 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MODNet: Multi-offset Point Cloud Denoising Network Customized for Multi-scale Patches
Sep 01, 2022
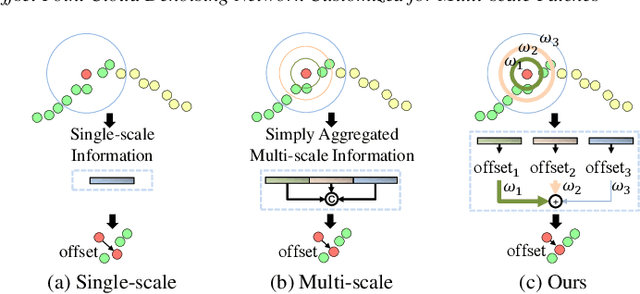
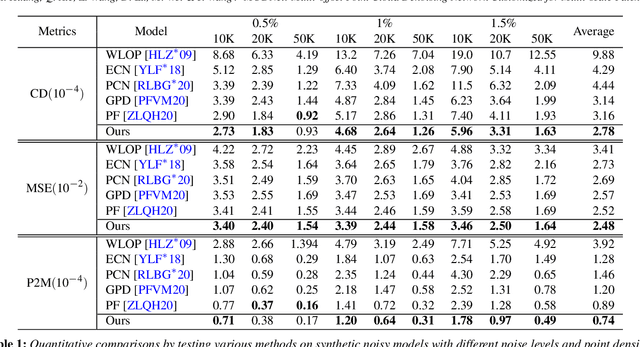
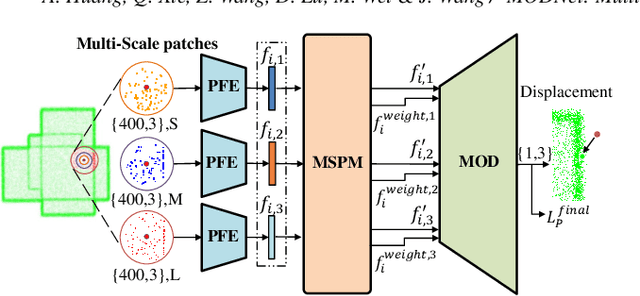
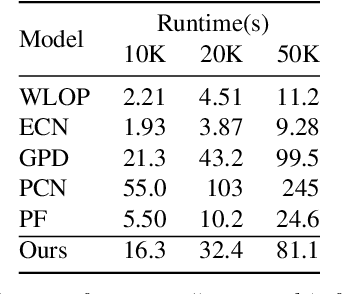
The intricacy of 3D surfaces often results cutting-edge point cloud denoising (PCD) models in surface degradation including remnant noise, wrongly-removed geometric details. Although using multi-scale patches to encode the geometry of a point has become the common wisdom in PCD, we find that simple aggregation of extracted multi-scale features can not adaptively utilize the appropriate scale information according to the geometric information around noisy points. It leads to surface degradation, especially for points close to edges and points on complex curved surfaces. We raise an intriguing question -- if employing multi-scale geometric perception information to guide the network to utilize multi-scale information, can eliminate the severe surface degradation problem? To answer it, we propose a Multi-offset Denoising Network (MODNet) customized for multi-scale patches. First, we extract the low-level feature of three scales patches by patch feature encoders. Second, a multi-scale perception module is designed to embed multi-scale geometric information for each scale feature and regress multi-scale weights to guide a multi-offset denoising displacement. Third, a multi-offset decoder regresses three scale offsets, which are guided by the multi-scale weights to predict the final displacement by weighting them adaptively. Experiments demonstrate that our method achieves new state-of-the-art performance on both synthetic and real-scanned datasets.
The Value of Information When Deciding What to Learn
Oct 26, 2021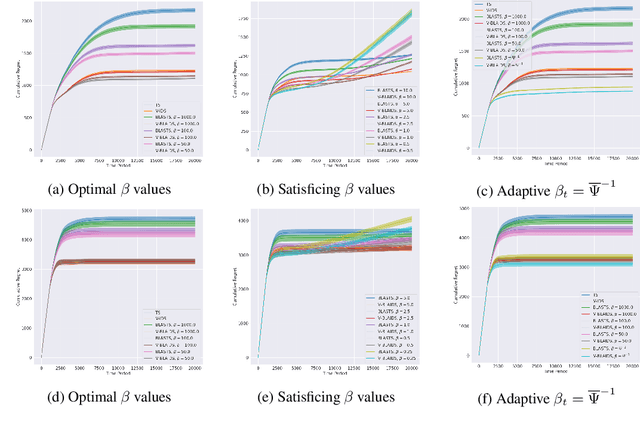
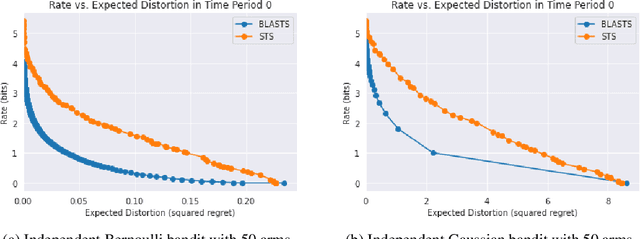
All sequential decision-making agents explore so as to acquire knowledge about a particular target. It is often the responsibility of the agent designer to construct this target which, in rich and complex environments, constitutes a onerous burden; without full knowledge of the environment itself, a designer may forge a sub-optimal learning target that poorly balances the amount of information an agent must acquire to identify the target against the target's associated performance shortfall. While recent work has developed a connection between learning targets and rate-distortion theory to address this challenge and empower agents that decide what to learn in an automated fashion, the proposed algorithm does not optimally tackle the equally important challenge of efficient information acquisition. In this work, building upon the seminal design principle of information-directed sampling (Russo & Van Roy, 2014), we address this shortcoming directly to couple optimal information acquisition with the optimal design of learning targets. Along the way, we offer new insights into learning targets from the literature on rate-distortion theory before turning to empirical results that confirm the value of information when deciding what to learn.
DMAP: a Distributed Morphological Attention Policy for Learning to Locomote with a Changing Body
Sep 28, 2022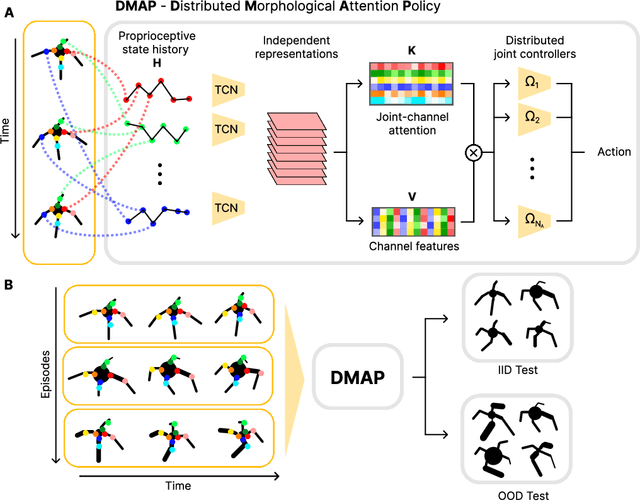
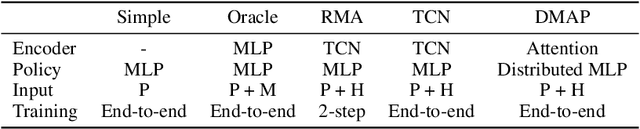
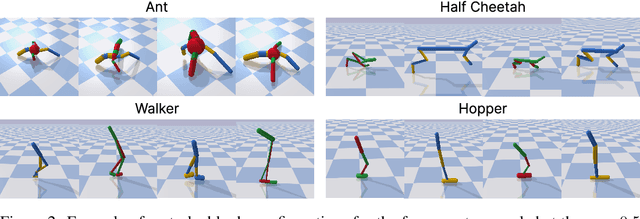

Biological and artificial agents need to deal with constant changes in the real world. We study this problem in four classical continuous control environments, augmented with morphological perturbations. Learning to locomote when the length and the thickness of different body parts vary is challenging, as the control policy is required to adapt to the morphology to successfully balance and advance the agent. We show that a control policy based on the proprioceptive state performs poorly with highly variable body configurations, while an (oracle) agent with access to a learned encoding of the perturbation performs significantly better. We introduce DMAP, a biologically-inspired, attention-based policy network architecture. DMAP combines independent proprioceptive processing, a distributed policy with individual controllers for each joint, and an attention mechanism, to dynamically gate sensory information from different body parts to different controllers. Despite not having access to the (hidden) morphology information, DMAP can be trained end-to-end in all the considered environments, overall matching or surpassing the performance of an oracle agent. Thus DMAP, implementing principles from biological motor control, provides a strong inductive bias for learning challenging sensorimotor tasks. Overall, our work corroborates the power of these principles in challenging locomotion tasks.
Prompt-driven efficient Open-set Semi-supervised Learning
Sep 28, 2022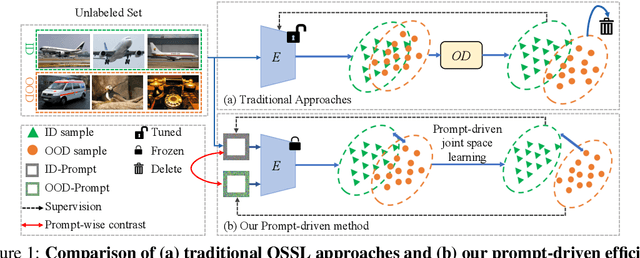
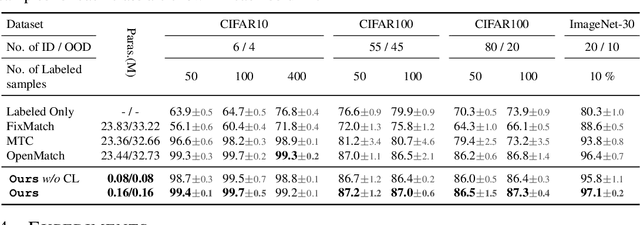
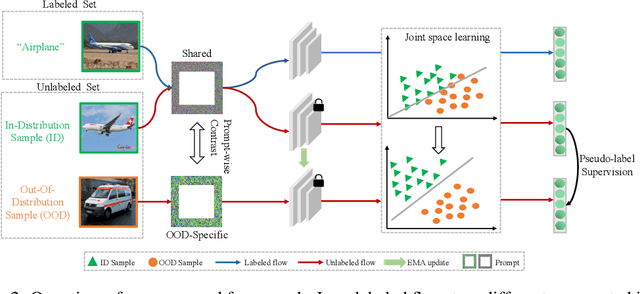
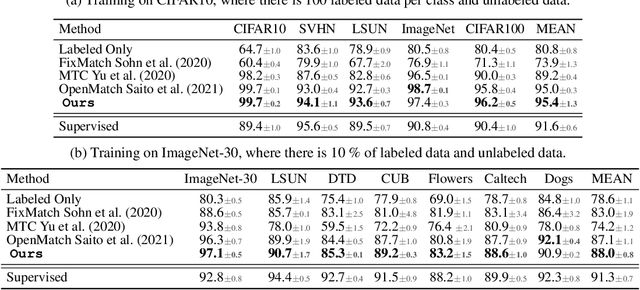
Open-set semi-supervised learning (OSSL) has attracted growing interest, which investigates a more practical scenario where out-of-distribution (OOD) samples are only contained in unlabeled data. Existing OSSL methods like OpenMatch learn an OOD detector to identify outliers, which often update all modal parameters (i.e., full fine-tuning) to propagate class information from labeled data to unlabeled ones. Currently, prompt learning has been developed to bridge gaps between pre-training and fine-tuning, which shows higher computational efficiency in several downstream tasks. In this paper, we propose a prompt-driven efficient OSSL framework, called OpenPrompt, which can propagate class information from labeled to unlabeled data with only a small number of trainable parameters. We propose a prompt-driven joint space learning mechanism to detect OOD data by maximizing the distribution gap between ID and OOD samples in unlabeled data, thereby our method enables the outliers to be detected in a new way. The experimental results on three public datasets show that OpenPrompt outperforms state-of-the-art methods with less than 1% of trainable parameters. More importantly, OpenPrompt achieves a 4% improvement in terms of AUROC on outlier detection over a fully supervised model on CIFAR10.
Cross-modal Learning for Image-Guided Point Cloud Shape Completion
Sep 20, 2022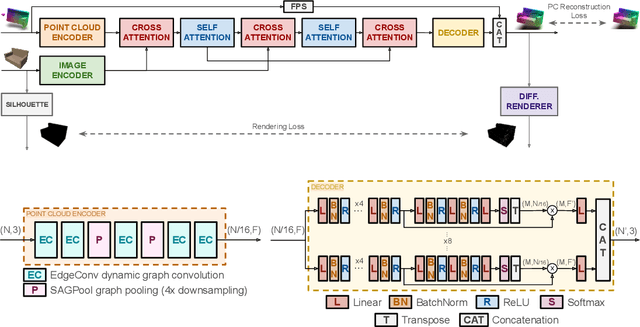
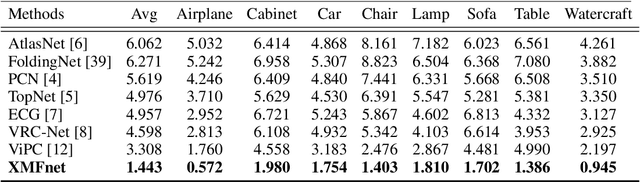
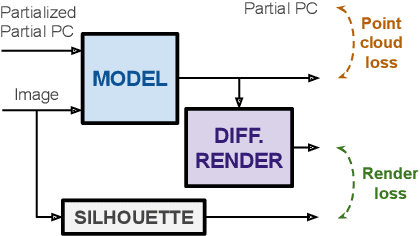
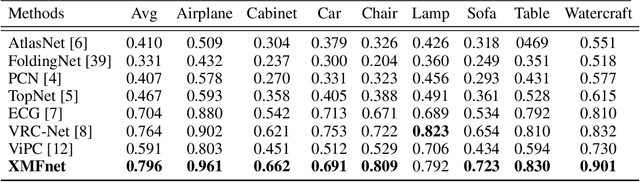
In this paper we explore the recent topic of point cloud completion, guided by an auxiliary image. We show how it is possible to effectively combine the information from the two modalities in a localized latent space, thus avoiding the need for complex point cloud reconstruction methods from single views used by the state-of-the-art. We also investigate a novel weakly-supervised setting where the auxiliary image provides a supervisory signal to the training process by using a differentiable renderer on the completed point cloud to measure fidelity in the image space. Experiments show significant improvements over state-of-the-art supervised methods for both unimodal and multimodal completion. We also show the effectiveness of the weakly-supervised approach which outperforms a number of supervised methods and is competitive with the latest supervised models only exploiting point cloud information.
Structure-Preserving Graph Representation Learning
Sep 02, 2022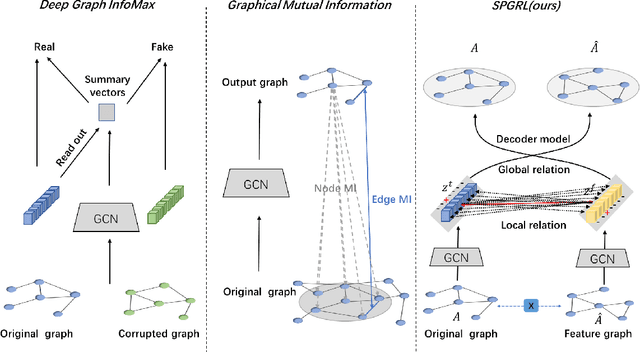

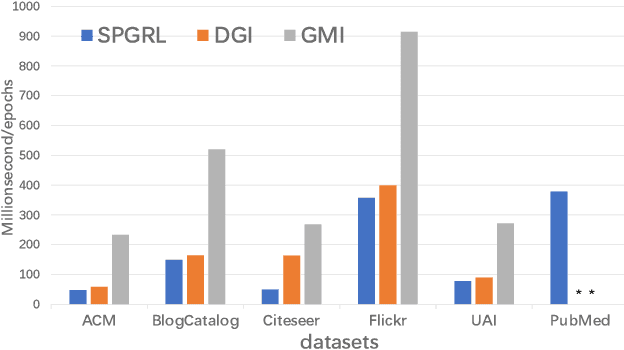
Though graph representation learning (GRL) has made significant progress, it is still a challenge to extract and embed the rich topological structure and feature information in an adequate way. Most existing methods focus on local structure and fail to fully incorporate the global topological structure. To this end, we propose a novel Structure-Preserving Graph Representation Learning (SPGRL) method, to fully capture the structure information of graphs. Specifically, to reduce the uncertainty and misinformation of the original graph, we construct a feature graph as a complementary view via k-Nearest Neighbor method. The feature graph can be used to contrast at node-level to capture the local relation. Besides, we retain the global topological structure information by maximizing the mutual information (MI) of the whole graph and feature embeddings, which is theoretically reduced to exchanging the feature embeddings of the feature and the original graphs to reconstruct themselves. Extensive experiments show that our method has quite superior performance on semi-supervised node classification task and excellent robustness under noise perturbation on graph structure or node features.
MLT-LE: predicting drug-target binding affinity with multi-task residual neural networks
Sep 13, 2022

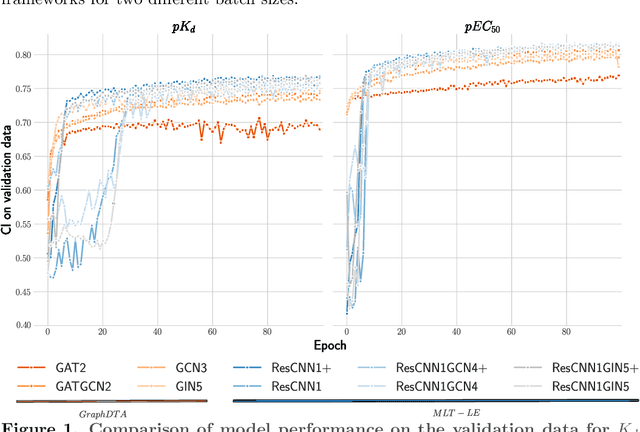
Assessing drug-target affinity is a critical step in the drug discovery and development process, but to obtain such data experimentally is both time consuming and expensive. For this reason, computational methods for predicting binding strength are being widely developed. However, these methods typically use a single-task approach for prediction, thus ignoring the additional information that can be extracted from the data and used to drive the learning process. Thereafter in this work, we present a multi-task approach for binding strength prediction. Our results suggest that these prediction can indeed benefit from a multi-task learning approach, by utilizing added information from related tasks and multi-task induced regularization.
Estimating and Maximizing Mutual Information for Knowledge Distillation
Oct 29, 2021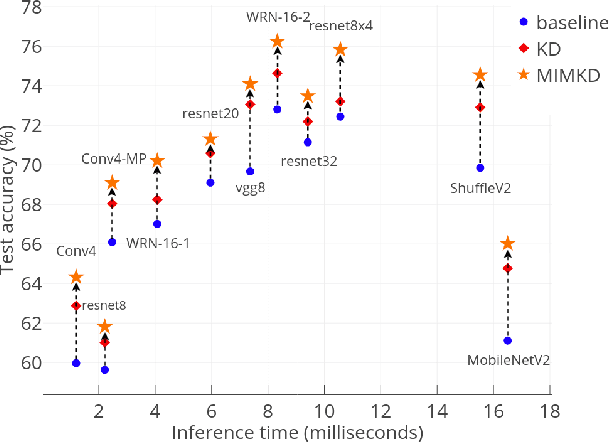
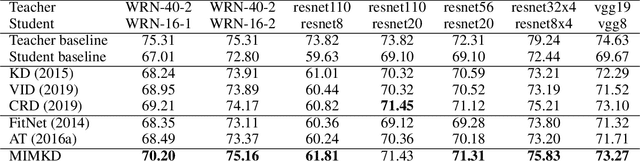
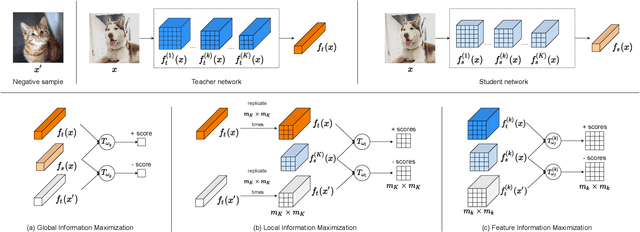
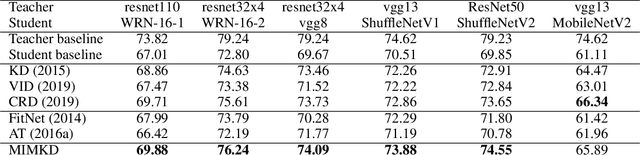
Knowledge distillation is a widely used general technique to transfer knowledge from a teacher network to a student network. In this work, we propose Mutual Information Maximization Knowledge Distillation (MIMKD). Our method uses a contrastive objective to simultaneously estimate and maximize a lower bound on the mutual information between intermediate and global feature representations from the teacher and the student networks. Our method is flexible, as the proposed mutual information maximization does not impose significant constraints on the structure of the intermediate features of the networks. As such, we can distill knowledge from arbitrary teachers to arbitrary students. Our empirical results show that our method outperforms competing approaches across a wide range of student-teacher pairs with different capacities, with different architectures, and when student networks are with extremely low capacity. We are able to obtain 74.55% accuracy on CIFAR100 with a ShufflenetV2 from a baseline accuracy of 69.8% by distilling knowledge from ResNet50.
Sar Ship Detection based on Swin Transformer and Feature Enhancement Feature Pyramid Network
Sep 21, 2022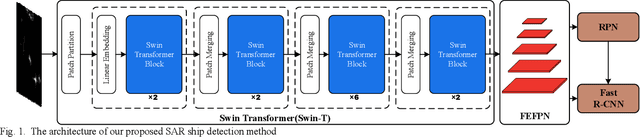

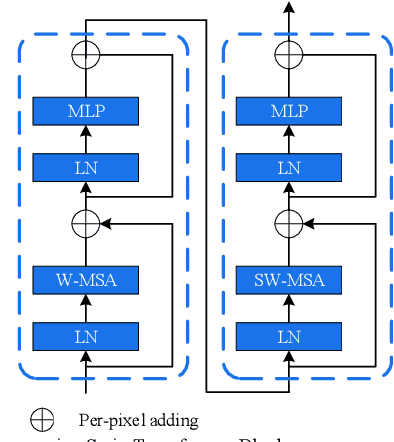

With the booming of Convolutional Neural Networks (CNNs), CNNs such as VGG-16 and ResNet-50 widely serve as backbone in SAR ship detection. However, CNN based backbone is hard to model long-range dependencies, and causes the lack of enough high-quality semantic information in feature maps of shallow layers, which leads to poor detection performance in complicated background and small-sized ships cases. To address these problems, we propose a SAR ship detection method based on Swin Transformer and Feature Enhancement Feature Pyramid Network (FEFPN). Swin Transformer serves as backbone to model long-range dependencies and generates hierarchical features maps. FEFPN is proposed to further improve the quality of feature maps by gradually enhancing the semantic information of feature maps at all levels, especially feature maps in shallow layers. Experiments conducted on SAR ship detection dataset (SSDD) reveal the advantage of our proposed methods.
Forgery Attack Detection in Surveillance Video Streams Using Wi-Fi Channel State Information
Jan 24, 2022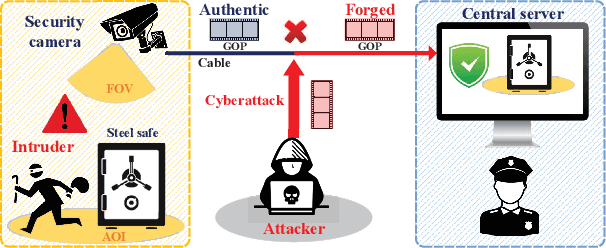
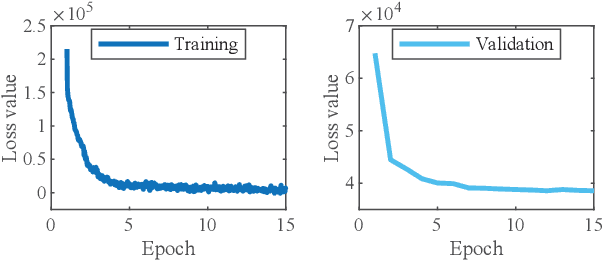
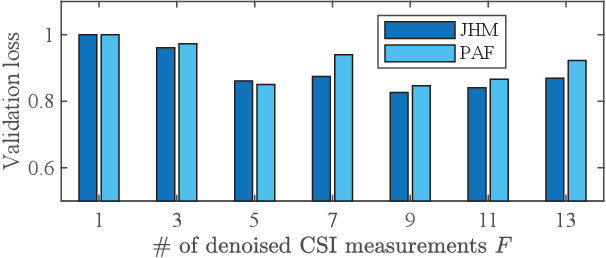
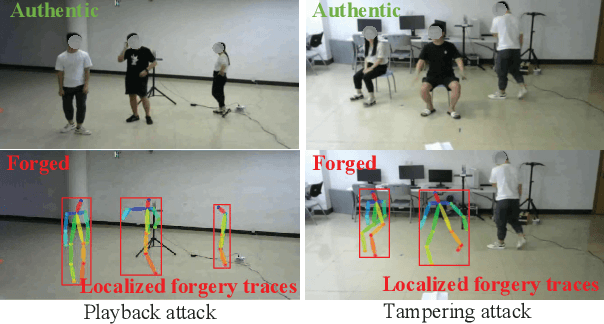
The cybersecurity breaches expose surveillance video streams to forgery attacks, under which authentic streams are falsified to hide unauthorized activities. Traditional video forensics approaches can localize forgery traces using spatial-temporal analysis on relatively long video clips, while falling short in real-time forgery detection. The recent work correlates time-series camera and wireless signals to detect looped videos but cannot realize fine-grained forgery localization. To overcome these limitations, we propose Secure-Pose, which exploits the pervasive coexistence of surveillance and Wi-Fi infrastructures to defend against video forgery attacks in a real-time and fine-grained manner. We observe that coexisting camera and Wi-Fi signals convey common human semantic information and forgery attacks on video streams will decouple such information correspondence. Particularly, retrievable human pose features are first extracted from concurrent video and Wi-Fi channel state information (CSI) streams. Then, a lightweight detection network is developed to accurately discover forgery attacks and an efficient localization algorithm is devised to seamlessly track forgery traces in video streams. We implement Secure-Pose using one Logitech camera and two Intel 5300 NICs and evaluate it in different environments. Secure-Pose achieves a high detection accuracy of 98.7% and localizes abnormal objects under playback and tampering attacks.