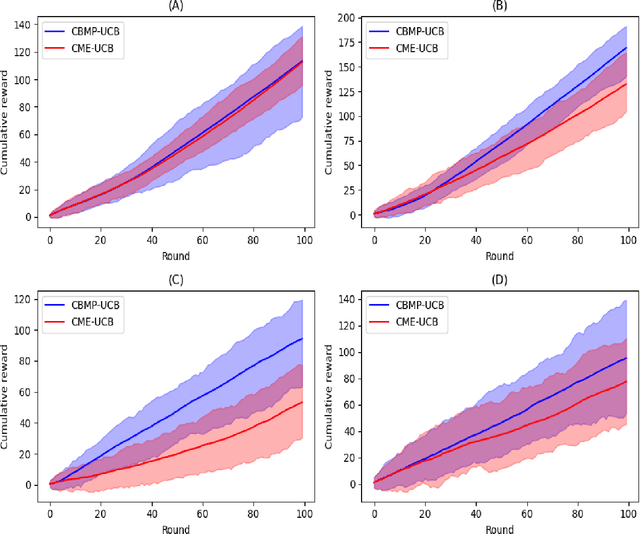
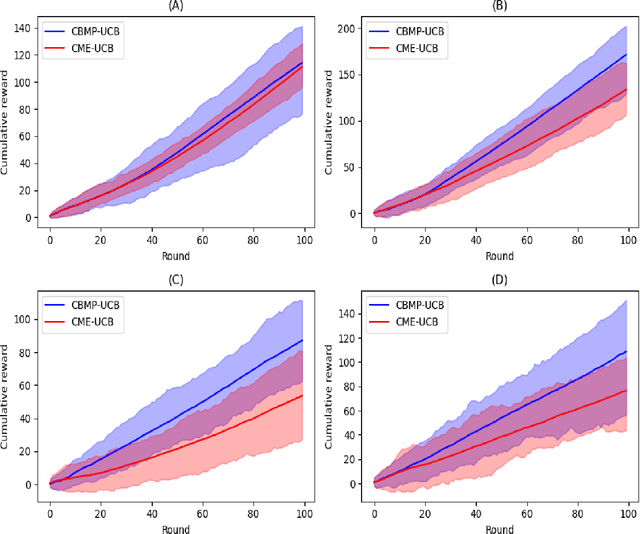
The problem of sequentially maximizing the expectation of a function seeks to maximize the expected value of a function of interest without having direct control on its features. Instead, the distribution of such features depends on a given context and an action taken by an agent. In contrast to Bayesian optimization, the arguments of the function are not under agent's control, but are indirectly determined by the agent's action based on a given context. If the information of the features is to be included in the maximization problem, the full conditional distribution of such features, rather than its expectation only, needs to be accounted for. Furthermore, the function is itself unknown, only counting with noisy observations of such function, and potentially requiring the use of unmatched data sets. We propose a novel algorithm for the aforementioned problem which takes into consideration the uncertainty derived from the estimation of both the conditional distribution of the features and the unknown function, by modeling the former as a Bayesian conditional mean embedding and the latter as a Gaussian process. Our algorithm empirically outperforms the current state-of-the-art algorithm in the experiments conducted.
PlanT: Explainable Planning Transformers via Object-Level Representations
Oct 25, 2022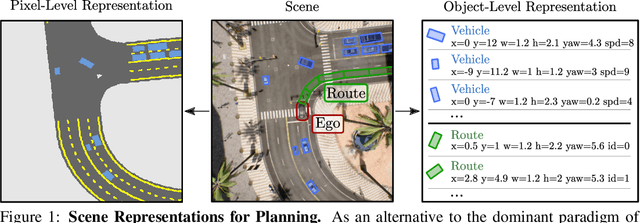

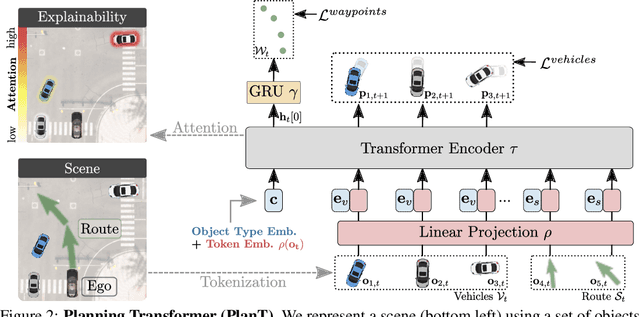
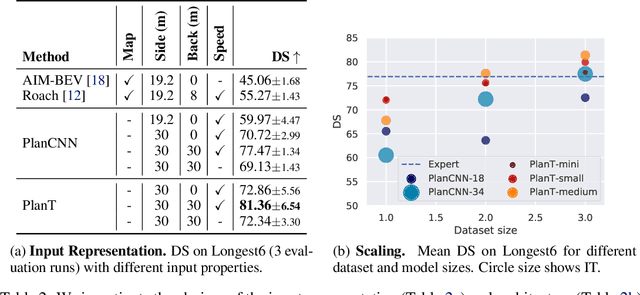
Planning an optimal route in a complex environment requires efficient reasoning about the surrounding scene. While human drivers prioritize important objects and ignore details not relevant to the decision, learning-based planners typically extract features from dense, high-dimensional grid representations containing all vehicle and road context information. In this paper, we propose PlanT, a novel approach for planning in the context of self-driving that uses a standard transformer architecture. PlanT is based on imitation learning with a compact object-level input representation. On the Longest6 benchmark for CARLA, PlanT outperforms all prior methods (matching the driving score of the expert) while being 5.3x faster than equivalent pixel-based planning baselines during inference. Combining PlanT with an off-the-shelf perception module provides a sensor-based driving system that is more than 10 points better in terms of driving score than the existing state of the art. Furthermore, we propose an evaluation protocol to quantify the ability of planners to identify relevant objects, providing insights regarding their decision-making. Our results indicate that PlanT can focus on the most relevant object in the scene, even when this object is geometrically distant.